Prologue
-
Java로 알고리즘/코딩테스트에서 자주 쓰이는 문법들을 정리하기 위한 포스팅이다.
-
(2025.07.26) 최근에 LeetCode로 문제를 풀면서 새롭게 알게된 개념 및 내용들을 추가했다.
구현
-
구현은 머릿속에 있는 알고리즘을 소스코드로 바꾸는 과정이다.
-
Problem -> Thinking -> Solution
-
구현 유형의 예시는 다음과 같다.
-
알고리즘은 간단한데 코드가 지나칠 만큼 길어지는 문제
-
실수 연산을 다루고, 특정 소수점 자리까지 출력해야 하는 문제
-
문자열을 특정한 기준에 따라서 끊어 처리해야 하는 문제
-
적절한 라이브러리를 찾아서 사용해야 하는 문제
-
-
-
구현 유형은
완전 탐색,시뮬레이션을 포함한다.완전 탐색(Brute Forcing) : 모든 경우의 수를 주저 없이 다 계산하는 해결 방법시뮬레이션: 문제에서 제시한 알고리즘을 한 단계씩 차례대로 직접 수행
관련 문제
DFS/BFS
- 깊이 우선 탐색과 너비 우선 탐색은 기본적인 그래프 기법 : DFS, BFS에 정리했으니, 해당 글을 참고하자.
유형1. 연결된 요소 찾기
-
연결된 노드의 개수는 몇 개인가요?
-
연결된 묶음/덩어리의 개수는 몇 개인가요?
-
1번과 연결된 노드의 번호를 오름차순으로 출력하세요
-
1번과 3번의 거리는 얼마인가요?
이 유형을 잘 풀기 위해 고민할 것들
-
주요 키워드: 정점(node), 간선(edge), 연결, 네트워크, 그래프
-
주어진 정보를 어떻게 변환할지 -> 2차원 배열(1,000이하) / ArrayList(1,000 초과)
-
재방문을 방지하는 방법
관련 문제
유형2. 같은 부류 찾기
-
연결된 묶음/덩어리의 개수는 몇 개인가요?
-
가장 큰 덩어리의 크기는 얼마인가요?
이 유형을 잘 풀기 위해 고민할 것들
-
주요 키워드: 인접한 위치로 이동, 상하좌우, 가로/세로, 대각선으로 이동
-
주어진 정보를 어떻게 변환할지
-
재방문을 방지하는 방법
-
어느 지점에서 DFS를 시작할지
-
어느 방향으로 DFS를 진행할지
그외
Stack
-
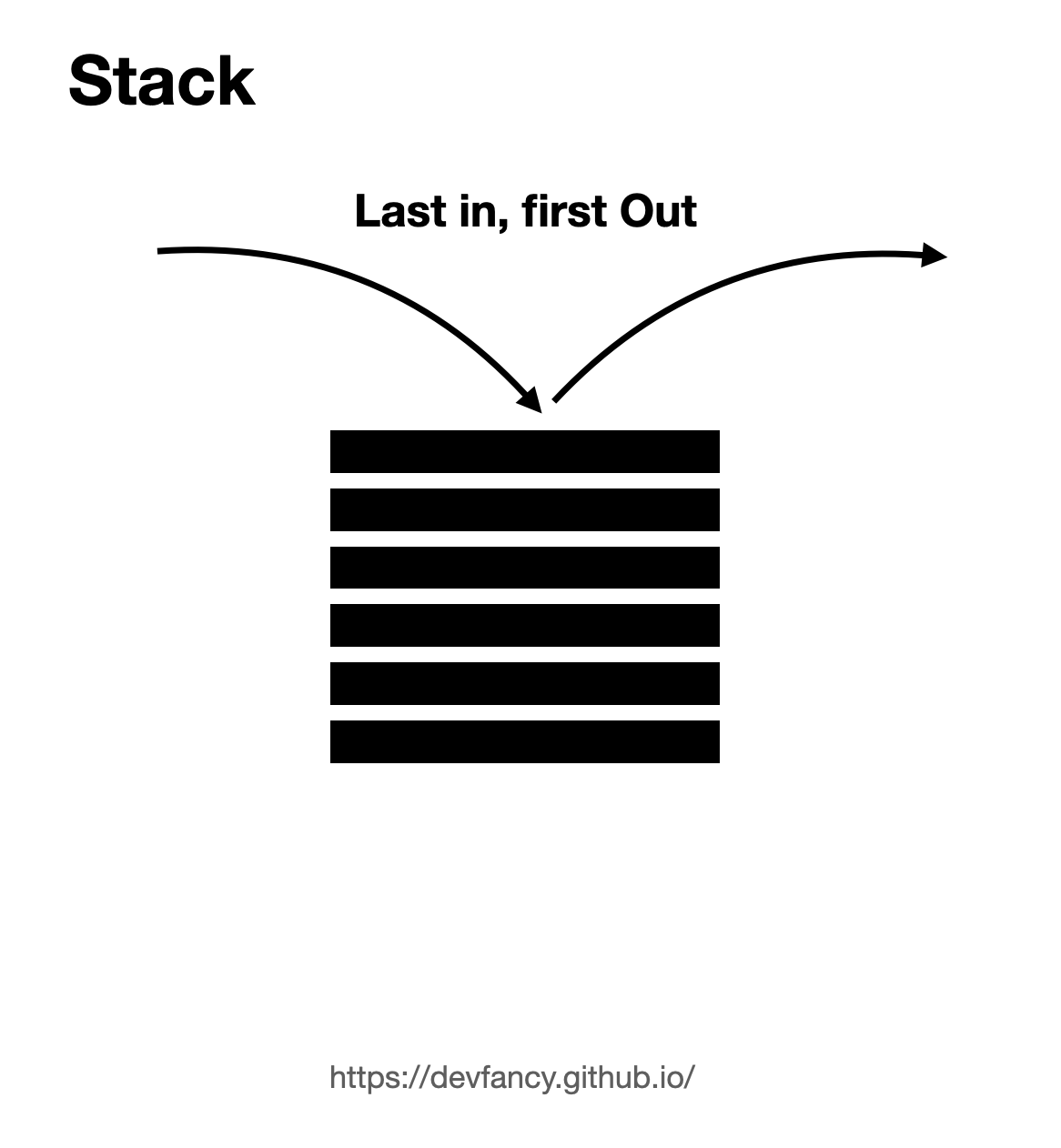
스택은
LIFO(List In First Out, 후입선출) 구조로 데이터를 쌓아올린 형태의 자료구조를 뜻한다. ex) 쓰레기통, 마트용 음료수 진열대, 프링X스(과자) -
즉 한쪽 끝에서만 자료(데이터)를 넣고 뺄 수 있는 형식의 자료 구조이다.
-
스택은 데이터를 쌓는 형식으로 저장하는데 따라서 조회, 추가, 삭제 모두 가장 위에 있는, 가장 최근의 값에서 이루어진다.
-
스택 구조에서 가장 상단에 있는 데이터를
Top라 부른다.
2025.07.26 업데이트
Stack클래스 대신Deque인터페이스를 사용하는 것을 권장한다.
-
Java에서
Stack클래스는 오래된Vector클래스를 상속받아 만들어져 지금은 사용이 권장되지 않는다. -
대신,
Deque(데크) 인터페이스와 그 구현체인ArrayDeque를 사용하면 스택의 모든 기능을 더 빠르고 효율적으로 사용할 수 있다.
관련 문제
Stack 선언 (Deque 사용)
import java.util.ArrayDeque;
import java.util.Deque;
// Deque 인터페이스를 사용하여 Stack을 선언 (ArrayDeque이 가장 일반적)
Deque<Integer> stack = new ArrayDeque<>();
Deque<String> stack2 = new ArrayDeque<>();
주요 메서드 (Deque 기준)
-
void push(E item): 스택의 맨 위에 데이터를 추가한다. -
E pop(): 스택의 맨 위 데이터를 꺼내서 반환한다. 스택이 비어있으면 예외가 발생한다. -
E peek(): 스택의 맨 위 데이터를 확인만 하고 제거하지는 않는다. 스택이 비어있으면null을 반환한다. -
boolean isEmpty(): 스택이 비어있는지 확인한다. 비어있으면true를 반환한다. -
int size(): 스택에 저장된 요소의 개수를 반환한다.
Stack 예제 (Deque 사용)
import java.util.ArrayDeque;
import java.util.Deque;
public class StackExample {
public static void main(String[] args) {
Deque<Integer> stack = new ArrayDeque<>();
// 데이터 추가
stack.push(1);
stack.push(2);
stack.push(3);
System.out.println("현재 스택: " + stack); // [1, 2, 3]
// 맨 위 데이터 확인
System.out.println("가장 위의 데이터: " + stack.peek()); // 3
// 데이터 꺼내기
System.out.println("꺼낸 데이터: " + stack.pop()); // 3
System.out.println("현재 스택: " + stack); // [1, 2]
// 스택이 비어있는지 확인
System.out.println("스택이 비었나요? " + stack.isEmpty()); // false
}
}
Queue
-
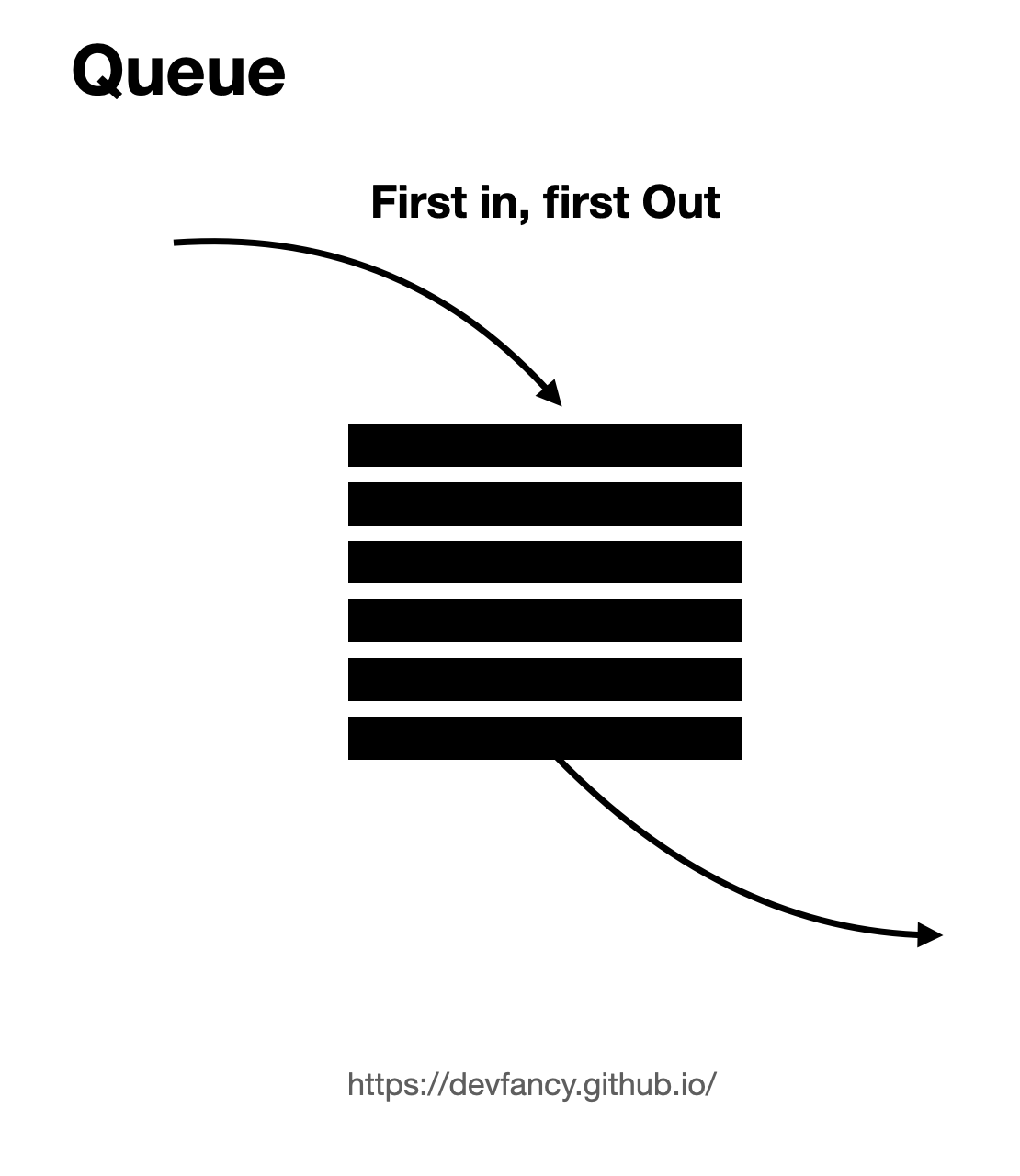
큐는
FIFO(First In First Out, 선입선출) 데이터를 순서대로 줄을 세운 형태의 자료구조를 뜻한다. ex) 놀이공원 이나 매표소 등 줄을 서서 차례로 업무를 처리하는 경우 -
주로
앞(frotn)에서는조회/삭제연산을 수행하고,뒤(Rear)에서는삽입연산을 수행한다. -
그래프의 넓이 우선 탐색(BFS)에서도 사용된다.
-
용어 정리
-
Enqueue: 큐 맨 뒤에 데이터 추가 -
Dequeue: 큐 맨 앞쪽의 데이터 삭제
-
관련 문제
Queue 선언
Queue는 인터페이스이므로, 실제 구현체인 LinkedList나 ArrayDeque를 사용해 인스턴스를 생성해야 한다.
import java.util.LinkedList;
import java.util.Queue;
import java.util.ArrayDeque;
// Queue 인터페이스로 선언 (LinkedList가 일반적)
Queue<Integer> queue1 = new LinkedList<>();
Queue<String> queue2 = new ArrayDeque<>(); // ArrayDeque도 Queue 구현체라 사용 가능
-
자바에서 큐는
LinkedList를 활용하여 생성해야 한다. 그렇기에 그렇기에Queue와LinkedList가 다 import되어 있어야 사용이 가능하다. -
Queue<Element> queue = new LinkedList<>()와 같이 선언해주면 된다.
Queue 주요 메서드
-
boolean offer(E e): 큐의 맨 뒤에 데이터를 추가한다. 성공 시true를 반환한다. (add는 실패 시 예외 발생) -
E poll(): 큐의 맨 앞에 있는 데이터를 꺼내서 반환한다. 큐가 비어있으면null을 반환한다. -
E peek(): 큐의 맨 앞에 있는 데이터를 확인만 하고 제거하지는 않는다. 큐가 비어있으면null을 반환한다. -
boolean isEmpty(): 큐가 비어있는지 확인한다. -
int size(): 큐에 저장된 요소의 개수를 반환한다.
Queue 예제
import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<>();
// 데이터 추가
queue.offer("고객1");
queue.offer("고객2");
queue.offer("고객3");
System.out.println("현재 대기열: " + queue); // [고객1, 고객2, 고객3]
// 맨 앞 데이터 확인
System.out.println("다음에 처리할 고객: " + queue.peek()); // 고객1
// 데이터 처리 (꺼내기)
System.out.println(queue.poll() + "님 업무 처리 완료"); // 고객1
System.out.println("현재 대기열: " + queue); // [고객2, 고객3]
// 대기열이 비었는지 확인
System.out.println("대기 고객이 없나요? " + queue.isEmpty()); // false
}
}
HashMap
-
맵(Map)은 key와 value로 이루어져 있고, 두개의 값이 한 쌍을 이루어 데이터를 저장하는 자료구조이다.
-
key는 중복될 수 없으며, 순서가 보장되지 않는다.
관련 문제
HashMap 선언
import java.util.HashMap;
import java.util.Map;
// HashMap 선언 (Map 인터페이스로 선언하는 것이 일반적)
Map<String, Integer> map = new HashMap<>(); // Key: String, Value: Integer
Map<String, String> map2 = new HashMap<>(); // Key: String, Value: String
HashMap 주요 메서드
-
데이터 추가
V put(K key, V value): key와 value를 저장한다.
-
데이터 삭제
-
void clear(): 모든 데이터를 삭제한다. -
V remove(Object key): key와 일치하는 기존 데이터(key와 value)를 삭제한다. -
boolean remove(Object key, Object value): key와 value가 동시에 일치하는 데이터를 삭제한다.
-
-
데이터 수정
-
V replace(K key, V value): key와 일치하는 기존 데이터의 value를 변경한다. -
V replace(K key, V oldValue, V newValue): key와 oldValue가 동시에 일치하는 데이터의 value를 newValue로 변경한다.
-
-
데이터 확인
-
boolean containsKey(Object key): key와 일치하는 데이터가 있는지 여부를 반환한다. (있으면 true) -
boolean containsValue(Object value): value가 일치하는 데이터가 있는지 여부를 반환한다. (있으면 true) -
boolean isEmpty( ): 데이터가 빈 상태인지 여부를 반환한다. (빈 상태면 true) -
int size( ): key-value 맵핑 데이터의 개수를 반환한다.
-
-
데이터 반환
-
V get(Object key): key와 맵핑된 value값을 반환한다. -
V getOrDefault(Object key, V defaultValue): key와 맵핑된 value값을 반환하고 없으면 defaultValue값을 반환한다. -
Set<Map.Entry<K, V>> entrySet( ): 모든 key-value 맵핑 데이터를 가진 Set 데이터를 반환한다. -
Set<K> keySet(): 모든 key 값을 가진 Set 데이터를 반환한다. -
Collection<V> values(): 모든 value 값을 가진 Collection 데이터를 반환한다.
-
HashMap 예제
다음은 HashMap의 기본적인 사용법을 보여주는 예제 코드이다.
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// 메뉴와 가격을 저장할 HashMap 생성
Map<String, Integer> menu = new HashMap<>();
// 데이터 추가
menu.put("햄버거", 8000);
menu.put("피자", 15000);
menu.put("치킨", 20000);
// 데이터 조회
System.out.println("피자 가격: " + menu.get("피자")); // 15000
// 데이터 존재 여부 확인
System.out.println("치킨이 메뉴에 있나요? " + menu.containsKey("치킨")); // true
// 데이터 개수 확인
System.out.println("총 메뉴 개수: " + menu.size()); // 3
// 데이터 삭제
menu.remove("햄버거");
// 전체 데이터 출력
System.out.println("현재 메뉴판: " + menu); // {피자=15000, 치킨=20000}
}
}
HashSet
HashSet은 중복된 값을 허용하지 않는 데이터의 집합을 다룰 때 유용한 자료구조이다.
내부적으로 HashMap을 사용하여 데이터를 저장하며, 이로 인해 순서를 보장하지 않는다는 특징이 있다.
알고리즘 문제에서 HashSet은 주로 다음과 같은 상황에서 효과적으로 사용된다.
-
중복된 원소를 간단하게 제거하고 싶을 때
-
특정 값이 이전에 등장했는지 빠르게 확인해야 할 때 (시간 복잡도 O(1))
-
데이터의 순서가 중요하지 않을 때
관련 문제
HashSet 선언
HashSet을 사용하려면 먼저 java.util.HashSet 을 import 해야 한다.
import java.util.HashSet; // import
// HashSet 선언
HashSet<String> stringHashSet = new HashSet<>(); // String 타입의 HashSet
HashSet<Integer> integerHashSet = new HashSet<>(); // Integer 타입의 HashSet
HashSet 주요 메서드
HashSet은 다음과 같은 주요 메서드를 제공한다.
-
boolean add(E e):HashSet에 요소를 추가한다. 성공적으로 추가되면true, 이미 존재하는 요소라 추가되지 않으면false를 반환한다. -
boolean remove(Object o):HashSet에서 특정 요소를 삭제한다. 요소가 존재하여 성공적으로 삭제되면true, 없으면false를 반환한다. -
boolean contains(Object o):HashSet에 특정 요소가 포함되어 있는지 확인한다. 포함되어 있으면true, 없으면false를 반환한다. -
void clear():HashSet의 모든 요소를 제거한다. -
int size():HashSet에 저장된 요소의 개수를 반환한다. -
boolean isEmpty():HashSet이 비어있는지 확인한다. 비어있으면true, 아니면false를 반환한다.
HashSet 예제
다음은 HashSet의 기본적인 사용법을 보여주는 예제 코드이다.
import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
Set<String> menu = new HashSet<>();
// 데이터 추가
menu.add("햄버거");
menu.add("피자");
menu.add("치킨");
menu.add("햄버거"); // 중복된 값은 추가되지 않음
// 데이터 포함 여부 확인
System.out.println("피자가 있나요? " + menu.contains("피자")); // true
System.out.println("파스타가 있나요? " + menu.contains("파스타")); // false
// 크기 확인
System.out.println("메뉴의 종류: " + menu.size()); // 3
// 데이터 삭제
menu.remove("치킨");
System.out.println("치킨 삭제 후 종류: " + menu.size()); // 2
// 전체 데이터 출력 (순서는 보장되지 않음)
System.out.println("현재 메뉴: " + menu); // 예: [피자, 햄버거]
}
}
문자열
String.toCharArray()
-
String.toCharArray()은 문자열을 한 글자씩 쪼개서 이를 char타입의 배열에 집어넣어주는 메소드이다. -
String(문자열)을 char형 배열로 바꾼다.
class Solution {
static boolean v[][]; // 체크 배열
public int solution(int m, int n, String[] board) {
int answer = 0;
char copy [][] = new char[m][n];
// 보드를 2차원 문자 배열로 복사합니다.
for(int i = 0; i < m; i++) {
copy[i] = board[i].toCharArray();
}
}
}
- 예를 들어, 입력으로 주어진 board 배열이 다음과 같다고 가정하면,
String[] board = ["CCBDE", "AAADE", "AAABF", "CCBBF"]
- 이때, 위에서 제시한 코드를 통해 copy 배열에는 아래와 같이 데이터가 저장된다.
char[][] copy = {
{'C', 'C', 'B', 'D', 'E'},
{'A', 'A', 'A', 'D', 'E'},
{'A', 'A', 'A', 'B', 'F'},
{'C', 'C', 'B', 'B', 'F'}
};
- 결과적으로 copy 배열은 board 배열의 복사본으로, copy 배열을 변경하여 작업하면 원본 board 배열에는 영향을 미치지 않는다.
관련 문제
String.contains
-
contains() 함수는 대상 문자열에 특정 문자열이 포함되어 있는지 확인하는 함수이다.
-
대/소문자를 구분한다.
-
공백을 확인한다.
-
public class ContainsTest{
public static void main(String[] args){
String str = "my java test";
System.out.println( str.contains("java") ); // true
System.out.println( str.contains(" my") ); // false -> 공백이 있기 때문
System.out.println( str.contains("JAVA") ); // false
System.out.println( str.contains("java test") ); // true
}
}