- 도입 배경
- 문제 상황
- 문제 원인 분석
- 해결1. Synchronized
- 해결2. 비관적 락
- 해결3. 낙관적 락
- 해결4. 쿼리 직접 실행(DB atomic operation)
- 개선할 점
- Reference
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
-
예상 독자: 동시성 처리로 인한 데이터 정합성 문제를 해결하는 것에 대해 궁금한 개발자
-
히빗 (ver.1)에서 발생한 데이터 정합성 문제를 히빗2 (ver.2)를 통해 해결한 과정에 대해 정리했습니다.
도입 배경
서버 개발을 하다 보면 여러 요청에서 동시에 공유 자원을 활용하는 경우 동시성 이슈가 발생할 수 있다.
특히 java를 활용한 웹 애플리케이션의 경우 멀티 쓰레드로 동작하기 때문에 데이터 정합성을 위해서는 공유 자원에 대한 관리가 필요하다.
동시성 이슈 해결을 위해서는 다양한 방법이 존재한다. 요청 쓰레드가 순차적으로 처리할 수 있도록 제한하거나 낙관적 락/비관적 락을 활용하거나 쿼리를 통해 해결하는 등 다양한 방법을 통해 막을 수 있다.
이번 글에서는 각각의 해결 방법을 사용해보고 고민해서 가장 적합한 해결 방법을 히빗2에 적용하는 과정을 정리하였다.
문제 상황
기존 히빗 서비스(ver.1) 에서는 ‘게시글 전체보기’ 에서 사용자가 하나의 게시글을 클릭할 때, 조회수 1이 증가되도록 구현했다.
게시글에 대한 엔티티 클래스인 Post는 제목, 내용 등 여러 필드가 있고, 그 중에서 조회수를 나타내는 viewCount를 가지고 있다.
@Entity
public class Post extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "post_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
@Column(name = "title", nullable = false)
@Embedded
private Title title;
@Column(name = "content", nullable = false)
@Embedded
private Content content;
// ...
private int viewCount = 0;
// ...
public void increaseViewCount() {
this.viewCount++;
}
}
여기서 사용자가 해당 게시글을 클릭했을 때, 조회수를 증가시키는 비즈니스 로직은 PostService에 작성했다.
@Service
@Transactional(readOnly = true)
public class PostService {
private final PostRepository postRepository;
// ...
@Transactional
public PostDetailResponse findPost(final Long postId) {
Post post = postRepository.getById(postId);
post.increaseViewCount();
return PostDetailResponse.of(post);
}
}
특정 id를 가진 Post를 조회하고 조회수 1 증가시키는 비즈니스 로직이다. 두 과정은 일련의 트랜잭션에서 이루어져야 하기 때문에 @Transactional을 활용했다.
이제 동시성 이슈를 발생시켜 문제를 확인해본다. 아래는 동시성 이슈 확인을 위해 성능 테스트 도구인 JMeter 를 사용했다.

동시 사용자 1000명이 1초동안 1번 반복한 이후에 Postman을 이용해서 결과를 확인해봤다.
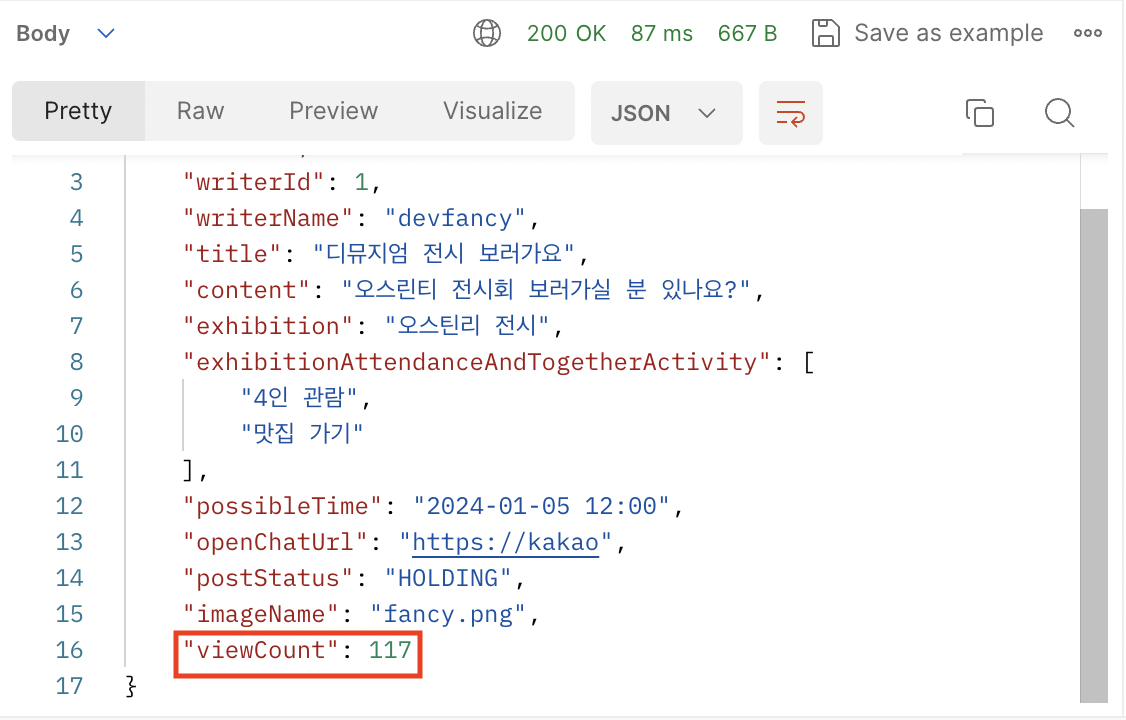
예상 결과가 1000이여야 하는데, 고작 117회의 조회수만 정상적으로 증가된 것을 확인할 수 있다.
정확히 말하자면, 해당 Postman 을 이용해서 한번 더 조회했기 때문에 실제로는 116회의 조회수가 나온 것이다.
{
"id": 10,
"writerId": 1,
"writerName": "devfancy",
"title": "디뮤지엄 전시 보러가요",
"content": "오스린티 전시회 보러가실 분 있나요?",
"exhibition": "오스틴리 전시",
"exhibitionAttendanceAndTogetherActivity": [
"4인 관람",
"맛집 가기"
],
"possibleTime": "2024-01-05 12:00",
"openChatUrl": "https://kakao",
"postStatus": "HOLDING",
"imageName": "fancy.png",
"viewCount": 117
}
문제 원인 분석
문제의 핵심은 viewCount 라는 공유 자원에 여러 요청, 즉 여러 쓰레드가 동시에 접근할 수 있다는 것이다.
순차적으로 접근하여 조회수를 증가시키길 기대하지만, 멀티 쓰레드 환경에서는 의도적으로 동작하지 않을 것이다.
그림으로 표현하면 아래와 같다.
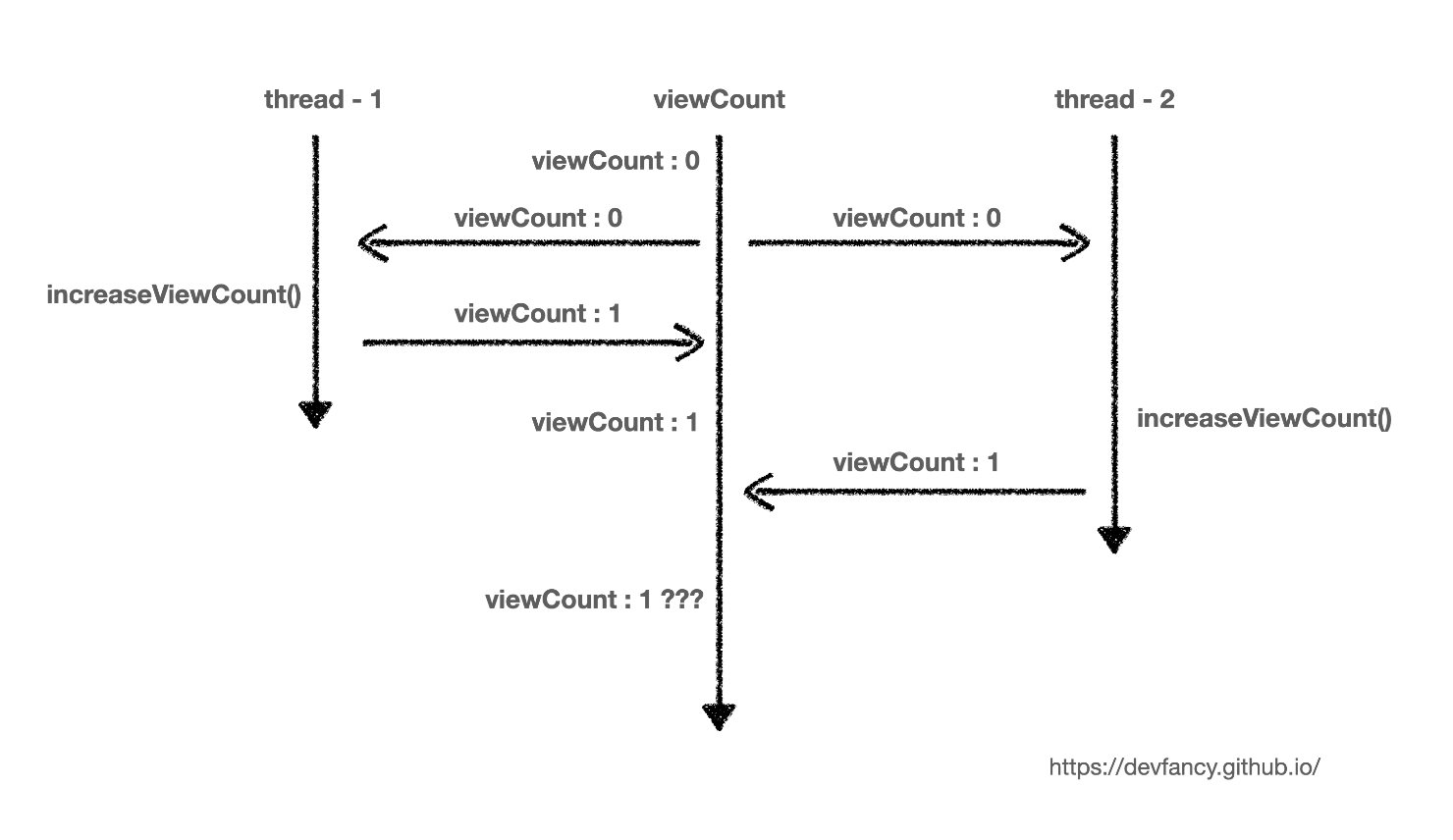
두 개의 요청이 들어와 조회수 2로 증가하길 기대했지만 자원이 동시에 접근하는 시점에 같은 수량을 읽게 되므로 업데이트 하는 시점에 갱신 손실이 발생하게 된다.
갱신 손실은 여러 쓰레드가 동시에 읽고 쓰는 환경에서 업데이트가 충돌하여 손실이 발생하는 것을 의미한다.
해결1. Synchronized
Java의 synchronized 키워드를 통해 임계 영역을 설정하여 해결할 수 있다.
synchronized 를 활용하면 여러 쓰레드에서 공유 자원을 사용할 때 최초에 접근하는 쓰레드를 제외하고 나머지 쓰레드는 접근할 수 없도록 제한한다.
임계 영역이란 멀티 스레드 환경에서 하나의 스레드만 실행할 수 있는 영역을 일컫는다
Java에서는 Monitor 도구를 통해 객체에 Lock을 걸어 상호 배제를 할 수 있다.
핵심은 synchronized 를 사용하면 **오직 하나의 쓰레드에 대해서만 임계 영역에 접근이 가능하다는 것이다.
비즈니스 로직에 적용하면 아래와 같다.
@Service
@Transactional(readOnly = true)
public class PostService {
private final PostRepository postRepository;
// ...
@Transactional
public synchronized PostDetailResponse findPost(final Long postId) {
Post post = postRepository.getById(postId);
post.increaseViewCount();
return PostDetailResponse.of(post);
}
}
메서드 선언부에 synchronized 키워드를 추가하면 된다. 해당 키워드를 통해 이 메서드를 가진 객체를 기준으로 동기화 과정을 진행한다.
PostService의 경우 기본적으로 싱글턴 방식으로 생성되기 때문에 해당 객체의 메서드는 한 번에 하나의 쓰레드만 접근할 수 있다고 이해하면 된다.
이 밖에도 synchronized 를 어디에, 어떤 메서드에 명시하느냐에 따라서 다양하게 동작할 수 있다.
이제 기존과 같이 동시 사용자 1000명이 1초안에 1번 반복한다고 가정해서 성능 테스트를 실행하고 Postman으로 확인하면 다음과 같은 결과가 나온다.
{
"id": 10,
"writerId": 1,
"writerName": "devfancy",
"title": "디뮤지엄 전시 보러가요",
"content": "오스린티 전시회 보러가실 분 있나요?",
"exhibition": "오스틴리 전시",
"exhibitionAttendanceAndTogetherActivity": [
"4인 관람",
"맛집 가기"
],
"possibleTime": "2024-01-05 12:00",
"openChatUrl": "https://kakao",
"postStatus": "HOLDING",
"imageName": "fancy.png",
"viewCount": 117
}
이상하게도 조회수가 1000이 아닌 117이 나온 것이다. 분명히 synchronized 를 통해 임계 영역을 설정했는데 왜 동시성 이슈가 발생할까?
문제 원인 다시 분석 후 해결하기
문제의 원인은 @Transactional의 특수한 구조 때문이다.
Spring은 기본적으로 @Transactional을 사용하면 프록시를 통해 부가기능인 트랜잭션을 구현한다.
간단하게 pseudocode 로 표현하면 아래와 같다.
public class PostServiceProxy {
private final PostService postService;
// ...
public PostDetailResponse findPost(final Long postId) {
Post post = postRepository.getById(postId);
startTransaction // (1) 트랜잭션 시작
postService.findPost(); // (2) 임계영역
endTransaction // (3) 트랜잭션 종료
return PostDetailResponse.of(post);
}
}
여러 쓰레드는 동시에 트랜잭션을 시작할 수 있다. 이후 임계 영역에 진입하면 순차적으로 findPost() 메서드를 수행할 것이다.
하지만 findPost() 는 (3)에 접근했을 때에만 데이터베이스에 반영되기 때문이다. 결국에는 반영 이전에 임계 영역에 접근하는 쓰레드 때문에 갱신 손실이 동일하게 발생하는 것이다.
이를 해결하기 위해서는 트랜잭션의 범위보다 임계 영역의 범위를 더 넓게 가져가는 것이다. PostService 보다 상위 계층에서 임계 영역을 지정한 뒤 findPost() 를 호출한다.
@Component
public class SynchronizedPostService {
private final PostService postService;
public SynchronizedPostService(final PostService postService) {
this.postService = postService;
}
public synchronized void findPost(final Long postId) {
postService.findPost(postId);
}
}
상위 계층을 추가한 이유는 같은 객체 내에서 내부 호출을 진행할 경우 프록시 로직을 정상적으로 타지 않는 문제가 발생할 수 있다.
- 프록시 로직이 정상적으로 타지 않는 이유는 Spring의 트랜잭션 처리 방식과 관련이 있다.
Spring은 기본적으로 `AOP` (Aspect-Oriented Programming)를 활용하여 트랜잭션을 처리한다.
이는 트랜잭션의 시작, 커밋, 롤백 등과 같은 부가 기능을 동적으로 주입하기 위해 프록시를 사용하는 것을 의미한다.
- `@Transactional` 어노테이션이 붙은 메서드는 실제로 호출되기 전에 Spring 프록시에 의해 감싸지게 된다.
그리고 이 프록시는 트랜잭션을 시작하고 종료하는 등의 부가 기능을 처리합니다.
그렇기 때문에 메서드 내부에서 임계 영역을 설정하더라도 프록시에 의해 감싸진 실제 메서드의 시작부와 끝부에서 트랜잭션이 처리되기 때문에, 임계 영역의 동기화는 제대로 이루어지지 않을 수 있다.
- 따라서 트랜잭션 내부 호출 시에는 프록시 로직이 정상적으로 동작하지 않을 가능성이 있다.
이를 해결하기 위해서는 상위 계층에서 임계 영역을 설정하거나, 별도의 서비스 클래스를 만들어서 해당 클래스의 메서드를 트랜잭션 밖에서 호출하는 방식을 고려할 수 있다.
위에서 제시한 `SynchronizedPostService` 클래스 역시 이와 같은 아이디어를 바탕으로 만들어진 것이다.
트랜잭션 AOP가 사용된 전체 흐름에 대해 이해가 필요하다면 Spring의 Transaction 이해 (@Transactional) 글을 참고하자
이제 다시 성능 테스트를 실행시키고 Postman으로 확인하면 조회수(1001)가 정상적으로 나오는 것을 확인할 수 있다.
Postman 으로 한번 더 조회했기 때문에 +1이 증가되어서 1001이 된거라, 실제로는 조회수가 1000으로 나온 것이다.
(이후 아래부터는 Postman 으로 조회해서 증가한 1에 대한 설명은 이 글에서 중요하지 않기 때문에 생략하기로 했다)
{
"id": 10,
"writerId": 1,
"writerName": "devfancy",
"title": "디뮤지엄 전시 보러가요",
"content": "오스린티 전시회 보러가실 분 있나요?",
"exhibition": "오스틴리 전시",
"exhibitionAttendanceAndTogetherActivity": [
"4인 관람",
"맛집 가기"
],
"possibleTime": "2024-01-05 12:00",
"openChatUrl": "https://kakao",
"postStatus": "HOLDING",
"imageName": "fancy.png",
"viewCount": 1001
}
정리. Synchronized
synchronized 을 통해 동시성 이슈를 해결할 수 있지만 다중 애플리케이션에서는 적합하지 않을 수 있다.
이는 하나의 서버 내에서만 동시성 이슈를 막아주기 때문에, 다수의 서버에서는 데이터베이스라는 공유 자원에 접근을 제어하는데 적합하지 않는 방식이다.
만약 스케일 아웃을 진행하지 않고 하나의 서버에서 모든 요청을 처리하는 경우에는 synchronized 는 좋은 대안이 될 수 있다.
다만, @Transactional 과 함께 사용할 때는 프록시 구조에 염두해두고 적절히 사용해야 하며, 임계 영역의 범위를 더 넓게가기 위해 서비스 Layer 클래스를 하나 더 만들어야 하는 점이 있다.
히빗2는 다중화를 고려해서 시스템을 구축하려고 하기 때문에 최소 2개 이상의 서버가 필요하다.
따라서 Synchronized 을 해결책으로 채택하지 않았다.
해결2. 비관적 락
비관적 락은 자원 요청에 따른 동시성 문제가 발생할 것이라 예상하고 Lock을 걸어버리는 방법이다.
다시 말해서, 트랜잭션이 시작될 때 Lock을 걸고 시작하는 방법이다.
그래서 특정 트랜잭션에서 x-lock 을 획득하게 되면 다른 트랜잭션에서는 락이 해제될 때까지 대기하게 된다.
비관적 락 적용
비관적 락은 @Lock 어노테이션을 통해 쉽게 적용이 가능하다.
// PostRepository 클래스
public interface PostRepository extends JpaRepository<Post, Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT p FROM Post p WHERE p.id = :id")
Optional<Post> findByIdForUpdate(@Param("id") final Long id);
// ...
@Modifying
@Query("UPDATE Post p SET p.viewCount = p.viewCount + 1 WHERE p.id = :postId")
void updateViewCount(@Param("postId") Long postId);
}
// PostService 클래스
@Service
@Transactional(readOnly = true)
public class PostService {
private final PostRepository postRepository;
// ...
@Transactional
public PostDetailResponse findPost(final Long postId) {
Post post = postRepository.findByIdForUpdate(postId)
.orElseThrow(NotFoundPostException::new);
post.increaseViewCount();
return PostDetailResponse.of(post);
}
}
PostRepository 클래스에서 @Lock(value = LockModeType.PESSIMISTIC_WRITE)을 적용하고 성능 테스트를 통해 해당 메서드를 수행하면 아래와 같은 쿼리를 확인할 수 있다.
Hibernate:
select
post0_.post_id as post_id1_2_,
post0_.member_id as member_14_2_,
post0_.created_date_time as created_2_2_,
post0_.updated_date_time as updated_3_2_,
post0_.content as content4_2_,
post0_.title as title11_2_,
post0_.view_count as view_co13_2_
// ...
from
post post0_
where
post0_.post_id=? for update
여기서 for update라는 키워드가 추가된 것을 확인할 수 있다. 이는 조회하는 데이터를 수정하기 위해 x-lock을 걸었다는 의미이다.
이렇게 하면 트랜잭션 A가 조회 시점에 락을 가져가기 때문에 다른 트랜잭션 B에서 해당 데이터를 변경할 수 없다.
트랜잭션 종료 시점까지 해당 데이터를 다른 곳에서 변경하지 못하도록 강제로 막아야 할 때 사용한다.
아래 성능 테스트를 수행하여 Postman 으로 확인하면 아래와 같이 정상적으로 통과하는 것을 확인할 수 있다.
{
"id": 10,
"writerId": 1,
"writerName": "devfancy",
"title": "디뮤지엄 전시 보러가요",
"content": "오스린티 전시회 보러가실 분 있나요?",
"exhibition": "오스틴리 전시",
"exhibitionAttendanceAndTogetherActivity": [
"4인 관람",
"맛집 가기"
],
"possibleTime": "2024-01-05 12:00",
"openChatUrl": "https://kakao",
"postStatus": "HOLDING",
"imageName": "fancy.png",
"viewCount": 1000
}
이러한 비관적 락 방식의 가장 큰 장점은 데이터의 충돌이 빈번한 상황에서도 정확한 데이터 정합성을 유지할 수 있다는 점이다. 이로 인해 데이터의 무결성을 보장하는 수준이 높아진다. 그러나 이러한 방식의 단점은 대기 시간이 발생한다는 것이다.
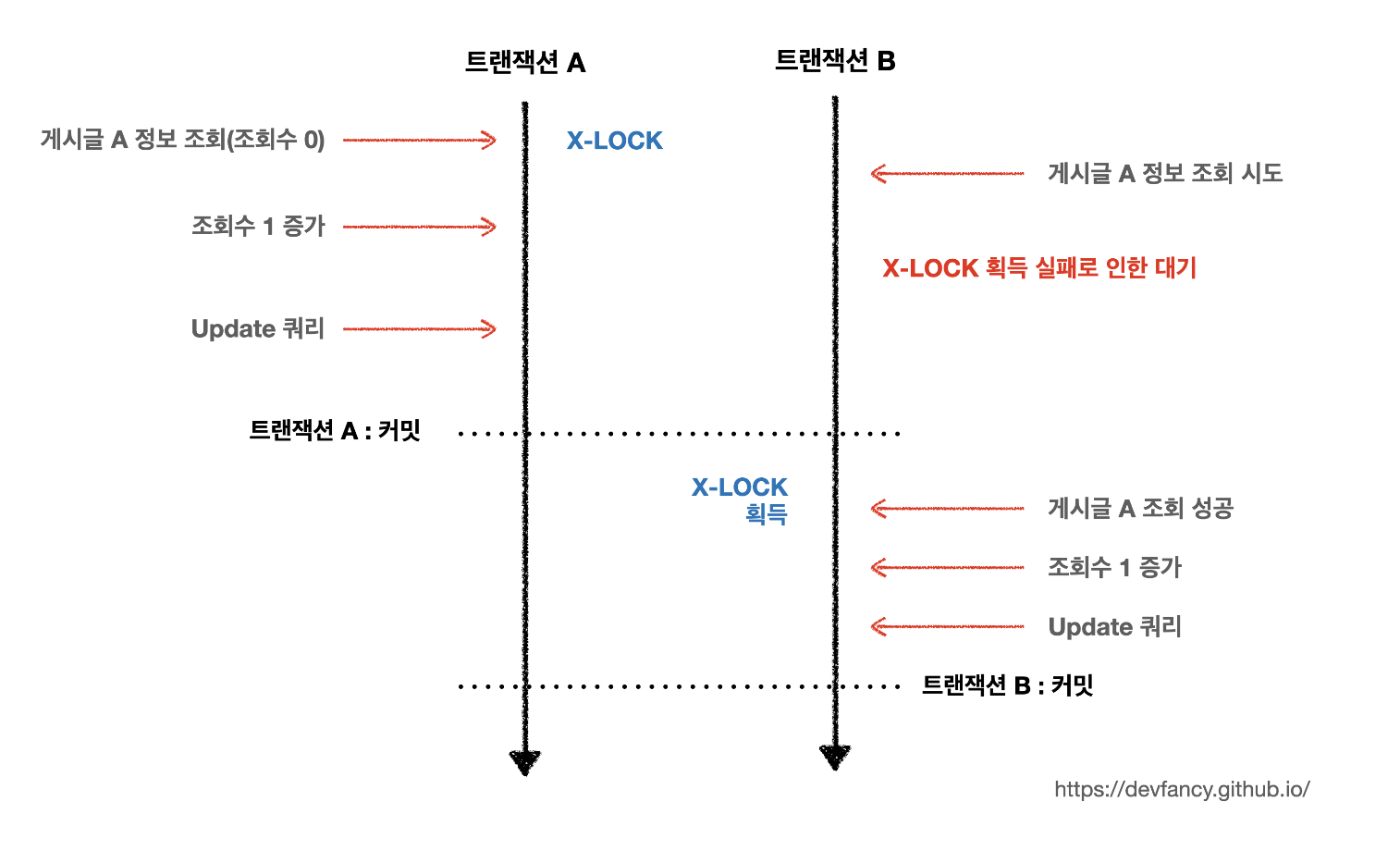
위 그림에서 확인할 수 있듯이, 트랜잭션의 시작이 배타락을 획득하는 조회이므로 각 트랜잭션은 먼저 시작된 트랜잭션이 커밋 또는 롤백될 때까지 로직을 실행하지 못하고 대기 상태에 들어가게 된다. 이는 사실상 하나의 트랜잭션이 전체 락을 점유하는 것과 유사합니다. 정합성은 유지되지만, 동시에 접근하는 트랜잭션이 증가하면 API 요청의 대기 시간이 더욱 증가할 수 있다.
또한, 실제 데이터베이스에 락을 걸어버리기 때문에 다수의 요청에 유연하게 대응할 수 없고, 동시성이 감소하여 성능 손실이 발생할 수 있다. 특히 읽기가 많은 데이터베이스의 경우 손실이 더욱 심할 수 있습니다.
정리하면, 비관적 락은 공유 자원인 데이터베이스에 락을 걸어 하나의 트랜잭션만 처리할 수 있도록 상호 배제를 달성한다. 다중 애플리케이션 서버와 단일 데이터베이스의 경우 이러한 방식은 동시성 이슈에 따른 빠른 해결책이 될 수 있다.
그러나 애플리케이션 레벨이 아닌 데이터베이스에 직접 락을 걸기 때문에 락에 걸린 자원에 접근하는 트랜잭션은 대기상태에 빠지며, 트랜잭션의 증가에 따라 대기 시간은 증가할 것이다. 결과적으로 성능상의 문제가 발생할 수 있기 때문에 비관적 락을 적용하지 않기로 했다.
해결3. 낙관적 락
낙관적 락이란 자원에 lock을 걸어서 선점하지 말고, 동시성 문제가 발생하면 그때 가서 처리하는 방법이다.
추가적인 @Version을 기반으로 충돌할 경우 롤백을 진행한다.
이 특징은 데이터베이스에서 동시성을 처리하는 것이 아닌 애플리케이션 레벨에서 처리하는 Lock이다.
장점은 충돌이 안난다는 가청하에, 동시 요청에 대해서 처리 성능이 좋다.
단점의 경우, 잦은 충돌이 일어날 때 개발자가 직접 처리해줘야 하는 롤백에 대한 비용이 많이 들어 성능에서 손해를 볼 수 있다.
또한 롤백을 처리하기 위해 비즈니스 로직을 희생해야 하는 문제가 있다.
@Version
낙관적 락을 사용하는 방법은 여러가지 있지만 대표적으로 @Version 어노테이션을 사용한다.
@Version 은 낙관적 락 값으로 사용되는 엔티티 클래스의 버전 필드 또는 속성을 지정한다.
이 버전은 병합 작업을 수행할 때 데이터의 무결성을 보장하고 낙관적 동시성 제어를 위해 사용된다.
@Version은 엔티티 클래스의 기본 테이블에 매핑되어야 한다. 기본 테이블이 아닌 다른 테이블에 매핑할 수 없다.
@Version이 사용된 엔티티는 수정될 때 자동으로 버전이 증가하며 수정할 때 조회 시점과 버전이 다른 경우 예외가 발생한다.
이러한 버전은 엔티티 수정 시점에 최신화되며 JPA에 의해 자동적으로 관리된다.
낙관적 락 적용
Post 엔티티에 @Version 이라는 어노테이션을 활용하여 version 관련 컬럼을 추가한다.
@Entity
public class Post extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "post_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
@Column(name = "title", nullable = false)
@Embedded
private Title title;
@Column(name = "content", nullable = false)
@Embedded
private Content content;
private int viewCount = 0;
@Version
private Long version;
// ...
}
그리고 PostRepository 에 락 옵션을 지정해준다.
public interface PostRepository extends JpaRepository<Post, Long> {
@Lock(value = LockModeType.OPTIMISTIC)
@Query("SELECT p FROM Post p WHERE p.id = :id")
Optional<Post> findByIdForUpdate(@Param("id") final Long id);
// ...
}
히빗2 에서는 Spring Data JPA를 사용한다. 따라서 위와 같이 Repository 위에 @Lock 어노테이션을 추가하여 락 옵션을 지정한다.
위 코드에서 사용한 OPTIMISTIC 옵션은 조회한 엔티티가 트랜잭션하는 동안 다른 트랜잭션에 의해 변경되지 않음을 보장한다.
즉, 엔티티를 수정하지 않더라도 버전을 체크한다.
조회수 증가시키는 트랜잭션은 해당 게시글을 조회하여 자기 자신의 조회수가 트랜잭션 내내 변화하지 않음을 보장한다. 따라서 OPTIMISTIC 락 옵션을 사용했다.
서비스 예외 처리
낙관적 락에서 문제가 발생한 경우 JPA는 ObjectOptimisticLockingFailureException 이라는 예외를 던지게 된다.
낙관적 락이 실패하면 예외를 던지기 때문에 요구사항에 따라 재시도를 하는 로직이 필요할 수 있다.
가장 간단한 방법은 충돌이 일어난 시점에 던지는 예외를 캐치하여 다시 로직 처리를 위한 요청을 보내는 것이다.
해당 서비스 계층에서 코드를 아래와 같이 수정했다.
@Component
public class OptimisticLockProductFacade {
private final PostService postService;
public OptimisticLockProductFacade(final PostService postService) {
this.PostService = postService;
}
public void findPost(final Long postId) throws InterruptedException {
while (true) {
try {
postService.findPost(postId);
break;
} catch (final ObjectOptimisticLockingFailureException e) {
Thread.sleep(100);
}
}
}
}
무한 로프를 돌면서 계속 게시글 조회를 진행하면 된다. 낙관적 락 예외가 발생했을 때, 잠깐의 쉬는 시간(0.1초) 이후 다시 요청을 진행한다.
이렇게 해서 성능 테스트를 수행하여 Postman으로 테스트하면 정상적으로 조회수 1000이 나오는 걸 확인할 수 있다.
{
"id": 10,
"writerId": 1,
"writerName": "devfancy",
"title": "디뮤지엄 전시 보러가요",
"content": "오스린티 전시회 보러가실 분 있나요?",
"exhibition": "오스틴리 전시",
"exhibitionAttendanceAndTogetherActivity": [
"4인 관람",
"맛집 가기"
],
"possibleTime": "2024-01-05 12:00",
"openChatUrl": "https://kakao",
"postStatus": "HOLDING",
"imageName": "fancy.png",
"viewCount": 1000
}
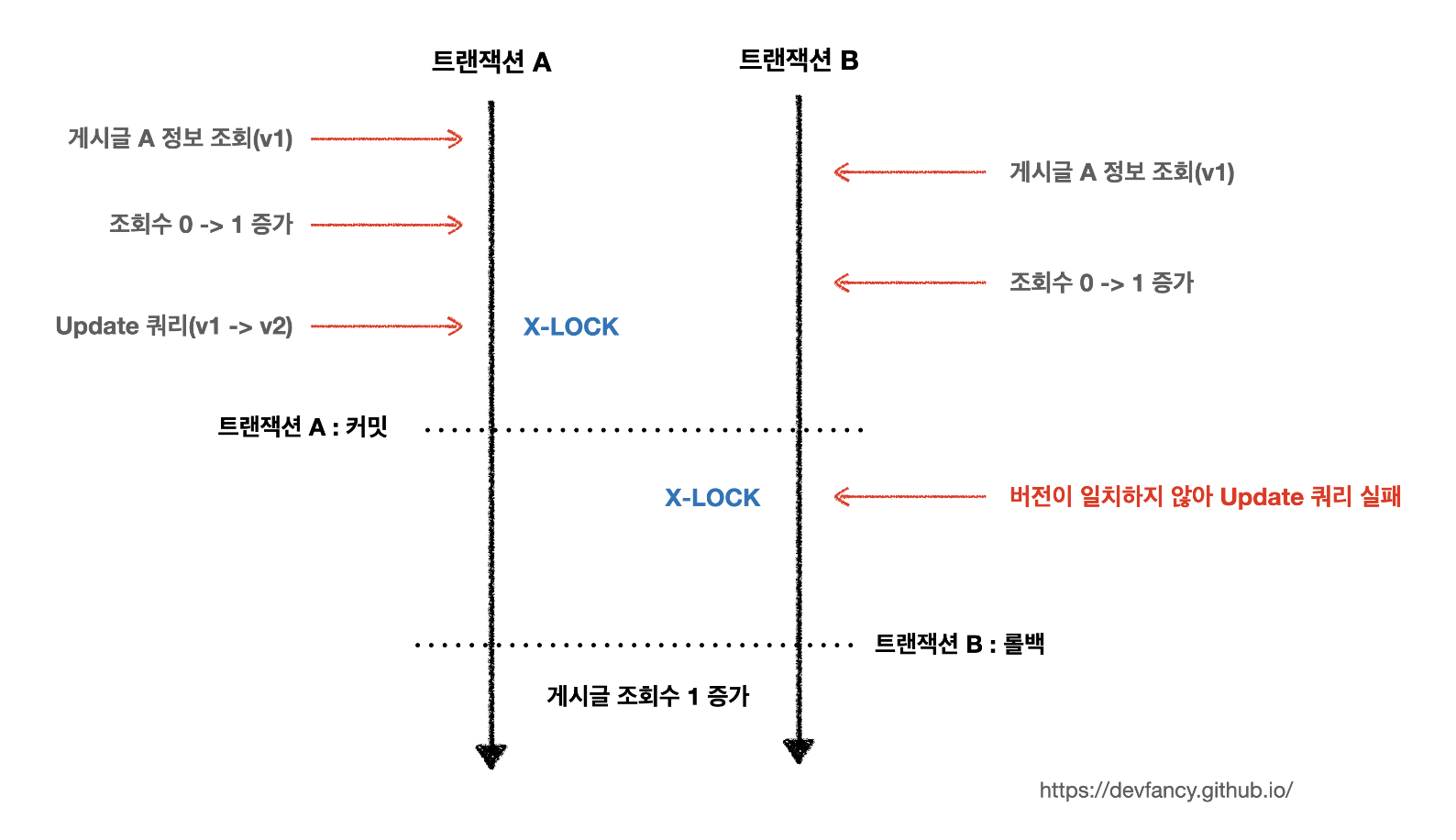
이러한 낙관적 락을 활용하게 되면 버전 정보를 활용하여 버전이 일치하는 경우에만 커밋을 하고, 일치하지 않는 경우에는 롤백 처리를 하게 된다.
이 경우 위 그림처럼 실제로 생성되는 조회수는 트랜잭션A로 인한 1로 데이터 정합성에는 문제가 생기지 않는다.
하지만 트랜잭션 B는 조회수 증가 정합성을 맞추는 로직의 실패 때문에 롤백처리가 필요한 상황이 발생한다.
이러한 상황에서 개발자는 직접 롤백 처리를 해주어야 하며, 충돌이 잦은 경우 롤백 처리에 따른 비용이 증가하여 성능 손실이 발생할 수 있다.
따라서 낙관적 락 방법 또한 역시 사용하지 않기로 결정했다.
해결4. 쿼리 직접 실행(DB atomic operation)
마지막 방법은 더티 체킹을 포기하고 컬럼 자체의 값을 통해 통계를 계산해주는 방법이다. 도메인 값을 변경하지 않고 서비스 계층에서 직접 레포지토리의 메서드를 호출해줘야하기 때문에 도메인에서 최대한 모든 로직을 처리하는 것은 불가능하지만 정합성은 맞출 수 있다. 이는 update 쿼리를 실행할 때 데이터베이스 자체적으로 배타락을 걸어주는 방식이다.
@Service
@Transactional(readOnly = true)
public class PostService {
private final PostRepository postRepository;
@Transactional
public PostDetailResponse findPost(final Long postId) {
Post post = postRepository.findByIdForUpdate(postId)
.orElseThrow(NotFoundPostException::new);
postRepository.updateViewCount(post.getId());
return PostDetailResponse.of(post);
}
}
아래 Repository에도 @Transactional 어노테이션을 적용했다.
두 메서드에 모두 적용하면 두 메서드는 동일한 트랜잭션 내에서 실행된다. 이는 두 메서드의 실행이 원자적으로 처리되며, 트랜잭션이 커밋되기 전까지 변경 사항이 데이터베이스에 반영되지 않는다.
따라서 findPost 메서드와 updateViewCount 메서드에 각각 @Transactional이 적용되면, 두 메서드는 하나의 트랜잭션 내에 실행되며 데이터베이스 작업이 일관되게 처리된다.
이를 통해 두 메서드 간에 일관성을 유지하고, 하나의 트랜잭션 내에서 실행되므로 어느 하나라도 실패할 경우 롤백이 된다.
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("SELECT p FROM Post p WHERE p.id = :id")
Optional<Post> findByIdForUpdate(@Param("id") final Long id);
// ...
@Transactional
@Modifying
@Query("UPDATE Post p SET p.viewCount = p.viewCount + 1 WHERE p.id = :postId")
void updateViewCount(@Param("postId") Long postId);
}
실제 성능 테스트를 수행하여 Postman으로 확인하면 정상적으로 조회수가 나온다.
{
"id": 10,
"writerId": 1,
"writerName": "devfancy",
"title": "디뮤지엄 전시 보러가요",
"content": "오스린티 전시회 보러가실 분 있나요?",
"exhibition": "오스틴리 전시",
"exhibitionAttendanceAndTogetherActivity": [
"4인 관람",
"맛집 가기"
],
"possibleTime": "2024-01-05 12:00",
"openChatUrl": "https://kakao",
"postStatus": "HOLDING",
"imageName": "fancy.png",
"viewCount": 1000
}
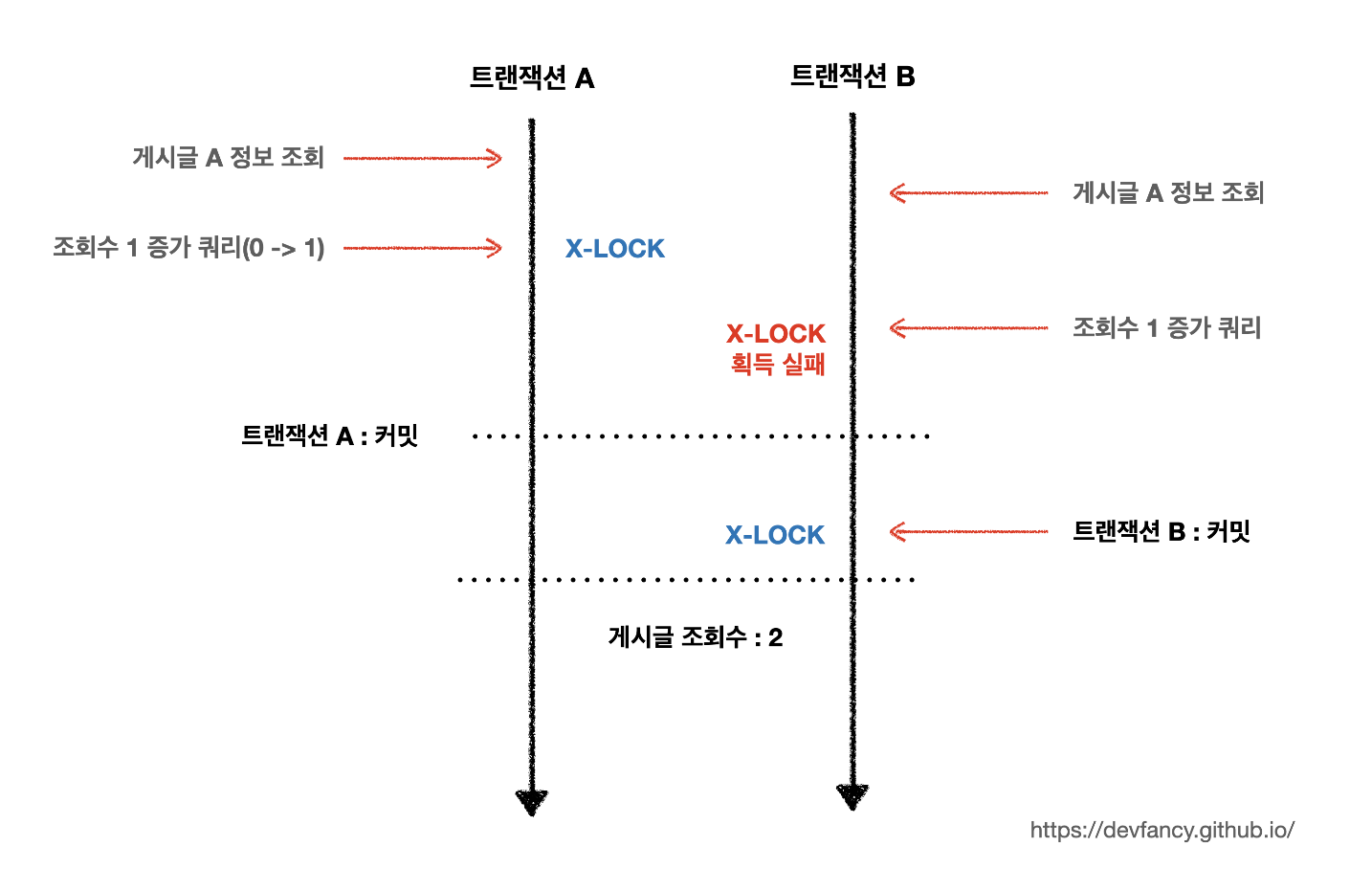
for update 를 통해 조회하지 않고 이렇게 자기 자신의 값을 이용하여 계산한다면, 배타락 덕분에 조회수 개수에 대한 데이터 정합성을 보장할 수 있다.
위 그림에서 보는 것처럼 먼저 실행된 트랜잭션이 update 쿼리를 통해 마치고 커밋 또는 롤백할 때까지 락 획득을 위해 대기하고 있기 때문이다. update만 되어도 동시성이 보장된다고 의구심이 들었는데, 단일 update/delete 구문은 원자적이여서 작업이 진행중인 동안 다른 트랜잭션은 행을 수행하지 않고 대기하게 된다.
이 경우 게시글 A의 레코드에 공유락이나 공유락이나 배타락을 걸어주는 다른 서비스 로직이 있지 않는 한 데드락 문제를 피할 수 있다.
결론
세 가지 방법을 비교해본 결과, JPA의 더티 체킹 기능을 포기하는 경우 덜 객체지향적인 코드가 되고, 도메인 로직이 외부로 이동하게 되고, 복잡한 비즈니스 로직이 첨부된다면 해당 방법은 쓰기가 힘들어질수도 있다고 생각한다.
쿼리를 통한 한 번의 요청으로 처리할 수 있지만 데이터베이스에 강하게 의존하게 된다.
또한, 현재 히빗2의 Controller 테스트 코드에서는 서비스 로직을 완벽하게 테스트하기 어려운 문제가 있다.
그러나 락을 최소화하면서도 정합성을 가장 확실하게 보장할 수 있는 방법이기 때문에 동시성으로 인한 정합성 문제를 이 방법으로 해결하기로 결정했다.
만약 현재 프로젝트에서 복잡한 비즈니스 로직이 추가되어서 서비스 계층에 대한 코드가 비대해진다면, select ... for update 로 값을 읽어오고 비즈니스 로직을 수행하고 update 하는 방식을 사용하자.
현재는 Post 엔티티의 viewCount 컬럼에 대한 간단한 로직을 사용하고 있기 때문에, 위에서 제시한 네 가지 방법 중 4번을 통해 이를 처리하기로 했다.
개선할 점
쿼리를 통해 데이터 정합성 문제는 해결했지만, 여전히 개선이 필요한 부분이 있습니다. 성능 테스트 도구인 JMeter를 활용하여 정합성 문제가 해결되었는지 확인했다.

테스트 결과, HTTP 요청을 통해 동시 접속자 1000명이 1초 동안 접속할 때의 TPS(초당 처리량)는 약 40.7으로 확인된다.
(참고로, TPS(Throughput Per Second)는 초당 시스템의 처리량 (Throughput)을 나타낸다)
서버가 초당 40건의 요청만 처리한다는 것은 매우 제한적인 성능을 의미다. 이에 따라 TPS를 개선하는 방법을 모색하고, 점차적인 성능 향상을 위한 프로젝트 개선을 해보고, 이후에 글을 작성해보자.
최근에는 올바른 성능 테스트란 무엇일까요? 라는 유튜브 영상을 통해 올바른 성능 테스트를 하기 위해 트래픽을 설정하는 유용한 팁을 알게되었다. 현업 개발자의 조언으로 예상 트래픽에서 곱하기 3을 기준으로 삼아야 한다는 지침을 얻었다.