이 글은 제가 혼자서 개발한 히빗 (version 2) 에 대한 회고 글입니다. 이전 version 1과 비교하여 어떤 성장을 이루었고, 그 과정에서 어떤 깨달음을 얻었는지 작성했습니다.
시작하며
히빗 프로젝트 version1에 참가하게된 계기와 회고는 이전에 작성했던 ‘[2023년 회고] 다양한 활동으로 가득한 특별한 한 해’ 글에 있기 때문에, 생략했다.
이번 글은 히빗 프로젝트를 version2로 다시 진행하면서 개선했던 들을 하나씩 알아보고, 느낀점(아쉬운 점)을 작성해보고자 한다.
과거의 ‘나’와 현재의 ‘나’
과거 version1 에 참가했을 때의 내 실력은 아래와 같았다.
2023, 과거의 ‘나’
-
자바 - 기초적인 개념은 어느 정도 알고 있으나 일부 개념에 대해서는 제대로 대답하지 못하는 수준. 람다 & 스트림을 알지만, 프로젝트에 적용할 수 없었음
-
스프링 - 김영한님 강의에서 Spring 핵심 원리, Spring MVC 1편, JPA 활용1,2 까지 들었고 복습한 수준
-
좋은 코드가 무엇이고, 좋은 코드를 만들기 위해 어떻게 작성해야 할지 판별을 못하는 수준
-
스프링 & JPA 기반 프로젝트에서의 테스트코드를 어떻게 작성해야 해야 하는지 모름
-
일단 기능 동작만 구현할 수 있을 정도의 실력
히빗 프로젝트(version 1)를 진행하면서, 그리고 끝난 이후에도 과거의 ‘나’의 실력을 성장시키기 위해 아래와 같은 공부를 했다.
2024, 현재의 ‘나’
-
자바 - ‘자바의 정석’ 책을 통해 빠르게 복습하면서 기본기 튼튼히 잡음. 람다 & 스트림 개념을 공부하면서 프로젝트에 적용할 수 있음
-
스프링 - 김영한님 강의에서 JPA 기본, Spring MVC 2편, Spring DB 1편를 수강했고, 기본기는 꾸준히 복습했음 -> JPA 정리, Spring 정리
-
좋은 코드가 무엇인지 알기 위해 우아한 스터디 겨울시즌, “내 코드가 그렇게 이상한가요?” 주제에 참가해서 2달간 공부 및 정리했음
-
테스트코드가 무엇이고, 스프링 & JPA 기반 프로젝트에서의 테스트코드를 작성하는 방법을 “Practical Testing” 강의를 통해 학습하고 정리했음
간단히 말해, 이전에는 프로젝트에서 개발할 줄 알았지만 깊이있게 학습하지 않았다. 그래서 그러한 약점을 보완하기 위해 꾸준히 공부하면서 부족한 부분을 채워나갔다.
version2의 목표
기존의 프로젝트를 version2를 하게된 이유는 내가 제대로 성장했는지 확인하고 싶었고, 기존 version1에 있는 백엔드 코드와 구조를 개선하는 것이였다.
그래서 version1에서 개선하고 싶은 점들을 리스트로 정리한 결과 아래와 같았다.
-
무분별한 setter 지양하고 하나의 메서드당 하나의 역할만 하도록 리팩터링하기
-
테스트코드를 도입하여 QA 작업을 자동화하고 Jacoco를 도입하여 코드 커버리지 80% 유지하기
-
데이터베이스 레플리케이션을 통한 쿼리 성능 개선하기
-
동시성으로 인한 데이터베이스 정합성이 맞지 않는 문제 해결하기
-
검색 기능의 개선과 보안 강화하기
-
게시글 조회에 대한 어뷰징을 막기 위해 조회수를 Cookie에 저장하여 관리하기
-
기존 API 명세서인 Swagger에서 Rest Docs로 전환하기
개선한 점
1. setter 지양, 단일 책임 원칙 준수
version1 -> version2로 개발을 진행하면서 개선한 사항 중 하나는 setter를 사용하지 않고, 단일 책임 원칙을 더욱 철저히 준수하는 것이였다.
초기 버전(ver.1) - PostService
@RequiredArgsConstructor
@Service
public class PostService {
// ...
@Transactional
public Post save(PostSaveDto postSaveDto, Long idx) {
Member member = memberRepository.getById(idx);
postSaveDto.setMember(member);
Post post = postSaveDto.toEntity();
postRepository.save(post);
postHistory postHistory = new postHistory();
postHistory.setPost(post);
postHistory.setOkUsers(new ArrayList<>());
postHistory.setRealUsers(new ArrayList<>());
postHistoryRepository.save(postHistory);
return post;
}
}
개선된 버전(ver.2) - PostService
@Service
@Transactional(readOnly = true)
public class PostService {
// ...
@Transactional
public Long save(final Long memberId, final PostCreateRequest request) {
validateMember(memberId);
Member foundMember = memberRepository.getById(memberId);
Post post = createPost(request, foundMember);
Post savedPost = postRepository.save(post);
return savedPost.getId();
}
}
기존 version1과 version2는 요구 사항이 다를 수 있어 코드상의 차이가 있을 수 있다.
그러나 version1에서는 엔티티 클래스와 비즈니스 로직에서 무분별하게 setter를 사용하고 있다.
왜 setter를 지양해야 할까? 누군가 이렇게 물어본다면, 나는 다음과 같이 2가지 이유를 들 수 있을 것 같다.
- 사용한 의도를 쉽게 파악하기 어렵다.
- set 메서드를 통한 값 변경은 여러 곳에서 사용될 수 있으며, 비즈니스 로직이 복잡해질수록 정확한 의도를 파악하기 어렵다.
- 객체의 상태가 복잡하면 한눈에 이해하기도 어렵다.
- 일관성을 유지하기 어렵다.
- public으로 작성된 setter 메서드는 어디서든 접근 가능하여, 의도치 않게 객체의 상태를 변경할 수 있다.
- 이는 객체의 일관성을 해칠 수 있다.
JPA에서는 setter를 통해 트랜잭션 안에서 엔티티의 변경 사항을 감지하여 update 쿼리를 수행한다.
즉, setter 메서드는 update 기능을 수행한다.
setter 없이 데이터를 수정하는 방법은 사용한 의도와 의미가 명확한 메서드명을 사용하는 것이 좋다.
예를 들어, 게시글 정보를 변경할 경우 updatePost 라는 메서드를 생성하여 사용하면 setter 메서드 보다 행위의 의도를 더 명확히 할 수 있다.
따라서 setter를 public으로 열어두고 사용하는 것보다는, 변경이라는 의미가 담긴 메서드를 통해 update 처리하는 것이 객체지향적인 접근 방식이라고 본다.
그리고 version2에서는 단일 책임 원칙을 잘 지키기 위해, 하나의 메서드가 한 가지 일만 하도록 구현했다.
이를 통해 각 메서드의 목적이 명확해지고 코드의 유지보수가 용이해졌다.
2. 테스트코드 도입 및 코드 커버리지 80% 유지
자세한 내용은 해당 포스팅에 정리했습니다.
우선 테스트코드에 대한 개념부터 실전까지의 경험을 쌓기위해 “Practical Testing: 실용적인 테스트 가이드” 강의를 들으면서 블로그에 정리해갔다.
해당 강의를 들으면서 동시에 히빗 ver2 프로젝트에도 적용하였고, BDD 기반으로 코드를 작성했다.
(단위 테스트 코드에 대한 자세한 내용은 이전에 작성한 좋은 단위 테스트란? 글에 작성했다)
단위 테스트코드를 작성하면서 동시에 통합 테스트코드를 작성했는데, @MockBean 이라는 어노테이션을 사용했다.
주로 Presentation Layer에서 Business Layer 하위로 Mocking 처리할 때 사용했다.
그리고 토스 유튜브 채널에서 토스뱅크 이응준님이 발표하신 SLASH21 - 테스트 커버리지 100% 영상을 보면서 테스트 커버리지의 여러 이점들을 알게되었고, 하신 말씀 중에 가장 기억에 남는 문구가 아래와 같았다.

테스트가 없으면 리팩터링을 할 수 없고, 리팩터링을 하지 않는 코드는 이해할 수 없게 되며, 이러한 코드는 수정할 수 없다는 확신이 없다. - 토스뱅크 이응준 -
이로 인해 테스트의 중요성을 새롭게 깨달았고, 프로덕션 코드의 품질과 신뢰를 높이기 위해 히빗 ver2 프로젝트에는 코드 커버리지를 80%를 유지하는 목표를 세우고 실천에 옮겼다.
그 결과, 아래와 같이 80% 유지를 할 수 있었다.
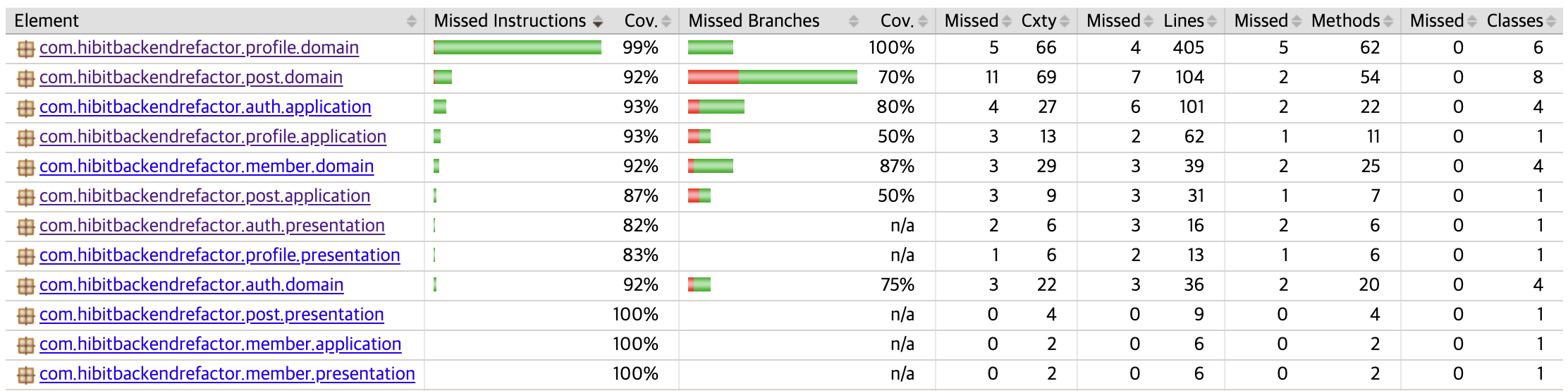
3. 데이터베이스 레플리케이션을 통한 쿼리 성능 개선
해당 내용과 관련된 PR 입니다.
기존 히빗 ver1 프로젝트는 데이터베이스가 1개였다. 그래서 등록, 조회, 수정, 삭제가 모두 하나의 데이터베이스에서 관리되기 때문에 성능적인 면에서 부족한 부분이 있다.
특히 히빗 서비스에서는 주로 등록, 수정, 삭제보다 ‘조회’하는 경우가 많았기 때문에, 조회에 대한 성능을 높이고자 레플리케이션을 도입하기로 했다.
아래와 같이 현재 RDS에 있는 데이터베이스(Source)를 기준으로 하위에 Replica 2개를 추가로 두었다.
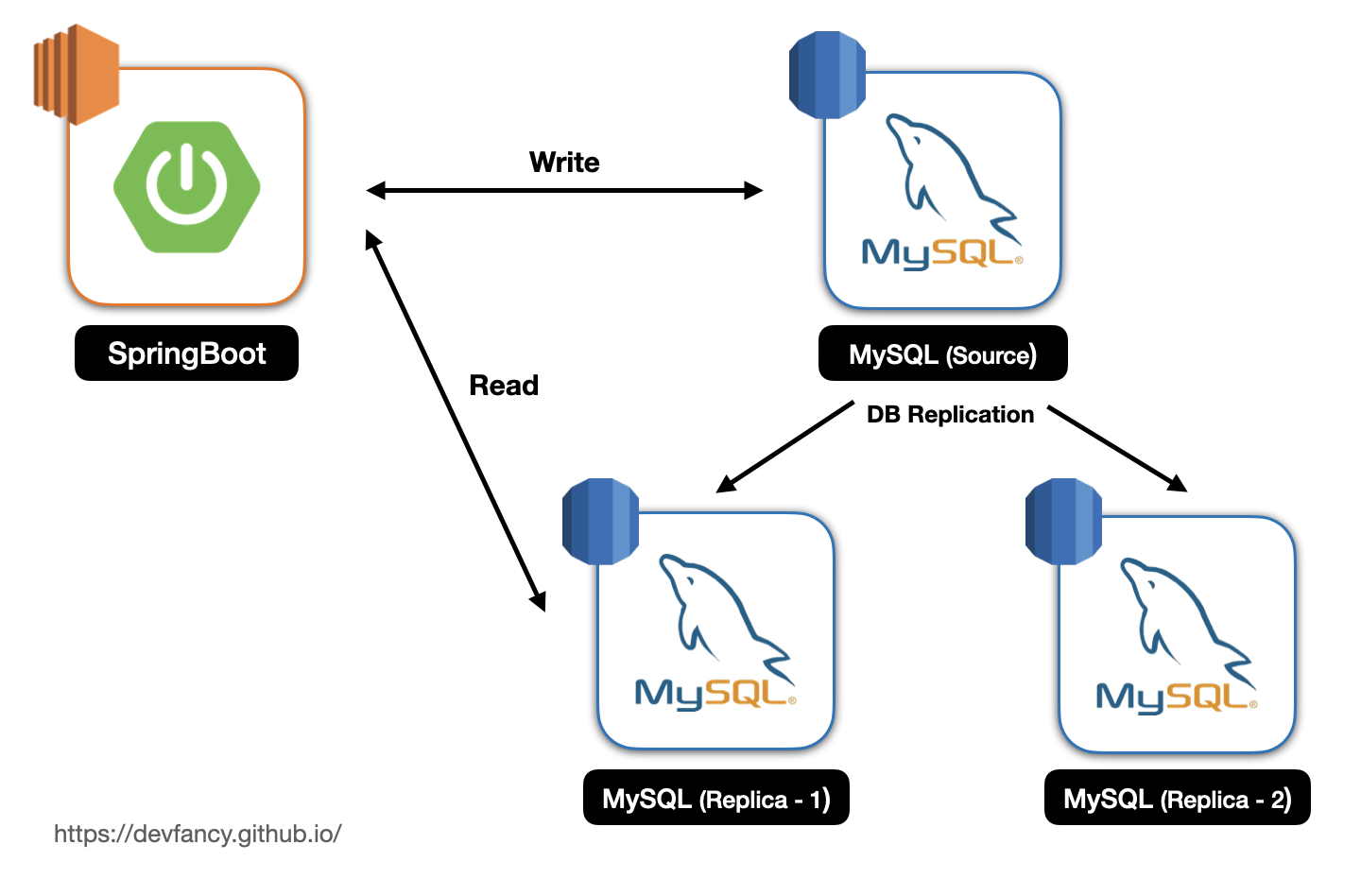
그리고 스프링 부트에도 쓰기와 읽기를 분리하기 위해 아래와 같이 DataSource를 구분지었다.
@Configuration
@Profile("prod")
public class DataSourceConfiguration {
@Bean
@Primary
public DataSource dataSource() {
DataSource determinedDataSource = routingDataSource(sourceDataSource(), replica1DataSource(), replica2DataSource());
return new LazyConnectionDataSourceProxy(determinedDataSource);
}
@Bean
@Qualifier(SOURCE_NAME)
@ConfigurationProperties(prefix = "spring.datasource.source")
public DataSource sourceDataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
@Qualifier(REPLICA_1_NAME)
@ConfigurationProperties(prefix = "spring.datasource.replica1")
public DataSource replica1DataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
@Qualifier(REPLICA_2_NAME)
@ConfigurationProperties(prefix = "spring.datasource.replica2")
public DataSource replica2DataSource() {
return DataSourceBuilder.create()
.build();
}
}
이후에 성능 테스트로 게시글 조회에 대한 테스트를 진행해본 결과, 2,000명을 기준으로 40TPS 에서 177.8 TPS로 4.4배 증가하였다.
레플리케이션 도입 전

레플리케이션 도입 전

4. 데이터베이스 정합성이 맞지 않는 문제 해결
자세한 내용은 해당 포스팅에 정리했습니다.
기존 히빗 ver1 에서 특정 게시글에 대한 조회수 증가에 대해 성능 테스트로 해본 결과, 정합성이 맞지 않는 문제가 생겼다.
서로 다른 사용자 1000명이 해당 게시글을 조회하면, 당연히 1000회가 증가해야 했는데, 아래와 같이 117회의 조회수만 정상적으로 증가된 것을 확인할 수 있다.
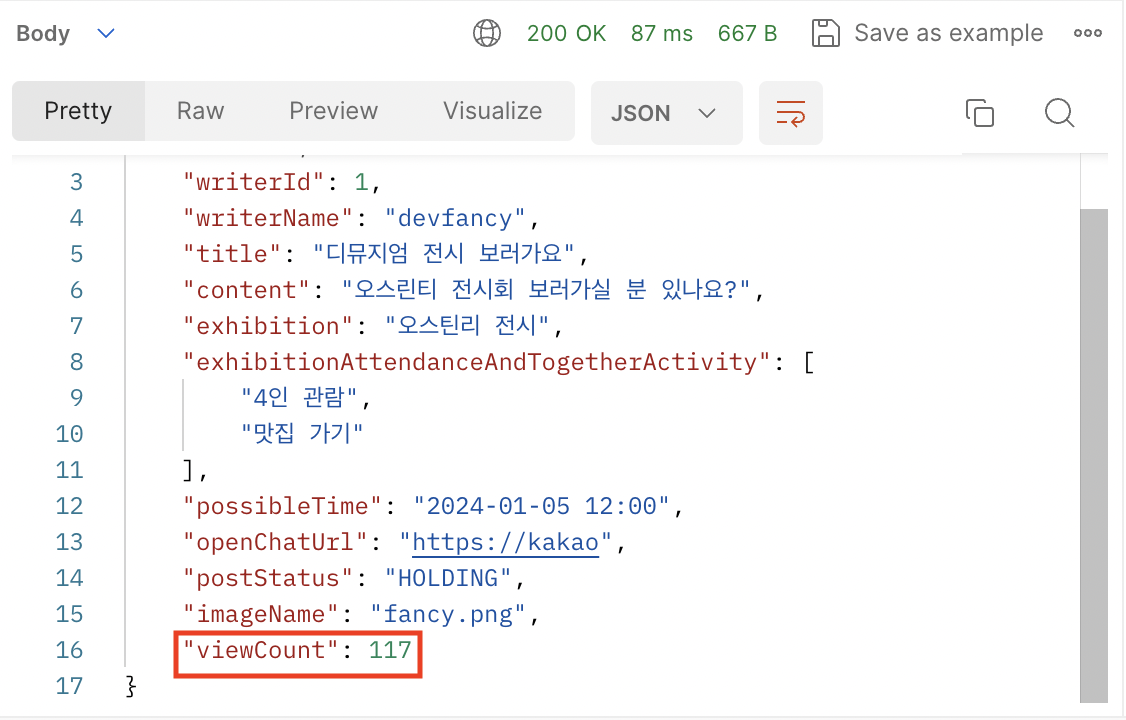
이러한 부분을 해결하기 위해 여러가지 방법 중 쿼리(DB atomic operation)을 적용했다.
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("SELECT p FROM Post p WHERE p.id = :id")
Optional<Post> findByIdForUpdate(@Param("id") final Long id);
// ...
@Transactional
@Modifying
@Query("UPDATE Post p SET p.viewCount = p.viewCount + 1 WHERE p.id = :postId")
void updateViewCount(@Param("postId") Long postId);
}
for update 를 통해 조회하지 않고 이렇게 자기 자신의 값을 이용하여 계산한다면, 배타락 덕분에 조회수 개수에 대한 데이터 정합성을 보장할 수 있다.
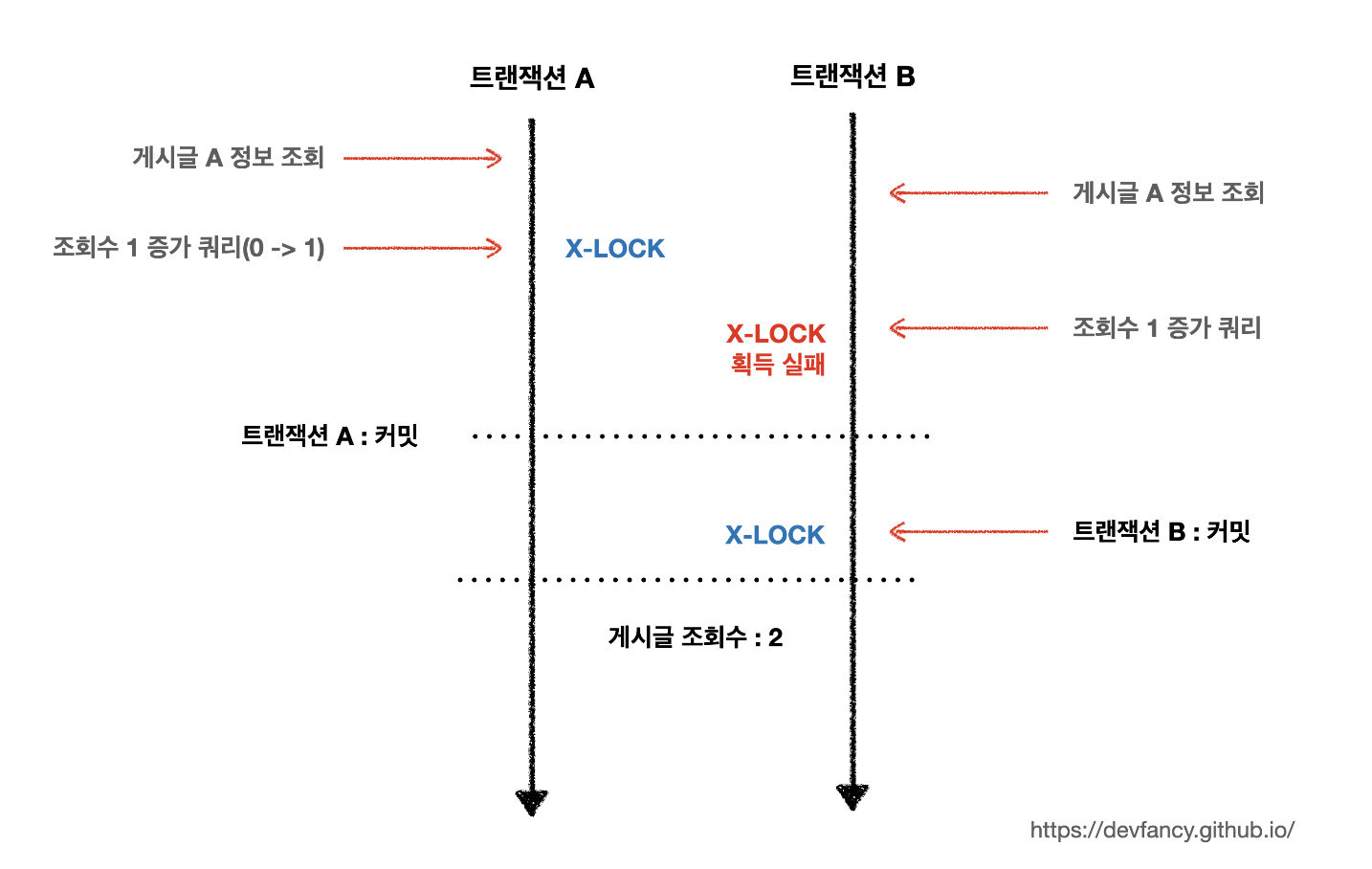
위 그림에서 보는 것처럼 먼저 실행된 트랙잭션이 update 쿼리를 통해 마치고 커밋 또는 롤백할 때까지 락 획득을 위해 대기하고 있는 방식이다.
5. 검색 기능의 개선과 보안 강화
해당 내용과 관련된 PR 입니다.
기존 히빗 ver1 에서는 사용자 입력을 그대로 쿼리에 사용할 경우 SQL 인젝션 공격의 위험이 있었고, 특정 키워드가 없는 경우에 대한 처리가 전혀 없었다.
따라서 안전하게 사용자 입력을 처리하여 SQL 인젝션 공격을 방지하고, 빈 입력값에 대해서도 적절히 처리할 수 있는 검색 기능을 구현하는 것을 목표로 두었다.
그리고 특정 키워드로 게시물을 검색하는 기능은 있지만, Page를 사용해서 구현했다.
하지만 총 페이지 수에 대한 값이 필요하지 않다면 Page 대신 Slice를 적용하는게 성능 개선에 있어서 더 나은 방법을 알게되었다.
해결1. SQL 인젝션 공격과 빈 입력값에 대한 처리를 위해 SearchQuery 클래스 생성
- 사용자 입력에 대한 SQL 인젝션 방지를 위해,
SearchQuery클래스를 통해 특수 문자 및 SQL 예약어 제거 로직을 구현하였고, 이를 통해 안전한 검색 쿼리 생성이 가능해졌다.
public class SearchQuery {
private static final Pattern SPECIAL_CHARS = Pattern.compile("\\[‘”-#@;=*/+]");
private static final Set<String> STRING_SET = Set.of("update", "select", "delete", "insert");
private final String value;
public SearchQuery(final String value) {
this.value = toSafeQuery(value);
}
private String toSafeQuery(String query) {
if (query != null) {
query = changeNoSqlInjection(query.toLowerCase(Locale.ROOT));
}
if (query == null) {
query = "";
}
return query;
}
private String changeNoSqlInjection(String query) {
query = SPECIAL_CHARS.matcher(query).replaceAll("");
for (String s : STRING_SET) {
if (query.contains(s)) {
return "";
}
}
return query;
}
public String getValue() {
return value;
}
}
-
PostRepository 내에 구현된 메서드들은 사용자의 다양한 입력(빈 값 포함)을 처리하여 게시물을 검색할 수 있도록
@Query어노테이션과nativeQuery를 활용했다. -
결과적으로,
SearchQuery클래스의 구현으로 SQL 인젝션 공격의 위험을 차단하며, 빈 입력값 처리 기능을 통해 사용자에게 유용한 검색 결과 제공이 가능해졌다.
해결2. 또한 사용자 10,000명을 기준으로 특정 게시물을 검색할 때 Page 대신 Slice를 적용하여 평균 TPS는 267 -> 309로, 최고 TPS는 320 -> 360 으로 증가하여 조회에 대한 성능을 조금 개선했다.
public interface PostRepository extends JpaRepository<Post, Long> {
String SEARCH_SQL = "select * from posts where "
+ "(:query is null or :query = '') "
+ "or "
+ "(title regexp :query) "
+ "or "
+ "(content regexp :query) ";
@Query(value = "SELECT * " +
"FROM posts p " +
"ORDER BY p.created_date_time DESC", nativeQuery = true)
List<Post> findAllByOrderByCreatedDateTimeDesc();
@Query(value = SEARCH_SQL, nativeQuery = true)
Page<Post> findPostPagesByQuery(Pageable pageable, @Param("query") String query);
@Query(value = SEARCH_SQL, nativeQuery = true)
Slice<Post> findPostSlicePageByQuery(Pageable pageable, @Param("query") String query);
}
6. 어뷰징을 막기 위해 Cookie에 저장하여 관리
자세한 내용은 해당 포스팅에 정리했습니다.
기존(히빗 ver1)에 개발했던 조회수에 대한 구현 방식에는 중복에 대한 처리를 고려하지 않아서 다음과 같은 문제가 발생했다.
-
비회원도 조회할 때마다 조회수가 증가하고, 하루에 여러 번 조회가 가능함
-
한 사용자가 여러 장소(다른 IP)에서 접속해도 조회수가 접속한 수 만큼 증가함
-
조회수가 증가할 때마다 데이터베이스에 업데이트하는데, 이는 많은 사용자들이 특정 게시글을 자주 조회할 경우 데이터베이스에 큰 부하를 유발할 수 있음
이러한 문제를 인식하고, 조회수에 대한 어뷰징을 방지하기 위해 새로운 접근 방식을 모색하게 되었다.
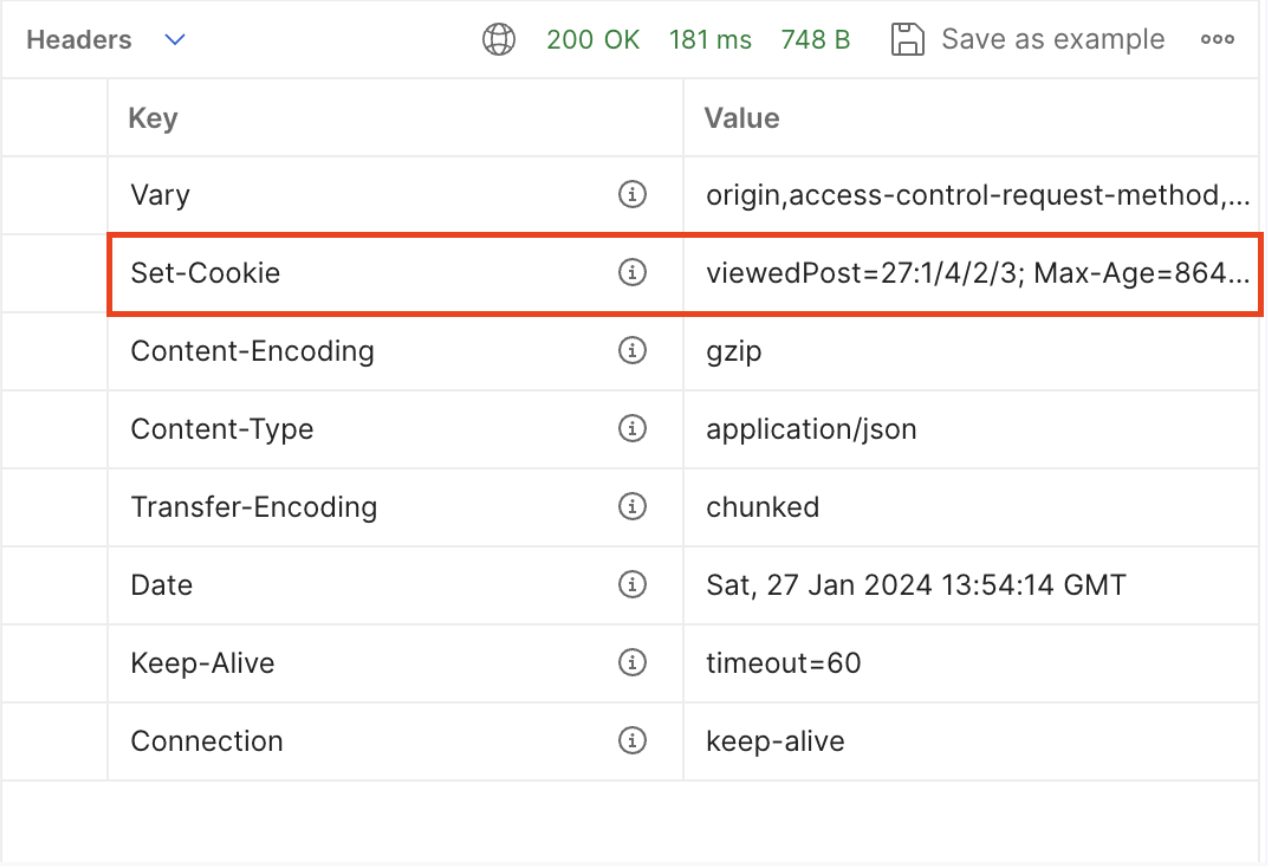
조회수 증가에 대한 기준을 설정한 뒤 어뷰징을 막기 위해 쿠키를 이용하기로 했다.
악의적인 사용자가 쿠키를 삭제하여 어뷰징을 할 수 있지만, 현재 서비스에서는 조회수가 수익 창출이나 주요 비즈니스에 큰 영향을 미치지 않기 때문에 이 방식을 선택했다.
쿠키에는 한 도메인당 최대 20개의 항목만 저장할 수 있는 제한이 있기 때문에, 하나의 쿠키에 여러 게시글 ID를 문자열로 저장하고 분할하는 방식으로 조회수 관리 로직(ViewCountManager)를 구현했다.
7. Swagger에서 Rest Docs로 전환
자세한 내용은 해당 포스팅에 정리했습니다.
기존 version1 에 개발했던 Hibit은 Swagger로 API 문서를 만들었다.
그러나 Swagger를 적용하면서 백엔드 코드에 Swagger와 관련된 어노테이션이 추가되는데, 이로 인해 코드 내부에 기능과 문서가 혼합되어 깔끔하지 않은 코드가 되었다.
이러한 이유로 version2 에서는 Swagger 보다는 깔끔하고 명료한 문서를 생성할 수 있는, 주로 문서 제공 용도로 사용되는 Spring Rest Docs로의 전환을 결정하게 되었다.
기존 Swagger와 관련된 어노테이션 제거, 의존성 제거하였고, build.gradle에 Spring Rest Docs 관련 의존성을 추가하는 것부터 시작해서 적용하기까지 구현했다. (코드에 대한 부분은 Github에서 확인해 볼 수 있습니다)
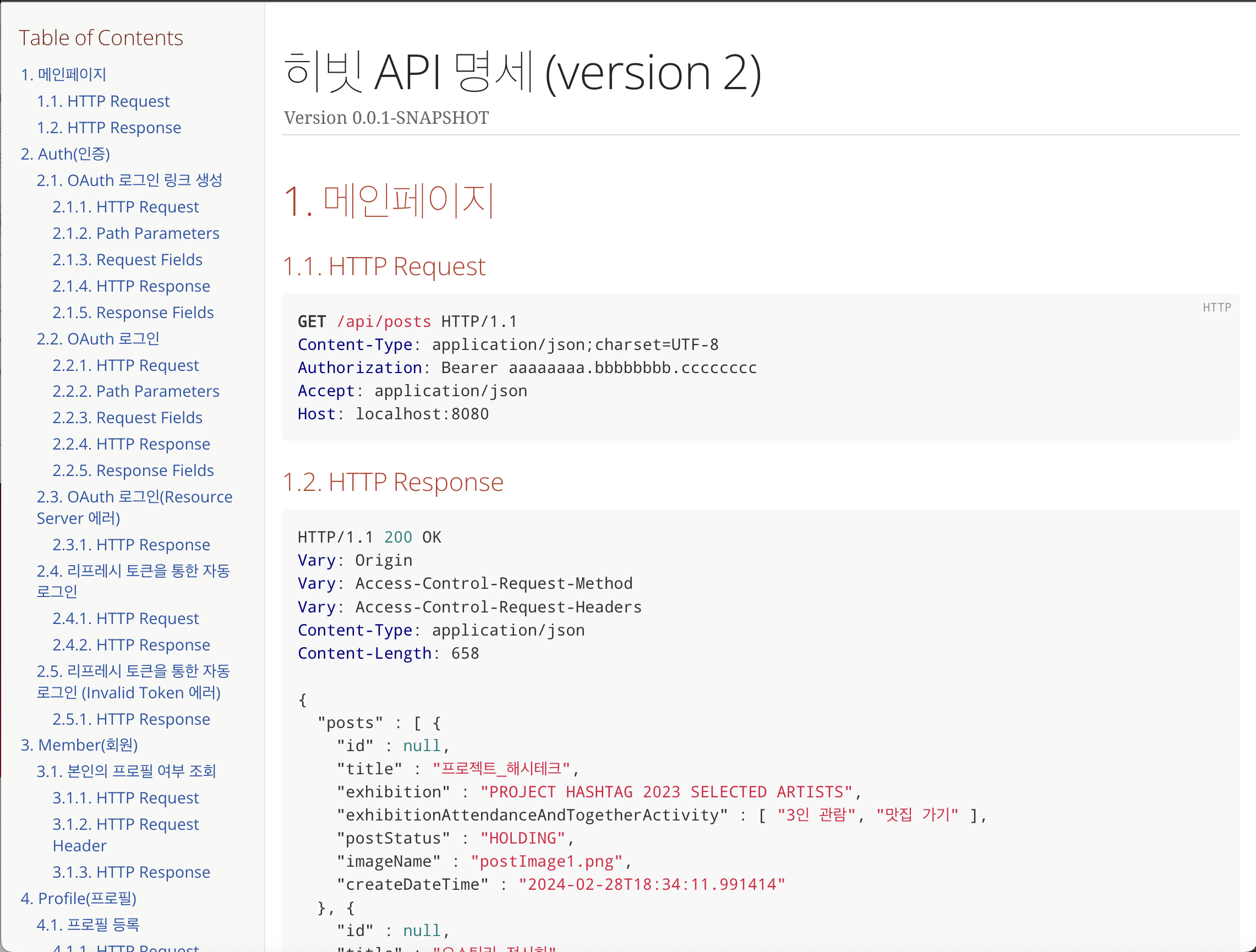
그래서 현재까지 구현된 API에 대해 아래와 같이 Spring Rest Docs로 문서화했다.
느낀점(아쉬운 점)
-
혼자서 히빗 version2 프로젝트를 진행하면서 그동안 내가 배웠던 지식을 실제로 활용해보는 중요한 경험을 했다.
이는 단순히 이론(인풋)을 알고 있던 것에서 한발 더 나아가 실제로 적용해보는 과정(아웃풋)까지 이르렀다는 점에서 큰 의미였다.
-
이번 프로젝트를 통해 데이터 정합성 문제와 성능 개선이라는 새로운 과제에 직면했다.
이를 해결하기 위해 여러 기술을 비교 분석하고, 프로젝트에 가장 적합한 기술을 선택하는 과정에서 많은 고민과 시도가 있었다.
혼자서 개발하는 과정에서 과연 내가 선택한 방법이 최선인지, 혹은 다른 더 나은 방법이 있는지에 대한 끊임없는 질문 속에서도, 스스로 해결책을 찾아가는 과정이 매우 보람찼다.
-
하지만, 혼자서 개발하다보니, 새로운 기술을 배우고 적용하는 데 많은 시간이 소요되었고, 내가 선택한 기술이나 코드가 최선인지 확신하기 어려웠다는 점이다.
“내 코드가 그렇게 이상한가요?” 라는 책에서 배운 내용을 바탕으로 구현했지만, 구현한 코드가 정말로
좋은 코드인지에 대해 의구심이 들었다.이러한 의문을 해소하기 위해 “클린코드” 와 같은 책을 통해 더 나은 코드 작성법을 학습하고, 실제로 적용해보려고 한다.
-
또한, 프로젝트를 진행하면서
시스템 설계에 대한 관심도 커졌다.현재는
Jmeter를 이용해서 사용자 1,000명 ~ 10,000명으로 성능 테스트를 시도했지만, 만약 사용자가 10만명 ~ 100만명과 같이 규모가 대폭 증가했을 때 시스템을 어떻게 보완해야 할지에 대한 고민이 생겼다.그러한 부족한 점을 채우고자 최근에 구매한 “대규모 시스템 설계 기초” 책을 읽으면서 하나씩 채워나가려고 한다.
-
트래픽과 관련해서 2019년에 우아한테크영상에서 올라온 [우아한테크토크] 선착순 이벤트 서버 생존기! 47만 RPM에서 살아남다?! 영상과
2023년에 올라온 대규모 트랜잭션을 처리하는 배민 주문시스템 규모에 따른 진화 영상을 참고하면서 다양한 인사이트를 얻게되었다.
지금까지
MySQL만 사용했었는데, 두 개의 영상을 통해Redis를 왜 써야 하는지 조금은 알게되었다.Redis에 대한 개념과 활용도 꼭 공부해서 적용해보자!
마치며
히빗 version2 프로젝트를 진행하며 발견한 개선점들은 아직도 많이 남았다. 그럼에도 불구하고, 모든 것을 동시에 해결하기보다는 차근차근, 하나씩 개선해 나가는 전략을 택하기로 했다.
이 프로젝트를 독립적으로 개발하면서 얻은 경험은 저에게 성장의 기회를 제공했으며, 앞으로도 지속적인 학습과 실천을 통해 더욱 발전된 모습을 보여드리고자 한다.
이러한 점진적인 발전 과정을 통해, 한 단계씩 밟아 나간다면 앞으로도 현재의 ‘저’ 보다 더 발전된 모습이지 않을까 생각한다.
지금까지 해당 글을 읽어주셔서 감사합니다. 😌