이 글은 내 코드가 그렇게 이상한가요? 책을 읽고 정리한 내용을 바탕으로 작성하였습니다.
1장. 잘못된 구조의 문제 깨닫기
의미를 알 수 없는 이름
-
프로그래밍이나 컴퓨터 용어를 기반으로 이름 붙이는 것을
기술 중심 명명이라 부른다. -
그리고 클래스와 메서드에 번호를 붙여서 이름을 짓는 것을
일련번호 명명이라 부른다. -
이렇게 이름을 지으면 코드를 읽고 이해하는데 시간이 오래걸리고, 충분히 이해하지 못한 코드를 변경하면 버그가 발생하게 됩니다.
-
따라서 의도와 목적을 드러내는 이름을 사용하는 것이 좋다.
이해하기 어렵게 만드는 조건 분기 중첩
-
if문의 중첩이 많을 수록 코드의 가독성이 나빠진다.
-
어디서부터 어디까지가 if 조건문 처리문인지 확인하기 힘들기 때문이다.
수많은 악마가 만들어 내는 데이터 클래스
-
데이터 클래스는 설계가 제대로 이루어지지지 않는 소프트웨어에서 빈번하게 등장하는 클래스 구조이다. -
금액을 다루는 서비스를 예로 들어 데이터 클래스의 어떤 점이 나쁜지 살펴보자.
데이터밖에 없는 클래스 구조
// 계약 금액
public class ContractAmount {
public int amountIncludingTax; // 세금 포함 금액
public BigDecimal salesTaxRate; // 소비세율
}
-
세금이 포함된 금액과 소비세율을
public인스턴스 변수로 갖고 있으므로, 클래스 밖에서도 데이터를 자유롭게 변경할 수 있는 구조이다. -
이처럼 데이터를 갖고 있기만 하는 클래스를
데이터 클래스라고 부른다. -
그런데 데이터 클래스에는 데이터뿐만 아니라, 세금이 포함된 금액을 계산하는 로직도 필요한데,
-
이러한 계산 로직을 데이터 클래스가 아닌 다른 클래스에 구현하는 일이 벌어지곤 한다.
-
이럴 경우, 작은 규모의 애플리케이션이라면 큰 문제가 되진 않지만, 규모가 큰 애플리케이션이라면 수많은 악마를 불러들인다.
예를 들어, 업무 계약 서비스에서 소비세와 관련된 사양이 변경되었다고 했을 때, 구현 담당자는 소비세율과 관련된 로직을 변경했다.
- 이때, 소비세와 관련된 부분을 소스 코드 전체에서 찾아서 확인해보니, 세금 포함 금액을 계산하는 로직이 수십 곳에 있음을 확인했다.
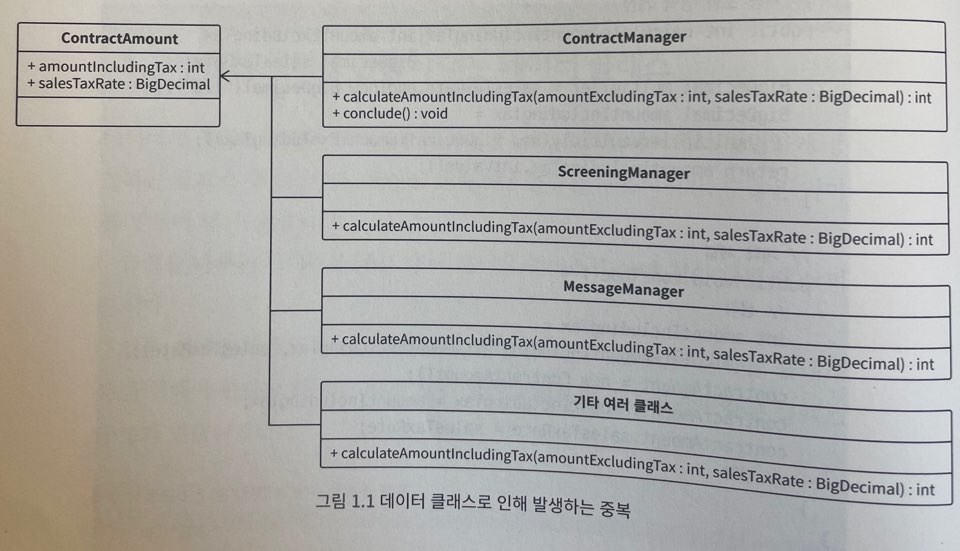
-
이런 상황은 데이터를 담고 있는 클래스와 데이터를 사용하는 계산 로직이 멀리 떨어져 있을 때 자주 일어난다.
-
이처럼 데이터와 로직 등이 분산되어 있는 것을 응집도가 낮은 구조라고 한다.
-
응집도가 낮아 생길 수 있는 여러 가지 문제는 아래와 같다.
[1] 코드 중복
-
관련된 코드가 서로 멀리 떨어져 있으면, 관련된 것끼리 묶어서 파악하기 힘들다.
-
이미 기능이 구현되어 있는데도, 해당 코드를 확인하지 못해서 같은 로직을 여러 곳에 구현할 수 있다.
-
정리하면, 의도하지 않게 코드 중복이 발생하는 것이다.
[2] 수정 누락
-
코드 중복이 많으면, 요구사항이 변경될 때 중복된 코드를 모두 고쳐야 한다.
-
하지만 이 과정에서 일부 코드를 놓칠 수 있으며, 결국 버그를 낳게 된다.
[3] 가독성 저하
-
가독성이란 코드의 의도나 처리 흐름을 얼마나 빠르게 정확하게 읽고 이해할 수 있는지 나타내는 지표다. -
코드가 분산되어 있으면, 찾기도 그 만큼 오래 걸린다.
[4] 초기화되지 않는 상태(쓰레기 객체)
-
초기화해야 하는 클래스라는 것을 모르면, 버그가 발생하기 쉬운 불완전한 클래스가 된다.
-
이처럼
초기화되지 않으면 쓸모 없는 클래스또는초기화하지 않는 상태가 발생할 수 있는 클래스를 안티 패턴 쓰레기 객체라고 부른다.
[5] 잘못된 값 할당
-
값이 잘못되었다는 것은 요구 사항에 맞지 않음을 의미한다.
-
예를 들면) 주문 건수가 음수가 나오는 경우이다.
결과적으로 이와 같은 문제들은 개발 생산성을 떨어뜨리게 된다.