이 글은 카프카 핵심 가이드 책을 읽고 정리한 글입니다.
이 글에서 다루는 모든 코드는 깃허브에서 확인하실 수 있습니다.
참고: 본 글에서 소개되는 코드 예시는 현재 시점의 구현을 바탕으로 작성되었으며, 프로젝트가 발전함에 따라 내용이 변경되거나 개선될 수 있음을 미리 알려드립니다.
Prologue
“카프카 핵심 가이드” 4장 내용을 바탕으로 카프카 컨슈머의 개념, 처리 속도, 리밸런싱 전략에 대해 내용을 정리했다.
이론적인 개념 설명과 더불어, 실제 Spring Kafka 환경에서 어떻게 컨슈머를 구현하고 사용하는지 개인 프로젝트 코드를 통해 함께 살펴본다.
카프카 컨슈머와 컨슈머 그룹의 개념
카프카 컨슈머(Consumer)란 토픽(Topic)에 저장된 데이터를 읽어가는 애플리케이션이다.
-
단순히 데이터를 읽는 것을 넘어, 카프카의 성능과 확장성을 이해하려면 컨슈머 그룹 개념을 반드시 알아야 한다.
-
카프카 컨슈머는 보통 컨슈머 그룹의 일부로 동작한다.
컨슈머 그룹이란 같은 목적을 가진 컨슈머의 묶음이다.
- 하나의 토픽을 하나의 컨슈머 그룹이 구독할 때, 그룹 내 컨슈머들은 파티션을 나눠서 데이터를 가져간다.
여기서 중요한 점은 그룹 내에서 하나의 파티션은 오직 하나의 컨슈머만 점유할 수 있다는 점이다.
컨슈머 처리 속도를 높이는 방법
애플리케이션이 처리하는 속도보다 프로듀서가 메시지를 쌓는 속도가 더 빠르면 데이터 처리가 계속 지연된다.
이때 컨슈머의 처리 속도를 높이는 가장 일반적이고 확실한 방법은 컨슈머의 병렬 처리 를 활용하는 것이다.
방법: 컨슈머 수를 늘려 파티션을 분담한다.
- 컨슈머 1개: 토픽의 모든 파티션에서 데이터를 혼자 처리한다. (아래 그림 4-1)
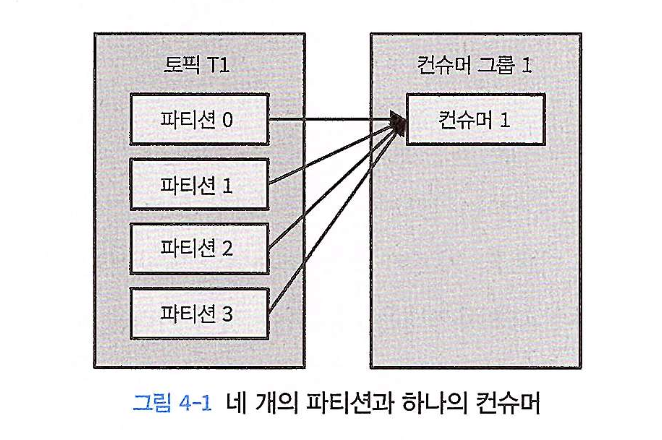
-
컨슈머 추가: 같은 그룹 내에 컨슈머를 추가하면, 카프카는 자동으로 파티션을 재분배(리밸런싱)하여 작업을 나눈다. 특히 데이터베이스 쓰기와 같이 지연시간이 긴 작업을 수행할 때, 이런 방식으로 파티션과 메시지 처리를 분산시키는 것이 가장 일반적인 규모 확장 방식이다.
- 컨슈머가 4개이면 각각 1개의 파티션을 담당하게 되어 처리량이 늘어난다. (아래 그림 4-3)
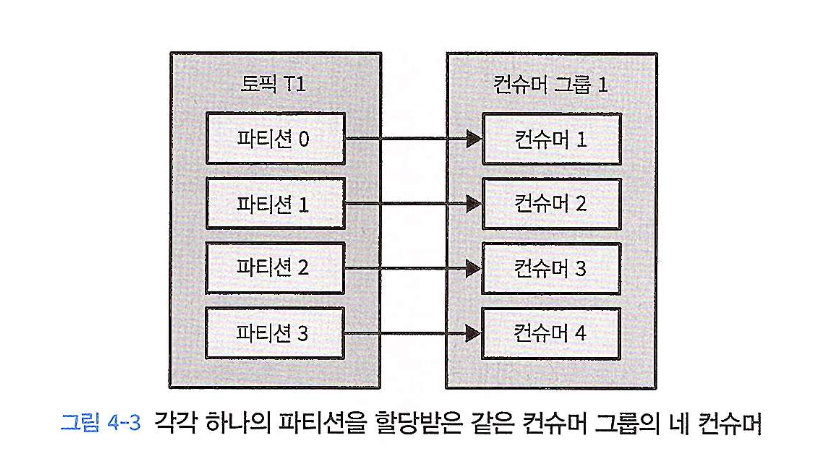
- 토픽의 파티션 개수를 선정하는 방법은 이전 글인 [카프카 핵심 가이드] CHAPTER 2. 카프카 설치하기의 “토픽의 파티션 수 결정 방법” 부분을 참고한다.
주의사항: 파티션 수만큼 확장 가능
-
처리량을 높이려고 컨슈머를 무작정 늘리는 것은 의미가 없다.
-
컨슈머 그룹 내 컨슈머의 수는 토픽의 파티션 수를 초과할 수 없다. (컨슈머 수 <= 토픽의 파티션 수)
-
만약 파티션이 4개인데, 컨슈머를 5개 투입하면, 1개의 컨슈머는 아무 파티션도 할당받지 못하고 유휴 상태(Idle)가 된다. (아래 그림 4-4)
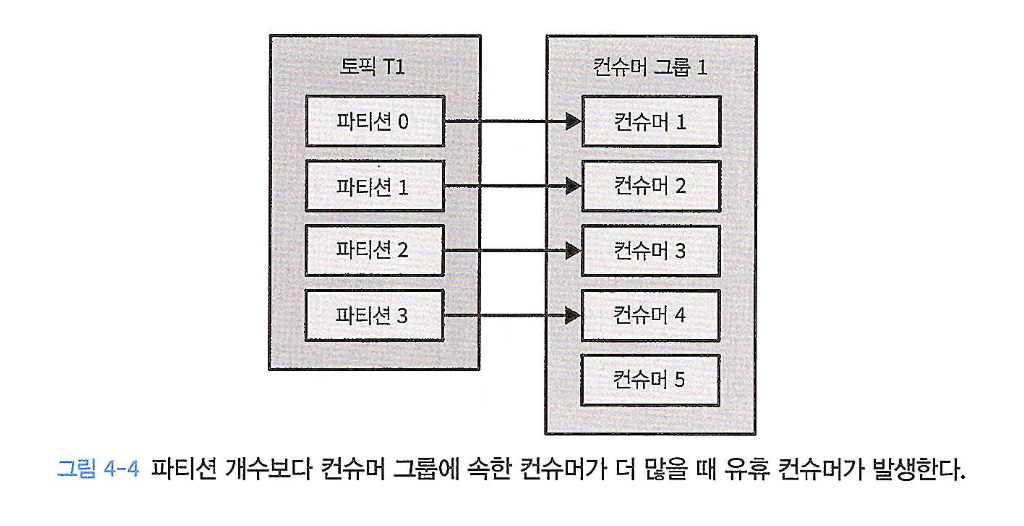
- TIP: 토픽을 처음 설계할 때 예상되는 최대 처리량을 고려하여 파티션 수를 설정하는 것이 좋다.
안정성을 위한 리밸런싱 전략
리밸런스(Rebalance)는 컨슈머 그룹의 확장성과 가용성을 보장하는 핵심 기능이다.
컨슈머 그룹에 새로운 컨슈머가 참여하거나, 기존 컨슈머가 종료 또는 장애로 이탈할 때 파티션의 소유권을 그룹 내 컨슈머들에게 재분배하는 과정을 말한다.
하지만 리밸런싱 중에는 데이터 처리가 일시적으로 중단될 수 있어, 그 동장 방식을 이해하는 것이 중요하다.
카프카는 크게 두 가지 리밸런스 전략을 제공한다.
조급한 리밸런스 (Eager Rebalance)
리밸런스가 시작되면 그룹 내 모든 컨슈머는 읽기 작업을 즉시 멈추고 자신이 담당하던 모든 파티션의 소유권 을 포기한다.
그 후 모든 컨슈머가 다시 그룹에 참여해 완전히 새로운 파티션을 할당을 받는다.
이러한 방식은 전체 컨슈머 그룹에 대해 짧은 시간 동안 작업을 멈추게 한다.
그래서 작업을 멈추는 시간의 길이는 컨슈머 그룹의 크기 뿐만 아니라 여러 설정 매개변수에 영향을 미친다.
아래 그림 4-6과 같이 두 단계에 걸쳐 일어나게 된다.
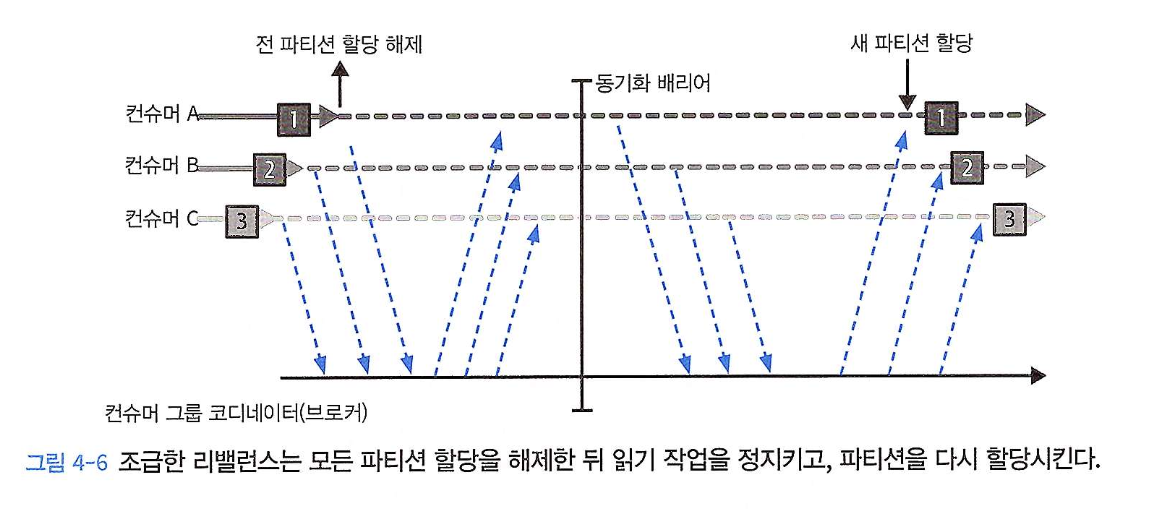
-
모든 컨슈머가 자신에게 할당된 파티션을 포기(해제)하고,
-
파티션을 포기한 컨슈머 모두가 다시 그룹에 참여한 뒤 새로운 파티션을 할당받고 읽기 작업을 재개한다.
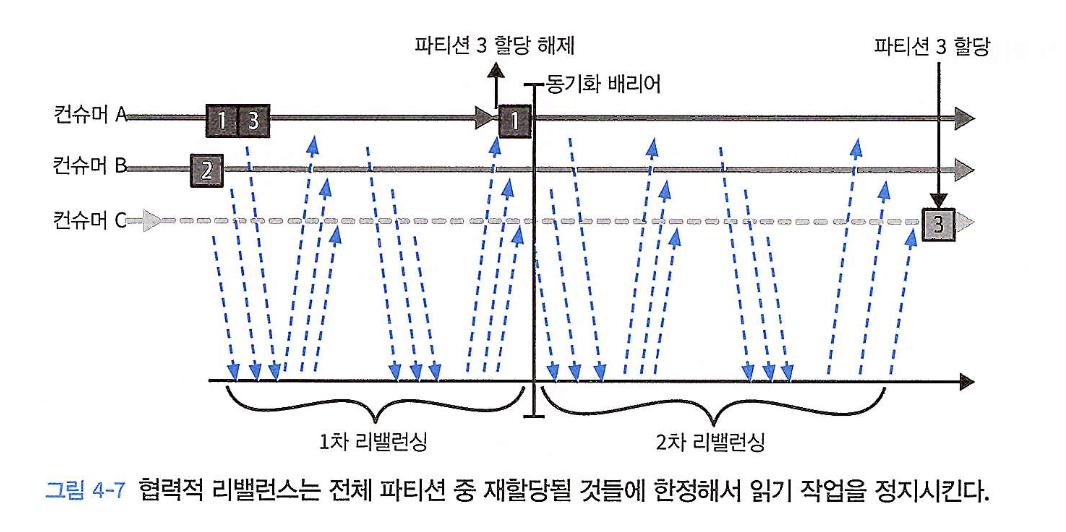
협력적 리밸런스 (Cooperative Rebalance)
점진적 리밸런스(incremental rebalance) 라고도 불리며, 리밸런스가 필요할 때 변경이 필요한 파티션만 재할당한다.
재할당 대상이 아닌 파티션을 담당하던 컨슈머들은 작업 중단 없이 계속 데이터를 처리할 수 있다. (<-> 조급한 리밸런스 방식 대비 장점)
이 경우 리밸런싱은 2개 이상의 단계에 걸쳐서 수행된다.
-
컨슈머 그룹 리더가 다른 컨슈머들에게 각자에게 할당된 파티션 중 일부가 재할당될 것이라고 통보하면, 컨슈머들은 해당 파티션에서 데이터를 읽어오는 작업을 멈추고 해당 파티션에 대한 소유권을 포기한다.
-
컨슈머 그룹 리더가 이 포기한 파티션들을 새로 할당한다.
이러한 특징은 리밸런싱 작업에 상당한 시간이 걸릴 위험이 있는, 컨슈머 그룹에 속한 컨슈머 수가 많은 경우에 중요하다.
또한, 규모가 크고 민감한 서비스에 유리하다.
아래 그림 4-7은 어떻게 컨슈머와 파티션의 일부만을 재할당함으로써 점진적으로 리밸런싱이 수행되는지 보여준다.
리밸런스는 어떻게 감지되는가?
컨슈머 그룹의 리밸런싱은 그룹 코디네이터(Group Coordinator)와 하트비트(Heartbeat)라는 메커니즘을 통해 관리된다.
-
그룹 코디네이터: 각 컨슈머 그룹을 담당하는 카프카 브로커. 그룹의 상태를 관리하고 리밸런스를 지시하는 총괄 책임자 역할을 한다. -
하트비트: 컨슈머가 그룹 코디네이터에게 주기적으로 보내는 “나 살아있어요!” 라는 생존 신호이다.
컨슈머는 백그라운드 스레드를 통해 하트비트를 계속 전송하여 그룹 멤버십을 유지한다.
만약 그룹 코디네이터가 일정 시간(session.timeout.ms) 동안 컨슈머의 하트비트를 받지 못하면,
해당 컨슈머에 장애가 발생했다고 판단하고 그룹에서 제외시킨 뒤 리밸런스를 시작한다.
이 때문에 컨슈머 장애 시에도 안정적인 데이터 처리가 가능하다.
카프카 컨슈머의 동작과 실제 구현
이제 컨슈머의 핵심 개념을 바탕으로, 실제 코드에서 컨슈머가 어떻게 생성되고 동작하는지 알아보자.
책에서는 순수 KafkaConsumer 라이브러리를 사용하지만,
여기서는 Spring Boot 환경에서 Spring Kafka를 사용하는 방법을 함께 비교하여 설명한다
컨슈머 생성 및 필수 설정
카프카에서 데이터를 읽기 위한 첫 단계는 KafkaConsumer 인스턴스를 생성하는 것이다.
이때 반드시 지정해야 하는 3가지 필수 속성과 사실상 필수인 1가지 속성이 있다.
컨슈머 필수 설정
-
bootstrap.servers: 카프카 클러스터에 처음 연결하기 위한 호스트와 포트 정보 목록 -
key.deserializer: 메시지의 키를 역직렬화(byte[] -> Java Object)하는 클래스 -
value.deserializer: 메시지의 값을 역직렬화하는 클래스 -
group.id: 컨슈머가 속한 컨슈머 그룹을 식별하는 ID
Spring Kafka 에서의 구현
Spring Boot 환경에서는 이러한 설정을 ConsumerFactory Bean을 통해 편리하게 관리할 수 있다.
쿠폰 시스템 프로젝트의 KafkaConsumerConfig 코드를 통해 확인해 보자.
KafkaConsumerConfig.java
// dev.be.coupon.kafka.consumer.config.KafkaConsumerConfig
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, CouponIssueMessage> consumerFactory() {
// ... JsonDeserializer 설정 생략 ...
Map<String, Object> config = new HashMap<>();
// 1. bootstrap.servers
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 2. key.deserializer
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 3. value.deserializer (JSON 메시지를 CouponIssueMessage 객체로 변환)
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserializer);
// 4. group.id
config.put(ConsumerConfig.GROUP_ID_CONFIG, "group_1");
// 오프셋 커밋 방식 설정 (자동/수동) -> 수동
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
return new DefaultKafkaConsumerFactory<>(config, new StringDeserializer(), deserializer);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, CouponIssueMessage> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, CouponIssueMessage> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL); // 리스너에서 Acknowledgment.acknowledge()를 명시적으로 호출해야만 오프셋이 커밋합니다.
factory.setConcurrency(3); // 토픽의 파티션 수와 일치시켜 병렬 처리 성능을 최적화합니다.
return factory;
}
}
책에서 설명한 필수 설정들이 Map 객체에 키-값 형태로 들어가는 것을 볼 수 있다.
수동 커밋은 개발자가 원하는 시점에 명시적으로 커밋을 할 수 있게 하여, 메시지 처리의 신뢰성을 보장한다.
즉, 모든 비즈니스 로직이 성공적으로 끝났을 때만 커밋하여 데이터 유실이나 중복 처리 문제를 방지할 수 있다.
(오프셋 커밋 방식 설정에 대한 부분은 이후 컨슈머 설정과 관련된 포스팅에서 다룰 예정이다.)
토픽 구독 및 폴링: Spring Kafka의 추상화
순수 KafkaConsumer는 subscribe()로 토픽을 구독한 뒤, while(true) 루프 안에서 poll()을 주기적으로 호출해야 한다.
이 poll() 메서드는 단순히 데이터를 가져오는 것을 넘어, 리밸런스에 참여하고 브로커에 생존 신호(하트비트)를 보내는 중요한 역할을 한다.
(poll() 메서드를 포함한 폴링 루프의 상세한 동작 과정은 “카프카 핵심 가이드” 4.4절을 참고한다.)
Spring Kafka는 이 복잡한 구독 및 폴링 루프 전체를 @KafkaListener 애노테이션 하나로 추상화하여 개발자가 비즈니스 로직에만 집중할 수 있게 해준다.
CouponIssueConsumer.java
// dev.be.coupon.kafka.consumer.application.CouponIssueConsumer
@Component
public class CouponIssueConsumer {
// ...
@KafkaListener(topics = "#{T(dev.be.coupon.infra.kafka.KafkaTopic).COUPON_ISSUE.getTopicName()}", groupId = "group_1")
public void listener(final CouponIssueMessage message,
final Acknowledgment ack) {
// Spring이 백그라운드에서 poll()로 가져온 '하나의 레코드'가 'message' 파라미터로 전달된다.
log.info("발급 처리 메시지 수신: {}", message);
try {
// 비즈니스 로직 수행
couponIssuanceService.process(message);
} finally {
// 로직이 성공적으로 끝나면 수동으로 오프셋을 커밋한다.
ack.acknowledge();
// ...
}
}
}
이처럼 @KafkaListener를 사용하면 컨슈머의 복잡한 생명주기 관리를 프레임워크에 위임하고,
개발자는 메시지를 받아 처리하는 핵심 로직에만 집중할 수 있다.