- Prologue
- 카프카 프로듀서(Producer)란?
- 프로듀서의 메시지 전송 과정
- 프로듀서를 생성하기 위한 필수 옵션
- 메시지 전송 방법
- 프로듀서 설정하기
- 프로듀서 설정 예시 (세부 옵션 추가)
- References
이 글은 카프카 핵심 가이드 책을 읽고 정리한 글입니다.
이 글에서 다루는 모든 코드는 깃허브에서 확인하실 수 있습니다.
참고: 본 글에서 소개되는 코드 예시는 현재 시점의 구현을 바탕으로 작성되었으며, 프로젝트가 발전함에 따라 내용이 변경되거나 개선될 수 있음을 미리 알려드립니다.
Prologue
“카프카 핵심 가이드” 책을 현재 두 번째 읽고 있지만, 생각보다 책의 난이도가 있고, 이해하기 어려운 점이 있어서 책에 있는 내용 중에 중요한 내용 위주로 정리하기 위해 + 간단한 실습 정리를 위해 이 글을 작성하게 되었다.
이 글은 책의 내용을 기반으로 하되, 앞으로 프로듀서와 관련하여 실무에서 중요하다고 생각되는 개념이 있다면 지속적으로 내용을 보완하고 업데이트할 예정이다.
자세한 내용은 책의 3장을 참고하자.
카프카 프로듀서(Producer)란?
카프카 프로듀서(Producer) 는 카프카 클러스터의 토픽(Topic)으로 메시지(데이터)를 전송하는 역할을 담당하는 애플리케이션이다.
프로듀서는 다양한 목적으로 사용될 수 있다.
-
사용자 행동 로그 기록
-
서버 성능 메트릭 수집
-
다른 애플리케이션과의 비동기 통신
-
데이터베이스에 저장하기 전 데이터 버퍼링
이처럼 다양한 요구조건(메시지 유실 허용 여부, 지연 시간, 처리율 등)에 맞춰 프로듀서의 동작 방식과 설정을 다르게 구성할 수 있다.
프로듀서의 메시지 전송 과정
프로듀서는 단순히 메시지를 보내는 것처럼 보이지만, 내부적으로는 아래 그림과 같이 여러 단계를 거쳐 동작한다.
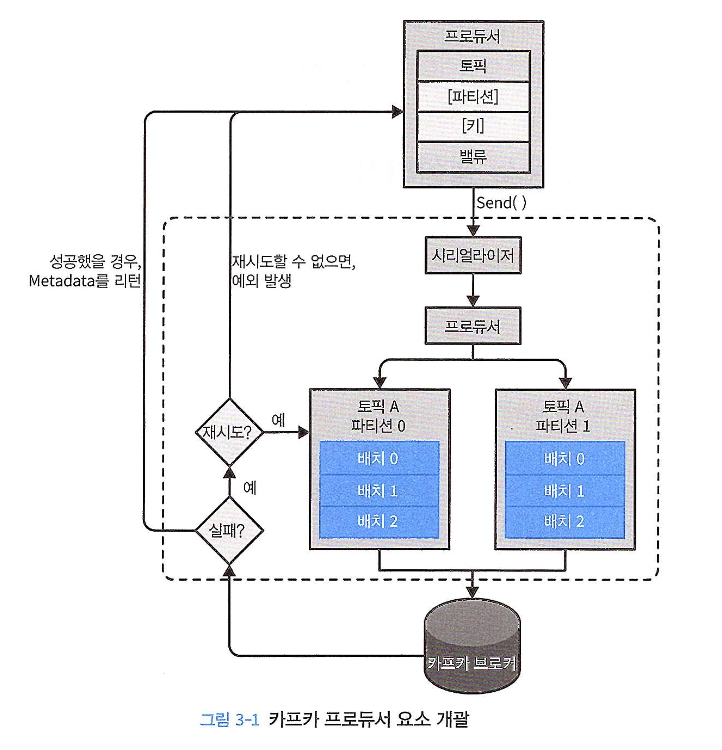
-
[1] ProducerRecord 생성:
-
전송할 메시지를 담은 ProducerRecord 객체를 생성하는 것으로 모든 과정이 시작된다.
-
이 객체에는 메시지를 보낼 토픽과 값(value) 이 필수로 포함되며, 필요에 따라 키(key) 와 파티션(partition) 을 지정할 수 있다.
-
-
[2] 직렬화(Serialization):
- 프로듀서는 ProducerRecord의 키와 값을 네트워크로 전송할 수 있도록 바이트 배열(byte array)로 변환하는 직렬화 과정을 수행한다.
-
[3] 파티셔너(Partitioner):
- 레코드에 파티션이 명시적으로 지정되지 않았다면, 파티셔너가 어떤 파티션으로 메시지를 보낼지 결정한다. 일반적으로 메시지의 키 값을 기준으로 파티션을 선택한다.
-
[4] 레코드 배치(Record Batch):
- 파티션이 결정되면, 프로듀서는 해당 레코드를 같은 토픽-파티션으로 전송될 다른 레코드들과 함께 레코드 배치에 추가한다. 별도의 스레드가 이 배치들을 모아 브로커로 전송함으로써 전송 효율을 높인다.
-
[5] 브로커 응답 및 재시도:
-
브로커는 메시지를 성공적으로 받으면 토픽, 파티션, 오프셋 정보가 담긴 메타데이터(Metadata)를 반환한다.
-
만약 실패하면 에러를 반환하며, 프로듀서는 설정에 따라 몇 번 더 재전송을 시도한다.
-
프로듀서를 생성하기 위한 필수 옵션
카프카 프로듀서를 생성하기 위해서는 최소한 다음 3가지 필수 속성을 설정해야 한다.
-
bootstrap.servers- 프로듀서가 카프카 클러스터에 처음 연결하기 위해 사용하는 ‘호스트:포트’ 목록이다. 모든 브로커 정보를 다 적을 필요는 없으며, 일부 브로커가 다운되더라도 접속할 수 있도록 최소 2개 이상을 설정하는 것이 권장된다.
-
key.serializer- 메시지의 키(key) 를 네트워크를 통해 전송 가능한 바이트 배열로 변환(직렬화)하는 클래스를 지정한다.
-
value.serializer- 레코드의 값 을 직렬화하는 데 사용할 클래스이다.
이러한 설정을 아래와 같이 쿠폰 발급 기능을 비동기적으로 처리하기 위해 Spring Boot 환경에서 카프카 프로듀서를 설정한 실제 코드 예시를 가져왔다.
KafkaProducerConfig.java (필수 옵션)
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> config = new HashMap<>();
// 1. bootstrap.servers 설정
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 2. key.serializer 설정
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 3. value.serializer 설정
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
// 카프카 메시지 전송을 위한 KafkaTemplate 빈 등록
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
위 코드는 앞서 설명한 세 가지 필수 속성을 그대로 구현하고 있다.
-
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG는bootstrap.servers에 해당한다. -
KEY_SERIALIZER_CLASS_CONFIG는key.serializer에 해당하며, 키로 문자열을 사용하기 위해StringSerializer를 지정했다. -
VALUE_SERIALIZER_CLASS_CONFIG는value.serializer에 해당하며, 쿠폰 객체와 같은 복잡한 데이터를 보내기 위해JsonSerializer를 사용했다.
이렇게 설정된 ProducerFactory를 기반으로 KafkaTemplate을 생성(Bean으로 등록)하면, 이제 애플리케이션 어디서든 KafkaTemplate을 주입받아 간편하게 메시지를 전송할 수 있다.
위 코드는 프로듀서를 동작시키기 위한 가장 기본적인 설정이다.
하지만 실제 운영 환경에서는 메시지 유실이나 중복을 방지하기 위해 더 많은 옵션을 고려해야 한다. 이어지는 ‘프로듀서 설정하기’ 섹션에서 이러한 세부 옵션들을 알아보고, 글의 마지막에서 이 모든 것을 종합한 최종 설정 예시를 다시 살펴보자.
메시지 전송 방법
프로듀서는 메시지를 보내는 세 가지 주요 방식을 제공한다.
-
파이어 앤 포겟 (Fire-and-forget): 전송만 하고 성공 여부는 확인하지 않는 방식이다. 빠르지만 메시지가 유실될 수 있다.
-
동기 전송 (Synchronous send)
send()메서드가 반환하는Future객체의get()을 호출하여 전송이 완료되고 성공할 때까지 기다리는 방식이다. 전송을 보장하지만, 응답을 기다리는 동안 애플리케이션이 멈추므로 성능이 저하된다.
-
비동기 전송 (Asynchronous send)
send()메서드에 콜백(Callback) 함수를 함께 전달하는 방식이다. 브로커로부터 응답이 오면 미리 지정한 콜백 함수가 실행된다. 애플리케이션을 차단하지 않으면서도 전송 결과를 확실하게 처리할 수 있어 가장 널리 사용하는 방식이다.
public class KafkaTemplate<K, V> implements KafkaOperations<K, V>, ApplicationContextAware, BeanNameAware, ApplicationListener<ContextStoppedEvent>, DisposableBean, SmartInitializingSingleton {
public CompletableFuture<SendResult<K, V>> send(Message<?> message) {
ProducerRecord<?, ?> producerRecord = this.messageConverter.fromMessage(message, this.defaultTopic);
if (!producerRecord.headers().iterator().hasNext()) {
byte[] correlationId = (byte[]) message.getHeaders().get("kafka_correlationId", byte[].class);
if (correlationId != null) {
producerRecord.headers().add("kafka_correlationId", correlationId);
}
}
return this.observeSend(producerRecord);
}
}
-
참고: Spring Kafka의
KafkaTemplate.send()메서드는 기본적으로CompletableFuture(또는 이전 버전의ListenableFuture)를 반환하여 비동기적으로 동작한다.-
따라서
send()만 호출하고 반환된Future객체를 처리하지 않으면 겉보기에는 ‘파이어 앤 포겟’처럼 보일 수 있다. -
하지만 실제로는 백그라운드에서 비동기 전송이 이루어지고 있으며, 명시적으로
whenComplete와 같은 콜백을 등록하여 성공 또는 실패를 처리하면 완전한 ‘비동기 전송’ 방식으로 활용할 수 있다.
-
쿠폰 시스템의 경우, 사용자가 쿠폰 발급 버튼을 눌렀을 때 즉시 “쿠폰 발급 요청이 처리 중입니다” 라고 응답하고 실제 발급 처리는 백그라운드에서 수행하는 것이 좋다. 이는 비동기 전송 방식에 가장 적합한 시나리오다.
KafkaTemplate을 이용한 메시지 전송 예시
Spring Boot 환경에서는 앞서 설정한 KafkaTemplate을 이용하여 편리하게 비동기 메시지를 전송할 수 있다.
실제 애플리케이션에서는 특정 도메인의 메시지를 전송하는 역할을 담당하는 전용 프로듀서 클래스를 만들어 사용하는 것이 일반적이다.
아래는 ‘쿠폰 발급’ 메시지를 발행하는 CouponIssueProducer 클래스의 코드 예시다.
CouponIssueProducer.java
@Component
public class CouponIssueProducer {
private final KafkaTemplate<String, Object> kafkaTemplate;
private static final String GLOBAL_TRACE_ID_HEADER = "globalTraceId";
private static final Logger log = LoggerFactory.getLogger(CouponIssueProducer.class);
// ...
/**
* 쿠폰 발급 요청 메시지를 동기적으로 Kafka에 발행합니다.
* .join()을 호출하여 메시지 전송이 완료될 때까지 현재 스레드를 블로킹합니다.
*/
public void issue(final UUID userId, final UUID couponId) {
CouponIssueMessage payload = new CouponIssueMessage(userId, couponId);
String globalTraceId = MDC.get("globalTraceId");
ProducerRecord<String, Object> record = new ProducerRecord<>(KafkaTopic.COUPON_ISSUE.getTopicName(), payload);
if (globalTraceId != null) {
record.headers().add(GLOBAL_TRACE_ID_HEADER, globalTraceId.getBytes(StandardCharsets.UTF_8));
}
kafkaTemplate.send(record).whenComplete((result, ex) -> {
if (ex != null) {
log.error("메시지 전송 실패. GlobalTraceId: {}, Record: {}",
globalTraceId, record, ex);
} else {
log.info("메시지 전송 성공. GlobalTraceId: {}, Topic: {}, Partition: {}, Offset: {}, Payload: {}",
globalTraceId,
result.getRecordMetadata().topic(),
result.getRecordMetadata().partition(),
result.getRecordMetadata().offset(),
payload);
}
}).join(); // 이 메서드가 호출되면, whenComplete의 콜백이 실행될 때까지 스레드가 블로킹됩니다.
}
}
이 클래스는 KafkaProducerConfig에서 Bean으로 등록한 KafkaTemplate을 의존성 주입 받는다.
issue 메서드의 동작은 코드의 주석과 같이 세 단계로 나뉜다.
-
페이로드 생성: 카프카로 보낼 실제 데이터(
CouponIssueMessage)를 만든다. -
ProducerRecord객체 생성: 토픽 이름, 페이로드, 추적 ID가 담긴ProducerRecord객체를 직접 생성한다. -
동기적 전송 및 대기:
kafkaTemplate.send()를 호출하여 메시지를 발행하고, 반환된CompletableFuture에.join()을 호출한다. 이로 인해 메시지 전송이 완료될 때까지(성공 또는 실패) 현재 스레드는 블로킹된다. 전송 결과는whenComplete콜백을 통해 로그로 남겨진다.
앞서 비동기 전송이 가장 널리 쓰인다고 설명했는데, 왜 코드에서는 .join()을 호출하여 동기 방식으로 처리했을까?
이는 응답 신뢰도와 순서 보장이라는 두 가지 중요한 목표를 달성하기 위한 설계적 선택이다.
-
응답 신뢰도
-
.join()을 사용하면, API 서버는 Kafka 브로커가 메시지를 성공적으로 받았다는 확신을 얻기 전까지 사용자에게 최종 성공 응답을 보내지 않는다. -
만약 Kafka 전송 단계에서 문제가 발생하면, API 서버는 사용자에게 즉시 에러를 반환하여 ‘요청이 실패했음’을 명확히 알릴 수 있다.
-
이는 ‘요청 성공’ 응답을 받았는데 실제로는 발급 처리가 시작조차 되지 않는 상황을 방지할 수 있는 안전장치다.
-
-
순서 보장(선착순)
-
선착순 쿠폰 시스템에서는 요청이 들어온 순서대로 처리되는 것이 매우 중요하다.
-
이러한 엄격한 순서 보장은 보통 Kafka 앞단에 있는 Redis의 원자적(Atomic) 연산을 통해 결정된다.
-
프로듀서의 .join()은 이 선착순을 직접 보장하기보다는, 단일 서버 내에서 요청 처리 흐름을 순차적으로 만들어 ‘응답 신뢰도’를 높이는 역할을 보조한다.
-
만약 프로듀서가 메시지를 비동기적으로 보낸다면 네트워크 상황에 따라 나중에 보낸 메시지가 먼저 도착할 수 있다.
-
만약 여러 서버가 운영되는 분산 환경에서는
.join()만으로는 서버 간의 처리 순서까지 보장할 수 없으므로, 선착순 로직은 반드시 Redis와 같은 외부 시스템에 위임해야 한다.
-
이렇게 프로듀서가 메시지를 Kafka에 안전하게 전달하고 나면, 그 책임은 이제 컨슈머(Consumer)에게로 넘어간다.
컨슈머는 coupon_issue 토픽을 구독하고 있다가, 새로운 메시지가 들어오면 이를 가져와 최종적으로 데이터베이스에 쿠폰 발급 내역을 저장하는 역할을 수행한다.
(컨슈머에 대한 자세한 내용은 다른 포스팅에서 설명할 예정이다)
결론적으로, 비동기 전송이 가장 널리 쓰이지만, 비즈니스 상황에 따라 동기적 전송을 사용할 수 있다.
프로듀서 설정하기
카프카 프로듀서는 수많은 설정값을 가지고 있지만, 대부분은 합리적인 기본값을 가지고 있다.
하지만 몇몇 설정은 프로듀서의 신뢰성, 성능, 메모리 사용량에 큰 영향을 미치므로, 실무에서 자주 사용되는 중요한 옵션들 위주로 정리해두자.
1. 데이터 전송 신뢰도 관련 설정
메시지를 유실 없이, 중복 없이 보내는 것은 매우 중요하다. 이때 acks 와 enable.idempotence 설정이 핵심적인 역할을 한다.
acks
acks는 프로듀서가 보낸 메시지에 대해 브로커로부터 ‘전송 성공’으로 간주하기 위해 필요한 응답(acknowledgment)의 수를 결정한다.
-
acks=0: 프로듀서는 응답을 기다리지 않고 즉시 다음 메시지를 전송한다. 속도는 가장 빠르지만, 브로커가 메시지를 받지 못해도 프로듀서는 알지 못해 메시지가 유실될 위험이 가장 크다. -
acks=1: 리더 파티션에 메시지가 저장되면 ‘성공’ 응답을 받는다. 리더에 장애가 발생하고 아직 복제가 완료되지 않았다면 메시지가 유실될 수 있다. -
acks=all(또는-1): 가장 안전한 옵션. 리더 파티션뿐만 아니라, 모든 팔로워(ISR, In-Sync Replica) 파티션에 메시지가 복제되었을 때 ‘성공’ 응답을 받는다. 브로커 하나에 장애가 생겨도 메시지 유실이 발생하지 않는다. (최신) 카프카 버전 3.0.0부터 프로듀서의acks기본값이1에서all로 변경되었다.
enable.idempotence (멱등성 프로듀서)
acks=all 로 설정하면 메시지 유실은 막을 수 있지만, 메시지 중복이 발생할 수 있다.
예를 들어, 브로커가 메시지를 받고 복제까지 완료했지만, 프로듀서에게 성공 응답을 보내기 전에 장애가 발생했다고 가정하자.
프로듀서는 응답을 받지 못했으므로 타임아웃 후 메시지를 재전송하게 되고, 이로 인해 동일한 메시지가 두 번 저장된다.
enable.idempotence=true 로 설정하면 이러한 중복을 방지할 수 있다.
-
프로듀서는 각 메시지에 고유한 시퀀스 번호를 붙여 전송한다.
-
브로커는 이미 받은 시퀀스 번호의 메시지가 다시 오면 중복으로 간주하여 저장하지 않는다.
-
이를 통해 ‘최소 한 번 전송(At-Least-Once)’에서 ‘정확히 한 번 전송(Exactly-Once)’에 가까운 효과를 낼 수 있다.
-
참고:
enable.idempotence=true로 설정하면, 카프카는 신뢰도를 보장하기 위해 내부적으로 다른 주요 설정값들을 안전한 값으로 강제하므로, 신뢰성이 중요한 대부분의 실무 환경에서는 이 옵션을 true로 설정하는 것이 좋다.-
(
retries는 Integer.MAX_VALUE로,acks는 all로,max.in.flight.requests.per.connection은 5 이하로 유지). -
따라서 신뢰성이 중요한 대부분의 실무 환경에서는 이 옵션을
true로 설정하는 것이 좋다.
-
2. 성능 및 처리량 관련 설정
batch.size, linger.ms, compression.type은 프로듀서의 처리량(throughput)을 높이기 위한 핵심 설정이다.
-
batch.size: 프로듀서가 메시지를 보낼 때, 여러 메시지를 묶어서 하나의 배치(batch)로 만들어 전송한다. 이 설정은 하나의 배치에 담을 수 있는 메모리(바이트) 크기를 의미한다. -
linger.ms: 배치가batch.size에 도달하지 않더라도, 메시지를 보내기 전까지 대기하는 시간(ms)을 의미한다. 프로듀서는batch.size가 차거나linger.ms시간이 지나면 배치를 전송한다. -
compression.type: 메시지를 브로커로 전송하기 전에 압축하는 방식을 지정한다. (snappy, gzip, lz4, zstd 등)-
압축을 사용하면 네트워크 대역폭과 브로커의 저장 공간을 크게 절약할 수 있다. 특히
batch.size를 늘려 여러 메시지를 함께 압축할수록 효율이 좋아진다.-
snappy: 적절한 압축률과 낮은 CPU 사용량으로 균형이 좋다. 대부분의 경우 무난한 선택이다. -
gzip: 압축률은 더 높지만 CPU 사용량도 더 많다. 네트워크 대역폭이 매우 제한적인 환경에서 유리하다.
-
-
3. 타임아웃 및 전송 시간 관련 설정
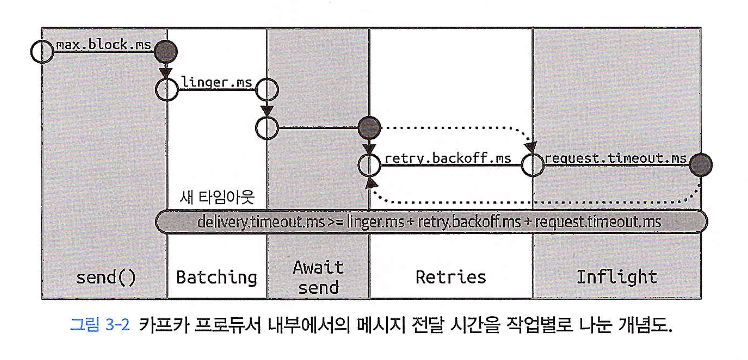
위 그림은 send() 호출부터 최종 응답까지의 과정을 보여준다. 이 과정에서 중요한 타임아웃 설정은 다음과 같다.
-
[1]
send()호출과 블로킹 (max.block.ms): 메시지 전송은send()호출로 시작된다. 만약 프로듀서 내부 버퍼가 가득 차 있다면, 버퍼에 공간이 생길 때까지send()호출이 블록(block) 되는데, 이때의 최대 대기 시간이max.block.ms다. -
[2] 배치 대기 (
linger.ms): 버퍼에 들어간 메시지는 전송될 배치를 이루기 위해 잠시 대기한다. 이 대기 시간이 바로linger.ms다. -
[3] 전송과 응답 대기 (
request.timeout.ms): 배치가 브로커로 전송(Inflight)되면, 프로듀서는 응답을 기다린다. 이 개별 요청에 대한 타임아웃이request.timeout.ms다. -
[4] 재시도 (
retry.backoff.ms):request.timeout.ms가 초과되거나 일시적인 오류를 받으면, 프로듀서는 재시도를 수행한다. 재시도와 재시도 사이의 대기 시간이retry.backoff.ms다. -
[5] 최종 마감 (
delivery.timeout.ms): 가장 중요한 마스터 타임아웃이다. send() 호출 이후의 모든 과정(배치 대기, 전송, 모든 재시도)은delivery.timeout.ms라는 최종 마감 시간 내에 완료되어야 한다. 이 시간을 초과하면 프로듀서는 최종적으로 메시지 전송 실패를 반환한다. 그림의 공식 (delivery.timeout.ms >= linger.ms + retry.backoff.ms + request.timeout.ms)은 이 관계를 보여주는 예시이며, 실제로는 설정된retries횟수에 따른 모든 재시도 과정을 포괄할 수 있도록 충분히 길게 설정해야 한다.
참고
-
책에서 권장하는 더 합리적인 설정 방식은
retries나retry.backoff.ms를 직접 계산하는 것이 아니라, 전체적인 관점에서 타임아웃을 관리하는 것이다. -
예를 들어 “클러스터 장애 복구에 2분이 걸릴 수 있으니,
-
최대 2분까지는 기다린다”는 식으로 비즈니스 요구사항에 맞춰
delivery.timeout.ms를120000으로 넉넉하게 설정하고, -
retries는 기본값(사실상 무한)으로 두는 방식이다. -
이렇게 하면 프로듀서는 주어진 최종 마감 시간 안에서 스스로 끈기 있게 재시도를 수행하므로, 개발자가 복잡한 재시도 로직을 계산할 필요가 없어지는 장점이 있다.
4. 데이터 포맷 설정 (Serializer)
프로듀서는 자바 객체를 카프카로 보내기 위해 바이트 배열로 변환하는 직렬화(Serialization) 과정이 필수적이다.
커스텀 시리얼라이저의 문제점
직접 객체를 위한 시리얼라이저를 구현할 수도 있지만, 실무에서는 다음과 같은 심각한 문제가 발생할 수 있다.
-
스키마 변경의 어려움: 객체에 필드 하나를 추가하거나 타입을 변경하면, 기존 데이터를 읽지 못하는 호환성 문제가 발생한다.
-
유지보수의 어려움: 서로 다른 팀이나 애플리케이션이 같은 데이터를 사용할 경우, 모두가 동일한 직렬화/역직렬화 로직을 유지해야 해서 변경이 매우 복잡해진다.
아파치 에이브로(Avro)와 스키마 레지스트리
이러한 문제를 해결하기 위해 아파치 에이브로(Avro)와 같은 범용 직렬화 라이브러리를 사용하는 것이 강력히 권장된다.
-
스키마 기반: Avro는 데이터를 스키마(데이터의 구조 정의)에 따라 직렬화한다.
-
호환성 보장: 스키마가 변경되더라도 정해진 규칙(필드 추가/삭제 등)을 지키면, 구버전의 스키마를 사용하는 애플리케이션도 문제없이 데이터를 처리할 수 있다.
-
스키마 레지스트리: 보통 스키마를 중앙에서 관리하는 스키마 레지스트리(Schema Registry) 와 함께 사용하여, 모든 프로듀서와 컨슈머가 스키마 정보를 공유하고 데이터 호환성을 보장받는다.
결론적으로, 안정적인 데이터 파이프라인을 구축하기 위해서는 직접 시리얼라이저를 구현하기보다 Avro와 스키마 레지스트리를 도입하는 것이 훨씬 좋은 선택이다
프로듀서 설정 예시 (세부 옵션 추가)
프로듀서의 신뢰성, 성능, 그리고 재시도 메커니즘을 상세하게 제어하기 위해 필수 옵션 외에 다음과 같은 설정을 추가할 수 있다.
이러한 설정들은 프로듀서의 전반적인 동작에 큰 영향을 미치므로, 애플리케이션의 요구사항과 카프카 클러스터의 환경에 맞춰 신중하게 조정해야 한다.
아래는 필수 옵션을 포함하여 지금까지 살펴본 acks, enable.idempotence, 재시도, 타임아웃 등 여러 옵션을 종합하여, 앞서 봤던 기본 설정을 실무 수준의 안정적인 프로듀서 설정으로 발전시키면 아래와 같다.
KafkaProducerConfig.java (세부 옵션을 포함한
최종 설정 예시)
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> config = new HashMap<>();
// 필수 옵션
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
// 데이터 전송 신뢰도 설정: 모든 ISR에 복제될 때까지 대기
// acks=all: 가장 높은 신뢰성을 보장하며, 메시지 유실을 방지한다.
config.put(ProducerConfig.ACKS_CONFIG, "all");
// [중요] 멱등성 활성화 (Exactly-Once Semantics 에 가까운 효과)
// 이 옵션을 true로 설정하면, 프로듀서는 메시지 중복을 방지하기 위해
// 내부적으로 acks=all, retries=Integer.MAX_VALUE 등을 강제한다.
// 따라서 실질적인 재시도 제어는 'delivery.timeout.ms'가 담당하게 된다.
config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 재시도 횟수: 일시적인 네트워크 문제나 브로커 장애 시 메시지를 재전송할 최대 횟수다.
// 멱등성 옵션이 활성화되면 이 설정은 무시되고, 내부적으로 Integer.MAX_VALUE로 설정되므로 주석 처리한다.
//config.put(ProducerConfig.RETRIES_CONFIG, 3);
// 재시도 사이의 대기 시간
// 재시도 간 지연 시간을 주어 브로커가 복구되거나 부하가 줄어들 시간을 벌어준다.
config.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 1000); // 1초 대기
// 프로듀서가 전송을 시도하는 총 시간 (재시도 포함)
// 메시지가 전송 대기열에 추가된 순간부터 브로커로부터 최종 응답을 받거나 실패할 때까지의
// 최대 시간이다. 이 시간 안에 전송이 완료되지 않으면 실패로 간주된다.
config.put(ProducerConfig.DELIVERY_TIMEOUT_MS_CONFIG, 120000); // 120초
// 배치 처리 설정: 메시지 전송 효율을 높이기 위해 여러 메시지를 모아 배치로 전송한다.
config.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 16KB
config.put(ProducerConfig.LINGER_MS_CONFIG, 10); // 10ms 대기
// 압축 타입 설정: 네트워크 대역폭과 저장 공간을 절약하기 위해 메시지 압축을 사용한다.
config.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
return new DefaultKafkaProducerFactory<>(config);
}
// 카프카 토픽에 데이터를 전송하기 위해 사용할 KafkaTemplate을 생성한다.
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
위 예시 코드는 프로듀서의 필수 설정과 함께, 메시지 전송의 신뢰성, 성능, 그리고 타임아웃 및 재시도와 관련된 세부 옵션들을 어떻게 설정하는지 보여준다.
이 설정들은 앞서 “프로듀서 설정하기” 섹션에서 설명한 내용과 직접적으로 연관된다.
위 코드에서 RETRIES_CONFIG 를 주석 처리한 이유가 중요하다. 이 부분은 아래 테스트 코드를 통해 자세히 살펴보자.
테스트코드로 검증하기
1. 잘못된 가정과 첫 번째 테스트
만약 enable.idempotence=true와 retries=3을 동시에 설정했다면, 어떤 일이 벌어질까?
아래는 이 상태를 검증하는 초기 테스트 코드다.
KafkaProducerConfigTest.java (초기 가정 테스트)
class KafkaProducerConfigTest {
@Test
@DisplayName("초기 프로듀서 설정값을 확인한다")
void check_initial_producer_configurations() {
// given
// KafkaProducerConfig에 retries=3 설정이 살아있다고 가정
KafkaProducerConfig config = new KafkaProducerConfig();
ProducerFactory<String, Object> producerFactory = config.producerFactory();
// when
Map<String, Object> configs = producerFactory.getConfigurationProperties();
// then
assertThat(configs.get(ProducerConfig.RETRIES_CONFIG)).isEqualTo(3); // 테스트 통과
assertThat(configs.get(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG)).isEqualTo(true);
}
}
놀랍게도 이 테스트는 성공한다. 여기서 ‘멱등성이 켜지면 retries가 Integer.MAX_VALUE로 강제된다고 했는데 왜 테스트는 통과하지?’ 라는 의문이 생긴다.
그 이유는 이 테스트가 ‘실제 동작하는 클라이언트’가 아닌, Spring의 ProducerFactory가 보관 중인 ‘원본 설정값’ 을 확인하기 때문이다.
실제 KafkaProducer 클라이언트가 생성되는 순간에는 이 retries 값이 내부적으로 재정의(override) 된다.
이처럼 테스트 결과와 실제 동작이 달라 혼동을 줄 수 있다.
2. 설정 코드 리팩토링과 최종 테스트
이러한 혼란을 없애고 코드의 의도를 명확히 하기 위해, KafkaProducerConfig의 retries 설정을 주석 처리했다.
필자의 의도는 “멱등성 옵션을 켤 것이므로, retries는 따로 설정하지 않고 카프카의 기본 정책에 맡긴다” 이다.
따라서 최종 테스트 코드는 retries 값이 3임을 확인하는 대신, 해당 설정이 ‘없음’(null)을 확인하는 것이 정확하다.
KafkaProducerConfigTest.java (최종 수정된 테스트)
class KafkaProducerConfigTest {
@Test
@DisplayName("리팩토링된 멱등성 프로듀서 설정을 올바르게 검증한다")
void check_refactored_idempotent_producer_configurations() {
// given
// retries가 주석 처리된 최종 KafkaProducerConfig
KafkaProducerConfig config = new KafkaProducerConfig();
ProducerFactory<String, Object> producerFactory = config.producerFactory();
// when
Map<String, Object> configs = producerFactory.getConfigurationProperties();
// then
// 멱등성 옵션이 켜져있을 때 retries는 명시적으로 설정하지 않는 것이 올바르므로,
// 해당 키가 없는 것을 검증하는 것이 가장 정확하다.
assertThat(configs.get(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG)).isEqualTo(true);
assertThat(configs).doesNotContainKey(ProducerConfig.RETRIES_CONFIG);
assertThat(configs.size()).isEqualTo(10); // retries가 빠져 전체 설정 개수는 10개
}
}
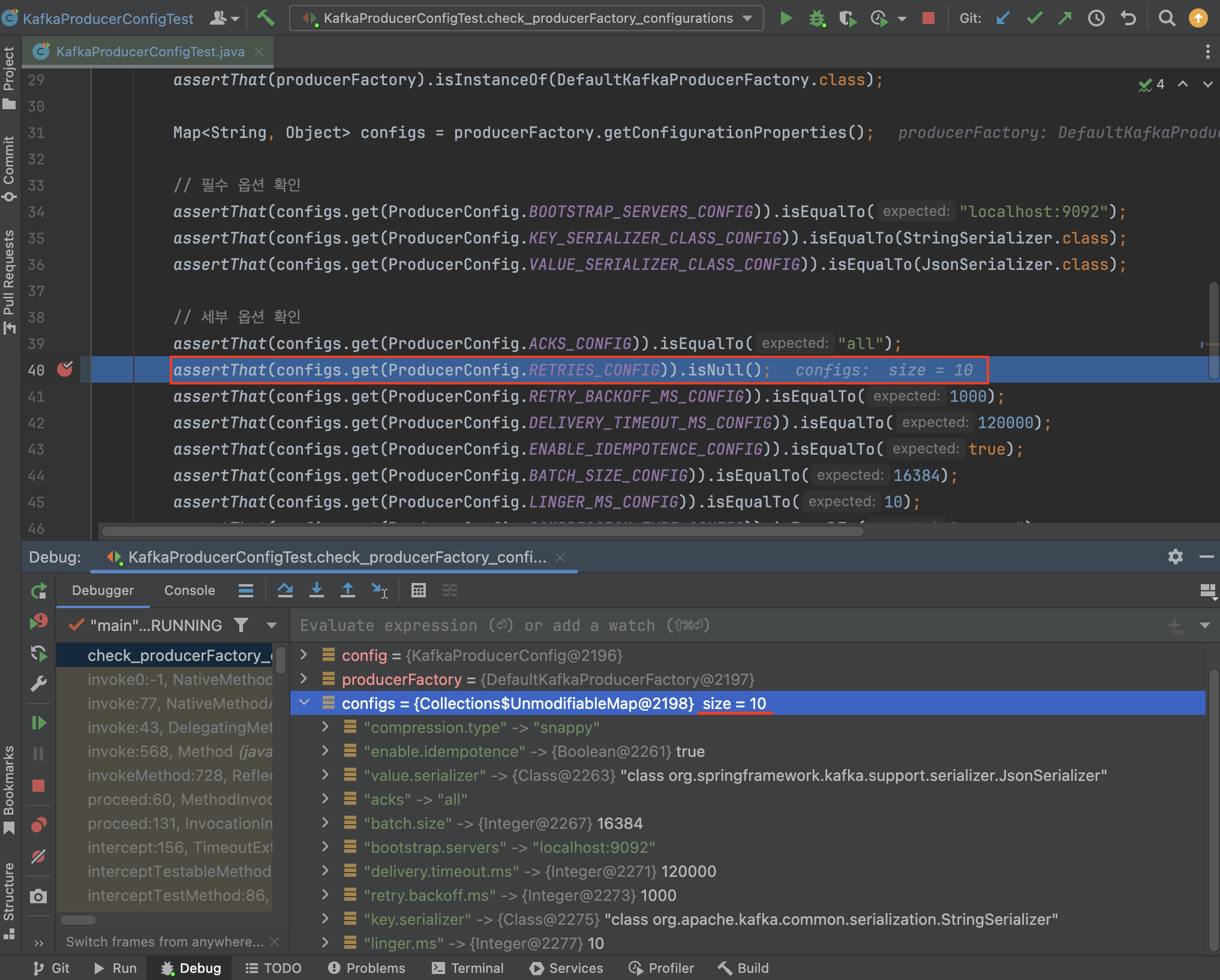
위의 테스트 실행 결과를 보면, RETRIES_CONFIG 키가 존재하지 않아 configs 맵의 전체 크기가 10개로 확인된다.
이처럼 설정과 테스트를 함께 뜯어보는 과정을 통해, 프로듀서의 동작 원리를 좀 더 깊이 이해하고 코드의 의도를 명확히 다듬어볼 수 있었다.
아직 완벽하게 이해할 수 있다고 보기는 어렵지만 차근차근 개념과 실무 경험을 쌓아가보자.