Prologue
실무에서 GPU를 사용하면서 관련 명령어인 nvidia-smi 에 대해 공식문서를 바탕으로 정리하고자 이 글을 작성하게 되었다.
nvidia-smi 는 NVIDIA System Management Interface의 약자로, NVIDIA GPU의 상태를 모니터링하고 관리하는 데 사용되는 명령어이다.
딥러닝 등 GPU를 사용하는 환경에서는 필수적인 도구 중 하나이다.
nvidia-smi 개념 및 출력 정보
터미널에 nvidia-smi 를 입력하면 현재 시스템에 설치된 모든 NVIDIA GPU의 상태 요약 정보를 볼 수 있다.
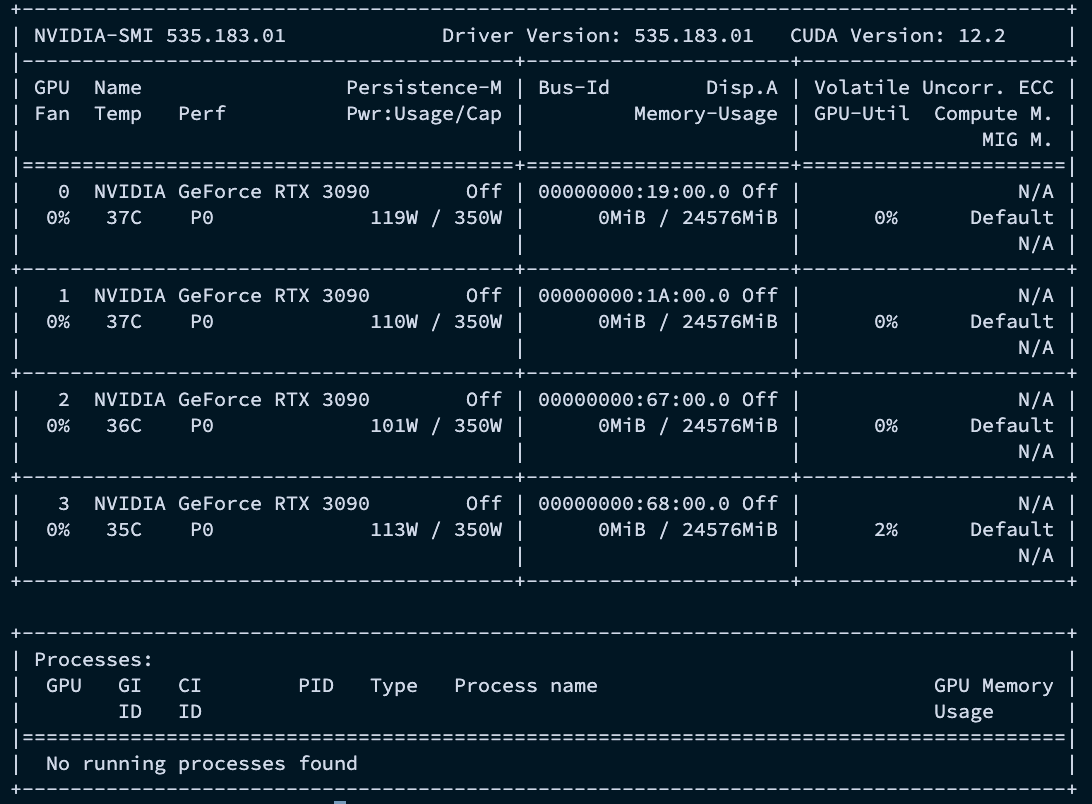
각 항목의 의미는 다음과 같다.
Driver Version: 설치된 NVIDIA 드라이버 버전CUDA Version: 설치된 CUDA 버전GPU: GPU의 인덱스 (0부터 시작)Fan: 팬 속도 (%)Name: GPU 모델명Temp: GPU 온도 (섭씨)Perf: 성능 상태 (Performance State). P0(최고 성능)부터 P8(최저 성능, 유휴 상태)까지 있다.Pwr:Usage/Cap: 현재 소비 전력 / 설정된 최대 전력 용량 (W)Memory-Usage: 사용 중인 GPU 메모리 / 전체 GPU 메모리GPU-Util: GPU 사용률 (%)Compute M.: 컴퓨트 모드 (Default, Exclusive_Process 등)Processes: 현재 GPU를 사용하고 있는 프로세스 목록
주요 명령어 옵션
보다 자세한 내용은 공식문서 를 참고하자.
nvidia-smi는 다양한 옵션을 통해 원하는 정보만 보거나 GPU 설정을 변경할 수 있다.
목록 및 기본 옵션
-L또는--list-gpus- 시스템에 설치된 모든 GPU의 목록과 각 GPU의 고유 식별자(UUID)를 간단히 보여준다.
- 명령어: nvidia-smi -L
-h또는--help- 사용 가능한 모든 명령어와 옵션에 대한 도움말을 보여준다.
쿼리(조회) 옵션
-q또는--query- 모든 GPU의 상세 정보를 출력한다.
- 기본
nvidia-smi명령어보다 훨씬 자세한 정보를 보여준다.
-i, --id=ID- 특정 GPU를 지정하여 정보를 조회한다. ID는 GPU 인덱스(0, 1, …), UUID, PCI 버스 ID 등으로 지정할 수 있다.
- 명령어: nvidia-smi -q -i 0 // 0번 GPU의 상세 정보 조회
-l SEC,--loop=SEC- 지정한 시간(초) 간격으로 정보를 계속해서 업데이트하며 보여준다.
Ctrl+C를 누르면 종료된다.watch명령어와 유사한 기능 - 명령어: nvidia-smi -l 2 -i 0 // 2초마다 0번 GPU의 상태를 갱신
- 지정한 시간(초) 간격으로 정보를 계속해서 업데이트하며 보여준다.
장치 변경 옵션
대부분의 옵션은 root 권한(sudo)이 필요하며, 시스템에 직접적인 영향을 줄 수 있으므로 신중하게 사용해야 한다.
pm, --persistence-mode=MODE- Persistence Mode(지속성 모드)를 설정합니다.
1또는Enabled로 설정하면 GPU를 사용하는 프로세스가 없어도 드라이버를 메모리에 계속 상주시켜, CUDA 애플리케이션 실행 시 드라이버 로딩 시간을 단축한다. - 명령어:
sudo nvidia-smi -pm 1// 모든 GPU에 지속성 모드 활성화
- Persistence Mode(지속성 모드)를 설정합니다.
pl, --power-limit=POWER_LIMIT- GPU의 최대 소비 전력(Power Limit)을 와트(W) 단위로 설정한다. GPU의 발열이나 전력 소모를 제어해야 할 때 유용하다.
- 명령어:
sudo nvidia-smi -i 0 -pl 300// 0번 GPU의 최대 전력을 300W로 제한
실제 예시
실시간 GPU 상태 모니터링
nvidia-smi는 특정 시점의 GPU 상태를 보여주기 때문에, 시간에 따른 변화를 관찰하려면 주기적으로 명령어를 실행해야 한다.
이때 리눅스의 watch 명령어를 사용하면 된다.
watch는 뒤따르는 명령어를 지정한 시간 간격으로 반복 실행하여 결과를 계속 갱신해주는 도구이다.
watch -d -n 1 nvidia-smi
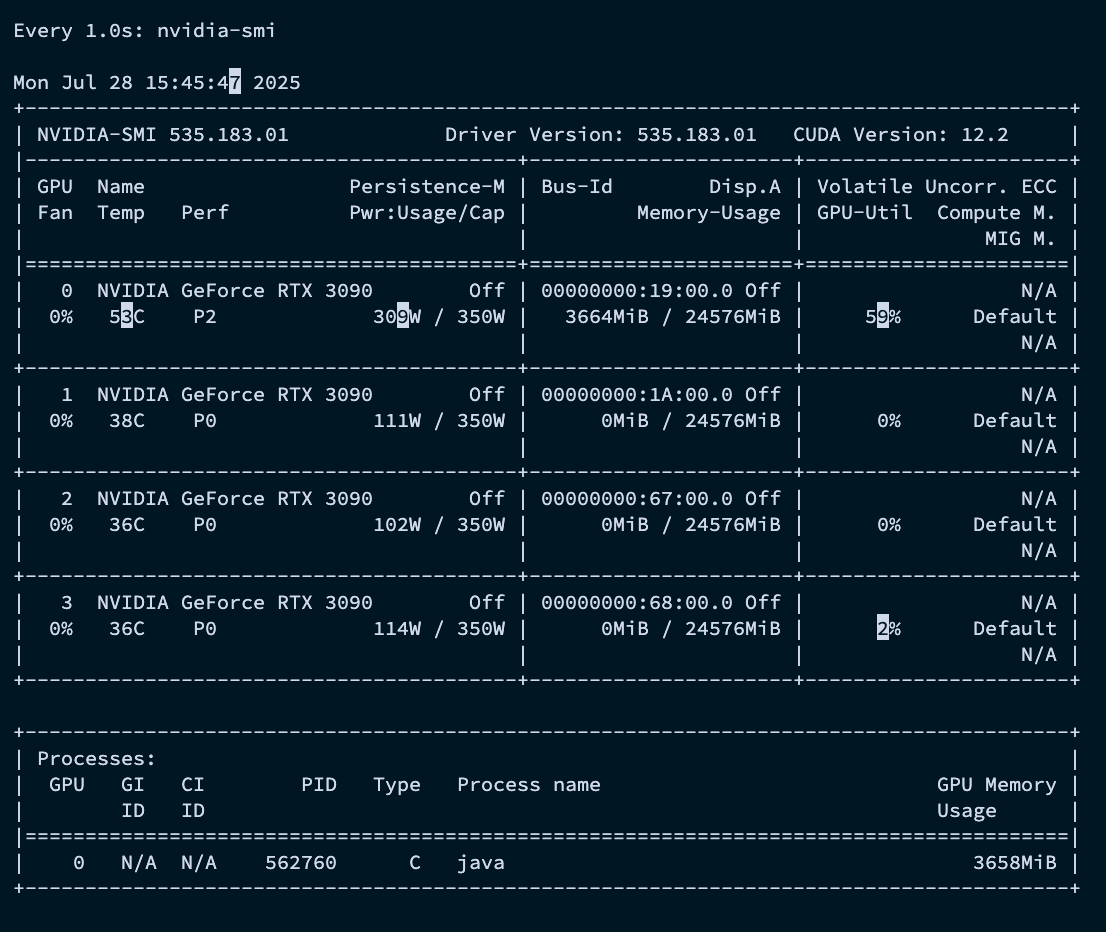
watch: 명령어를 주기적으로 실행한다.-n 1: 1초 간격으로 실행한다.-d: 이전 실행 결과와 달라진 부분을 하이라이트로 표시해준다.
주로 모델 학습이나 성능 테스트 중 GPU가 의도대로 잘 동작하는지 확인할 때 유용하다.
특정 GPU의 메모리, 사용률, 온도 확인
nvidia-smi -q -i 0 -d MEMORY,UTILIZATION,TEMPERATURE -l 10
-
0번 GPU 에 대해 원하는 핵심 지표들만 10초마다 모니터링한다. (아래는 주요 값만 정리했다)
-
메모리 (FB Memory Usage): GPU 메모리(VRAM)는 딥러닝 모델, 학습 데이터 등 실제 작업에 필요한 모든 것을 올려두는 작업 공간이다. 이 수치를 통해 메모리가 부족하지는 않은지 확인할 수 있다.
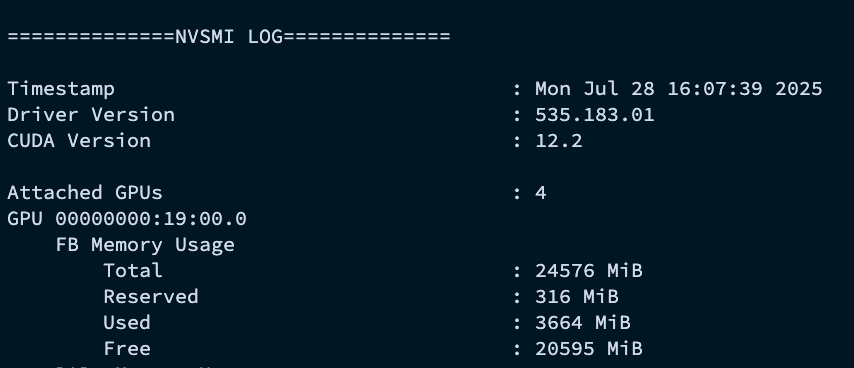
-
Total: GPU의 전체 메모리 용량이다. -
Used: 현재 애플리케이션이 사용 중인 메모리 양이다. 이 수치가Total에 가까워지면 ‘Out of Memory’ 에러가 발생할 수 있다. -
Free: 앞으로 더 사용할 수 있는 남은 메모리 양이다.
-
-
사용률 (Utilization): GPU의 각 부분이 얼마나 활발하게 일하고 있는지를 나타낸다. GPU가 일을 제대로 하고 있는지, 아니면 병목 현상이 있는지 파악하는 핵심 지표이다.

-
Gpu: GPU의 핵심 연산 장치(코어)가 실제로 계산 작업을 처리하는 비율이다. -
Memory: GPU 메모리 컨트롤러의 사용률이다. 데이터를 메모리에서 읽고 쓰는 작업이 얼마나 활발한지를 보여준다.
-
-
온도 (Temperature)
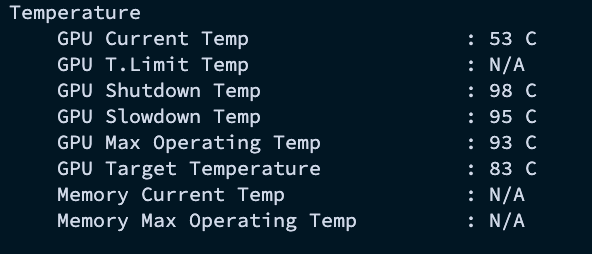
-
GPU: GPU 칩의 현재 온도이다. 일반적으로 유휴 상태에서는 30~50°C, 작업 시에는 70~85°C 사이를 유지한다. 90°C를 넘어가면 성능 저하(Throttling)가 발생하거나 하드웨어 수명에 영향을 줄 수 있다. -
GPU Shutdown Temp: GPU가 과열로 인한 손상을 막기 위해 자동으로 꺼지는 온도 -
GPU Slowdown Temp: GPU가 성능을 스스로 낮추기 시작하는 온도
-
-
GPU를 사용하는 프로세스 ID(PID)와 메모리 사용량 확인
nvidia-smi --query-compute-apps=pid,used_memory --format=csv
## 결과
pid, used_gpu_memory [MiB]
562760, 3658 MiB
- 현재 GPU에서 실행 중인 프로세스의 PID와 메모리 사용량을 CSV 형식으로 출력하여 다른 스크립트에서 활용하기 좋다.
Review
지금까지 nvidia-smi 명령어의 기본적인 개념과 실무에서 유용한 활용 예시를 살펴보았다.
이 외에 다른 명령어 옵션들에 대해서는 아래 공식문서와 다른 사이트를 참고하자.