이 글은 MySQL 기반의 SELECT, JOIN 문제에 대한 정리를 바탕으로 작성했습니다.
해당 문제는 sakila DB를 기반으로 풀었습니다.
-
설치 과정에 대한 내용은 Installation이며,
-
sakila DB를 다운받는 위치는 Other MySQL Documentation 안에 Example Databases -
sakila database(ZIP)다운받으면 됩니다.
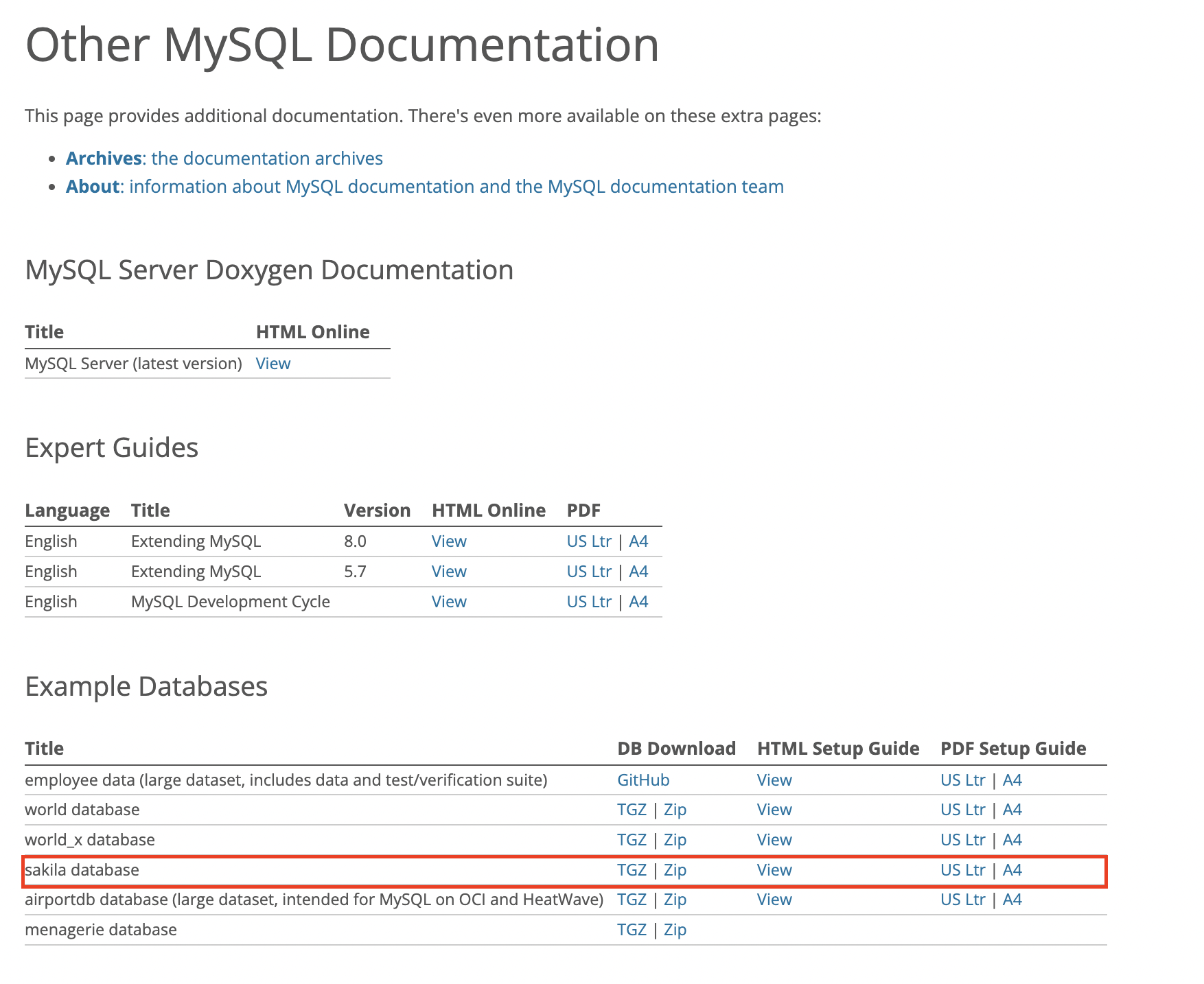
-
위의 sakila DB 다운받은 후에
MySQL Workbench를 실행한 다음, 해당 파일(4.exercise)에서 문제를 풀었습니다. -
문제를 풀기 전에
sakila DB를 사용하는 명령어를 입력한다.
use sakila;
SELECT Example
Q1. actor 테이블에서 전체 컬럼(열) 조회 -> 실행 결과 행의 수는 총 200개
SELECT * FROM actor LIMIT 200;
Q2. actor 테이블에서 first_name, last_name 컬럼 조회 -> 실행 결과 행의 수는 총 200개
SELECT first_name, last_name FROM actor LIMIT 200;
Q3. actor 테이블에서 first_name과 last_name을 하나로 연결(concat)하여 Actor Name이라는 컬럼명으로 조회하고, 전부 대문자로 조회 -> 실행 결과 행의 수는 총 200개
SELECT concat(first_name, '+' ,last_name) AS Actor_Name FROM actor;
Q4. actor 테이블에서 actor_id, first_name, last_name을 조회하되, first_name이 Joe인 데이터만 필터링하여 조회 -> 실행 결과 행의 수는 1개
SELECT actor_id, first_name, last_name
FROM actor
WHERE first_name = 'Joe';
Q5. actor 테이블에서 actor_id, first_name, last_name을 조회하되, last_name 에 Gen이 포함된 actor를 필터링하여 조회 (last_name의 맨 앞, 맨 뒤, 중간 등 어느 부분에 포함되어도 상관없이 전체 조회) -> 실행 결과 행의 수는 총 4개
SELECT actor_id, first_name, last_name
FROM actor
WHERE last_name LIKE '%Gen%';
Q6. actor 테이블에서 actor_id, first_name, last_name을 조회하되, last_name에 LI(엘, 아이)가 포함된 데이터를 필터링하고, last_name, first_name 순서로 오름차순 정렬하여 조회 -> 실행 결과 행의 수는 총 10개
SELECT actor_id, first_name, last_name
FROM actor
WHERE last_name LIKE '%LI%'
ORDER BY last_name, first_name ASC;
Q7. country 테이블에서 country_id, country 열을 조회하되,
IN 연산자를 활용하여 country가 Afghanistan, Bangladesh, China 중에 속하는 데이터만 필터링하여 조회 -> 실행 결과 행의 수는 총 3개
SELECT country_id, country
FROM country
WHERE country IN('Afghanistan', 'Bangladesh', 'China');
Q8. actor 테이블에서 서로 동일한 last_name을 사용하는 배우(actor)들이 각각 몇 명인지 조회하고 싶을 때, actor 테이블에서 last_name 컬럼과 해당 last_name을 사용하는 사람의 인원 수를 집계해주는 컬럼을 조회 ex) 아래의 이미지를 참고하면, last_name으로 ALLEN을 사용하는 배우(actor)는 총 3명(2번째 행) https://guguttemy.speedgabia.com/DB/dml_practice8.png -> 8번 문제 실행 결과 행의 수는 총 121개
SELECT last_name, count(last_name)
FROM actor
GROUP BY last_name;
Q9. actor 테이블에서 last_name 컬럼과 해당 last_name을 사용하는 수를 집계해주는 컬럼을 조회하되, 집계되는 컬럼의 별칭은
Count of Last Name이라고 짓고, last_name 카운트가 2 초과인 그룹만 필터링하여 조회 -> 실행 결과 행의 수는 총 20개
SELECT last_name, count(last_name) AS "Count of Last Name"
FROM actor
GROUP BY last_name
HAVING count(last_name) > 2;
JOIN Example
Q10. address 테이블의 정보(description) 조회
SELECT * FROM address;
Q11. address 테이블의 총 행 수 조회 -> 실행 결과 행의 수는 총 603개
SELECT count(*) FROM address;
Q12. address 테이블의 가상 상위 데이터 5개만 제한(LIMIT)하여 조회 -> 실행 결과 행의 수는 총 5개
SELECT * FROM address ORDER BY address_id LIMIT 5;
Q13. staff 테이블의 별칭을 s, address 테이블의 별칭을 a로 짓고, 두 테이블을 연결(JOIN)하여 address_id가 일치하는 first_name, last_name, address를 조회 -> 실행 결과 행의 수는 총 2개
SELECT first_name, last_name, address
FROM staff c JOIN address a
WHERE c.address_id = a.address_id;
Q14. staff 테이블의 별칭을 s, payment 테이블의 별칭을 p로 짓고, 두 테이블을 연결(JOIN)하여 staff_id가 일치하는 조건의 staff_id, first_name, last_name 및 amount의 총 금액(sum) 컬럼을 조회하되 payment_date가 2005-08-01 00:00:00 이후이고, 2005-08-02 00:00:00 ‘미만’인 데이터만 필터링하여 staff_id를 기준으로 묶어서(grouping) 조회** -> 실행 결과 행의 수는 총 2개
SELECT s.staff_id, first_name, last_name, sum(amount)
FROM staff s JOIN payment p ON s.staff_id = p.staff_id
WHERE p.payment_date BETWEEN '2005-08-01 00:00:00' AND '2005-08-02 00:00:00'
GROUP BY staff_id;
Q15. film 테이블의 별칭을 f, film_actor 테이블의 별칭을 fa로 짓고, 두 테이블을 연결(JOIN)하여 각 film_id가 일치하는 조건의 title 및 해당 film에 참여한 총 actor의 수를 의미하는 컬럼 ‘총 배우 수’ 컬럼을 film 테이블의 title 별로(grouping) 조회 (단, 이대로 조회하면 결과 데이터가 총 997행이기 때문에 상위 20개의 행만 제한하여 조회) -> 실행 결과 행의 수는 총 20개(로 제한, LIMIT 사용)
SELECT title, actor
FROM film f JOIN film_actor fa
WHERE f.film_id = fa.film_id
LIMIT 20;
Q16. inventory 테이블의 정보(description) 조회
SELECT * FROM inventory;
Q17. inventory 테이블의 데이터 상위 10개 조회 ->실행 결과 행의 수는 총 10개
SELECT * FROM inventory LIMIT 10;
Q18. film 테이블에서 title, description 컬럼을 조회하되, 상위 20개만 조회 -> 실행 결과 행의 수는 총 20개
SELECT title, description
FROM film LIMIT 20;
Q19. ALABAMA DEVIL film이 모든 영화 대여점에 총 몇 개의 복제본(영화 필름)이 배포되어있는지 알고 싶을 때, film 테이블의 별칭을 f, inventory 테이블의 별칭을 i로 짓고, 두 테이블을 연결(JOIN)하여 film_id 컬럼이 일치하는 조건의 title 및 film_id의 총 개수(count)를 ‘복제본’으로 별칭을 작성하여 title 별로 조회하되, title이 ‘ALABAMA DEVIL’인 film만 조회 -> 실행 결과 행의 수는 1개
LECT title, count(f.film_id) AS '복제본'
FROM film f JOIN inventory i
WHERE f.film_id = i.film_id AND title = 'ALABAMA DEVIL';
Q20. 고객 별 총 사용 금액을 last_name을 오름차순 정렬하여 조회하고 싶을 때, customer 테이블의 별칭을 c, payment 테이블의 별칭을 p로 짓고, 두 테이블을 customer_id컬럼으로 연결(JOIN)하여 first_name, last_name, amount의 총 액수를 조회하되, first_name, last_name 순으로 묶어서(grouping) last_name을 기준으로 오름차순하여 조회 -> 실행 결과 행의 수는 599개
SELECT first_name, last_name, sum(amount)
FROM customer c JOIN payment p
GROUP BY first_name, last_name
ORDER BY last_name ASC;