- 로드밸런싱(Load Balancing)
- 로드밸런싱이 필요한 이유
- 로드밸런싱 알고리즘
- 로드밸런싱의 주요 기능
- 로드밸런싱의 종류
- 로드밸런싱 장애 대비
- DNS 활용(대용량 세션을 위한 로드밸런서)
- 클러스터링(Clustering)
- 로드밸런싱과 클러스터링의 차이
- 예상 질문
- Reference
로드밸런싱(Load Balancing)
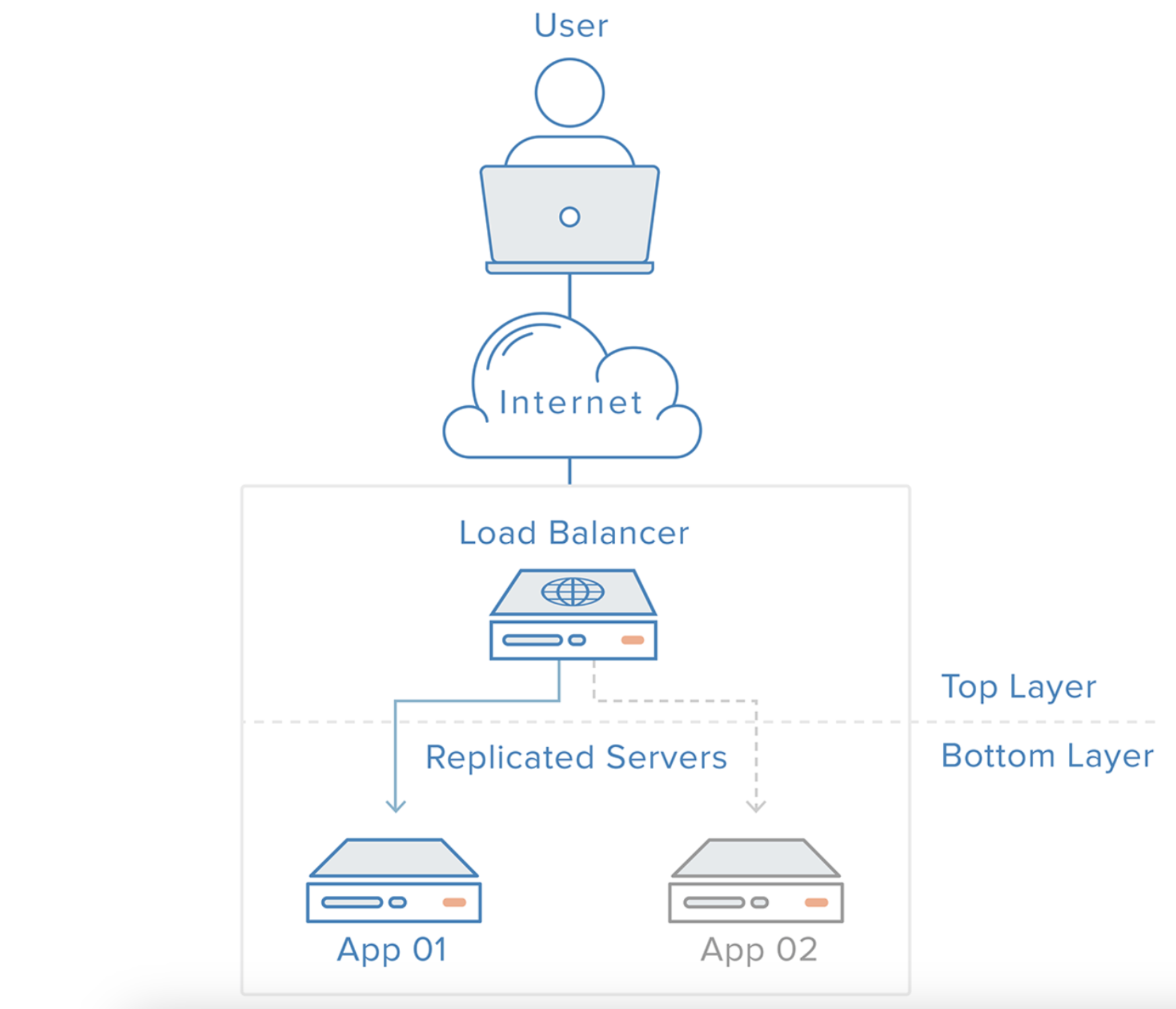
로드밸런싱은 서버에 가해지는 부하(=로드)를 분산(=밸런싱)해주는 장치 또는 기술을 말한다.
-
클라이언트와 서버풀 사이에 위치하며, 한 대의 서버로 부하가 집중되지 않도록 트래픽을 관리해 각각의 서버가 최적의 퍼포먼스를 보일 수 있도록 한다.
-
로드밸런싱을 해주는 소프트웨어 혹은 하드웨어 장비를 로드밸런서라고 한다.
-
로드밸런서는 VIP(Virtual IP)와 함께 구성된다.
VIP란 로드밸런싱의 대상이 되는 여러 서버들을 대표하는 가상의 IP이다. 클라이언트들을 서버에게 IP로 직접 요청 하는 것이 아니라 로드밸런서가 가지고 있는 VIP를 대상으로 요청을 한다. 그리고 로드밸런서는 설정된 부하 분산 방법에 따라 각 서버로 요청을 분산시키는 것이다.
-
로드밸런싱의 주 목적은 서버 자원 사용의 최적화, 데이터 처리량의 증가, 클라이언트와 서버 간의 응답속도 감소, 특정 서버의 과부화 방지, 안정성 및 가용성 극대화 등을 고려하여 적절히 분산처리하여 해주는 서비스이다.
로드밸런싱이 필요한 이유
-
로드밸런싱은 여러 대의 서버를 두고 서비스를 제공하는 분산 처리 시스템에서 필요한 기술이다.
-
사업의 규모가 확장되고, 클라이언트의 수가 기하 급수적으로 늘어나면서, 그에 따라 증가된 트래픽을 대처하려면 어떻게 해야할까?
Scale-up 과 Scale-out
-
Scale-up은 서버 자체의 성능을 확장하는 것을 의미한다. 서버에 CPU 또는 RAM을 추가하거나, 고성능의 부품을 교체할 때 쓰는 방법이다.- 모든 부하가 서버 한 대에 집중하기 때문에 장애시 위험하고, 데이터 역시 한 곳에서 처리하므로 데이터 갱신이 빈번하게 일어나는
데이터베이스 서버에 적합하다.
- 모든 부하가 서버 한 대에 집중하기 때문에 장애시 위험하고, 데이터 역시 한 곳에서 처리하므로 데이터 갱신이 빈번하게 일어나는
-
Scale-out은 서버를 여러 대 추가하여 시스템을 확장하는 방법이다.- 서버가 여러대가 되므로 로드밸런싱이 필수이며, 다중화를 통해 서버에서 장애가 났을 경우에도 다른 서버에서 대응이 가능하다. 하지만 모든 서버가 동일한 데이터를 가져야 하므로 데이터 변화가 적은
웹 서버에 적합하다.
- 서버가 여러대가 되므로 로드밸런싱이 필수이며, 다중화를 통해 서버에서 장애가 났을 경우에도 다른 서버에서 대응이 가능하다. 하지만 모든 서버가 동일한 데이터를 가져야 하므로 데이터 변화가 적은
-
Scale-out 장점
-
하드웨어 향상하는 비용보다 서버 한대 추가 비용이 더 적다.
-
여러 대의 Server 덕분에 무중단 서비스를 제공할 수 있다.
-
-
여러 대의 서버에게 균등하게 트래픽을 분산시켜주는 역할을 하는 것이
로드밸런서이다.
로드밸런싱 알고리즘
- 클라이언트의 요청을 특정 서버에 분배하는 로드밸런싱 기법은 여러가지 있다.
정적 부하분산(Static Load Balancing)
[1] 라운드 로빈 방식(Round Robin Method)
-
입력 받은 요청을 각각의 서버에 순차적으로 할당하는 방식이다.
-
클라이언트의 요청을 순서대로 분배하기 때문에 알고리즘이 단순하고 각 서버가 트래픽을 골고루 나눠서 처리하므로 각 서버의 처리량이 비슷한 경우에 쓰이는 기법이다.
[2] IP 해시 방식(IP Hash Method)
-
클라이언트의 IP 주소를 특정 서버로 매핑하여 요청을 처리하는 방식이다.
-
사용자의 IP를 해싱해 로드를 분배하기 때문에 클라이언트는 항상 동일한 서버로 접속하게 된다.
동적 부하분산(Dynamic Load Balancing)
[1] 가중 라운드 로빈 방식(Weighted Round Robin Method)
-
각 서버별로 가중치를 설정하고 가중치가 높은 서버에 클라이언트 요청을 우선적으로 배분하는 방식이다.
-
주로 서버의 트래픽 처리 능력이 상이한 경우 사용되는 부하 분산 방식이다.
-
예) 클라이언트의 입력이 100이고, 각 서버 A, B, C의 가중치가 2,3,5라고 가정한다면 각 서버에는 20, 30, 50의 입력이 라운드 로빈 방식으로 전달된다.
[2] 최소 연결 방식(Least Connection Method)
-
요청이 들어온 시점에 가장 적은 연결 상태를 보이는 서버에 우선적으로 트래픽을 배분하는 방식이다.
-
세션이 자주 길어지거나, 서버에 분배된 트래픽들이 일정하지 않는 경우에 사용되는 방식이다.
[3] 최소 응답 시간 방식(Least Response Time)
-
클라이언트 요청을 전달하기 전에 각 서버에 응답을 요청하고 응답 시간이 가장 짧은 서버에 클라이언트 요청을 전달하는 방식이다.
-
각 서버의 성능이 상이한 경우에 사용되는 방식이다.
로드밸런싱의 주요 기능
-
NAT(Network Address Translation) : 사설 IP 주소를 공인 IP 주소로 바꾸는 데 사용하는 통신망의 주소 변조기이다.
-
Tunneling : 인터넷상에서 눈에 보이지 않는 통로를 만들어 통신할 수 있게 하는 개념이다. 데이터를 캡슐화해서 연결된 상호 간에만 캡슐화된 패킷을 구별해 캡슐화를 해제할 수 있다.
-
DSR(Dynamic Source Routing protocol) : 로드밸런서 사용시 서버에서 클라이언트로 되돌아가는 경우 목적지 주소를 스위치의 IP 주소가 아닌 클라이언트 IP 주소로 전달해서 네트워크 스위치를 거치지 않고 바로 클라이언트를 찾아가는 개념이다.
로드밸런싱의 종류
-
L2 : Mac주소를 바탕으로 로드밸런싱을 한다.
-
L3 : IP주소를 바탕으로 로드밸런싱을 한다.
-
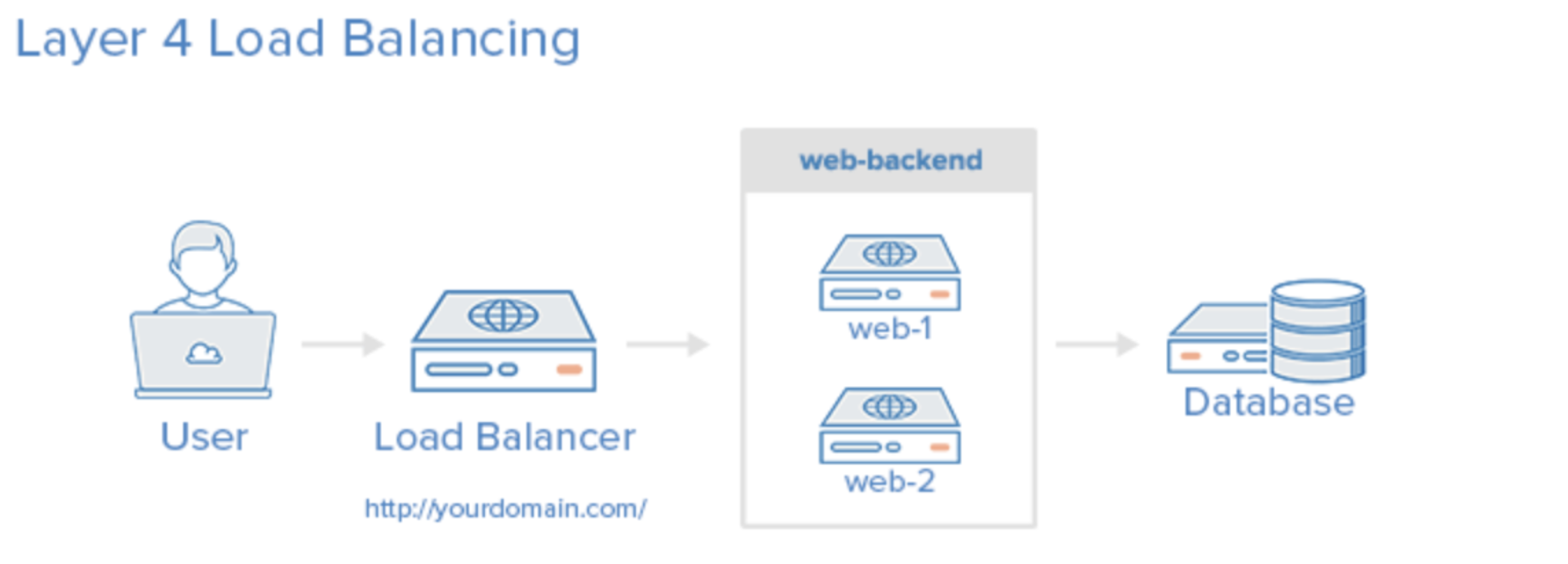
L4 : 전송계층(Transport Layer)에서 로드밸런싱을 한다. (TCP, UDP 포트 정보를 바탕으로 한다)
-
장점 : 데이터 안을 들여다보지 않고 패킷 레벨에서만 로드를 분산하기 때문에 속도가 빠르고 효율이 높다. L7 로드밸런서보다 가격이 저렴하다.
-
단점 : 패킷의 내용을 살펴볼 수 없기 때문에 섬세한 라우팅이 불가능하다. 사용자의 IP가 자주 바뀐다면 연속적인 서비스를 제공하기 어렵다.
-
-
L7 : 응용계층(Application Layer)에서 로드밸런싱을 한다. (TCP/UDP뿐만 아니라 HTTP, HTTPS, FTP의 파일명, 쿠키 정보를 바탕으로 한다)
-
장점 : 상위 계층에서 로드를 분산하기 때문에 더 섬세한 라우팅이 가능하며 캐싱 기능을 제공한다. 비정상적인 트래픽을 사전에 필터링 할 수 있어서 서비스 안정성이 높다.
-
단점 : 패킷의 내용을 복호화해야 하기에 L4 로드밸런서보다 더 높은 비용을 지불해야 한다.(가격이 더 비싸다) 그리고 클라이언트가 로드밸런서와 인증서를 공유해야하므로 해커가 로드밸런서를 통해서 클라이언트 데이터에 접근할 가능성이 있어서 보안상 위험성이 존재한다.
-
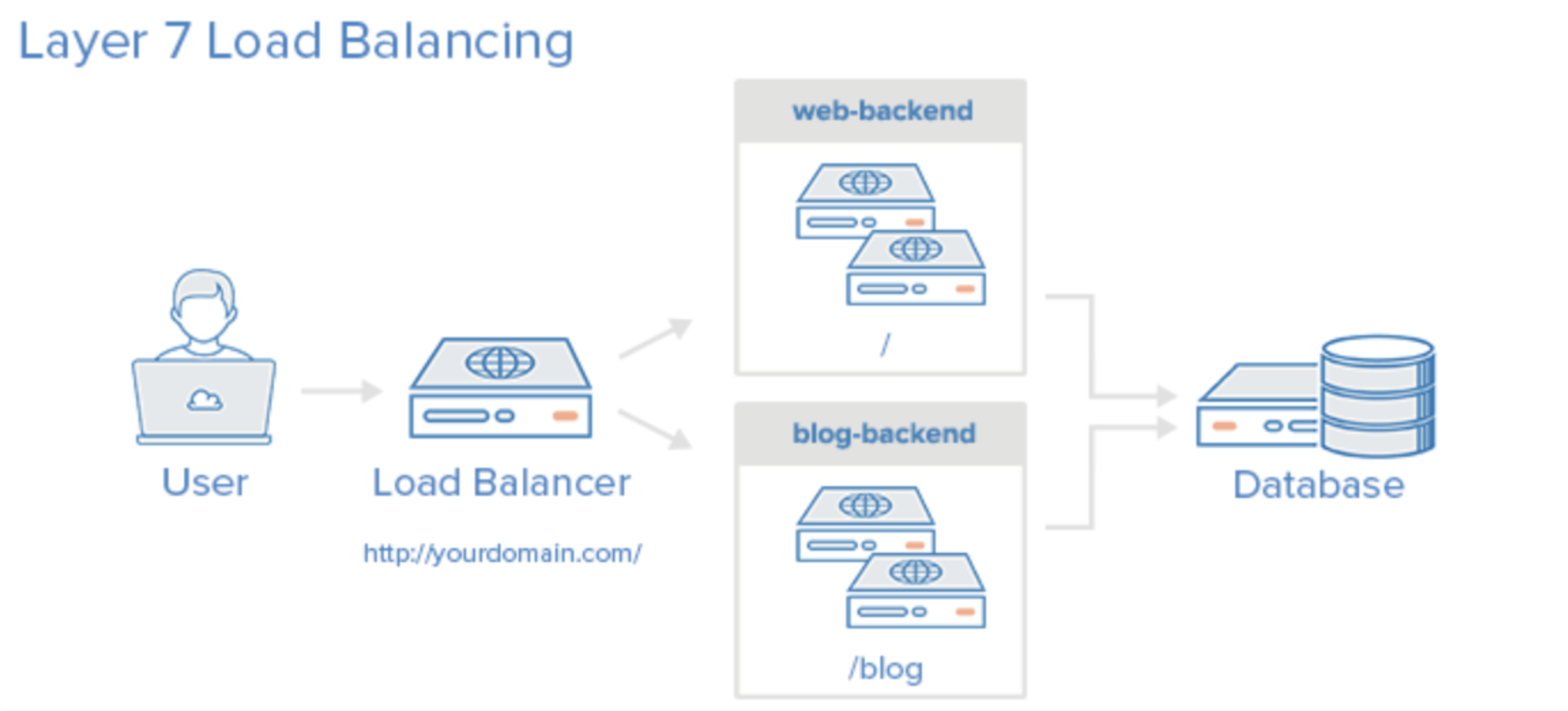
- 참고로, 4 ~ 7 계층은 하위 계층의 기능을 포함한다.
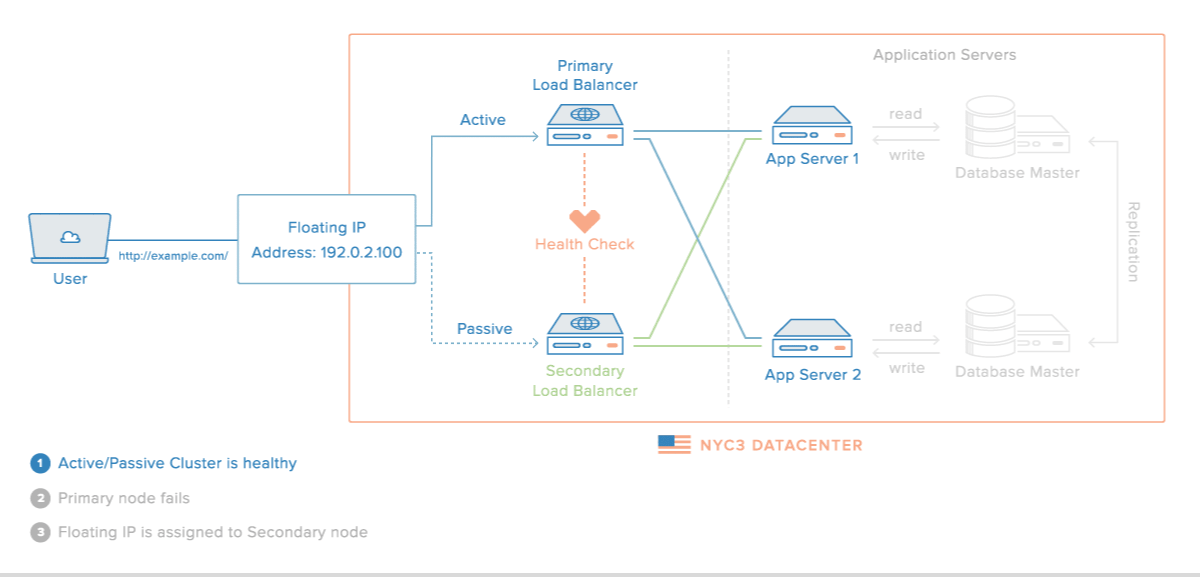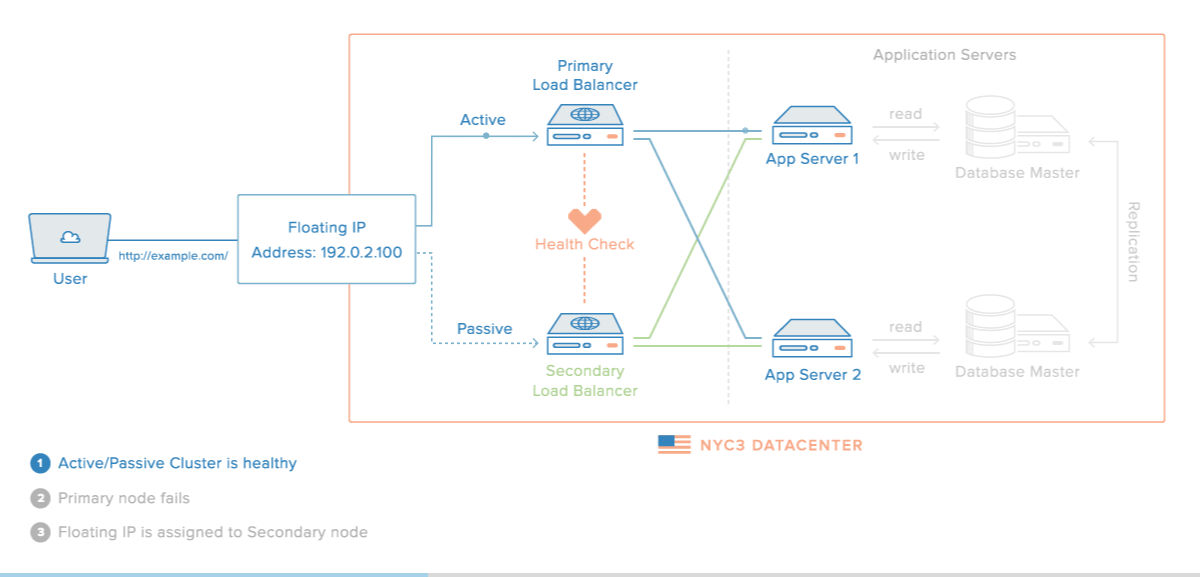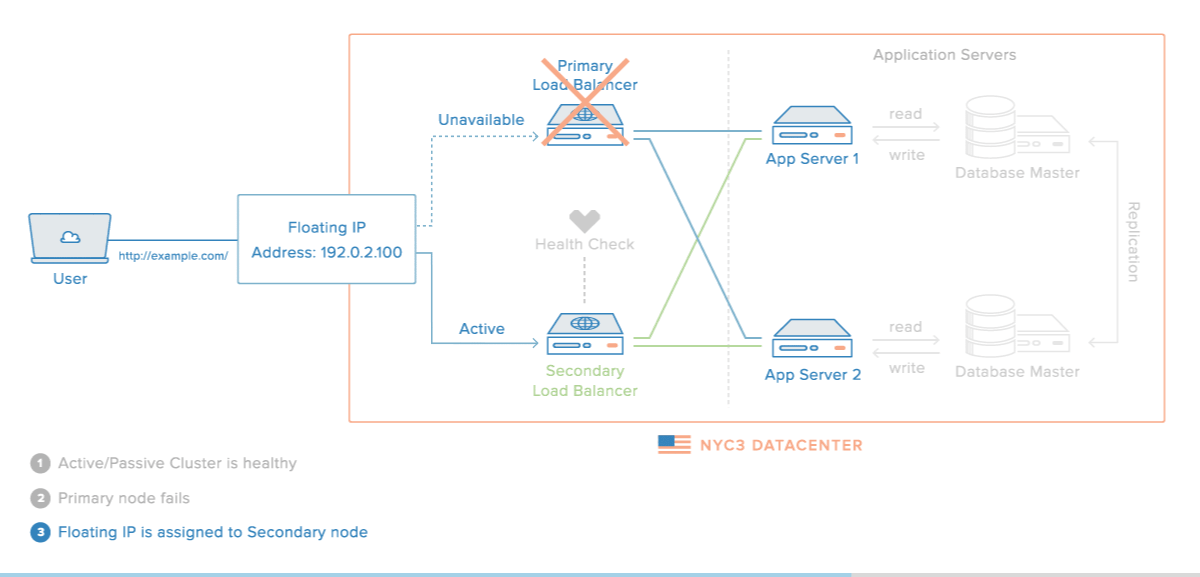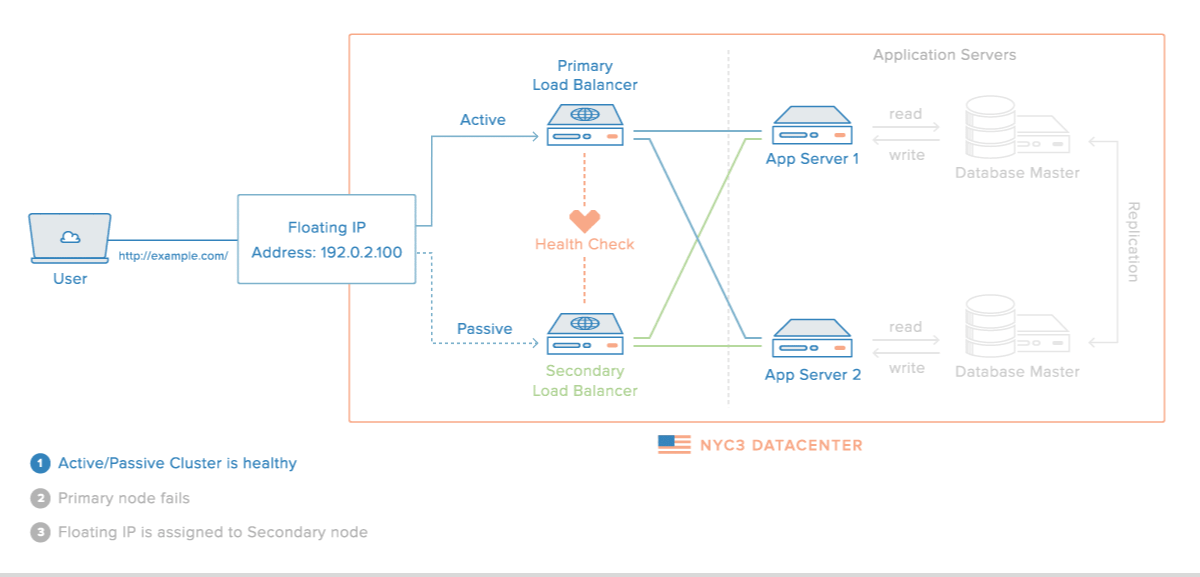
로드밸런싱 장애 대비
- 로드밸런서를 이중화하여 장애를 대비할 수 있다.
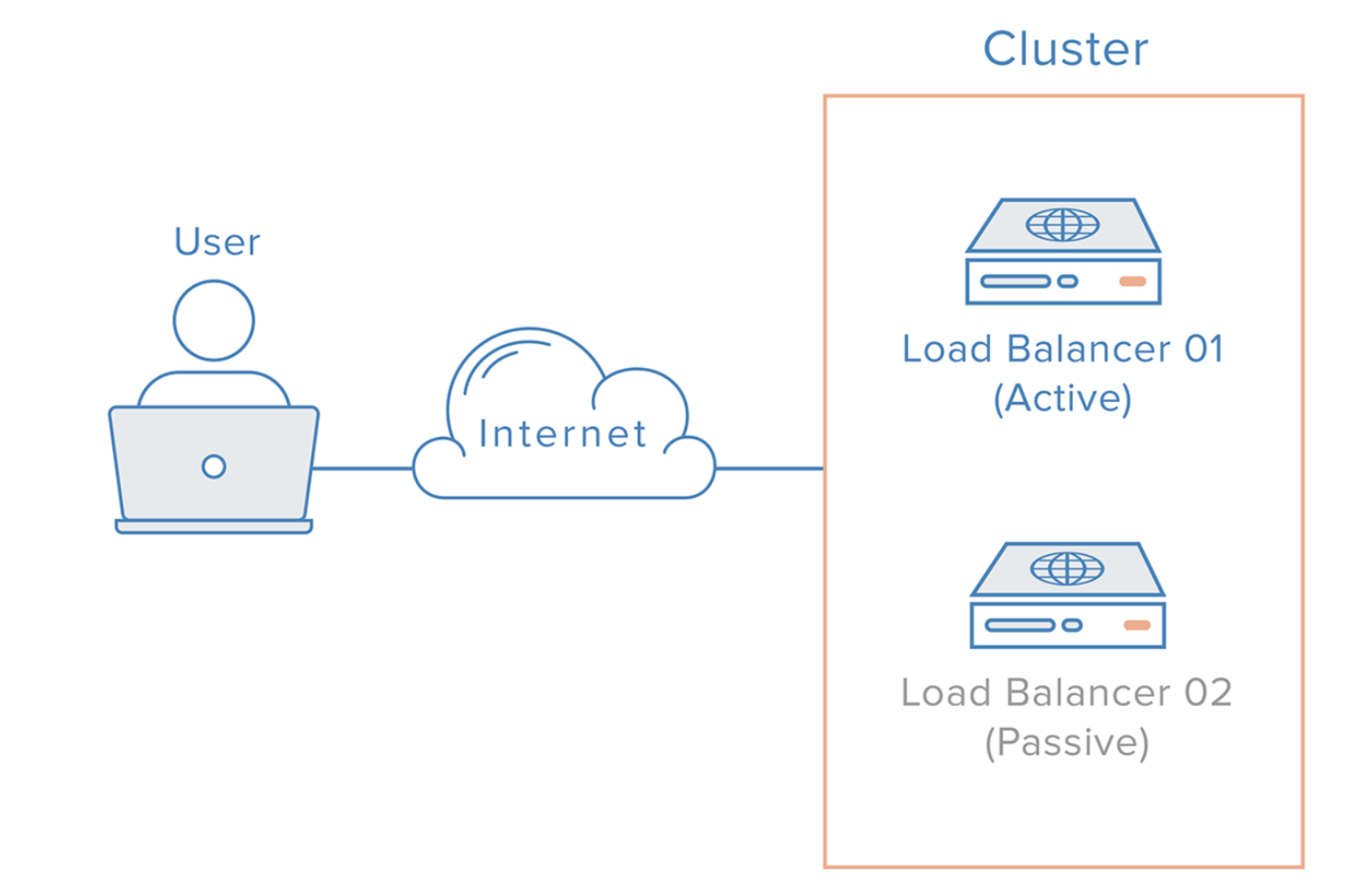
장애가 났을 경우의 시나리오
-
이중화된 로드밸런서들은 서로 Health Check를 한다.
-
메인 로드밸런서가 동작하지 않으면 가상 IP(VIP, Virtual IP)는 여분의 로드밸런서로 변경된다.
-
여분의 로드밸런서로 운영하게 된다.
DNS 활용(대용량 세션을 위한 로드밸런서)
-
DNS는 도메인 이름을 IP주소로 변환하는 기술이다.
-
대용량 서비스를 운영하려면 부하 분산은 필수다. 대용량 트래픽을 장애없이 처리하려면 여러 대의 서버에 적절한 트래픽을 분배해야 한다. 단지 몇 개의 노드만 있다면
DNS 라운드 로빈 방식이 합리적이다. 로드 밸런서 자체는 비용이 높고 불필요한 복잡함을 증가시킬 수 있기 때문이다. -
DNS에서는 하나의 도메인 이름을 라운드 로빈 방식으로 여러 개의 IP 주소로 변환한다면 이것만으로 쉽게 부하 분산이 가능하다.
-
하지만 여기에 두 가지 단점이 존재한다.
-
첫째, 대부분의 클라이언트에서는 DNS 서버의 부하를 줄이고 성능을 향상시키기 위해 일정 시간 동안 캐싱하기 때문에 부하 분산이 균등하게 되지 않는다.
-
둘째, 특정 서버에 장애가 발생하더라도 장애 여부가 감지되지 않아 서비스에서 해당 서버를 제거할 수 없다. 이것을 보안하기 위해 health check로 장애를 감지하여 DNS 서버에서 제거할 수 있지만, 모든 DNS 서버에 적용되는 데에는 상당한 시간이 소요될 뿐만 아니라 클라이언트의 캐싱 때문에 서비스에서 바로 제거되지 않는다.
-
-
그렇기 때문에 대규모 시스템에서는 상황에 따라 적절한 로드밸런싱 알고리즘과 스케줄링이 사용되고 있다.
클러스터링(Clustering)
-
클러스터은 여러 대의 컴퓨터를 똑같은 구성의 서버군을 병렬로 연결한 시스템으로 마치 하나의 컴퓨터처럼 사용하는 것을 말한다. -
클러스터링은 여러 대의 컴퓨터를 가상의 하나의 컴퓨터처럼 사용하게 해주는 것을 말한다.
-
클러스터링 환경에서는 특정 장비에 문제가 생기거나 애플리케이션에 문제가 생기더라도, 전체 서비스에는 영향을 주지 않게 제어가 가능하다.
-
클러스터링은 Virtual IP(가상 IP)기반으로 구현되는데, 서비스를 제공하는 실제 장비는 Physical IP(실제 IP)를 가지고, 데이터의 처리는 Virtual IP를 통해 처리한다. 이러허게 내부의 시스템은 철저하게 가려 추상화하는 것이 원칙이다.
로드밸런싱과 클러스터링의 차이
-
로드밸런싱은 L4 혹은 L7이 여러대의 서버에 패킷을 부하분산시켜주는 것이고,클러스터링은 여러대의 서버를 하나의 서버로 만들어주는 것이다. -
둘다 똑같이 분산을 시켜주는 것이지만,
클러스터링은 한 서비스를 제공하는 여러개의 서비스를 하나로 묶어 성능을 높여 많은 양의 패킷을 감당하는 것이고,로드밸런싱은 여러대의 서버에 분산을 시켜주는 것이다.
예상 질문
-
L4 로드밸런서와 L7 로드밸런서의 장단점에 대해 설명해 주세요.
-
로드밸런서 장치를 사용하지 않고, DNS를 활용해서 유사하게 로드밸런싱을 하는 방법에 대해 설명해 주세요.
-
로드밸런싱과 클러스터링의 차이점에 대해서 설명해 주세요.