이 글의 사진과 내용은 공룡책 과 컴퓨터학부 수업인 운영체제 강의자료를 기반으로 작성했습니다.
Multi-Level Queue
멀티-레벨 큐(MLQ)
-
MLQ란 준비 큐를 여러 개로 분할해 관리하는 스케줄링 기법을 말한다. 즉 프로세스들이 CPU를 기다리기 위해 한 줄로 서는 것이 아니라 여러 줄로 서는 것이다. -
MLQ는 일반적으로 성격이 다른 프로세스들을 별도로 관리하고, 프로세스의 성격에 맞는 스케줄링을 적용하기 위해 ready queue를 별도로 두게 된다.
-
미래를 예측하기 위해 과거를 배우는 스케줄러이다.
ML(F)Q : Basic Rules
-
ML(F)Q는 다수의 개별 queue를 유지한다.
- 각각의 queue는 다양한 우선순위 레벨을 부여받는다.
-
Rule 1: Run-time이 짧은 job에게 우선순위(priority)를 부여한다. -
Rule 2: 만약 우선순위가 같으면, 라운드 로빈 스케줄링(RR)을 사용한다.
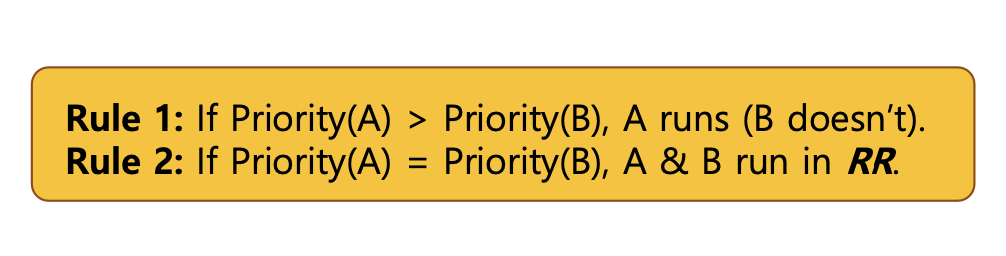
- ML(F)Q Example : Static Snapshot
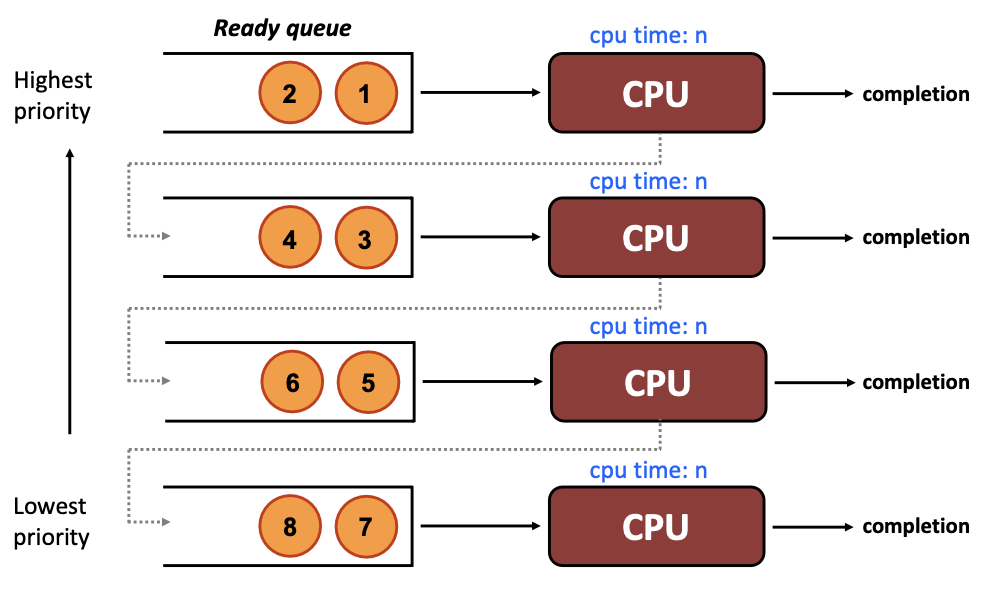
-
MLQ는 관찰된 동작에 따라 작업의 우선순위를 변경한다.
-
Example 동작 :
-
job은 I/O를 기다리는 동안 CPU를 반복적으로 양도한다.
-
대화형(interative) 프로세스의 동작은 다음과 같습니다.
-
우선순위를 높게 유지(단시간 슬라이스 포함) -> 응답 시간 향상
-
-
job이 장시간 동안 CPU를 집중적으로 사용한다.
-
일괄(batch) 작업의 동작은 다음과 같습니다.
-
우선순위 감소(긴 시간 슬라이스 포함) -> 소요 시간 단축
-
-
-
이러한 방식으로 MLQ는 프로세스가 실행될 때 프로세스에 대해 학습하고, 따라서 job의 기록을 사용하여 미래의 동작을 예측합니다.
Multi-Level Feedback Queue
멀티레벨 피드백 큐(MLFQ)
-
MLFQ는 CPU를 기다리는 프로세스를 여러 queue에 줄 세운다는 측면에서 MLQ와 동일하나, 프로세스가 하나의 queue에서 다른 queue로 이동 가능하다는 점이 다르다. -
목적
-
Turnaround time(소요 시간)을 최적화하는 것이다.
-
Response time을 최소화하는 것이다.
-
MLFQ : How to Change Priority
-
MLFQ 우선순위 조정 알고리즘:
-
Rule 3: job이 시스템에 들어오면, 가장 높은 우선순위를 둔다. -
Rule 4a: 만약 job이 실행하는 동안 time slice를 다 쓰게 되면, 그것의 우선순위를 줄이게 된다(그것은 queue에서 아래로 이동한다) -
Rule 4b: 만약 job이 time slice를 다 쓰기 전에 CPU를 양도한다면, 같은 우선순위 레벨이 유지된다.
-
-
Example 1 : 한 개의 실행 작업을 가진 작업
-
A three-queue schedular
-
우선순위가 높을수록 time slice가 작다.
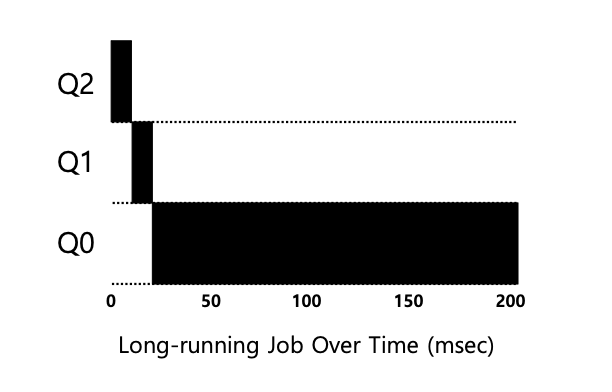
- job이 최고 우선순위인 Q2에 진입한다. 이후 time slice를 소진하면, 다음 Q1 -> Q0으로 진입하게 된다.
-
-
Example 2 : 짧은 작업과 함께
-
Job A : A long-running CPU-intensive job(180ms runtime) - 오래 실행되는 CPU 위주 작업
-
Job B : A short-running interactive job(20ms runtime) - 짧은 대화형 작업
-
A가 얼마 동안 실행되고 있다가 B가 시간 T=100에 도착한다.
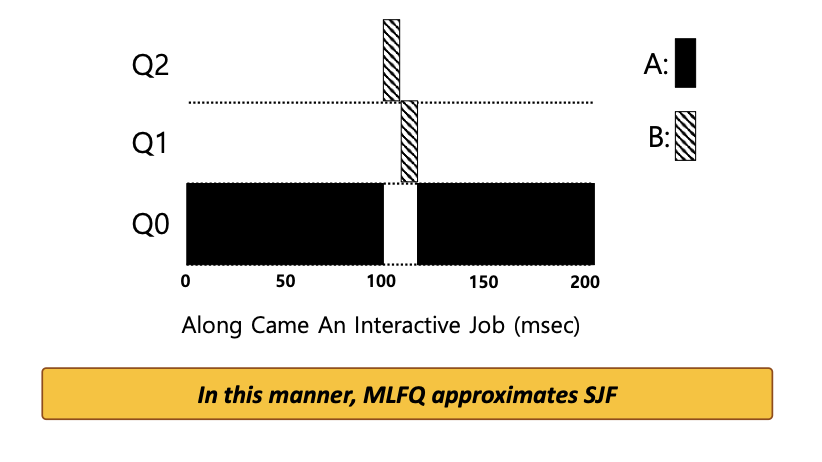
-
위 예시에서 스케줄러는 B를 먼저 선호(높은 우선순위 부여)하는 것을 볼 수 있다.
-
스케줄러는 짧은 작업이라고 가정하여 높은 우선순위를 부여한다
-
이런 경우 MLFQ는 SJF를 근사할 수 있다.
-
-
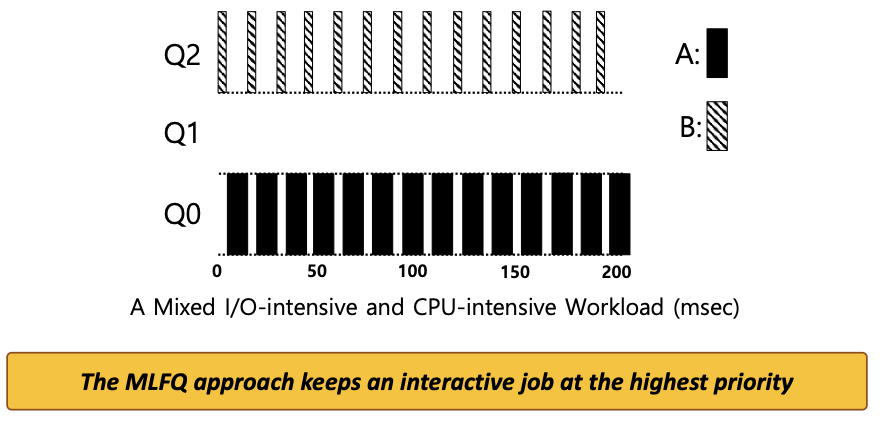
Example 3: 입출력 작업에서는 어떻게 할까?
-
Job A :
A long-running CPU-intensive job(CPU 중심 작업) -
Job B :
An interactive job(대화형 작업) that need the CPU only for 1ms before performing an I/O -
규칙 4b가 말하는 것처럼, 프로세스가 타임 슬라이스를 소진하기 전에 프로세서를 양도하면 같은 우선순위를 유지하게 된다. 즉, 대화형 작업이 키보드나 마우스로부터 사용자 입력을 대기하며 자주 입출력을 수행하면 time slice가 종료되기 전에 CPU를 양도하게 될 것이다. 그러면 동일한 우선순위를 유지하게 된다.
-
B는 입출력을 수행하기 전에 CPU를 1ms만 사용한다.
-
A는 긴 배치형 작업(CPU 중심 작업)으로서 B와 CPU를 사용하기 위해 경쟁한다.
-
B는 CPU를 계속해서 양도하기 때문에 MLFQ방식은 B를 가장 높은 우선순위로 유지한다.
-
기본적인 MLFQ의 문제점들
[1] Starvation(기아 상태)가 발생할 수 있다.
-
시스템에 너무 많은 대화형 작업이 존재하면 그들이 모든 CPU 시간을 소모하게 될 것이다.
-
따라서 긴 실행 시간 작업은 CPU 시간을 할당받지 못할 것이다.
[2] 똑똑한 사용자라면 스케줄러를 자신에게 유리하게 동작하도록 프로그램을 다시 작성할 수 있다.(malicious attack, 악의적 공격)
-
time slice가 99% 실행한 후, 의도적으로 I/O 작업을 실행한다.
-
time slice가 끝나기 전에 CPU를 양도하므로 CPU를 독점하는 기회가 생긴다.
[3] 프로그램은 시간이 지남에 따라 동작을 변경할 수 있다.
-
CPU 바운드 프로세스 -> I/O 바운드 프로세스(CPU 위주 작업 -> 대화형 작업)
-
작업이 가장 낮은 큐에 머무르게 된다.
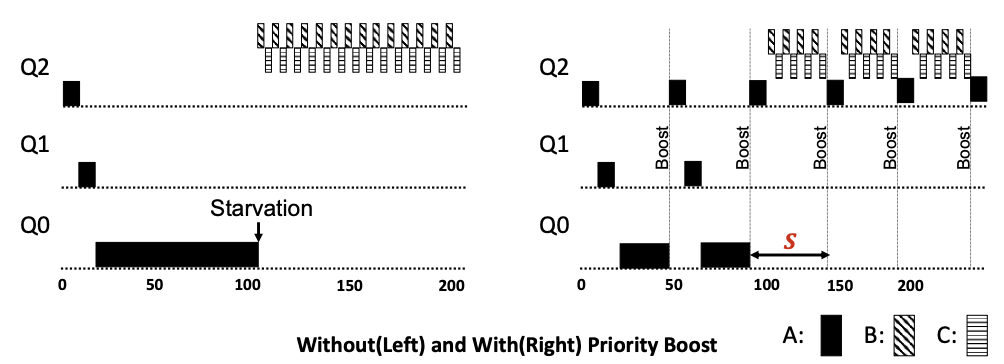
해결방안 1 : The Priority Boost
모든 작업의 우선순위를 상향 조정하는 것
-
Rule 5: 일정 시간 S가 지나면, 시스템에 있는 모든 작업들을 최상위 큐로 이동한다. -
Rule 5 규칙은 1번과 3번의 문제점을 해결한다.
-
최상위 큐에 존재하는 동안 작업은 다른 높은 우선순위 작업들과 라운드 로빈 방식으로 CPU를 공유하게 되고 서비스를 받게 된다.
-
CPU 위주의 작업이 대화형 작업으로 특성이 변할 경우 우선순위 상향을 통해 스케줄러가 변경된 특성에 적합한 스케줄링 방법을 적용한다.
-
Example :
-
A long-running job(A) with two short-running interactive job(B, C)
-
S값을 어떠한 값으로 할까? 이러한 종류의 값을
voo-doo constants(부두 상수)라고 부른다. -
S값이 너무 크면 긴 실행 시간을 가진 작업은 굶을 수 있으며, S값이 너무 작으면 대화형 작업이 적절한 양의 CPU 시간을 사용할 수 없게 된다.
-
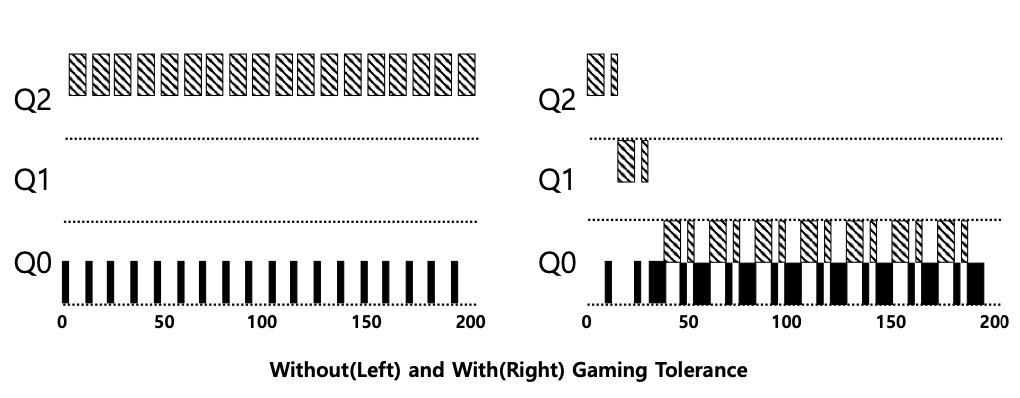
해결방안 2 : Better Accounting
MLFQ의 각 단계에서 CPU 총 사용 시간을 측정하는 것
-
스케줄러를 자신에게 유리하게 동작시키는 것을 어떻게 막을 수 있는가(CPU 독점)
-
해결 방안
-
해결책은 MLFQ의 각 단계에서 CPU 총 사용 시간을 측정하는 것이다. 스케줄러는 현재 단계에서 프로세스가 소진한 CPU 사용 시간을 저장한다. 프로세스가 타임 슬라이스에 해당하는 시간을 모두 소진하면 다음 우선순위 큐로 강등된다. 타임 슬라이스를 한 번에 소진하든 짧게 여러 번 소진하든 상관 없다.
-
- Rule 4(Rule 4a와 Rule 4b를 합쳐 규칙을 재정의)
- 주어진 단계에서 시간 할당량(time allotment)을 소진하면 (CPU를 몇 번 양도하였는지 상관없이), 우선순위는 낮아진다. (아래 단계의 큐로 이동한다.)
-