성능 개념을 공부하게 된 이유
성능이라는 개념을 공부하기 전에, 왜 이 개념과 관련 도구들이 필요하게 되었는지 궁금했다.
나는 아직 사용자 1000만 명 이상의 대규모 서비스를 개발한 경험이 없지만, 지금까지의 경험을 바탕으로 생각해보면 다음과 같다.
-
서비스 사용자가 증가할수록 트래픽 양도 함께 늘어나며, 서버가 이를 감당할 수 있는지 성능 테스트를 통해 확인하고 그에 맞게 대응하고 보완해야 한다.
-
성능 테스트는 다양한 상황에서 시스템의 안정성과 효율성을 확인하는 데 중요한 역할을 한다. 내가 생각하는 성능 테스트의 활용 사례는 다음과 같다:
-
서비스를 출시하기 전, 예상되는 트래픽의 양을 서버가 감당할 수 있는지 성능 테스트로 파악한다. 일반적으로 예상 사용자 수의 3배로 부하 테스트를 수행해 예기치 않은 트래픽 급증에도 대비할 수 있도록 한다.
-
기존 서비스를 운영하면서 선착순 이벤트 등으로 갑자기 트래픽이 몰릴 때 발생하는 병목 지점을 성능 테스트(예: 스파이크 테스트)를 통해 식별한다.
-
멀티스레드 환경에서 비즈니스 로직을 비동기 방식으로 처리할 때, 논블로킹 방식 등을 고려하여 성능을 개선하기 위해 응답 속도와 TPS(초당 트랜잭션 수)를 성능 테스트로 측정한다.
-
-
아래는 최근 내가 공부한 성능 개념과 주요 병목 지점, 그리고 성능 테스트에 대한 내용을 정리한 내용이다.
1. 성능 최적화
1.1 성능이란 무엇인가?
성능은 시스템이나 애플리케이션이 주어진 자원 내에서 작업을 얼마나 효율적으로 처리하는지를 측정하는 개념이다. 이는 사용자 만족도와 서비스 품질에 직접적인 영향을 미치며, 성능이 높을수록 짧은 응답 시간과 높은 처리량을 제공해 자원을 효율적으로 사용하는 것이 목표이다.
1.2 성능 지표와 분석
성능을 측정하고 분석하기 위해 다양한 지표가 사용되는데, 대표적인 성능 지표는 다음과 같다.
- Response Time (응답 시간): 사용자가 요청을 보낸 순간부터 시스템이 응답을 반환하는 데 걸리는 시간이다. 응답 시간이 짧을수록 사용자 경험이 향상된다.
- Latency (지연 시간): 네트워크나 시스템에서 데이터가 전송되는 데 걸리는 시간이다. 지연 시간이 길어지면 시스템의 응답 속도가 느려진다.
- Throughput (처리량): 시스템이 일정 시간 동안 처리할 수 있는 작업의 수를 의미한다. 처리량이 높을수록 시스템이 효율적으로 작동한다
성능 지표를 분석함으로써 시스템이 어떻게 작동하는지 이해하고, 개선이 필요한 부분을 식별할 수 있다.
1.3 성능 최적화의 필요성과 목표
성능 최적화는 시스템의 효율성과 사용자 만족도를 높이기 위해 필수적이다. 주요 목표는 다음과 같다:
- 사용자 경험 개선: 빠르고 원활한 응답을 제공해 사용자가 더 나은 경험을 할 수 있게 한다.
- 리소스 관리: 제한된 자원을 효율적으로 활용해 운영 비용을 절감하고, 불필요한 리소스 사용을 줄이며 필요할 때 최적화한다.
- 확장성 확보: 더 많은 사용자가 시스템을 동시에 사용할 수 있도록 성능을 강화하며, 증가하는 수요에도 시스템이 안정적으로 작동하도록 보장한다.
2. 병목 현상의 이해와 원인
2.1 병목 현상의 정의
병목 현상은 시스템의 특정 부분이 전체 성능을 저하시키는 현상을 의미한다. 하나의 구성 요소가 비효율적으로 작동하면 시스템 전체의 처리 속도가 느려질 수 있다. 이러한 현상은 시스템 자원의 불균형 사용으로 인해 발생하며, 성능 최적화의 주요 대상이 된다.
- 예시: 인기 있는 레스토랑에 손님들이 몰려들어 예약이 끊이지 않지만, 주방의 불판과 조리 공간이 제한되어 있어 모든 손님을 빠르게 응대할 수 없는 상황이 발생한다. 그 결과, 손님들은 대기해야 하고 서비스 속도도 느려지게 된다.
2.2 시스템 병목의 주요 원인
병목 현상은 여러 가지 원인에 의해 발생할 수 있다. 주요 원인은 다음과 같다:
-
CPU 병목: CPU가 과부하 상태일 경우 작업 처리 속도가 저하된다. 과도한 계산 작업이나 비효율적인 코드가 원인이 될 수 있다.
-
예시: 넷플릭스는 방대한 콘텐츠를 사용자에게 제공하기 위해 추천 알고리즘을 실행한다. -
사용자가 선호할 만한 영상을 추천하는 과정에서 복잡한 기계 학습 모델이 사용된다.
-
만약 특정 시간대에 많은 사용자가 동시에 접속해 추천 알고리즘이 과도한 연산을 요구하면, 서버의 CPU가 과부하 상태에 빠져 전체 응답 속도가 느려질 수 있다.
-
이때 CPU 병목이 발생하며, 사용자가 스트리밍을 시작할 때 지연이 생길 위험이 있다.
-
-
메모리 병목: 메모리 사용이 한계에 도달하면 성능이 급격히 떨어진다. 메모리 누수나 대용량 데이터 처리가 원인이 될 수 있다.
-
예시: 국민은행, 카카오뱅크와 같은 시중 은행 및 인터넷 은행의 송금 시스템에서 대량의 거래 데이터를 실시간으로 처리할 때, 메모리를 효율적으로 사용하지 못하면 문제가 생길 수 있다. -
예를 들어, 수많은 사용자 거래를 메모리에 유지하면서 여러 검증 작업을 동시에 수행할 경우 메모리 한계에 도달해 성능이 급격히 저하될 수 있다.
-
메모리 누수나 비효율적인 데이터 구조 사용이 원인일 수 있으며, 이런 상황에서는 실시간 송금이 지연되거나 오류가 발생할 위험이 있다.
-
-
네트워크 병목: 네트워크 대역폭이 부족하거나 데이터 전송 속도가 느릴 때 발생한다. 대량의 데이터 전송이 필요한 작업이 주된 원인이다.
-
예시: 페이팔 같은 결제 서비스는 여러 국가의 은행과 통신해 거래를 처리한다. -
만약 페이팔 서버가 해외 은행과의 네트워크 연결 속도가 느려지면 사용자 결제 승인 과정이 지연될 수 있다.
-
특히 블랙프라이데이 같은 대규모 이벤트 때 대량의 결제 요청이 몰리면 네트워크 병목이 발생할 가능성이 높다.
-
이 병목은 사용자에게 결제 대기 화면을 보여주며, 거래가 정상적으로 완료되지 않아 불편함을 초래할 수 있다.
-
-
I/O 병목: 디스크 읽기/쓰기 속도가 느릴 때 성능 저하가 발생한다. 데이터베이스나 파일 입출력이 많을 때 흔히 나타난다.
-
예시: AWS에서 호스팅된 웹 애플리케이션이 대량의 로그를 S3 같은 스토리지에 지속적으로 기록할 때, 디스크 쓰기 속도가 느리면 전체 애플리케이션 성능이 저하될 수 있다. -
대량의 데이터베이스 읽기/쓰기 작업이 동시에 수행되면 I/O 병목이 발생할 수 있다.
-
이런 문제는 클라우드 환경에서 특히 중요하며, 파일 시스템이 제대로 최적화되지 않으면 서비스의 응답 시간이 길어질 수 있다.
-
2.3 병목 지점 식별 방법
병목 지점을 식별하기 위해 다음 방법을 사용할 수 있다:
- 모니터링 도구:
top,htop,iostat,vmstat같은 시스템 모니터링 도구를 사용해 자원의 사용률을 확인하고, CPU, 메모리, 네트워크, I/O 상태를 실시간으로 관찰한다. - 프로파일링: 애플리케이션 프로파일링 도구를 사용해 코드의 성능 병목 지점을 분석한다. 예를 들어, JProfiler나 VisualVM을 사용해 메서드 호출 시간과 메모리 사용량을 분석하고, 비효율적인 코드나 과도한 객체 생성 지점을 식별할 수 있다.
- 로그 분석: 로그 데이터를 통해 응답 시간이나 오류 발생 지점을 분석한다. 예를 들어, ELK Stack이나 Splunk를 사용해 특정 API의 응답 시간 증가 패턴이나 빈번한 에러 발생 지점을 추적할 수 있다.
이 도구들(예: JProfiler, VisualVM, ELK Stack, Splunk)은 성능 모니터링 및 분석 도구에 해당한다. 성능 테스트는 부하를 생성해 시스템의 한계를 평가하는 과정이며, VisualVM 같은 도구는 테스트가 끝난 후 병목 지점을 식별하거나 리소스 사용을 분석하는 데 사용된다.
3. 성능 테스트의 기본과 과정
3.1 성능 테스트 이해하기
워크로드란, 가장 일반적인 의미에서 시스템이나 네트워크가 작업을 완료하거나 특정 출력을 생성하는 데 걸리는 시간과 사용되는 컴퓨터 리소스를 말한다. - IBM
성능 테스트는 특정 워크로드에서 소프트웨어의 응답 시간, 안정성, 확장성, 가용성 등을 평가하여 고객에게 최적의 소프트웨어 성능을 제공할 수 있는지를 측정하는 과정이다.
- 응답 시간: 사용자의 요청으로부터 결과를 반환하기까지 걸리는 시간.
- 안정성: 다양한 문제 상황에서도 일정한 품질의 서비스를 안정적으로 제공할 수 있는지 여부.
- 확장성: 부하가 증가하거나 시스템 용량이 한계에 도달했을 때 수직 또는 수평 확장을 통해 서비스 품질을 유지할 수 있는지 여부.
- 가용성: 물리적 장애나 높은 부하가 발생해도 일정한 품질을 유지하며 서비스를 제공할 수 있는지 여부.
3.2 성능 테스트를 통해 알 수 있는 것
-
예상 목표 TPS를 달성할 수 있는지.
-
피크 시간대에도 서비스가 원활히 제공되는지.
-
장시간 운영 시 자원 누수 없이 안정적으로 작동하는지.
-
사용자가 증가할 경우 수평/수직 확장을 위한 기준이 무엇인지.
-
일부 시스템이 다운되더라도 최소한의 리소스로 서비스가 유지되는지.
-
시스템 리소스가 과도하게 할당되지 않았는지.
-
시스템 메트릭이 시스템 상태를 정확히 설명하는지.
-
최적의 하드웨어 및 소프트웨어 설정값이 무엇인지.
3.3 성능 테스트의 주요 용어
트랜잭션(Transaction): DB 트랜잭션과는 다르게, 논리적인 업무 요청의 단위로, 사용자가 한 번의 요청을 보내는 행위.총 사용자(Total User): 현재 서비스 요청자 + 대기자 + 비접속자.현재 서비스 요청자(Active User): 현재 서비스에 요청을 보낸 사용자.서비스 대기자(Inactive User): 서비스에 접속해 있지만 아직 요청을 보내지 않은 사용자.동시 사용자(Concurrency User): Active User + Inactive User.
처리량(Throughput): 단위 시간당 처리되는 작업의 양 (TPS: 초당 트랜잭션 수, RPS: 초당 요청 수).- 처리량 계산: TPS = 현재 서비스 요청자(Active User) / 평균 응답 시간(Average Response Time)
- Active User 계산: Active User = 처리량(TPS) × 평균 응답 시간(Average Response Time)
응답 시간(Response Time): 사용자가 서버에 요청을 보낸 후 응답을 받기까지 걸리는 시간.요청 주기(Request Interval): 요청 주기는 응답 시간 + 생각 시간 + 조작 시간.생각 시간(Think Time): 사용자가 응답을 받은 후 화면을 보며 생각하는 시간.조작 시간(Operation Time): 사용자가 데이터를 입력하거나 화면을 채우는 시간 (예: 로그인 시 아이디와 비밀번호를 입력하는 시간).
3.4 성능 테스트 과정
성능 테스트 과정은 아래의 크게 4가지로 구분되어 진행된다.
-
테스트 항목: 현재 테스트할 모든 애플리케이션을 나열하고, 우선순위를 기준으로 테스트 범위를 정한다. -
테스트 조건: 각 애플리케이션이 충족해야 할 조건을 설정한다. -
테스트 시나리오: 워크로드 모델을 작성하여, 업무 중요도가 높은 항목을 선정하고 가설을 세워 성능 테스트 대상을 설정한다. (워크로드 모델, 목표 TPS, 사용자 수, 응답 시간(sec), 생각 시간, 결과 TPS) -
점검 항목: TPS, 응답 시간, 시스템 메트릭, 에러 발생률, 네트워크 사용률, 로드 밸런서 부하 등을 점검한다.
3.5 성능 테스트 Graph
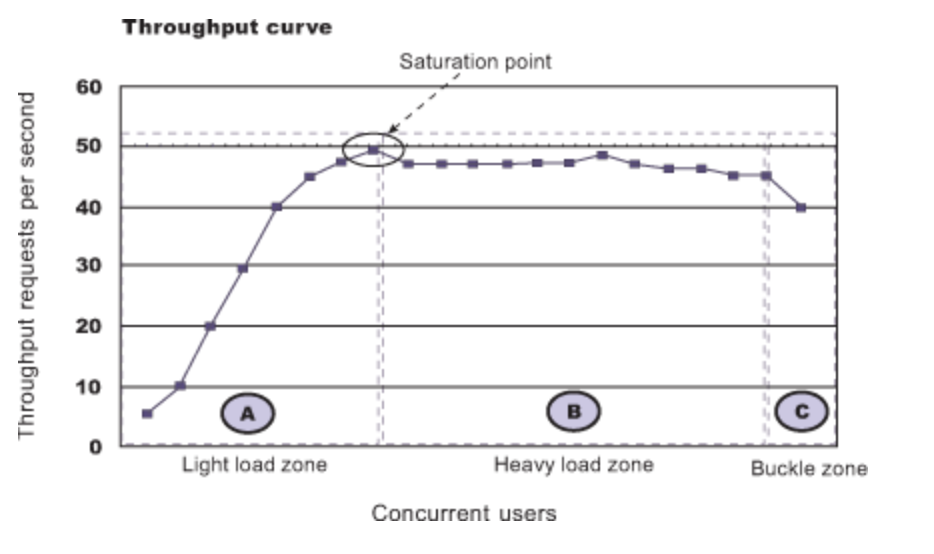
(출처: IBM: Aspects of Performance Tuning)
-
A: 사용자가 증가되는 시점 (Ramp Up)
- 해당 지점동안 사용자가 증가하면서 처리량도 함께 증가한다.
-
Saturation point: 임계지점(포화지점)
-
사용자가 증가해도 더 이상 처리량이 증가되지 않는 상태가 되는 시점
-
이 상태가 되면 현재 시스템이 처리할 수 있는 최대 Capacity 에 도달했음을 나타낸다.
-
-
B: 최대 부하 지점
-
사용자가 증가해도 처리량이 일정하게 유지되는 지점
-
이때 그래프가 고르고 안정적이라면 서비스가 최대 Capacity로 유지될 수 있음을 나타낸다.
-
-
C: Buckie 영역(성능 감소지점)
-
최대 처리를 더 이상 견뎌내니 못하고 성능이 감소되는 지점
-
이 시점은 시스템의 한계를 초과했을 때 혹은 네트워크 대역폭을 전부 사용한 경우에 이런 현상이 발생한다.
-
3.6 성능 테스트별 그래프
성능테스트 방법에 따라 그래프 패턴을 확인할 수 있다.
(자세한 내용은 Grafana Labs - Load test types 에서 확인한다)
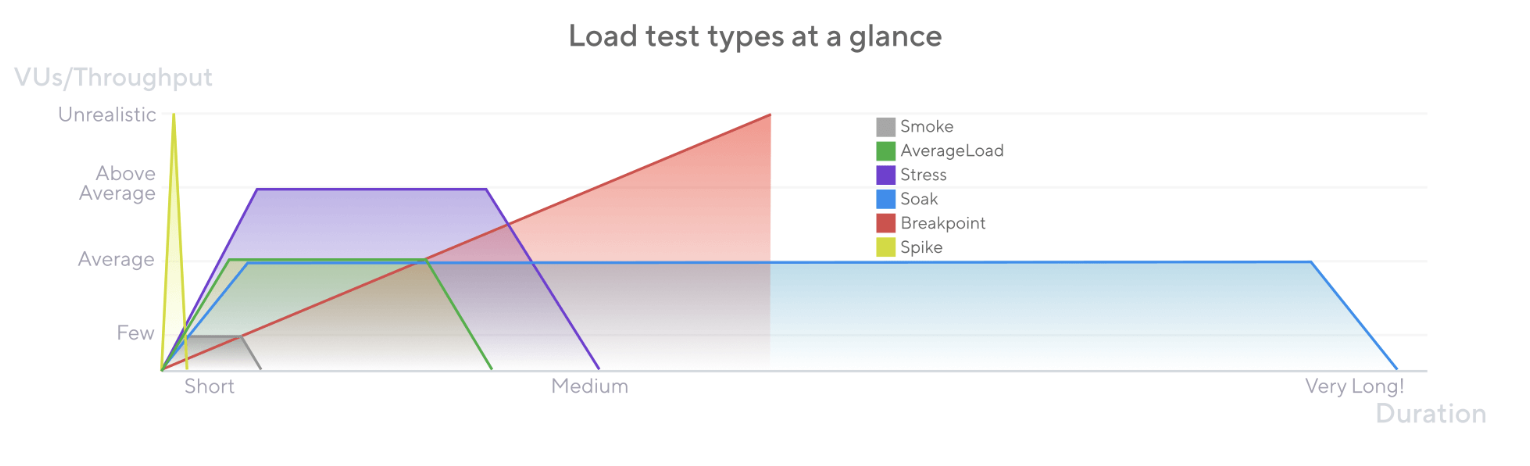
-
Smoke 테스트는 스크립트가 제대로 작동하는지와 시스템이 최소한의 부하에서 적절하게 성능을 발휘하는지를 검증한다. -
Average Load 테스트는 시스템이 예상되는 정상적인 조건에서 어떻게 작동하는지를 평가한다. -
Stress 테스트는 부하가 예상 평균을 초과할 때 시스템이 한계에서 어떻게 작동하는지를 평가한다. -
Soak 테스트는 시스템의 신뢰성과 성능을 장시간에 걸쳐 평가한다. -
Breakpoint 테스트는 부하를 점진적으로 증가시켜 시스템의 용량 한계를 식별한다. -
Spike 테스트는 갑작스럽고 짧으며 대규모로 증가하는 활동에서 시스템의 동작과 생존 여부를 검증한다.
3.7 워크로드 모델링
-
워크로드 모델링은 성능 테스트 대상 워크로드를 나열하고, 업무 중요도가 높은 순서로 가설을 설정해 성능 테스트 대상을 선정하는 작업이다. -
시스템에서 사용하는 모든 워크로드를 나열한 후, 가장 많이 사용되는 70~80% 의 워크로드만을 성능 테스트 대상으로 삼는다.
| 워크로드 | Target TPS | User | Response Time (sec) | Think Time | TPS |
|---|---|---|---|---|---|
| 메인화면 | 20 | 60 | 2 | 1 sec | 20 |
| 로그인 | 15 | 45 | 1 | 2 sec | 15 |
| 마이페이지 | 10 | 50 | 3 | 2 sec | 10 |
| 상품 | 25 | 75 | 2 | 1 sec | 25 |
| 이체 | 10 | 70 | 4 | 3 sec | 10 |
| 혜택 | 8 | 32 | 2 | 2 sec | 8 |
| 알림 | 12 | 36 | 1 | 2 sec | 12 |
| Total | 100 | 368 | - | - | 100 |
-
위 워크로드는 7개의 주요 애플리케이션을 나열한 것이다. (실제 워크로드는 이보다 많지만, 여기서는 약 80%의 주요 워크로드만 모델링했다.)
-
표에서 사용된 용어들은 다음과 같다. (위에 있는 “3.3 성능 테스트의 주요 용어”와 같은 내용이다)
-
Target TPS: 목표로 하는 초당 트랜잭션 수. -
User: 가상 사용자 수로, 예상되는 사용자 수를 설정한다.- 현재 서비스 사용자 수: 처리량(TPS) × 평균 응답 시간(Response Time + Think Time)
-
Reponse Time: 응답 시간. -
TPS: 실제로 측정된 처리량.- 처리량: 현재 서비스 요청자 수 / 평균 응답 시간(Response Time + Think Time)
-
-
위와 같은 워크로드 모델을 구성하여 성능 테스트를 진행하고, 각 워크로드에 부하를 균등하게 분산해 주입할 방안을 결정한다.
3.8 주요 성능 테스트 도구 소개
오픈 소스로 공개된 성능 테스트 도구들 중 nGrinder와 K6에 대해 정리했다.
- nGrinder
- 구성: 스크립트 기반 부하 테스트 플랫폼으로, 테스트 관리를 담당하는 Controller와 부하 생성을 위한 Agent로 구성된다.
- 기능:
- 스크립트 기반 시나리오 작성: Jython 또는 Groovy 스크립트를 사용해 테스트 시나리오를 작성할 수 있으며, 여러 Agent를 통해 JVM에서 부하를 생성한다.
- 확장 가능한 테스트: 사용자 정의 라이브러리(JAR, Python 스크립트, Maven 의존성)를 추가하여 무제한으로 테스트를 확장할 수 있다.
- 웹 기반 인터페이스: 프로젝트 관리, 모니터링, 결과 관리, 리포트 관리를 위한 웹 기반 UI를 제공한다.
- IDE 지원: Groovy 스크립트를 IDE에서 개발하고, 분산 Agent를 통해 실행할 수 있다.
- 병렬 테스트: 여러 테스트를 동시에 실행하며, 각 Agent의 자원 활용도를 극대화할 수 있다.
- 다중 네트워크 지역: 다양한 네트워크 위치에서 테스트를 실행할 수 있도록 여러 네트워크 지역에 Agent를 배포할 수 있다.
- 내장 Subversion: 스크립트 관리를 위해 Subversion이 내장되어 있다.
- 모니터링: 부하를 생성하는 Agent의 상태와 부하를 받는 대상 시스템을 실시간으로 모니터링할 수 있다.
- 장점: 직관적인 UI 제공과 글로벌 부하 테스트 환경을 지원하며, 대규모 시스템 테스트에 적합한 검증된 솔루션이다.
- 단점: Jython/Groovy에 대한 지식이 부족할 경우 복잡한 스크립트 작성이 어려울 수 있다. 또한, 분산 테스트 시 여러 Agent를 사용하는 경우 많은 시스템 자원이 필요하다.
- 참고자료: nGrinder 설치 (GitHub) , nGrinder(공식문서)
- K6
- 특징: 웹 애플리케이션과 API의 부하 및 성능 테스트를 위해 설계된 오픈 소스 성능 테스트 도구로, 개발자 친화적이고 확장 가능하다.
- 기능: 다양한 부하 조건에서 시스템의 성능과 확장성을 측정하며, 여러 기능을 제공한다.
- JavaScript 기반: JavaScript를 사용해 테스트 스크립트를 작성할 수 있어 JavaScript 개발자들이 쉽게 사용할 수 있다.
- 부하 생성: 여러 가상 머신과 클라우드 인스턴스를 활용해 높은 부하를 생성하고 실제 사용자 행동을 시뮬레이션하여 확장성 테스트를 수행할 수 있다.
- 모니터링: 테스트 결과를 실시간으로 분석하고 성능 문제를 즉시 식별할 수 있다.
- 확장성: 오픈 소스 특성 덕분에 사용자 정의 플러그인 개발을 통해 기능을 확장할 수 있다.
- 성능 체크: 시스템 동작을 검증하고 통과/실패 기준을 설정할 수 있는 기능을 제공한다.
- 통합: Grafana Cloud 및 k6 Cloud와 통합되어 추가적인 결과 저장, 분석, 공유 기능을 제공한다.
- 단점: 브라우저 기반 테스트를 지원하지 않으며, Node.js 환경에서 직접 사용할 수 없다. 대규모 부하 테스트를 위해 멀티 Agent 환경을 구성할 때 설정이 복잡할 수 있다.
- 참고자료: K6 (공식문서)
마치면서
-
이번 글에서는 성능의 기초 개념, 병목 현상, 그리고 성능 테스트에 대해 간단하게 정리해보았다. 이러한 개념을 이해함으로써 시스템의 성능을 최적화하고 문제를 사전에 예방하는 데 필요한 기반 지식을 다질 수 있었다. 글을 작성하면서 성능 테스트와 함께 활용해야 할 모니터링 도구의 중요성도 새롭게 느끼게 되었는데, 이 부분은 다음 글에서 성능 테스트와 함께 더 깊이 다뤄볼 예정이다.
-
추가로, 앞으로 작성할 글에서는 Java/Kotlin, Spring Boot 환경에서 성능을 개선하기 위해 고려할 수 있는 요소들을 다루어 보려 한다.
Reference
-
-
Linux Performance Analysis in 60,000 Miliseconds (리눅스 서버에서 성능 이슈가 발생했을 때, 첫 60초 안에 확인해야할 사항)
-
Linux Systems Performance (넷플릭스 - 시니어 성능 엔지니어 Brendan Gregg)
-