- Prologue
- 쿠폰 시스템 설계 개요
- 쿠폰 발급 전체 시스템 흐름과 분산락의 역할
- 기존 SETNX 직접 사용 방식의 고려사항
- Redisson RLock과 AOP를 선택한 이유
- Redisson 분산락 적용 과정
- 애플리케이션 실행 후 플로우 추적
- Redisson 도입 후 성능 테스트
- Summary
- References
Prologue
이번 포스팅에서는 개인적으로 진행한 쿠폰 발급 시스템 프로젝트에서 분산락(Distributed Lock) 메커니즘을 개선했던 경험을 공유하고자 합니다. 초기 시스템은 단일 Redis 서버 환경을 기준으로 SETNX 명령어를 직접 사용하여 분산락을 구현했습니다.
물론 SETNX는 간단하게 분산락을 구현할 수 있는 방법이지만, 몇 가지 불편한 점과 단일 인스턴스 환경에서도 고려해야 할 점들이 있었습니다. 예를 들어, 락 획득 및 해제 로직이 비즈니스 코드와 섞여 가독성을 해치거나, 반복적인 try-finally 구문을 사용해야 하는 점, 그리고 락 임대 시간(Lease Time) 관리의 복잡성 등이 그것입니다.
본 글에서는 이러한 점들을 개선하기 위해 Redisson의 RLock과 Spring AOP를 도입하여, 비즈니스 로직과 락킹 로직을 분리하고 보다 안정적이며 재사용 가능한 분산락 코드를 작성한 과정을 상세히 설명드리겠습니다. 현재는 Redis 단일 인스턴스 환경을 기준으로 설명하며, 고가용성 환경으로의 확장은 향후 과제로 남겨두었습니다.
예상 독자
이 글은 아래에 해당하는 분들께 도움이 될 것입니다.
-
Redis 환경에서
SETNX를 직접 사용하여 분산락을 구현하며 불편함을 느끼셨던 분 -
Spring AOP를 활용하여 공통 로직(특히 락킹)을 분리하고 싶으신 분
-
Redisson의
RLock을 이용한 분산락 구현 방법에 관심 있으신 분 -
보다 깔끔하고 안정적인 분산락 코드를 작성하고자 하시는 분
참고: 본 글에서 소개되는 코드 예시는 현재 시점의 구현을 바탕으로 작성되었으며, 프로젝트가 발전함에 따라 내용이 변경되거나 개선될 수 있음을 미리 알려드립니다.이 글에서 다루는 모든 코드는 깃허브에서 확인하실 수 있습니다.
쿠폰 시스템 설계 개요
분산락 개선에 대해 자세히 알아보기 전에, 제가 개발 중인 쿠폰 발급 시스템의 전반적인 설계 특징과 구조를 간략히 소개하겠습니다.
이 시스템은 도메인 중심 설계(Domain-Driven Design) 원칙을 따르려고 노력했으며, 각 기능의 책임을 명확히 분리하기 위해 멀티 모듈 구조를 채택했습니다.
도메인 모델링 및 용어 정의는 해당 문서 링크 문서에 상세히 정리했습니다.
주요 설계 특징
-
도메인 중심 설계:
Coupon,IssuedCoupon,User등 핵심 도메인 모델을 중심으로 시스템을 구성했습니다. 쿠폰 발급 수량 제한이나 유효기간 검증과 같은 도메인 내부 정책은 해당 엔티티에서 직접 제어하도록 구현했습니다. -
멀티 모듈 구조: 프로젝트의 각 부분을 기능적으로 분리하여 유지보수성과 확장성을 높이고자 다음과 같은 멀티 모듈 구조를 적용했습니다.
coupon/
├── coupon-api # REST API, 인증, 핵심 비즈니스 로직 (분산락 적용 부분)
├── coupon-domain # 도메인 모델 (JPA Entity 등)
└── coupon-kafka-consumer # Kafka를 통한 비동기 쿠폰 발급 처리 로직
support/
├── logging # 공통 로깅 필터 및 설정
├── monitoring # Prometheus, Grafana, K6 연동 구성
└── common # 공통 예외 처리, API 응답 구조 등
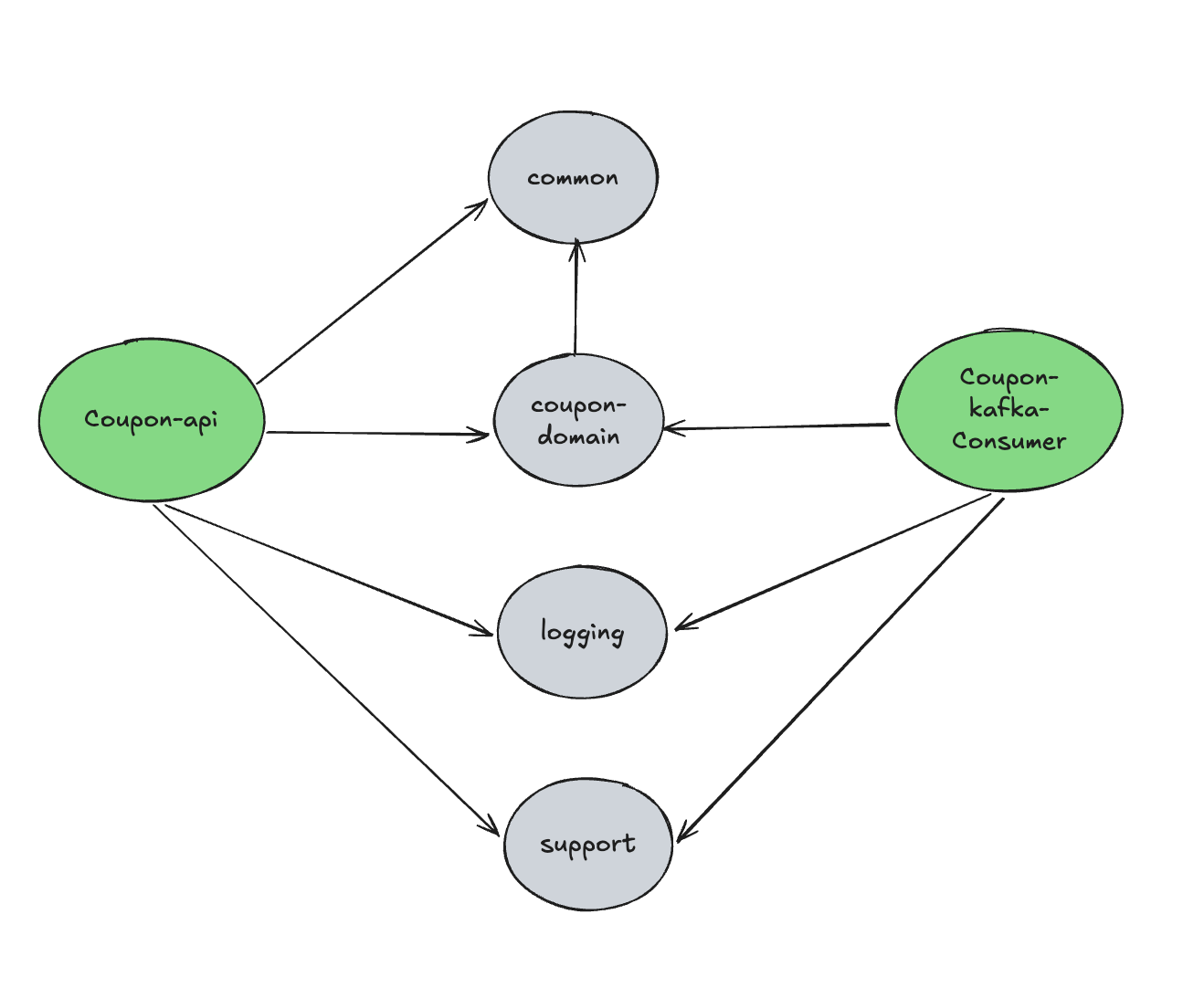
이번 포스팅에서 다루는 분산락 개선은 주로 coupon-api 모듈 내에서 이루어졌습니다.
이러한 구조적 배경 위에서, 다음으로 쿠폰 발급 전체 시스템 흐름과 그 안에서 분산락이 수행하는 역할에 대해 살펴보겠습니다.
쿠폰 발급 전체 시스템 흐름과 분산락의 역할
본격적으로 분산락 개선 과정에 대해 이야기하기에 앞서, 이 분산락이 시스템의 어느 지점에서 왜 중요한 역할을 하는지 간략한 흐름을 통해 이해해 보겠습니다.
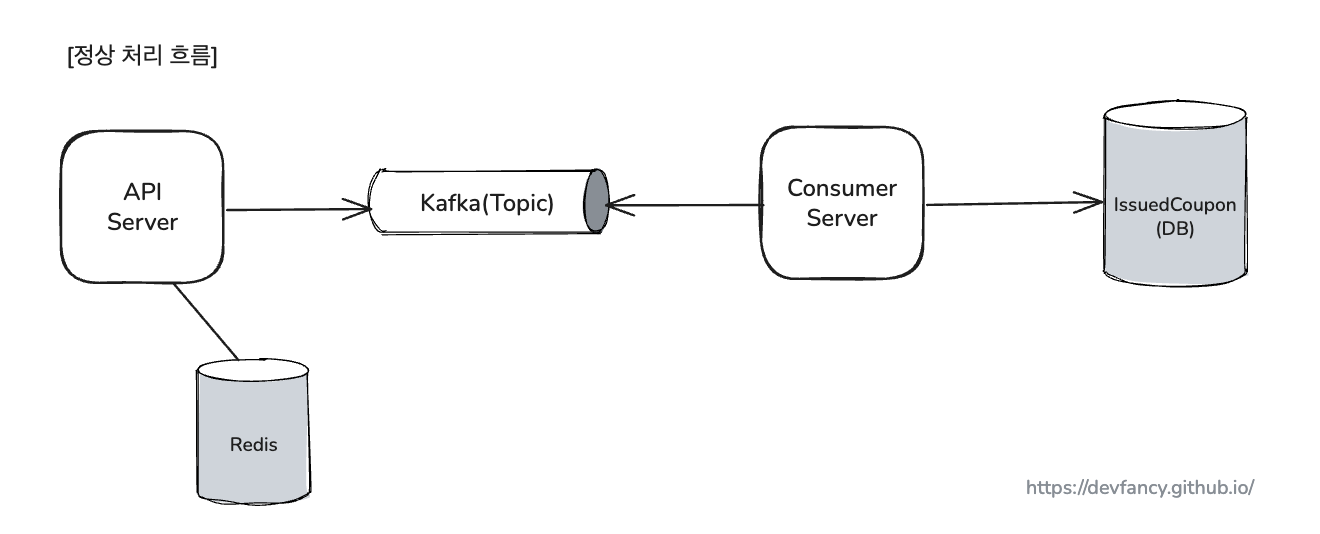
사용자의 쿠폰 발급 요청은 다음과 같은 주요 단계를 거쳐 처리됩니다.
- 선 검증 및 요청 접수 (API 서버)
- 사용자의 요청이 들어오면, 가장 먼저 분산락을 획득하여 동시성을 제어합니다.
- 이후 Redis의 Atomic 연산을 통해 중복 발급을 방지하고, INCR/DECR 명령으로 쿠폰 수량을 제어하는 빠른 검증을 수행합니다.
- 비동기 전달 (Kafka)
- 검증을 통과한 요청은 즉시 Kafka 토픽으로 발행됩니다.
- 덕분에 API 서버는 DB 작업의 지연 시간 없이 사용자에게 빠르게 응답할 수 있습니다.
- 최종 처리 (Consumer 서버)
- 별도의 Consumer 서버가 Kafka 메시지를 받아 최종적으로 데이터베이스에 쿠폰 발급 내역을 저장합니다.
(이러한 아키텍처를 채택한 이유와 전체 시스템의 더 상세한 처리 흐름(실패 및 재처리 포함)은 깃허브에서 확인하실 수 있습니다.)
이처럼 쿠폰 발급 시스템의 전체 흐름에서 분산락은 가장 먼저 동시성 문제를 해결하고 데이터의 일관성을 유지하기 위한 핵심적인 방어선 역할을 수행합니다. 그렇기 때문에 이 분산락 메커니즘을 어떻게 구현하고 관리하느냐가 시스템 전체의 안정성에 큰 영향을 미치게 됩니다.
이제, 이 중요한 분산락 기능을 기존 SETNX 방식에서 어떻게 개선해 나갔는지 자세히 살펴보겠습니다.
기존 SETNX 직접 사용 방식의 고려사항
단일 Redis 인스턴스 환경에서 SETNX 명령어는 분산락을 구현하는 기본적인 수단입니다. 저도 프로젝트 초기에는 lock:coupon:{couponId}:user:{userId}와 같은 키 형식으로 SETNX를 사용하여 동일 사용자의 중복 쿠폰 발급 요청을 제어했습니다.
하지만 이 방식은 다음과 같은 점들을 추가적으로 고려해야 했습니다.
-
- 비즈니스 로직과 락 로직의 혼재
- 쿠폰 발급과 같은 핵심 비즈니스 로직 내에 락을 획득하고 해제하는 코드가 직접 포함되어, 코드의 가독성과 유지보수성을 저해할 수 있었습니다. 핵심 로직에 집중하기 어려워지게 됩니다.
-
- 반복적인 상용구 코드
- 모든 락 사용 지점마다
try-catch-finally구문을 사용하여 락 해제를 보장해야 했고, 락 키를 생성하는 로직 또한 중복될 수 있었습니다.
- 락 임대 시간(Lease Time) 및 유실 문제
SETNX로 락을 설정할 때EXPIRE명령으로 TTL(Time To Live)을 설정하여 락 유실(Lock Leak)을 방지해야 합니다.- 하지만 이 TTL 관리가 수동적이어서, 만약 락을 획득한 클라이언트가 예상보다 오래 작업을 수행할 경우 락이 먼저 해제되어 다른 클라이언트가 락을 중복 획득할 위험이 있었습니다.
- 반대로, 클라이언트 장애 시 락이 너무 길게 남아있을 수도 있고요. Redisson이 제공하는 Watchdog과 같은 Lease Time 자동 연장 기능은
SETNX만으로는 구현하기 복잡합니다.
이러한 불편함과 고려사항들을 개선하고, 보다 안정적이며 재사용 가능한 락킹 메커니즘을 구축하고자 Redisson 도입을 결정했습니다. 특히 Spring AOP를 활용하여 락킹 로직을 공통화하고 비즈니스 로직과 분리하는 것에 큰 장점을 느꼈습니다.
Redisson RLock과 AOP를 선택한 이유
앞서 언급된 SETNX 직접 사용 방식의 한계점을 극복하기 위해 Redisson 라이브러리의 RLock과 Spring AOP를 조합하여 사용하는 방식을 선택했습니다. 주요 이유는 다음과 같습니다.
-
비즈니스 로직과 락 로직의 명확한 분리: Spring AOP를 사용하면
@DistributedLock과 같은 커스텀 어노테이션을 정의하고, 해당 어노테이션이 붙은 메서드 실행 전후로 락 획득 및 해제 로직을 자동으로 처리할 수 있습니다. 이를 통해 비즈니스 로직은 순수하게 핵심 기능에만 집중할 수 있게 되어 코드의 가독성과 유지보수성이 크게 향상됩니다. -
공통화 및 재사용성 증대: 한번 AOP와 어노테이션을 잘 정의해두면, 락이 필요한 다른 여러 비즈니스 로직에
@DistributedLock어노테이션 한 줄만 추가하여 동일한 락킹 메커니즘을 쉽게 적용할 수 있습니다. 이는 코드 중복을 줄이고 일관된 방식으로 락을 관리할 수 있게 해줍니다. -
Redisson
RLock의 안정적인 기능 활용: Redisson의RLock은 단순SETNX와DEL의 조합보다 훨씬 정교하고 다양한 기능을 제공합니다. 예를 들어, 락 획득 시도 시간(Wait Time), 락 임대 시간(Lease Time) 설정, 그리고 특히 Watchdog을 통한 락 임대 시간 자동 연장 기능 등은 락 관리의 안정성을 크게 높여줍니다. Watchdog은 락을 점유한 스레드가 살아있는 동안 Lease Time을 자동으로 연장해주어, 로직 수행 시간이 Lease Time을 초과하더라도 락이 갑자기 해제되는 위험을 줄여줍니다. -
단일 인스턴스 환경에서의 안정성 및 편의성 강화:
SETNX와DEL명령, TTL 설정을 수동으로 조합하며 발생할 수 있는 잠재적인 실수들을 줄일 수 있습니다. Redisson은 잘 테스트되고 검증된 락 구현체를 제공하므로, 단일 Redis 인스턴스 환경에서도 더 신뢰할 수 있는 락 운영이 가능해집니다.
이러한 이유들로, Redis 단일 인스턴스 환경을 기준으로 Redisson의 RLock과 Spring AOP를 결합하여 분산락 시스템을 개선하기로 결정했습니다.
Redisson 분산락 적용 과정
Redisson의 RLock과 Spring AOP를 시스템에 통합하는 과정은 다음과 같이 진행되었습니다.
1. RedissonClient 빈(Bean) 설정
가장 먼저, Spring 애플리케이션 컨텍스트 내에서 RedissonClient를 사용할 수 있도록 빈으로 등록했습니다.
현재는 단일 Redis 서버에 연결하는 useSingleServer() 방식을 사용합니다.
RedisConfig.java
@Configuration
public class RedisConfig {
private static final Logger log = LoggerFactory.getLogger(RedisConfig.class);
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private int redisPort;
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean(destroyMethod = "shutdown") // 애플리케이션 종료 시 RedissonClient 자원 해제
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer()
.setAddress(REDISSON_HOST_PREFIX + redisHost + ":" + redisPort)
.setConnectionPoolSize(128)
.setConnectionMinimumIdleSize(24)
.setConnectTimeout(10000)
.setTimeout(5000);
log.info("Redisson Client 생성 시도: {}{}:{}", REDISSON_HOST_PREFIX, redisHost, redisPort);
try {
RedissonClient redisson = Redisson.create(config);
log.info("Redisson Client 생성 성공");
return redisson;
} catch (Exception e) {
log.error("Redisson Client 생성 실패", e);
throw e;
}
}
}
2. @DistributedLock 어노테이션 정의
락 적용을 위한 커스텀 어노테이션 @DistributedLock 을 정의했습니다.
이 어노테이션에는 락 키(SpEL 표현식 지원), 대기 시간, 임대 시간 등을 설정할 수 있도록 속성을 추가했습니다.
DistributedLock.java
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DistributedLock {
/**
* 락의 이름 (SpEL 표현식 사용 가능)
*/
String key();
/**
* 락의 시간 단위 - waitTime 및 leaseTime 에 적용될 시간 단위입니다.
*/
TimeUnit timeUnit() default TimeUnit.SECONDS;
/**
* 락 획득을 시도하는 최대 대기 시간입니다.
* 이 시간 동안 락을 획득하지 못하면 실패로 간주합니다. (기본값: 5초)
*/
long waitTime() default 5L;
/**
* 락을 성공적으로 획득한 후, 해당 락을 점유하는 시간(임대 시간)입니다. (기본값: 30초)
* 이 시간이 지나면 락은 자동으로 해제될 수 있습니다.
* Redisson 의 Watchdog 은 락을 점유한 스레드가 활성 상태인 동안 이 시간을 자동으로 연장하려고 시도합니다.
* 주의: 이 시간이 실제 로직 수행 시간보다 너무 짧고 Watchdog 연장이 실패하면, 로직 실행 중 락이 해제될 위험이 있습니다.
*/
long leaseTime() default 30L;
}
leaseTime은 Redisson의 Watchdog 기능과 연관되어, 락을 점유한 스레드가 활성 상태이면 자동으로 연장될 수 있습니다.
다만, 로직 수행 시간보다 leaseTime을 충분히 길게 설정하는 것이 안전합니다.
3. DistributedLockAop Aspect 클래스 구현
@DistributedLock 어노테이션을 감지하여 실제 분산락 로직을 수행하는 Aspect 클래스를 구현했습니다. 이 클래스는 RedissonClient 를 사용하여 RLock 인스턴스를 가져오고, 락을 획득한 후 실제 비즈니스 로직을 실행하며, 최종적으로 락을 해제하는 핵심적인 역할을 담당합니다.
(전체 코드는 깃허브 저장소에서 확인하실 수 있으며, 여기서는 핵심적인 부분만 살펴보겠습니다)
락 키는 @DistributedLock 어노테이션의 key 속성에 정의된 SpEL(Spring Expression Language) 표현식을 파싱하여 동적으로 생성합니다. 이 SpEL 파싱은 별도로 구현한 CustomSpringELParser 유틸리티 클래스를 통해 이루어집니다.
DistributedLockAop.java
@Aspect
@Component
public class DistributedLockAop {
private static final Logger log = LoggerFactory.getLogger(DistributedLockAop.class);
private static final String REDISSON_LOCK_PREFIX = "LOCK:";
private final RedissonClient redissonClient;
public DistributedLockAop(final RedissonClient redissonClient) {
this.redissonClient = redissonClient;
}
@Around("@annotation(distributedLockAnnotation)")
public Object lock(final ProceedingJoinPoint joinPoint, final DistributedLock distributedLockAnnotation) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
String spELKeyExpression = distributedLockAnnotation.key();
String dynamicKeyPart;
try {
Object spELResult = CustomSpringELParser.getDynamicValue(
signature.getParameterNames(), joinPoint.getArgs(), spELKeyExpression);
// 평가된 값을 기반으로 실제 락 키 부분 생성
if (spELResult == null || !StringUtils.hasText(spELResult.toString())) {
dynamicKeyPart = method.getName(); // SpEL 결과가 부적절하면 메서드 이름 사용
} else {
dynamicKeyPart = spELResult.toString(); // 유효한 SpEL 결과 사용
}
} catch (Exception e) {
dynamicKeyPart = method.getName();
log.warn("락 키 SpEL 평가 실패, 메서드 이름을 대체 키로 사용합니다. SpEL: '{}', 메서드: '{}', 오류: {}",
spELKeyExpression, dynamicKeyPart, e.getMessage(), e);
}
String lockName = REDISSON_LOCK_PREFIX + dynamicKeyPart;
// (1) 락의 이름으로 RLock 인스턴스를 가져온다.
RLock rLock = redissonClient.getLock(lockName);
long waitTime = distributedLockAnnotation.waitTime();
long leaseTime = distributedLockAnnotation.leaseTime();
log.debug("락 획득 시도: 키='{}', 대기시간={}s, 임대시간={}s", lockName, waitTime, leaseTime);
boolean acquired = false;
try {
// (2) 정의된 waitTime 까지 획득을 시도하고, 정의된 leaseTime 이 지나면 락을 해제한다.
acquired = rLock.tryLock(waitTime, leaseTime, distributedLockAnnotation.timeUnit());
if (!acquired) {
log.warn("락 획득 실패: 키='{}'", lockName);
throw new DistributedLockNotAcquiredException(lockName);
}
log.info("락 획득 성공: 키='{}'", lockName);
// (3) @DistributedLock 어노테이션이 선언된 원본 비즈니스 메서드(예: CouponIssueService#issue)를 실행한다.
return joinPoint.proceed();
} catch (InterruptedException e) {
log.error("락 대기 중 인터럽트 발생: 키='{}'", lockName, e);
Thread.currentThread().interrupt();
throw new DistributedLockNotAcquiredException(lockName);
} finally {
if (acquired && rLock.isHeldByCurrentThread()) { // 락을 획득했고 현재 스레드가 락을 보유하고 있는지 확인
try {
// (4) 종료 시 획득했던 락을 무조건 해제한다.
rLock.unlock();
log.info("락 해제 성공: 키='{}'", lockName);
} catch (IllegalMonitorStateException imse) {
log.warn("락 해제 시도 시 이미 해제되었거나 현재 스레드가 락을 보유하고 있지 않음 (IllegalMonitorStateException). 키='{}', 메서드: '{}', 오류 메시지='{}'",
lockName, method.getName(), imse.getMessage());
} catch (Exception e) {
log.warn("락 해제 중 예외 발생. 키='{}', 메서드: '{}', 오류 메시지='{}'",
lockName, method.getName(), e.getMessage());
}
}
}
}
}
DistributedLockAop는 다음과 같은 핵심적인 역할을 수행합니다.
-
동적 락 키 생성:
@DistributedLock어노테이션에 지정된 SpEL 표현식을 파싱하여 메서드 파라미터 등을 기반으로 동적인 락 키를 생성합니다. 이는 특정 사용자 또는 특정 자원에 대한 락을 효과적으로 관리할 수 있게 합니다. -
락 획득 시도 및 타임아웃 처리:
redissonClient.getLock(lockName)을 통해RLock인스턴스를 얻고,rLock.tryLock(waitTime, leaseTime, timeUnit)메서드를 사용하여 설정된waitTime동안 락 획득을 시도합니다. 이 시간 내에 락을 획득하지 못하면DistributedLockNotAcquiredException을 발생시켜 불필요한 비즈니스 로직 실행을 방지합니다. -
비즈니스 로직 실행: 락 획득에 성공하면
joinPoint.proceed()를 호출하여@DistributedLock어노테이션이 붙은 실제 비즈니스 메서드를 실행합니다. -
안정적인 락 해제:
finally블록에서rLock.unlock()을 호출하여 락을 확실하게 해제합니다. 이때,rLock.isHeldByCurrentThread()조건을 추가하여 현재 스레드가 락을 보유하고 있는 경우에만 해제를 시도함으로써, 이미 락이 해제되었거나 다른 스레드에 의해 재획득된 상황에서의 불필요한 오류를 방지합니다.
CustomSpringELParser.java
SpEL 표현식을 파싱하여 동적 키를 생성하는 유틸리티 클래스입니다.
DistributedLockAop에서 이 클래스의 getDynamicValue static 메서드를 호출하여 사용합니다.
public class CustomSpringELParser {
private CustomSpringELParser() {
}
public static Object getDynamicValue(final String[] parameterNames, final Object[] args, final String key) {
if (ObjectUtils.isEmpty(key)) {
return "";
}
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
return parser.parseExpression(key).getValue(context, Object.class);
}
}
4. 서비스 메서드에 @DistributedLock 적용
이제 락이 필요한 서비스 메서드에 @DistributedLock 어노테이션을 추가하기만 하면 됩니다
IssuedCouponSaver.java (coupon-consumer 모듈에 위치)
@Component
public class IssuedCouponSaver {
private final IssuedCouponRepository issuedCouponRepository;
// ... 생략 ...
/**
* DB에 쿠폰을 저장하는 구간만 분산 락으로 보호하여 동시성을 제어합니다.
* 순서: Lock -> Transaction -> Unlock
*/
@DistributedLock(key = "'coupon:' + #couponId", waitTime = 5, leaseTime = 10)
@Transactional
public void save(final UUID userId, final UUID couponId) {
if (issuedCouponRepository.existsByUserIdAndCouponId(userId, couponId)) {
log.warn("DB에 이미 발급된 쿠폰입니다. - userId: {}", userId);
return;
}
IssuedCoupon issuedCoupon = new IssuedCoupon(userId, couponId);
issuedCouponRepository.save(issuedCoupon);
log.info("쿠폰 발급 DB 저장 완료: {}", issuedCoupon);
}
}
이렇게 함으로써, 쿠폰 발급 로직은 분산락 처리의 복잡성으로부터 완전히 분리되어 핵심 기능에만 집중할 수 있게 되었습니다.
애플리케이션 실행 후 플로우 추적
분산락이 실제로 어떻게 작동하는지 시각적으로 보여드리기 위해, 애플리케이션 실행 후 단일 쿠폰 발급 요청에 대한 로그 흐름을 추적해 보았습니다.
먼저, docker compose를 통해 필요한 외부 컴포넌트(Redis, Kafka 등)를 실행합니다. docker-compose.yml 파일이 있는 경로에서 아래 명령어를 입력합니다.
- 명령어:
docker compose up -d
이후 쿠폰 API 서버와 Kafka Consumer 서버를 실행하고, 쿠폰 발급 요청을 보냈을 때 출력되는 주요 로그를 살펴보겠습니다.
특히, 동일한 traceId (예: 683f06)를 통해 API 서버에서의 락 획득/해제부터 Kafka 메시지 전송, 그리고 Consumer 서버에서의 비동기 처리까지 하나의 요청이 어떻게 이어지는지 확인할 수 있습니다.
쿠폰 API 서버 로그 (요약)
아래는 쿠폰 발급 과정에서 핵심적인 로그 부분만 발췌한 것입니다. 실제 로그에서는 couponId, userId, traceId, spanId가 긴 UUID로 표시되지만, 가독성을 위해 placeholder(임시 값) 로 처리했습니다.
{TraceId}: 분산 트랜잭션의 고유 식별자 (블로그 포스팅에서는 앞 6글자만 표기하지만, 실제 운영 환경에서는 보통 32자로 표기됩니다.){SpanId}:traceId내에서 특정 작업 단위를 나타내는 식별자{httpTraceId}: HTTP 요청에 대한 고유 식별자 (일반적으로traceId와는 별개로 관리되거나, 다른 규칙으로 생성될 수 있습니다.){couponId}: 쿠폰의 고유 ID{userId}: 사용자의 고유 ID
INFO| , |d.b.c.a.c.i.redis.config.RedisConfig |Redisson Client 생성 시도: redis://localhost:6379
INFO| , |org.redisson.Version |Redisson 3.27.0
INFO| , |d.b.c.a.c.i.redis.config.RedisConfig |Redisson Client 생성 성공
INFO| , |d.b.c.a.c.i.redis.config.RedisConfig |couponRedisTemplate 빈 생성 완료
INFO| , |dev.be.coupon.CouponApplication |Started CouponApplication in 4.752 seconds (process running for 5.087)
# --- 단일 쿠폰 발급 요청 처리 시작 ---
DEBUG|{TraceId},{SpanId}|d.b.c.a.c.i.r.aop.DistributedLockAop |락 획득 시도: 키='LOCK:coupon:{couponId}:{userId}', 대기시간=5s, 임대시간=30s
INFO|{TraceId},{SpanId}|d.b.c.a.c.i.r.aop.DistributedLockAop |락 획득 성공: 키='LOCK:coupon:{couponId}:{userId}'
INFO|{TraceId},{SpanId}|d.b.c.a.c.application.CouponService |쿠폰 발급 요청 Kafka 전송 성공 - userId: {userId}, couponId: {couponId}
INFO|{TraceId},{SpanId}|d.b.c.a.c.i.r.aop.DistributedLockAop |락 해제 성공: 키='LOCK:coupon:{couponId}:{userId}'
INFO|{httpTraceId}, |.f.v.HttpRequestAndResponseLoggingFilter|
[REQUEST] POST /api/coupon/{couponId}/issue/test [RESPONSE - STATUS: 201 CREATED]
>> HEADERS: host: localhost:8080; user-agent: k6/0.55.0 (https://k6.io/); content-length: 49; content-type: application/json
>> REQUEST_BODY: {"userId":"{userId}"}
>> RESPONSE_BODY: {"resultType":"SUCCESS","data":{"userId":"{userId}","couponId":"{couponId}","used":false,"issuedAt":"2025-06-03T23:29:25.624245"},"errorMessage":null}
쿠폰 API 서버 로그를 보면, 요청이 들어오자마자 분산락(LOCK:coupon:...)을 획득하고(락 획득 시도 -> 락 획득 성공), 즉시 Kafka로 쿠폰 발급 메시지를 전송한 뒤 락을 해제하는 것을 볼 수 있습니다.
이 모든 과정이 동일한 traceId (예: 683f06) 하에 진행됩니다.
HttpRequestAndResponseLoggingFilter 로그는 HTTP 요청 자체에 대한 정보를 담고 있으며, 여기서 부여된 httpTraceId는 서비스 내부의 traceId와는 다르게 관리될 수 있음을 참고 부탁드립니다.
Kafka Consumer 서버
API 서버에서 Kafka로 전송된 메시지를 Kafka Consumer 서버가 수신하여 처리하는 과정입니다. 여기서도 API 서버의 traceId가 어떻게 이어지는지 확인해 보실 수 있습니다.
INFO| , |o.a.kafka.common.utils.AppInfoParser |Kafka version: 3.6.2
INFO| , |o.s.web.servlet.DispatcherServlet |Completed initialization in 0 ms
# --- API 서버로부터 전달받은 메시지 처리 시작 (traceId: {traceId}) ---
INFO|{TraceId},{SpanId}|d.b.c.k.c.a.CouponIssueConsumer |발급 처리 메시지 수신: CouponIssueMessage[userId={userId}, couponId={couponId}]
INFO|{TraceId},{SpanId}|d.b.c.k.c.a.CouponIssueConsumer |쿠폰 발급 완료: dev.be.coupon.domain.coupon.IssuedCoupon@bf62ea13
Kafka Consumer 서버에서는 API 서버에서 전송한 CouponIssueMessage를 수신하고(발급 처리 메시지 수신),
최종적으로 쿠폰 발급을 완료합니다(쿠폰 발급 완료).
여기서 traceId는 API 서버의 {TraceId}와는 다른, 새로운 {NewTraceId}가 기록됩니다.
그 이유는 Consumer가 메시지를 비동기적으로, 그리고 별도의 트랜잭션(@Transactional(propagation = Propagation.REQUIRES_NEW))으로 처리하기 때문입니다.
이렇게 프로세스와 실행 컨텍스트가 완전히 분리되면 기존의 traceId가 자동으로 전파되지 않고 새로운 추적이 시작됩니다.
이처럼 비동기 경계로 단절된 흐름을 하나의 요청으로 묶어 추적하기 위해,
실무에서는 별도의 전역 추적 ID(예: GlobalTraceId)를 Kafka 메시지 헤더 등에 담아 명시적으로 전파하는 패턴을 사용합니다.
이를 통해 비록 시스템 내부의 traceId는 다르더라도, 사용자의 최초 요청부터 최종 처리까지의 전체 여정을 쉽게 파악할 수 있습니다.
2025.06.18 업로드
Redisson 도입 후 성능 테스트
분산락을 Redisson RLock과 Spring AOP 방식으로 개선한 이후, 시스템의 성능 지표를 분석했습니다. 특히, 기존 SETNX 방식과 비교하여 Redisson 도입으로 인한 영향도를 파악하는 데 중점을 두었습니다.
부하 테스트 도구로는 K6를 사용했고, 모니터링 도구로는 Prometheus와 Grafana를 활용하여 주요 지표를 추려서 테스트를 진행했습니다.
모니터링 도구에 대한 내용은 아래 링크와 같이 공식 문서를 참고했습니다.
Before: SETNX 방식
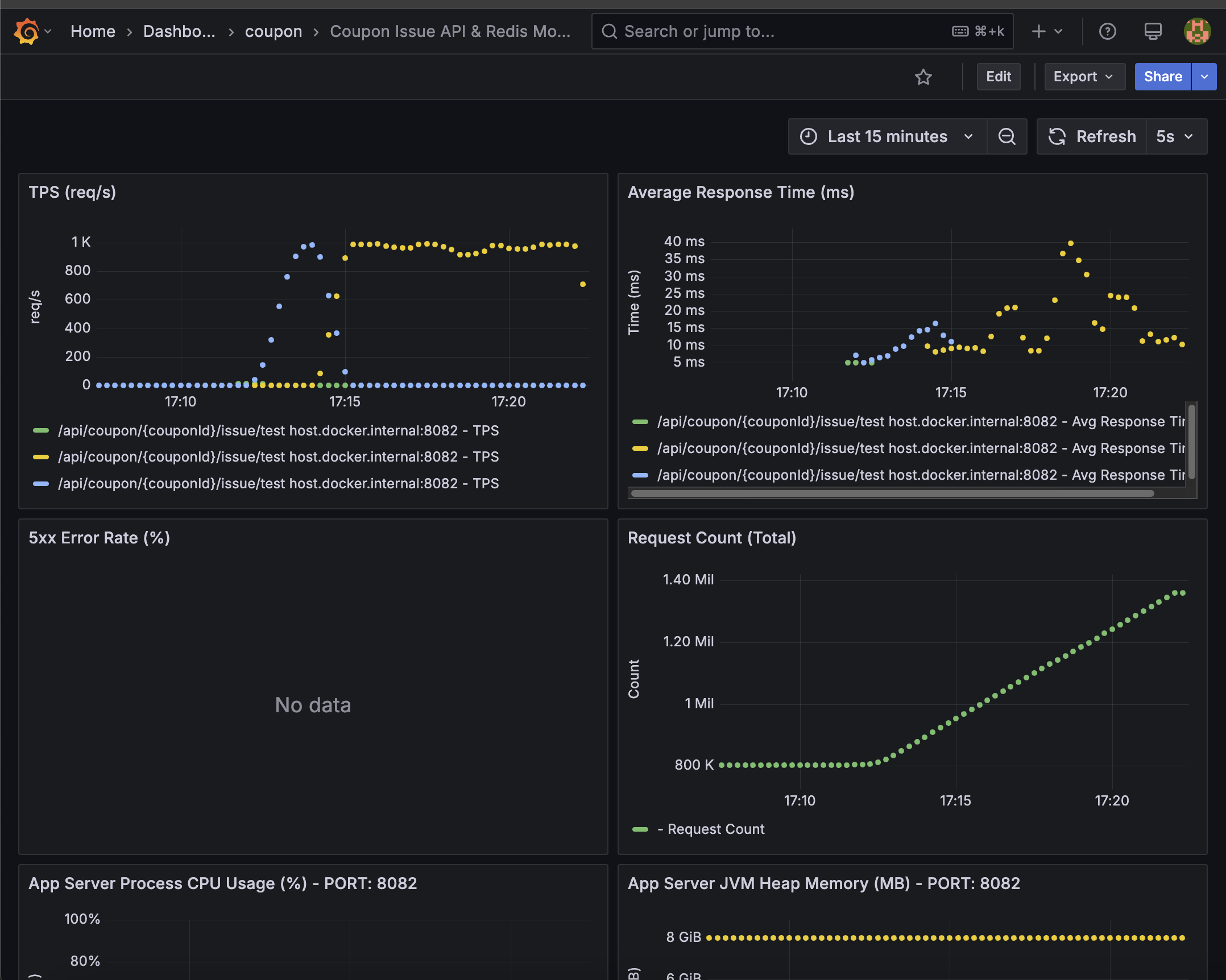
Grafana - Coupon Api Server
- TPS (req/s): Approx. 1K (1000)
- Average Response Time (ms): 25ms
- 5xx Error Rate (%): 0%
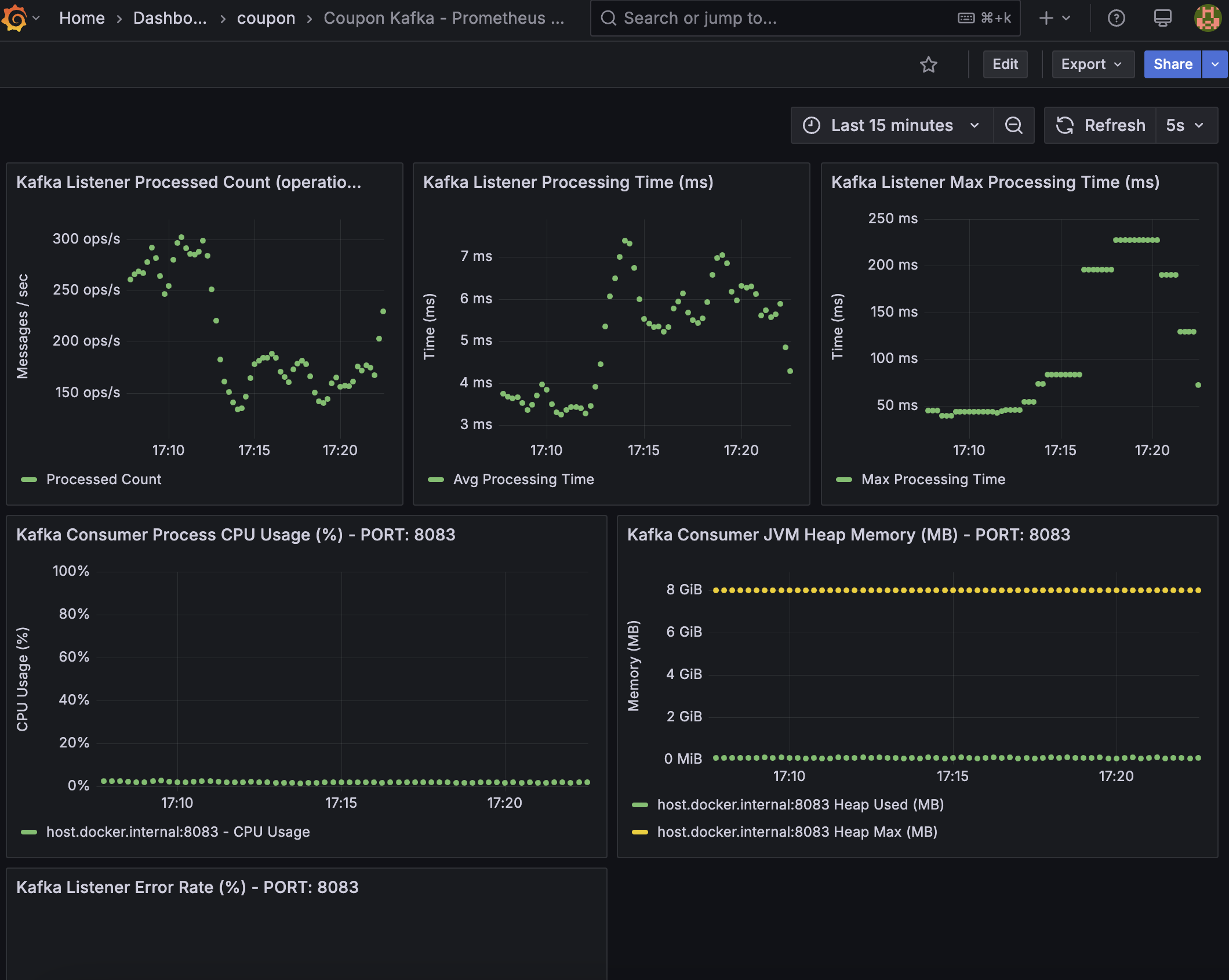
Grafana - Kafka Consumer Server
- Kafka Listener Processed Count: avg 200 ops/s
- Kafka Listener Processing Time (ms): avg 6ms
- Kafka Listener Max Processing Time (ms): avg 200ms
After: Redisson RLock 및 AOP 도입 후
K6
- Average Throughput (requests/sec) =
http_reqs / duration= 549366 / 600s = 914.04929/s - Response Time P95 (ms) =
http_req_duration {p(95)}= 93.79ms - Error Rate (%) =
http_req_failed= 0.00%
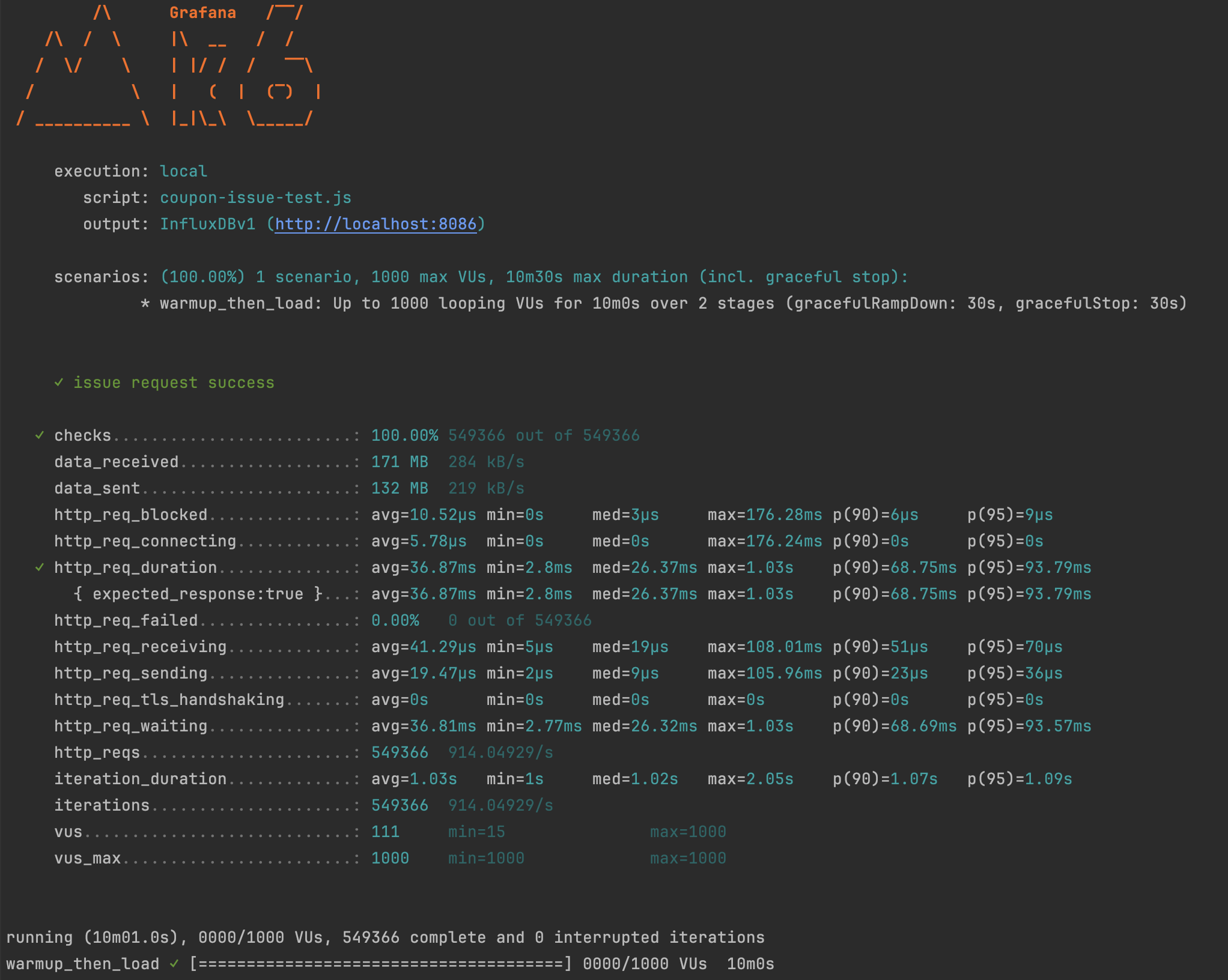
K6 테스트 결과는 600초 동안 약 55만 건의 요청을 처리하며 클라이언트 측에서 초당 약 914건의 요청을 안정적으로 소화했음을 보여줍니다.
특히 0%의 에러율은 Redisson RLock이 동시성 문제를 효과적으로 제어했음을 입증합니다.
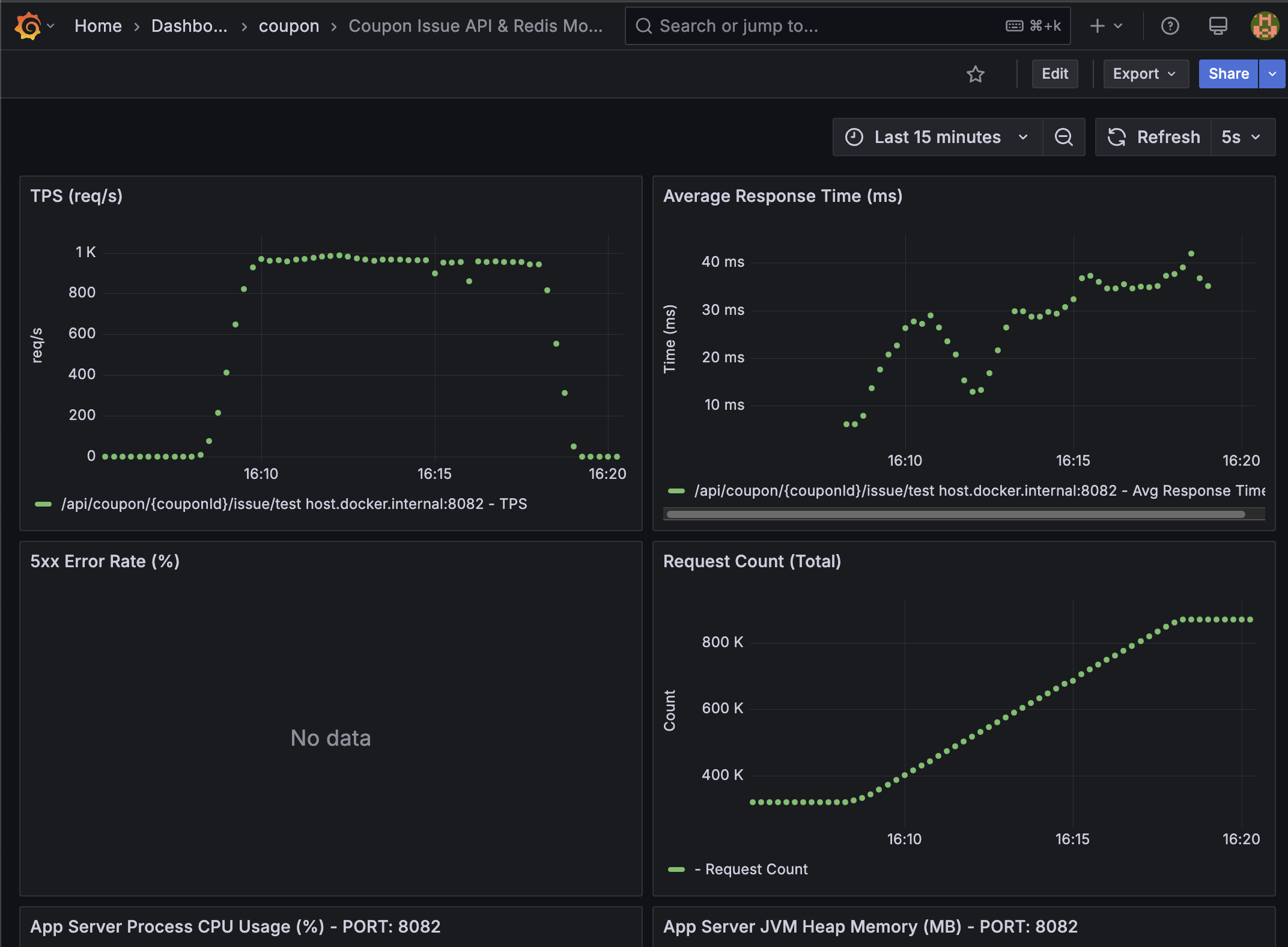
Grafana - Coupon Api Server
- TPS (req/s): Approx. 1K (1000)
- Average Response Time (ms): 30ms
- 5xx Error Rate (%): 0%
애플리케이션 서버의 지표에서도 평균 TPS 1,000 req/s와 평균 응답 시간 30ms라는 준수한 성능을 확인할 수 있습니다.
Grafana - Kafka Consumer Server
- Kafka Listener Processed Count: avg 150 ops/s
- Kafka Listener Processing Time (ms): avg 15ms
- Kafka Listener Max Processing Time (ms): avg 300ms
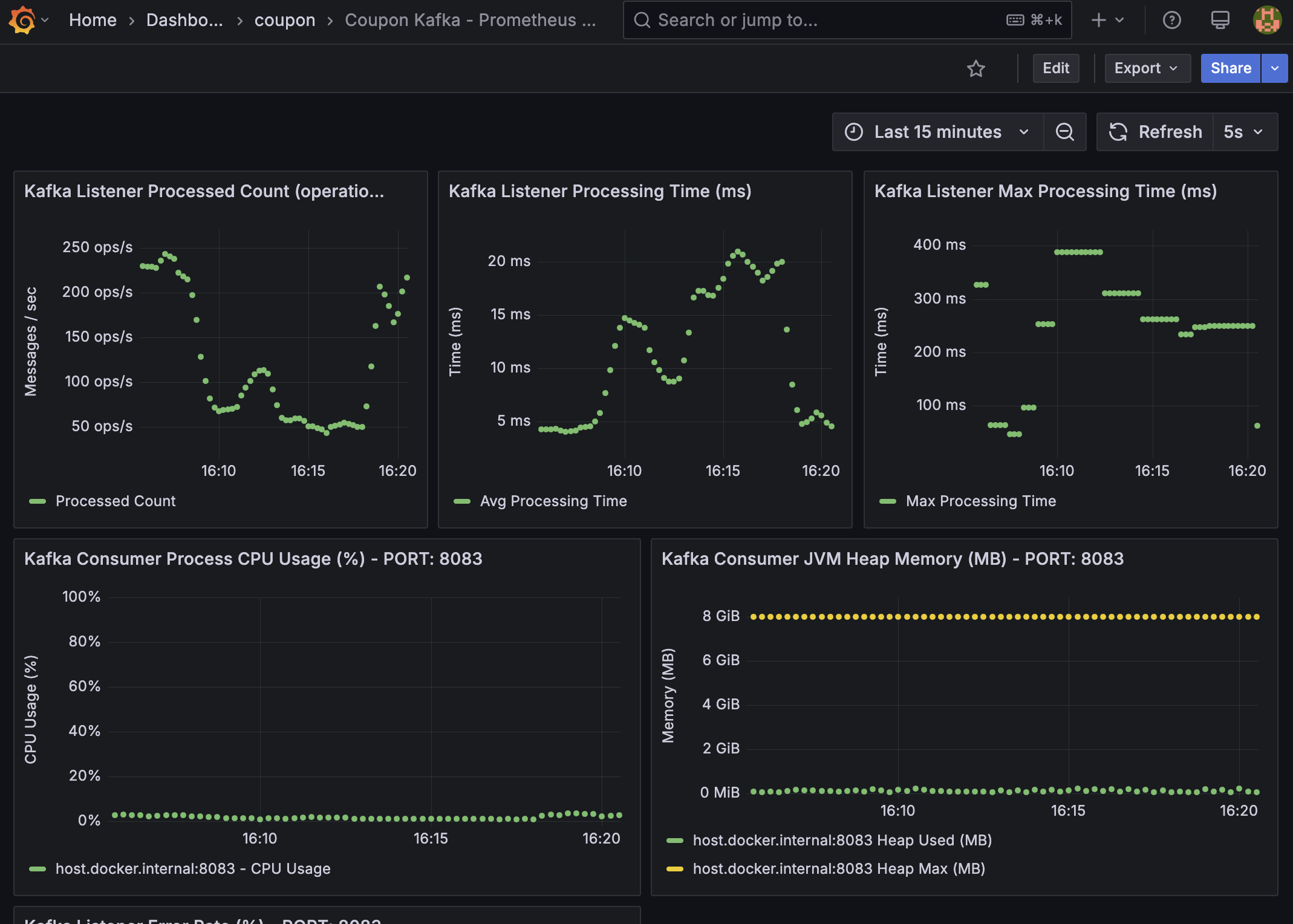
Kafka Consumer 서버는 평균 초당 150건의 메시지를 처리하며, 평균 처리 시간은 15ms로 동작합니다.
분석 및 결론
SETNX 방식과 Redisson RLock 도입 후의 성능 지표를 비교했을 때, 전반적인 처리량과 응답 시간 측면에서 큰 차이는 나타나지 않았습니다.
-
API 서버: TPS는 동일하게 약 1K를 유지했으며, 평균 응답 시간은 25ms에서 30ms로 소폭 증가했습니다. 이는 Redisson의 락킹 로직(예: Watchdog 메커니즘, 내부 Pub/Sub 통신 등)으로 인한 예상 범위 내의 미미한 오버헤드로 판단됩니다. 무엇보다 5xx 에러율은 두 방식 모두 0%로, 시스템의 안정성은 일관되게 유지되었습니다.
-
Kafka Consumer 서버: 메시지 처리량은 200 ops/s에서 150 ops/s로 소폭 감소했고, 평균 처리 시간 또한 6ms에서 15ms로 증가했습니다. 최대 처리 시간도 다소 늘어났지만, 이는 Redisson 도입으로 인한 전반적인 시스템 복잡도 증가 및 락킹 로직의 안정성 강화에 따른 감수할 만한 수준의 변화로 해석됩니다.
결론적으로, Redisson RLock과 AOP를 도입하면서 발생한 성능 오버헤드는 최소화되었으며, 시스템의 전반적인 처리량과 응답 시간은 안정적인 수준을 유지했습니다.
특히, 비즈니스 로직의 간결화, 코드 재사용성 증대, 그리고 Redisson이 제공하는 훨씬 더 안정적이고 견고한 분산 락 관리 기능(락 유실 방지, 자동 연장 등)을 통해
얻는 이점이 이러한 미미한 성능 변화를 압도적으로 상회한다고 판단했습니다. 0%의 에러율은 이러한 안정성 확보의 명확한 증거입니다.
현재 이 성능 테스트는 단일 Redis 인스턴스 환경을 기준으로 진행되었습니다. 향후 고가용성 환경(예: Redis Sentinel 또는 Cluster)으로 확장 시에는 Redisson의 분산 락 메커니즘이 더욱 큰 가치를 발휘할 것이며, 그때의 성능 및 안정성 지표를 다시 분석하고 공유할 예정입니다.
Summary
이번 포스팅에서는 SETNX를 직접 사용하던 기존 방식의 불편함과 한계를 Redisson의 RLock과 Spring AOP를 도입하여 개선한 과정을 공유했습니다.
이를 통해 비즈니스 로직과 분산 락 로직을 효과적으로 분리하고, 보다 안정적이며 재사용 가능한 분산락 코드를 작성할 수 있었습니다.
특히 AOP를 활용한 선언적 락킹 방식은 개발 편의성을 크게 향상시켰으며, Redisson의 풍부한 기능은 단일 Redis 인스턴스 환경에서도 락 관리의 안정성을 높이는 데 기여했습니다.
개인 프로젝트를 통해 이러한 기술적인 개선을 진행하면서, 코드의 품질과 시스템의 안정성에 대해 더 깊이 고민하는 계기가 되었습니다.
지금까지 읽어주셔서 감사합니다.