이 글의 코드와 정보들은 [실전! 스프링 부트와 JPA 활용 2] 강의를 들으며 정리한 내용을 토대로 작성하였습니다.
API 개발 고급
이번 글은 주문내역에서 주문한 상품 정보를 추가로 조회하자.
Order 기준으로 컬렉션인 OrderItem와 Item이 필요하다.
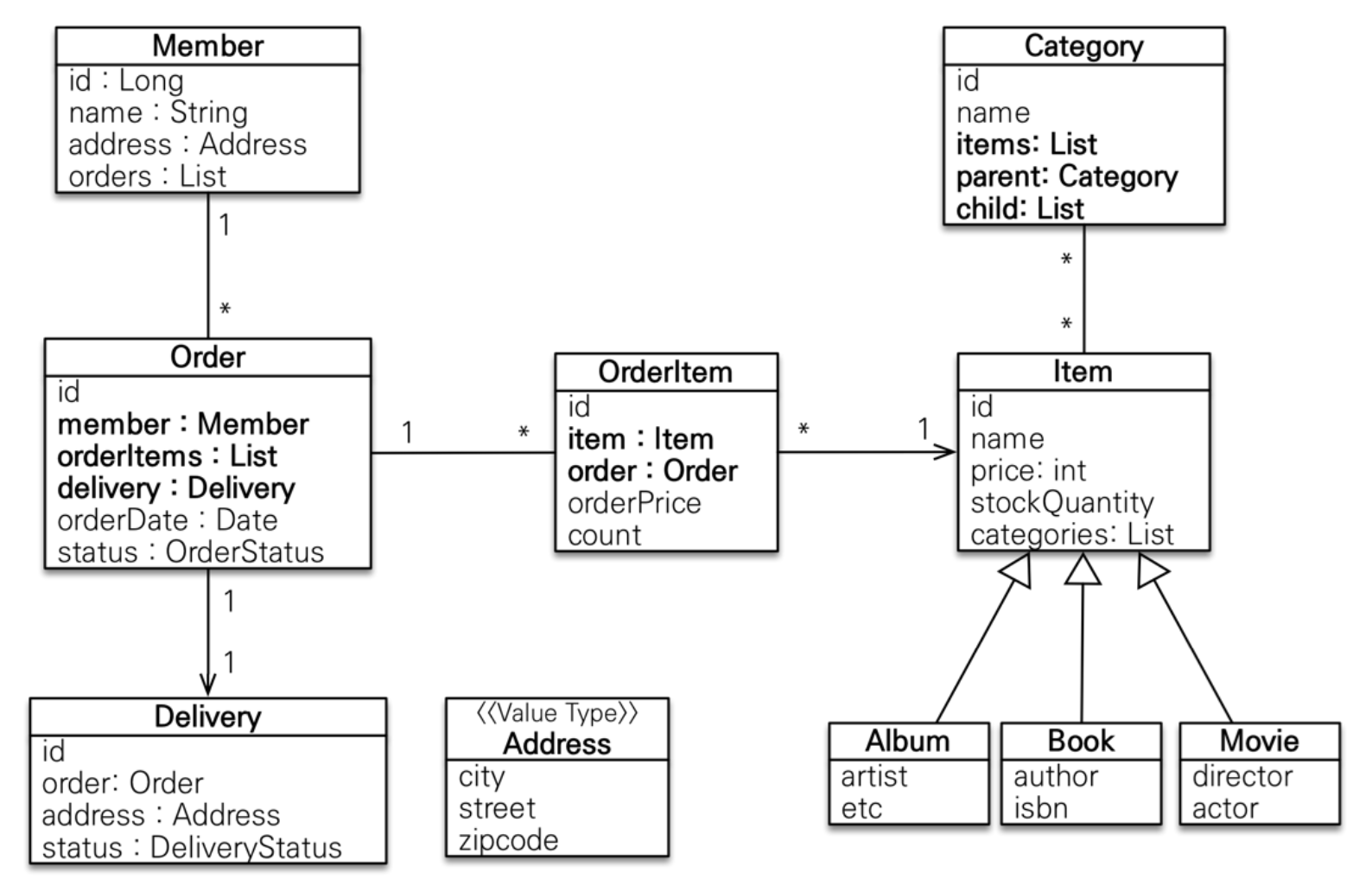
(참고로, 위의 엔티티 테이블에서 확인할 수 있듯이 주문과 주문상품(OrderItem)은 일대다 관계이며, 주문상품과 상품(Item)은 다대일 관계로 구성되어 있다)
이전 글인 지연 로딩과 조회 성능 최적화 부분에서는 toOne(OneToOne, ManyToOne) 관계에 대한 해결책을 정리했다.
이번에는 컬렉션인 엔티티 조회를 기준으로 일대다(OneToMany) 관계를 조회하고, 최적화하는 방법을 알아보자.
앞서, 이번 글에서는 V1(엔티티 직접 노출), V2(엔티티를 조회해서 DTO로 변환)은 이전 글에서 이미 다루었기 때문에 생략했다.
주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화
OrderApiController에 추가
@RestController
@RequiredArgsConstructor
public class OrderApiController {
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithItem();
for (Order order : orders) {
System.out.println("order ref=" + order + " id=" + order.getId());
}
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}
}
출력결과
order ref=jpabook.jpashop.domain.Order@27dc3bfe id=4
order ref=jpabook.jpashop.domain.Order@27dc3bfe id=4
order ref=jpabook.jpashop.domain.Order@300b5fd6 id=11
order ref=jpabook.jpashop.domain.Order@300b5fd6 id=11
-
DB 참조값, JPA pk id 값이 동일하게 2번 반복되어 출력되는 것을 확인할 수 있다.
-
동일하게 반복된 부분을 제거하기 위해 DB 쿼리문에서
distinct를 추가해주면 된다.
OrderRepository에 추가
@Repository
@RequiredArgsConstructor
public class OrderRepository {
private final EntityManager em;
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.setFirstResult(1)
.setMaxResults(100)
.getResultList();
}
}
-
페치 조인(fetch join)으로 SQL이 1번만 실행된다.
-
현재 Order(주문)과 OrderItem(주문상품)의 관계는 일대다 관계이면서 조인이 있으므로 데이터베이스의 row가 증가한다.
-
그 결과 같은 order 엔티티의 조회 수도 증가하게 된다.
-
이런 반복된 부분을 제거하기 위해 SQL에
distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러주게 된다. -
위의 예시처럼
order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다. -
하지만 이런 경우 단점이 존재한다.
-
컬렉션 페치 조인을 사용하면 페이징이 불가능하다.
-
하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버려 매우 위험한 결과를 초래한다.
-
-
컬렉션 페치 조인은 1개만 사용할 수 있다. 컬렉션 둘 이상에 페치 조인을 사용하게 되면 데이터가 부정합하게 조회 될 수 있기 때문에 사용해선 안된다.
(자세한 내용은 자바 ORM 표준 JPA 프로그래밍을 참고하자)
주문 조회 V3.1: 엔티티를 DTO로 변환 - 페이징과 한계 돌파
그렇다면 페이징 + 컬렉션 엔티티를 함께 조회하려면 어떻게 해야할까?
페이징 문제 해결 방안
-
먼저 ToOne(OneToOne, ManyToOne) 관계를 모두 페치 조인한다.
-
ToOne관계는 row 수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다. -
켈력선은 지연 로딩으로 조회한다.
-
지연 로딩 성능 최적화를 위해 다음 2가지를 중 1개를 사용하면 된다.
-
[1] 글로벌 설정: application.yml 파일에
hibernate.default_batch_fetch_size를 추가한다. -
[2] 개별 최적화: 적용할 엔티티 클래스, 컬렉션 필드 위에
@BatchSize을 추가한다. -
이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
-
OrderRepository에 추가
@Repository
@RequiredArgsConstructor
public class OrderRepository {
private final EntityManager em;
// 재사용성 O
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class
).getResultList();
}
}
OrderApiController에 추가
/**
* V3.1 엔티티를 조회해서 DTO로 변환 페이징 고려
*-ToOne 관계만 우선 모두 페치 조인으로 최적화
* - 컬렉션 관계는 hibernate.default_batch_fetch_size, @BatchSize로 최적화 */
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(@RequestParam(value = "offset",
defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue
= "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset,
limit);
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}
}
최적화 옵션 - 글로벌
spring: jpa:
properties:
hibernate:
default_batch_fetch_size: 1000
-
만약, 글로벌 설정이 아닌 개별로 설정하려면
@BatchSize를 적용하면 된다. -
이렇게 최적화 옵션을 적용하면 다음과 같은 장점이 존재한다.
-
쿼리 호출 수가
1 + N->1 + 1로 최적화 된다. (N+1 문제 해결) -
조인보다 DB 데이터 전송량이 최적화 된다. (Order와 OrderItem을 조인하면 Order가 OrderItem 만큼 중복해서 조회된다. 이 방법은 각각 조회하므로 전송해야할 중복 데이터가 없다)
-
페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 데이터 전송량이 감소한다.
-
컬렉션 페치 조인은 페이징이 불가능하지만, 이 방법은 페이징이 가능하다.
-
-
결론
-
ToOne관계는 페치 조인해도 페이징에 영향을 주지 않는다. -
따라서
ToOne관계는 페치 조인으로 쿼리 수를 줄이고, 나머지는hibernate.default_batch_fetch_size로 최적화하자.
-
-
참고로,
default_batch_fetch_size의 크기는 100 ~ 1000 사이 선택하는 것을 권장한다. DB에 따라 IN 절 파라미터를 1000으로 제한하기도 한다.-
예시) 1000으로 잡으면 한번에 1000개를 DB에서 애플리케이션에 불러오므로 DB에 순간 부하가 증가할 수 있다.
-
하지만 애플리케이션은 100이든 1000이든 결국 전체 데이터를 로딩해야 하므로 메모리 사용량이 같다.
-
즉, DB든 애플리케이션이든 순간 부하를 어디까지 견딜 수 있는지로 결정하면 된다.
-
Review
컬렉션이 포함된 조회인 경우 어떻게 해야 최적화 되는지 알게 되는 강의였다.
다대일, 일대일 관계처럼 ToOne 관계는 페치 조인으로 하고 일대다 관계인 ToMany인 경우 개별적으로 @BatchSize 하거나 또는 글로벌 설정으로 hibernate.default_batch_fetch_size을 적용하자.
이번 시간에는 엔티티 조회를 기준으로 컬렉션에 대한 조회를 최적화하는 방법을 정리했다.
다음 시간에는 DTO 직접 조회를 기준으로 컬렉션에 대한 조회를 최적화 하는 방법을 정리해보자.