- Prologue
- Filter vs. HandlerInterceptor
- 프로젝트 환경 구성
- HttpLogMessage
- RequestAndResponseLoggingFilter
- 멀티쓰레드 환경에서 request 식별자 필요성
- MDC로 traceId 설정 및 적용
- logback.xml 에 traceId 설정
- Filter 순서 조정
- 최종 결과
- Summary
- References
Prologue
이번 포스팅에서는 Spring Boot 프로젝트에서 HTTP 요청과 응답을 효과적으로 로깅하고,
멀티쓰레드 환경에서 요청 흐름을 명확히 추적할 수 있도록 traceId 를 활용하는 방법을 소개합니다.
일반적으로
- 단일 서비스에서는
requestId로 요청을 구분하고, - 분산 시스템(마이크로서비스) 에서는
traceId로 전체 요청 흐름을 추적합니다.
이 글에서는 단일 서비스 환경을 다루지만, 초기부터 traceId를 적용하여 향후 분산 시스템에서도 확장 가능한 구조를 제공합니다.
특히, 실무에 적용한 내용을 중심으로 프로덕션 환경에서도 활용 가능한 실용적인 예제를 설명합니다.
예상 독자
-
Spring Boot 프로젝트에 Logging Filter를 적용하고자 하는 분
-
Filter와 HandlerInterceptor의 차이점을 알고 싶은 분
-
OncePerRequestFilter의 동작 원리와 사용 이유가 궁금한 분
-
멀티쓰레드 환경에서 로그가 뒤섞이는 문제를 해결하고 싶은 분
-
프로덕션 환경에 바로 적용 가능한 실용적인 예제를 찾는 분
관련 포스팅
Filter vs. HandlerInterceptor
해당 섹션에 대한 자세한 내용은 이 글을 참고해 주시기 바랍니다.
아래 세부 섹션에 있는 내용은 해당 글과 다른 자료들을 종합해서 정리했습니다.
Filter
Filter는 Spring Framework의 일부가 아닌 웹 서버(servlet container) 수준의 컴포넌트입니다.
요청과 응답을 서블릿이 처리하기 전후로 가로채어 조작할 수 있습니다.
대표적인 예로 Spring Security가 있습니다.
Spring Security 에서는 인증/인가를 위해 여러 개의 Filter 체인을 사용하며, 이를 Spring과 연동하기 위해 DelegatingFilterProxy를 활용합니다.
이 구조 덕분에 Spring Security는 Spring MVC에 종속되지 않고도 동작할 수 있습니다.
Filter는 다음과 같은 메서드를 제공합니다.
init: 필터 초기화 시 호출doFilter: 요청과 응답을 가로채어 처리 (핵심 메서드)destroy: 필터 종료 시 호출
HandlerInterceptor
HandlerInterceptor는 Spring MVC Framework의 일부로,
디스패처 서블릿(DispatcherServlet)과 컨트롤러(Controller) 사이에서 동작합니다.
요청이 컨트롤러에 도달하기 전이나, 뷰가 렌더링된 후에 요청을 가로챌 수 있습니다.
HandlerInterceptor는 다음과 같은 메서드를 제공합니다.
preHandle: 컨트롤러 실행 이전 호출postHandle: 컨트롤러 실행 이후, 뷰 렌더링 이전 호출afterCompletion: 요청 처리 완료 후 (뷰 렌더링 완료 후) 호출
Filter와 HandlerInterceptor의 차이
요청-응답 흐름에서 Filter와 HandlerInterceptor는 다음과 같은 위치에 있습니다.
요청-응답 흐름: Client → Filter → DispatcherServlet → InterHandlerInterceptorceptor → Controller
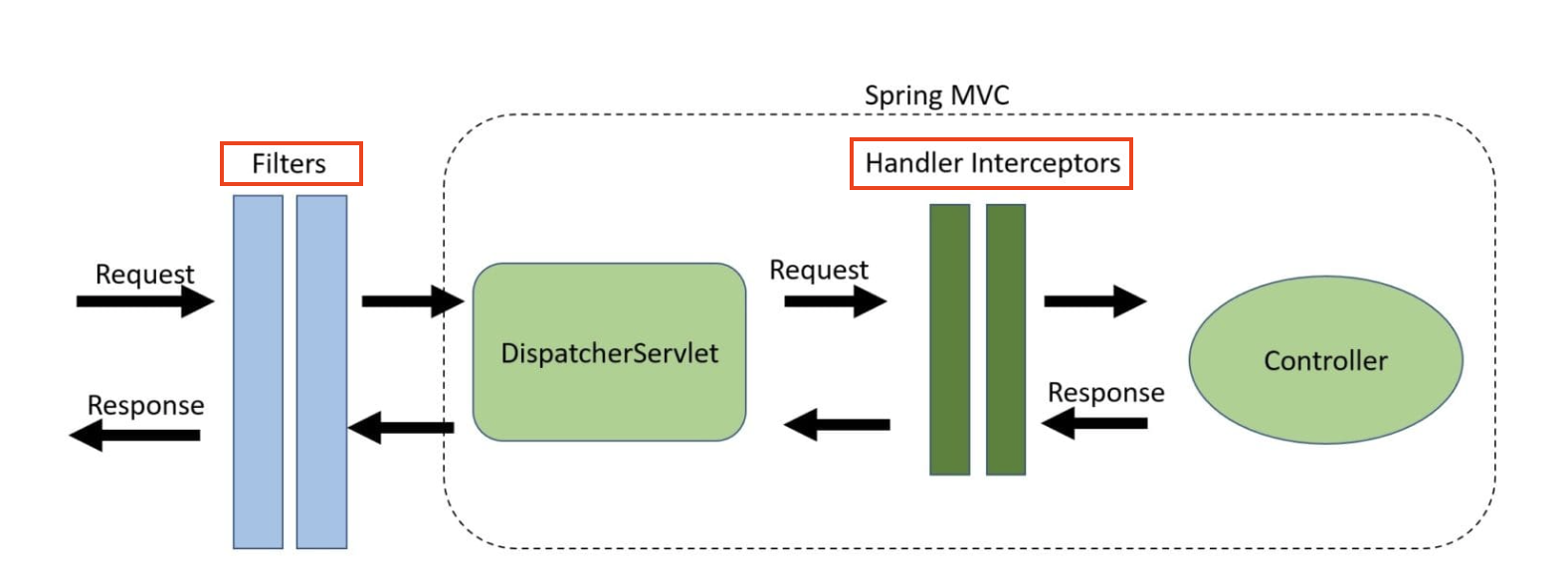
Filter는 다음과 같은 경우 사용합니다.
- 인증(Authentication) 및 인가(Authorization)
- 로깅(Logging) 및 감사(Auditing)
- 이미지(Image) 및 데이터 압축(data compression)
- Spring MVC와 분리된 전역 처리가 필요할 때
HandlerInterceptor 는 다음과 같은 경우 사용합니다.
- 애플리케이션 로깅과 같은 관점 지향적 처리 (cross-cutting concerns)
- 세밀한 권한 검사
- Spring context나 모델 조작
정리하면,
- Filter 는 Spring MVC 외부에서 동작하며, 전역적인 요청/응답 처리가 필요할 때 사용합니다.
- HandlerInterceptor 는 Spring MVC 내부에서 동작하며, 컨트롤러와 관련된 로직을 조작할 때 사용합니다.
Filter를 선택한 이유
실무에서 Filter를 적용한 이유는 다음과 같습니다.
- 요청(Request)과 응답(Response)을 가장 먼저, 그리고 마지막으로 다룰 수 있기 때문입니다.
- 클라이언트가 보낸 요청을 가장 먼저 받아서 로깅할 수 있고,
- 클라이언트에게 응답을 보내기 직전 상태로 로깅할 수 있습니다.
- 또한, 요청과 응답의 헤더(Header)를 포함한 원본을 조작하거나 확인할 수 있습니다.
- HandlerInterceptor 에서는
HttpServletRequest,HttpServletResponse를 조작하긴 어렵지만, - Filter 에서는 이를 자유롭게 다룰 수 있습니다.
- HandlerInterceptor 에서는
- 마지막으로
Spring MVC에 종속되지 않은 범용적인 처리가 가능합니다.- 인증/인가, 보안 처리 등은 DispatcherServlet과 무관하게 항상 동작해야 하므로 Filter가 적합합니다.
- 예를 들어, 정적 리소스 요청이나 예외 처리 페이지 등 Spring MVC가 관여하지 않는 흐름에서도 Filter는 동작할 수 있습니다.
아래부터는 Filter를 프로젝트에 적용하기 위해 어떤 환경을 구성했고, 어떻게 구현을 진행했는지 구체적인 과정을 설명드리겠습니다.
프로젝트 환경 구성
이 글에서 다루는 모든 코드는 깃허브에서 확인하실 수 있습니다.
filter 코드 관련 패키지 경로: dev.be.core.api.support.filter
(추가 - 2025.04.26) 시간이 지남에 따라 해당 코드가 변경될 수 있습니다.
- Spring Boot 3.2.5
- Java 21
- Multi Module (시간이 지남에 따라 모듈 구조가 변할 수 있습니다)
- Gradle 8.1
HttpLogMessage
아래와 같이 요청(request)과 응답(response) 내용에 넣을 정보를 정리합니다.
- request
http method: 요청 메서드 (예시: GET, POST, PUT, PATCH, DELETE 등)url: 요청 API 경로 (예시: /api/health )headers: 요청에 포함된 HTTP 헤더 목록 (key: value 형태) (예시: Content-Type: application/json; User-Agent: PostmanRuntime/7.43.3)request body: 요청 본문 (JSON, XML, Form 등)
- response
http status: 응답 상태 코드 및 메시지 (예시: 200 OK, 404 Not Found)response body: 응답 본문 (JSON, XML 등)
Logging의 대상이 되는 http 프로토콜 관련 정보들을 Spring Boot Application에 사용하기 위해 HttpLogMessage 클래스를 생성하여 위의 정보를 바탕으로 필드를 추가해줍니다.
HttpLogMessage.class
public record HttpLogMessage(
String httpMethod,
String url,
HttpStatus httpStatus,
String headers,
String requestBody,
String responseBody
) {
// ...
}
RequestAndResponseLoggingFilter
그런 다음, 요청(Request)과 응답(Response)을 로깅하는 Filter 클래스를 아래와 같이 구현했습니다.
RequestAndResponseLoggingFilter.java
@Component
@Order(Ordered.HIGHEST_PRECEDENCE) // 모든 필터 중 가장 먼저 실행되도록 설정 (요청/응답 전체를 로깅하기 위함)
public class HttpRequestAndResponseLoggingFilter extends OncePerRequestFilter {
private final Logger log = LoggerFactory.getLogger(HttpRequestAndResponseLoggingFilter.class);
@Override
protected void doFilterInternal(@NonNull final HttpServletRequest request,
@NonNull final HttpServletResponse response,
@NonNull final FilterChain filterChain) {
ContentCachingRequestWrapper requestWrapper = new ContentCachingRequestWrapper(request);
ContentCachingResponseWrapper responseWrapper = new ContentCachingResponseWrapper(response);
try {
filterChain.doFilter(requestWrapper, responseWrapper);
// HttpLogMessage 생성
HttpLogMessage logMessage = new HttpLogMessage(
requestWrapper.getMethod(),
requestWrapper.getRequestURI(),
HttpStatus.valueOf(responseWrapper.getStatus()),
getRequestHeaders(requestWrapper),
getRequestBody(requestWrapper),
getResponseBody(responseWrapper)
);
log.info("\n{}", toPrettierLog(logMessage));
} catch (Exception e) {
handleException(e);
} finally {
try {
responseWrapper.copyBodyToResponse();
} catch (IOException copyException) {
log.error("[RequestAndResponseLoggingFilter] I/O exception occurred while copying response body", copyException);
}
}
}
// ...
}
위의 클래스에서 사용하는 주요 Filter 관련 클래스를 하나씩 살펴보겠습니다.
OncePerRequestFilter
Spring에서 필터를 적용할 때 요청(Request)이 여러 번 디스패치(Dispatch) 되는 경우가 있습니다.
특히, 비동기(Async)나 에러(Error) 처리가 발생하면 필터가 중복 실행될 수 있습니다.
이런 중복 실행을 방지하기 위해 Spring에서는 OncePerRequestFilter라는 추상 클래스를 제공합니다.
이름 그대로 “하나의 요청 당 한 번만 실행” 되도록 보장해주는 필터입니다.
주요 특징
- 요청(Request)마다 단 한 번만 필터 실행.
- 비동기(Async) 및 에러(Error) 디스패치 시에도 중복 실행 여부를 제어.
- 내부적으로 request attribute를 사용해 중복 실행을 방지.
OncePerRequestFilter.class (Java 17 기준) - 핵심 동작 코드
해당 클래스에 대한 자세한 설명은 공식 문서를 참고해 주시기 바랍니다.
public abstract class OncePerRequestFilter extends GenericFilterBean {
public final void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws ServletException, IOException {
// HTTP 프로토콜 기반 요청/응답만 처리 (ServletRequest/ServletResponse는 상위 개념)
if (request instanceof HttpServletRequest httpRequest) {
if (response instanceof HttpServletResponse httpResponse) {
// "이미 필터가 실행됐는지" 체크할 attribute 이름을 가져옴
String alreadyFilteredAttributeName = this.getAlreadyFilteredAttributeName();
boolean hasAlreadyFilteredAttribute = request.getAttribute(alreadyFilteredAttributeName) != null;
// 디스패치(Dispatch) 타입이 skip 대상이 아니고, 필터링을 하지 않아야 할 경우도 아닌 경우만 필터 수행
if (!this.skipDispatch(httpRequest) && !this.shouldNotFilter(httpRequest)) {
// 이미 필터가 실행된 경우
if (hasAlreadyFilteredAttribute) {
// 만약 에러 디스패치(DispatcherType.ERROR)라면, 별도로 정의된 error 처리 필터를 수행
if (DispatcherType.ERROR.equals(request.getDispatcherType())) {
this.doFilterNestedErrorDispatch(httpRequest, httpResponse, filterChain);
return;
}
// 이미 실행된 경우 → 그냥 다음 필터로 넘김
filterChain.doFilter(request, response);
} else {
// 첫 실행인 경우
request.setAttribute(alreadyFilteredAttributeName, Boolean.TRUE);
try {
// 실제 필터 로직 실행 (여기서 doFilterInternal 오버라이드)
this.doFilterInternal(httpRequest, httpResponse, filterChain);
} finally {
// 필터 로직 실행 후 → 마킹 attribute 제거
request.removeAttribute(alreadyFilteredAttributeName);
}
}
} else {
// skip 대상(Async, Error 등) → 필터 건너뛰고 다음 필터 체인 실행
filterChain.doFilter(request, response);
}
return; // HTTP 요청 처리가 끝났으면 반환
}
}
// HTTP 요청이 아니면 예외 발생
throw new ServletException("OncePerRequestFilter only supports HTTP requests");
}
// ...
}
위 클래스에 있는 코드를 정리하면,
- 중복 실행을 막기 위해 요청에 “이미 실행됨” 표시(attribute)를 남깁니다.
- 이후 다시 호출될 경우 필터를 생략하고, 다음 필터 체인으로 넘깁니다.
- 실제 필터 로직은
doFilterInternal()에서 오버라이드하여 구현합니다.
이를 통해 요청/응답 로깅 필터도 중복 실행 없이 한 번만 동작하도록 설정한 것입니다.
이러한 구조를 활용하여 HttpRequestAndResponseLoggingFilter 클래스에서 doFilterInternal() 메서드를 오버라이드해서 구현한 것입니다.
요청/응답 본문 캐싱 (ContentCachingWrapper)
제가 오버라이딩해서 구현한 doFilterInternal 메서드에 내부에는 요청(Request)과 응답(Response) 본문을 로깅하기 위해 ContentCachingRequestWrapper, ContentCachingResponseWrapper 를 사용했습니다.
왜 필요한가? -> Stream은 기본적으로 한 번만 읽을 수 있는 구조입니다. 한 번 데이터를 읽으면 포인터가 이동하고, 다시 읽을 수 없습니다.
InputStream 과 관련하여 동작 원리에 대한 자세한 설명은 이 글 을 참고해 주시기 바랍니다
InputStream 을 예로 들면,
-
InputStream 내부에는 포인터(pos) 가 있어서, read()를 호출하면 포인터가 앞으로 이동하고, 다시 같은 데이터를 읽을 수 없습니다.
-
이 때문에 Request body나 Response body를 한 번 읽고 나면, 서버 내부에서 재사용할 수 없습니다.
이러한 문제를 해결하기 위해
ContentCachingRequestWrapper, ContentCachingResponseWrapper 는 Stream을 메모리에 캐싱해서 여러 번 읽을 수 있도록 지원합니다.
쉽게 말해, Stream을 복사해두고 재사용하는 방식으로, InputStream 캐싱과 비슷한 원리입니다.
ContentCachingRequestWrapper - 내부 동작
해당 두 개의 클래스 중 하나인 ContentCachingRequestWrapper 에 대해 내부 코드를 살펴보면 다음과 같습니다.
해당 클래스에서 Stream을 어떻게 캐싱하는지 간단히 살펴보겠습니다.
ContentCachingRequestWrapper.class
public class ContentCachingRequestWrapper extends HttpServletRequestWrapper {
private final FastByteArrayOutputStream cachedContent;
// ...
public ServletInputStream getInputStream() throws IOException {
if (this.inputStream == null) {
this.inputStream = new ContentCachingInputStream(this.getRequest().getInputStream());
}
return this.inputStream;
}
// ...
}
-
FastByteArrayOutputStream으로 Request body를 메모리에 저장합니다.
-
getInputStream()을 호출하면, 실제HttpServletRequest.getInputStream()을 ContentCachingInputStream 으로 감싸서, 읽을 때마다 캐시에 저장합니다.
public int read(final byte[] b, final int off, final int len) throws IOException {
int count = this.is.read(b, off, len);
this.writeToCache(b, off, count);
return count;
}
- 요청 본문을 읽을 때마다 캐시에 저장되기 때문에, 나중에 동일한 데이터를 다시 읽을 수 있습니다.
ContentCachingResponseWrapper - 내부 동작
public class ContentCachingResponseWrapper extends HttpServletResponseWrapper {
private final FastByteArrayOutputStream content = new FastByteArrayOutputStream(1024);
@Nullable
private ServletOutputStream outputStream;
@Nullable
private PrintWriter writer;
@Nullable
private Integer contentLength;
public ContentCachingResponseWrapper(HttpServletResponse response) {
super(response);
}
}
-
해당 클래스도
ContentCachingRequestWrapper와 마찬가지로, 내부적으로 FastByteArrayOutputStream을 사용해 Response body를 메모리에 캐싱합니다. -
그리고
getOutputStream()(또는getWriter()) 를 호출하면, 실제 응답 스트림을 감싸는 ResponseServletOutputStream (또는 ResponsePrintWriter)를 반환합니다.
public ServletOutputStream getOutputStream() throws IOException {
if (this.outputStream == null) {
this.outputStream = new ResponseServletOutputStream(this.getResponse().getOutputStream());
}
return this.outputStream;
}
- Response body 은 쓰기 시점에 캐시에 저장됩니다.
copyBodyToResponse()메서드가 중요한 이유
ContentCachingResponseWrapper는 응답 본문을 캐시에 쌓아놓기만 하고, 자동으로 클라이언트에게 전송하지 않습니다.copyBodyToResponse()를 호출해야만 캐시에 저장된 응답 본문을 클라이언트로 전송합니다.- 만약 이 메서드를 호출하지 않으면, 클라이언트가 응답을 받지 못하는 상황이 발생합니다.
그래서 보통 finally 블록에서 항상 호출해줘야 응답이 정상적으로 전송됩니다.
@Override
protected void doFilterInternal(@NonNull HttpServletRequest request,
@NonNull HttpServletResponse response,
@NonNull FilterChain filterChain) {
ContentCachingRequestWrapper requestWrapper = new ContentCachingRequestWrapper(request);
ContentCachingResponseWrapper responseWrapper = new ContentCachingResponseWrapper(response);
try {
filterChain.doFilter(requestWrapper, responseWrapper);
// 로그 출력
} catch (Exception e) {
handleException(e);
} finally {
try {
responseWrapper.copyBodyToResponse(); // 응답 전송
} catch (IOException ex) {
log.error("[RequestAndResponseLoggingFilter] I/O exception occurred while copying response body", ex);
}
}
}
대용량 데이터 처리 시 주의할 점
본 예제 코드에서는 대용량 데이터에 대한 캐시 제한을 따로 적용하지 않았습니다.
이 부분은 추후 더 깊이 다루거나, 다른 포스팅에서 별도로 소개할 계획입니다.
ContentCachingRequestWrapper 와 ContentCachingResponseWrapper 는 요청/응답 본문을 메모리에 캐싱하기 때문에,
편리하게 여러 번 읽거나 기록할 수 있습니다.
하지만 모든 데이터를 메모리에 저장한다는 점에서 몇 가지 주의할 사항이 있습니다.
특히 대용량 요청/응답을 처리할 때는 아래와 같은 문제가 발생할 수 있습니다.
-
OutOfMemoryError (OOM) 발생 가능성
-
ContentCachingRequestWrapper, ContentCachingResponseWrapper 두 개의 클래스 모두 요청/응답 전체 본문(body) 내용을 메모리에 저장하는 공통점이 있습니다.
-
(1) 대용량 파일을 다운로드 하거나 (2) 대량의 JSON 요청/응답의 경우 (보통은 응답의 비중이 큼) FastByteArrayOutputStream 에 전부 쌓이기 때문에, 메모리 부족(Out of Memory) 현상이 발생하게 됩니다.
-
대응 방법
-
본문 크기를 제한하거나 일부만 로깅하는 방식도 고려할 수 있습니다.
-
대용량 파일 다운로드 API는 캐싱 대상에서 제외하는 것도 좋은 방법입니다.
-
-
-
캐시 크기 제한 설정 필요 (Request vs Response)
-
Request(요청):
ContentCachingRequestWrapper에서는 생성자에서contentCacheLimit을 설정할 수 있지만, -
Response(응답):
ContentCachingResponseWrapper에서는 기본적으로 캐시 크기 제한이 없습니다. 필요하다면,handleContentOverflow()메서드를 오버라이드해 캐시 용량 초과 시 별도로 처리할 수 있습니다.
-
-
copyBodyToResponse() 호출 시점에 대한 응답 전송 지연 가능성
-
일반적으로 응답 데이터를 모두 캐시에 쌓아둔 다음에
copyBodyToResponse()로 한 번에 클라이언트에 전송합니다. -
하지만, 대용량 데이터를 응답하는 경우, 메모리가 오래 유지됨으로써 클라이언트에게 전송이 지연될 수 있습니다.
-
대응 방법
-
응답 크기가 임계치를 넘으면 즉시 전송하는 구조를 고려할 수 있습니다.
-
또는, 대용량 응답 API는 로깅 자체를 생략하는 방식도 가능합니다.
-
-
Logging 요청/응답 format
HttpRequestAndResponseLoggingFilter 에서는 요청(Request)과 응답(Response)을 아래와 같은 고정된 포맷으로 출력합니다.
(Logging 포맷 형식의 경우는 개발자 마음이기 때문에 아래 방식 외에 본인이 원하는 방식으로 적용하셔도 됩니다)
HttpRequestAndResponseLoggingFilter.java - toPrettierLog 메서드
@Component
public class HttpRequestAndResponseLoggingFilter extends OncePerRequestFilter {
private String toPrettierLog(final HttpLogMessage msg) {
// Java 15+ 텍스트 블록 (""") 사용
return """
[REQUEST] %s %s [RESPONSE - STATUS: %s]
>> HEADERS: %s
>> REQUEST_BODY: %s
>> RESPONSE_BODY: %s
""".formatted(
msg.httpMethod(), msg.url(), msg.httpStatus(),
msg.headers(), msg.requestBody(), msg.responseBody()
);
}
}
-
Java 15+에서 지원하는 텍스트 블록 (“””) 을 활용해, 로그 메시지를 가독성 좋게 정렬합니다.
-
%s포맷팅으로 요청 메서드, URL, 응답 상태, 헤더, 본문 등을 채웁니다.
Logging 출력 예시
Swagger url:
http://localhost:8080/service-docs.html
해당 SpringBoot Application 을 실행한 뒤, controller 패키지에 있는 HealthController 클래스에 있는 api 를 호출하면 아래와 같이 출력되는 것을 확인할 수 있습니다.
- [GET] url:
http://localhost:8080/api/health

이번에는 controller/v1 패키지에 있는 ExamplePostController 클래스에 있는 다른 api를 호출해보겠습니다.
- [POST] url:
http://localhost:8080/api/posts/new

멀티쓰레드 환경에서 request 식별자 필요성
지금까지는 각 request마다 HTTP 요청/응답 본문을 로깅하는 작업을 진행했습니다. 하지만 이 상태에서는 요청을 구분할 식별자가 로그에 포함되지 않아, 멀티쓰레드 환경에서는 서로 다른 요청의 로그가 뒤섞이는 문제가 발생할 수 있습니다.
왜 request 식별자가 필요한가?
Spring Boot는 멀티쓰레드 기반으로 요청을 처리하며, 운영체제(OS)는 컨텍스트 스위칭을 통해 여러 쓰레드를 번갈아가며 실행합니다.
이 때문에 여러 요청이 동시에 들어올 때, 서로 다른 요청의 로그가 섞여 출력될 수 있습니다.
이를 방지하고 요청 흐름을 명확히 구분하기 위해서는 각 요청마다 고유한 식별자 를 로그에 남기는 것이 필수적입니다.
requestId vs traceId
requestId와 traceId의 역할은 아래와 같습니다.
-
requestId: 단일 서비스에서 요청을 구분하는 식별자. -
traceId: 분산 시스템(마이크로서비스) 환경에서 여러 서비스를 오가는 요청 전체 흐름을 추적하는 식별자.
이 식별자는 Kibana, Grafana와 같은 모니터링 도구에서 로그를 검색하거나 요청 흐름을 추적할 때도 유용하게 활용됩니다.
(이번 포스팅에서는 단일 서비스 기준에서는 흔히
requestId를 사용하지만, 본 포스팅에서는 분산 추적 확장을 고려해traceId라는 용어를 사용합니다. 향후 Spring Cloud Sleuth 등을 도입할 경우traceId,spanId로 자연스럽게 확장 가능합니다.
다음 섹션에서는 MDC(Mapped Diagnostic Context) 를 활용해
요청마다 traceId 를 자동으로 설정하고, 이를 Logback 포맷에 적용하는 방법을 설명하겠습니다.
(참고로, 현재 제가 속한 팀에서는 userId를 추가로 활용해 특정 사용자의 요청 흐름을 더 쉽게 추적하고 있습니다.)
MDC로 traceId 설정 및 적용
MDC에 대한 자세한 내용은 이 글을 참고해 주시기 바랍니다.
멀티쓰레드 환경에서 각 요청(request)의 로그를 식별하고 추적하기 위해 Spring Boot + Logback 환경에서 MDC(Mapped Diagnostic Context) 를 활용했습니다.
MDC를 적용한 이유는 다음과 같습니다.
-
MDC는 각 쓰레드별로 별도의 컨텍스트(Context)를 유지할 수 있게 해줍니다.
-
이 컨텍스트에 traceId, requestId와 같은 식별자 정보를 저장하면, 로그를 남길 때마다 해당 정보를 함께 출력할 수 있습니다.
MDC는 ThreadLocal과 유사하게 현재 실행 중인 쓰레드에만 국한된 정보를 저장합니다.
MDC의 동작 방식을 간단하게 설명드리자면,
(이번 포스팅에서는 단일 서비스 기준으로 requestId 대신 traceId 라는 이름을 사용했습니다.)
-
MDC에 traceId(requestId 역할)를 저장합니다.(예시.
MDC.put("traceId", "1234-5678-qwer")) -
그리고 logback.xml 과 같은 로그 포맷에서
%X{traceId}와 같은 형태로 MDC 값을 가져와 출력합니다. -
요청 처리가 완료되면 메모리 누수 방지를 위해 해당 MDC를 제거합니다. (예시.
MDC.remove(TRACE_ID))
이 과정을 통해, 각 요청마다 고유한 traceId가 로그에 출력되며, 멀티쓰레드 환경에서도 로그가 뒤섞이지 않고 요청 흐름을 명확히 추적할 수 있습니다.
이로써 요청 흐름을 쉽게 구분하고, 문제를 효과적으로 추적할 수 있습니다.
위에서 작성한 HttpRequestAndResponseLoggingFilter 클래스에 MDC로 traceId를 추가하여 구현한 코드는 아래와 같습니다.
public class HttpRequestAndResponseLoggingFilter extends OncePerRequestFilter {
private final Logger log = LoggerFactory.getLogger(HttpRequestAndResponseLoggingFilter.class);
private static final String TRACE_ID = "traceId";
@Override
protected void doFilterInternal(@NonNull final HttpServletRequest request,
@NonNull final HttpServletResponse response,
@NonNull final FilterChain filterChain) {
ContentCachingRequestWrapper requestWrapper = new ContentCachingRequestWrapper(request);
ContentCachingResponseWrapper responseWrapper = new ContentCachingResponseWrapper(response);
final String traceId = UUID.randomUUID().toString().substring(0, 32);
MDC.put(TRACE_ID, traceId);
try {
filterChain.doFilter(requestWrapper, responseWrapper);
// ...
} catch (Exception e) {
handleException(e);
} finally {
// ...
MDC.remove(TRACE_ID);
}
}
}
참고:
MDC는 단일 JVM 내에서만 컨텍스트를 유지하므로, 외부 API 통신이 많은 분산 환경 시 traceId 가 전파되지 않습니다. 이런 분산 환경에서는 Spring Cloud Sleuth 를 도입해 traceId/spanId를 자동으로 생성하고 서비스 간에 전파할 수 있습니다.
logback.xml 에 traceId 설정
현재 local 환경에서 작업하고 있어서, logback-local.xml 파일에 아래와 같이 로그 패턴을 설정해줬습니다.
logback-local.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- traceId 적용 (현재는 단일 서비스 기준으로 requestId 역할, 분산 시스템에서는 traceId + spanId 구조로 확장 가능) -->
<pattern>%clr(%d{HH:mm:ss.SSS}){faint}|%clr(${level:-%5p})|%32X{traceId:-},%16X{spanId:-}|%clr(%-40.40logger{39}){cyan}%clr(|){faint}%m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<logger name="org.springframework" level="INFO"/>
<logger name="dev.be" level="DEBUG"/>
<root level="INFO">
<appender-ref ref="STDOUT"/>
</root>
</configuration>
Filter 순서 조정
마지막으로 Filter의 순서를 조정해야 합니다.
Spring Boot 프로젝트에서는 다양한 필터(Filter)를 사용하게 됩니다.
예를 들어, Spring Security Filter, CORS Filter, Custom Filter 등이 함께 동작할 수 있습니다.
이때, Logging Filter가 다른 필터보다 먼저 동작해야 요청(Request)과 응답(Response)의 전체 흐름을 가장 먼저/마지막으로 캡처할 수 있습니다.
예를 들어,
- Spring Security Filter가 먼저 동작하면, 인증/인가 과정 중 발생하는 예외나 리다이렉션을 Logging Filter가 캡처하지 못할 수 있습니다.
- 반대로, Logging Filter가 먼저 동작하면 모든 요청/응답을 정확히 캡처할 수 있습니다.
이를 위해 Filter의 순서를 명시적으로 조정합니다.
@Order(Ordered.HIGHEST_PRECEDENCE)
public class HttpRequestAndResponseLoggingFilter extends OncePerRequestFilter {
// ...
}
-
Ordered.HIGHEST_PRECEDENCE: 모든 필터 중 가장 먼저 실행되도록 설정합니다. -
이 설정 덕분에 모든 요청/응답 흐름을 가장 앞단에서 로깅할 수 있습니다.
최종 결과
이렇게 설정하면, traceId가 포함된 로그 출력을 확인할 수 있습니다.
- [GET] url: http://localhost:8080/api/health

로그에서 traceId가 포함되어, 동일한 요청 흐름의 로그를 쉽게 구분할 수 있습니다.
-
이렇게 하면 멀티쓰레드 환경에서도 요청별 로그 추적이 용이해지고,
-
나중에 Kibana, Grafana 같은 모니터링 도구에서도 traceId로 검색하여 요청 흐름을 한눈에 파악할 수 있습니다.
(현재는 단일 서비스 기준으로 traceId를 설정했지만, 향후 분산 시스템(마이크로서비스) 환경에서는 Spring Cloud Sleuth 같은 분산 추적 도구를 연동해 traceId + spanId 구조로 더 확장할 수 있습니다.)
Summary
이번 글에서는 Spring Boot 환경에서 요청과 응답을 로깅하는 필터를 적용하고, traceId를 활용해 멀티쓰레드 환경에서도 요청 흐름을 구분하는 방법을 정리했습니다.
처음에는 Filter와 HandlerInterceptor의 차이를 이해하는 것부터 시작해, ContentCachingWrapper를 이용한 요청/응답 본문 로깅, 대용량 데이터 처리 시 주의사항, 그리고 MDC를 활용한 traceId 설정까지 순차적으로 정리했습니다. 이 과정을 통해 요청별로 로그를 구분하고, Kibana나 Grafana와 같은 모니터링 도구를 통해서도 쉽게 추적할 수 있는 구조를 마련했습니다.
저 역시 처음 이 작업을 시작할 때는 관련 개념들이 생소하게 느껴졌지만, 내부 동작을 하나씩 파악하고 적용해보면서 많은 것을 배울 수 있었습니다.
이번 글에서 traceId로 개별 요청의 흐름을 추적할 수 있게 되었다면, 다음 포스팅에서는 한 걸음 더 나아가 Prometheus와 Grafana를 연동하여 애플리케이션의 전반적인 성능 상태를 한눈에 파악하는 모니터링 대시보드를 구축하는 방법을 다루어보겠습니다.
지금까지 읽어주셔서 감사합니다.