- Prologue
- 1. Prometheus와 Grafana
- 2. 핵심 성능 지표와 Prometheus 원시 데이터 이해하기
- 3. Grafana 대시보드 구성
- 4. 실전. 쿠폰 시스템 모니터링 환경 구축하기
- 5. 성능 분석 노하우 및 결론
- Summary
- References
Prologue
이번 포스팅에서는 성능 테스트와 시스템 운영 환경에서 어떤 지표를 주시해야 하는지, 그리고 Spring Boot 환경에서 Prometheus와 Grafana를 활용해 직접 모니터링 환경을 구축한 경험을 공유하고자 합니다.
빠른 응답 시간은 사용자 이탈률을 낮추고, 안정적인 시스템은 비즈니스 신뢰도를 높입니다. 그렇기 때문에 이러한 지표를 꾸준히 관찰하고 개선하는 것은 매우 중요하다고 생각합니다.
이전 포스팅이었던 “Spring Boot 요청 흐름 추적: Logging Filter와 traceId 적용기”에 이어, 이번 글에서는 3편을 작성해보고자 합니다.
이 글은 경험을 바탕으로 한 하나의 접근법이며, 정답이라기보다는 여러분이 각자의 상황에 맞는 최적의 방법을 찾아가는 데 도움이 되기를 바라는 마음으로 작성했습니다.
성능 테스트나 Prometheus, Grafana에 대한 기본적인 개념을 알고 계신다면 이 글을 수월하게 읽으실 수 있을 겁니다.
예상 독자
이 글은 아래에 해당하는 분들께 도움이 될 것입니다.
-
성능 테스트 시 어떤 지표를 봐야 할지 막막하신 분
-
Prometheus가 수집하는 핵심 지표의 의미가 궁금하신 분
-
Spring Boot 애플리케이션의 지표를 Grafana 대시보드로 직접 만들어보고 싶으신 분
참고: 본 글에서 소개되는 코드 예시는 현재 시점의 구현을 바탕으로 작성되었으며, 프로젝트가 발전함에 따라 내용이 변경되거나 개선될 수 있음을 미리 알려드립니다.이 글에서 다루는 모든 코드는 깃허브에서 확인하실 수 있습니다.
한 가지 명확히 하고 싶은 점은, 이 글에서 소개하는 핵심 원리는 다른 기술 스택에도 적용 가능하다는 것입니다. Prometheus와 Grafana는 특정 언어나 프레임워크에 종속되지 않는 범용적인 도구입니다.
다만, 이 글에서는 Spring Boot 환경에서 가장 편리하고 표준적인 방법인 Micrometer와 Actuator를 통해 지표를 수집하고 노출하는 과정을 다루기 때문에 ‘Spring Boot 기반’으로 설명합니다.
그럼 어떤 과정을 거쳤는지 설명해보겠습니다.
1. Prometheus와 Grafana
Spring Boot 기반으로 개발한 프로젝트의 특정 API 상태를 안정적으로 모니터링하기 위한 도구를 검토했습니다. 그 과정에서 Prometheus와 Grafana 조합이 가장 적합하다고 판단했고, 그 이유는 다음과 같습니다.
Prometheus
이 글에서는 Prometheus 에 대한 자세한 설명은 다루지 않으니, 공식 문서를 참고해 주시길 바랍니다.
Prometheus는 대상 시스템의 상태 지표(메트릭)를 수집하고 저장하는 데 특화된 오픈소스입니다. 이 도구를 선택한 데에는 몇 가지 기술적인 장점이 있었습니다.
-
Pull 방식 아키텍처
-
Prometheus는 모니터링 대상의 메트릭을 직접 가져오는(Pull) 구조로 동작합니다.
-
이 방식은 모니터링 대상에 문제가 생겨도 중앙에서 상태를 꾸준히 확인하고 관리하기에 용이했습니다. 특히 컨테이너처럼 동적으로 자원이 변하는 환경에서도 안정적으로 상태를 파악할 수 있다는 점이 장점이었습니다.
-
-
레이블 기반의 다차원 데이터 모델과 PromQL
-
수집하는 모든 데이터를 ‘메트릭 이름’과 ‘Key-Value 형태의 레이블’ 조합으로 저장하여, 데이터를 다각도로 조회하고 분석하는 데 편리합니다.
-
덕분에 전용 쿼리 언어인 PromQL을 통해 “특정 API에서 발생한 500 에러 중 특정 서버의 것만 집계”하는 등, 복잡하고 세밀한 조건의 데이터 조회가 가능했습니다.
-
-
신뢰성과 검증된 생태계
-
각 서버가 독립적으로 동작하기 때문에, 시스템 일부에 문제가 생겨도 모니터링 시스템은 의존성 없이 동작합니다. 장애 상황에서 원인을 파악하는 데 유용하다고 판단했습니다.
-
또한 경고를 보내주는 Alertmanager나 다른 시스템의 지표를 연결해주는 Exporter 등, 이미 잘 갖춰진 생태계를 통해 모니터링 환경을 유연하게 확장할 수 있다는 점도 고려했습니다.
-
Grafana
이 글에서는 Grafana 에 대한 자세한 설명은 다루지 않으니, 공식 문서를 참고해 주시길 바랍니다.
Grafana는 Prometheus가 수집한 데이터를 가장 효과적으로 보여주는 시각화 파트너입니다.
-
직관적인 데이터 시각화
-
Prometheus의 기본 UI만으로는 데이터의 추이나 패턴을 파악하기 어렵습니다. Grafana를 사용하면 수집된 데이터를 사용자가 원하는 거의 모든 형태로 시각화할 수 있습니다.
-
패널 종류나 쿼리, 범례, 색상 등을 직접 제어해서 서비스 상태에 대한 스토리가 담긴 대시보드를 만들 수 있어, 복잡한 데이터의 변화를 한눈에 파악하고 이상 징후를 빠르게 알아차리는 데 도움이 됩니다.
-
-
다양한 데이터 소스 연동
-
Grafana가 마음에 들었던 점 중 하나는 Prometheus 외에도 여러 데이터 소스를 지원한다는 것이었습니다.
-
예를 들어, 하나의 대시보드에 Prometheus의 성능 지표와 Elasticsearch의 로그 데이터를 함께 표시할 수 있습니다.
-
이를 통해 분산된 시스템의 여러 정보를 한곳에서 연관 지어 분석하는 통합적인 관점을 가질 수 있습니다.
-
마지막으로, 이 두 도구는 현재 업계에서 표준처럼 널리 쓰이고 있어 참고할 수 있는 공식 문서나 기술 블로그, 공개 대시보드가 많다는 현실적인 장점도 있었습니다. 덕분에 모니터링 시스템을 처음 구축하면서 겪는 시행착오를 줄이고, 관련 내용을 팀 내에서 공유하고 논의하기도 수월했습니다.
이제 이 도구들을 활용해 어떤 지표들을 봐야 하는지 구체적으로 살펴보겠습니다.
2. 핵심 성능 지표와 Prometheus 원시 데이터 이해하기
좋은 대시보드를 만들기 전에, 먼저 어떤 핵심 성능 지표를 주시해야 하는지, 그리고 이를 계산하기 위한 Prometheus의 원시 데이터(Raw Metrics)가 무엇인지 정리해 보았습니다.
저는 주로 다음 5가지 핵심 영역에 집중합니다.
처리량(TPS) 및 에러율 지표
얼마나 많은 요청을, 얼마나 안정적으로 처리하는가?
-
필요한 원시 지표:
http_server_requests_seconds_count -
타입: Counter (누적 계수기)
-
의미: HTTP 요청이 발생할 때마다 1씩 증가하는 누적 카운터입니다.
uri,method,status등 다양한 레이블을 통해 요청을 세분화할 수 있습니다. 이 단일 지표와rate()함수를 통해 초당 처리량(TPS)과 에러율을 모두 계산합니다.
응답 시간(Latency) 지표
요청 하나를 처리하는 데 시간이 얼마나 걸리는가?
-
필요한 원시 지표:
http_server_requests_seconds_sum -
타입: Counter
-
의미: 각 HTTP 요청의 처리 시간을 초(seconds) 단위로 모두 합산한 누적값입니다. 바로 위
_count지표와 함께 평균 응답 시간을 계산하는 데 필수적입니다.
CPU 사용량 지표
애플리케이션이 시스템의 CPU를 얼마나 사용하는가?
-
필요한 원시 지표:
process_cpu_usage -
타입: Gauge (현재 상태 값)
-
의미: 해당 JVM 프로세스가 최근 사용한 CPU 시간의 비율(0.0 ~ 1.0)입니다. 시스템 전체 CPU 자원 중 얼마나 점유했는지를 나타냅니다.
JVM 메모리 사용량 지표
애플리케이션의 메모리 상태는 건강한가?
- 필요한 원시 지표:
jvm_memory_used_bytes: 실제 사용 중인 힙 메모리jvm_memory_max_bytes: 설정된 최대 힙 메모리
-
타입: Gauge
- 의미: 이 두 지표를 통해 현재 메모리 사용량과 최대치 대비 사용률을 파악하여 메모리 누수나 부족 현상을 감지합니다.
이 외에도 jvm_threads_... (스레드 상태), jvm_gc_pause_seconds_... (GC 성능) 등의 지표도 중요하며, GitHub의 대시보드 JSON(coupon-prometheus-dashboard.json, coupon-kafka-dashboard.json) 파일에서 더 다양한 지표를 확인하실 수 있습니다.
3. Grafana 대시보드 구성
이제 2장에서 다룬 원시 지표들을 조합하여, 개인 프로젝트에서 실제로 사용했던 coupon-prometheus-dashboard.json의 핵심 패널들을 어떻게 구성했는지 보여드리겠습니다.
TPS (req/s)
초당 얼마나 많은 요청을 처리하는지 보여주는 처리량 지표입니다.
-
PromQL 쿼리:
rate(http_server_requests_seconds_count{uri=~"/api/coupon/.*/issue/test"}[1m]) -
쿼리 설명:
http_server_requests_seconds_count카운터의 1분간 평균 초당 증가율을 계산하여 TPS를 구합니다.
Average Response Time (ms)
요청 1건을 처리하는 데 평균적으로 얼마나 걸리는지 보여주는 지연 시간 지표입니다.
-
PromQL 쿼리:
(rate(http_server_requests_seconds_sum{uri=~"/api/coupon/.*/issue/test"}[1m]) / rate(http_server_requests_seconds_count{uri=~"/api/coupon/.*/issue/test"}[1m])) * 1000 -
쿼리 설명:
(초당 총 소요 시간 / 초당 총 요청 수)공식을 이용해 1건당 평균 응답 시간(초)을 구하고,1000으로 밀리초(ms) 단위로 변환합니다.
5xx Error Rate (%)
전체 요청 중 서버 측 오류가 얼마나 발생하는지 보여주는 안정성 지표입니다.
-
PromQL 쿼리
100 * sum(rate(http_server_requests_seconds_count{uri=~"/api/coupon/.*/issue/test", status=~"5.."}[1m])) by (job) / sum(rate(http_server_requests_seconds_count{uri=~"/api/coupon/.*/issue/test"}[1m])) by (job) -
쿼리 설명:
(초당 에러 발생 수 / 초당 총 요청 수) * 100으로 백분율(%) 에러율을 계산합니다.
App Server Process CPU Usage (%)
애플리케이션이 시스템의 CPU를 얼마나 점유하고 있는지 보여주는 리소스 지표입니다.
-
PromQL 쿼리
process_cpu_usage{instance="http://{server_ip}:{server_port}"} * 100 -
쿼리 설명:
process_cpu_usage값(0.0~1.0)에100을 하여 백분율(%)로 변환합니다.
App Server JVM Heap Memory (MB)
JVM 힙 메모리의 현재 상태를 파악하여 메모리 관련 문제를 진단하는 리소스 지표입니다.
-
PromQL 쿼리 (Used Heap)
sum without (id) (jvm_memory_used_bytes{area="heap", instance="http://{server_ip}:{server_port}"}) / (1024*1024) -
쿼리 설명:
jvm_memory_used_bytes를 MB 단위로 변환하여 현재 사용 중인 힙 메모리를 보여줍니다. 이 값을 최대 힙 메모리(jvm_memory_max_bytes)와 함께 그래프에 표시하면 상황을 직관적으로 파악하기 좋습니다.
참고: 해당 대시보드에는 이 외에도 Redis 성능 지표 등도 포함되어 있습니다. 이는 애플리케이션의 주요 의존성을 함께 모니터링하는 좋은 습관이라 생각합니다. 전체 구성은 GitHub의 coupon-prometheus-dashboard.json 파일에서 확인하실 수 있습니다.
해당 파일 위치: /support/monitoring/infra/grafana/dashboards/coupon
4. 실전. 쿠폰 시스템 모니터링 환경 구축하기
위의 이론을 바탕으로, ‘쿠폰 시스템’의 모니터링 환경을 어떻게 구축했는지 그 과정을 공유해 보겠습니다. 참고로 저는 Java 17, Spring Boot 3.x 버전을 기반으로 프로젝트 환경을 구성했습니다.
전체 아키텍처 한눈에 보기
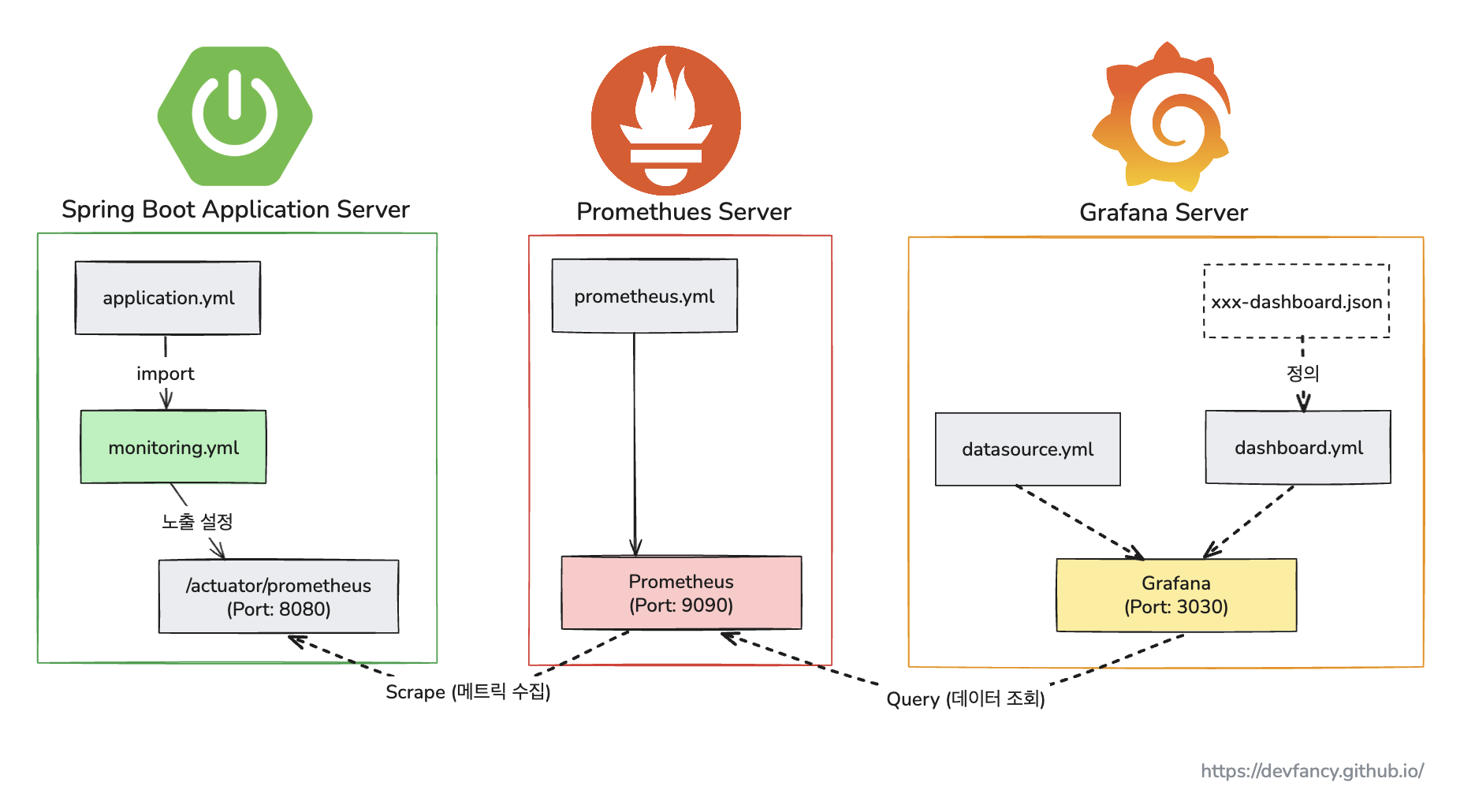
위 아키텍처의 동작 흐름을 간단히 정리하면 다음과 같습니다.
-
먼저 Spring Boot 애플리케이션 서버는
Actuator를 통해 자신의 상태 메트릭을/actuator/prometheus엔드포인트에 노출합니다. -
그 다음, Prometheus 서버는 주기적으로 이 엔드포인트에 방문하여 메트릭을 수집(Scrape)하고 자신의 시계열 데이터베이스에 저장합니다.
-
마지막으로, Grafana 서버는 Prometheus를 데이터 소스로 사용하여, 저장된 메트릭 데이터를 쿼리(Query)해와서 사용자가 볼 수 있는 대시보드로 시각화합니다.
결국 전체 데이터의 흐름은 애플리케이션 -> Prometheus (수집/저장) -> Grafana (조회/시각화) 순서로 이루어집니다.
이러한 아키텍처를 구현하기 위해, 프로젝트의 모니터링 관련 디렉토리 구조는 다음과 같이 구성했습니다.
├── infra
│ ├── grafana
│ │ ├── dashboards # Grafana 특정 대시보드 JSON 자동 로드
│ │ │ ├── coupon
│ │ │ │ ├── coupon-kafka-dashboard.json
│ │ │ │ └── coupon-prometheus-dashboard.json
│ │ │ └── dashboard.yml
│ │ └── datasources # Grafana-Prometheus 자동 연결
│ │ └── datasource.yml
│ ├── k6 # 부하테스트시 사용할 테스트 스크립트
│ │ ├── coupon-create-test.js
│ │ └── coupon-issue-test.js
│ └── prometheus
│ └── prometheus.yml # Prometheus가 애플리케이션 서버의 메트릭 수집
└── src
└── main
└── resources
└── monitoring.yml # Spring Boot가 메트릭 노출 설정
Spring Boot 애플리케이션 설정
먼저, Spring Boot 애플리케이션이 자신의 메트릭을 외부에 노출하도록 설정합니다.
공통 설정을 재사용하기 위해 별도의 monitoring 모듈을 만들었습니다.
monitoring 모듈의 build.gradle에 다음 두 의존성을 추가하여 Actuator와 Prometheus 연동 기능을 활성화합니다.
-
spring-boot-starter-actuator -
micrometer-registry-prometheus

다음으로, monitoring.yml 파일을 통해 어떤 메트릭을 어떻게 노출할지 설정합니다.
monitoring.yml 상세 설명
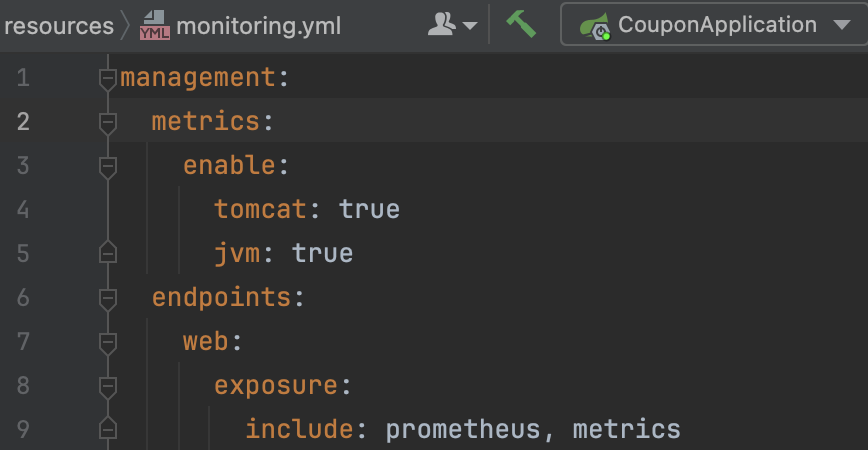
위 설정 파일의 각 부분이 어떤 역할을 하는지 자세히 살펴보겠습니다.
메트릭 ‘수집’ 설정 (What to collect)
-
metrics 부분은 어떤 종류의 메트릭을 ‘수집’할지 결정하는 스위치입니다.
-
tomcat: true: 내장 톰캣 서버의 상태(세션 수, 스레드 풀 상태 등)에 대한 메트릭을 수집합니다. -
jvm: true: JVM의 상태(메모리 사용량, GC 성능, 스레드 수 등)에 대한 메트릭을 수집합니다. -
(이 설정들이 true이기 때문에 2장에서 다루었던
jvm_memory_used_bytes와 같은 상세 지표들이 생성될 수 있는 것입니다.)
메트릭 ‘노출’ 설정 (How to expose)
-
이 부분은 위에서 수집한 메트릭들을 ‘어떻게 외부로 노출’할지 결정합니다.
-
management.endpoints.web.exposure.include는 Actuator가 제공하는 여러 엔드포인트 중, HTTP를 통해 외부에서 접근할 수 있도록 허용할 엔드포인트의 목록(Whitelist)을 지정하는 역할을 합니다. 보안상의 이유로 기본적으로는 대부분의 엔드포인트가 비활성화되어 있습니다. -
include: prometheus: 이 부분이 바로 핵심입니다.micrometer-registry-prometheus의존성이 추가된 상태에서 이 설정을 추가하면, Spring Boot Actuator는/actuator/prometheus라는 URL을 활성화하고, 수집된 모든 메트릭을 Prometheus 서버가 읽어갈 수 있는 텍스트 형식으로 변환하여 제공해 줍니다. -
include: metrics: 이 설정은/actuator/metrics라는 엔드포인트를 활성화합니다. 이 엔드포인트는 수집 가능한 모든 메트릭의 목록을 JSON 형식으로 보여주어, 개발자가 어떤 지표들이 있는지 직접 확인할 때 유용합니다.
이렇게 작성된 monitoring.yml은 coupon-api와 같은 실제 애플리케이션 모듈에서 spring.config.import를 통해 공통 설정으로 가져와 사용하게 됩니다.
Prometheus 서버 설정 및 연동
이제 Prometheus가 어떤 애플리케이션의 메트릭을 수집할지 알려줄 차례입니다. prometheus.yml 파일에 수집 대상(target)을 등록합니다.
(쿠폰 발급 요청을 비동기로 처리하기 위해 Kafka 컨슈머 애플리케이션도 함께 추가했습니다.)
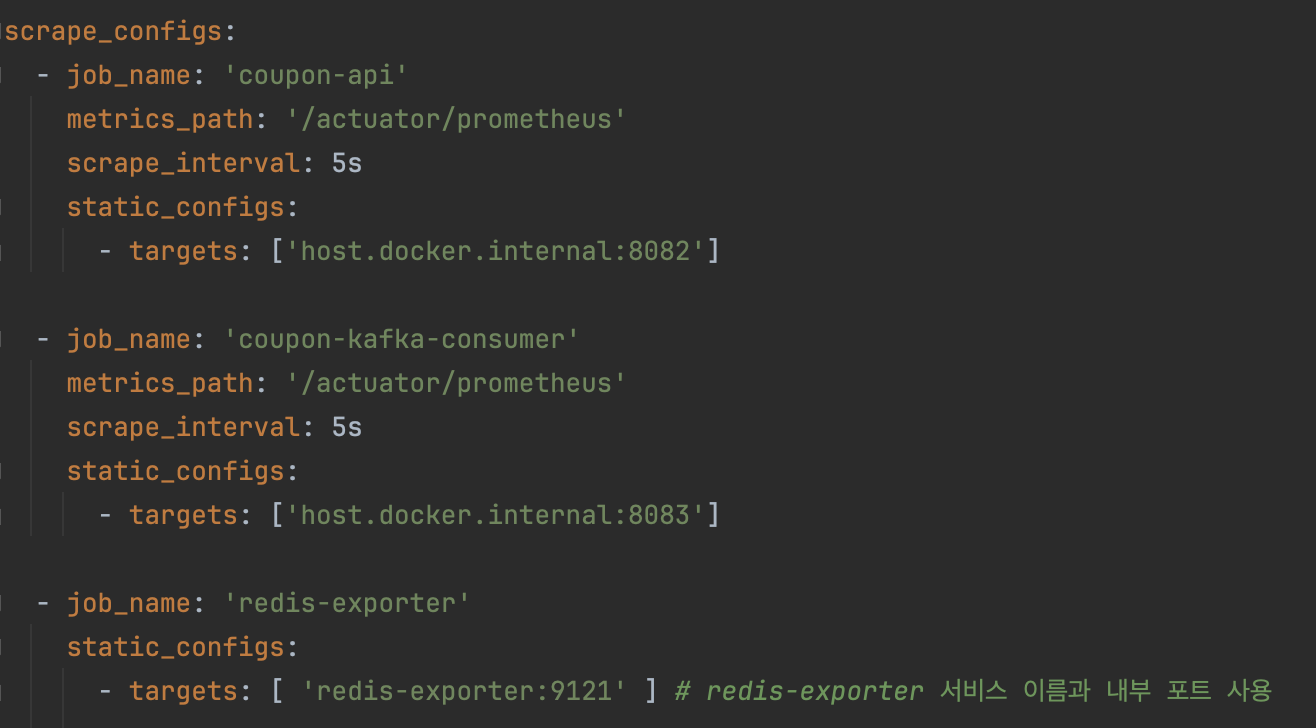
- 참고: 실제 운영 환경에서는
targets에['{server_ip}:{server_port}']와 같이 서버의 실제 IP 주소를 기입해야 합니다. 이 글의 로컬 Docker 테스트 환경에서는 Prometheus 컨테이너가 호스트 머신에서 실행 중인 애플리케이션에 접근할 수 있도록 특별한 주소인host.docker.internal을 사용했습니다.
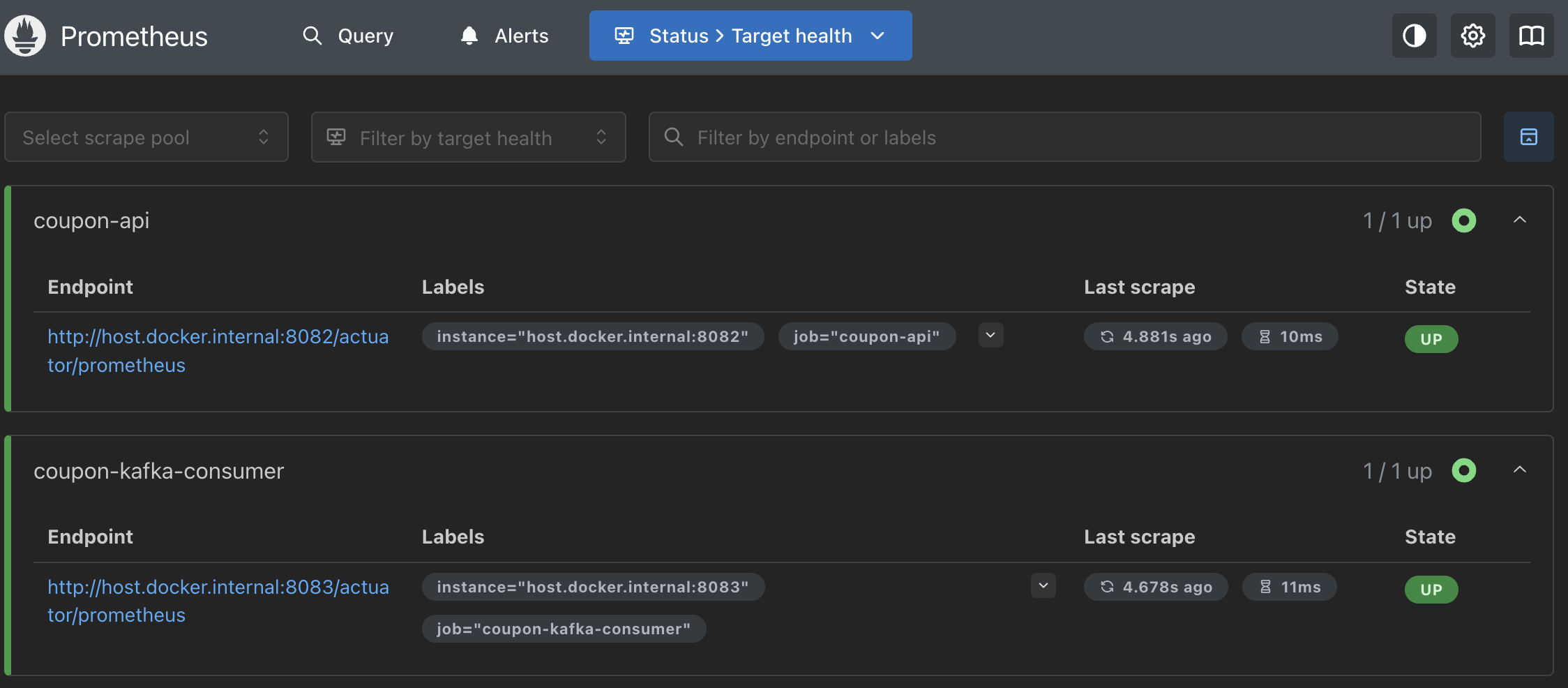
설정 후 Prometheus UI(http://localhost:9090)의 Status > Targets 메뉴에서 두 서비스가 UP 상태로 잘 연결되었는지 확인합니다.
Grafana 대시보드 만들기
마지막으로, Grafana가 Prometheus를 데이터 소스로 사용하고, 미리 정의된 대시보드를 그리도록 설정합니다.
docker-compose.yml의 volumes 설정을 통해 Grafana 컨테이너가 시작될 때 이 설정들을 자동으로 로드하도록 구성하여 편의성을 높였습니다.
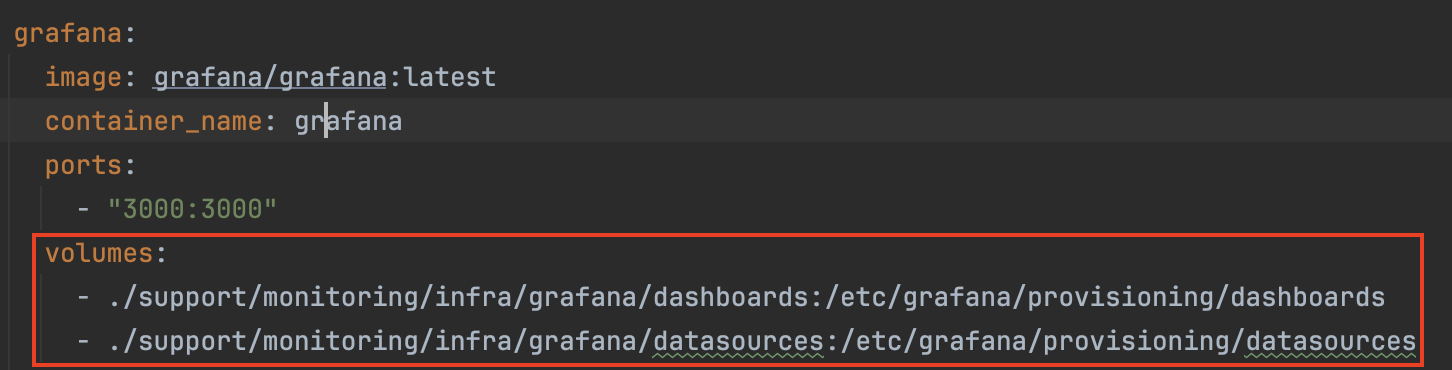
이렇게 로드되는 대시보드 파일은 다음과 같습니다.
coupon-prometheus-dashboard.json: 쿠폰 발급 API의 핵심 지표- 쿠폰 발급 API에 대한 TPS, 평균 응답 시간, 에러율, CPU 및 JVM 메모리 사용량 등 주요 지표
coupon-kafka-dashboard.json: Kafka 컨슈머의 처리 관련 지표- 쿠폰 발급 API에 대한 컨슈머 처리량, 처리 시간, CPU 및 JVM 메모리 사용량 등 주요 지표
부하 테스트 및 결과 확인
모든 구성 요소가 준비되었습니다. docker-compose로 인프라를 실행하고 애플리케이션을 띄운 뒤, k6로 부하를 발생시켜 대시보드에 데이터가 잘 그려지는지 확인해 보겠습니다.
- 명령어: docker compose up -d
그런 다음, 애플리케이션 2개(coupon-api, coupon-kafka-consumer) 를 실행시켜줍니다.
docker container와 애플리케이션이 모두 정상적으로 동작되면, localhost:3000으로 접속하면 Grafana 화면이 나오게 됩니다. (default - id/pw: admin)
이제 k6를 이용해 시스템에 부하를 주어 대시보드에 데이터가 잘 그려지는지 확인해 보겠습니다.
(k6 개념에 대해 잘모르겠다면, 공식 문서 및 “부하테스트 - K6 도구 소개” 를 참고해 주시면 감사하겠습니다)
1. 사전 데이터 생성
부하 테스트에 사용할 쿠폰을 미리 생성합니다.
참고로, 부하 테스트의 요청 수보다 발급할 쿠폰 총 수량값이 커야 4xx 에러 없이 성공률 100%를 확인할 수 있습니다.
-
coupon-create-test.js 내의
totalQuantity가 발급할 쿠폰 총 수량을 의미합니다. -
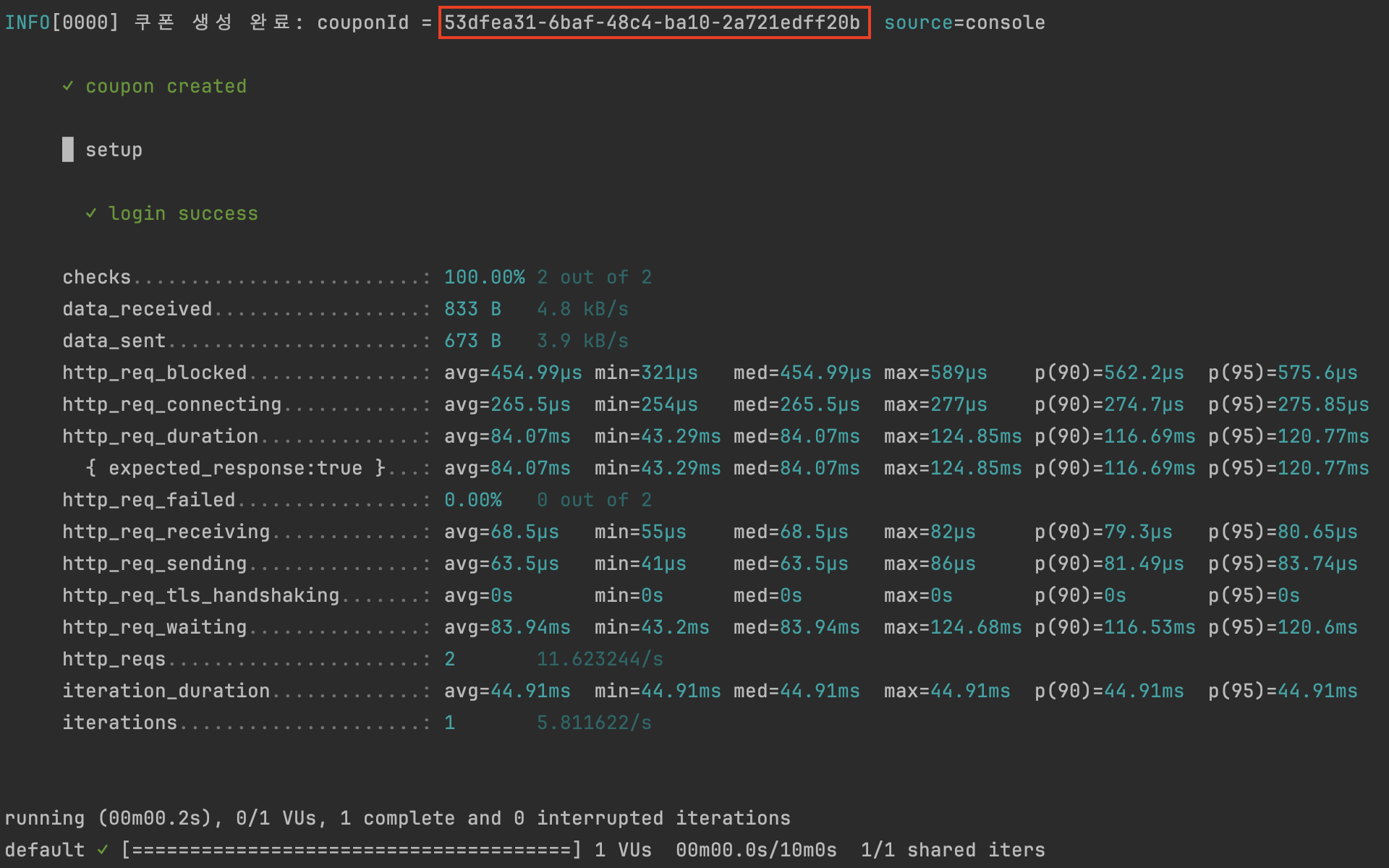
명령어: k6 run –out influxdb=http://localhost:8086/k6 coupon-create-test.js
2. 부하 테스트 실행
생성된 쿠폰 ID를 coupon-issue-test.js 파일에 넣고, 스크립트를 실행합니다. 저는 가상 사용자 1000명이 10분간 부하를 주도록 설정했습니다.
해당 쿠폰 생성의 결과에서 생성된 쿠폰 ID를 가져와 coupon-issue-test.js 파일에서 아래와 같이 couponId 부분에 넣어준 뒤, 명령어를 입력합니다.
-
const couponId = '53dfea31-6baf-48c4-ba10-2a721edff20b'; // 쿠폰 ID -
명령어: k6 run –out influxdb=http://localhost:8086/k6 coupon-issue-test.js
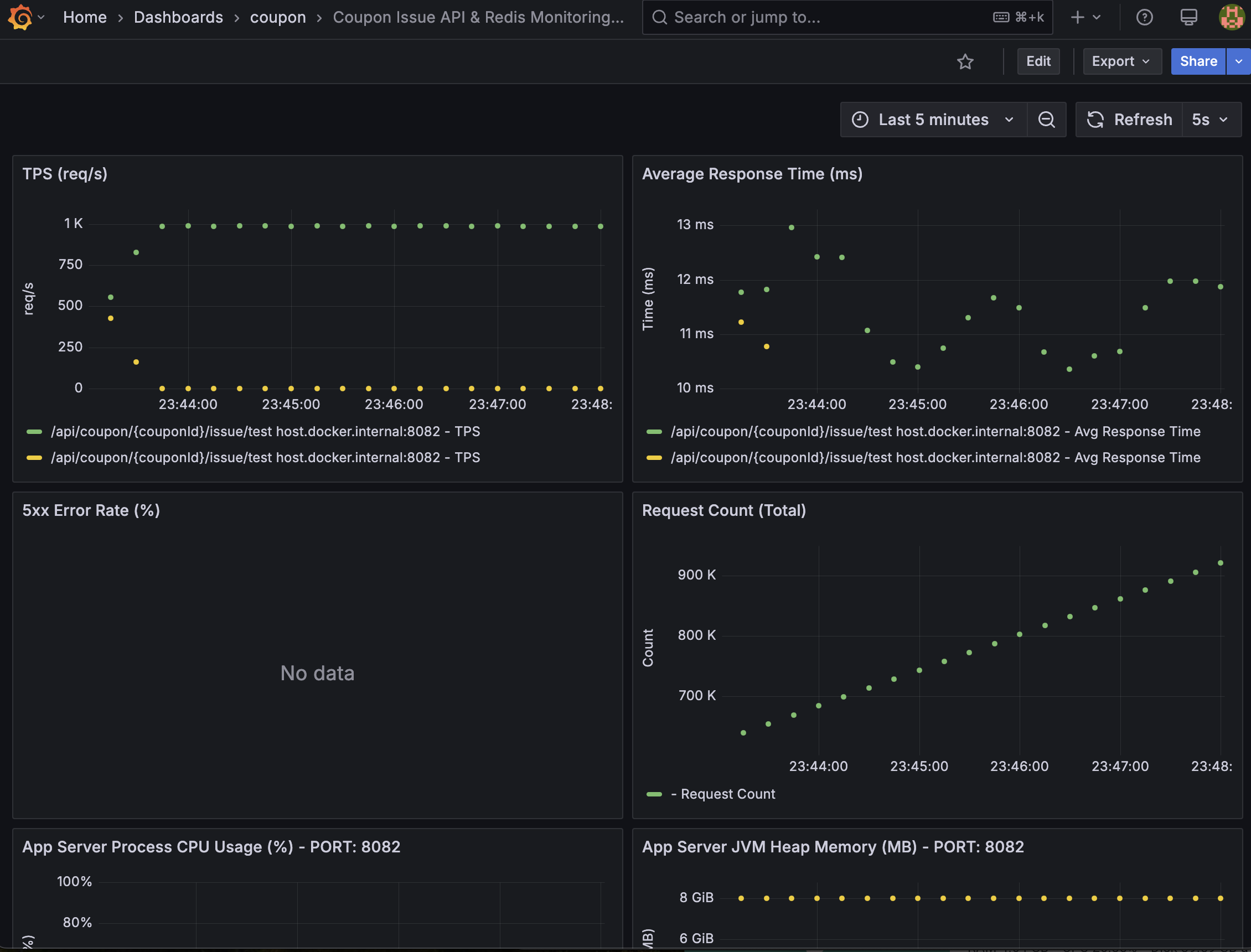
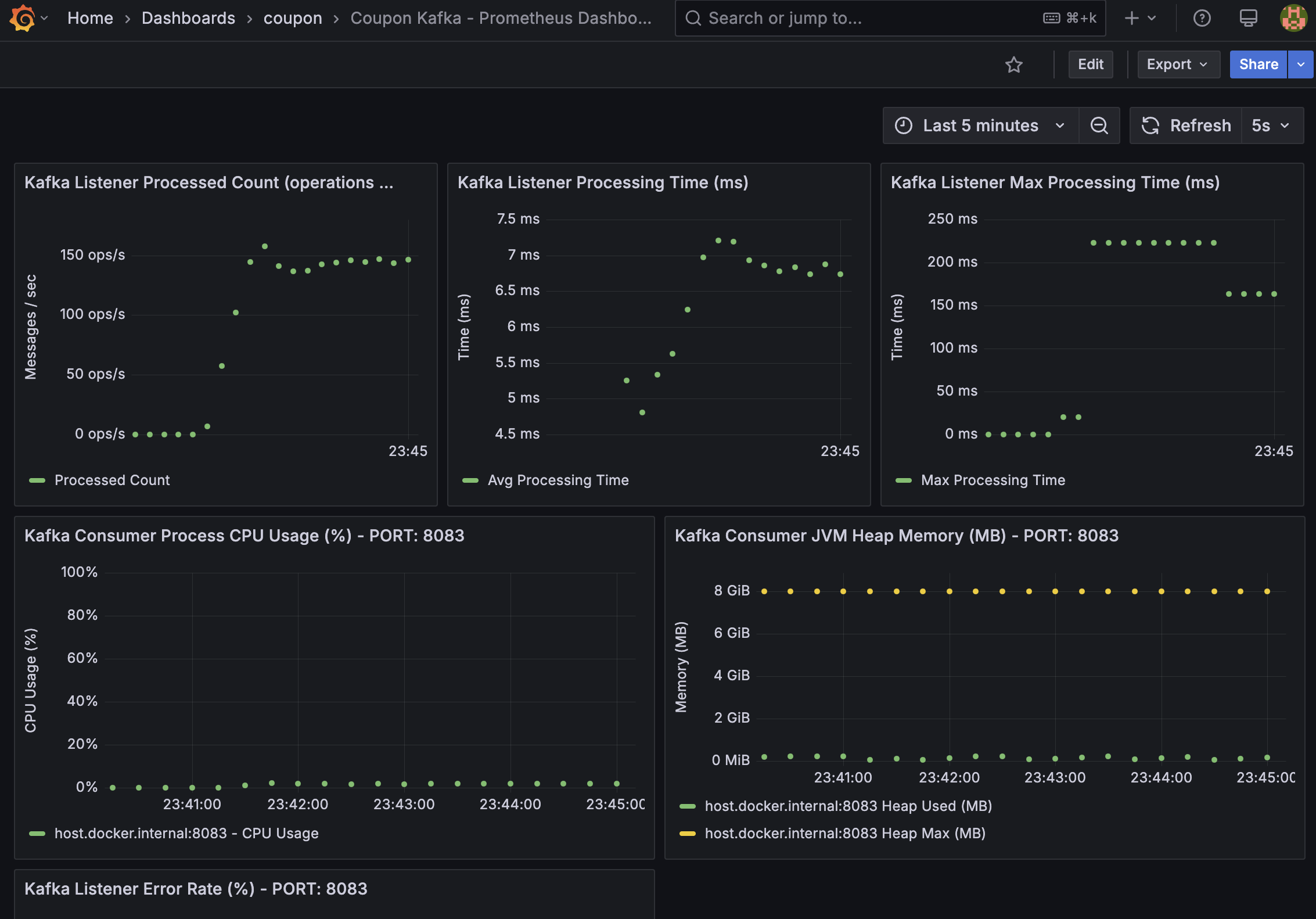
그러면 아래와 같이 coupon-api 와 coupon-kafka-consumer 애플리케이션으로부터 수집된 지표를 Grafana 대시보드(http://localhost:3000)에서 실시간으로 변화하는 지표들을 확인할 수 있습니다.
부하 테스트 중인
coupon-api애플리케이션 대시보드 예시
부하 테스트 중인
coupon-kafka-consumer애플리케이션 대시보드 예시
5. 성능 분석 노하우 및 결론
이번 경험을 통해 얻은 성능 분석 노하우 몇 가지를 정리하며 글을 마무리하려 합니다.
-
종합적 판단: 단일 지표가 아닌 여러 지표를 연관 지어 종합적으로 판단하려고 노력합니다.
-
추이 분석: 순간의 값보다는 시간 흐름에 따른 변화 추이를 통해 문제의 패턴을 읽습니다.
-
기준선 설정: 부하 테스트 전후의 기준선(Baseline)을 설정하고 변화를 비교 분석하는 것이 중요합니다.
-
자동화: 주요 지표에 임계치를 설정하고 알림 시스템을 활용하여 선제적으로 대응합니다.
Summary
이번 포스팅에서는 Prometheus와 Grafana를 중심으로 애플리케이션 관점의 지표를 살펴보고 모니터링 환경을 직접 구축한 경험을 공유했습니다.
지금까지 읽어주셔서 감사합니다.