- Prologue
- 요구사항 정의
- 소프트웨어 설계
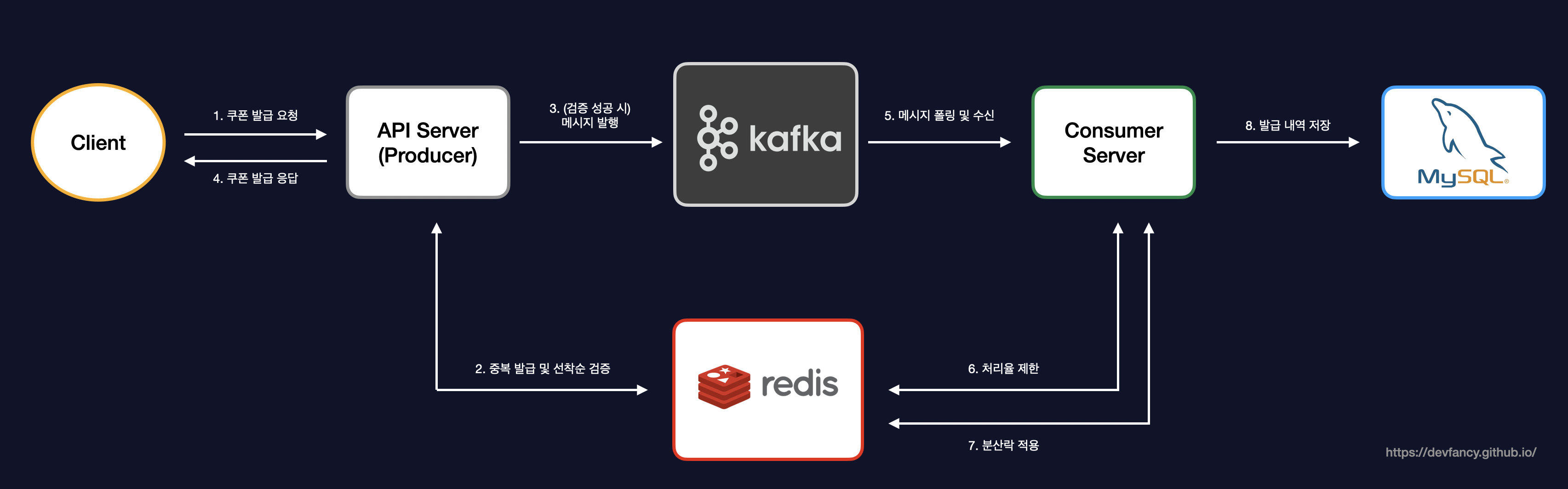
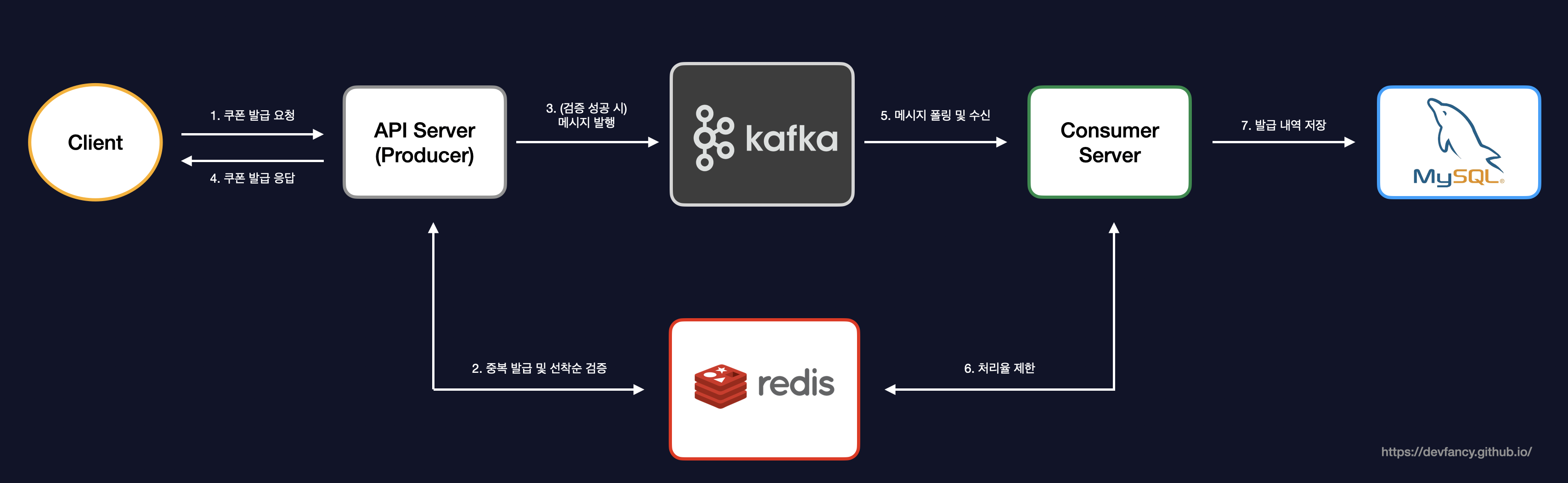
- 쿠폰 발급 프로세스
- 초기 아키텍처 구성
- 성능 테스트 목표
- 부하 테스트 서버 구축
- 1. 초기 아키텍처 구성
- 2. 인프라 확장 및 병목 지점 파악
- 3. 시스템 안정성을 위해 고가용성 확보
- 성과 및 결론
- 향후 개선 방안
- 마무리하며
- Reference
Prologue
이 글에서 다루는 내용은 해당 Github 기반으로 작성되었으며, 시간에 따라 아키텍처 및 코드는 변경될 수 있습니다.
이번 글에는 개인 프로젝트인 쿠폰 발급 시스템을 개발하면서, 프로젝트 목표인 선착순 이벤트 시 대규모 트래픽 속에서도 안정성과 성능을 보장하고자 했습니다.
AWS EC2 기반으로 구축하고 최소 사양부터 시작해서 부하 테스트를 진행하면서 점진적으로 개선하는 과정을 공유하고자 작성하게 되었습니다.
예상 독자
-
부하 테스트를 통해 성능과 안정성을 점진적으로 개선하고자 하는 사람
-
대규모 트래픽 처리를 위해 어떤 요소를 고려하고 그에 맞게 개선해야 하는지 궁금한 사람
(이 글은 Redis와 Kafka에 대한 지식과 경험이 있는 예상 독자를 기준으로 작성했습니다.)
요구사항 정의
쿠폰 발급에 대한 기능적인 요구사항은 간단합니다.
정해진 개수만큼의 쿠폰이 발급되며, 사용자에게 중복 발급이 되지 않도록 방지해야 합니다. (1회만 발급 가능)
하지만 여기서 아래와 같이 비기능적인 요구사항이 추가된다면 얘기는 달라집니다.
-
동시성 처리: 많은 사용자가 동시에 쿠폰을 신청할 경우에도 정상적으로 동작해야 합니다.
-
성능 고려: 대량 트래픽을 고려하여 시스템이 효율적으로 동작하도록 설계해야 하며, 쿠폰 발급 요청이 몰릴 경우에도 빠르게 처리될 수 있도록 설계해야 합니다.
이러한 기능적 요구사항과 비기능적 요구사항을 모두 충족하는 쿠폰 발급 시스템을 점진적으로 개선해보고자 합니다.
소프트웨어 설계
대규모 트래픽을 처리하기에 앞서, 복잡한 비즈니스 로직을 명확히 정의하고 시스템의 확장성을 확보하기 위해 도메인 주도 설계와 멀티 모듈 구조를 적용했습니다.
전략적 설계
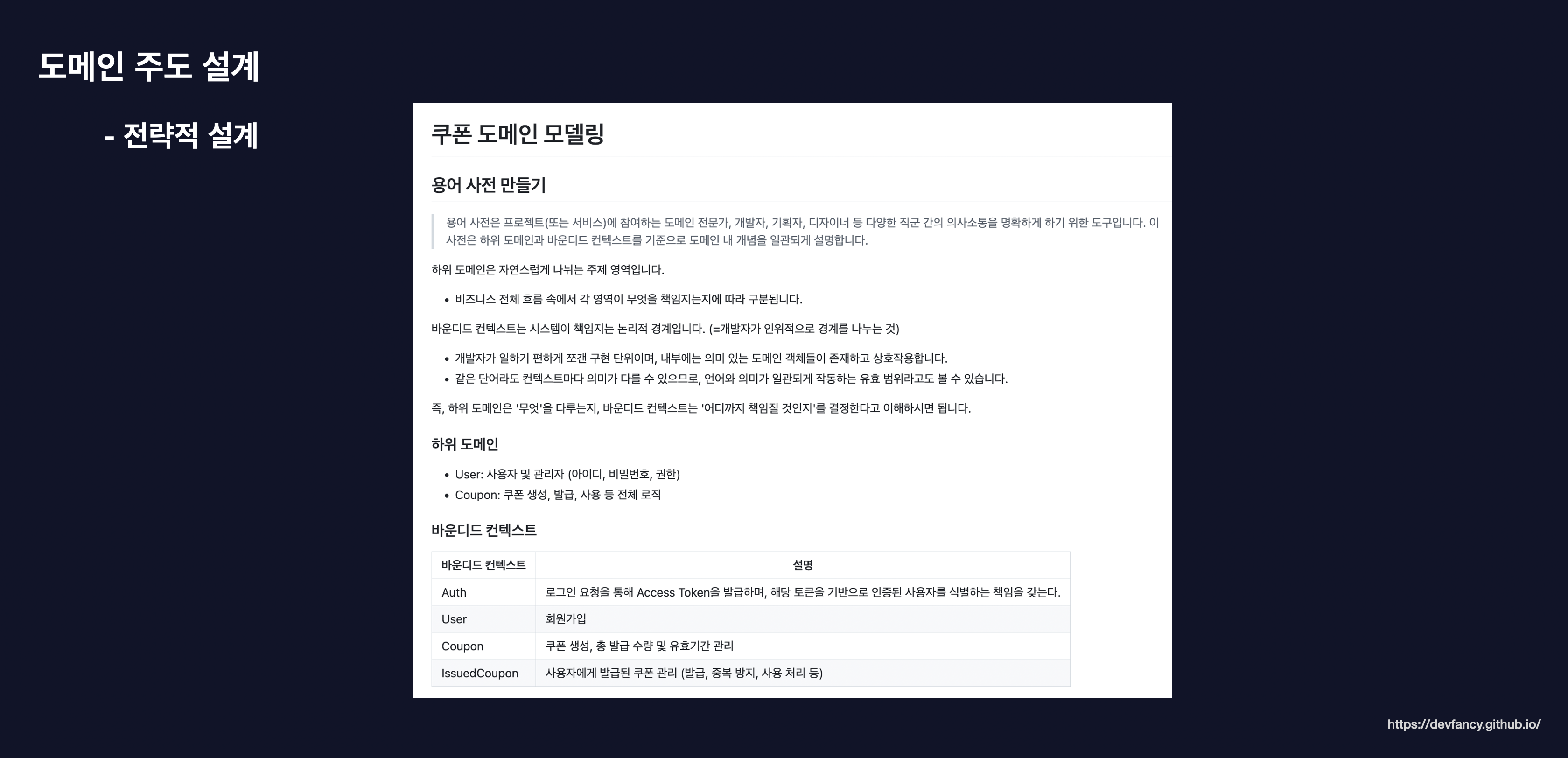
협업 시 용어의 혼선을 방지하고 비즈니스 로직의 응집도를 높이기 위해 전략적 설계를 진행했습니다. 용어 사전을 통해 도메인 내 개념을 일관되게 정의하고, 시스템이 책임지는 논리적 경계인 바운디드 컨텍스트(Bounded Context)를 다음과 같이 정의했습니다. (자세한 내용은 해당 링크를 참고해 주시면 감사하겠습니다.)
-
Auth: 로그인 및 토큰 발급을 통한 사용자 식별 -
User: 회원가입 및 사용자 관리 -
Coupon: 쿠폰 생성, 수량 및 유효기간 관리 -
IssuedCoupon: 사용자에게 발급된 쿠폰 관리(중복 방지 및 사용 처리)
멀티 모듈 구조
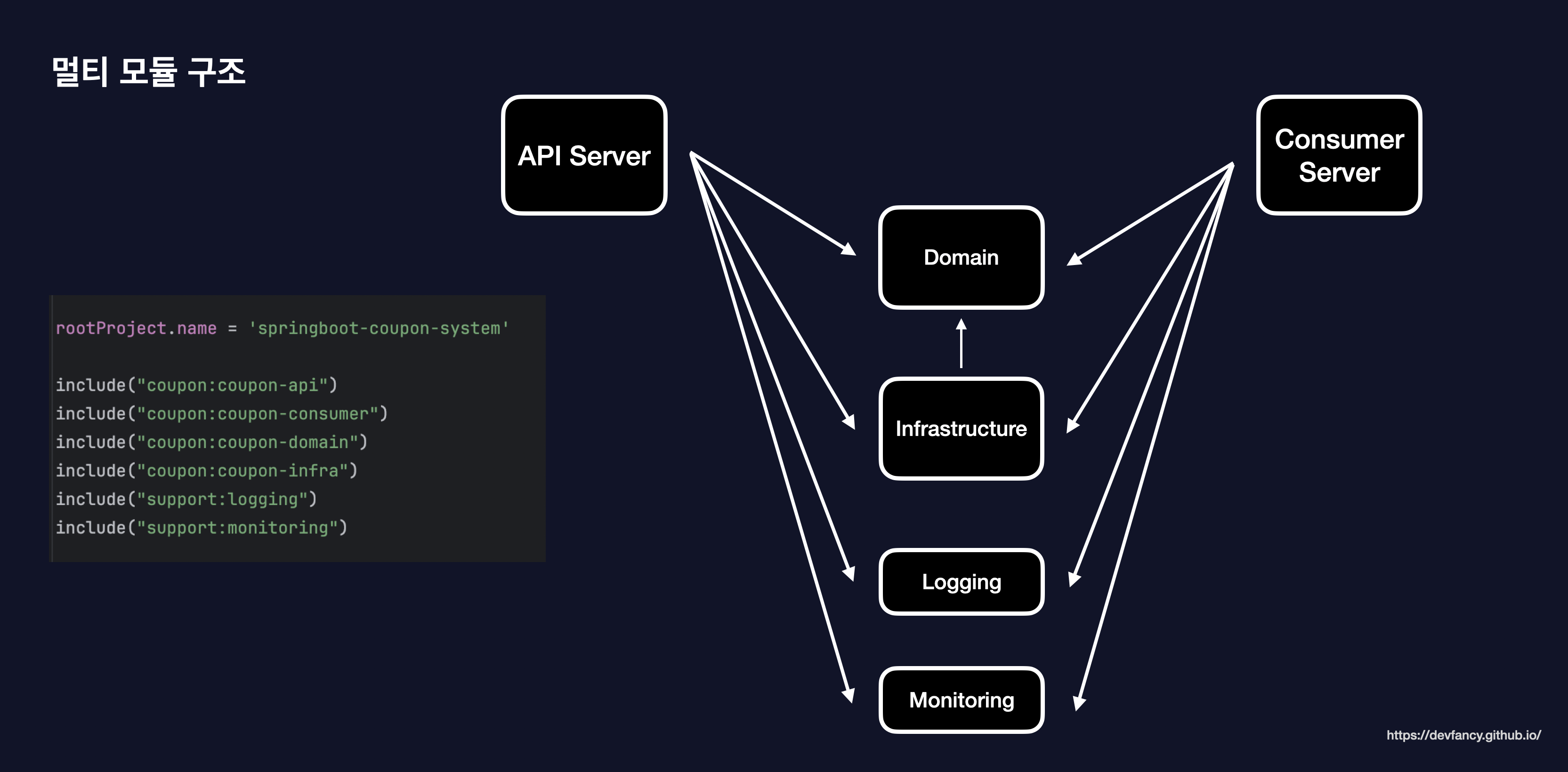
각 모듈의 역할과 책임을 명확히 분리하기 위해 멀티 모듈 구조를 도입했습니다. 특히 애플리케이션의 핵심인 비즈니스 로직(Domain)이 기술적인 세부 구현에 오염되지 않도록 설계하는 데 집중했습니다.
도메인 계층에는 순수한 인터페이스만 두고, 실제 데이터베이스에 접근하는 구현체(JPA 등)는 인프라 모듈로 격리했습니다. 이를 통해 향후 기술 스택이 변경되더라도 핵심 도메인 로직은 안정적으로 보호될 수 있는 구조로 설계했습니다.
또한 애플리케이션의 핵심인 API 서버와 Consumer 서버가 필요한 공통 로직을 효율적으로 공유하면서도, 독립적인 확장 및 배포가 가능하도록 설계했습니다.
특히 로깅이나 모니터링처럼 여러 모듈에서 공통으로 필요한 기술적 기능들을 별도의 support 모듈로 분리하여 코드 재사용성을 높였습니다.
-
coupon-api: 쿠폰 발급 요청 접수 및 검증 (Producer 역할) -
coupon-consumer: Kafka 메시지 소비 및 데이터 저장 (Consumer 역할) -
coupon-domain: 외부 환경에 의존하지 않는 순수한 비즈니스 로직과 엔티티를 포함 -
coupon-infra: 외부 시스템 연동 및 인프라 설정 (JPA, Redis, Kafka) -
support-logging: 서비스 전반의 로그 표준화 및 추적 시스템을 제공 -
support-monitoring: Prometheus, Grafana, Sentry 등 시스템 가용성을 실시간으로 관측하기 위한 지표 수집 라이브러리를 포함
쿠폰 발급 프로세스
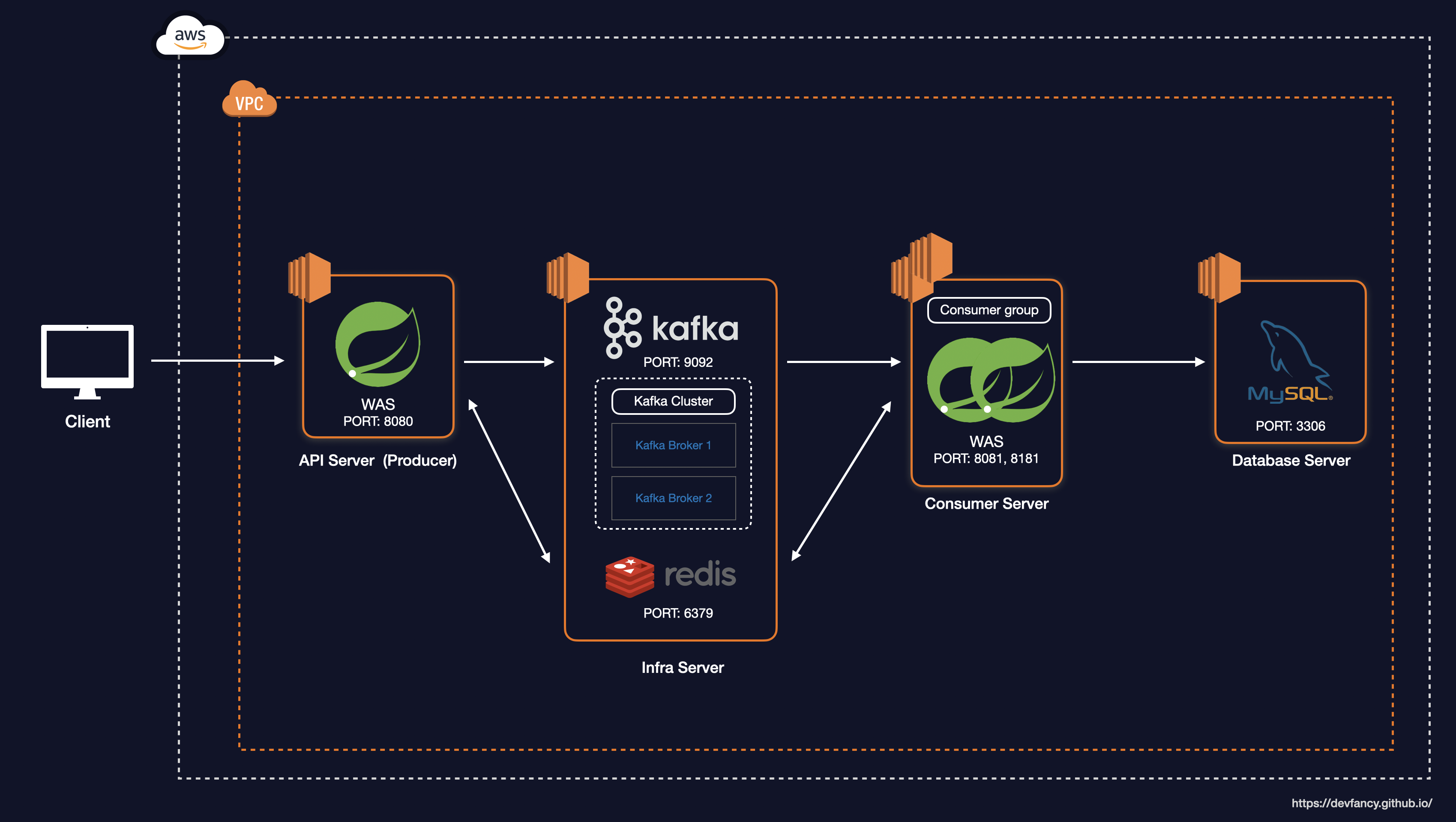
이러한 소프트웨어 설계 원칙을 바탕으로, 실제 시스템이 단일 서버 환경에서 어떻게 비동기 분산 아키텍처로 진화하며 선착순 이벤트를 위한 쿠폰 발급 로직을 처리했는지 살펴보겠습니다.
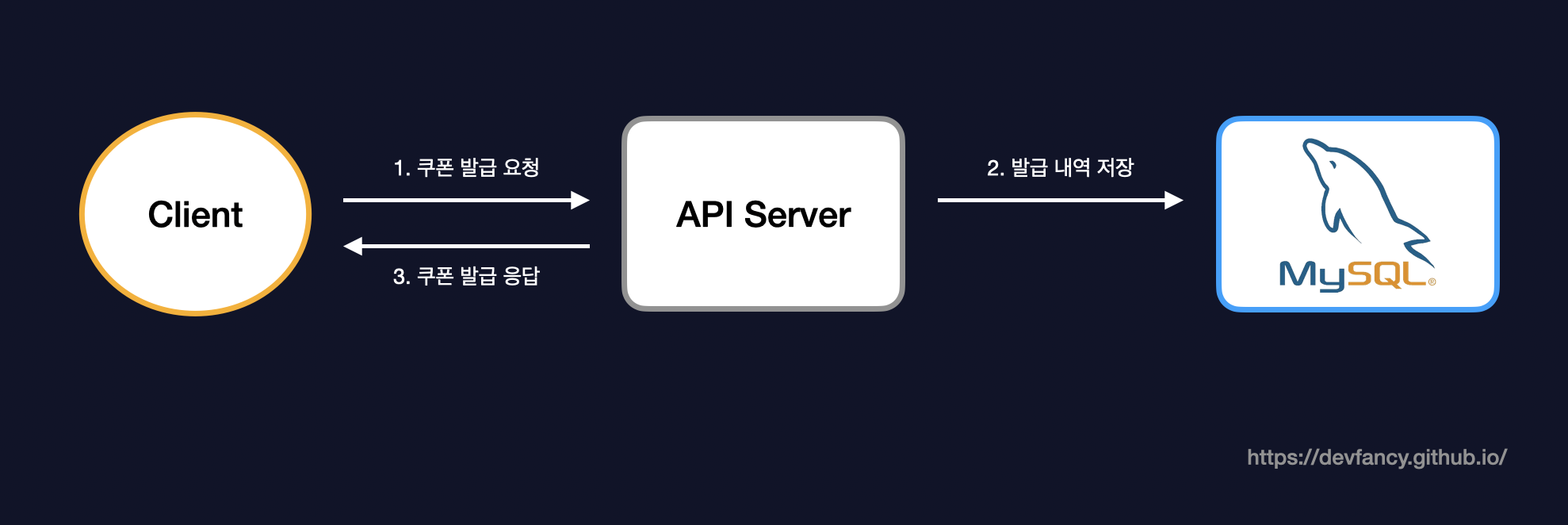
초기 프로젝트는 아래 사진과 같이 단일 서버 내의 API 서버와 MySQL 연동만 하는 상황이었습니다.
하지만 대규모 트래픽 속에서 안정성과 성능을 보장하는 선착순 이벤트를 진행해야 했기 때문에, 저는 Redis와 Kafka를 도입했습니다. (만약 사용자 수가 적고 실시간 처리가 주가 아닌 서비스라면, 두 가지의 기술을 모두 도입하지 않아도 된다고 생각합니다. 배보다 배꼽이 커지면 안되는 것 처럼요.)
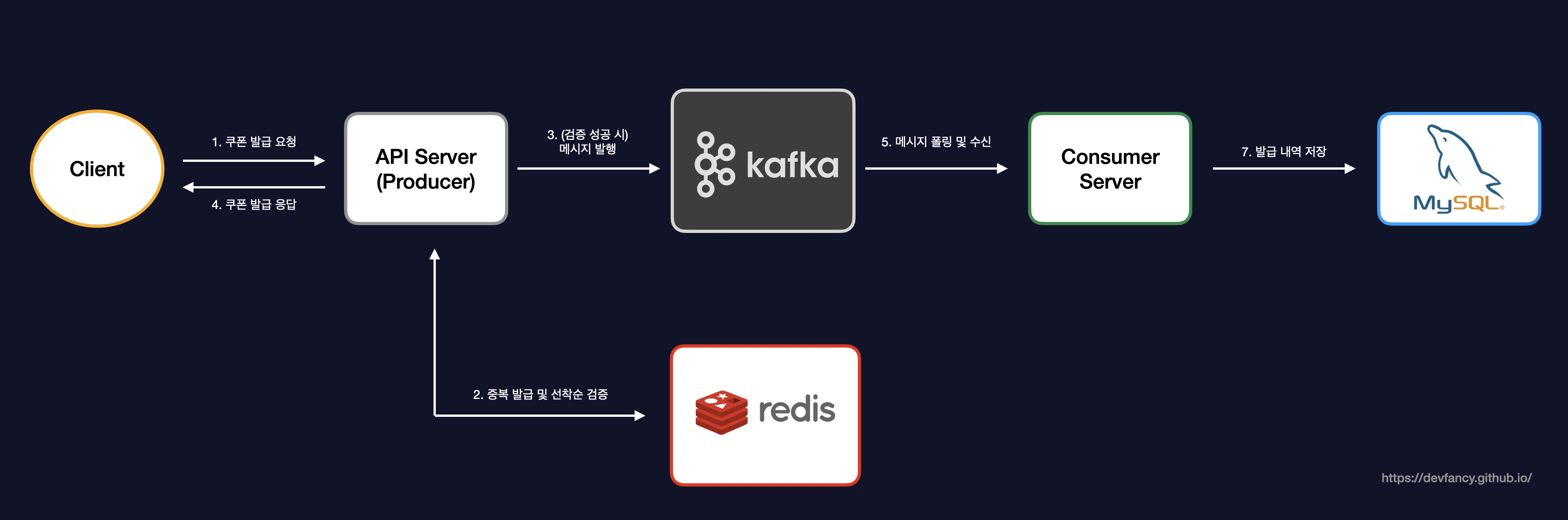
Redis를 이용하여 중복 발급 방지 및 선착순 재고 처리를 구현했고, 선착순 이내로 들어온 요청을 Kafka를 통해 DB에 저장하도록 구현했습니다.
기존에 하나의 서버에서 두 가지 역할을 저는 다음과 같이 분리했습니다.
-
API Server(=Producer): 쿠폰 발급에 대한 요청이 들어올 때 중복 발급 및 선착순을 검증하는 역할
-
Consumer Server: 선착순 이내로 들어온 요청에 대해 유효성 검사 및 DB에 저장하는 역할
이를 통해 사용자에게 쿠폰 발급에 대한 요청을 빠르게 응답할 수 있도록 설계했습니다.
이제 위의 발급 프로세스를 가지고 AWS EC2 기반으로 부하 테스트를 진행해보고자 합니다.
초기 아키텍처 구성
처음부터 대규모 트래픽을 견디는 시스템을 만들기 보다는, 최소 사양부터 구축하면서 성능과 안정성을 가져가고자 했습니다.
AWS EC2의 여러 서버 사양을 확인했을 때 t2 기반으로 사용하기 보다는 t3 기반으로 사용하기로 결정했습니다.
정확한 부하 테스트를 위해 t3 인스턴스의 Unlimited 모드를 활성화했습니다.
이는 CPU 크레딧 소진 시에도 성능 제한 없이 추가 비용을 지불하며 성능을 유지하는 설정으로, 인프라 제약으로 인한 테스트 왜곡을 방지하기 위함입니다.
반면 t2로도 부하 테스트를 해봤지만, 크레딧 고갈 시 성능이 베이스라인 수준으로 강제로 급락해서 정확하게 부하 테스트를 진행할 수 없었습니다. 또한 t3는 Nitro 시스템 아키텍처를 기반으로 하여 t2 대비 훨씬 높은 네트워크 대역폭과 I/O 성능을 제공하므로, Kafka와 Redis 간의 잦은 통신이 발생하는 분산 환경에 더욱 적합했습니다.
(자세한 내용은 공식 홈페이지에서 확인하실 수 있습니다.)
아래는 T3 에 대한 제품 세부 정보이며, 저는 이 중에서 t3.medium 제품을 선택했습니다.
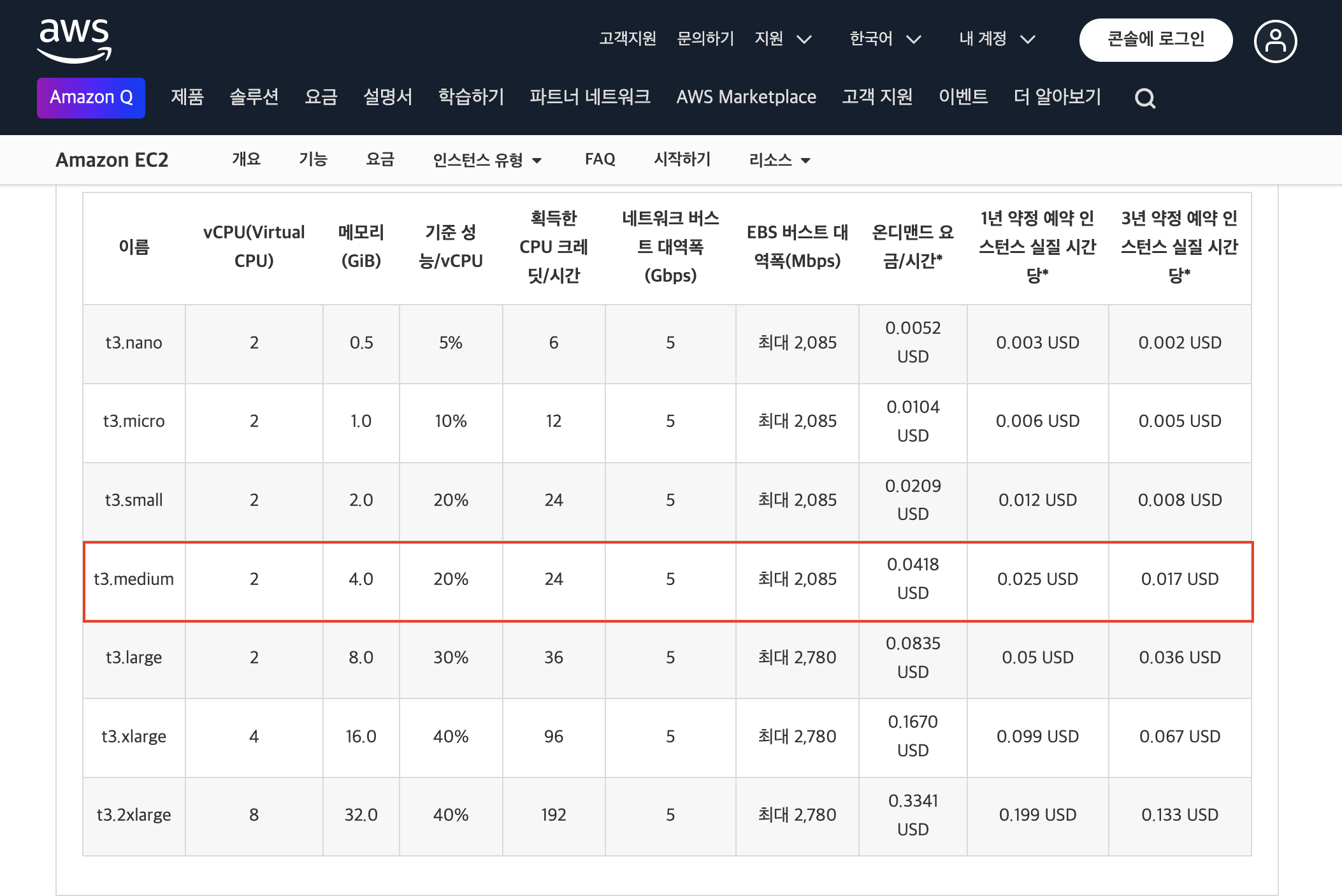
쿠폰 발급 시스템에 대해 API Server, Consumer Server 뿐만 아니라, Infra(MySQL, Redis, Kafka), Monitoring(Prometheus, Grafana) 까지 사용해야 한다면 Memory가 2GB는 적고 최소 4GB는 필요하다고 생각했습니다.
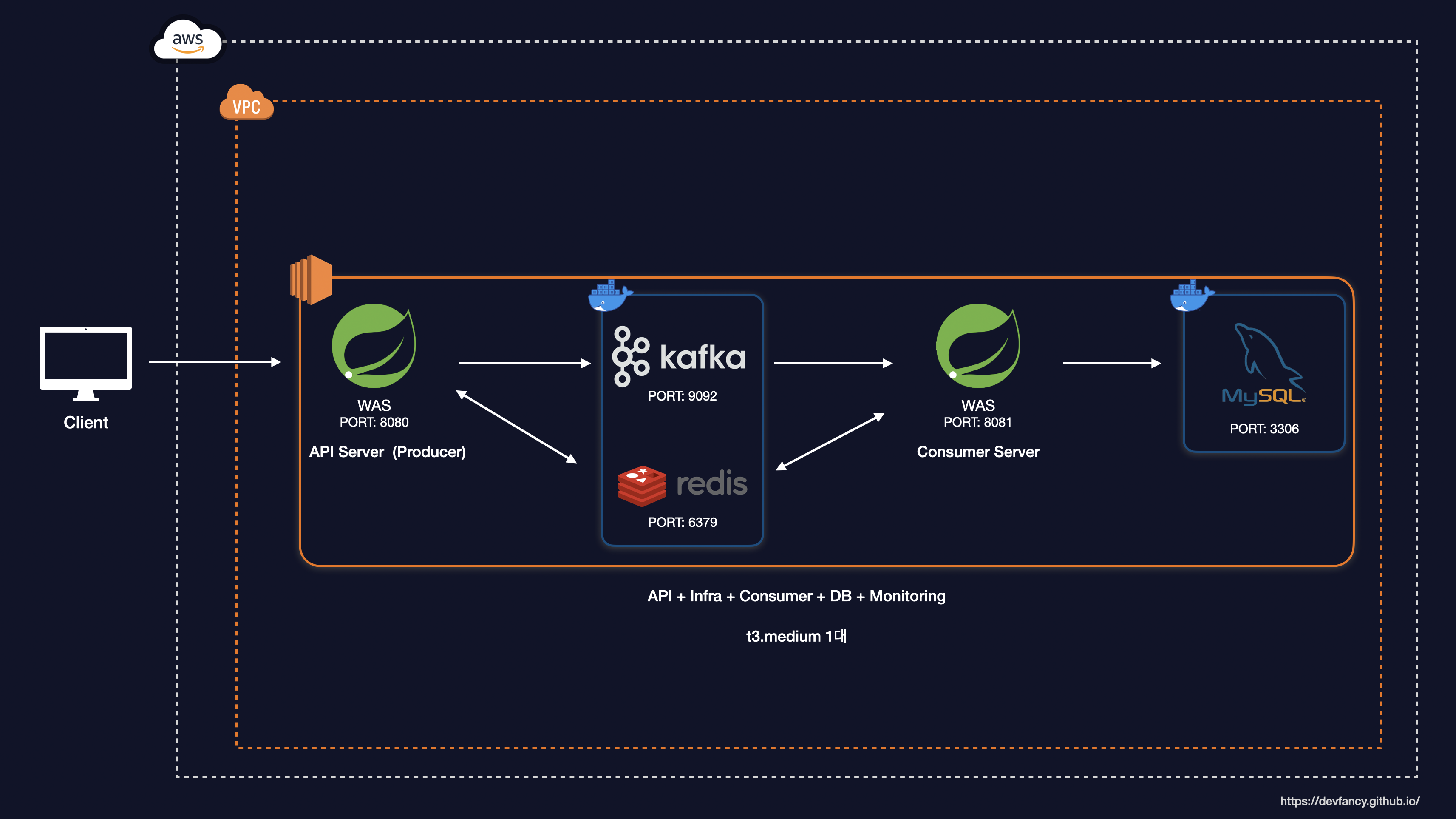
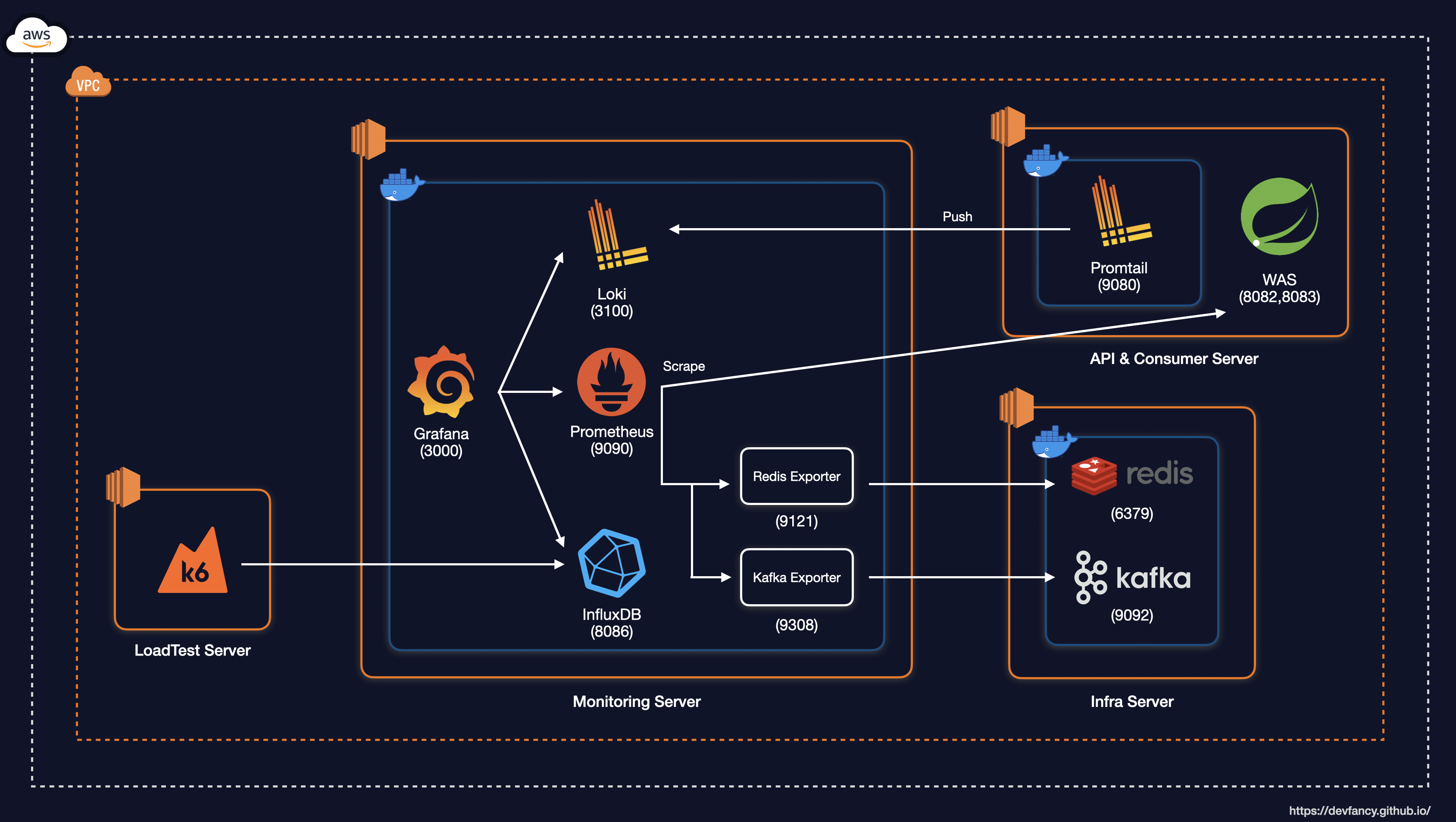
그래서 t3.medium 기준으로 각 서버, 인프라, 모니터링의 메모리 양을 한정적인 용량으로 설정하여 Docker Container 기반으로 아래와 같이 시스템 아키텍처를 구축했습니다. (모니터링 부분도 해당 인스턴스에 포함했지만, 그림에 넣으면 복잡해질 것 같아 생략했습니다.)
System Architecture
성능 테스트 목표
성능 테스트에 대한 자세한 내용은 이전에 작성한 성능 개념 및 주요 병목 지점, 성능 테스트 학습 포스팅을 참고해 주시면 감사하겠습니다.
성능 테스트의 목표는 만 명 정도의 사용자가 쿠폰 발급을 동시에 요청할 때 최대 3초 안에 발급할 수 있도록 서비스를 안정적으로 운영하는 것으로 잡았습니다. 또한, 실시간 처리는 해야하는 상황이고 선착순 이내로 들어오면 순서는 보장하지 않아도 됩니다.
만 명의 사용자가 요청할 때 3초 안에 모두 응답하기 위해서는 초당 약 3,333건의 요청을 처리할 수 있어야 합니다. 즉, 최소 3,300 TPS 이상의 성능 확보를 목표로 설정했습니다.
이러한 성능을 측정하기 위해서는 부하를 점진적으로 증가시키면서 병목 지점을 파악하고 이를 개선해야 합니다.
그래서 부하 테스트를 진행하면서 지표로 요청 수, 응답 시간, 에러율을 수집하면서 서비스가 잘 동작하는지를 파악합니다.
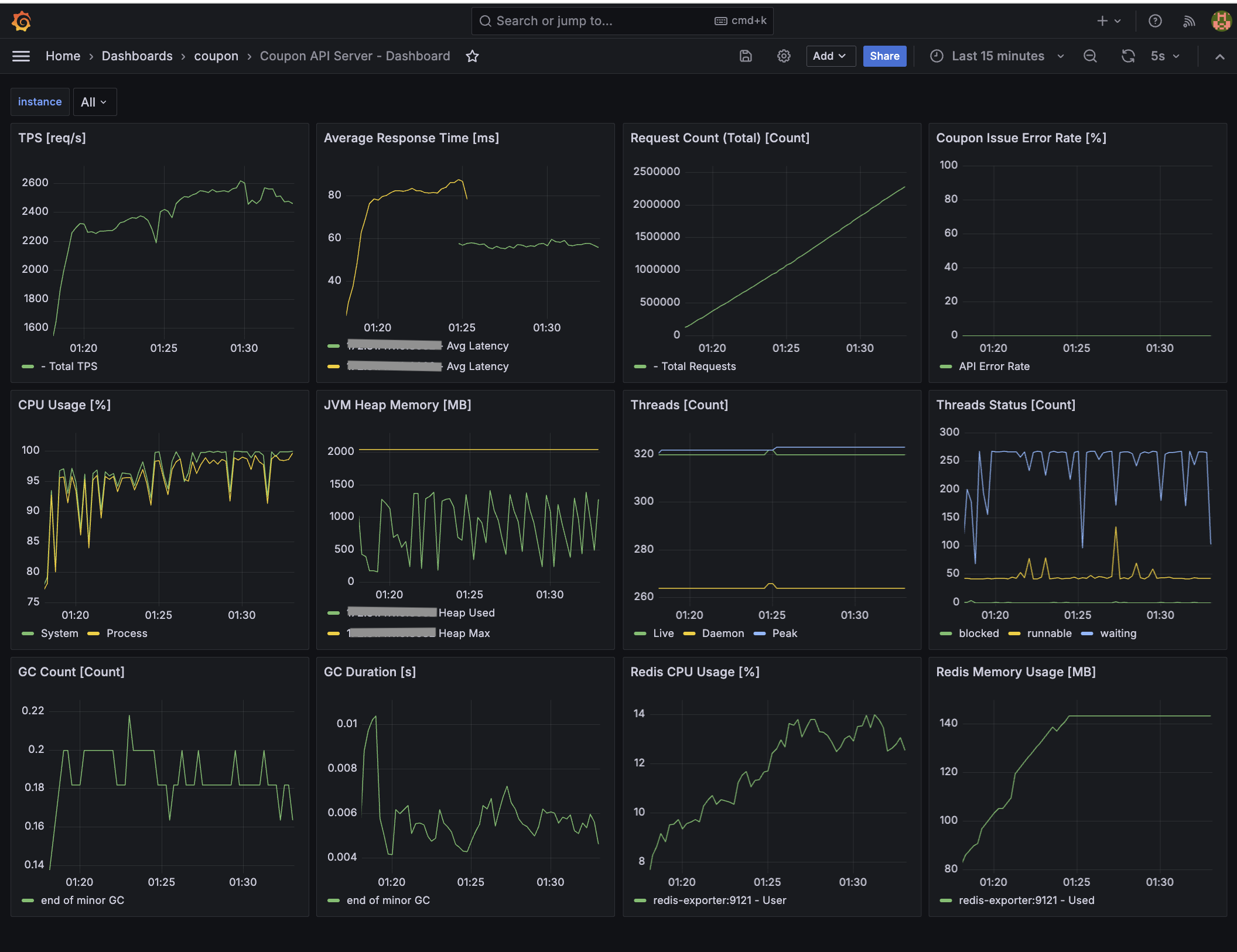
또한, 서비스를 안정적으로 운영하기 위해서는 실시간으로 모니터링을 하면서 필요한 지표를 확인해야 합니다. 저는 시스템과 애플리케이션 별로 각 CPU 및 Memory 지표를 선정했고, 이외에 각 서버마다 중요한 지표를 수집하고자 했습니다.
-
API Server: 부하 테스트 관련 지표(TPS, 평균 응답 시간, 요청 수, 에러율 등), 시스템 및 API 애플리케이션 관련 지표(CPU, JVM 힙 메모리, Threads 등) -
Consumer Server: 부하 테스트 관련 지표, 시스템 및 컨슈머 애플리케이션 관련 지표, 시스템 및 애플리케이션 관련 지표, HikariCP 등
Redis와 Kafka 관련 메트릭은 Redis Exporter 와 Kafka Exporter를 활용했습니다.
-
Redis Exporter를 사용하면 Redis의 CPU, Memory 뿐만 아니라 Redis의 다양한 지표를 수집할 수 있습니다.
-
Kafka Exporter를 사용하면 Consumer Lag Count과 같은 Kafka의 다양한 지표를 수집할 수 있습니다.
부하 테스트 서버 구축
부하 테스트 도구로는 K6를 선택했고, 모니터링은 Prometheus, Grafana를 통해 구축했습니다.
부하 테스트 개념 및 모니터링 구축에 대한 자세한 내용은 이전에 작성한 아래 포스팅을 참고해 주시면 감사하겠습니다.
부하 테스트는 기존 t3.medium과 동일한 버전으로 별도로 구축했습니다. 정확한 TPS를 측정하기 위해서는 부하 테스트 전용의 서버가 별도로 구축되어야 한다고 생각했습니다.
이를 통해 성능 테스트의 신뢰성을 확보할 수 있습니다.
부하 테스트를 포함한 시스템 아키텍처를 그림으로 표현하면 아래와 같습니다.
System Architecture
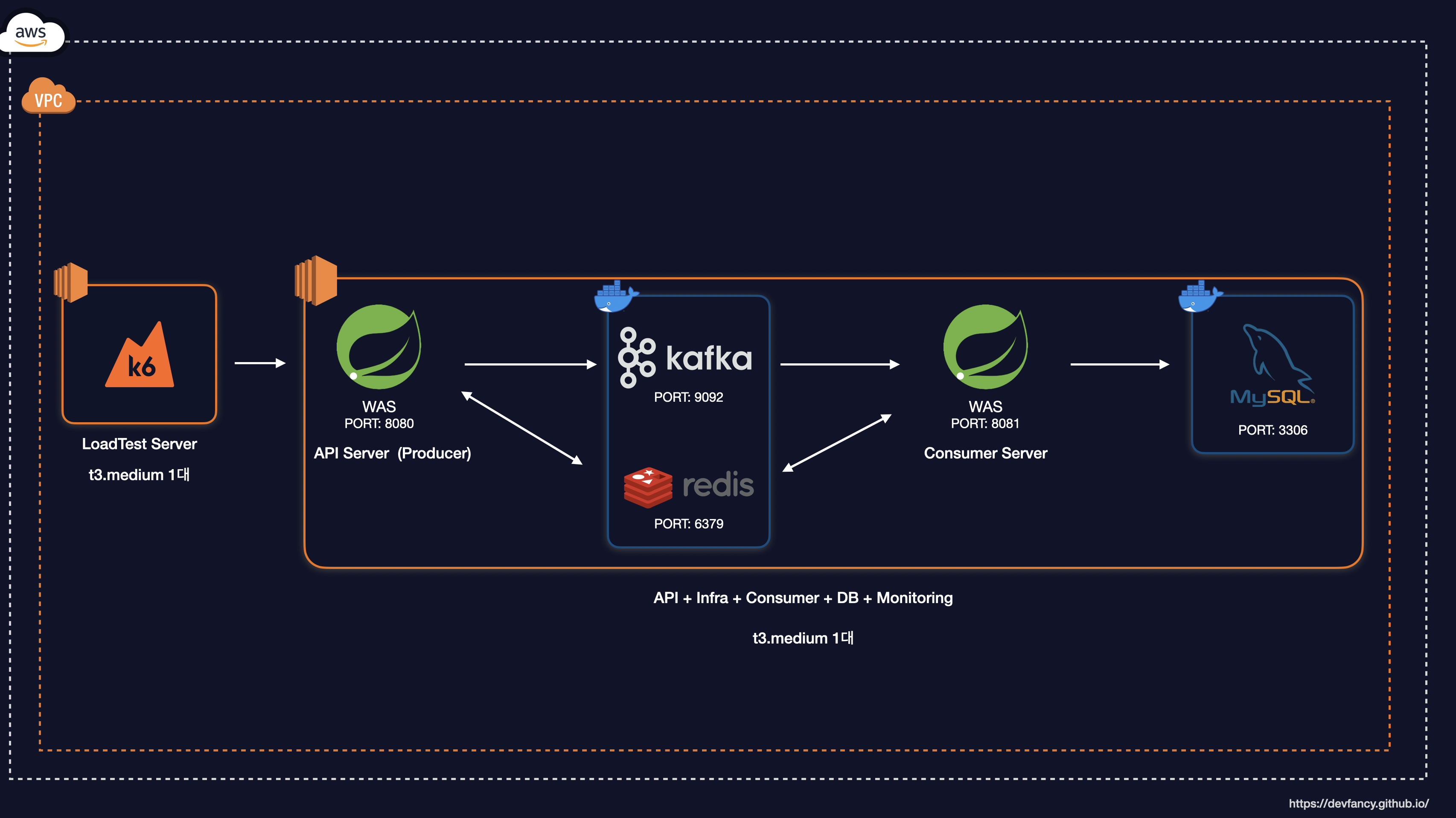
1. 초기 아키텍처 구성
이제 부하 테스트를 진행해보겠습니다.
동시 사용자 요청 500명 기준으로 부하 테스트를 진행한 결과, 한 가지 문제점을 발견했습니다. API 서버를 통과하여 Kafka에 적재된 요청에 대해 컨슈머 서버가 처리할 때 요청 수가 많아질 수록 CPU 점유율이 100%로 커지고, 처리할 수 있는 컨슈머 스레드가 포화 상태에 이르러 시스템 장애로 이어졌습니다.
이를 해결하기 위해 컨슈머 서버에 들어오는 트래픽을 조절하기 위해 Resilience4J 기반의 Rate Limiter를 도입했습니다.
이를 통해 단순히 요청을 제한하는 것을 넘어, 컨슈머 서버와 최종 저장소인 DB가 감당할 수 있는 수준으로 유입량을 조절하여 시스템 전체의 안정성을 확보하고자 했습니다.

(Redis 기반의 글로벌 Rate Limiter 구성도)
또한 단일 컨슈머 환경에서는 로컬 락만으로 충분할 수 있지만, 향후 트래픽 증가에 따른 컨슈머 증설(스케일 아웃)을 고려했을 때 서버 간 공유 자원 접근을 제어할 방법이 필요했습니다.
따라서 초기 설계에서는 Redis를 활용한 분산락을 통해 인스턴스 대수와 상관없이 쿠폰 중복 발급을 방지하는 동시성 제어 및 데이터 정합성을 확보했습니다.
(초기에는 데이터 정합성을 위해 분산락을 도입했으나 이후 구조적 단순화를 위해 DB 제약조건으로 개선하는 과정을 거쳤습니다.)
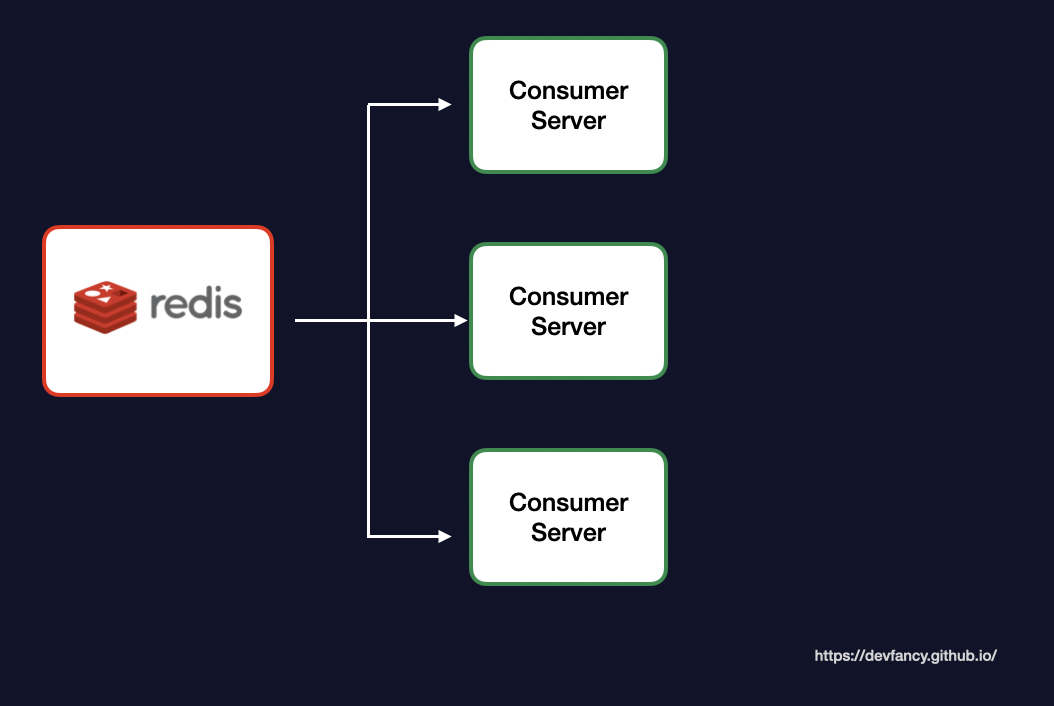
(초기 설계 시 도입했던 Redis 분산락 구조)
Redis 기반의 처리율 제한과 분산락을 적용한 쿠폰 발급 프로세스는 아래와 같습니다.
쿠폰 발급 프로세스
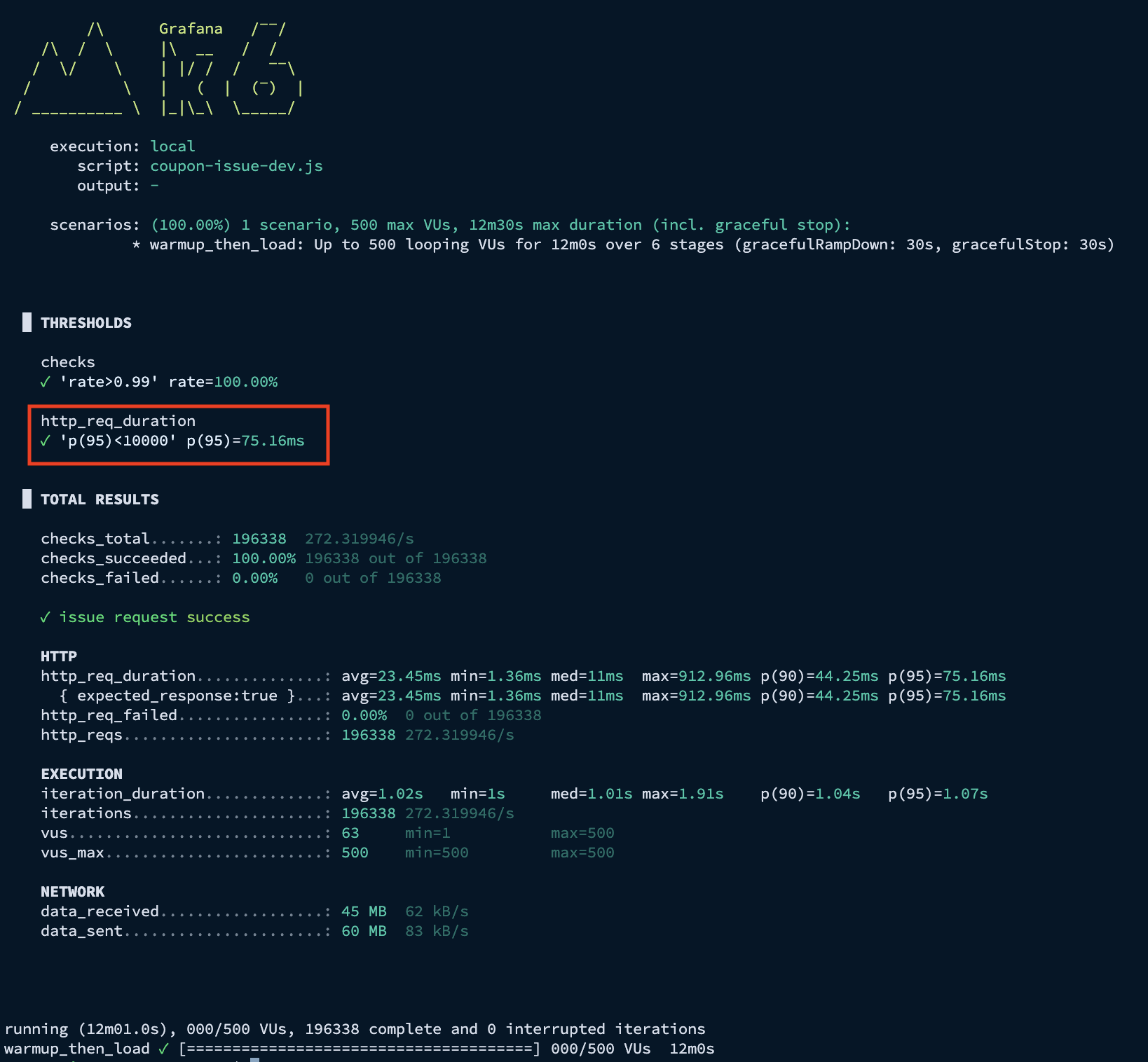
1-1. 부하 테스트 결과 (VU 500 / Rate Limiter 100)
이를 기반으로 첫 번째로 동시 사용자 요청 500명으로 설정하고 Rate Limiter 값을 100으로 적용한 뒤 부하 테스트를 진행한 결과, 저부하 상황에서는 지연 없이 정상 동작함을 검증했습니다.
K6 결과 - p95 응답 시간: 2.95s
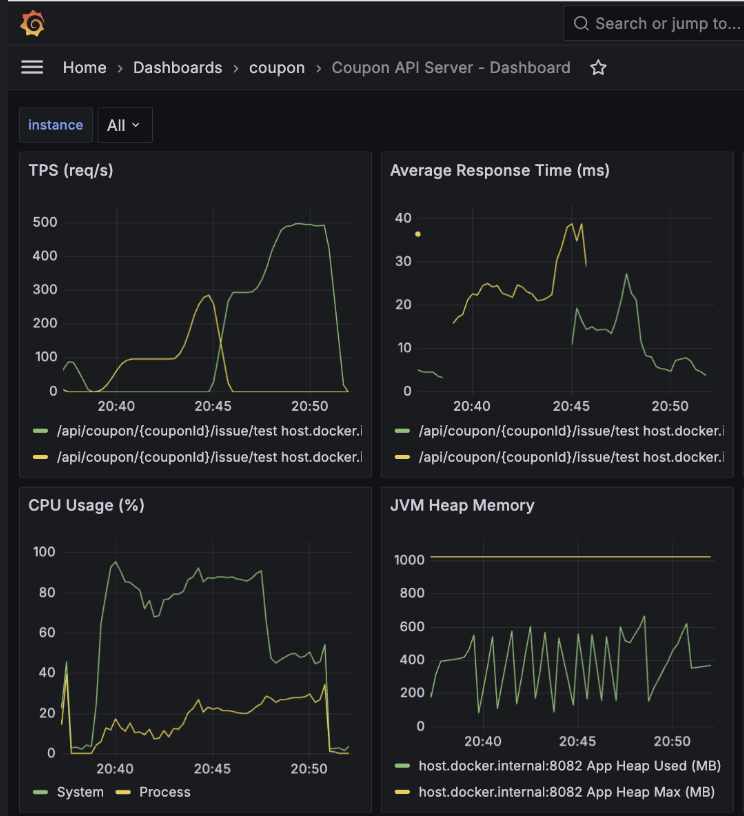
API 서버 결과 - 평균 TPS: 270, 최고 TPS: 400
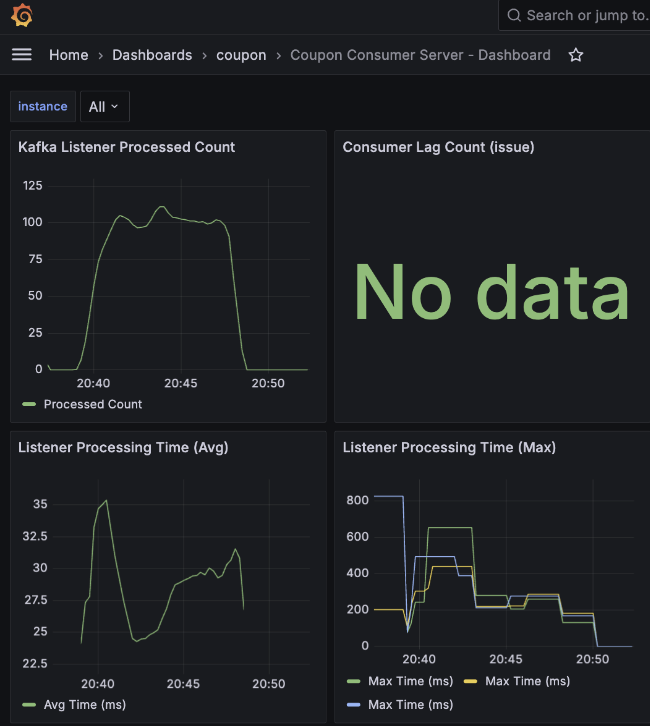
Consumer 서버 결과 - 평균 TPS: 100, 최고 TPS: 120
1-2. 부하 테스트 결과 (VU 5,000 / Rate Limiter 100)
두 번째로 동시 사용자 요청을 1,000명에서 5,000명으로 늘려 테스트를 진행하고 Rate Limiter 값을 100으로 적용한 뒤 부하 테스트를 진행한 결과,
단일 인스턴스 내 리소스 경합으로 인해 레이턴시가 이전 대비 약 40배(0.075s -> 2.95s) 가까이 상승하며 시스템이 포화점에 도달했음을 확인했습니다.
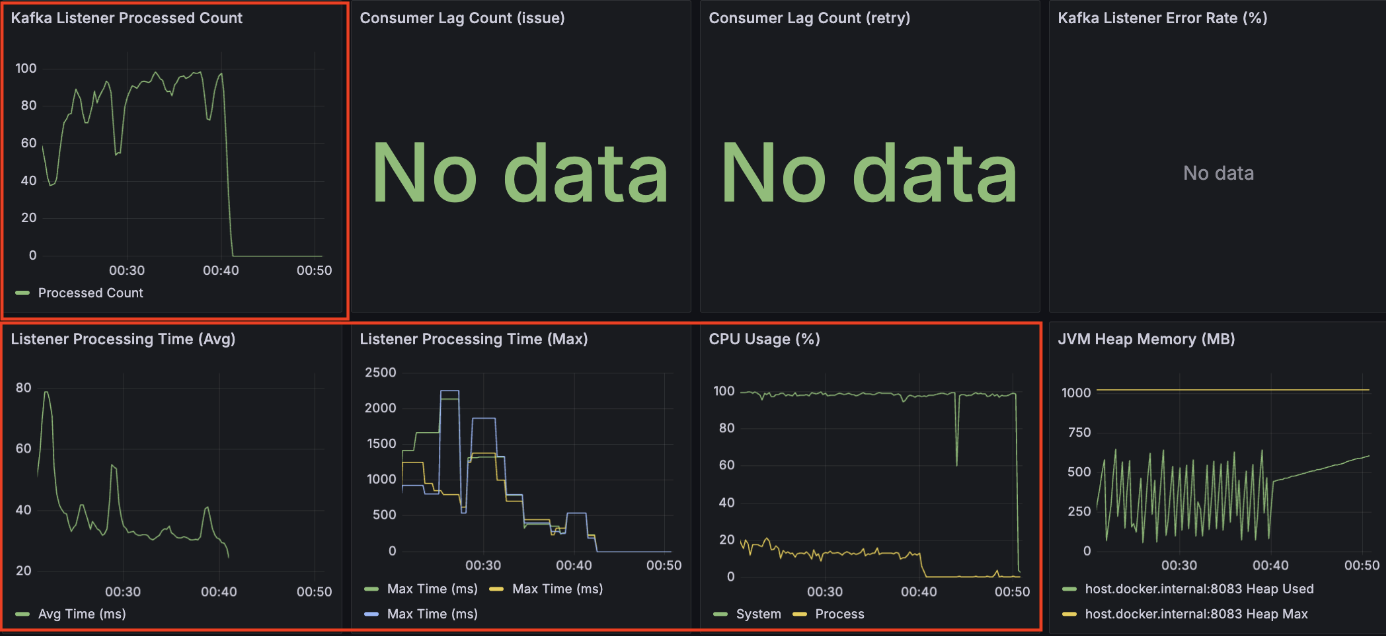
또한 고부하 상황에서 API 서버 대비 컨슈머 처리 속도가 현저히 낮아 Consumer Lag이 누적되면서, 이는 시스템 전반의 가용성을 저하시키는 핵심 병목임을 파악했습니다.
K6 결과 - p95 응답 시간: 6.75s
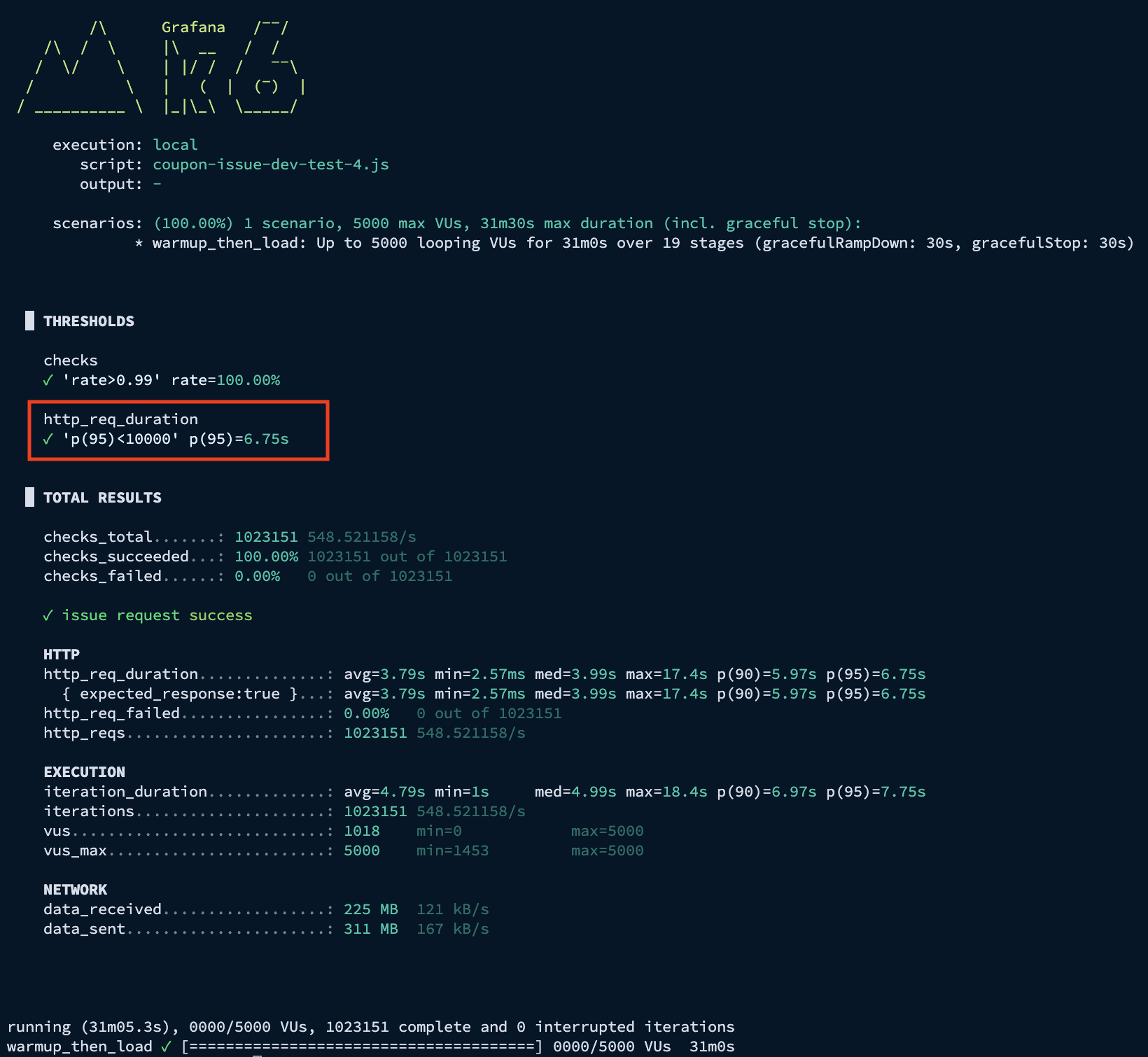
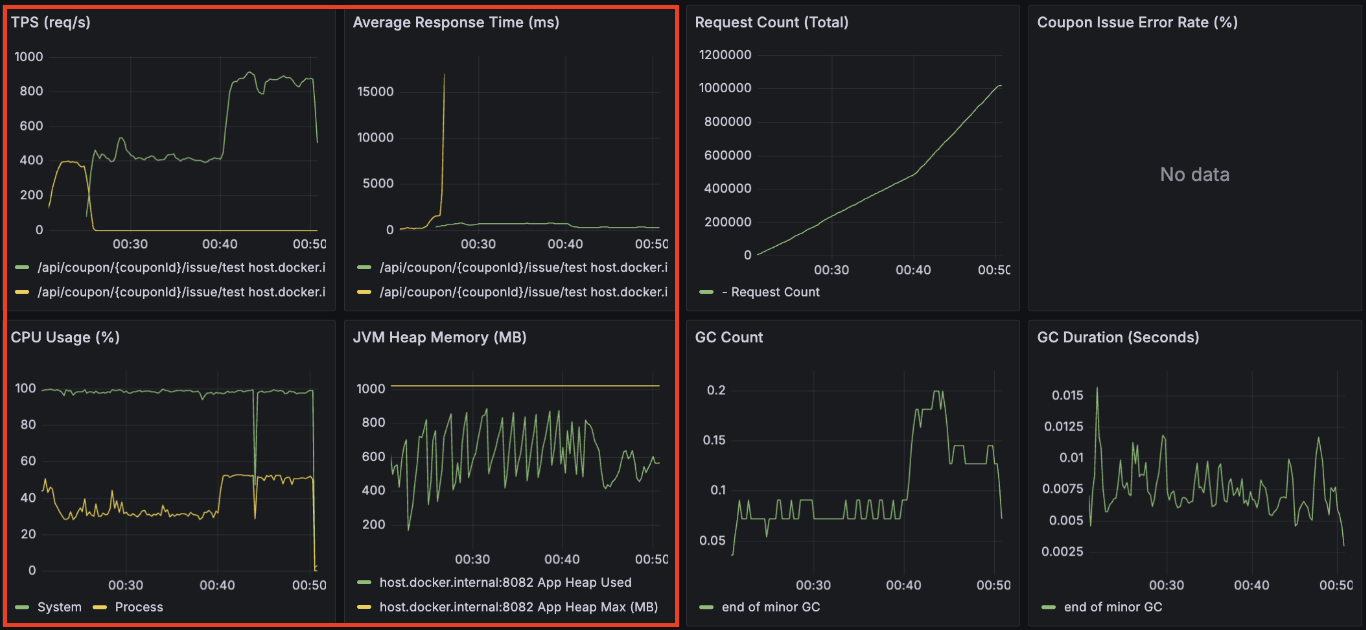
API 서버 결과 - 평균 TPS: 550, 최고 TPS: 900
Consumer 서버 결과 - 평균 TPS: 80, 최고 TPS: 95
API 서버와 컨슈머 서버의 CPU 점유율을 보면 System CPU 점유율은 100%에 육박하는 반면, 애플리케이션 자체가 점유하는 Process CPU는 상대적으로 낮아지는 것을 확인했습니다.
이는 단일 인스턴스 내에 API 서버, 컨슈머, Kafka, Redis, DB가 공존하면서 발생하는 컨텍스트 스위칭 오버헤드와 입출력 대기 시간이 시스템 전체에 악영향을 줄 수 있다는 것을 알 수 있습니다.
2. 인프라 확장 및 병목 지점 파악
사용자 증가에 따른 리소스 포화를 분석하고, 서버 인스턴스 분리 및 코드 리팩터링, 인프라 튜닝을 통해 처리량을 극대화하는 작업을 진행했습니다.
이전 테스트를 통해 단일 인스턴스 환경에서는 CPU 점유율이 100%에 도달하여 TPS를 높이는 데 한계가 있음을 확인했습니다.
이를 해결하고자 아래와 같이 시스템 아키텍처를 개선했습니다. 서버 사양이 상대적으로 덜 중요한 모니터링 서버는 t3.small로, 나머지는 t3.medium으로 인스턴스를 분리하여 할당했습니다.
-
API 서버: t3.medium
-
인프라 서버(Redis, Kafka, DB) - t3.medium
-
컨슈머 서버 - t3.medium
-
모니터링 서버 - t3.small
-
부하 테스트 서버 - t3.medium
Monitoring Architecture
새로운 아키텍처 기반으로 동시 사용자 5,000명 부하 테스트를 실시한 결과, 이전 대비 성능과 안정성이 개선되었습니다. 하지만 여전히 성능을 최적화할 여지가 있다고 판단하여 다음과 같은 주요 개선 작업을 수행했습니다.
주요 개선 작업
첫 번째로 Redis 분산락을 제거했습니다.
현재 시스템의 쿠폰 발급 로직은 발급 내역을 DB에 저장하는 단순한 구조입니다.
만약 포인트 차감이나 복잡한 비즈니스 로직이 포함된다면 분산락이 필수적이겠지만, 단순 INSERT 환경에서는 DB Unique Key(userId + couponId) 제약 조건만으로도 데이터 정합성을 충분히
보장할 수 있다고 판단했습니다.
제약 조건 위반 시 발생하는 예외를 애플리케이션에서 적절히 catch하여 처리함으로써, 락 획득과 해제에 드는 오버헤드를 제거하고 비즈니스 로직의 복잡도를 낮췄습니다.
분산락을 제거한 쿠폰 발급 프로세스를 수정하면 아래와 같습니다.
쿠폰 발급 프로세스
이렇게 함으로써 컨슈머 서버는 Redis의 처리율 제한만을 사용하여 이전보다 Redis에 대한 의존성을 줄일 수 있고, 비즈니스 로직 복잡도도 단순화했습니다.
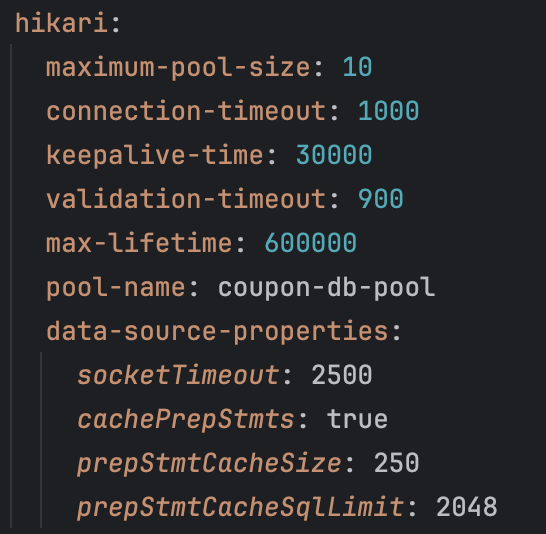
두 번째로 데이터베이스 가용성을 위해 HikariCP 설정을 진행했습니다.
시스템 장애 방지를 위해 최대 커넥션 풀 크기, 타임아웃, 캐시 크기를 현재 시스템 부하에 맞춰 조정했습니다.
DB (MySQL) - HikariCP
세 번째로 컨슈머 서버의 처리 성능을 강화하기 위해 스레드와 파티션 수를 조정했습니다.
API 서버의 유입 속도에 비해 컨슈머의 처리 속도가 낮아 발생하는 Consumer Lag을 억제하고자 컨슈머 인스턴스를 2대로 확장했습니다.
이때 컨슈머 스레드 수(Concurrency)를 10개, 파티션 개수를 20개로 설정하여 파티션 >= 총 컨슈머 스레드 수 공식을 유지했습니다.
또한, 컨슈머 스레드 수와 DB 커넥션 풀 사이즈를 동일하게 설정하여 커넥션 타임아웃 발생 리스크를 최소화했습니다.
추가로 max.poll.records를 500에서 2,000으로 상향하여 폴링 효율을 높였으며, 이에 맞춰 Rate Limiter 임계치도 1,000으로 상향 조정했습니다.
max.poll.records: 컨슈머 스레드가 poll() 메서드를 한 번 호출할 때 가져오는 최대 메시지 개수를 지정할 때 사용합니다.
마지막으로 모니터링 지표를 개선했습니다.
분산 환경에서 개별 서버 지표만으로는 전체 병목을 파악하기 어렵습니다. 특히 컨슈머의 처리 지연 상태를 클러스터 관점에서 관측하기 위해 Kafka Exporter를 별도의 Docker 컨테이너로 실행했습니다.
Consumer 서버 - Consumer Lag 모니터링 지표
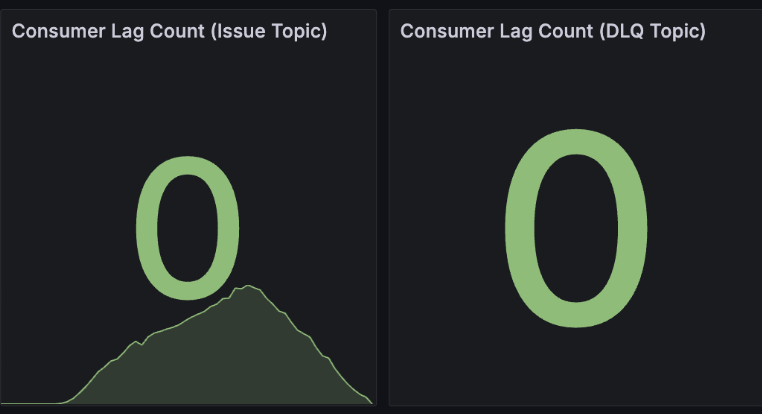
이를 통해 단순히 애플리케이션 내부 지표뿐만 아니라, Kafka 브로커 관점의 핵심 지표들을 Prometheus로 수집했습니다.
-
kafka_consumergroup_current_offset: 특정 컨슈머 그룹이 특정 파티션에서 마지막으로 읽고 커밋한 번호
-
kafka_consumergroup_current_offset_sum: 해당 토픽의 모든 파티션 오프셋을 합친 값
또한, 컨슈머 애플리케이션의 상세 메트릭 수집을 위해 MicrometerConsumerListener를 연동하여 가시성을 확보했습니다.
@Configuration
public class KafkaConsumerConfig {
//...
@Bean
public ConsumerFactory<String, CouponIssueMessage> consumerFactory(final MeterRegistry meterRegistry) {
// ...
DefaultKafkaConsumerFactory<String, CouponIssueMessage> factory =
new DefaultKafkaConsumerFactory<>(config, new StringDeserializer(), deserializer);
factory.addListener(new MicrometerConsumerListener<>(meterRegistry));
//...
}
//...
}
Consumer 서버 - 컨슈머 그룹 관련 모니터링 지표

특히 Kafka Listener Poll Interval 지표를 모니터링하면서 Rate Limiter로 인한 대기 시간이 리밸런싱 타임아웃(max.poll.interval.ms)을 초과하지 않는지 실시간으로
검증하며 튜닝을 진행했습니다
테스트 결과, 대기 시간이 임계치 이내에서 안정적으로 유지됨을 확인했으며, 이를 통해 처리율 제한과 컨슈머 그룹의 안정성 사이의 적절한 균형점을 찾을 수 있었습니다.
2-1. 부하 테스트 결과 (VU 7,000 / Rate Limiter 1,000)
개선 작업을 마친 후 동시 사용자 7,000명, Rate Limiter 1,000 설정으로 부하 테스트를 진행한 결과입니다.
K6 결과 - p95 응답 시간: 5.55s
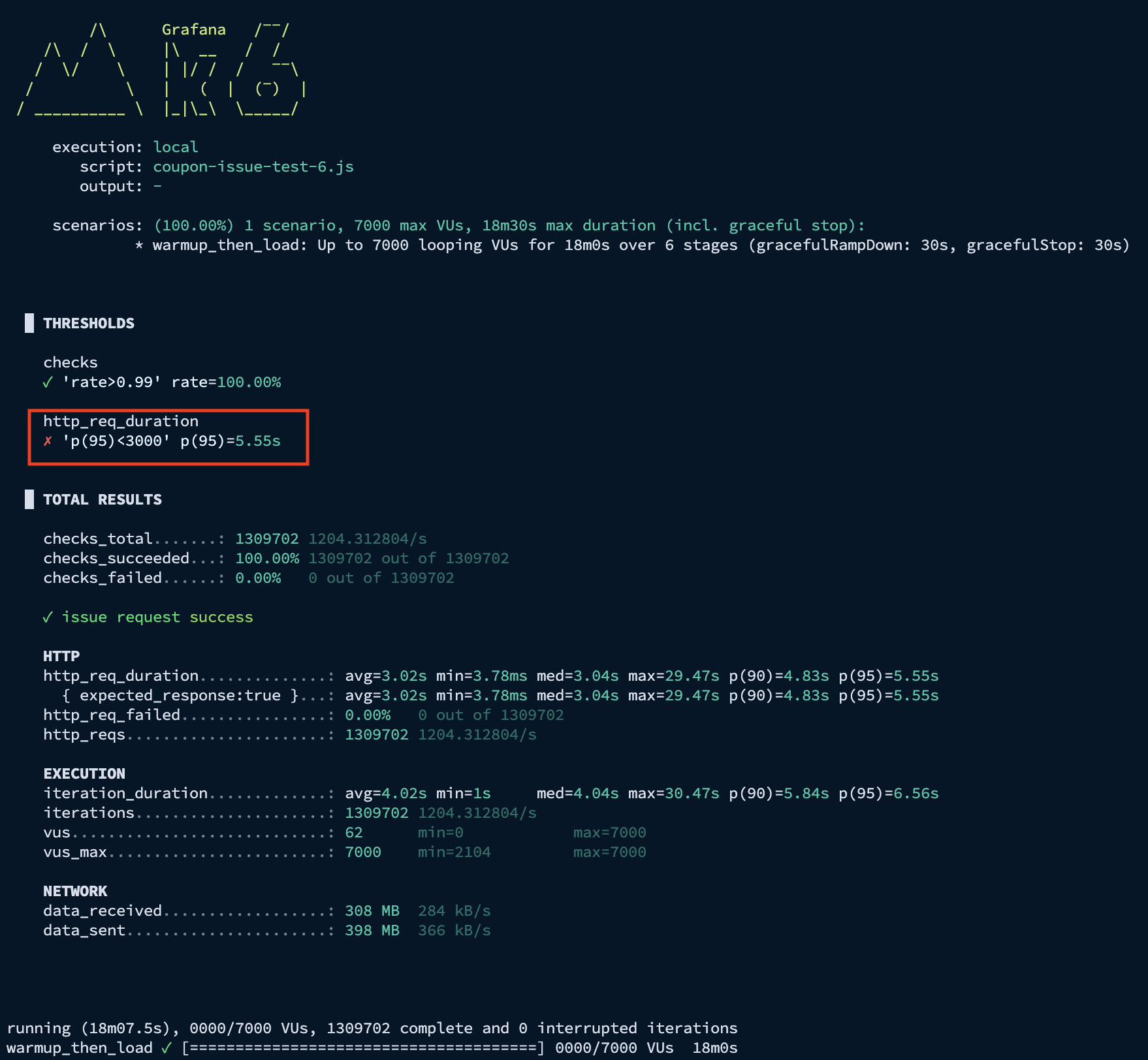
API 서버 결과 - 평균 TPS: 1,200, 최대 TPS: 1,450
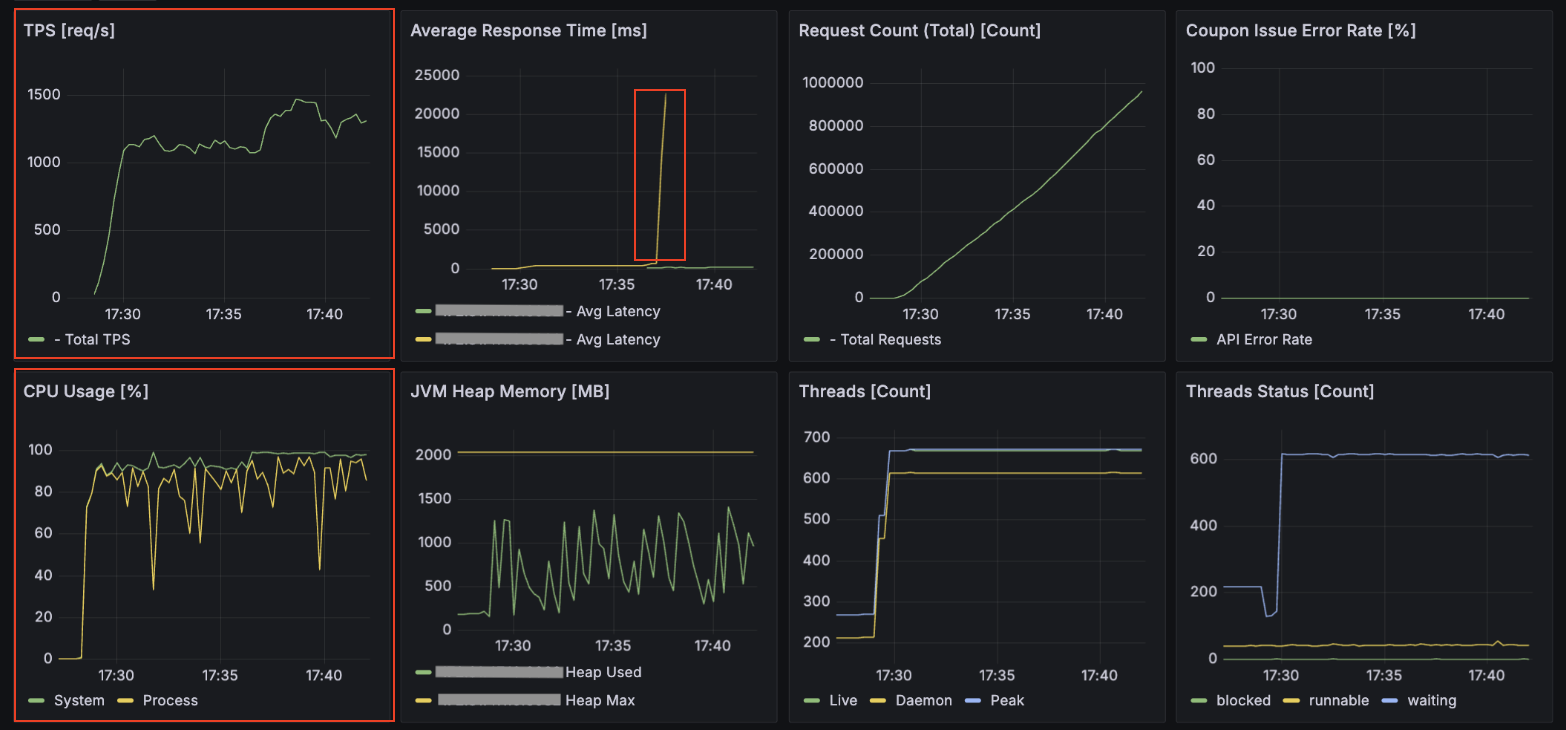
최대 TPS는 1,500에 근접했으나, 평균 응답 시간이 일시적으로 20초를 상회하는 병목 구간이 발견되었습니다.
특히 API 서버의 CPU 점유율은 90~100% 가까이 나왔고, 동시 사용자 요청이 5,000명 이상일 때 가끔씩 API 서버가 다운되는 현상이 발생했습니다.
아무래도 스레드 개수가 서버 사양에 비해 과도하게 설정되어, 컨텍스트 스위칭 비용이 많이 발생하면서 스레드가 멈춤으로써 서버 다운으로 이어지는 현상이 관측되었습니다.
Consumer 서버 결과 - 평균 TPS: 약 700, 최대 TPS: 810
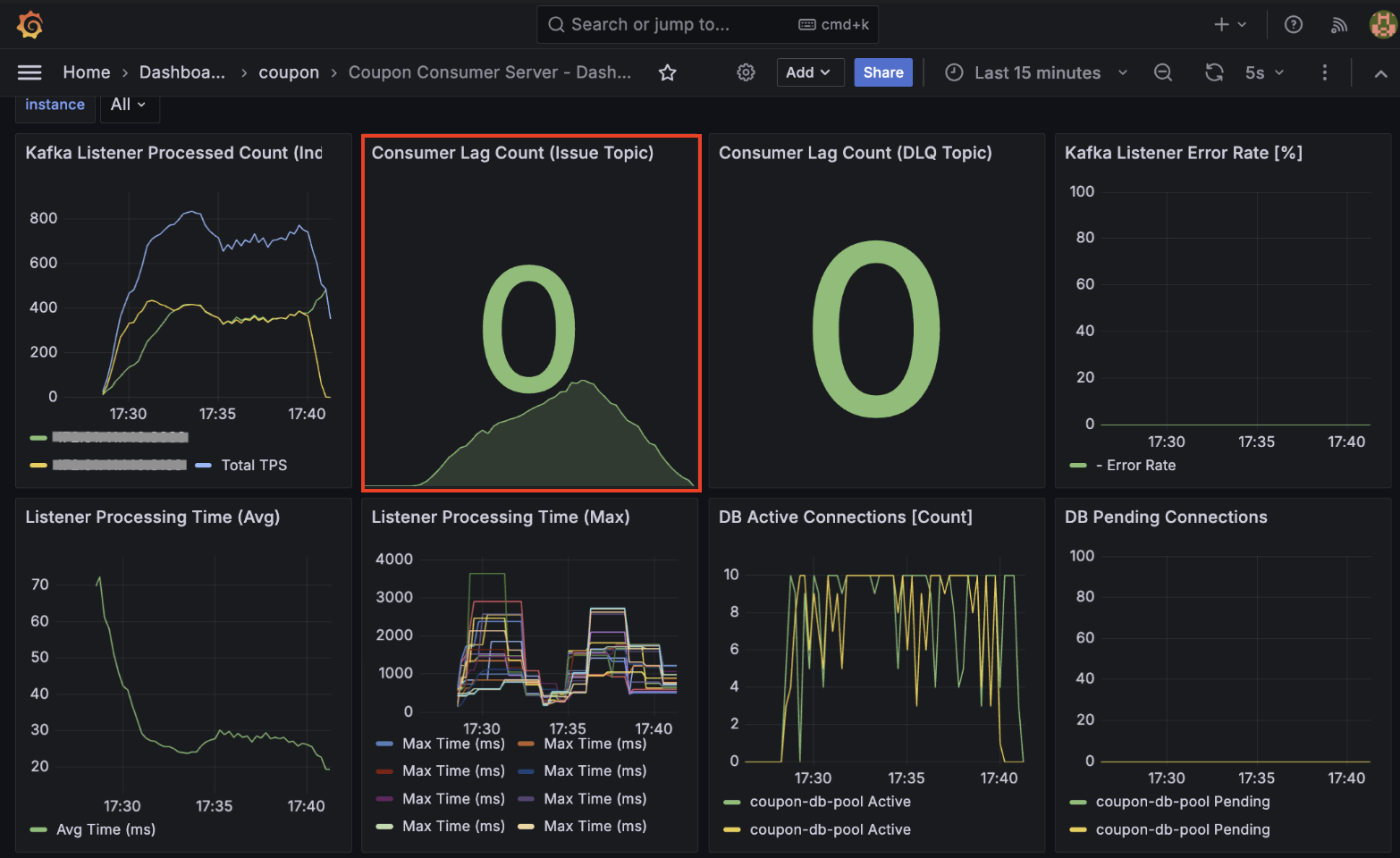
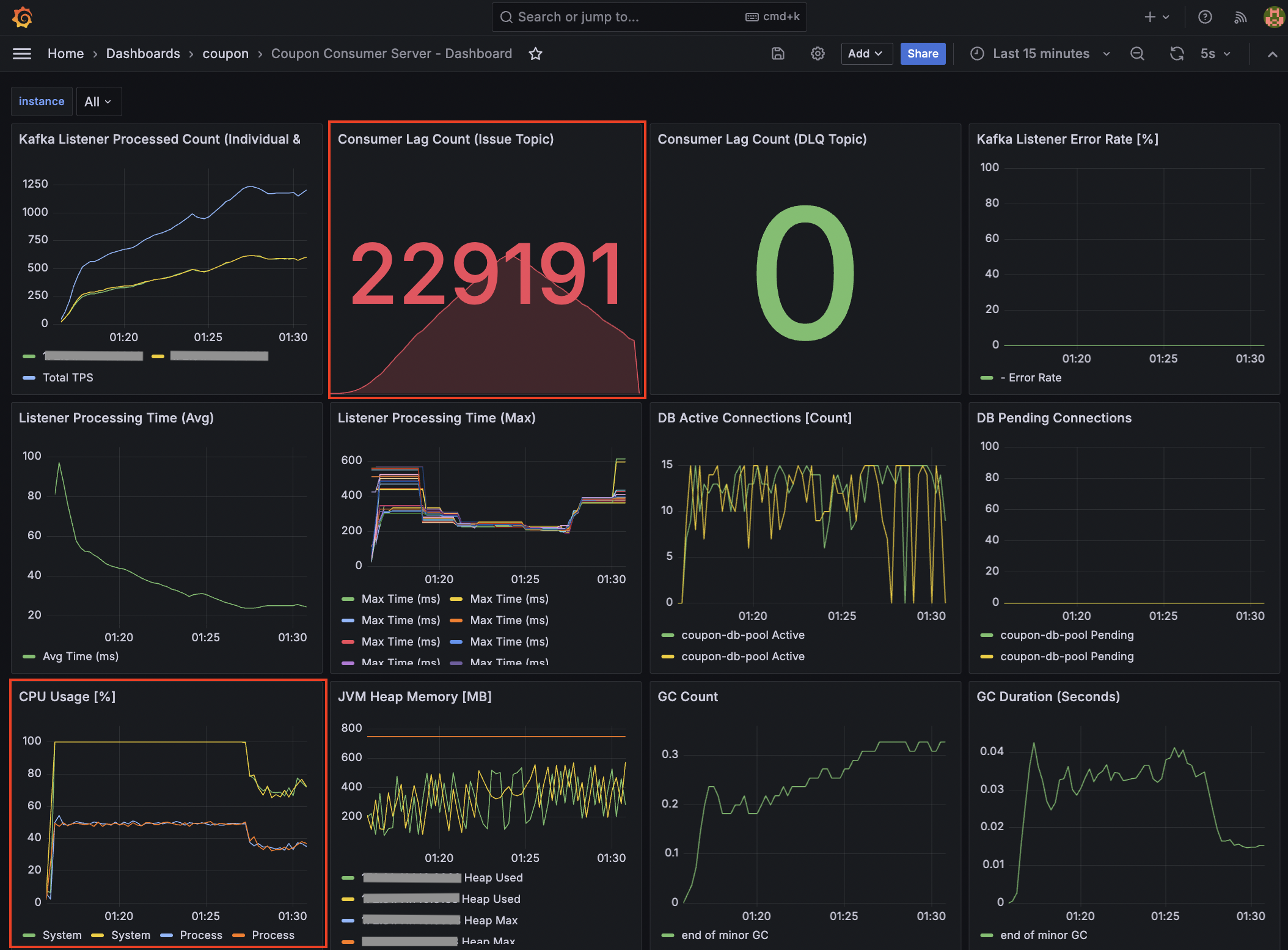
컨슈머 TPS는 최대 810 수준으로 API 서버의 유입 속도를 따라가지 못해 Consumer Lag이 상승했습니다.
Consumer 서버 - CPU 점유율: 70 ~ 85%
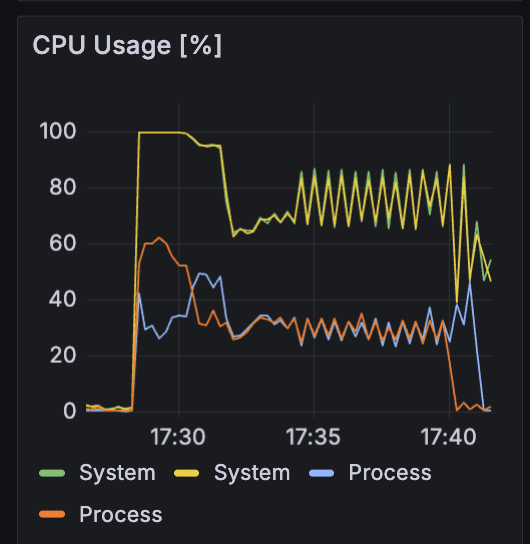
다만, 컨슈머 서버의 CPU 점유율이 70~85% 수준으로 여유 자원을 보유하고 있음을 확인했기에, Rate Limiter 임계치를 추가로 높여 처리량을 더 개선할 수 있다는 근거를 확보했습니다.
추가 개선 작업
기존 인프라 서버 내에서 DB의 CPU 점유율이 매우 높아 리소스 간섭이 발생하는 것을 확인했습니다.
이를 해결하기 위해 DB 서버를 인프라 서버에서 분리하여 전용 서버(t3.small)로 구축하고 아래와 같이 시스템 아키텍처를 개선했습니다.
System Architecture
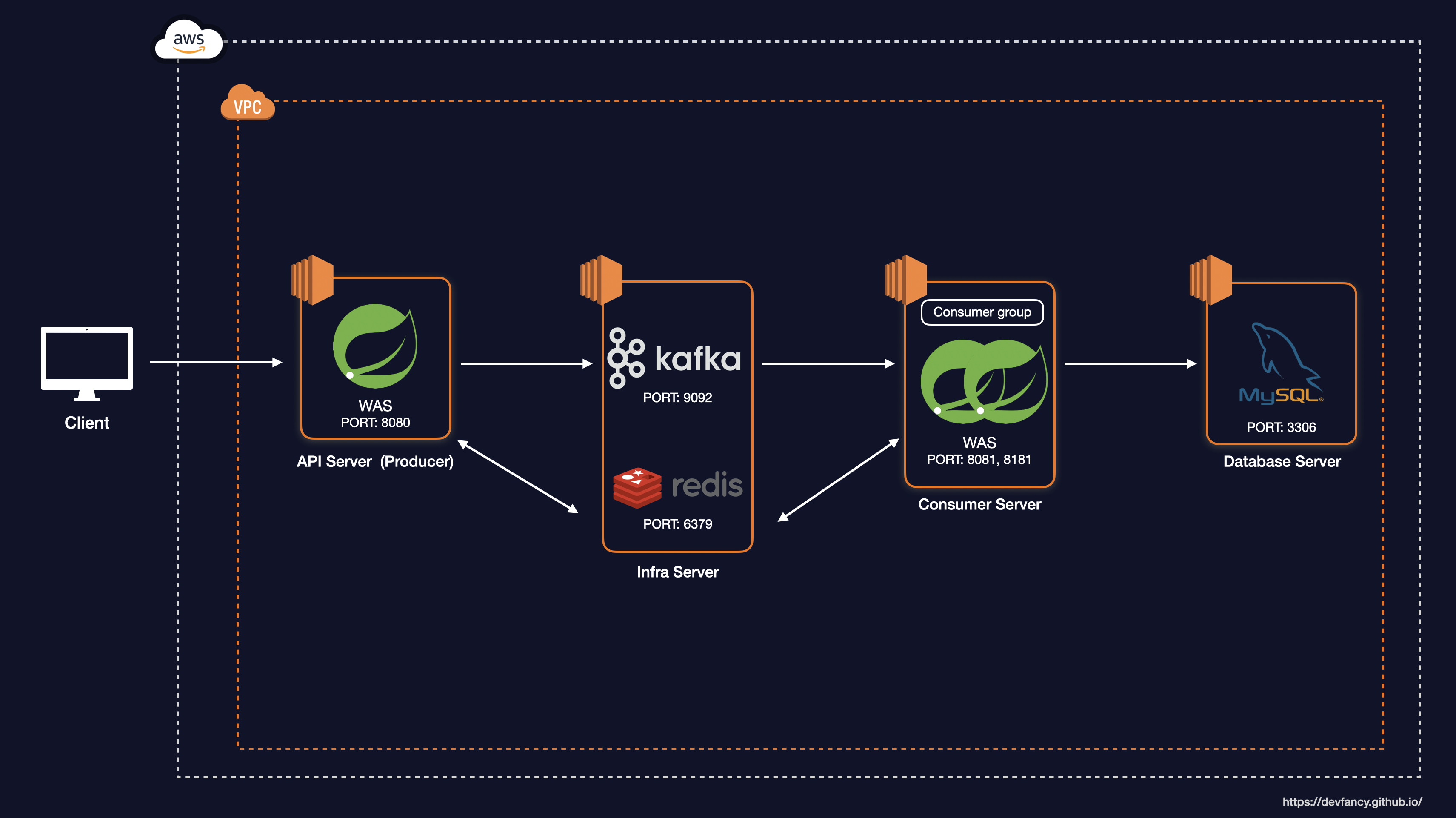
그리고 각 서버별로 사양에 맞게 튜닝 작업을 진행했습니다.
- API 서버
- tomcat.thread.max: 500 -> 200
- 컨슈머 서버
- 컨슈머 스레드 수: 10 -> 15
- 파티션 수: 20 -> 30
- Config 값 수정
- fetch.min.bytes: 1MB -> 1KB
- fetch.max.wait.ms: 1초 -> 0.2초
- DB 튜닝
- HikariCP maximum-pool-size: 10 -> 15
2-2. 부하 테스트 결과 (VU 7,000 / Rate Limiter 1,300)
K6 결과 - p95 응답 시간: 2.49s
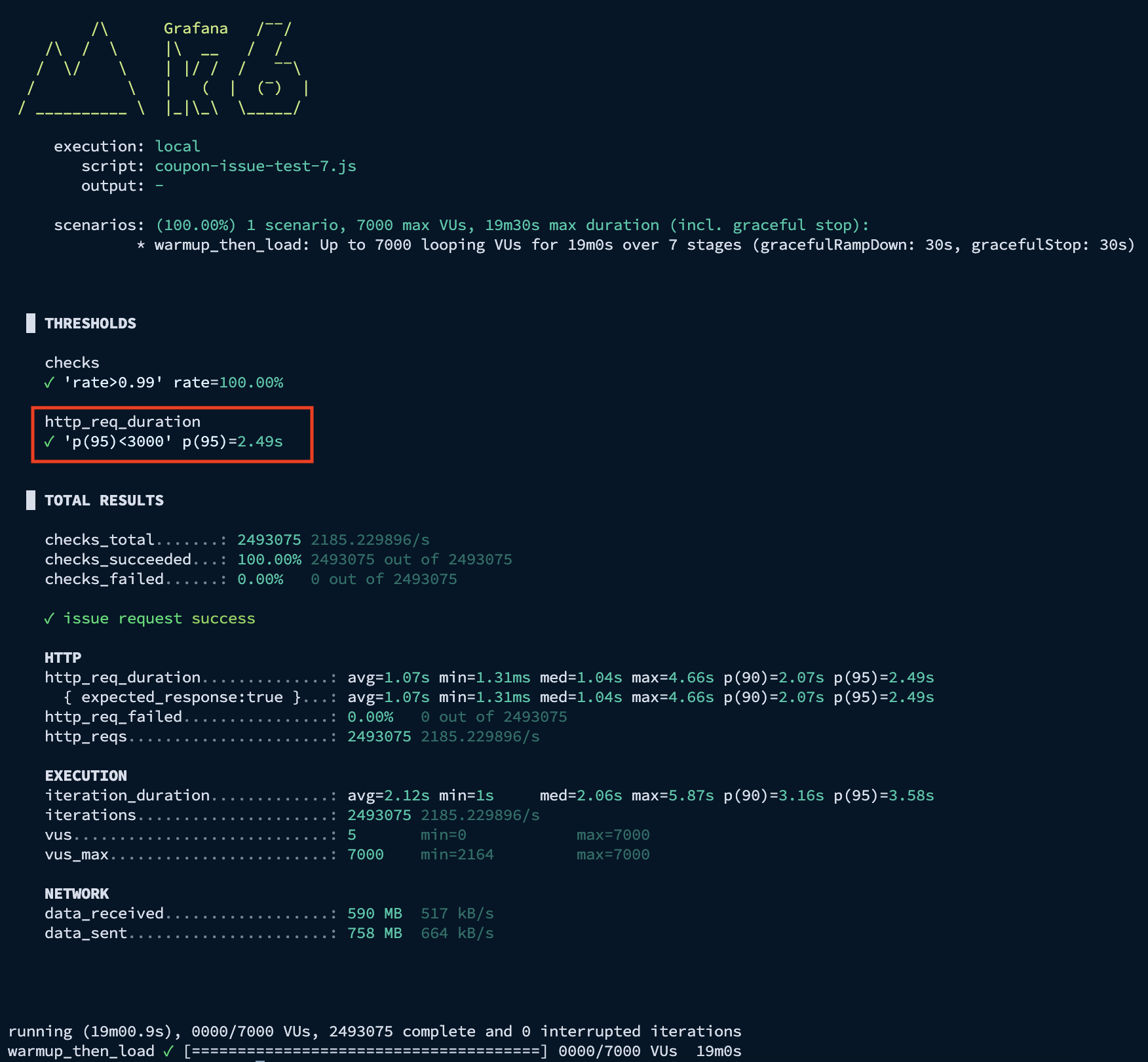
API Server 결과 - 최대 TPS: 2,500
Consumer Server 결과 - 최대 TPS: 1,250
DB 모니터링 결과 - CPU 점유율: 192% (2 vCPU 기준 Max 200%)

DB 서버를 분리한 후 p95 응답 시간은 2.49s로 목표치(3s 이내)를 달성했습니다. 하지만 이미지에서 확인되듯 DB 서버의 CPU 점유율이 192%에 도달하며 2-core 자원을 한계치까지 점유하고 있음을 확인했습니다.
처음 DB 서버를 분리할 때 가용 자원을 고려하여 t3.small을 선택했습니다.
API와 컨슈머 서버가 medium급인 것에 비해 DB 사양을 보수적으로 잡았던 이유는, 쿼리가 단순 INSERT 위주라 하드웨어 부하가 크지 않을 것이라 판단했기 때문입니다.
그러나 실제 부하 상황에서 수많은 컨슈머 스레드가 쏟아내는 쓰기 요청은 CPU 연산 부하를 예상을 훨씬 상회하게 만들었습니다. 비용을 최대한 아끼기 위해 단계적으로 접근했으나, 대규모 트래픽과 같은 환경에서는 DB가 시스템 전체의 최종 병목 지점이 될 수 있음을 알 수 있는 계기였습니다.
또한 컨슈머 서버 역시 CPU 100%를 기록하며 API 서버의 처리량을 따라가지 못해 Consumer Lag이 다시 증가하는 양상을 보였습니다. 이는 소프트웨어적 튜닝을 넘어선 물리적 한계로 판단되어, 서버 사양 자체를 높이는 Scale-up 결정을 내렸습니다.
추가 개선 작업
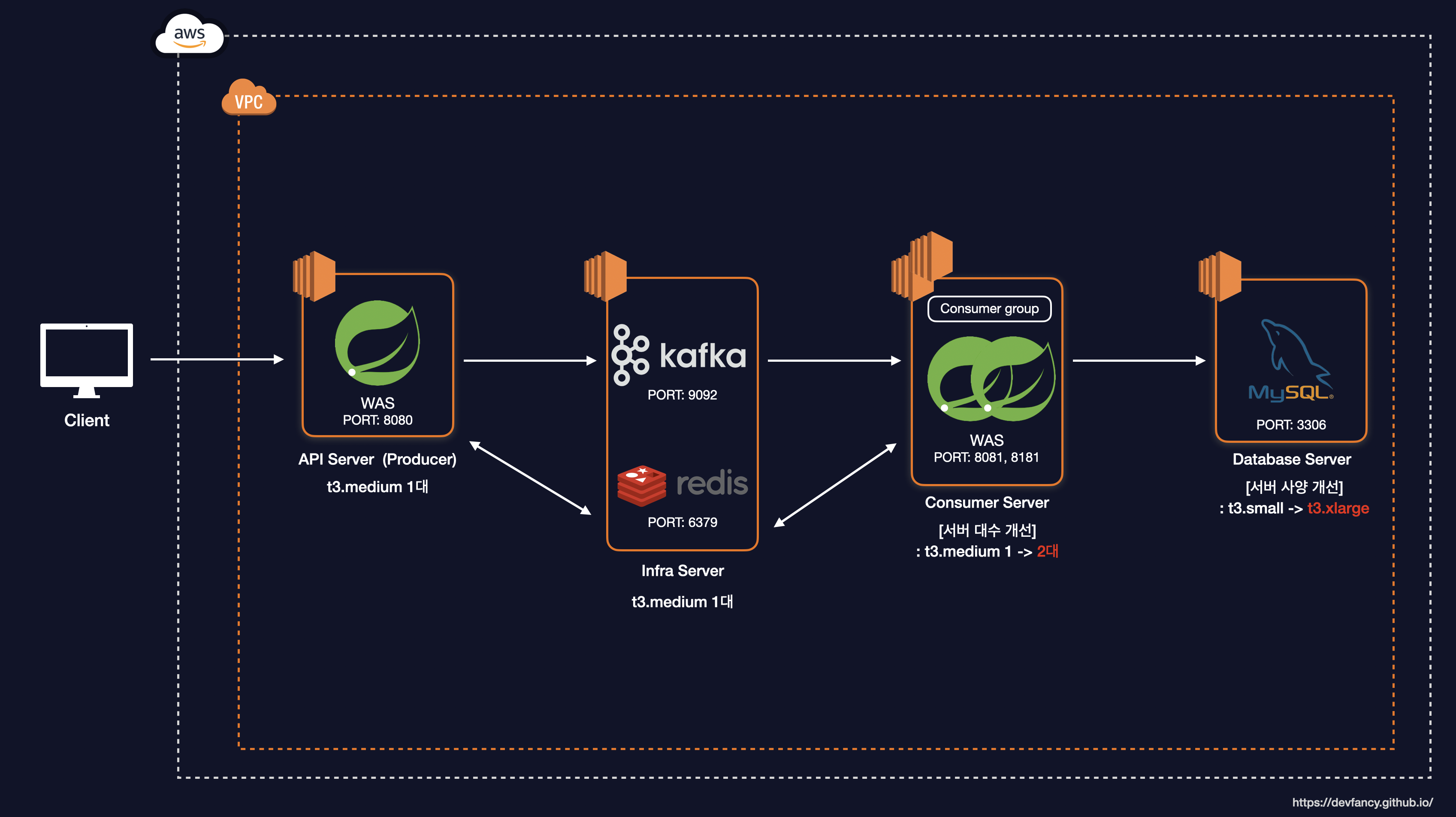
물리적 자원 한계를 극복하기 위해 DB 사양을 상향하고 컨슈머를 확장했습니다.
- 컨슈머 서버 수평 확장(Scale-out): 컨슈머 서버 인스턴스를 1대에서 2대로 증설했습니다. (
t3.medium) - DB 서버 수직 확장(Scale-up): 연산 병목 해소를 위해 DB 서버를 기존
t3.small(2-core) 에서t3.xlarge(4-core)로 업데이트했습니다.
이를 기반으로 시스템 아키텍처를 개선하고 세부 설정을 조정했습니다.
System Architecture
- 컨슈머 스레드 및 파티션 수 조정
- 컨슈머 스레드 수: 15 -> 20
- 파티션 수: 30 -> 40
- DB 튜닝
- HikariCP maximum-pool-size: 15 -> 20
- Redis 커넥션 및 타임아웃 관련 값 수정
- connectionPoolSize: 40
- connectionMinimumIdleSize: 12
- connectTimeout: 3000
- timeout: 1000
-
Rate Limiter 값 수정: 1,300 -> 2,700
- 모니터링 지표 개선
- DLQ 관련 지표 추가
- Kafka Listener Processing Time (Avg) 지표 추가
2-3. 부하 테스트 결과 (VU 10,000 / Rate Limiter 2,700)
API Server 결과 - 최대 TPS: 2,500
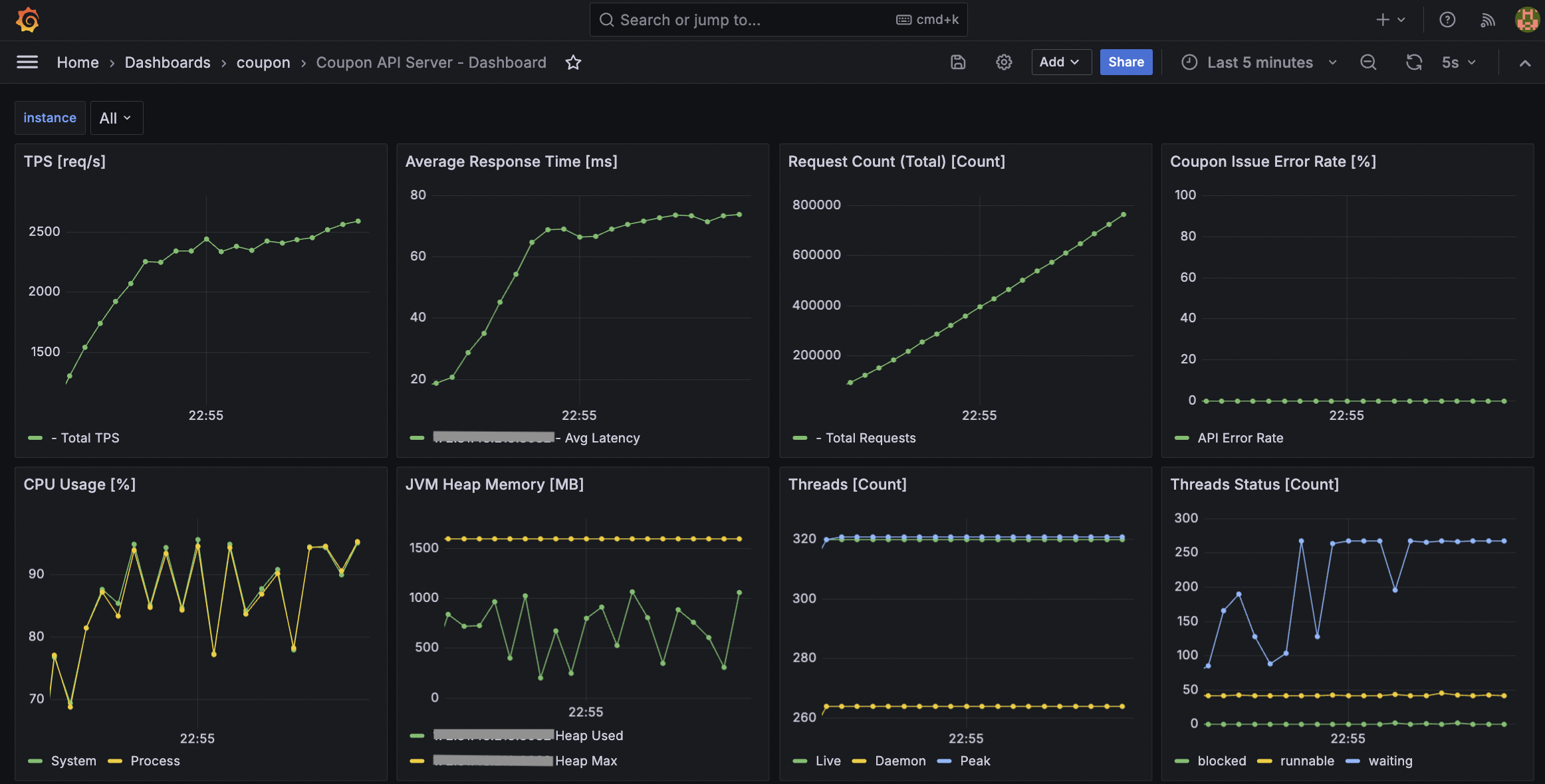
Consumer Server 결과 - 최대 TPS: 2,500
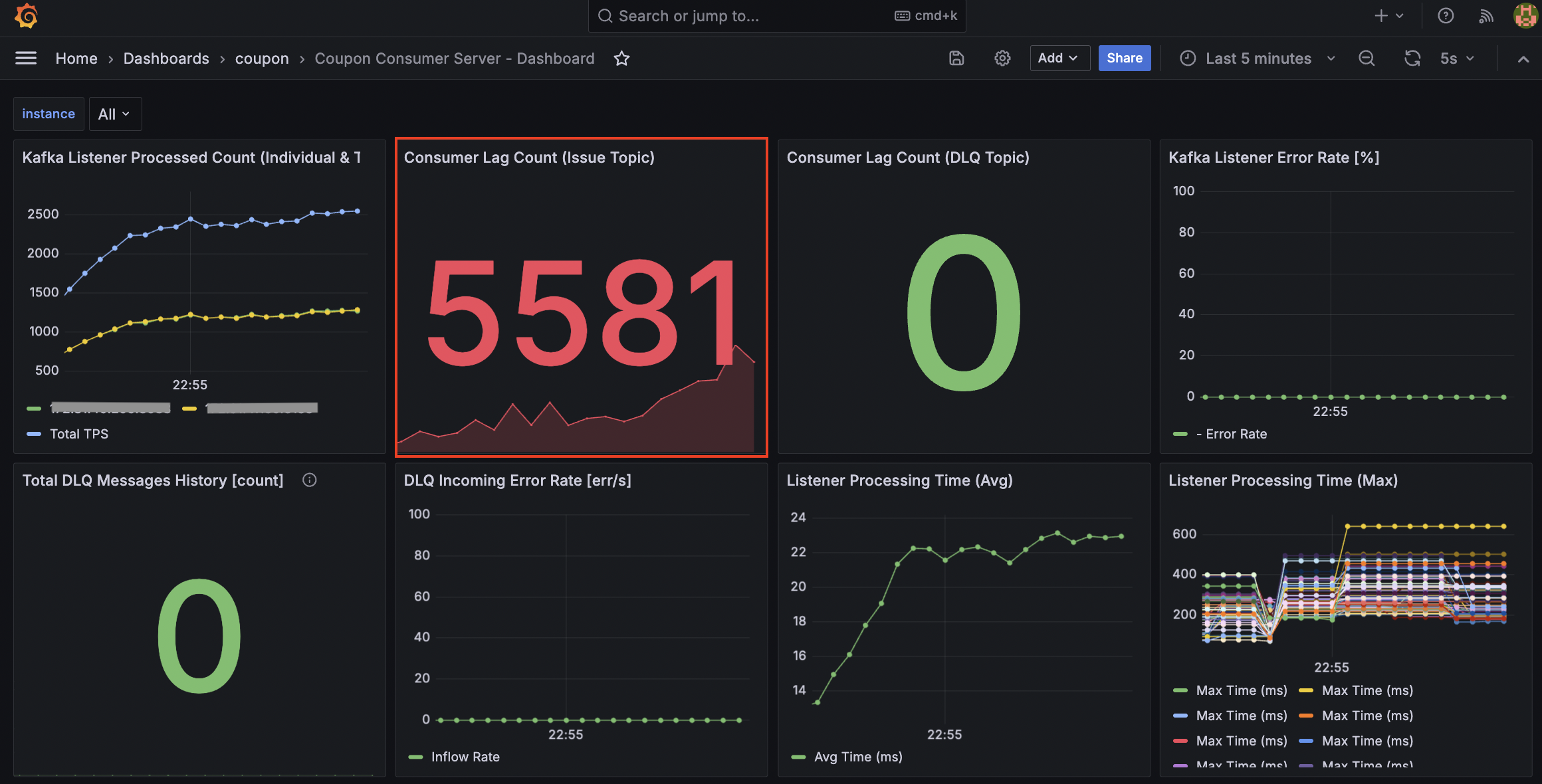
Consumer Lag이 10만 단위에서 1천 단위로 개선되어 유입 속도와 처리 속도의 균형을 맞췄습니다.
3. 시스템 안정성을 위해 고가용성 확보
이전 부하 테스트를 통해 유입 속도와 처리 속도의 균형을 맞췄지만, 단일 브로커구성은 하드웨어 장애 발생 시 전체 서비스가 마비될 수 있는 단일 장애점(SPOF)이라는 위험이 존재했습니다.
실제 운영 환경 수준의 안정성을 확보하기 위해, 성능을 일부 희생하더라도 데이터 유실을 방지하고 시스템의 지속성을 보장하는 고가용성 아키텍처를 구축하고자 했습니다.
이를 위해 브로커를 이중화하고 복제 설정을 적용하여 아래와 같이 시스템 및 모니터링 아키텍처를 최종적으로 개선했습니다.
System Architecture
Monitoring Architecture
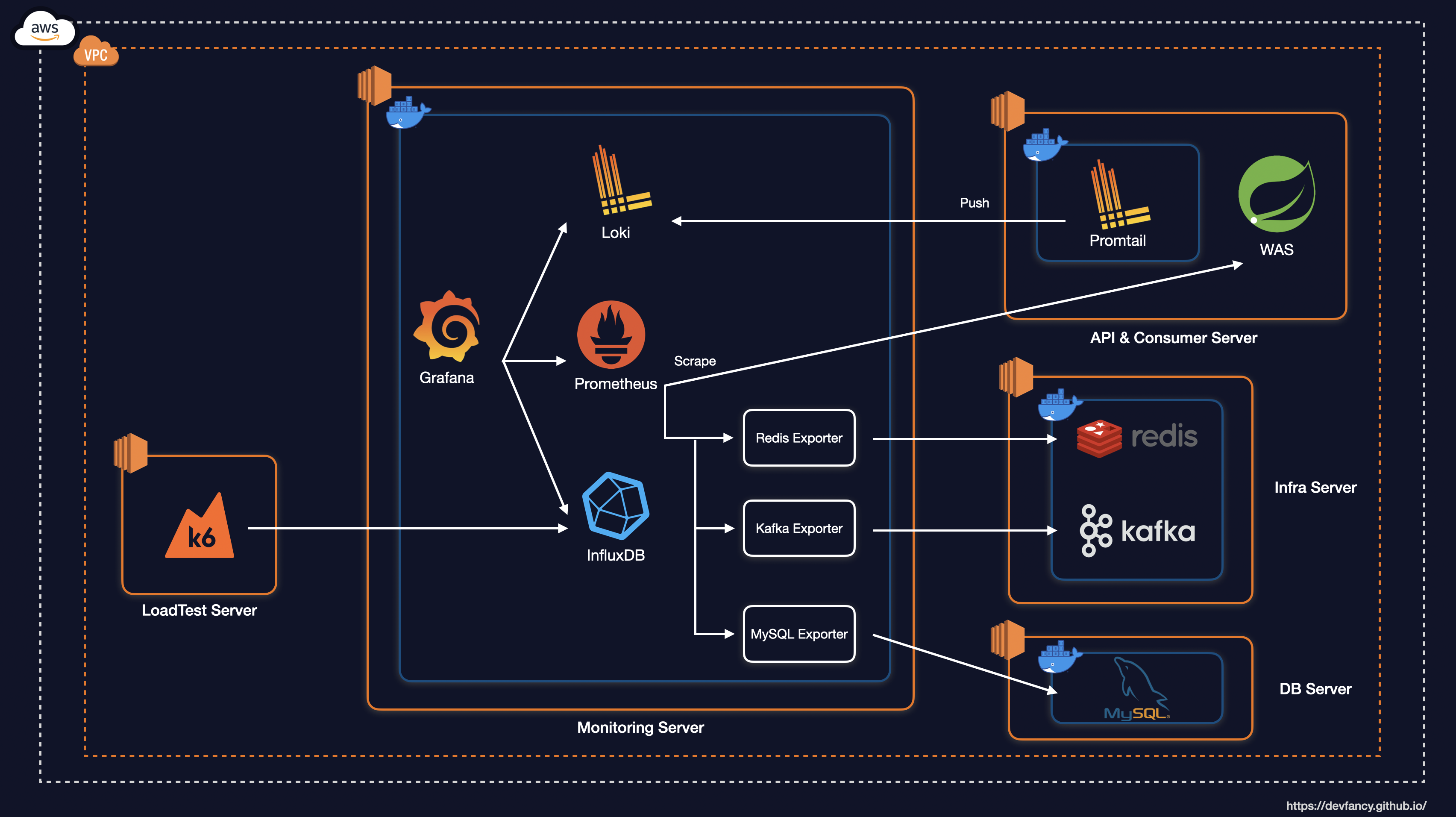
위 아키텍처를 기반으로 안정성을 확보하기 위해 적용한 주요 개선 작업은 다음과 같습니다.
주요 개선 작업
첫 번째로 카프카 클러스터의 고가용성을 확보했습니다.
운영 환경에서는 통상 3대 이상의 브로커로 구성하지만, 본 프로젝트에서는 한정된 인프라 자원(t3.medium) 내에서 가용성을 테스트하기 위해 최소한의 이중화인 2대 구성을 채택했습니다.
-
Broker: 브로커 수를 1개에서 2개로 증설하여 단일 장애점을 제거했습니다. 이때 메모리 부족 현상을 방지하기 위해 브로커 1대당 512M로 힙 메모리를 제한했습니다.
-
Topic 설정: 브로커가 2대인 상황에서 데이터 무결성을 보장하기 위해
replication.factor=2,min.insync.replicas=2로 설정했습니다. 이를 통해 브로커 한 대가 다운되더라도 데이터가 유실되지 않도록 조치했습니다.
2026.01.30 추가 - 2개의 브로커 구성 시
min.insync.replicas설정의 문제점과 해결 방안
- 문제 상황 및 원인 분석: 운영 환경에서 브로커 2대 중 1대가 다운되면, 프로듀서가 메시지를 보낼 때 다음과 같은 상황이 발생하게 됩니다.
- 브로커 1대가 다운됨에 따라, 해당 토픽의 ISR(In-Sync Replicas, 동기화된 레플리카) 개수가 1개로 줄어듭니다.
- 이때 리더 브로커는 설정된
min.insync.replicas=2조건과 현재 ISR 개수(1개)를 비교합니다. - 결과적으로 현재 ISR는 1개이고, 최소 요구 조건(2개)을 충족하지 못하므로, 브로커는 프로듀서의 쓰기 요청을 거부합니다.
- 에러 로그 확인: 이런 경우 프로듀서 쪽인 API 서버에서 다음과 같은 예외가 발생하며 서비스 장애로 이어지게 됩니다. (브로커 -> 프로듀서에게 에러를 뱉음)
- Error Message:
org.apache.kafka.common.errors.NotEnoughReplicasException: Messages are rejected since there are fewer in-sync replicas than required. - 결과적으로 안정성을 위해 브로커를 2대로 늘렸음에도 불구하고, 설정값을 잘못했기 때문에 단일 브로커일 때보다 가용성이 떨어지는 역설적인 상황이 발생하게 됩니다.
- Error Message:
- 해결 방안: 이를 해결하기 위해서는 현재
t3.medium이라는 한정된 자원(최대 브로커 2대)에서 다음과 같이 해당 방안을 떠올려볼 수 있습니다.- 브로커 2대 환경에서 가용성을 보장하려면
min.insync.replicas값이 반드시 1이여야 합니다. 이렇게 하면 브로커 1대가 죽더라도 남은 1대가 메시지를 받아내므로 서비스 중단을 막을 수 있습니다. - 참고) 가장 이상적인 방법은 브로커를 3대로 증설(
replication.factor=3,min.insync.replicas=2)하는 것입니다. - 하지만 이는 트래픽 규모와 인프라 비용을 고려해야 하므로, 향후 서비스 성장에 맞춰 서버 사양 증설과 함께 고려하기로 결정했습니다.
- 브로커 2대 환경에서 가용성을 보장하려면
두 번째로 프로듀서와 컨슈머의 Config 값을 튜닝하여 안정성을 높였습니다.
-
Producer:
batch.size를 64KB에서 32KB로,linger.ms를 10ms에서 5ms로 줄여, 처리량보다는 전송 지연 시간을 줄이는 방향으로 조정했습니다. -
Consumer:
fetch.min.bytes와max.poll.records를 하향 조정하여, 한 번에 가져오는 데이터 양을 줄이는 대신 리밸런싱 위험을 낮추고 안정적인 처리가 가능하도록 했습니다.
세 번째로 인프라 확장에 맞춰 Redis, Kafka, DB 튜닝 작업을 진행했습니다.
- 컨슈머 스레드 및 파티션 수, DB HikariCP 조정
- 컨슈머 스레드 수: 15 -> 30
- 파티션 수: 30 -> 60
- DB 튜닝
- maximum-pool-size: 20 -> 30
- Redis 관련 커넥션 풀 사이즈 값 수정
- connectionPoolSize: 40 -> 65
마지막으로 기존 API 및 Consumer 서버에서 각 서버별로 모니터링 대시보드 구축 및 지표를 개선했습니다.
-
API Server - 부하 테스트 관련 지표, 시스템 관련 지표, 애플리케이션 관련 지표
-
Infra Server - Redis, Kafka
-
Consumer Server - 부하 테스트 관련 지표, 시스템 관련 지표, 애플리케이션 관련 지표
-
Database Server - MySQL
부하 테스트 결과 (아키텍처 개선 후 VU 7,000 / Rate Limiter 2,700)
K6 결과 - p95 응답 시간: 5.97s
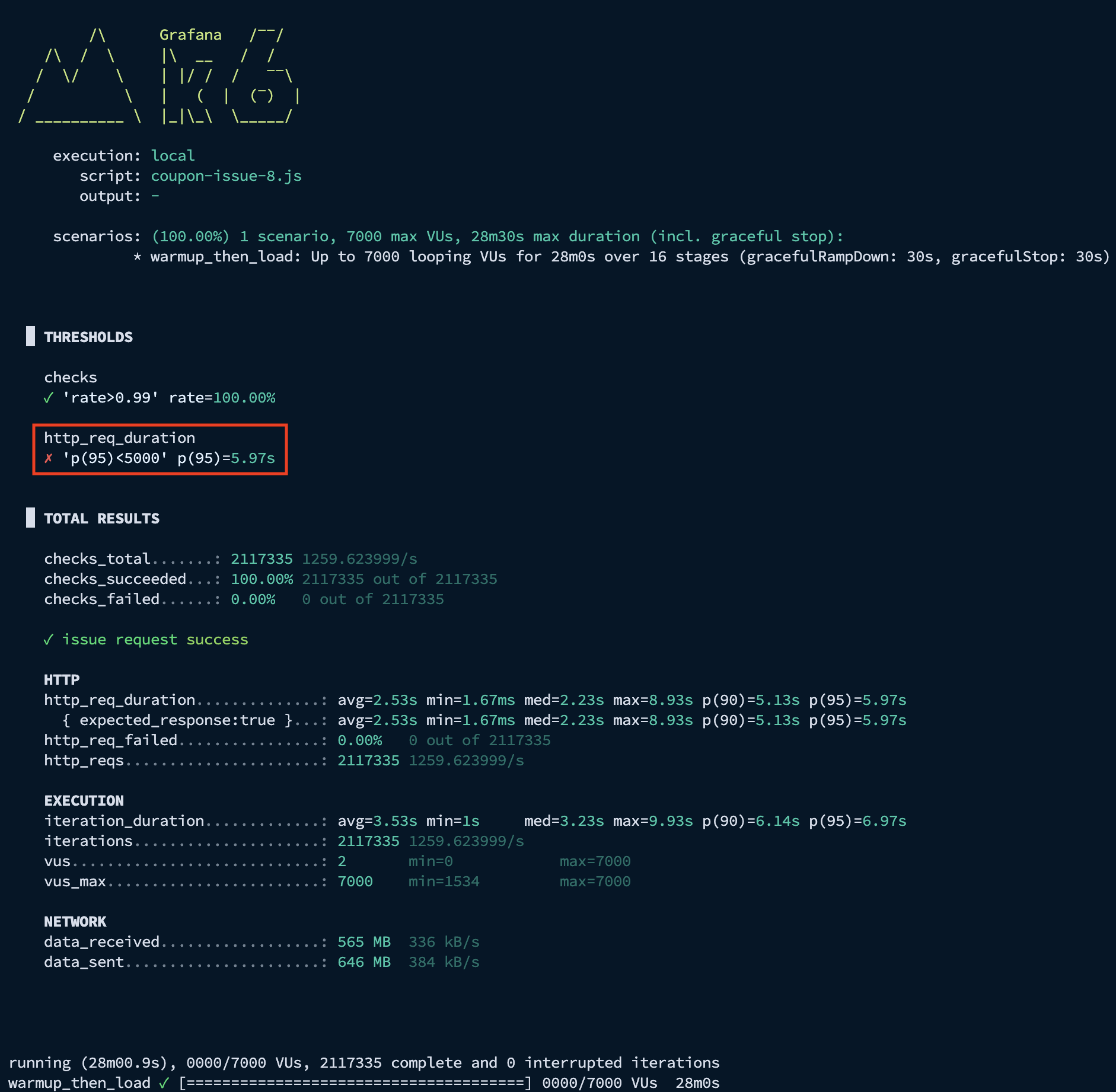
약 210만 건의 요청 중 실패 없이 100% 성공했습니다.
설정한 임계치(5s)를 소폭 상회하는 결과는 API 서버의 CPU 포화로 인한 병목임을 확인했습니다.
API Server 결과 - 최대 TPS: 1,830, 평균: 1,550
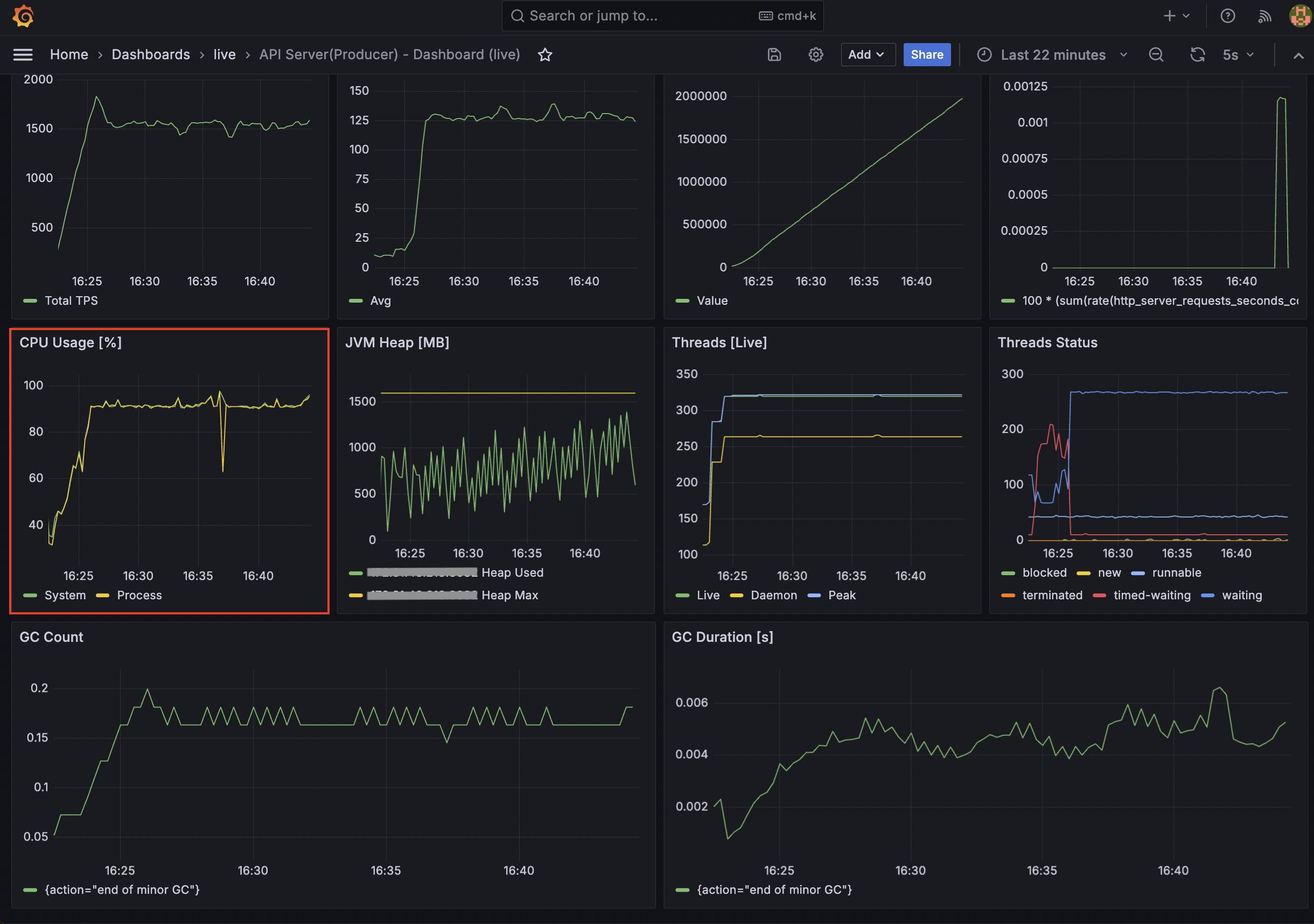
Consumer Server 결과 - 최대 TPS: 1,820, 평균: 1,550
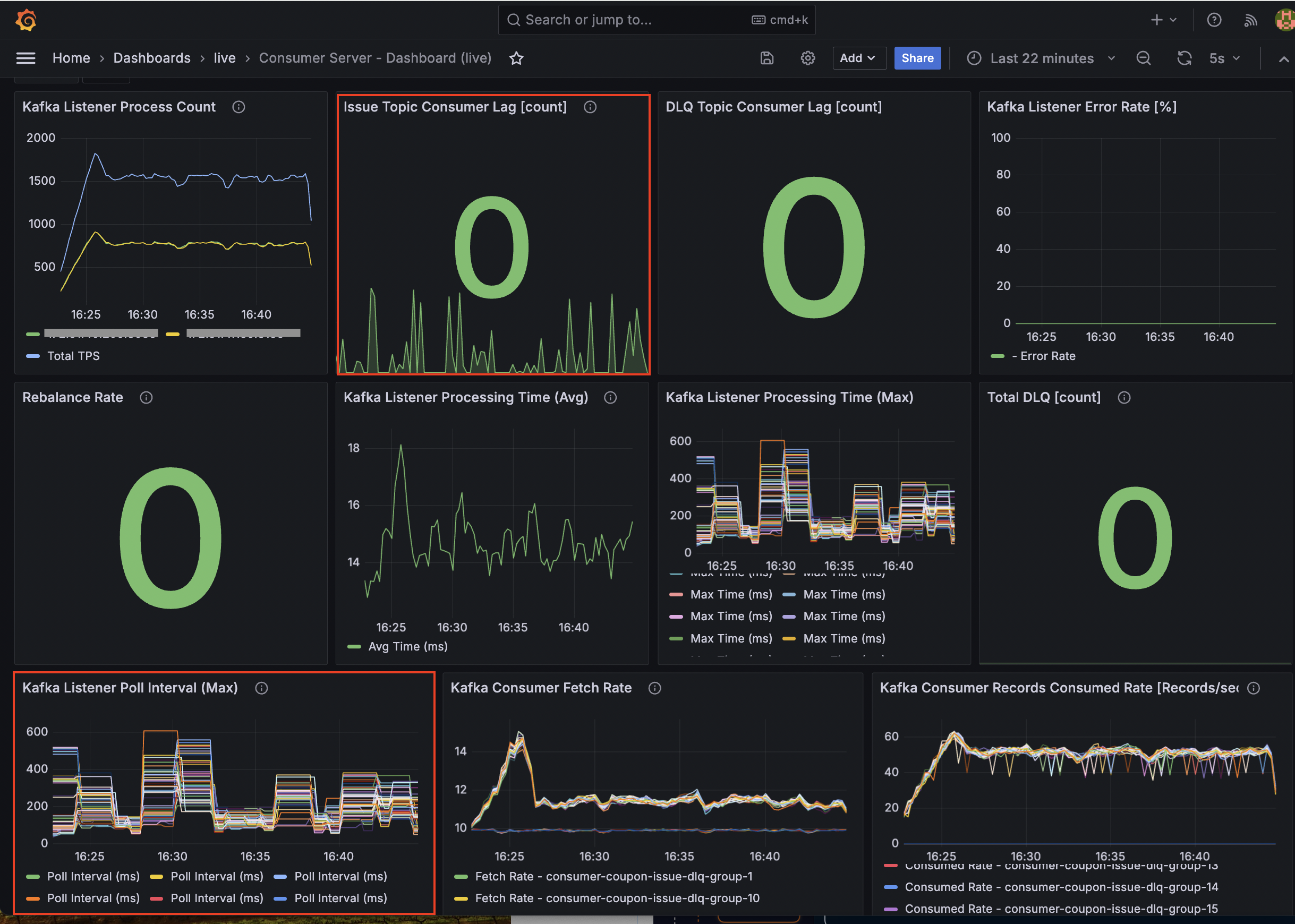
대량의 메시지가 인입되는 순간 일시적인 지연(Lag)이 발생했으나, Consumer 서버의 TPS가 API 서버의 TPS를 따라잡으면서 Consumer Lag이 0에 수렴하는 안정적인 구조를 확인했습니다.
Infra Server - Monitoring
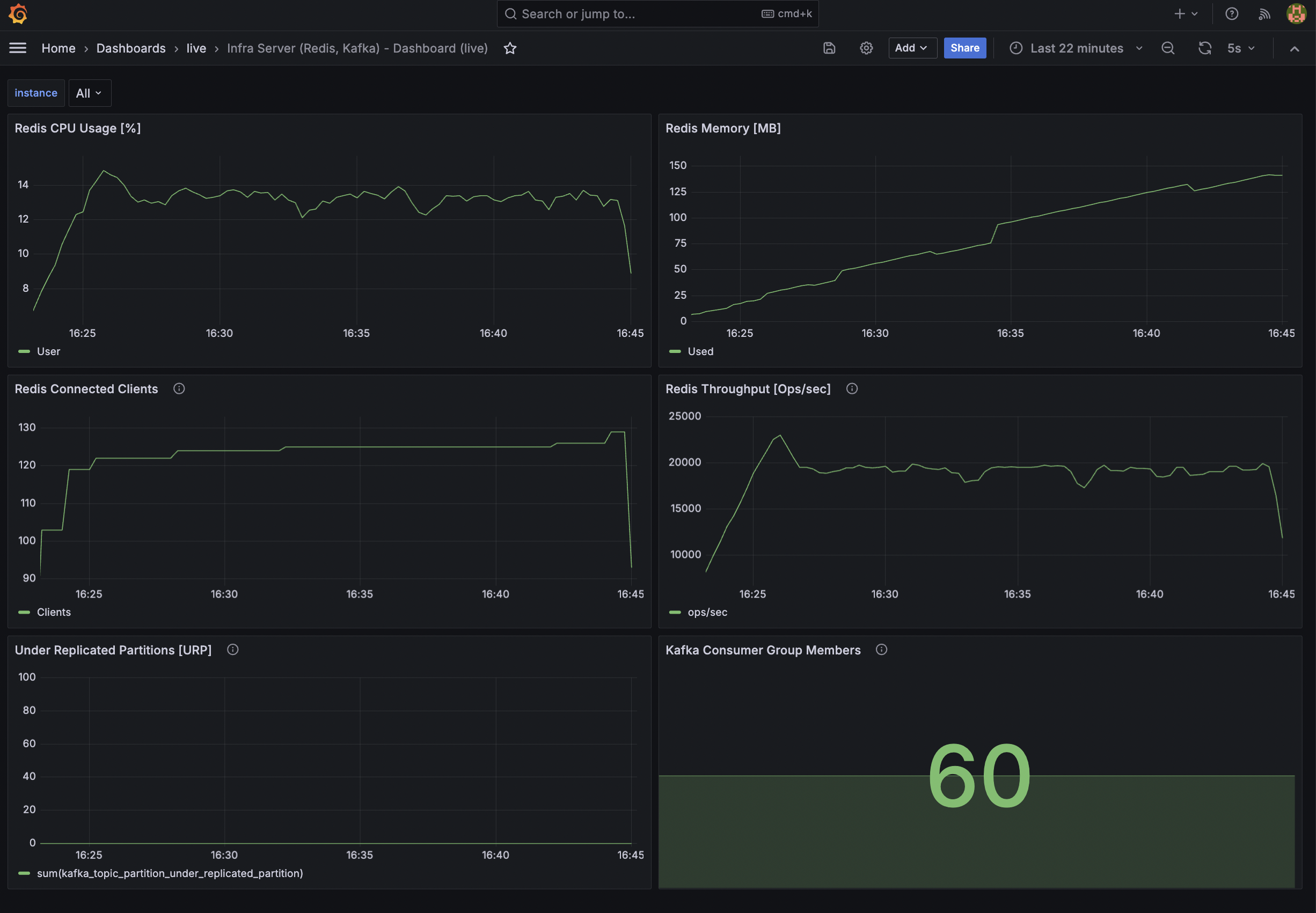
Redis Throughput이 약 20,000 ops/sec를 안정적으로 유지하며 중복 체크 및 선착순 로직의 병목을 해소했습니다.
Database Server(MySQL) - Monitoring
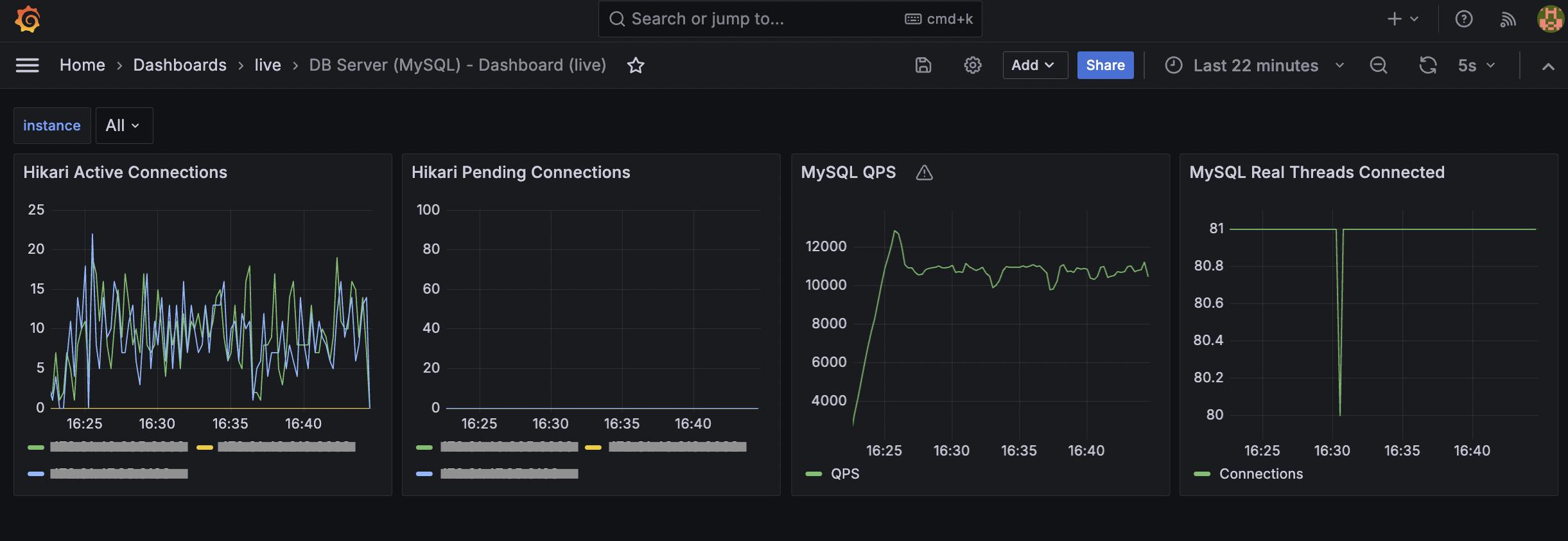
HikariCP 활성 연결 수가 설정 범위 내에서 안정적으로 유지되며, 대량의 쿼리(QPS 약 11,000)를 지연 없이 소화하고 있습니다.
Infra Server(Redis, Kafka) & Database Server(MySQL) - Docker Monitoring
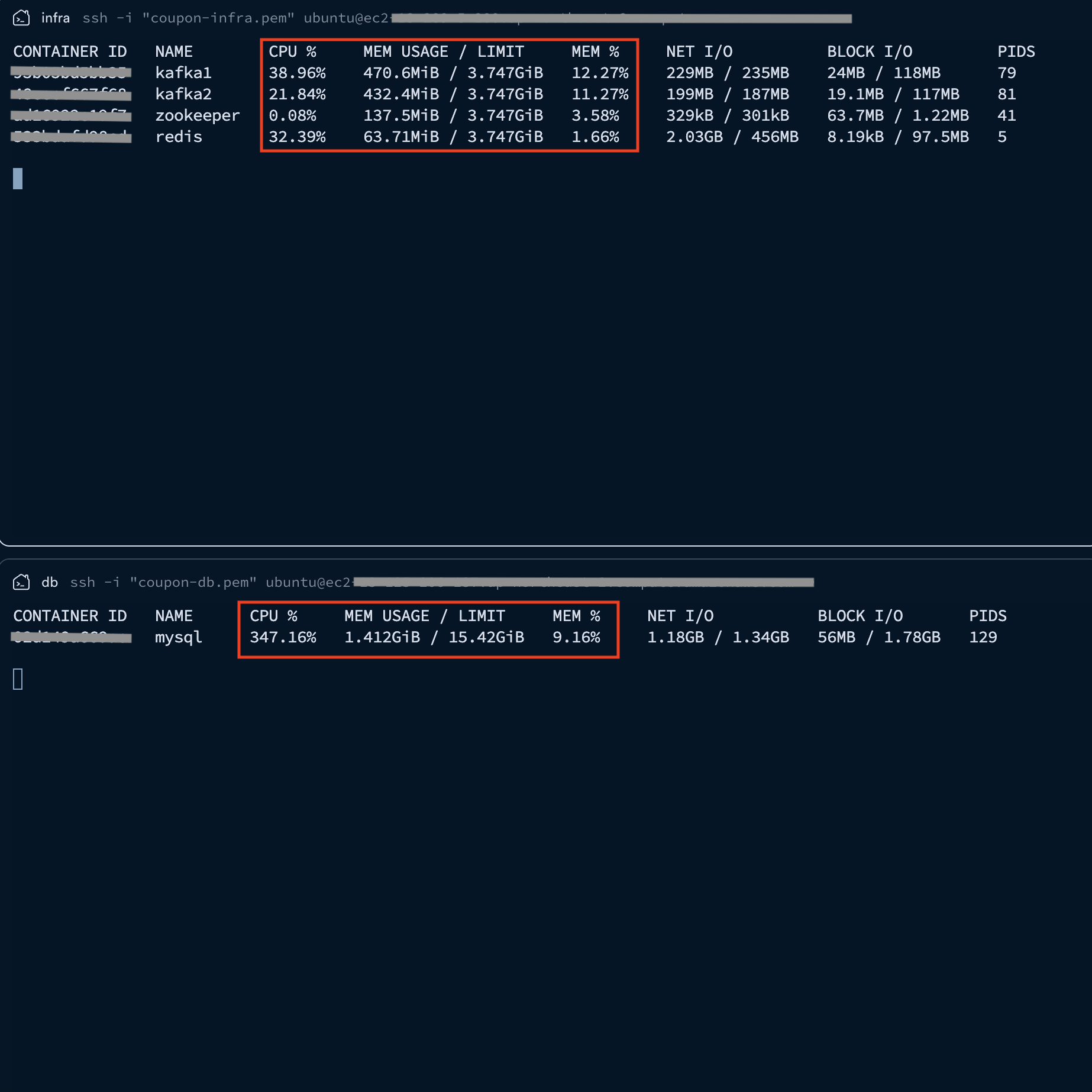
MySQL의 CPU 사용량이 347.16%(CPU 점유율: 86.79%)를 기록했습니다. (4 vCPU 기준 Max 400%) 이는 수직 확장(Scale-up)된 서버의 4-core 자원을 활용하여 쓰기 성능을 극대화하고 있다는 걸 확인했습니다.
Monitoring - Prometheus
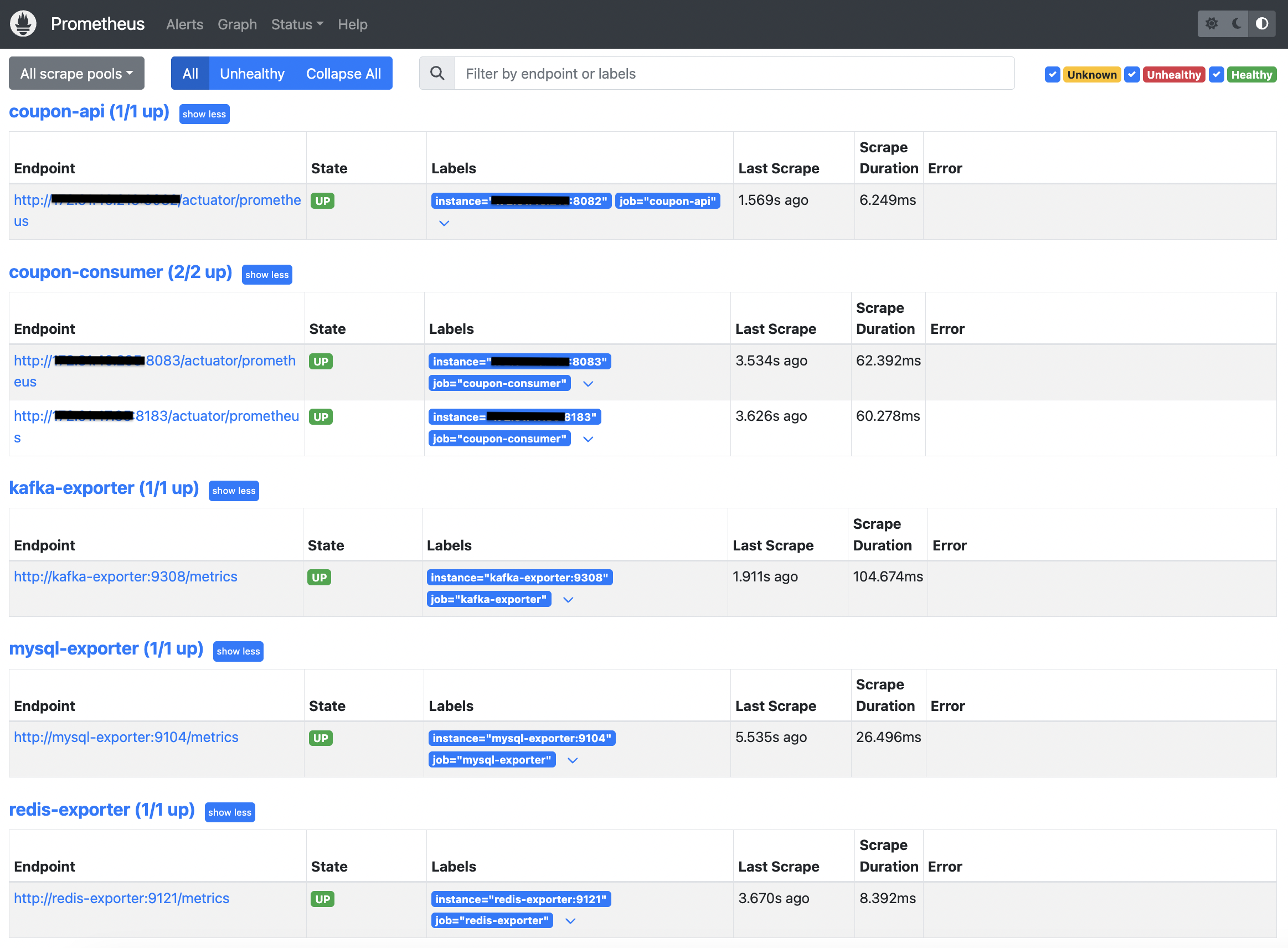
모든 지표 수집 타겟이 UP 상태를 유지하며 데이터 누락 없는 신뢰도 높은 관측 환경을 구축했습니다.
성과 및 결론
이번 프로젝트를 통해 단일 서버에서 시작하여 고가용성을 갖춘 분산 아키텍처로 진화하며 트래픽을 안정적으로 처리하는 구조를 완성했습니다. 단순히 TPS 수치를 높이는 것에 그치지 않고, 시스템의 병목 지점을 모니터링을 통해 수치를 확인하고 해결해 나가는 과정에서 다음과 같은 성과를 얻었습니다.
먼저, Kafka 프로듀서 및 컨슈머의 Config 튜닝을 통해 대량 유입 상황에서도 Consumer Lag을 실시간으로 해소하는 구조를 완성했습니다. 또한, 브로커 이중화 및 복제 설정을 통해 성능(2,700 TPS -> 1,500 TPS)을 일부 희생하는 대신, 운영 환경 수준의 데이터 안정성과 고가용성을 확보했습니다.
현재 시스템의 최대 한계는 API 서버의 CPU 자원 고갈임이 확인되었으나, 컨슈머와 DB 서버는 여전히 여유 자원을 보유하고 있어 API 서버 확장 시 선형적인 성능 향상이 가능할 것으로 판단됩니다.
지금까지 진행한 점진적 개선 과정을 표로 요약하면 다음과 같습니다.
아키텍처 개선 단계별 요약
| 테스트 단계 | 주요 아키텍처 변경 사항 | VU (가상 사용자) | Rate Limiter | API 서버 (최대 TPS) | Consumer 서버 (최대 TPS) | 주요 결과 및 병목 지점 |
|---|---|---|---|---|---|---|
| Step 1-1 | 초기 아키텍처 (단일 인스턴스) | 500 | 100 | 400 | 120 | 저부하 상황 정상 동작 확인 |
| Step 1-2 | 초기 아키텍처 (부하 증가) | 5,000 | 100 | 900 | 95 | Consumer Lag 누적, 레이턴시 급증 |
| Step 2-1 | 서버 인스턴스 분리 | 7,000 | 1,000 | 1,450 | 810 | 성능 개선되었으나 API 서버 CPU 포화 |
| Step 2-2 | DB 전용 인스턴스 분리 및 API 서버 스레드 튜닝 | 7,000 | 1,300 | 2,500 | 1,250 | p95 응답 시간 개선, DB CPU 한계 도달 |
| Step 2-3 | DB Scale-up, 컨슈머 Scale-out | 10,000 | 2,700 | 2,500 | 2,500 | 유입/처리 속도 균형 확보 (Lag 해소) |
| Step 3-1 | Kafka Broker 이중화 | 7,000 | 2,700 | 1,830 | 1,820 | 안정성 확보 및 현재까지 완성된 아키텍처 |
향후 개선 방안
현재 CPU 점유율 100%에 도달한 API 서버를 증설하여 부하를 분산한다면, p95 응답 시간을 목표치인 3초 이내로 단축할 수 있을 것으로 판단됩니다.
또한, API 서버의 TPS 유입량에 맞춰 컨슈머 서버의 Rate Limiter 값을 유동적으로 조정함으로써 시스템 전체의 처리 효율을 극대화하는 방향도 고려해 볼 수 있습니다.
부하 테스트 결과, 아직 컨슈머 서버는 약 20~30%, DB 서버는 약 13%의 CPU 가용 리소스를 보유하고 있음을 확인했기에, API 서버 확장 시 전체 시스템의 TPS가 임계치까지 선형적으로 향상될 수 있는 구조적 여력이 충분하다고 보입니다.
추가적으로, 동시 접속자가 10만 명에서 1,000만 명 단위까지 급증하는 대규모 트래픽 상황을 대비하여 대기열 시스템 도입을 검토해 볼 수 있습니다
단순히 서버를 증설하는 것만으로는 순간적인 트래픽 폭주를 감당하는 데 비용 효율과 기술적 한계가 존재하기 때문입니다. 이를 위해 Redis의 ZSet을 활용하여 사용자의 진입 순서를 보장하고, 시스템이 처리 가능한 속도에 맞춰 입장 토큰을 발급하는 구조로 개선하는 것이 효과적일 것으로 생각됩니다.
특히 대기열 시스템을 시스템의 부하 상태에 따라 유연하게 동작하도록 설계하는 방식을 고민해 볼 수 있습니다. 평소에는 바로 진입할 수 있도록 허용하되, 모니터링 중인 API 서버의 응답 지연 시간이나 Consumer 서버의 Lag이 임계치를 초과하는 상황이 감지될 때만 대기열이 활성화되는 유량 제어 방식을 적용한다면, 사용자 경험과 시스템 안정성을 동시에 확보할 수 있을 것으로 보입니다.
마무리하며
비즈니스 로직은 최대한 단순화하되, 시스템 구조는 트래픽 변화에 유연하게 대응할 수 있어야 한다고 생각합니다.
쿠폰 발급 시스템을 처음부터 설계하고 점진적으로 개선하면서 얻은 배움을 정리하면 다음과 같습니다.
-
트래픽 제어와 분산의 중요성: Redis Rate Limiter를 통해 DB가 처리할 수 있을 만큼만 트래픽을 조절하고, 리소스 지표를 확인하며 서버를 늘리거나 사양을 높이는 과정이 유기적으로 이루어져야 함을 경험했습니다.
-
운영 관점의 가용성 확보: 카프카 브로커 이중화와 복제 설정을 진행하며, 단순히 빠른 시스템보다 “장애 상황에서도 안전하게 돌아가는 시스템”을 만드는 법을 고민할 수 있었습니다.
초기 목표였던 3,300 TPS를 수치상으로 완전히 달성하지는 못했지만, 모니터링 지표를 통해 API 서버의 CPU 병목 지점을 확인했습니다. 이는 API 서버를 한 대 더 증설한다면 목표치를 충분히 달성할 수 있다는 데이터 기반의 확신을 얻은 값진 성과였습니다.
단순히 기술을 적용하는 것에 그치지 않고, 시스템의 한계를 측정하고 최적의 내부 설정값을 찾아가는 엔지니어링의 본질을 깊이 이해할 수 있었던 경험이었습니다. 이번 경험을 통해 대규모 트래픽 처리를 위해 어떤 부분을 우선순위로 고려하고 개선해 나가야 할지 조금이나마 자신감을 얻을 수 있었습니다.
지금까지 읽어주셔서 감사합니다. 😌