- Prologue
- DLQ(Dead Letter Queue)란
- 재처리를 포함한 쿠폰 발급 프로세스
- 재시도 정책 및 DLQ 처리
- 테스트 코드로 확인
- 부하 테스트 및 모니터링으로 확인
- 마무리하며
- Reference
모든 기술 선택에는 트레이드오프가 존재합니다.
이 글에서 소개하는 방식이 유일한 정답은 아니며, 각자의 비즈니스 환경에 맞는 최선의 선택을 고민하는 데 작은 참고가 되길 바랍니다.
Prologue
대규모 트래픽을 처리하는 비즈니스 로직에서 가장 두려운 상황 중 하나는 비동기 처리 중 발생하는 데이터 유실입니다. 특히 쿠폰 발급과 같이 유저에게 민감한 보상이 주어지는 시스템에서, API 응답은 성공했지만 내부 장애로 실제 발급이 누락된다면 서비스 신뢰도에 치명적인 타격을 입게 됩니다.
이번 글에서는 쿠폰 발급 시스템을 예시로, Consumer 서버에서 처리 도중 DB 장애 등의 시스템 예외가 발생했을 때 어떻게 메시지를 유실 없이 보호하고 재처리하는지, 그 설계와 구현 과정을 공유합니다.
예상 독자
-
시스템 장애(DB) 발생 시 재처리에 대한 로직에 대해 해결 과정이 궁금하신 분
-
SpringBoot 환경에서 재처리 방식 및 DLQ 처리 과정이 궁금하신 분
(이 글은 재처리/DLQ에 대한 기본 개념과 경험이 있는 독자를 대상으로 작성했습니다.)
DLQ(Dead Letter Queue)란
DLQ(Dead Letter Queue)는 소프트웨어 시스템에서 오류로 인해 처리할 수 없는 메시지를 임시로 저장하는 특수한 유형의 메시지 대기열입니다. - AWS -
분산 환경에서는 메시지 처리가 실패했을 때 무한 재시도로 인해 전체 시스템이 마비되는 것을 방지하고, 실패한 메시지를 별도로 관리하여 사후 분석이나 수동 조치를 가능하게 하는 핵심 장치입니다.
재처리를 포함한 쿠폰 발급 프로세스
대규모 트래픽 처리를 위해 API 서버가 Kafka로 메시지를 발행하고, Consumer가 이를 수신하여 DB에 저장하는 단방향 흐름을 가지도록 구현했습니다.
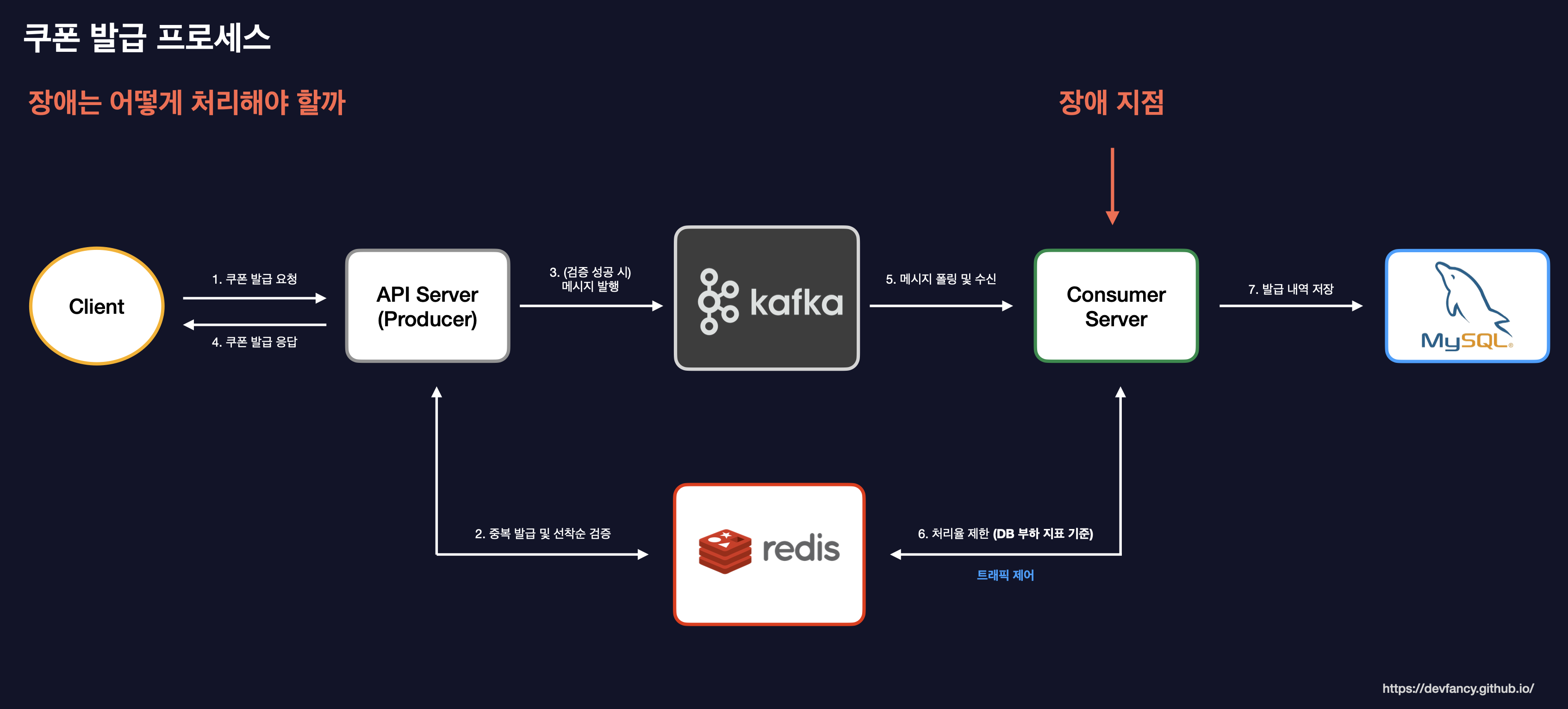
하지만 비동기 구간에서 DB 장애가 발생하면 메시지가 유실될 위험이 존재합니다. 이를 해결하기 위해 다음과 같이 3단계 장애 대응 체계를 설계했습니다.
- [1] 자동 재시도: 지수 백오프(Exponential Backoff) 전략을 통해 일시적인 시스템 이슈를 해결합니다.
- [2] DLQ 격리: 최대 재시도 횟수를 초과한 메시지는 별도의 DLQ 토픽으로 분리하여 메인 토픽의 처리를 방해하지 않도록 격리합니다.
- [3] 최종 기록: DLQ 재처리 과정에서도 실패할 경우, 운영자가 조치할 수 있도록 실패 이력 DB에 적재합니다. 만약 DB 장애가 영구적이어서 이력 적재마저 실패한다면, 최종적으로 에러 로그를 남겨 수동 조치의 근거를 확보합니다.
DLQ가 적용된 전체 구조는 다음과 같습니다.

DLQ 도입 시 고려해야 할 점
DLQ 도입 시 고려해야 할 사항들이 있습니다.
먼저, 메시지 전송을 무한히 재시도해야 하는 경우라면 정렬되지 않은 대기열과 함께 DLQ를 사용하는 것을 지양해야 합니다.
또한 선착순 이벤트처럼 순차 처리가 중요한 비즈니스 로직에서는 기존 Consumer와 DLQ 처리 서버의 자원을 분리하는 것이 좋습니다.
이를 통해 장애 메시지 처리가 정상 메시지 처리에 영향을 주는 것을 막고 확장성을 확보할 수 있습니다.
현재는 Consumer 서버에 DLQ 처리 로직을 포함했지만, 실제 운영 환경에서 트래픽이 많은 상황에서는 아래 그림처럼 별도의 DL 서버로 분리해서 관리하면 더 안정적입니다.

재시도 정책 및 DLQ 처리
비동기 메시징 시스템에서 가장 위험한 상황은 특정 메시지의 장애가 전체 파티션의 처리를 멈추게 하는 현상입니다.
이를 전문 용어로 Head-of-Line Blocking이라고 부릅니다.
쉽게 비유하자면, 1차선 도로에서 맨 앞의 고장 난 차 한 대 때문에 뒤에 줄지어 있는 모든 차가 꼼짝달싹 못 하고 막혀버리는 상태와 같습니다.
이런 병목 현상을 방지하기 위해 Kafka Consumer에서 예외가 발생했을 때의 행동 지침을 정의하는 DefaultErrorHandler를 아래와 같이 구현했습니다.
에러 핸들러는 크게 두 가지 핵심 역할을 수행합니다.
-
Recoverer 설정: 지정된 재시도 횟수를 모두 소진한 메시지를 즉시 DLQ 토픽으로 이동시켜 파티션을 점유하던 장애 메시지를 격리합니다.
-
백오프 전략: 시스템의 일시적인 순단을 고려하여
ExponentialBackOff를 적용했습니다. 재시도 간격을 지수적으로 늘려 DB나 외부 시스템에 가해지는 부하를 줄이면서 복구 시간을 확보합니다.
Consumer 서버 - KafkaConsumerConfig.java
@Configuration
public class KafkaConsumerConfig {
// ...
@Bean
public DefaultErrorHandler couponIssueErrorHandler(final KafkaTemplate<String, Object> kafkaTemplate) {
// 모든 재시도가 실패했을 때 메시지를 DLQ 토픽으로 전송하는 Recoverer 정의
DeadLetterPublishingRecoverer recoverer = new DeadLetterPublishingRecoverer(kafkaTemplate,
(record, exception) -> {
log.error("[COUPON_ISSUE_DLQ] 쿠폰 발급에 대한 재시도 횟수를 초과하여 메시지를 DLQ로 전송합니다. " +
"topic: {}, partition: {},offset: {}, error: {}",
record.topic(), record.partition(), record.offset(), exception.getMessage());
return new org.apache.kafka.common.TopicPartition(
record.topic() + "-dlq",
record.partition()
);
});
// 지수 백오프 전략 설정: 초기 2초 간격, 2.0배수로 최대 5회 재시도
ExponentialBackOff backOff = new ExponentialBackOff(2000L, 2.0);
backOff.setMaxAttempts(5);
return new DefaultErrorHandler(recoverer, backOff);
}
}
여기서 주의해야 할 점은 재시도 횟수가 5회라고 설정했을 때, 실제 실행 횟수는 총 6회(초기 시도 1회 + 재시도 5회)가 된다는 점입니다. 이 모든 과정이 실패하면 메시지는 비로소 DLQ로 넘어가며, 메인 컨슈머는 다음 메시지를 처리할 수 있게 됩니다.
해당 재처리 및 DLQ 전송에 대한 동작 과정을 시퀀스 다이어그램으로 표현하면 아래와 같습니다.
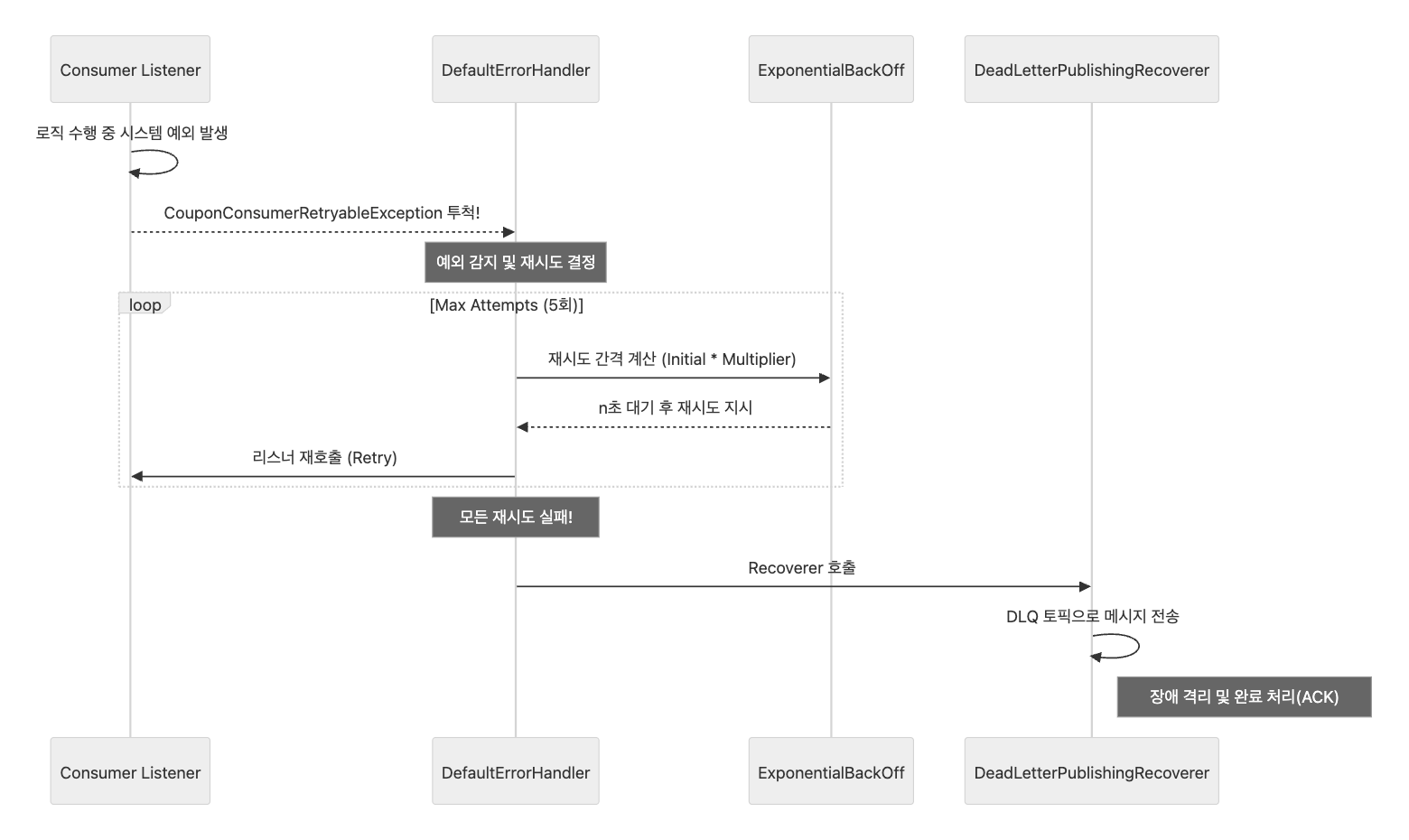
DLQ 리스너와 최종적 일관성
DLQ로 격리된 메시지는 별도의 리스너(dlq-consumer)를 통해 재처리를 시도합니다. 이는 일시적 장애가 해소된 후 시스템이 자동으로 데이터를 복구하는 과정입니다.
만약 DLQ에서의 재처리마저 실패한다면, 이는 자동 복구가 불가능한 영구 장애로 간주합니다. 이 경우 무한 루프에 빠지지 않도록 Acknowledgment(ACK)를 호출해 메시지를 소모하되, 사후 추적을 위해 실패 이력을 DB에 저장하고 에러 로그를 남깁니다.
Consumer 서버 - CouponIssueConsumer.java
@Component
public class CouponIssueConsumer {
// ...
@KafkaListener(
id = "dlq-consumer",
topics = "${kafka.topic.coupon-issue.name}-dlq",
groupId = "coupon-issue-dlq-group",
autoStartup = "true"
)
public void listenDlq(final CouponIssueMessage message, final Acknowledgment ack) {
log.info("[COUPON_ISSUE_DLQ_RETRY] 쿠폰 발급 실패 건에 대한 재처리를 시작합니다. userId={}", message.userId());
try {
// DLQ 메시지 재처리 시도
couponIssueService.issue(message.userId(), message.couponId());
ack.acknowledge();
log.info("[COUPON_ISSUE_DLQ_SUCCESS] DLQ 재처리가 성공적으로 완료되었습니다. userId={}", message.userId());
} catch (Exception e) {
// DLQ에서도 실패 시 최종 실패 이력 저장
log.error("[COUPON_ISSUE_DLQ_FAIL] DLQ 재처리가 최종적으로 실패했습니다. 실패 이력을 DB에 저장합니다. userId={}, error={}",
message.userId(), e.getMessage());
String payload = convertToJson(message);
couponIssueService.saveFailedEvent(message.userId(), message.couponId(), e.getMessage(), payload);
ack.acknowledge();
}
}
// ...
}
테스트 코드로 확인
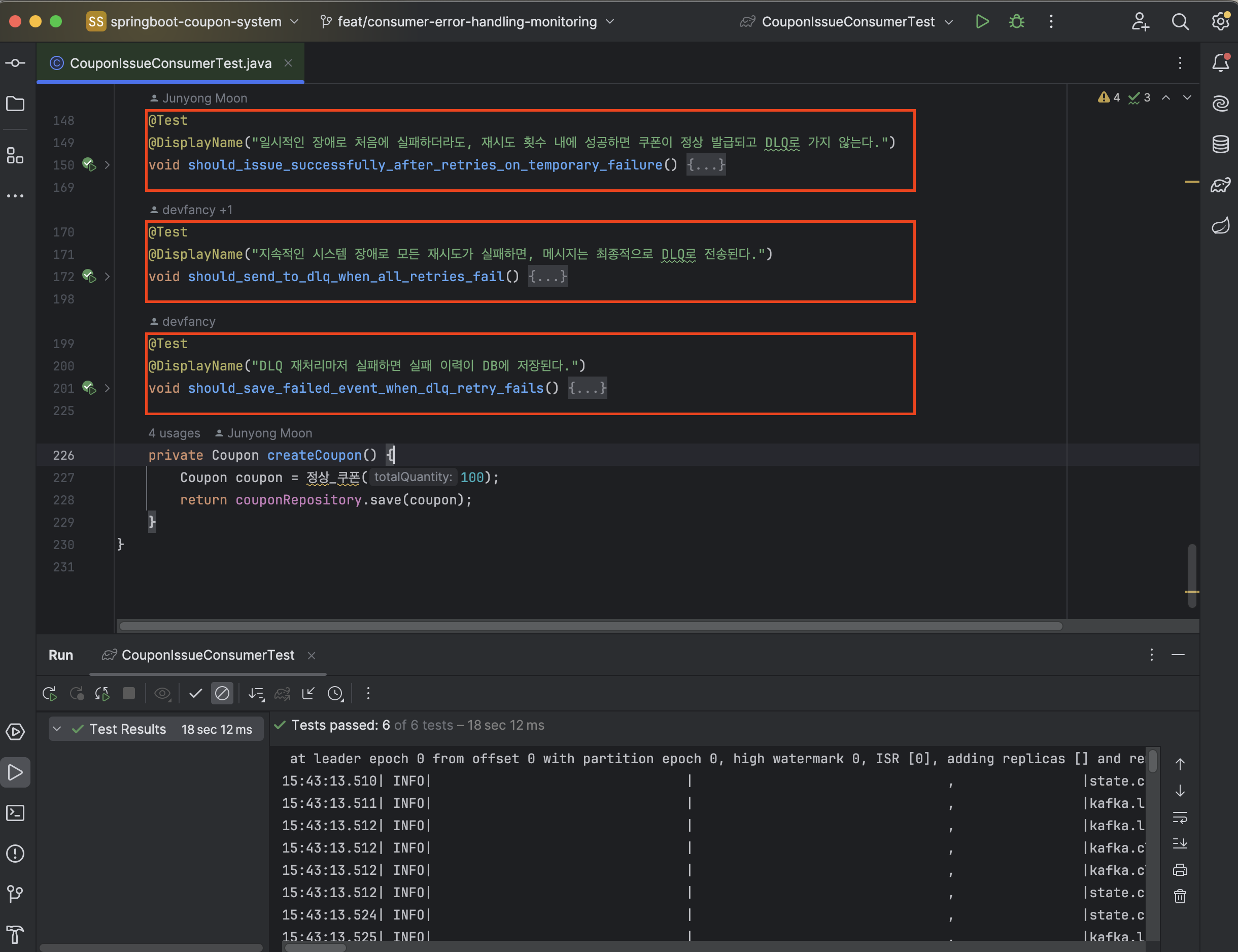
이러한 재처리 로직이 의도한 대로 동작하는지 검증하기 위해 단위 테스트를 작성했습니다
특히 SpyBean을 활용해 메인 컨슈머의 실패 횟수와 DLQ 리스너의 동작이 제대로 이뤄지는지 확인했습니다.
SpyBean이란 테스트 과정에서 실제 스프링 빈의 로직을 그대로 수행하면서도, 특정 메서드가 몇 번 호출되었는지(verify) 혹은 강제로 예외를 던지게 할 것인지(doThrow) 등을 제어하기 위해 사용합니다.- Mock과 달리 실제 빈을 래핑하므로, 별도의 설정이 없는 한 실제 비즈니스 로직이 그대로 실행되는 것이 특징입니다.
@ActiveProfiles("test")
@SpringBootTest(properties = {
//...
})
@EmbeddedKafka(
//...
)
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_EACH_TEST_METHOD)
class CouponIssueConsumerTest {
// ...
// Case 1: 일시적 장애 (재시도 성공)
@Test
@DisplayName("일시적인 장애로 처음에 실패하더라도, 재시도 횟수 내에 성공하면 쿠폰이 정상 발급되고 DLQ로 가지 않는다.")
void should_issue_successfully_after_retries_on_temporary_failure() {
// given
final Coupon coupon = createCoupon();
final UUID userId = UUID.randomUUID();
final CouponIssueMessage message = new CouponIssueMessage(userId, coupon.getId());
// NOTE: 메시지 전송 전에 미리 정의함
doThrow(new RuntimeException("Temporary DB Error 1")).doThrow(new RuntimeException("Temporary DB Error 2")).doCallRealMethod().when(couponIssueService).issue(any(UUID.class), any(UUID.class));
// when
kafkaTemplate.send(issueTopic, message);
// NOTE: 재시도 횟수와 시간 간격에 따라 timeout 조정 필요
await().atMost(10, TimeUnit.SECONDS).untilAsserted(() -> {
boolean exists = issuedCouponRepository.existsByUserIdAndCouponId(userId, coupon.getId());
assertThat(exists).isTrue();
});
verify(couponIssueService, times(3)).issue(any(UUID.class), any(UUID.class));
}
// Case 2: 지속적 장애 (DLQ 전송)
@Test
@DisplayName("지속적인 시스템 장애로 모든 재시도가 실패하면, 메시지는 최종적으로 DLQ로 전송된다.")
void should_send_to_dlq_when_all_retries_fail() {
// given
final Coupon coupon = createCoupon();
final UUID userId = UUID.randomUUID();
final CouponIssueMessage message = new CouponIssueMessage(userId, coupon.getId());
doThrow(new RuntimeException("Main Consumer Error"))
.doThrow(new RuntimeException("Main Consumer Error"))
.doThrow(new RuntimeException("Main Consumer Error"))
.doThrow(new RuntimeException("Main Consumer Error"))
.doThrow(new RuntimeException("Main Consumer Error"))
.doCallRealMethod() // 6번째 호출(DLQ)에서는 정상 실행
.when(couponIssueService).issue(any(UUID.class), any(UUID.class));
// when
kafkaTemplate.send(issueTopic, message);
// then
await().atMost(20, TimeUnit.SECONDS).untilAsserted(() -> {
boolean exists = issuedCouponRepository.existsByUserIdAndCouponId(userId, coupon.getId());
assertThat(exists).isTrue();
});
// NOTE: 최초 실행 1회 + 재시도 5회 = 총 6회
verify(couponIssueService, times(6)).issue(any(UUID.class), any(UUID.class));
}
// Case 3: 영구 장애 (DB 기록)
@Test
@DisplayName("DLQ 재처리마저 실패하면 실패 이력이 DB에 저장된다.")
void should_save_failed_event_when_dlq_retry_fails() {
// given
final Coupon coupon = createCoupon();
final UUID userId = UUID.randomUUID();
final CouponIssueMessage message = new CouponIssueMessage(userId, coupon.getId());
// 시나리오: 메인 리스너(5회) + DLQ 리스너(1회) 모두 실패
doThrow(new RuntimeException("Persistent Error"))
.when(couponIssueService).issue(any(UUID.class), any(UUID.class));
// when
kafkaTemplate.send(issueTopic, message);
// then
await().atMost(15, TimeUnit.SECONDS).untilAsserted(() -> {
long count = failedEventRepository.count();
assertThat(count).isEqualTo(1);
});
// 1. 발급 시도 횟수 검증 - 메인 횟수(초기 시도 + 재시도 횟수) + DLQ 1회
verify(couponIssueService, atLeast(6)).issue(any(UUID.class), any(UUID.class));
verify(couponIssueService, times(1))
.saveFailedEvent(eq(userId), eq(coupon.getId()), anyString(), anyString());
}
// ...
}
테스트 코드를 작성하고 실행한 결과, 아래와 같이 정상적으로 성공한 것을 확인할 수 있습니다.
부하 테스트 및 모니터링으로 확인
실무에서는 코드 레벨의 테스트뿐만 아니라 인프라 수준에서의 검증이 반드시 필요합니다. 설계한 로직이 실제 장애 상황에서 어떻게 작동하는지 확인하기 위해 장애 유도 테스트를 진행했습니다.
테스트 시나리오
- 부하 조건: 가상 사용자 100명, 총 6분간 요청 발생
- 장애 유도: 테스트 진행 1분 시점에 MySQL 컨테이너를 약 2분간 강제 중단
- 복구: 2분 후 컨테이너 재시작 및 중단되었던 트래픽 처리가 정상적으로 재개되는지 관찰
모니터링 지표 관찰
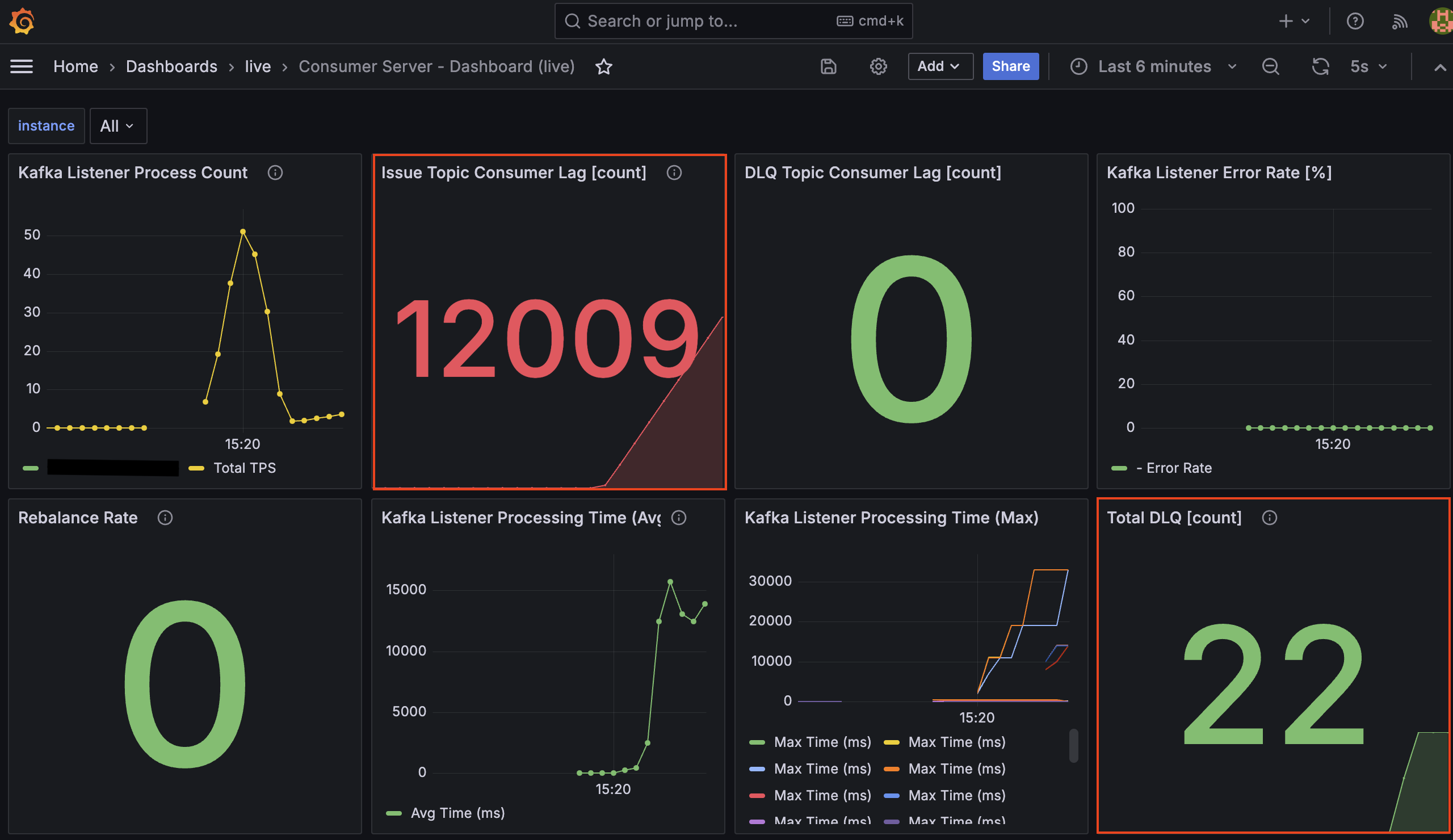
장애 유도 테스트 중 Grafana 대시보드를 통해 시스템의 변화를 실시간으로 관찰했습니다. 특히 장애 발생 시점과 DB 복구 직후 시점의 지표 변화를 통해 시스템의 동작을 명확히 확인할 수 있었습니다.
MySQL 컨테이너 중단 이후 (장애 발생)
DB 연결이 끊기자마자 재시도 로직이 동작하며 처리 시간이 급증하고, 이에 따라 컨슈머 랙(Lag)이 쌓이기 시작합니다.
MySQL 컨테이너 재시작 이후 (자동 복구)
DB가 살아나자마자 대기하던 메시지들이 빠르게 처리되면서 랙이 해소되고, 실패한 건들은 DLQ로 격리됩니다.
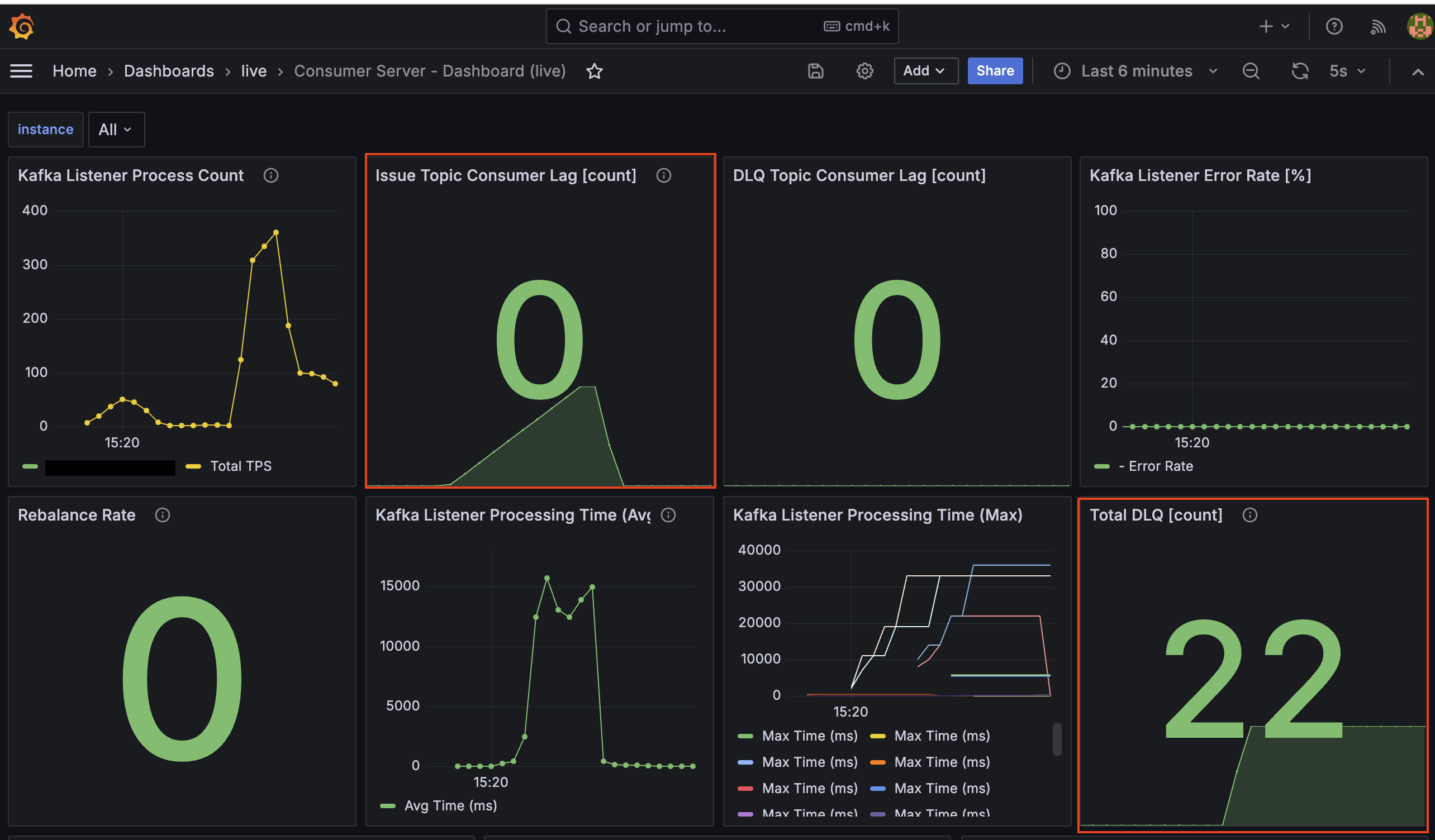
주요 지표 분석
Kafka Listener Process Count(처리량/TPS)- 장애 구간에서는 처리량이 바닥을 쳤으나, 복구 직후 평소보다 높은 약 400 TPS까지 치솟았습니다.
- 이는 시스템이 밀린 랙을 해소하기 위해 최대 성능으로 동작했음을 보여줍니다.
Issue Topic Consumer Lag(적체량)- DB 중단 시 처리가 지연되면서 랙(Lag)이 급증하다가, MySQL 재시작 후 컨슈머가 밀린 메시지를 빠르게 처리하며 다시 0으로 감소하는 것을 확인했습니다.
Kafka Listener Processing Time(처리 시간)- 장애 구간에서 평균(Avg) 처리 시간이 약 15,000ms(15초)를 기록했습니다.
- 이는 2초에서 32초까지 늘어나는
ExponentialBackOff대기 시간들의 평균치로, 재시도 로직이 정상적으로 동작하며 컨슈머 스레드를 점유하고 있었음을 보여주는 지표입니다.
Total DLQ [count](격리량)- 최대 재시도 횟수(5회)를 초과한 메시지들이 순차적으로 DLQ 토픽으로 이동하며 최종적으로 22건이 격리되었습니다.
재시도가 발생했는데 왜 Kafka Listener Error Rate는 0%인가요?
-
spring_kafka_listener_seconds_count지표의result="failure"는 예외가 핸들링되지 못하고 컨테이너 밖으로 전파될 때만 기록됩니다. -
현재 아키텍처는
DefaultErrorHandler가 예외를 잡아 DLQ로 안전하게 전송하고 오프셋을 커밋하기 때문에, 프레임워크 관점에서는 “성공적으로 예외를 처리했다”고 판정합니다.
최종 데이터 정합성 검증
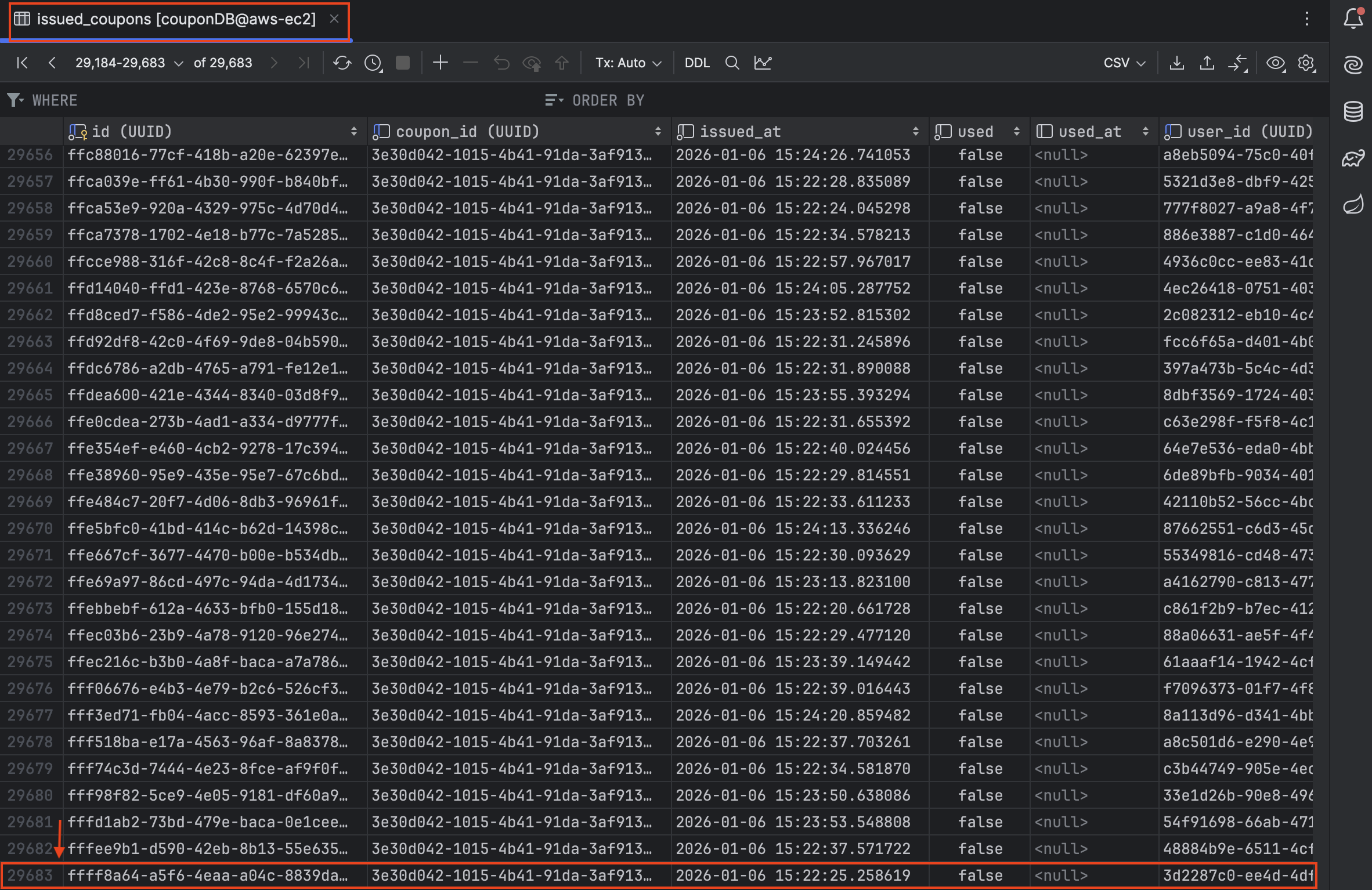
테스트 결과, k6 총 요청 수와 DB 데이터(성공 + 실패)의 합이 정확히 일치했고 유실 없이 정상적으로 수행된 것을 확인했습니다.
K6 - 총 요청 수: 29,693건

해당 횟수에 맞게 쿠폰 발급 테이블 및 실패 이력 테이블의 합이 맞는지 테이블에서 조회한 결과, 아래와 같이 정확히 일치함을 확인했습니다.
쿠폰 발급 완료: 29,683건
최종 실패 이력: 10건
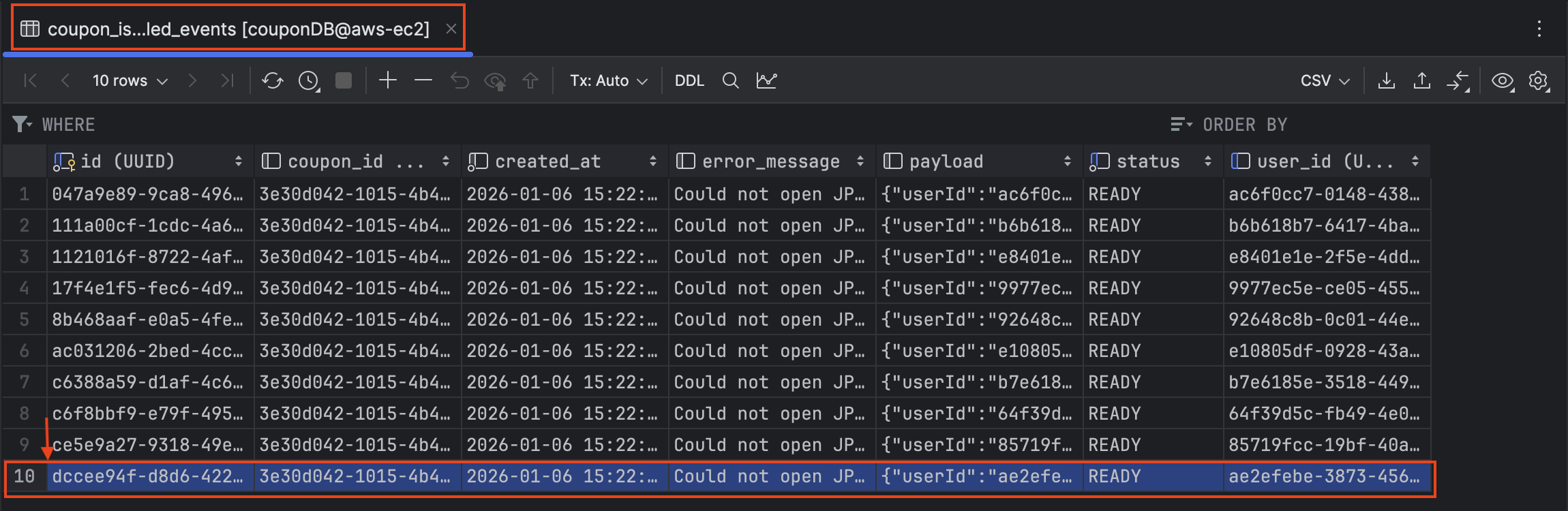
여기서 인상 깊은 지표는 대시보드상 DLQ Count는 22였지만 최종 실패는 10건이라는 점입니다. 이는 장애 상황에서 DLQ로 격리된 22건 중, DB가 복구된 후 DLQ 리스너가 다시 시도했을 때 12건이 정상적으로 자동 복구 되었음을 의미합니다.
부하 테스트 진행 중 Consumer 서버의 로그를 통해서도 DLQ 관련 성공/실패 로그가 의도한 대로 출력되는 것을 확인했습니다.
Consumer 서버 - DLQ 관련 성공 로그 (복구 성공)

Consumer 서버 - DLQ 관련 실패 로그 (최종 실패)

마무리하며
비동기 분산 시스템에서 장애는 언제든 발생할 수 있습니다. 중요한 것은 장애를 피하는 것이 아니라, 장애 상황에서도 데이터 정합성을 어떻게 유지할 것인가 입니다.
이번 DLQ 도입과 부하 테스트를 통해 최종적 일관성을 확보하는 과정을 경험했습니다. 특히 모니터링 지표와 DB 데이터를 대조하며 단 한 건의 유실도 없음을 확인했습니다.