- Prologue
- 왜 Sentry를 사용하는가?
- Sentry 연동 및 테스트
- Sentry 연동의 한계
- Logback 연동을 통해 예외 감지하는 범위 확장하기
- 에러 추적 시스템 개선하기
- 정리 및 마무리하기
- Reference
Prologue
서비스를 운영하다 보면 운영 전 단계인 환경(Staging)에서 QA 작업을 진행하면서 예상치 못한 오류들이 실제 운영 환경에서 발생하곤 합니다. 특히 예측 불가능한 외부 요인(네트워크, OS, 브라우저 등)이나 아주 특이한 케이스에서만 발생하는 런타임 오류는 개발자가 모든 경우를 예측하고 대비하기 어렵습니다.
이런 예측 불가능한 오류를 신속하게 탐지하고, 원인을 정확히 파악하여 빠르게 대응할 수 있도록 도와주는 것이 바로 실시간 에러 추적 도구이며,
Sentry는 이러한 해결책 도구들 중 하나입니다.
이번 글에서는 Sentry에 대한 개념과 연동 과정, 그리고 에러를 추적하는 방법에 대해 공유하고자 합니다.
예상 독자
-
Spring Boot 환경에서 Sentry 연동뿐만 아니라, Logback을 활용해 에러 감지하는 방법이 궁금한 분
-
단순한 에러 수집을 넘어, 태그를 활용해 알림 규칙을 정교하게 관리하고 싶은 분
왜 Sentry를 사용하는가?
공식문서에 따르면, Sentry는 개발자가 성능 문제와 에러를 식별하고 디버깅하는 데 도움을 주는 소프트웨어 모니터링 도구라고 합니다.
애플리케이션 모니터링 도구는 많지만, 그중 Sentry를 선택한 이유는 단순한 에러 수집을 넘어, 코드 레벨의 관측 가능성을 제공하기 때문입니다.
기존의 로그 파일로 확인하는 방식은 에러 발생 당시의 구체적인 맥락과 원인을 파악하는데 시간 소요가 크다는 점이 있습니다.
이에 비해 Sentry는 이슈를 실시간으로 감지하여 알림을 제공하고, 유사한 에러를 그룹화하며 문제가 발생한 정확한 코드 라인을 시각화해줍니다.
결과적으로 단순한 로그 수집을 넘어 코드 레벨의 관측 가능성을 확보함으로써 장애 인지부터 원인 파악까지의 시간을 단축하기 위해 도입하게 되었습니다.
Sentry 연동 및 테스트
아래는 Spring Boot 환경에서 Sentry를 연동하고 테스트하는 과정입니다. (관련 공식문서: Spring Boot)
먼저 Spring Boot 환경에서 build.gradle 파일에서 Sentry 의존성을 추가하고 application.yml 에 DSN 키만 설정하면 간단하게 연동할 수 있습니다.
설정(Configure)
예시를 위해 Spring boot 3.2.5 버전과 호환되는 라이브러리를 사용했습니다.
build.gradle
implementation "io.sentry:sentry-spring-boot-starter-jakarta:${property("sentryVersion")}" // 7.19.0
DSN 키는 Sentry 공식 홈페이지에서 로그인한 뒤에 프로젝트 설정 메뉴에서 발급받을 수 있습니다. (참고로, 저는 Github 계정을 통해 로그인했습니다.)
application.yml
sentry:
dsn: https://....ingest.us.sentry.io/... # Sentry 프로젝트에서 발급받은 DSN 키
DSN 키 발급 위치: Sentry 대시보드 - Settings -> Project -> SDK SetUp -> Client Keys(DSN)

간단히 테스트해보기
설정을 마쳤다면 Sentry가 에러를 정상적으로 추적하는지 확인하기 위해, 의도적으로 예외를 발생시키는 테스트 API를 호출해봅니다.
@RequestMapping("/api/coupon")
@RestController
public class CouponController {
@GetMapping("/sentry-test")
public ResponseEntity<CommonResponse<Void>> sentryTest() {
throw new CouponException(ErrorType.SENTRY_ERROR);
}
}
위의 코드의 동작 흐름은 다음과 같습니다.
CouponController에서CouponException발생하면, 별도의 처리 로직이 없으므로 예외가 서블릿 컨테이너까지 전파됩니다.- 이때 스프링의
HandlerExceptionResolver체인 중 하나인SentryExceptionResolver가 이를 감지하여 Sentry로 이벤트를 전송합니다.
결과적으로 아래와 같이 Sentry 대시보드에서 에러가 수집된 것을 확인할 수 있습니다.

Sentry 연동의 한계
하지만 만약 try-catch 구문을 통해 예외를 내부에서 처리한다면 어떻게 될까요?
아래 코드는 의도적으로 예외를 발생시키지만, catch 블록에서 잡아 500 에러 응답을 반환하는 구조입니다.
@RequestMapping("/api/coupon")
@RestController
public class CouponController {
@GetMapping("/sentry-test")
public ResponseEntity<ApiResultResponse<?>> sentryTest() {
try {
throw new CouponException(ErrorType.SENTRY_ERROR);
} catch (CouponException e) {
// 예외를 잡아서 응답 객체로 변환하여 리턴
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(ApiResultResponse.error(ErrorType.SENTRY_ERROR));
}
}
}
테스트 결과, 클라이언트는 500 에러를 응답받았지만 Sentry 대시보드에는 아무런 에러도 기록되지 않았습니다.
원인 분석해보기
Spring Boot 환경에서 Sentry 의존성을 추가하면 SentryExceptionResolver가 자동으로 등록됩니다.
이 클래스는 처리되지 않고 컨트롤러 밖으로 던져진 예외를 가로채 Sentry로 전송하는 역할을 합니다.
public class SentryExceptionResolver implements HandlerExceptionResolver, Ordered {
// ...
protected @NotNull SentryEvent createEvent(@NotNull HttpServletRequest request, @NotNull Exception ex) {
// ... 예외 정보를 담아 이벤트 생성
SentryEvent event = new SentryEvent(throwable);
return event;
}
}
하지만 위에서 컨트롤러 코드에서 다룬 것처럼 로직 내부에 try-catch로 예외를 잡아 처리해버리면, 예외 객체가 서블릿 컨테이너의 Resolver까지 도달하지 않습니다.
즉, 개발자는 의도적으로 예외를 처리했지만, Sentry 입장에서는 에러가 발생하지 않은 정상적인 요청으로 간주하여 모니터링 누락이 발생합니다.
또한, 실무에서는 보통 사용자 경험을 위해 @RestControllerAdvice 어노테이션을 사용해서 전역적으로 예외를 핸들링합니다.
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ResponseEntity<ApiResultResponse<?>> handleException(Exception e) {
log.error("Exception : {}", e.getMessage(), e); // 로그는 찍지만 Sentry로 가지 않음
return new ResponseEntity<>(ApiResultResponse.error(ErrorType.DEFAULT_ERROR), ErrorType.DEFAULT_ERROR.getStatus());
}
}
이 경우 모든 예외가 ExceptionHandler에 의해 잡히기 때문에 SentryExceptionResolver 까지 전달되지 않습니다.
물론 catch 블록마다 Sentry.captureException(e)를 명시적으로 호출할 수도 있습니다.
하지만 이렇게 되면 비즈니스 로직과 모니터링 로직이 강하게 결합되는 또다른 문제가 생깁니다.
그래서 만약 log.error 와 같은 에러 로그를 남기고 있다면, 코드 수정 없이 로그 레벨에 따라 자동으로 이벤트를 수집해주는 SentryAppender 방식을 도입하는 것이 효율적이라고 생각합니다.
Logback 연동을 통해 예외 감지하는 범위 확장하기
SentryAppender를 Logback 설정에 추가하면, Sentry가 log.error() 같은 로깅 이벤트를 직접 감시할 수 있게 됩니다.
이를 통해 예외가 컨트롤러까지 전파되지 않더라도, 개발자가 log.error()로 기록되는 모든 중요한 예외 상황을 Sentry 이벤트로 발행할 수 있습니다.
Logback에 SentryAppender 설정하기
logback.xml 파일(또는 logback-spring.xml)에 아래와 같이 SentryAppender 를 추가하고, root 로거에 참조를 추가합니다.
<configuration>
<appender name="SENTRY" class="io.sentry.logback.SentryAppender">
<minimumEventLevel>WARN</minimumEventLevel>
<minimumBreadcrumbLevel>INFO</minimumBreadcrumbLevel>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT"/>
<appender-ref ref="SENTRY"/>
</root>
</configuration>
주요 설정값은 다음과 같습니다.
-
minimumEventLevel: Sentry 대시보드에서 하나의 이슈(Issue)로 등록될 최소 로그 레벨을 지정할 때 사용합니다.WARN으로 설정하면,log.warn()이 호출될 때 Sentry 이슈가 생성됩니다.
-
minimumBreadcrumbLevel: 이슈가 발생했을 때, 그 원인을 파악할 수 있도록 첨부되는 Breadcrumbs(발자국)의 최소 로그 레벨을 지정할 때 사용합니다.INFO로 설정하면, 에러 발생 직전의log.info()기록까지 타임라인에 함께 표시되어 문맥을 파악하는 데 큰 도움이 됩니다.
예외를 올바르게 전달하는 방법
SentryAppender를 효과적으로 사용하려면 로그를 남길 때 반드시 예외 객체 자체를 파라미터로 함께 전달해야 합니다.
(예시. log.error("예외 발생!!", e);)
SLF4J의 마지막 인자로 예외 객체 e 를 전달하면, SentryAppender 가 이를 감지하여 스택 트레이스를 포함한 이슈를 생성합니다.
이렇게 해야 Sentry의 분석 및 그룹핑 기능을 활용할 수 있습니다.
Logback 연동 후 다시 테스트하기
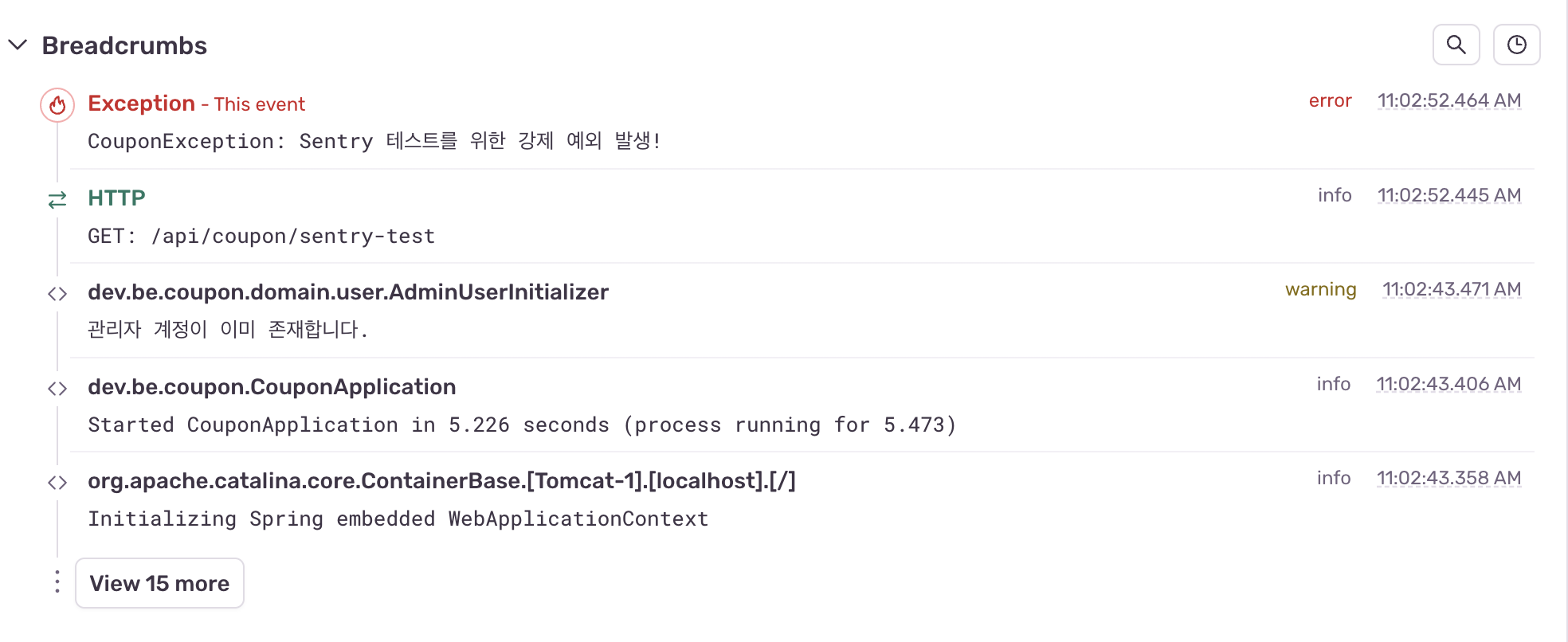
Logback 연동 후 애플리케이션을 재실행하고 API를 다시 호출하면, 아래와 같이 Sentry 대시보드에서 해당 에러를 확인할 수 있습니다.
특히 minimumBreadcrumbLevel 값을 INFO로 설정했기 때문에, 에러 발생 시점뿐만 아니라 그 이전의 INFO 로그까지 Breadcrumbs에 기록된 것을 볼 수 있습니다.
에러 추적 시스템 개선하기
단순히 에러를 수집하는 것은 부족합니다. 운영 환경에서는 수많은 요청이 뒤섞여 들어오기 때문에, 특정 사용자의 요청 흐름을 한눈에 파악할 수 있어야 합니다.
또한, 모든 예외를 무차별적으로 알림으로 보내면 담당자(개발자 또는 운영자)에게 알림 피로도를 누적시킬 수 있습니다. 담당자가 알림에 대해 집중력이 떨어지게 되면, 정작 긴급한 장애가 발생했을 때 대응이 늦어지는 리스크로 이어질 수 있습니다.
이러한 문제를 해결하기 위해 Sentry의 Tag 기능을 활용하여 추적 가능한 에러와 선별적인 알림 규칙을 아래와 같이 정의했습니다.
-
globalTraceId(Scope Tag): 요청의 전체 흐름을 추적하기 위한 범위 태그. -
errorCode(Event Tag): 에러의 종류를 분류하고 알림을 최적화하기 위한 이벤트 태그.
globalTraceId: 분산 환경에서의 요청 추적
globalTraceId는 사용자의 요청이 여러 서비스를 거쳐 처리될 때, 그 모든 여정을 하나의 ID로 묶어주는 역할을 합니다.
이 태그는 에러 발생 여부와 관계없이, 해당 요청 내에서 발생하는 모든 Sentry 이벤트에 공통적으로 포함되어야 합니다.
이를 위해 아래와 같이 Sentry.configureScope를 사용하여 요청 스코프 전역에 태그를 주입하는 방식을 적용했습니다.
public class HttpRequestAndResponseLoggingFilter extends OncePerRequestFilter {
private static final String GLOBAL_TRACE_ID_HEADER = "X-Global-Trace-Id";
private static final String GLOBAL_TRACE_ID_KEY = "globalTraceId";
@Override
protected void doFilterInternal(@NonNull final HttpServletRequest request,
@NonNull final HttpServletResponse response,
@NonNull final FilterChain filterChain) throws ServletException, IOException {
ContentCachingRequestWrapper requestWrapper = new ContentCachingRequestWrapper(request);
ContentCachingResponseWrapper responseWrapper = new ContentCachingResponseWrapper(response);
// Trace ID 추출 또는 생성 (Gateway 등 앞단에서 넘어온 헤더가 있으면 우선 사용)
String globalTraceId = requestWrapper.getHeader(GLOBAL_TRACE_ID_HEADER);
if (!StringUtils.hasText(globalTraceId)) {
globalTraceId = UUID.randomUUID().toString().substring(0, 32);
}
// MDC와 Sentry Scope에 Trace ID 주입 -> MDC: 로그백(Logback)에서 사용, Sentry: 이슈 태깅에 사용
MDC.put(GLOBAL_TRACE_ID_KEY, globalTraceId);
final String finalGlobalTraceId = globalTraceId;
Sentry.configureScope(scope -> scope.setTag(GLOBAL_TRACE_ID_KEY, finalGlobalTraceId));
try {
filterChain.doFilter(requestWrapper, responseWrapper);
log(requestWrapper, responseWrapper);
} finally {
responseWrapper.copyBodyToResponse();
MDC.remove(GLOBAL_TRACE_ID_KEY);
}
}
//...
}
구현 참고:
ContentCachingWrapper를 사용하여 요청/응답 본문(Body)을 안전하게 캐싱하고MDC를 통해 쓰레드 컨텍스트를 관리하는 구체적인 원리는 이전에 작성한 Spring Boot 요청 흐름 추적: Logging Filter와 traceId 적용기 포스팅에서 자세히 다루었으므로 해당 글을 참고해 주시기 바랍니다.)
이렇게 설정된 globalTraceId 는 Sentry뿐만 아니라 Grafana Loki와 같은 중앙 로그 시스템과 연계할 때 에러의 전체 맥락을 파악하는 데 도움이 됩니다.
활용 예시1: Sentry 이슈 추적
Sentry 이슈 화면에서 globalTraceId 태그를 클릭하거나 검색하면, 아래와 같이 해당 요청 시점에서 발생한 특정 이벤트를 필터링하여 볼 수 있습니다.

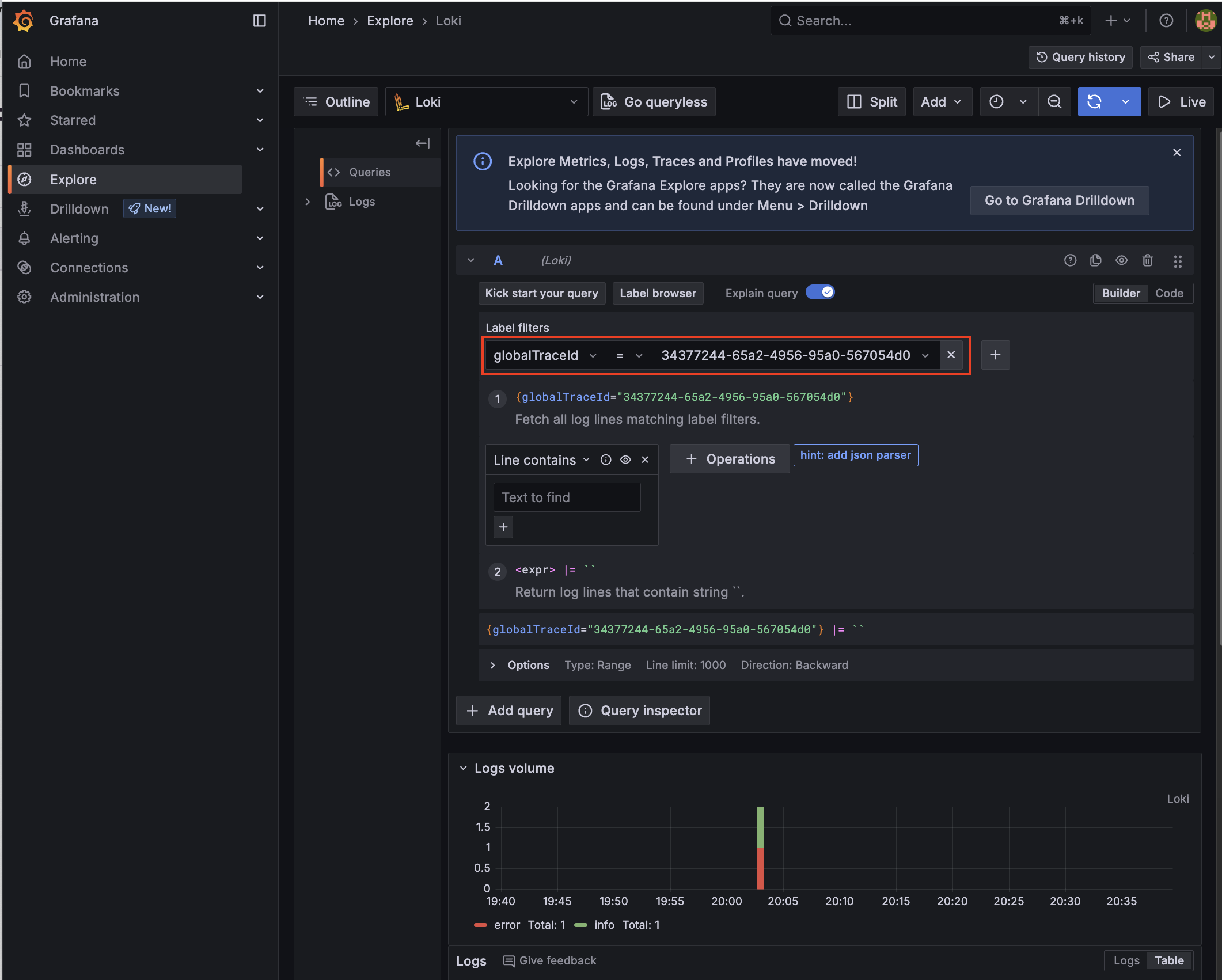
활용 예시2: Grafana Loki 연계 분석
Sentry에서 확보한 globalTraceId를 Grafana Loki의 레이블 필터로 사용하면,
에러 로그뿐만 아니라 해당 요청이 남긴 모든 정상 로그까지 타임라인 순으로 조회하여 문제의 전체 맥락을 상세하게 파악할 수 있습니다.
errorCode: 동적 태깅으로 검색 및 알림 설정
에러를 검색하거나 정교한 알림 규칙을 만들 때 “쿠폰이 존재하지 않습니다.”와 같은 에러 메시지를 기준으로 삼으면, 나중에 해당 에러 메시지가 조금만 바뀌어도 규칙이 깨질 수 있습니다.
따라서 변하기 쉬운 메시지 대신 E500 와 같은 고유 값인 errorCode를 태그로 달아 관리하는 것이 유리합니다.
beforeSend vs configureScope 을 비교하면 아래와 같습니다.
-
configureScope: “앞으로 발생할 모든 이벤트에 이 꼬리표를 미리 붙여둬라.” (정적)
-
beforeSend: “이벤트가 발생했네? 잠깐 멈춰봐. 내용을 뜯어보고 태그를 달거나 버릴지 결정하자” (동적)
아래와 같이 beforeSend 콜백을 구현하여, CouponException 이 발생 시 내부에 담긴 에러 코드를 추출해 태그로 등록하고, 불필요한 INFO 레벨의 예외는 필터링하여 비용을 줄이는 로직을
구현했습니다.
@Component
public class SentryBeforeSendCallback implements SentryOptions.BeforeSendCallback {
private static final String ERROR_CODE_TAG = "errorCode";
private final Logger log = LoggerFactory.getLogger(SentryBeforeSendCallback.class);
@Override
public SentryEvent execute(@NotNull SentryEvent event, @NotNull Hint hint) {
if (event.getExceptions() != null && !event.getExceptions().isEmpty()) {
SentryException sentryException = event.getExceptions().get(0);
log.debug("Sentry Exception Type: {}, Value: {}", sentryException.getType(), sentryException.getValue());
}
Throwable throwable = event.getThrowable();
// 커스텀 예외(CouponException)인 경우에만 전처리 로직 수행
if (throwable instanceof CouponException couponException) {
ErrorType errorType = couponException.getErrorType();
if (errorType != null) {
if (errorType.getLogLevel() == LogLevel.INFO) {
return null;
}
// 에러 코드를 태그로 추가한다.
if (errorType.getCode() != null) {
event.setTag(ERROR_CODE_TAG, errorType.getCode().name());
}
}
}
return event;
}
}
errorCode 태그를 적용한 결과, 다음과 같이 Sentry의 활용도를 높일 수 있게 되었습니다.
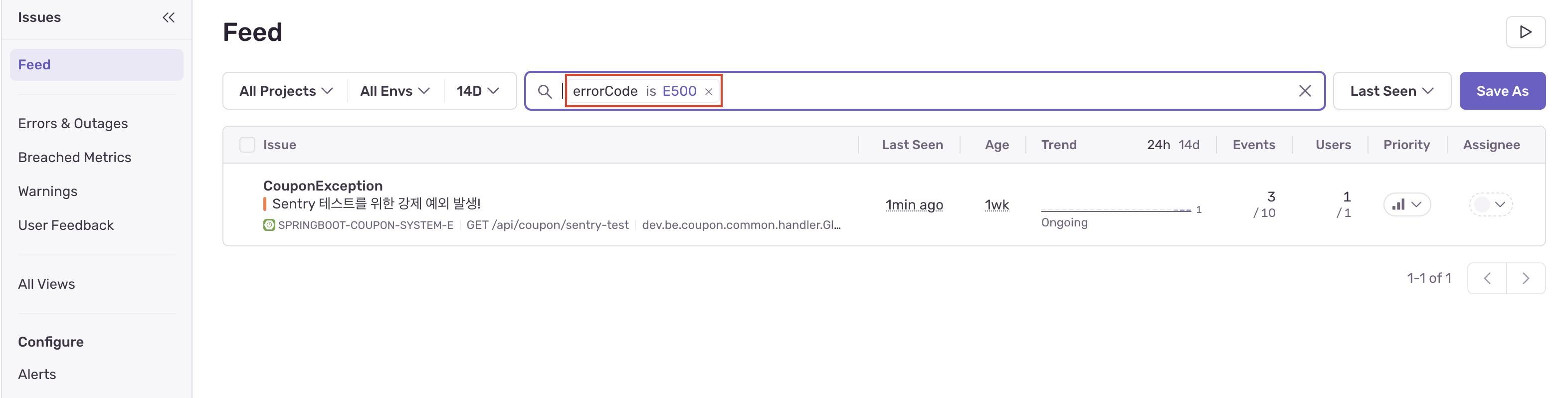
errorCode로 이슈 필터링
Sentry의 Issues 피드 검색창에 errorCode is E500과 같은 쿼리를 입력하면, 수많은 에러 로그 속에서도 특정 비즈니스 로직과 관련된 문제만 즉시 선별하여 확인할 수 있습니다.
이는 장애 발생 시 노이즈를 제거하고 핵심 원인을 빠르게 파악하는 데 큰 도움이 됩니다.
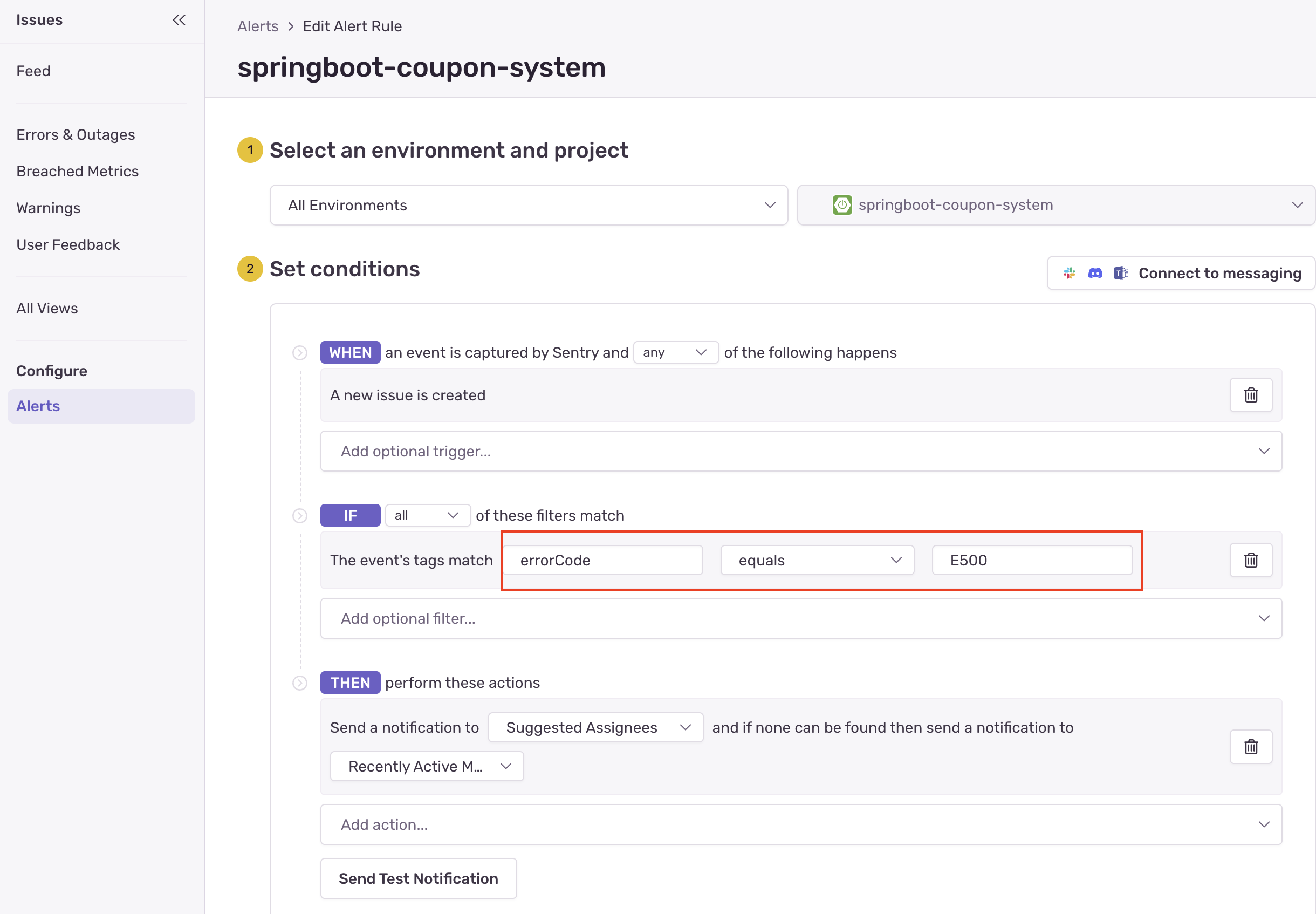
errorCode 기반의 정교한 Alert 규칙 정의
단순히 에러 발생 횟수로 알림을 받는 것이 아니라, 태그를 활용해 자동화된 알림 규칙을 만들 수 있습니다.
아래 그림과 같이 “(WHEN) 새로운 이슈가 발생했고, (IF) 태그의 errorCode가 E500과 같다면, (THEN) 즉시 담당자에게 알림을 발송하라”는 규칙을 적용할 수 있습니다.
이를 통해 비즈니스 중요도에 따라 알림 채널을 분리하거나, 특정 팀에게만 선별적으로 알림을 보내는 등 에러 대응 프로세스를 구축할 수 있습니다.
정리 및 마무리하기
운영 환경에서 발생하는 예측 불가능한 오류를 신속하게 탐지하고 분석하는 것은 서비스 안정성의 핵심입니다. 단순히 로그를 적재하는 것만으로는 파편화된 서비스 환경에서 장애의 근본 원인을 추적하기 어렵습니다.
이번 포스팅에서는 Sentry를 도입하여 에러를 실시간으로 감지하고, 주요 컨텍스트를 파악할 수 있는 환경을 구축했습니다.
무엇보다 Sentry의 Tag 기능을 두 가지 전략으로 활용하여 관측 가능성을 높였습니다.
첫 번째로 globalTraceId를 통해 분산된 요청의 흐름을 하나로 묶었습니다. 이를 Grafana Loki와 연계함으로써, 에러 로그뿐만 아니라 에러가 발생한 시점의 정상 로그까지 한 번에 추적하여 전체
맥락을 파악할 수 있게 했습니다.
두 번째로 errorCode를 태그로 등록하여 에러 관리의 효율성을 높였습니다. Sentry 내에서 특정 유형의 에러를 검색하는 것을 포함하여, 비즈니스 중요도에 따라 선별적인 알림 규칙을 적용하여 대응
체계를 구축했습니다.
이처럼 Sentry는 단순한 에러 수집 도구가 아닌 분석 플랫폼으로 활용함으로써, 무분별한 알림으로 인한 운영 피로도를 낮추고 장애 대응 속도를 개선할 수 있었습니다. 이는 곧 사용자에게 더 신뢰받는 서비스를 제공하는 기반이 될 것입니다.
지금까지 읽어주셔서 감사합니다.