- Prologue
- 테스트 코드를 왜 작성해야 할까요
- 테스트 코드를 작성하기 위한 전략
- 도메인 정책 기반 테스트 코드 작성하기
- 사용자 시나리오 기반 테스트 코드 작성하기
- 독립적이고 효율적인 테스트 환경 구축하기
- 외부 의존성을 제어 가능한 영역으로 만들기
- 테스트 대역을 올바르게 활용하기
- 마무리하며
- 함께 읽으면 좋은 글
- Reference
이 글에서 다루는 모든 코드는 개인 프로젝트를 기반으로 작성되었으며, 아래 Github 를 참고해 주시면 감사하겠습니다.
Prologue
테스트 코드를 처음 작성하기 시작한 지 어느덧 2년이 되었습니다. 초기에는 단순히 “테스트 코드가 있어야 한다”는 의무감이나 문법적인 사용법(How)을 익히는 데 급급했습니다. 하지만 프로젝트의 규모가 커지고 비즈니스 로직이 복잡해질수록, “어떻게 짜는 것이 지속 가능한 테스트인가?”에 대한 고민이 깊어졌습니다.
단순히 커버리지를 높이는 것을 넘어, 유지보수 비용을 낮추고 비즈니스 가치를 지키는 테스트 전략이 필요함을 느꼈습니다.
이 글은 여러 기술 서적과 현업의 기술 블로그를 참고하며, 실제 프로젝트에 적용해 본 가치 있는 테스트를 위한 전략과 고민을 정리한 글입니다.
저와 비슷한 고민을 하고 계신 분들께 작은 이정표가 되기를 바랍니다.
예상 독자
이 글은 Java, Spring Boot 환경에서 기본적인 테스트 코드 작성 경험이 있으며, 더 효율적이고 체계적인 테스트 전략을 고민하는 분들을 대상으로 작성했습니다.
테스트 코드를 왜 작성해야 할까요
이 질문에 대해 저는 “사람이 하는 수동 검증의 한계를 넘어, 우리 서비스의 첫 번째 고객에게 피드백을 받기 위해서”라고 답하고 싶습니다.
과거 히빗이라는 사이드 프로젝트와 실무 초기 경험을 되돌아보면, 서비스가 성장할수록 공통적으로 겪었던 현실적인 문제들이 있었습니다.
-
반복적이고 늘어나는 QA 시간: 기능이 추가될 때마다 전수 검사를 사람이 직접 수행해야 했고, 이는 결국 신규 기능 개발 시간이 점점 줄어들었습니다.
-
배포 전의 불안감과 야근: 마감 기한이 다가올수록 반복되는 수정과 검증으로 인해 야근이 빈번해졌고, 그럼에도 불구하고 에러에 대한 불안감은 사라지지 않았습니다.
-
문서와 코드의 불일치: 별도로 관리되던 기능 명세서는 코드의 변화를 따라가지 못해 결국 신뢰할 수 없는 레거시가 되기 일쑤였습니다.
물론, 현실에서 테스트 코드를 도입하는 것은 말처럼 쉬운 일이 아닙니다.
운영 중인 코드의 양이 방대하거나, 당장의 비즈니스 기능 개발이 너무 시급해 테스트를 후순위로 미루는 경우도 많습니다. 저 또한 입사 전에는 막연히 ‘실무에는 완벽한 테스트 환경이 있겠지?’라고 상상했지만, 실제로는 테스트 코드가 아예 없는 환경도 많다는 것을 알게 되었습니다.
하지만 그럼에도 불구하고 테스트는 필요했습니다.
테스트 코드는 단순한 버그 방지턱이 아니라, 가장 먼저 내 코드를 사용해 보고 가차 없이 피드백을 주는 첫 번째 고객이었기 때문입니다.
실제 고객이 버그를 발견하기 전에 테스트 코드가 먼저 문제를 지적해 줌으로써, 저는 반복되는 노동에서 벗어나 시스템의 안정성과 비즈니스 가치에 더 집중할 수 있게 되었습니다.
이러한 경험 덕분에, 저는 회사와 팀의 상황에 맞춰 ‘안정적인 서비스를 만든다’를 목표로 한 걸음씩 나아가는 태도를 갖게 되었습니다.
테스트 코드를 작성하기 위한 전략
무작정 테스트를 작성하기보다 “좋은 테스트란 무엇인가?”를 고민하며 저만의 기준을 세우게 되었습니다.
-
빠른 피드백: 로직 검증은 가볍고 빨라야 한다. (POJO 기반 권장)
-
독립성: 각 테스트는 서로 의존하지 않아야 한다.
-
경계값 검증: 성공 케이스보다 실패하기 쉬운 엣지 케이스를 중심으로 작성한다.
-
문서화: 테스트 코드 자체가 요구사항과 정책을 설명하는 문서 역할을 해야 한다.
또한, 테스트 코드 역시 읽기 편하도록 간결하게 작성하려 노력했습니다.
결론적으로 제가 생각하는 좋은 테스트는 비즈니스적으로 가치가 있는 테스트입니다.
과거에는 커버리지를 높이는 것이 좋다고 막연하게 생각했지만, 경험이 쌓일수록 비즈니스 가치를 지키는 것이 훨씬 중요하다는 것을 체감했습니다.
그래서 저는 비즈니스적으로 중요한 부분부터 작성하고, 이후에 엣지 케이스를 보강하며 커버리지를 점진적으로 높여가는 방식을 선택했습니다.
서비스의 모든 테스트를 작성하면 좋겠지만, 현실에서는 시간이 여유롭지 못하고 여러 요구사항이 매번 새롭게 주어지며 예외 처리도 해야 하는 복잡한 상황이 생깁니다. 그래서 테스트를 작성하기 전에, ‘이 테스트가 가치가 있는가?’ 를 먼저 생각해보고, 가치가 있다면 작성하고, 아니라면 더 우선순위가 높은 곳에 집중하기로 했습니다.
이러한 저의 생각은 토스 기술 블로그의 가치있는 테스트를 위한 전략과 구현 글을 읽으면서 더 확고해졌습니다. 해당 글에서는 효율적인 테스트 전략에 대해 파레토 법칙(20:80)을 들어 다음과 같이 설명합니다.
“작성 가치를 현명하게 고려하면 가치 있는 20%의 테스트로 80% 이상의 신뢰성을 얻을 수 있습니다.”
이 문장을 보면서 무작정 테스트 커버리지(수치)를 높이는 것보다 핵심 비즈니스 로직(가치)을 지키는 20%에 집중하는 것이 효율적이라는 것을 알게 되었습니다.
또한, 테스트를 작성하다 보면 실용성도 고려해야 했습니다. 테스트 시나리오가 많아질수록 각 계층별로 작성해야 할 양과 겹치는 부분이 많아지게 됩니다. 테스트 코드 역시 유지보수의 대상이기 때문에, 서비스가 지속적인 성장을 하기 위해서는 테스트의 양을 최소화하고 효율적으로 관리해야 할 필요가 있습니다.
최대한 실용적으로 작성하려면 하나의 테스트로 모든 계층을 커버하여 부담을 최소화하고, 문서화 역할까지 겸할 수 있는 통합 테스트를 적극적으로 활용했습니다.
마지막으로 목적에 따라 테스트를 구분하여 작성해야 합니다.
-
도메인 정책 기반 테스트 코드 작성하기
-
사용자 시나리오 기반 테스트 코드 작성하기
아래부터는 실제 경험을 기반으로 위의 테스트를 어떻게 작성했는지 알아보겠습니다.
도메인 정책 기반 테스트 코드 작성하기
도메인 정책 기반 테스트는 특정 비즈니스 규칙이 코드로 올바르게 구현되었는지 검증하는 과정입니다.
이는 기능을 확인하는 것을 넘어, 테스트 코드 자체가 살아있는 정책 문서 역할을 한다는 점에서 중요한 역할이라고 생각합니다.
1. 단위 테스트로 검증 로직 구현하기
여기서 도메인 정책이란 도메인 객체 내에 표현되는 비즈니스 정책을 의미합니다.
예를 들어, 쿠폰을 생성할 때 “발급 가능 수량이 1보다 커야 한다”는 정책이 있다고 가정해 보겠습니다.
이 규칙은 서비스 레이어가 아닌, Coupon 도메인 엔티티 내부에서 검증되어야 가장 안전합니다.
불필요한 JPA 어노테이션이나 필드는 생략하고, 검증 로직에만 집중하여 코드를 보면 다음과 같습니다.
public class Coupon {
// ... 필드 생략
public Coupon(final int totalQuantity, ...) {
validateCouponTotalQuantity(totalQuantity);
// ...
this.totalQuantity = totalQuantity;
}
private void validateCouponTotalQuantity(final int totalQuantity) {
if (totalQuantity < 1) {
throw new CouponDomainException("쿠폰 발급 수량은 1 이상이어야 합니다.");
}
}
}
위의 도메인 엔티티에 대한 정책을 검증하기 위해 아래와 같이 단위 테스트를 작성해볼 수 있습니다.
class CouponTest {
@DisplayName("쿠폰 생성 시 발급 가능한 총 수량이 1보다 작으면 예외가 발생한다.")
@Test
void fail_should_throw_exception_when_coupon_totalQuantity_less_then_1() {
// given
int invalidQuantity = 0;
// when & then
assertThatThrownBy(() -> new Coupon(..., invalidQuantity, ...))
.isInstanceOf(CouponDomainException.class)
.hasMessage("쿠폰 발급 수량은 1 이상이어야 합니다.");
}
}
이처럼 도메인 정책 테스트는 Spring Context나 데이터베이스 같은 무거운 설정 없이, 순수한 Java 객체(POJO) 구조로 작성하면 빠르게 검증할 수 있습니다. 이 덕분에 개발 과정에서 가장 빈번하게 실행하며 테스트로부터 피드백을 받아볼 수 있습니다.
위와 같이 정책 기반으로 테스트를 작성할 때 Spring Bean Context와 Infrastructure 관련 코드 없이 순수한 POJO 구조로 작성하면 빠르게 검증이 가능합니다.
2. 경계값 테스트 활용하기
단위 테스트를 작성할 때는 성공 케이스보다 실패 케이스, 특히 경계값(Edge Case)을 검증하는 것이 비즈니스적으로 가치가 높은 경우가 많습니다.
예를 들어 “게시글 제목은 1자 이상 30자 이하여야 한다”는 정책이 있다면, 정확히 31자일 때 예외가 발생하는지, 그리고 허용 범위 내의 값들은 정상 처리되는지 확인해야 합니다.
class TitleTest {
@DisplayName("게시글 제목이 30자를 초과하면 예외를 던진다")
@Test
void fail_should_throw_exception_when_title_more_then_30() {
// given
String longerThanThirty = "a".repeat(31); // 경계값: 31자
// when & then
assertThatThrownBy(() -> new Title(longerThanThirty))
.isInstanceOf(InvalidTitleException.class)
.hasMessageContaining("제목은 1자 이상 30자 이하여야 합니다.");
}
@DisplayName("게시글 제목이 1자 이상 30자 이하이면 성공한다")
@ParameterizedTest
@ValueSource(strings = {"한 글자", "30자 꽉 채운 제목...", "일반적인 제목"})
void success_create_title_when_title_is_valid(String value) {
// given & when
Title title = new Title(value);
// then
assertThat(title.getValue()).isEqualTo(value);
}
}
이처럼 @ParameterizedTest를 활용하면 다양한 경계값 케이스를 하나의 테스트 메서드로 깔끔하게 검증할 수 있어 효율적입니다.
사용자 시나리오 기반 테스트 코드 작성하기
단위 테스트가 도메인 정책을 검증하는 용도로 사용한다면, 사용자 시나리오 테스트는 사용자의 여정이 올바르게 동작하는지 검증하는 것을 목표로 합니다.
이를 흔히 유스케이스 테스트라고 부릅니다.
일반적으로 이러한 시나리오 검증은 인수 테스트(Acceptance Test) 단계에서 수행합니다.
인수 테스트란 사용자(클라이언트)의 관점에서 요구사항이 충족되었는지 확인하는 테스트입니다.
하지만 인수 테스트는 실제 네트워크 통신 비용이 발생하거나 환경 구축 비용이 커서, 실행 속도가 느리고 피드백이 지연된다는 단점이 있습니다.
그래서 저는 빠른 피드백과 검증의 정확성 사이에서 균형을 맞추기 위해 통합 테스트 계층에서 시나리오 테스트를 구현하는 방법을 선택했습니다. (추후 E2E 레벨의 인수 테스트 경험이 쌓이면 이 포스팅에 내용을 보강할 예정입니다.)
통합 테스트란 서로 다른 계층이 상호작용하며 제대로 동작하는지 검증하는 테스트입니다. 데이터베이스와 같은 외부 의존성을 포함하여 시스템의 내부 흐름을 검증합니다.
사용자 시나리오는 복잡한 비즈니스 로직이 포함된 단일 API일 수도 있고, 회원가입부터 주문까지 이어지는 여러 과정일 수도 있습니다.
단순 조회 기능과 달리 실제 비즈니스 가치를 검증해야 하므로, 테스트를 작성하다 보면 입력 데이터의 복잡성이나 환경 격리 등 현실적인 난관에 부딪히게 됩니다. 이를 해결한 경험을 아래에 공유합니다.
Given 절에서 반복되는 부분을 Fixture 로 활용하기
서비스 규모가 커지고 연관된 객체가 많아질수록 테스트의 Given 절(준비 단계)이 비대해지는 문제가 발생합니다.
이는 정작 테스트하고자 하는 핵심 로직보다 데이터를 세팅하는 준비 시간이 더 오래 걸리게 되고, 이러한 현상이 반복될수록 테스트를 작성하는 사람 입장에서는 테스트 작성에 대한 피로감이 누적되어 결국 최소한의 테스트만 작성하게 되는 악순환으로 이어질 수 있습니다.
실제로 Fixture를 도입하기 전, 하나의 테스트를 작성하기 위해 얼마나 많은 준비 코드가 필요했는지 확인해 보겠습니다.
Fixture 적용 전: Given 절이 비대해진 상황
@ActiveProfiles("test")
@SpringBootTest(classes = ExternalApiConfig.class)
class PostServiceTest {
// ... (Repository 주입 등 생략) ...
@DisplayName("게시글에 대한 상세 페이지를 반환한다.")
@Test
void 게시글에_대한_상세_페이지를_반환한다_Before() {
// given
// 1. 회원(Member) 생성 - 매 테스트마다 빌더로 생성해야 함
Member member = Member.builder()
.email("fancy@gmail.com")
.displayName("팬시")
.socialType(SocialType.GOOGLE)
.build();
memberRepository.save(member);
// 2. 프로필(Profile) 생성 - 필수 값이 많아 코드가 매우 길어짐 (Given 지옥)
Profile profile = Profile.builder()
.member(member)
.nickname("팬시")
.age(28)
.gender(0)
.personality(PersonalityType.TYPE_1)
.introduce("안녕하세요. 저는 백엔드 개발자 팬시입니다.")
.imageName("fancy.png")
.job("백엔드 개발자")
.addressCity(AddressCity.SEOUL)
.addressDistrict(AddressDistrict.SEOUL_GANGNAM)
.jobVisible(true)
.addressVisible(false)
.myImageVisibility(false)
.build();
profileRepository.save(profile);
// 3. 게시글(Post) 생성 - 연관 관계 설정 및 데이터 세팅의 반복
Post post = Post.builder()
.member(member)
.title("프로젝트_해시테크")
.content("프로젝트 해시 태크(http://projecthashtag.net/) 보러가실 분...")
.exhibition("PROJECT HASHTAG 2025 SELECTED ARTISTS")
.exhibitionAttendance(3)
.possibleTime(LocalDateTime.now())
.openChatUrl("http://projecthashtag.net/")
.togetherActivity(TogetherActivity.EAT)
.imageName("postImage1.png")
.postStatus(PostStatus.HOLDING)
.build();
Long savedPostId = postRepository.save(post).getId();
// when
PostDetailResponse response = postService.findPost(savedPostId, LOGIN_MEMBER, EMPTY_COOKIE_VALUE);
// then
assertAll(
() -> assertThat(response.getId()).isEqualTo(post.getId()),
() -> assertThat(response.getTitle()).isEqualTo(post.getTitle()),
() -> assertThat(response.getExhibition()).isEqualTo(post.getExhibition())
);
}
}
위 코드처럼 Given 절을 재활용하지 않으면 테스트를 작성할수록 동일한 셋업 코드가 중복되고 이는 테스트를 작성하는 핵심 관심사의 양보다 많아져서 나중에는 테스트의 핵심 의도를 파악하기가 어려워지게 됩니다.
이러한 문제를 해결하기 위해, 각 테스트마다 반복되는 객체 생성 로직을 별도의 헬퍼 클래스로 분리하는 Test Fixture 방식을 도입했습니다.
Fixture 적용 후: 핵심 로직에 집중
Test Fixture란 테스트를 위해 원하는 상태로 고정시킨 일련의 객체나 데이터를 의미합니다. (흔히 ‘고정물’이라고도 부릅니다.)
예를 들어, 게시글 관련 통합 테스트를 작성할 때 Given 절에서 반복되는 셋업을 아래와 같이 Fixtures 클래스를 작성해볼 수 있습니다. (이 외에 회원, 프로필 클래스도 마찬가지로 Fixtures 클래스를 작성합니다.)
public class PostFixtures {
/* 상수 정의 */
public static final String 게시글_작성한_사용자_닉네임 = "팬시";
public static final String 게시글제목1 = "프로젝트_해시테크";
public static final String 게시글내용1 = "프로젝트 해시 태크(http://projecthashtag.net/) 보러가실 분 있으면 아래 댓글 남겨주세요~";
public static final String 전시회제목1 = "PROJECT HASHTAG 2025 SELECTED ARTISTS";
public static final int 전시관람인원1 = 3;
public static final LocalDateTime 전시관람희망날짜1 = LocalDateTime.now();
public static final String 오픈채팅방Url1 = "http://projecthashtag.net/";
public static final TogetherActivity 함께하고싶은활동1 = TogetherActivity.EAT;
public static final String 게시글이미지1 = "postImage1.png";
public static final PostStatus 모집상태1 = PostStatus.HOLDING;
// 커스텀 Fixture 생성 메서드 (파라미터로 변형 가능)
public static Post 프로젝트_해시테크(Member member) {
return Post.builder()
.member(member)
.title(게시글제목1)
.content(게시글내용1)
.exhibition(전시회제목1)
.exhibitionAttendance(전시관람인원1)
.possibleTime(전시관람희망날짜1)
.openChatUrl(오픈채팅방Url1)
.togetherActivity(함께하고싶은활동1)
.imageName(게시글이미지1)
.postStatus(모집상태1)
.build();
}
}
위의 Fixture 클래스를 활용하면, 비대했던 통합 테스트가 아래와 같이 핵심 비즈니스 로직만 남은 깔끔한 코드로 변합니다.
@ActiveProfiles("test")
@SpringBootTest(classes = ExternalApiConfig.class)
class PostServiceTest {
// ... (Repository 주입 등 생략) ...
@Test
void 게시글에_대한_상세_페이지를_반환한다() {
// given
// Fixture를 사용하여 복잡한 객체 생성 과정을 한 줄로 단축 (메서드명이 문맥을 설명함)
Member 팬시 = memberRepository.save(팬시());
Profile 팬시_프로필 = profileRepository.save(팬시_프로필(팬시));
Post post = postRepository.save(프로젝트_해시테크(팬시));
// when
PostDetailResponse response = postService.findPost(post.getId(), LOGIN_MEMBER, EMPTY_COOKIE_VALUE);
// then
assertAll(
() -> assertThat(response.getId()).isEqualTo(post.getId()),
() -> assertThat(response.getTitle()).isEqualTo(post.getTitle()),
// ... (일부 검증 로직 생략) ...
() -> assertThat(response.getExhibition()).isEqualTo(post.getExhibition())
);
}
}
여기서 한 가지 주의할 점은, 공통 셋업 코드를 @BeforeEach나 @BeforeAll 어노테이션에 몰아넣는 것을 지양했다는 것입니다.
@BeforeEach 어노테이션에 정의된 셋업 코드는 모든 테스트 메서드와 강한 결합을 맺게 됩니다.
만약 비즈니스 로직 변경으로 인해 셋업 코드를 수정해야 한다면, 이 셋업을 공유하는 모든 테스트가 영향을 받게 됩니다.
또한, 테스트 코드를 읽을 때 위아래를 오가며 문맥을 파악해야 하므로, 테스트 자체가 문서로서 기능하기 어려워집니다.
그렇다면 언제 사용하는 것이 좋을까요?
해당 셋업 코드를 몰라도 테스트 내용을 이해하는 데 문제가 없고, 수정해도 다른 테스트에 영향을 주지 않는 경우라면 사용해도 괜찮다고 생각합니다.
저의 경우, Given 절에 일부 중복이 발생하더라도 각 테스트가 독립적으로 읽히고 이해될 수 있는 문서화의 역할이 더 중요하다고 판단했기 때문에,
데이터 셋업에는 @BeforeEach 나 @BeforeAll 어노테이션 사용을 최소화했습니다.
멀티 모듈 환경에서 Fixture 공유하기
위의 사례는 단일 모듈 환경이었습니다. 하지만 프로젝트가 멀티 모듈(Multi-module)로 구성되어 있다면 어떻게 될까요?
예를 들어, 아래와 같은 구조를 가정해 봅시다.
coupon/
├── coupon-api (API 서버)
├── coupon-consumer (카프카 컨슈머)
├── coupon-domain (도메인 엔티티)
이 경우 api 모듈과 consumer 모듈 모두 테스트를 위해 Coupon 객체를 생성해야 하므로, Given 절 작성 시 중복 코드가 발생하게 됩니다.
이를 해결하기 위해 Gradle의 java-test-fixtures 플러그인을 도입했습니다.
이 플러그인을 사용하면 domain 모듈의 테스트 헬퍼 코드(Fixtures 등)를 src/testFixtures 디렉토리로 분리하여 관리할 수 있으며,
이를 다른 모듈(api, consumer)에서 의존성으로 가져와 재사용할 수 있습니다.
먼저 domain 모듈의 build.gradle 파일에서 아래와 같이 해당 java-test-fixtures 플러그인을 추가합니다.
// domain 모듈 - build.gradle(groovy 기준)
plugins {
id 'java-test-fixtures'
}
dependencies {
// 테스트 작성을 위해 아래 의존성 추가
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
그런 다음, 도메인 생성에 필요한 객체를 Fixtures 클래스에 작성합니다.
여기서 주의해야 할 점은 아래 사진과 같이 src/testFixtures에 위치한 Fixture 클래스는 원본 도메인 클래스와 동일한 패키지 경로에 위치시켜야 protected 생성자나 메서드에도 접근할 수 있어 유리합니다.
- 예를 들어, Coupon 클래스의 위치가 CouponFixtures 클래스의 패키지 위치와 같아야 합니다. (위치: package dev.be.coupon.domain.coupon)
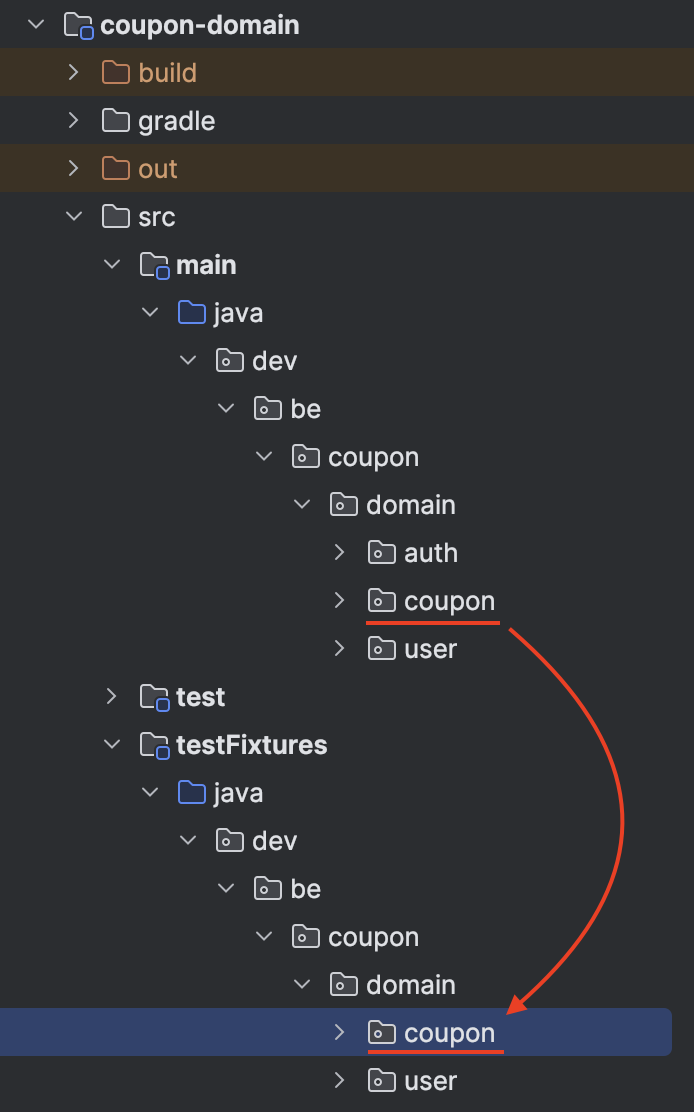
Fixture 클래스는 기본적으로 인자 없이 구성할 수도 있으나, 아래와 같이 테스트하고자 하는 요구사항에 따라 필요한 값만 인자로 받아 유연하게 생성할 수 있도록 구성했습니다.
public class CouponFixtures {
// ... 상수 정의 생략 ...
public static Coupon 정상_쿠폰(int totalQuantity) {
return new Coupon(
쿠폰_이름,
쿠폰_타입_버거,
쿠폰_할인_유형,
쿠폰_할인_금액,
totalQuantity, // 필요한 값만 인자로 받음
유효_기간일
);
}
}
이제 api나 consumer 모듈의 build.gradle에 의존성을 추가하면, domain 모듈에 있는 Fixture를 그대로 사용할 수 있습니다.
// api 모듈, consumer 모듈 - build.gradle(groovy 기준)
dependencies {
// domain 모듈의 testFixtures를 가져옴
testImplementation(testFixtures(project(":coupon:coupon-domain")))
}
api 모듈에서 특정 메서드를 테스트할 때 아래와 같이 domain 모듈에 있는 Fixtures를 적용하면 다음과 같습니다.
@ActiveProfiles("test")
@SpringBootTest
class CouponServiceImplTest {
//...
@DisplayName("사용자가 쿠폰 발급을 요청하면 성공적으로 접수된다.")
@Test
void success_issue_request() {
// given
// 다른 모듈(domain)의 Fixture를 재사용하여 코드 간결화
final UUID couponId = createCoupon(100).getId();
// ...
}
private Coupon createCoupon(final int totalQuantity) {
Coupon coupon = CouponFixtures.정상_쿠폰(totalQuantity);
return couponRepository.save(coupon);
}
}
이를 통해 모듈 간 중복 코드를 제거하고, 일관된 방식으로 테스트 데이터를 생성할 수 있게 되었습니다.
Fixture 구성 시 유의해야 할 점
Given 절에 Fixtures를 구성하다 보면 자연스럽게 셋업 코드가 방대해지고 클래스가 많아질 수 있습니다.
무분별하게 Fixture를 늘리기보다, 지속 가능한 테스트를 위해 저는 다음과 같은 관리 기준을 세웠습니다.
이때 어떤 기준을 가지고 Fixture를 관리해야 할까요?
1. 전역적인 data.sql 사용은 지양하기
가장 먼저 경계해야 할 것은 data.sql 등을 이용해서 모든 테스트가 공유하는 전역 데이터를 미리 셋업해 두는 방식입니다.
테스트 코드를 확인할 때 어떤 데이터가 들어있는지 파악하기 위해 SQL 파일을 뒤져야 하는 번거로움이 발생합니다.
또한, 서비스가 고도화될수록 SQL 파일이 비대해지고, 데이터 하나를 수정하면 이와 연관 없는 수십 개 이상의 테스트가 깨지는 Side Effect가 발생합니다.
따라서 테스트 간의 독립성을 유지하기 위해 전역 데이터 세팅은 가급적 피하는 것이 좋다고 생각합니다.
2. 필요한 파라미터만 유연하게 받기
기본적으로 코드 기반의 Fixture를 사용하는 것을 권장합니다. 그 이유는 컴파일 타임 체크가 가능하고 리팩터링에 유리하기 때문입니다.
테스트 클래스마다 검증하려는 필드가 다를 수 있습니다. 이때 모든 필드를 다 받는 빌더 하나만 사용하는 것보다는 테스트 목적에 맞게 필요한 파라미터만 받는 팩토리 메서드를 여러 개 두는 것이 좋다고 봅니다.
그리고 무작정 필드 조합별로 빌더를 만들기보다, 기본값을 활용하고 변경이 필요한 값만 인자로 받는 방식을 사용하면 복잡도를 낮출 수 있습니다. (Kotlin 에서는 Named Argument가 이를 잘 해결해 줍니다.)
3. 복잡한 데이터 셋업의 한계와 Sql 어노테이션 활용하기
하지만 코드 기반의 Fixture만 고집하다 보면 Given 지옥에 빠지는 경우가 있습니다.
카카오페이 기술 블로그의 실무에서 적용하는 테스트 코드 작성 방법과 노하우 Part 3: Given 지옥에서 벗어나기 에서는 다음과 같은 경우 객체 기반 셋업의 한계를 지적합니다.
- 주문 시스템처럼 상품, 회원, 쿠폰, 결제 등 수십 개의 객체가 얽혀있는 경우
- 대량의 데이터를 Aggregation 하는 배치(Batch) 애플리케이션을 테스트해야 하는 경우
이럴 때 억지로 코드를 객체로 생성하려고 하면, Given 절만 수십 줄이 되고 객체 간의 의존성을 맞추느라 정작 테스트 로직에 집중하기 어려워집니다.
이런 복잡도가 높은 상황에서는 테스트 전용 @Sql 어노테이션이나 @SqlGroup 어노테이션을 활용하는 것이 더 효율적일 수 있습니다.
-
@Sql: 특정 시점의 데이터를 SQL 파일로 미리 정의하여, 테스트 실행 전에 DB 상태를 원하는 대로 빠르게 셋업합니다. -
@SqlGroup: 여러 SQL 파일을 묶어서 실행하거나, 실행 순서를 제어할 때 유용합니다.-
예를 들어
Schema 설정 -> 데이터 삽입 -> 테스트 실행 -> 데이터 삭제(Clean up)와 같은 흐름을 정의하여, 데이터 셋업뿐만 아니라 테스트 후 정리 과정까지 깔끔하게 관리할 수 있습니다. -
특히 복잡한 연관관계를 가진 데이터나, 대량의 데이터를 가공해야 하는 배치(Batch) 애플리케이션 테스트에 적합합니다.
-
이 방식의 장단점은 다음과 같습니다.
-
장점: 복잡한 연관 관계나 대량의 데이터를 SQL 스크립트로 한 번에 구성하므로, 비즈니스 로직 검증에만 집중할 수 있습니다.
-
단점: 코드 리팩터링(컬럼명 변경 등) 시 SQL 파일은 컴파일 타임에 체크되지 않으므로, 별도의 관리가 필요합니다.
결국 유지보수성과 편의성 사이의 트레이드오프라고 생각합니다. 그래서 저는 아래와 같은 기준을 세워 적용하고 있습니다.
-
일반적인 도메인 검증시에는 코드 기반의 Fixture를 사용합니다.
-
그리고 테스트 독립성을 확보하기 위해 가급적 전역 데이터를 사용하지 않습니다.
-
만약 복잡한 조회 혹은 배치, 대량의 데이터를 검증할 경우, 코드 기반의 Fixture로 표현하기 복잡하다면 해당 테스트 메서드에 한정하여
@Sql이나@SqlGroup을 사용하여 셋업 효율성을 확보합니다.
독립적이고 효율적인 테스트 환경 구축하기
이번에는 테스트를 독립적이고 반복적으로 수행할 수 있도록 격리하고, 그에 필요한 환경을 초기화했던 경험을 공유하고자 합니다.
통합 테스트를 작성하다 보면 필연적으로 데이터베이스를 사용하게 됩니다. 이때 가장 중요한 원칙은 각 테스트는 독립적이어야 한다는 것입니다. (이는 위 섹션인 “테스트 코드를 가치있게 작성하기 위한 전략”에서 언급한 바 있습니다.) 즉, A 테스트가 만든 데이터가 B 테스트에 영향을 주어서는 안 됩니다.
이를 위해 매 테스트가 실행될 때마다 데이터베이스를 깨끗하게 비워줘야 하는데, 저는 TRUNCATE 명령어를 활용한 초기화 방법을 선택했습니다.
왜
@Transactional롤백 대신 TRUNCATE를 사용했는가?
흔히 테스트 격리를 위해 테스트 메서드에 @Transactional을 붙여, 테스트가 끝나면 자동으로 롤백되는 방식을 사용하곤 합니다.
간편한 방법이지만, 저는 다음과 같은 이유로 이 방식을 사용하지 않았습니다.
-
Auto Increment(ID)가 초기화되지 않습니다.
-
롤백은 데이터(Row)만 취소될 뿐, 증가된 ID 값(Sequence)은 초기화되지 않습니다.
-
이로 인해 테스트 순서에 따라 ID 값이 달라지게 되어, 특정 ID를 검증하는 테스트가 실패할 수 있습니다.
-
-
비즈니스 로직의 트랜잭션 검증이 어렵습니다.
- 테스트 메서드 자체에
@Transactional이 걸려있으면, 실제 비즈니스 로직의 트랜잭션 경계가 모호해지거나 의도치 않게 전파(Propagation)될 수 있습니다.
- 테스트 메서드 자체에
따라서 저는 확실한 초기 상태를 만들기 위해 테이블을 비우고 ID 값까지 초기화하는 TRUNCATE 방식을 택했습니다.
데이터 오염을 방지하는 초기화 방식
TRUNCATE는 테이블의 모든 행을 삭제하고 스토리지 공간을 반납하는 DDL(Data Definition Language) 명령어입니다.
DELETE 명령어보다 속도가 빠르고 ID 값도 1부터 다시 시작하게 해줍니다.
하지만, 테이블 간의 외래 키(Foreign Key) 제약 조건이 걸려있는 경우 무작정 테이블을 지울 수 없습니다.
그래서 아래와 같이 DatabaseCleaner 유틸리티 클래스를 구현했습니다.
@Component
public class DatabaseCleaner {
private final EntityManager entityManager;
private final List<String> tableNames;
public DatabaseCleaner(final EntityManager entityManager) {
this.entityManager = entityManager;
// 1. JPA의 EntityMetamodel을 이용하여, @Entity가 붙은 모든 테이블 이름을 추출합니다.
this.tableNames = entityManager.getMetamodel()
.getEntities()
.stream()
.map(Type::getJavaType)
.map(javaType -> javaType.getAnnotation(Table.class))
.map(Table::name)
.collect(Collectors.toList());
}
@Transactional
public void execute() {
entityManager.flush();
// 2. 제약 조건 무효화: 외래 키 체크를 잠시 해제합니다.
entityManager.createNativeQuery("SET foreign_key_checks = 0").executeUpdate();
// 3. 전체 테이블 Truncate: 데이터를 비우고 ID를 초기화합니다.
for(String tableName : tableNames) {
entityManager.createNativeQuery("TRUNCATE TABLE " + tableName).executeUpdate();
}
// 4. 제약 조건 재설정: 외래 키 체크를 다시 활성화합니다.
entityManager.createNativeQuery("SET foreign_key_checks = 1").executeUpdate();
}
}
(참고로, 위 코드는 MySQL(MariaDB) 환경을 기준으로 작성되었습니다.)
- 만약 H2 Database를 사용하신다면
SET foreign_key_checks = 0대신SET REFERENTIAL_INTEGRITY FALSE구문을 사용해야 하니, 사용하시는 DB 방언에 맞춰 쿼리를 조정해 주시면 감사하겠습니다.
위 코드는 JPA의 메타모델을 이용해 테이블 이름을 동적으로 가져오기 때문에, 엔티티가 추가되거나 변경되어도 코드를 수정할 필요가 없다는 장점이 있습니다.
테스트 설정 재사용으로 실행 속도 개선하기
환경 초기화만큼이나 중요한 것이 테스트 실행 속도입니다.
@SpringBootTest를 사용하면 스프링 컨텍스트(서버)가 로딩되는데, 설정(Configuration)이 달라질 때마다 컨텍스트가 새로 띄워지게 됩니다.
이는 테스트가 많아질수록 전체 빌드 시간을 기하급수적으로 늘리는 원인이 됩니다.
이를 방지하기 위해, 저는 모든 통합 테스트가 상속받아 사용할 수 있는 상위 추상 클래스인 IntegrationTestSupport를 구현했습니다.
@Import(JpaAuditingConfig.class)
@ActiveProfiles("test")
@SpringBootTest
public abstract class IntegrationTestSupport {
// 자주 사용되는 Fixture 혹은 유틸리티 클래스
protected static final LoginMember LOGIN_MEMBER = new LoginMember(FANCY_ID);
@Autowired
private DatabaseCleaner databaseCleaner;
@Autowired
private TokenRepository tokenRepository;
@BeforeEach
void setUp() {
// 매 테스트 시작 전, DB를 초기화합니다.
databaseCleaner.execute();
// Redis 등 다른 저장소가 있다면 여기서 함께 초기화합니다.
tokenRepository.deleteAll();
}
}
이렇게 구성하면 모든 테스트가 동일한 IntegrationTestSupport의 설정을 공유하게 되므로, 스프링 컨텍스트를 최소한의 횟수만 띄우고 계속 재사용할 수 있어 테스트 성능을 높일 수 있습니다.
이를 통해 개발자가 격리된 환경과 개선된 속도 덕분에 비즈니스 로직 검증에만 온전히 집중할 수 있습니다.
외부 의존성을 제어 가능한 영역으로 만들기
테스트를 작성하다 보면 외부 서비스를 이용해야 하는 경우가 필연적으로 발생합니다. 대표적으로 소셜 로그인(OAuth)이나 결제 시스템 등이 있습니다.
만약 테스트를 돌릴 때마다 실제 구글 서버에 네트워크 요청을 보낸다면 어떤 문제가 발생할까요?
-
외부 서버의 상태에 따라 테스트 성공 여부가 달라지는 불확실성이 생깁니다.
-
네트워크 통신으로 인해 테스트 수행 속도가 느려지게 됩니다.
-
마지막으로 실제 외부 서비스에 불필요한 테스트 데이터가 쌓이는 데이터 오염이 발생합니다.
저는 이러한 제어할 수 없는 외부 의존성을 제어 가능한 영역으로 가져오기 위해, 실제 동작과 동일한 결과를 반환하지만 네트워크 요청은 하지 않는 가짜 객체(Stub/Fake)를 활용하는 전략을 활용했습니다.
1. 테스트 환경 분리를 위한 Bean 설정
실제 프로덕션 코드에서는 외부 API를 호출하는 구현체가 동작해야 하지만, 테스트 환경에서는 가짜 객체가 동작하도록 설정을 분리해야 합니다.
이를 위해 ExternalApiConfig라는 테스트 전용 설정 클래스를 만들고,
여기서 OAuthClient나 TokenProvider 같은 인터페이스의 구현체를 가짜 객체(Stub)로 생성했습니다.
- 여기서
Stub이란 상태 검증을 의미하며, 가짜 객체로 요청한 것에 대해 미리 준비한 결과를 제공합니다.
@TestConfiguration
public class ExternalApiConfig {
// 실제 네트워크 통신 대신, 미리 정의된 값을 반환하는 Stub 객체를 빈으로 등록
@Bean
public OAuthClient oAuthClient() {
return new StubOAuthClient();
}
@Bean
public OAuthUri oAuthUri() {
return new StubOAuthUri();
}
// JWT 토큰 생성도 테스트 환경에 맞는 가짜 키와 유효기간을 가진 Provider로 대체
@Bean
public TokenProvider tokenProvider() {
return new StubTokenProvider(더미_시크릿_키);
}
}
그리고 이 설정을 통합 테스트의 공통 부모 클래스인 IntegrationTestSupport에 Import 하여, 모든 통합 테스트가 이 가짜 빈들을 사용하도록 구성했습니다.
@ActiveProfiles("test")
@SpringBootTest(classes = ExternalApiConfig.class) // 테스트 설정 적용
public abstract class IntegrationTestSupport {
// ...
}
2. 가짜 객체(Stub)로 구현하기
가짜 객체는 실제 로직처럼 복잡하게 구현할 필요가 없습니다. 테스트 목적에 맞게 “약속된 동작”만 수행하면 됩니다.
예를 들어 StubTokenProvider는 복잡한 암호화 로직 검증보다는, 단순히 토큰을 생성하고 파싱 할 수 있는 최소한의 기능만 갖추도록 구현했습니다.
public class StubTokenProvider implements TokenProvider {
private final SecretKey key;
private final long accessTokenValidityInMilliseconds = 0;
private final long refreshTokenValidityInMilliseconds = 360000;
// 실제 키가 아닌 테스트용 더미 키를 사용하여 초기화
public StubTokenProvider(final String secretKey) {
this.key = Keys.hmacShaKeyFor(secretKey.getBytes(StandardCharsets.UTF_8));
}
@Override
public String createAccessToken(final String payload) {
// 네트워크 통신 없이 즉시 토큰 생성
return createToken(payload, accessTokenValidityInMilliseconds);
}
// ... 검증 및 파싱 로직 ...
}
3. 외부 요인 없이 비즈니스 로직 검증하기
이렇게 환경을 구축한 덕분에, AuthServiceTest에서는 외부 OAuth 서버의 상태와 상관없이 우리 서비스의 로그인 및 토큰 발급 로직을 안정적으로 검증할 수 있게 되었습니다.
@RecordApplicationEvents
class AuthServiceTest extends IntegrationTestSupport {
@Autowired
private AuthService authService;
@Autowired
private ApplicationEvents events;
//...
@DisplayName("토큰 생성을 하면 OAuth 서버에서 인증 후 토큰을 반환한다")
@Test
void 토큰_생성을_하면_OAuth_서버에서_인증_후_토큰들을_반환한다() {
// given & when
// StubOAuthClient가 동작하므로 실제 네트워크 요청 없이 즉시 결과 반환
AccessAndRefreshTokenResponse actual = authService.generateAccessAndRefreshToken(MEMBER.getOAuthMember());
// then
assertAll(() -> {
assertThat(actual.getAccessToken()).isNotEmpty();
assertThat(actual.getRefreshToken()).isNotEmpty();
// 외부 요인을 배제하고, 핵심 비즈니스 로직(이벤트 발행 등)만 검증 가능
assertThat(events.stream(MemberSavedEvent.class).count()).isEqualTo(1);
});
}
// ...
}
결과적으로 외부 의존성을 격리함으로써 테스트 속도를 이전보다 더 개선했고, 외부 이슈로 인해 테스트가 깨지는 일을 방지하여 테스트의 신뢰성을 높일 수 있습니다.
테스트 대역을 올바르게 활용하기
앞서 소개한 Stub 방식 외에도 상황에 따라 다양한 테스트 대역을 활용할 수 있습니다. 가짜 객체를 통칭하는 테스트 대역(Test Double)은 크게 다섯 가지로 분류됩니다.
-
Dummy: 아무것도 하지 않는 깡통 객체. (인자 채우기 용도) -
Fake: 단순한 형태로 동일한 기능은 수행하나, 프로덕션에서 쓰기에는 부족한 객체. (예시. 인메모리 DB, HashMap Repository) -
Stub: 테스트에서 요청한 것에 대해 미리 준비한 결과를 제공하는 객체. (상태 기반 검증) -
Spy: 실제 객체처럼 동작하면서 호출된 내용을 기록하거나 일부만 조작할 수 있는 객체. -
Mock: 행위(호출 여부, 횟수 등)에 대한 기대를 명세하고, 그에 따라 동작하도록 만들어진 객체. (행위 기반 검증)
다양한 대역이 존재하지만, 좋은 테스트란 무엇인가?를 다시 생각해보면, 결국 실제 서비스 환경과 가장 유사하게 검증하는 것이 중요하다고 생각합니다.
Mocking을 통해 특정 메서드가 호출되었는지(행위)를 검증하게 되면, 테스트가 “어떻게(How) 동작하는지”와 같은 내부 구현에 깊게 의존하게 됩니다. 이는 비즈니스 로직을 리팩터링할 때 기능은 문제없이 동작함에도 불구하고, 내부 구현 방식이 달라졌다는 이유로 테스트가 깨지는 강결합 문제를 야기할 수 있습니다.
실제로 구글 엔지니어링 블로그에서도 과거의 시행착오를 바탕으로 “모의 객체 사용을 줄이고 실제 객체를 활용하여 테스트 충실도를 높이라”고 강조합니다.
(관련해서 구글 공식 Testing 블로그에 있는 해당 포스팅을 참고했습니다.)
-
Increase Test Fidelity By Avoiding Mocks (2024)
Tests that use mocks are often less faithful to the production system (lower fidelity) because they test the code in isolation from its dependencies. (Mock을 사용하는 테스트는 의존성으로부터 격리된 코드를 테스트하기 때문에, 실제 운영 시스템에 대한 충실도가 떨어지는 경우가 많습니다.)
지나친 Mocking이나 Stubbing은 테스트 구현을 편하게 할 수는 있어도, 실제 운영 환경에서의 동작을 보장하지 못하며 리팩터링 내성을 떨어뜨립니다.
그래서 저는 제어할 수 있는 영역에는 가능한 실제 객체를 사용하고, 외부 서비스와 같은 제어할 수 없는 영역은 가짜 객체를 사용하는 것으로 원칙을 세웠습니다.
이를 정리하면 다음과 같습니다.
-
우리 서비스인 경우(내부), 가급적 실제 객체를 사용합니다.
-
비즈니스적으로 특정 상태를 재현하기 어려운 경우에만
Stub을 사용합니다. -
예외 발생 상황 등을 검증할 때 제한적으로
Spy를 사용합니다.
-
-
우리 서비스가 아닌 경우(외부), 제어할 수 없는 영역이므로
Stub이나Fake객체와 같은 가짜 객체를 사용합니다.
Spy 객체를 활용하여 예외 상황 검증하기
위 전략 중 “제한적으로 Spy를 사용한다”는 부분에 대해 구체적인 사례를 공유하고자 합니다.
Spy 객체는 실제 객체를 감싸서 동작하되, 특정 메서드만 원하는 동작으로 변경(Stubbing)하거나, 호출 여부를 감시할 수 있다는 장점이 있습니다.
저는 주로 “대부분 실제 로직을 실행하고 싶지만, 특정 구간에서만 강제로 예외를 발생시켜야 할 때” Spy를 유용하게 사용했습니다.
예를 들어, 쿠폰 발급 실패를 처리하는 핸들러(FailureHandler)를 테스트한다고 가정해 봅시다. DB 연결이 끊어진 치명적인 상황(Fatal Exception)을 재현하려면, 실제 서비스 객체의 로직을 수행하다가 저장하는 시점에만 강제로 예외를 던져야 합니다.
@ActiveProfiles("test")
@SpringBootTest
class CouponIssueFailureHandlerTest {
@Autowired
private CouponIssueFailureHandler failureHandler;
// 실제 객체처럼 동작하되, 필요할 때만 동작을 조작하기 위해 @SpyBean 사용
@SpyBean
private CouponIssuanceService couponIssuanceService;
@Test
@DisplayName("[신규 - 실패] DB 다운 시, 실패 이력 저장을 '시도'하고 예외를 던진다 (ack 안함).")
void fail_record_failure_and_rethrow_when_fatal_exception_on_handle() {
// given
// ... (메시지 생성 로직 생략) ...
// Spy 객체의 recordFailure 메서드가 호출될 때만 강제로 예외를 던지도록 설정 (Stubbing)
doThrow(new RuntimeException("DB Connection Pool is down"))
.when(couponIssuanceService).recordFailure(any(), any());
// when & then
// 예외가 잡히지 않고 전파되는지 검증 (치명적 오류이므로 Ack를 보내면 안 됨)
assertThatThrownBy(() -> failureHandler.handle(message, ack, e))
.isInstanceOf(CouponConsumerException.class); // 예외가 전파되는지 검증
// 실제 메서드가 호출되었는지(행위) 검증
verify(couponIssuanceService, times(1)).recordFailure(any(), any());
}
}
위 코드처럼 Spy를 사용하면 정상적인 흐름은 실제 객체에 위임하고, 테스트하고 싶은 엣지 케이스를 제대로 검증할 수 있습니다.
이러한 전략이 절대적인 정답은 아니겠지만, 비즈니스 상황과 팀의 환경에 맞춰 가치 있고 신뢰성 높은 테스트를 작성하기 위한 저만의 기준이 되었습니다.
마무리하며
테스트 코드를 작성하다 보니 자연스럽게 코드 품질에 대해 고민하게 되었고, 이를 개선하기 위해 리팩터링을 반복하며 개발자로서 한 단계 성장할 수 있었습니다. 책과 강의를 통해 배운 내용을 기존 코드에 적용해 보며, 더 읽기 쉽고 견고한 코드로 바꿔나가는 과정 자체가 저에게는 큰 배움이었습니다.
이처럼 테스트가 주는 이점은 단순히 QA 시간을 단축하는 것을 넘어, 더 나은 설계를 유도하고 코드의 품질을 높이는 데 있다고 봅니다.
실무의 복잡한 비즈니스 로직을 모두 테스트하는 것은 결코 쉬운 일이 아닙니다. 하지만 꾸준히 작성하려는 노력이 쌓인다면, 이는 장기적으로 유지보수하기 좋은 자산이 될 것입니다.
그렇기에 처음부터 완벽한 확장성을 고려하기보다는, 작은 단위 테스트부터 시작해 점진적으로 개선해 나가는 방식을 지향합니다. 또한, 서비스의 성장 단계와 팀의 리소스, 개발 환경에 따라 가장 실용적인 전략을 선택하는 유연함이 중요합니다.
모든 문제에 대한 완벽한 정답은 없기에, 우리 팀만의 기준을 세우고 실행하며 전략을 계속해서 수정해 나가는 과정 자체가 중요하다고 생각합니다.
완벽한 테스트는 없겠지만, 매 순간 더 나은 테스트를 고민하며 팀의 생산성과 서비스의 안정성에 기여하는 개발자가 되고자 합니다.
함께 읽으면 좋은 글
해당 포스팅과 관련해서 이전에 제가 Java, Spring Boot 기반으로 테스트와 관련된 포스팅을 작성한 글은 아래와 같습니다.
Reference
-
[토스] 기술 블로그 - 가치있는 테스트를 위한 전략과 구현 (발행 날짜: 2024. 10)
-
[카카오페이] 기술 블로그 - 실무에서 적용하는 테스트 코드 작성 방법과 노하우 (발행 날짜: 2023. 07 - 2025. 02)
-
[Google] Testing Blog - Increase Test Fidelity By Avoiding Mocks (발행 날짜: 2024. 02)