흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
실전! 스프링 부트와 JPA 활용1 - 변경 감지와 병합(merge)
이 글의 코드와 정보들은 [실전! 스프링 부트와 JPA 활용 1] 강의를 들으며 정리한 내용을 토대로 작성하였습니다..
-
실전! 스프링 부트와 JPA 활용1 - H2 데이터베이스 설치
이 글의 코드와 정보들은 [실전! 스프링 부트와 JPA 활용 1] 강의를 들으며 정리한 내용을 토대로 작성하였습니다.
-
H2DB를 사용하는 이유 : 개발이나 테스트 용도로 가볍고 편리한 DB, 웹 화면 제공하기 때문. -
[1] H2 데이터베이스 1.4.199 다운로드를 받은 후, 압축을 푼다. (압축푼 폴더명 : h2)
-
[2] 터미널을 열고 해당 폴더(h2) -> bin으로 이동한다.(cd bin) ->
ll로 h2.sh가 있는지 확인한다. -
[3]
cat h2.sh-> java 언어이기 때문에 java 언어로 미리 다운받아있어야 한다. -
사전에 brew + java11이 설치되어 있어야 한다.
-
[3-1] adoptopenjdk/openjdk 추가 :
brew tap adoptopenjdk/openjdk -
[3-2] 설치 가능한 모든 JDK 찾기 :
brew search jdk -
[3-3] java 11버전 설치 :
brew install --cask adoptopenjdk11 -
[3-4] 자바가 설치된 곳 확인 :
/usr/libexec/java_home -V -
[3-5] 자바 버전 확인 :
java --version
-
-
[4] 실행 :
./h2-> [5], [6]-
만약
-bash: ./h2.sh: Permission denied문제가 발생하는 경우,chmod 755 h2.sh입력후 엔터친 다음에 다시./h2.sh를 입력한다. -
cf) 실행 취소 명령어 :
control + c
-
-
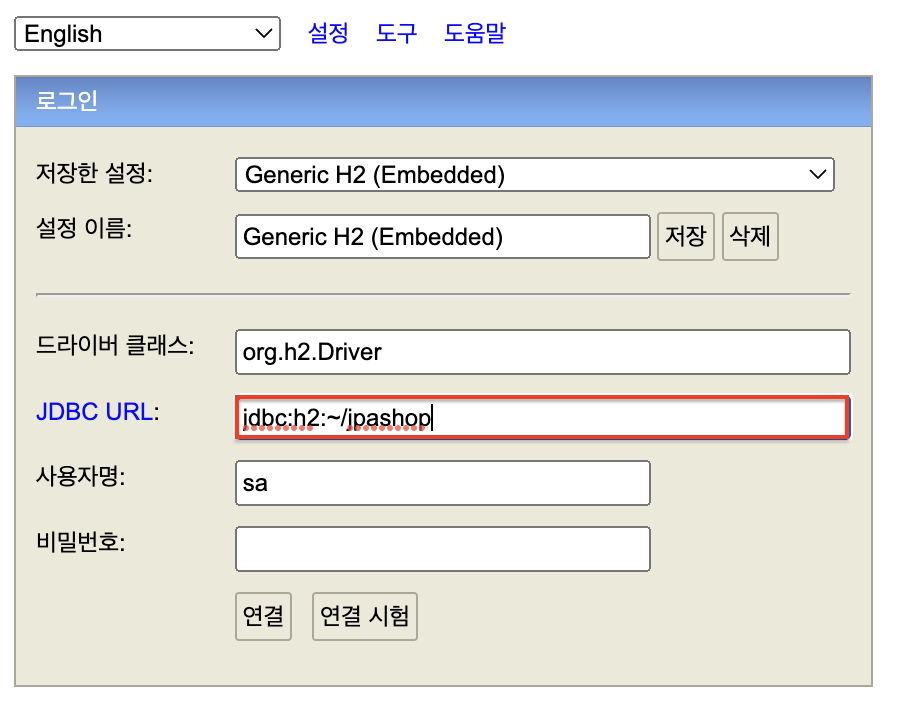
[5] DB 파일 생성 방법 : 세션키 유지한 상태로, JDBC URL에 해당
jdbc:h2:~/jpashop입력후연결버튼을 클릭한다. 그러면 /jpashop이라는 DB 파일이 생성된다.
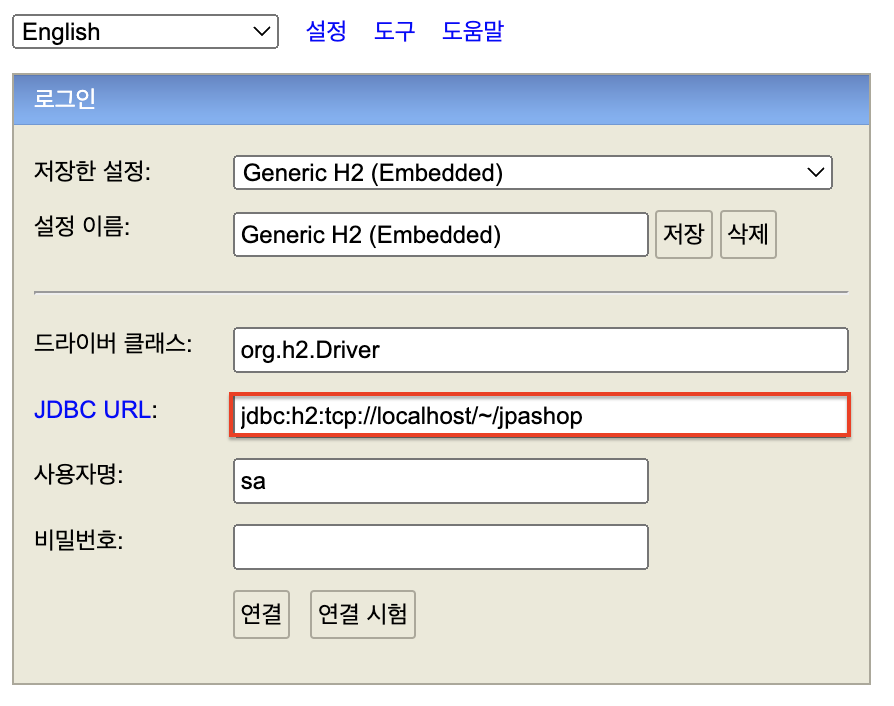
- [6] 생성된 이후에는 JDBC URL에 네트워크 모드로(TCP/IP를 통해) 접근하기 위해
jdbc:h2:tcp://localhost/~/jpashop입력후연결버튼을 클릭한다.
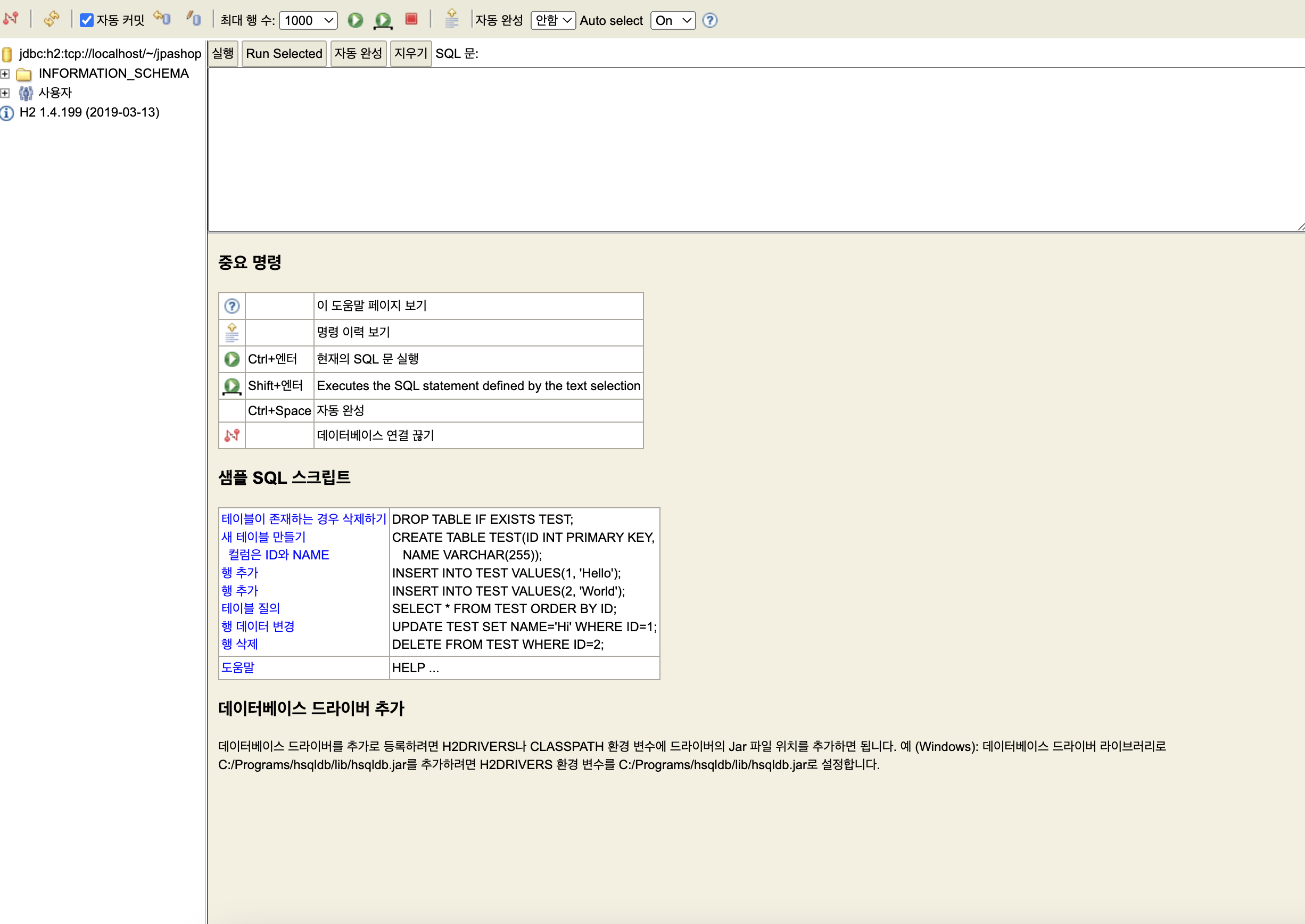
- [7] 이렇게 해서 DB 설치가 완료된 것을 확인할 수 있다. (http://localhost:8082/~)
Reference
-
-
인텔리제이 템플릿 자동완성(Live Template 적용)
- 코드를 작성하다보면 똑같은 코드를 치는 경우가 생기는 경우에는
Live Template기능을 적용시켜서 코드의 가독성을 높여보자.
@RunWith(SpringRunner.class) @SpringBootTest public class MemberRepositoryTest { @Autowired MemberRepository memberRepository; }-
기존 코드에서 @Test 와 같이 테스트코드의 형식은 똑같은 경우가 많다.
-
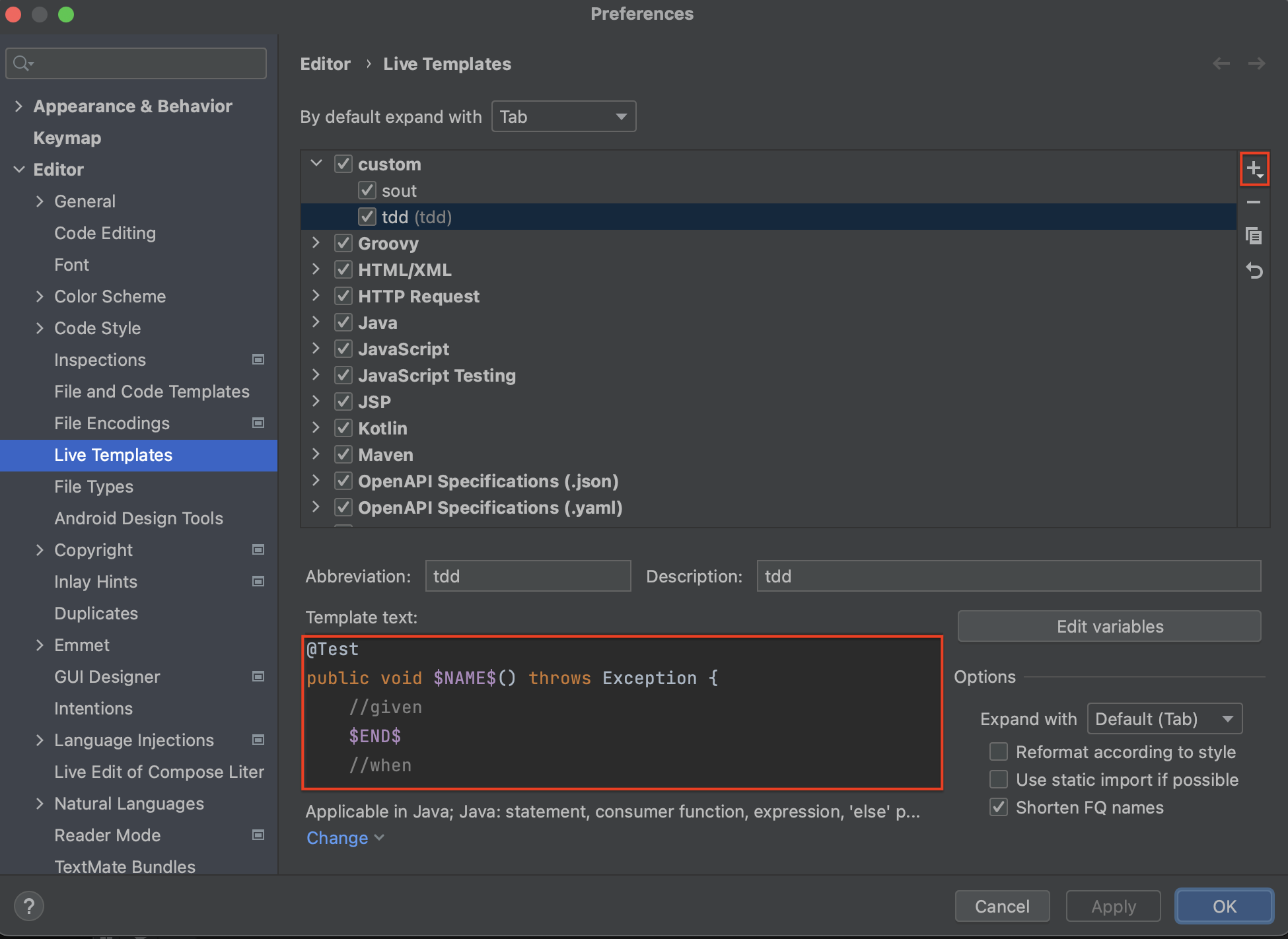
해당 테스트코드를 Live Template 기능을 적용시켜보자.
-
위측 상단의 IntelliJ IDEA -> Settings -> Live Template
-
custom아래에 tdd라는 이름을 추가하기 위해 오른쪽에+버튼을 클릭하고,Abbreviation부분에 tdd를 입력한다.Description부분에는 tdd에 대한 설명을 입력하면 된다.(나는 설명이 필요없기 때문에, tdd로 했다)
-
그리고 아래의
Template text부분에 반복적으로 작성할 코드를 입력한다. -
입력을 다한 이후에 Apply -> Ok 버튼을 클릭한다.
-
해당 코드로 넘어와서 tdd 를 입력하고 Tap 키를 누르면, 아래와 같이 Live Template 기능이 적용된 것을 확인할 수 있다.
@RunWith(SpringRunner.class) @SpringBootTest public class MemberRepositoryTest { @Autowired MemberRepository memberRepository; @Test public void testMember() throws Exception { //given //when //then } }
- 코드를 작성하다보면 똑같은 코드를 치는 경우가 생기는 경우에는
-
[Programmers] 131529. 카테고리 별 상품 개수 구하기(Lv.2) (String, Date)
성능 요약
- 메모리: 0.0 MB, 시간: 0.00 ms
구분
- 코딩테스트 연습 > String, Date
Answer Code1(2023.02.25)
SELECT LEFT(PRODUCT_CODE, 2) AS CATEGORY, COUNT(PRODUCT_ID) AS PRODUCTS FROM PRODUCT GROUP BY CATEGORY;문제 풀이 - Answer Code1
-
이번 문제는 컬럼에서 특정 문자열을 추출하고 이를 집계하는 문제였다.
-
[1] 상품 카테코리 코드(PRODUCT_CODE, 2)별 상품 개수를 출력한다.
-
아래 실행 예시를 보면
CATEGORY,PRODUCTS을 확인할 수 있다. -> 문제에서 해당 두개의 컬럼을 사용하라는 의미다. -
‘PRODUCT_CODE’ 컬럼에서 앞 2글자가
CATEGORY를 의미하고, 카테고리별로 해당하는 숫자를 구하면 되는 문제인 것이다. -
결과 :
SELECT LEFT(PRODUCT_CODE, 2) AS CATEGORY, COUNT(PRODUCT_ID) AS PRODUCTS
-
-
[2] PRODUCT 테이블에서 가져오는 것이므로 -> 결과 :
FROM PRODUCT -
[3] 상품 카테고리 코드를 기준으로 오름차순 정렬해주세요. -> 실행 예시에서는
CATEGORY를 기준으로 오름차순 했으므로 해당 키워드를 사용하라는 의미다.-
유형별로 갯수를 알고 싶을 때 컬럼에 데이터를 그룹화 할 수 있는
GROUP BY를 사용한다. (특정 컬럼을 그룹화) -
결과 :
GROUP BY CATEGORY: 기본적으로 오름차순으로 정렬한다.
-
-
[Programmers] 92335. k진수에서 소수 개수 구하기
- 성능 요약
- 구분
- Answer Code1(2022.02.20)
- Answer1 - 문제 풀이
- Answer Code2(2022.02.24)
- Answer2 - 문제 풀이
- Review
- Reference
성능 요약
-
메모리: 67.2 MB, 시간: 8.99 ms - Answer Code1(2022.02.20)
-
메모리: 72.9 MB, 시간: 0.09 ms - Answer Code2(2022.02.23)
구분
- 코딩테스트연습 > 2022 KAKAO BLIND RECRUITMENT
Answer Code1(2022.02.20)
import java.util.*; class Solution { public int solution(int n, int k) { int answer = 0; String temp = ""; //N진법 변환 while(n != 0) { temp = n % k + temp; n /= k; } String [] arr = temp.split("0"); for(String str : arr) { if(str.equals("")) { continue; } long num = Long.parseLong(str); if(isPrime(num)) { answer++; } } return answer; } // 소수 확인 메서드 public boolean isPrime(long decimal) { if(decimal < 2) return false; for(int i = 2; i <= Math.sqrt(decimal); i++) { if(decimal % i == 0) { return false; } } return true; } }Answer1 - 문제 풀이
-
소수 판별 알고리즘 문제였다.
-
처음에 문제에 대한 설명을 보고 도무지 이해가 안되어서 가만히 생각해봤는데,
0을 기준으로 분해시켜서 개수를 구하면 되는 문제였다. -
[1] N진법 로직으로 구현한다.
- N진법 변환 로직은 While문을 사용하여, N을 K로 나눈 나머지를 계속 앞에 붙여나간다.
-
[2] N진법으로 푼 문자열을
0을 기준으로 Split 한다.-
주의 1) 1001 처럼 가운데 0이 있는 상태로 분해할 경우 1, “”, 1이 반환이 된다. 빈칸을 숫자로 변환하면 오류가 생기니 이런 경우를 제외해야 한다.
-
주의 2) 변환할 때 숫자를 Long 타입으로 바꿔야한다. 최대 100만이라는 숫자를 N진법으로 변환하면 엄청난 길의 숫자가 나열되고, int의 범위를 넘어서는 숫자가 생성되기 때문이다.
-
-
소수를 판별할 때는 에라토네스 체를 사용하는 걸 권장한다. 권장한 이유는 연산을 최대한 많이 줄이면서 소수인지 판별이 가능하기 때문이다.
Answer Code2(2022.02.24)
class Solution { public int solution(int n, int k) { int ans = 0; String temp[] = Integer.toString(n, k).split("0"); Loop : for(String t : temp) { if(t.length() == 0) continue; long a = Long.parseLong(t); if(a == 1) continue; for(int i=2; i<=Math.sqrt(a); i++) if(a%i == 0) continue Loop; ans++; } return ans; } }Answer2 - 문제 풀이
-
두 번째 풀이는 좋아요 수가 많은 답안인데, 정말 깔끔한 풀이였다.
-
10진수 -> k진수로 변경은
String.valueOf(바꾸려는 숫자(10진수), 바꾸려는 k진법)으로 간단하게 구현 가능하는 것을 구글링을 통해 알게 되었다. -
Prime() 메서드를 단 세줄로 작성했다는 점에서 성능이 8배 가까이 개선되었다.
Review
- 문제를 푼다고 끝내지 말고, 더 나은 성능 개선을 위해 깔끔하면서 좋은 코드를 구현하려고 노력하자.
Reference
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8