흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
2024년 1분기 회고
그동안 1년 단위로 회고를 진행해왔는데, 최근 3개월은 여러가지 활동들을 보내서 처음으로 분기별 회고를 작성해보려고 합니다.
-
[Hibit] Swagger에서 Spring Rest docs로 전환하기: 이유, 개념, 그리고 적용 가이드
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
이와 관련해서 코드에 대한 부분은 PR에 있습니다.
-
[글또 9기] 나만의 글쓰기 파이프라인
- 예상 독자: 저의 글쓰기 파이프라인 전/후를 궁금해하는 분
시작하며
글또 9기를 시작하고 4회차가 지난 이후에 글또의 운영진이신 성윤님께서 ‘글쓰기’ 라는 주제로 세미나를 해주셨어요.
해당 세미나에서 다룬 주로 내용은 다음과 같아요.
-
글쓰기가 어려운 이유
-
글쓰기의 핵심 요소
-
글을 쓰는 과정
-
글쓰기 전략
해당 세미나을 들으면서 지금까지 고수해왔던 저의 글쓰기 방식의 미흡한 부분과 개선점에 대해 고민해보게 되었습니다.
-
[Hibit] 히빗 V2 업그레이드: 백엔드 개선과 개발자 성장기
이 글은 제가 혼자서 개발한 히빗 (version 2) 에 대한 회고 글입니다. 이전 version 1과 비교하여 어떤 성장을 이루었고, 그 과정에서 어떤 깨달음을 얻었는지 작성했습니다.
시작하며
히빗 프로젝트 version1에 참가하게된 계기와 회고는 이전에 작성했던 ‘[2023년 회고] 다양한 활동으로 가득한 특별한 한 해’ 글에 있기 때문에, 생략했다.
이번 글은 히빗 프로젝트를 version2로 다시 진행하면서 개선했던 들을 하나씩 알아보고, 느낀점(아쉬운 점)을 작성해보고자 한다.
-
[우아한테크토크] 선착순 이벤트 서버 생존기! 47만 RPM에서 살아남다?!
선착순 이벤트 배너

- 역대급 이벤트
- 어떤 반응인지 커뮤니티를 참고
- 그 중에서 “배민 또 장애 나겠네..” 반응도 있었음
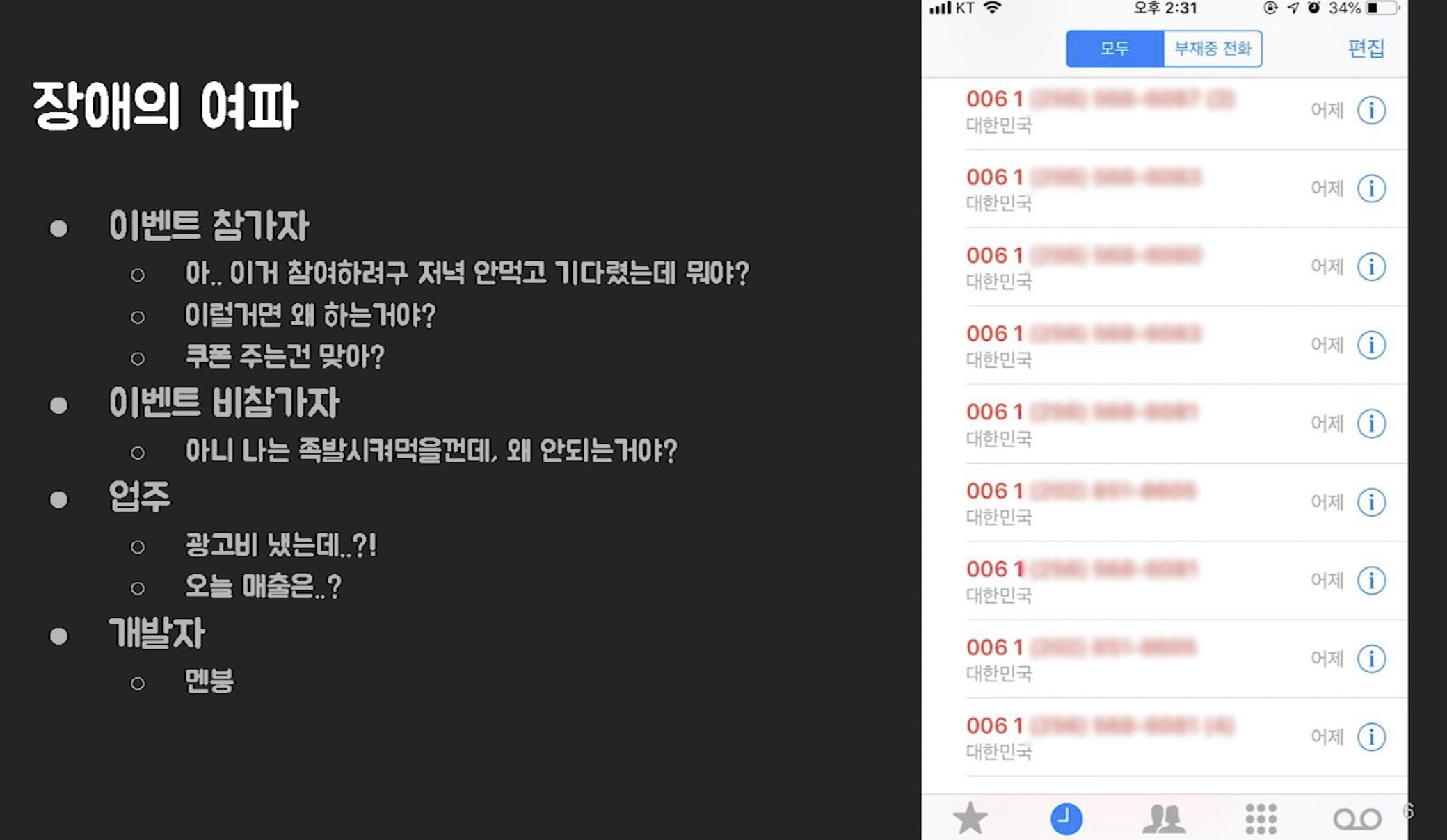
- 장애나는 날 전화가 폭주함

- 2가지 큰 목표를 잡음
- 개발 기간이 1~2주 → 빠르게 개발, 최대한 기존 로직은 건드리지 않고 새로운 시스템을 가지고 구성하려했음
Recent Posts
Categories
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8