흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[Hibit] 조회수 어뷰징 방지를 위한 쿠키 기반 로그 관리
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
해당 이슈에서 고민했던 주제입니다.
아래 부터는 ‘히빗 프로젝트(ver.2)’를
히빗2라고 줄여서 작성했습니다.
-
@EntityGraph 을 이용하여 조회 성능 개선하기
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
- 예상 독자:
@EntityGraph가 무엇이고 어떻게 적용해야할지 궁금한 개발자
문제 상황
현재, 특정 게시글 조회를 위한 API에 대한 성능 테스트를 진행하면서 다음 가정을 설정했다.
- 예상 독자:
-
[Hibit] 동시성으로 인한 데이터 정합성 문제를 쿼리를 통해 해결
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
-
예상 독자: 동시성 처리로 인한 데이터 정합성 문제를 해결하는 것에 대해 궁금한 개발자
-
히빗 (ver.1)에서 발생한 데이터 정합성 문제를 히빗2 (ver.2)를 통해 해결한 과정에 대해 정리했습니다.
-
-
[Hibit] JMeter를 활용한 성능 테스트 도입
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
-
예상 독자: 성능 테스트에 대한 도구와 설치 과정에 대해 궁금한 개발자
-
아래 글부터는 히빗 프로젝트(ver.2) 를
히빗2로 줄여서 작성했습니다.
-
-
성능 테스트, 부하 테스트, 스트레스 테스트란
성능 테스트
성능 테스트는 특정 상황에서 시스템의 구성 요소가 어떻게 수행되는지 확인하기 위해 수행되는 테스트이다. 또한 이 테스트를 통해 제품의 리소스 사용량, 확장성 및 신뢰성을 확인할 수 있다. 이 테스트는 소프트웨어 제품의 설계 및 아키텍처에서 성능 문제를 해결하는 데 중점을 둔 성능 엔지니어링의 하위 집합이다.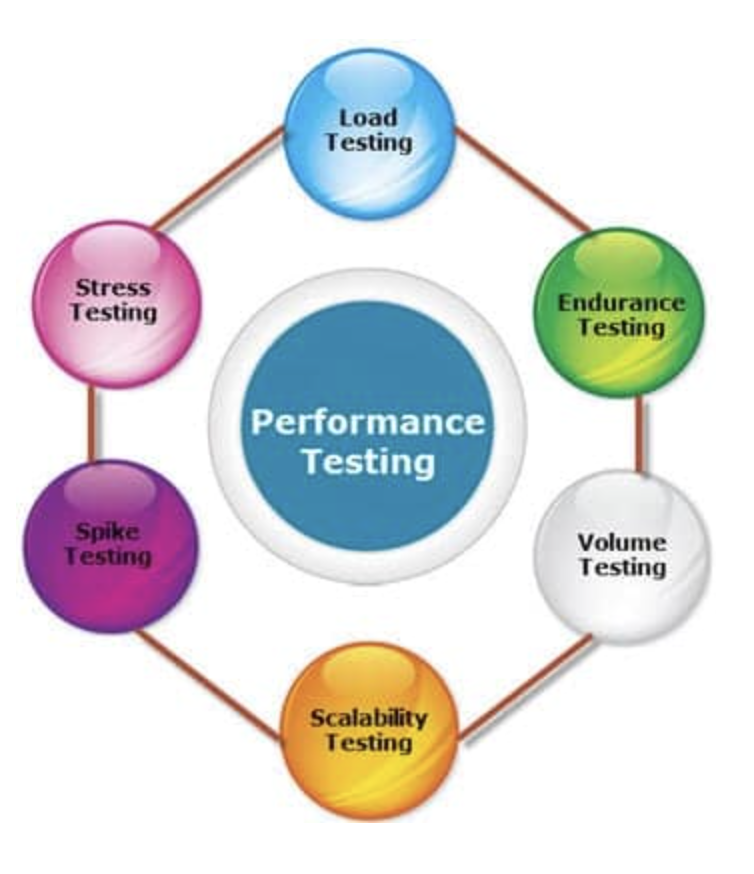
위의 이미지는 성능 테스트가 부하 및 스트레스 테스트 모두에 대한 상위 집합이라는 것을 명확하게 설명한다. 성능 테스트에 포함된 다른 유형의 테스트는 스파이크 테스트, 볼륨 테스트, 내구성 테스트 및 확장성 테스트가 있다. 따라서 성능 테스트는 기본적으로 광범위한 용어이다.
성능 테스트의
주요 목표에는 시스템의 벤치마크 동작을 설정하는 것이 포함된다. 성능 테스트는 애플리케이션의 결함을 찾는 것을 목표로 하지 않고, 애플리케이션의 벤치마크 및 표준을 설정하는 중요한 작업을 처리한다. 그래서 실제 트래픽 상황에서 정상적으로 동작되는지, 애플리케이션/시스템 성능에 대한 모니터링이 성능 테스트의 주요 특성을 의미한다.성능 테스트는 속도(speed), 응답 시간(response time), 처리량(throughput), 자원 사용량(resource usage), 안정성(stability) 등의 속성을 기준으로 애플리케이션의 벤치마크와 표준을 설정해야 하고, 이 모든 속성을 테스트한다.
성능 테스트는 다음과 같은 상황에서 주로 사용된다.
-
실제 트래픽 상황에서의 정상 동작
-
기존 시스템 대비 BenchMarking
-
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8