흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
알고리즘 수업 - 깊이 우선 탐색 1(DFS)
성능 요약
- 메모리: 92592 KB, 시간: 1076 ms
구분
- 그래프 이론, 그래프 탐색, 너비 우선 탐색, 깊이 우선 탐색
Answer Code(2023.11.29)
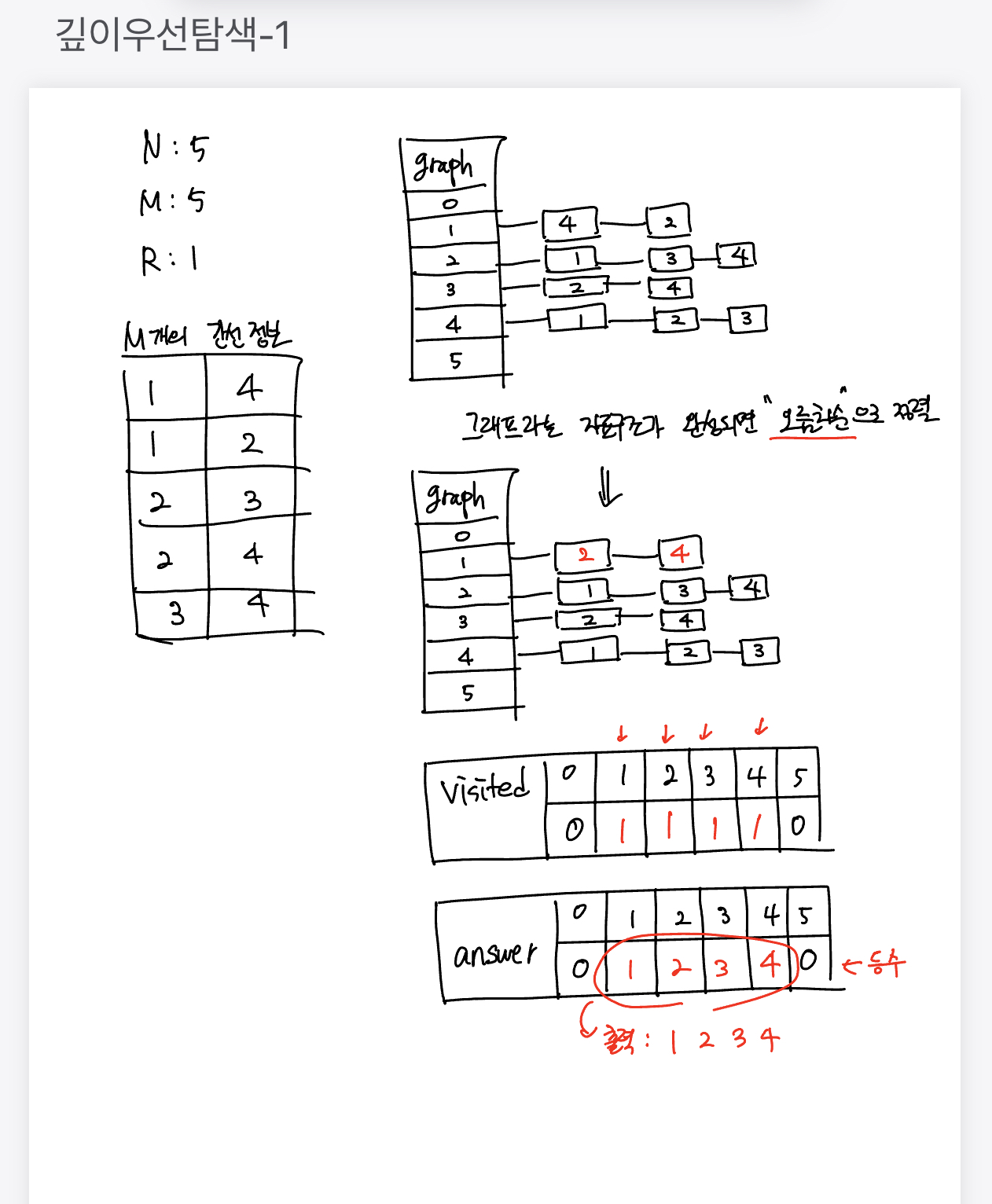
import java.util.*; import java.io.*; public class Main { static final int MAX = 100000 + 10; static ArrayList<Integer>[] graph; static boolean[] visited; static int N, M, R; // 정점(N)과 간선(M) static int[] answer; static int order; public static void dfs(int idx) { visited[idx] = true; answer[idx] = order; order++; for(int i = 0; i < graph[idx].size(); i++) { int next = graph[idx].get(i); if(visited[next] == false) { dfs(graph[idx].get(i)); } } } public static void main(String[] args) throws IOException{ // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); R = Integer.parseInt(st.nextToken()); // 1. graph에 연결 정보 채우기 graph = new ArrayList[MAX]; for(int i = 1; i <= N; i++) { graph[i] = new ArrayList<>(); } visited = new boolean[MAX]; answer = new int [MAX]; order = 1; for(int i = 0; i < M; i++) { st = new StringTokenizer(br.readLine()); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); graph[x].add(y); graph[y].add(x); } // 2. 오름차순 정렬 for(int i = 1; i <= N; i++) { Collections.sort(graph[i]); } // 3. dfs(재귀함수 호출) dfs(R); // 4. 출력 for(int i = 1; i <= N; i++) { bw.write(String.valueOf(answer[i])); bw.newLine(); } bw.close(); br.close(); } }문제풀이
Step0. 입력 및 초기화
public class Main { static final int MAX = 100000 + 10; static ArrayList<Integer>[] graph; static boolean[] visited; static int N, M, R; // 정점(N)과 간선(M) static int[] answer; static int order; public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); R = Integer.parseInt(st.nextToken()); } }-
N의 최대값이 10만이므로, 2차원 배열로 쓰기에는 저장하기에 크기가 너무 커진다.
-
그래서 필요할 때마다 쓰는, 동적 할당을 가능하게 해주는
ArrayList을 사용한다.-
어떤
특정 노드를 기준으로 봤을 때, 나랑 연결되어 있는 노드가 누가 있는지 는 이전에 배열로 썼던 것과 동일하다. -
다만,
ArrayList로 만들었기 때문에 M개의 간선 정보에 맞춰서 그때그때마다 하나씩 노드를 추가해가는 구조이다.
-
-
answer를 하나의 배열 형태로 만들어준 이유는 각각의 노드가 몇번째로 방문했는지 기록하고, 그것을 오름차순으로 출력하기 위해서이다. -
visited는 이전 바이러스, 연결 요소의 개수 문제와 동일하게, 특정 노드를 방문했는지를 기록하기 위해 boolean 타입의 배열인 자료구조를 사용했다.
Step1. graph에 연결 정보 채우기
public class Main { static final int MAX = 100000 + 10; static ArrayList<Integer>[] graph; static boolean[] visited; static int N, M, R; // 정점(N)과 간선(M) static int[] answer; static int order; public static void main(String[] args) throws IOException { // 1. graph에 연결 정보 채우기 graph = new ArrayList[MAX]; for (int i = 1; i <= N; i++) { graph[i] = new ArrayList<>(); } visited = new boolean[MAX]; answer = new int[MAX]; order = 1; for(int i = 0; i < M; i++) { st = new StringTokenizer(br.readLine()); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); graph[x].add(y); graph[y].add(x); } } }-
graph[x].add(y)는 x번째 ArrayList 에서 y라는 값을 추가하겠다는 의미이다.반대 역시 마찬가지로,
graph[y].add(x)은 y번째 ArrayList 에서 x라는 값을 추가하겠다는 의미이다.
Step2. dfs(재귀함수 호출)
public class Main { static final int MAX = 100000 + 10; static ArrayList<Integer>[] graph; static boolean[] visited; static int N, M, R; // 정점(N)과 간선(M) static int[] answer; static int order; public static void dfs(int idx) { visited[idx] = true; answer[idx] = order; order++; for (int i = 0; i < graph[idx].size(); i++) { int next = graph[idx].get(i); if (visited[next] == false) { dfs(graph[idx].get(i)); } } } public static void main(String[] args) throws IOException { // 2. 오름차순 정렬 for(int i = 1; i <= N; i++) { Collections.sort(graph[i]); } // 3. dfs(재귀함수 호출) dfs(R); } }-
여기서
order라는 변수는 내가 지금 몇번째인지 순서를 담고 있는 변수이고, 순서를answer라는 배열에 해당하는 인덱스 번째에 담는 것이다.그런 다음에, 1등, 2등, 3등 처럼 순서대로 담길 수 있도록
order에 +1을 증가시켜준다. -
for(int i = 0; i < graph[idx].size(); i++)은 인덱스번째의 노드랑 연결되어 있는 애들이 이 그래프의 인덱스번째의 ArrayList에 담겨져 있으므로 이 ArrayList를 하나씩 뒤져보겠다는 의미이다.예를 들어, 1번째 노드와 연결되어 있는 게 2,4라면 -> 2번 만큼 반복문을 돌리는 것이다.
그리고
dfs(graph[idx].get(i))은 인덱스와 연결되어 있는 i번째 노드를 가져와서, i를 기준으로 DFS를 태우겠다는 의미이다.그런데 조건 없이 불러오면, 무한 루프에 빠질 수 있기 때문에 위에 조건문
if(visited[next] == false)추가해준다.해당 조건문의 의미는 인덱스를 기준으로 i번째 연결되어 있는 요소를
next라는 int형 변수에 담고, 다음 방문하려는 하는 곳이 방문할 기록이 없다면 DFS를 태우겠다는 것이다.
정리
해당 문제를 풀면서, 아래의 순서에 맞게 생각하고 구현하면 풀 수 있는 문제였다.
-
DFS, 정점, 간선, 무방향 그래프 -> DFS/BFS
-
서로 연결되었다는 정보를 어떻게 하나의 자료구조로 통합할까? -> 2차원 배열 vs ArrayList -> 범위가 크기 때문에
ArrayList를 사용했다. -
이미 방문한 지점을 다시 방문하지 않으려면 어떤 자료구조를 사용해야 될까?
-
어떻게 오름차순으로 방문할 수 있을까?
-
방문 순서를 담기 위해서는 어떤 자료구조를 사용해야 될까?
Review
-
이전 DFS 유형인
연결 요소의 개수문제와 다른 점은 크게 2가지 였다.-
시작점이 주어진 것(R)이고,
-
N이라는 값이 10만개까지 들어오기 때문에 단순히 2차원 배열로 쓸 수 없어서, 동적 할당을 가능하게 해주는
ArryList를 사용했다.
-
-
해당 문제에서 요구했던 건 몇 개를 방문했냐라는 하나의 정수값이 아니라 각각의 노드를 몇 번째로 방문했는지 그걸 알고 싶었기 때문에 이번에는 배열이라는 자료구조를 써야 됐다.
-
[solved.ac] Class3++ 2606. 바이러스 (DFS)
성능 요약
- 메모리: 14236 KB, 시간: 120 ms
구분
- 그래프 이론, 그래프 탐색, 너비 우선 탐색, 깊이 우선 탐색
Answer Code(2023.11.28)
```java import java.util.; import java.io.;
-
[solved.ac] Class3++ 11724. 연결 요소의 개수(DFS)
성능 요약
- 메모리: 113376 KB, 시간: 552 ms
구분
- 그래프 이론, 그래프 탐색, 너비 우선 탐색, 깊이 우선 탐색
Answer Code(2023.11.28)
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.util.StringTokenizer; import java.io.*; class Main { final static int MAX = 1000 + 10; static boolean[][] graph; static boolean[] visited; static int N, M; static int answer; static void dfs(int idx) { visited[idx] = true; for(int i = 1; i <= N; i++) { if(visited[i] == false && graph[idx][i]) { dfs(i); } } } public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); // 1. graph에 연결 정보 채우기 graph = new boolean[MAX][MAX]; visited = new boolean[MAX]; int u, v; for(int i = 0; i < M; i++) { st = new StringTokenizer(br.readLine()); u = Integer.parseInt(st.nextToken()); v = Integer.parseInt(st.nextToken()); graph[u][v] = true; graph[v][u] = true; } // 2. dfs(재귀함수 호출) - visited가 모두 true일때까지 방문한다. for(int i = 1; i <= N; i++) { if(visited[i] == false) { dfs(i); answer++; } } // 3. 출력 bw.write(String.valueOf(answer)); bw.close(); br.close(); } }문제풀이
- 아이디어: ‘연결 요소의 개수를 구하는 프로그램’에서
연결되어 있다는 것을 그래프에서 탐색하는 방법으로 풀어야 겠다 -> DFS 사용하자.
Step0. 입력 및 초기화
class Main { static final int MAX = 1000 + 10; static boolean[][] graph; static boolean[] visited; static int N, M; static int answer; public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); ... } }-
이전 바이러스 문제와 거의 비슷하기 때문에, 비슷한 부분들에 대한 문제풀이는 생략했다.
-
N과 M개의 범위를 볼 때, 최대 1000개라고 되어 있어서,
MAX라는 변수를 선언했고, 1000 + 10개로 초기화했다.-
static + final= “고정된 + 최종적인”의 의미로, 모든 영역에서 고정된 값으로 상수를 선언하고자 할 때 사용한다. => 불변의 값을 가진다. -
MAX라는 상수를 graph와 visited를 만들기 위해서 사용할텐데, 넉넉하게10개를 추가했다. -
Tip : 문제를 풀면서 발생하는 시간 낭비와 예외 처리를 한 번에 끝낼 수 있기 때문에, 넉넉하게
10개를 추가하자.
-
-
그리고 입력 부분에서 첫번째 줄에 N, M을 띄어쓰기를 기준으로 구분하기 때문에
StringTokenizer.nextToken을 이용하여 값을 저장한다.
Step1. graph에 연결 정보 채우기
class Main { final static int MAX = 1000 + 10; static boolean[][] graph; static boolean[] visited; static int N, M; static int answer; public static void main(String[] args) throws IOException { ... // 1. graph에 연결 정보 채우기 graph = new boolean[MAX][MAX]; visited = new boolean[MAX]; int u, v; for(int i = 0; i < M; i++) { st = new StringTokenizer(br.readLine()); u = Integer.parseInt(st.nextToken()); v = Integer.parseInt(st.nextToken()); graph[u][v] = true; graph[v][u] = true; } ... } }-
위에서 말했던
MAX라는 상수를 배열 크기로 graph와 visited를 선언한다. -
그런 다음, M번만큼 반복문을 돌려서 간선의 양 끝점인 u와 v가 연결된 부분은
true로 바꿔준다.
Step2. dfs(재귀함수 호출)
- 바이러스 문제와 다른 점은, 이 문제는 모든 요소를 방문할 때까지 반복하는 문제이므로, 반복문을 선언해줘야 한다.
class Main { ... static void dfs(int idx) { visited[idx] = true; for(int i = 1; i <= N; i++) { if(visited[i] == false && graph[idx][i]) { dfs(i); } } } public static void main(String[] args) throws IOException { ... // 2. dfs(재귀함수 호출) - visited가 모두 true일때까지 방문한다. for(int i = 1; i <= N; i++) { if(visited[i] == false) { dfs(i); answer++; } } ... } }-
1번부터 N번까지 모든 정점을 방문하기 때문에 1부터 N까지 반복하는 것이고, 한번도 방문하지 않았을 경우에만 dfs를 호출한다.
-
dfs 함수에서는 N번만큼 반복문을 돌려서,
한번도 방문하지 않은 경우 && idx 번호와 i번호가 연결된 경우에만 dfs를 호출하도록 한다. -
해당 예제 1번에서, 아래와 같이 입력 값을 받을 경우
6 5 1 2 2 5 5 1 3 4 4 6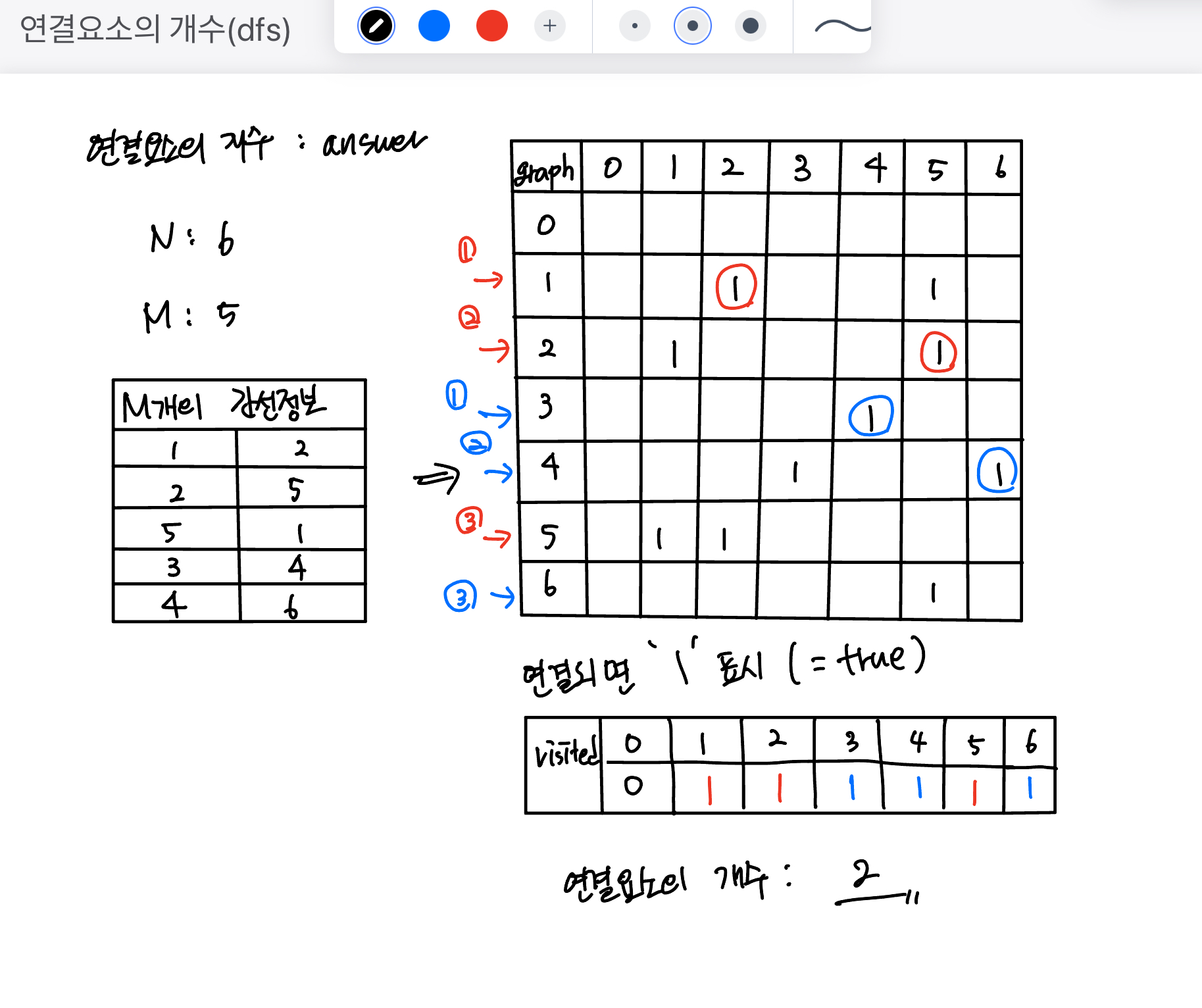
-
처음에는 1,2,5에서 끝나기 때문에 여기서 연결 요소의 개수가 +1 증가하고
두번째에는 3,4,6에서 끝나기 때문에 여기서 연결 요소의 개수가 +1 증가하게 된다.
-
그래서 dfs가 끝난 뒤에 +1 증가하므로 dfs 뒤에
answer++를 해주는 것이다.
Step3. 출력하기
class Main { ... public static void main(String[] args) throws IOException { // 3. 출력 bw.write(String.valueOf(answer)); bw.close(); br.close(); } }-
출력하기는 연결 요소의 개수, 즉
answer값을 출력하므로bw.write(String.valueOf(answer));을 작성한다.여기서
BufferedWriter를 통해 String으로 전달해줘야 하므로String.valueOf()함수를 안에 넣은 것이다. -
그리고
BufferedReader,BufferedWriter모두 버퍼를 잡아 놓았기 때문에 반드시 flush() 또는 close()를 호출해서 뒤처리를 해줘야한다.flush()는 스트림을 비우는 함수이고,close()는 스트림을 닫는 함수이다.만약 한번 출력후, 다른 것도 출력하고자 한다면
flush()를 사용하면 된다.
Review
-
해당 문제는 이전 바이러스 문제와 비슷해서, 조금더 빠르게 풀 수 있었다.
-
문제를 풀면서, 입출력에 대한 여러 함수를 배울 수 있어서 좋았다.
-
[Programmers] 후보키 (2019 카카오 블라인드)
성능 요약
- 메모리: 70.4 MB, 시간: 3.66 ms
구분
- 코딩테스트 연습 > 2019 KAKAO BLIND RECRUITMENT
문제풀이
먼저, 주어진 데이터베이스의 릴레이션에서 후보키의 개수를 찾는 문제입니다.
주어진 String 타입의 2차원 배열 relation에서 후보키의 개수를 찾아 반환합니다.
코드는 재귀적인 방식인 깊이 우선 탐색(DFS)을 사용하여 후보키를 찾습니다.
먼저, 주어진 데이터베이스의 릴레이션에서 후보키의 개수를 찾는 문제입니다. 주어진
String타입의 2차원 배열relation에서 후보키의 개수를 찾아 반환합니다. 코드는 재귀적인 방식인 깊이 우선 탐색(DFS)을 사용하여 후보키를 찾습니다.- 전역 변수 및 메서드:
List<String> candi: 후보키를 저장하는 리스트입니다.dfs메서드: 깊이 우선 탐색을 수행하는 메서드로, 후보키를 찾기 위해 가능한 모든 조합을 탐색합니다.
이 부분은
dfs메서드로, 깊이 우선 탐색(Depth-First Search)을 수행하여 후보키를 찾아내는 역할을 합니다. 코드를 한 부분씩 살펴보겠습니다.-
깊이가 목표 깊이에 도달했을 때:
if (depth == end) { // ... }depth가end와 같아지면, 즉, 조합이 완성된 경우입니다.- 조합을 확인하고 유일성을 검사하는 부분입니다.
-
조합 확인 및 유일성 검사:
List<Integer> list = new ArrayList<>(); String key = ""; for (int i = 0; i < visited.length; i++) { if (visited[i]) { key += String.valueOf(i); list.add(i); } }- 선택된 열의 인덱스를
list에 저장하고,key에는 해당 인덱스를 문자열로 연결합니다.
- 선택된 열의 인덱스를
-
중복 체크를 위한 Map 생성 및 유일성 검사:
Map<String, Integer> map = new HashMap<>(); for (int i = 0; i < relation.length; i++) { String s = ""; for (Integer j : list) { s += relation[i][j]; } if (map.containsKey(s)) { return; } else { map.put(s, 0); } }- 조합을 이용하여 만들어진 문자열
s를 이용해map에 저장하여 유일성을 체크합니다. - 이미 존재하는 경우(
map.containsKey(s)), 중복된 튜플이므로 함수를 종료합니다.
- 조합을 이용하여 만들어진 문자열
-
최소성 검사 및 후보키 추가:
for (String s : candi) { int count = 0; for(int i = 0; i < key.length(); i++){ String subS = String.valueOf(key.charAt(i)); if(s.contains(subS)) count++; } if (count == s.length()) return; }- 현재 후보키(
key)가 이미 저장된 후보키들 중에서 어떤 것에도 속하지 않는지를 확인합니다. count를 통해 일치하는 문자열의 개수를 셉니다.- 만약
count가 현재 후보키의 길이와 같다면, 현재 후보키는 이미 저장된 후보키의 일부이므로 함수를 종료합니다. - 그렇지 않으면,
candi리스트에 후보키를 추가합니다.
- 현재 후보키(
-
재귀 호출을 통한 깊이 우선 탐색:
for (int i = start; i < visited.length; i++) { if (visited[i]) continue; visited[i] = true; dfs(visited, i, depth + 1, end, relation); visited[i] = false; }- 재귀 호출을 통해 깊이 우선 탐색을 수행합니다.
- 현재 선택한 열을 방문 표시하고, 깊이를 증가시켜 재귀 호출을 합니다.
- 재귀 호출이 끝나면 방문 표시를 해제하여 이전 상태로 돌아갑니다.
이렇게 하면
dfs메서드는 주어진 릴레이션에서 모든 가능한 후보키를 찾아내는 역할을 합니다.Answer Code(23.11.27)
import java.util.*; class Solution { List<String> candi = new ArrayList<>(); public int solution(String[][] relation) { int answer = 0; for (int i = 0; i < relation[0].length; i++) { boolean[] visited = new boolean[relation[0].length]; dfs(visited, 0, 0, i + 1, relation); } answer = candi.size(); return answer; } public void dfs(boolean[] visited, int start, int depth, int end, String[][] relation) { if (depth == end) { List<Integer> list = new ArrayList<>(); String key = ""; for (int i = 0; i < visited.length; i++) { if (visited[i]) { key += String.valueOf(i); list.add(i); } } Map<String, Integer> map = new HashMap<>(); for (int i = 0; i < relation.length; i++) { String s = ""; for (Integer j : list) { s += relation[i][j]; } if (map.containsKey(s)) { return; } else { map.put(s, 0); } } // 후보키 추가 for (String s : candi) { int count = 0; for(int i = 0; i < key.length(); i++){ String subS = String.valueOf(key.charAt(i)); if(s.contains(subS)) count++; } if (count == s.length()) return; } candi.add(key); return; } for (int i = start; i < visited.length; i++) { if (visited[i]) continue; visited[i] = true; dfs(visited, i, depth + 1, end, relation); visited[i] = false; } } }Reference
- https://tmdrl5779.tistory.com/219)
-
[Programmers] [1차] 프렌즈4블록(2018 카카오 블라인드)
성능 요약
- 메모리: 72.6 MB, 시간: 3.40 ms
구분
- 코딩테스트 연습 > 2018 KAKAO BLIND RECRUITMENT
Answer Code(23.11.27)
import java.util.*; class Solution { static boolean v[][]; // 체크 배열 public int solution(int m, int n, String[] board) { int answer = 0; char copy [][] = new char[m][n]; for(int i = 0; i < m; i++) { copy[i] = board[i].toCharArray(); } boolean flag = true; while(flag) { v = new boolean[m][n]; flag = false; for(int i = 0; i < m-1; i++) { for(int j = 0; j < n-1; j++) { if(copy[i][j] == '#') continue; // #은 빈칸을 의미 if(check(i, j, copy)) { v[i][j] = true; v[i][j+1] = true; v[i+1][j] = true; v[i+1][j+1] = true; flag = true; } } } answer += erase(m,n,copy); v = new boolean[m][n]; } return answer; } /* 2*2가 같은지 체크 */ public static boolean check(int x, int y, char[][] board) { char ch = board[x][y]; if(ch == board[x][y+1] && ch ==board[x+1][y] && ch == board[x+1][y+1]) { return true; } return false; } public static int erase(int m, int n, char [][] board) { int cnt = 0; for(int i = 0; i < m; i++) { for(int j = 0; j < n; j++) { if(v[i][j]) { board[i][j] = '.'; } } } /* 큐를 이용해 세로로 제거 작업 진행 */ for(int i = 0; i < n; i++) { Queue<Character> q = new LinkedList<>(); for(int j = m-1; j >=0; j--) { if(board[j][i] == '.') { cnt++; // 지우는 블록 카운트 } else { q.add(board[j][i]); } } int idx = m-1; // 삭제한 블록 위의 블록들 내리기 while(!q.isEmpty()) { board[idx--][i] = q.poll(); } // 빈칸 채우기 for(int j = idx; j >=0; j--) { board[j][i] = '#'; } } return cnt; } }문제풀이
시뮬레이션 유형으로 특정 규칙에 따라 블록이 지워지고 이동하는 과정을 반복하며 최종적으로 몇 개의 블록이 지워지는지를 구하는 것이 목표다.-
문제에서는 다음과 같은 매개변수가 주어지고, 2가지를 기준으로 코드를 작성하면 된다.
-
판의 높이 = m
-
폭 = n
-
판의 배치 정보 = board
-
-
2*2블록이 같은지 체크하는 함수
-
현재 블록을 기준으로 오른쪽, 아래, 오른쪽 아래가 같은지 체크하면 된다.
-
이때 조심할 것은 배열의 범위를 벗어나지 않도록 해야 한다.
-
만약 2*2 블록이 같다면 이를 기록할 boolean[][] 배열에 따로 표시를 한다.
-
직접적으로 board 배열을 바꾸지 않는 이유는 모든 블록을 조사한 후에 일괄적으로 처리해야 하기 때문이다.
-
-
블록을 제거하는 함수
-
큐를 이용해 세로로 블록을 제거하는 방법을 사용했다. -
맨 아래에서부터 큐에 집어넣고, 제거해야 하는 블록이라면 개수만 세고 큐에 넣지 않는다.
-
이후에 큐에 있는 원소를들 빼내서 아래부터 차곡차곡 블록을 쌓아준다.
-
빈 블록은 ‘#’으로 표시해준다.
-
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8