흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[백준] 13565. 침투
성능 요약
- 메모리: 53320 KB, 시간: 1356 ms
- 메모리: 54268 KB, 시간: 696 ms
구분
- 그래프 이론, 그래프 탐색, 트리, 너비 우선 탐색, 깊이 우선 탐색
Answer Code1(23.12.04)
// 침투 (백준 13565) import java.util.*; import java.io.*; class Penetrate { static final int MAX = 1000 + 10; static boolean[][] map; static boolean[][] visited; static int M, N; static int dirX[] = {-1, 1, 0, 0}; static int dirY[] = {0, 0, -1, 1}; static boolean answer; public static void dfs(int y, int x) { if(y == N) { answer = true; return; } visited[y][x] = true; for(int i = 0; i < 4; i++) { int newX = x + dirX[i]; int newY = y + dirY[i]; if(map[newY][newX] && visited[newY][newX] == false) dfs(newY, newX); } } public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); // 1. map에 정보 반영하기 map = new boolean[MAX][MAX]; visited = new boolean[MAX][MAX]; for(int i = 1; i <= N; i++) { String str = br.readLine(); for(int j = 1; j <= M; j++) map[i][j] = (str.charAt(j - 1) == '0' ? true : false); } // 2. dfs 수행 for(int j = 1; j <= M; j++) { if(map[1][j]) { dfs(1, j); } } // 3. 출력 if(answer) bw.write("YES"); else bw.write("NO"); bw.close(); br.close(); } }문제풀이
-
이 문제에서 DFS를 떠올릴 수 있는 키워드는 다음과 같다.
-
상하좌우로 인접한 흰색 격자들
-
안쪽까지 침두될 수 있는지 아닌지를 판단
-
-
문제에서는 전류가 흐르는 것을 ‘0’으로 해주고, 흐르지 않는 것을 ‘1’로 나와있는데, 이는 문제를 풀때 헷갈릴 수 있다.
그래서 전류가 흐르는 것을 ‘1’로 하고, 흐르지 않는 것을 ‘0’으로 해주기 위해 바꿔주는 로직을 구성한다.
이 문제에서 핵심은 내가 방문하고자 하는 곳을
1로 하는 것이 훨씬 더 유리하다. -
이 문제에서는 첫 번째 줄에서 시작해서 마지막에 도달할 수 있는지 판단하는 것이므로
dfs(1, j)라고 해준 것이다.
[1]. map에 정보 반영하기
- 이중 반복문을 통해 해당 위치에 해당하는 값이 0일 경우, ‘1’로 바꿔준다.
[2]. dfs 수행
-
처음 시작 위치가 1부터 시작하기 때문에
dfs(1, j)과 같이 표현한 것이고, -
M번 만큼 반복하면서 값이 true일 경우에 한해서만 dfs를 수행하기 때문에 for문 안에 조건문인
if(map[1][j])을 추가해준 것이다. -
dfs를 수행할 때, 상하좌우로 확인하므로 반복문
for(int i = 0; i < 4; i++)과 방향에 대한 dirX, dirY를 선언해줬다.그리고 상하좌우를 확인할 때, map에 해당하는 값이 true(1)이고, 방문한 적이 없을 경우에만 dfs를 다시 호출하도록 했다.
-
마지막으로 dfs 메서드 시작할 때,
if(y == N)을 한 이유는 안쪽까지 도달했는지 확인하기 위해서다.만약 안쪽까지 도달했다면, 즉 N번 줄에 도달했다면 침투를 했다는 의미이므로
answer값을 true로 바꿔주고 return 해주면 된다.
[3]. 출력
- 출력할 때는 answer가 true이면 YES를 출력하고, 그게 아니라면 NO를 출력해주면 된다.
visited 없이 map으로만 구현하기
아래는 visited 없이 map으로도 구현한 코드이다.
import java.util.*; import java.io.*; class Penetrate { static final int MAX = 1000 + 10; static boolean[][] map; static int M, N; static int dirX[] = {-1, 1, 0, 0}; static int dirY[] = {0, 0, -1, 1}; static boolean answer; public static void dfs(int y, int x) { if(y == N) { answer = true; return; } map[y][x] = false; for(int i = 0; i < 4; i++) { int newX = x + dirX[i]; int newY = y + dirY[i]; if(map[newY][newX]) dfs(newY, newX); } } public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); map = new boolean[MAX][MAX]; // 1. map에 정보 반영하기 for(int i = 1; i <= N; i++) { String str = br.readLine(); for(int j = 1; j <= M; j++) { map[i][j] = (str.charAt(j - 1) == '0' ? true : false); } } // 2. dfs 수행 for(int j = 1; j <= M; j++) { if(map[1][j]) dfs(1, j); } // 3. 출력 if(answer) bw.write("YES"); else bw.write("NO"); bw.close(); br.close(); } }Answer Code2(24.01.16)
package DFS; // 24.01.16 침투 복습 import java.util.*; import java.io.*; class Penetrate_2 { static final int MAX = 1000 + 10; static boolean[][] map; static int N, M; static boolean answer; static int[] dirX = {-1, 1, 0, 0}; static int[] dirY = {0, 0, -1, 1}; public static void dfs(int x, int y) { if(x == N) { answer = true; return; } map[x][y] = false; for(int i = 0; i < 4; i++) { int newX = x + dirX[i]; int newY = y + dirY[i]; if(map[newX][newY]) { dfs(newX, newY); } } } public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); // 1. map에 정보반영 map = new boolean[MAX][MAX]; for(int i = 1; i <= N; i++) { String str = br.readLine(); for(int j = 1; j <= M; j++) { map[i][j] = (str.charAt(j - 1) == '0' ? true : false); } } // 2. bfs 호출 for(int j = 1; j <= M; j++) { if(map[1][j]) { dfs(1, j); } } // 3. 출력 if(answer) bw.write("YES"); else bw.write("NO"); bw.close(); br.close(); } }정리
문제를 풀기 시작하기 전에, 아래 5가지를 생각해보면서 접근해보자.
-
상하좌우로 인접한 흰색 격자들로 전달 -> DFS/BFS
-
서로 연결되었다는 정보를 어떻게 하나의 자료구조로 통합할까? -> 2차원 배열
-
이미 방문한 지점을 다시 방문하지 않으려면 어떤 자료구조를 사용해야 할까?
-
visited 배열을 생략할 수는 없을까?
-
어느 지점에서 dfs를 시작할까?
Review
-
visited 없이 map으로만 할 경우
처리 시간이 1892(ms) -> 1356(ms) 줄었다는 걸 확인할 수 있다. -
그래도 이해를 위해 우선 visited 변수를 사용해서 풀어보고, 완전히 dfs를 이해했다면 이후에는 visited 없이도 바로 생각할 수 있도록 하자.
-
[백준] 11725. 트리의 부모찾기
성능 요약
- 71236 KB, 시간: 596 ms
구분
- 그래프 이론, 그래프 탐색, 트리, 너비 우선 탐색, 깊이 우선 탐색
Answer Code
import java.util.*; import java.io.*; class TreeParentSearch { static final int MAX = 100000 + 10; static ArrayList<Integer>[] graph; static boolean[] visited; static int N; static int[] answer; public static void dfs(int idx) { visited[idx] = true; for(int i = 0; i < graph[idx].size(); i++) { int next = graph[idx].get(i); if(visited[next] == false) { answer[next] = idx; dfs(next); } } } public static void main(String[] args) throws IOException{ // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); N = Integer.parseInt(br.readLine()); graph = new ArrayList[MAX]; for(int i = 1; i <= N; i++) { graph[i] = new ArrayList<>(); } visited = new boolean[MAX]; answer = new int[MAX]; // 1. 연결 정보 채우기 int x, y; for(int i = 0; i < N-1; i++) { StringTokenizer st = new StringTokenizer(br.readLine()); x = Integer.parseInt(st.nextToken()); y = Integer.parseInt(st.nextToken()); graph[x].add(y); graph[y].add(x); } // 2. dfs(재귀 함수) 호출하기 dfs(1); // 3. 출력 for(int i = 2; i <= N; i++) { bw.write(String.valueOf(answer[i])); bw.newLine(); } bw.close(); br.close(); } }문제풀이
-
‘각 노드의 부모를 구하라’ => 다른 말로 **연결되어 있는 상태에서 각 노드의 상위 노드가 누구인지 찾는 문제였다.
-
그리고 트리의 루트를
1이라고 문제에서 주어졌기 때문에, 최상단 노드는1부터 시작한다는 의미이다. =>dfs(1);
class TreeParentSearch { public static void dfs(int idx) { visited[idx] = true; for (int i = 0; i < graph[idx].size(); i++) { int next = graph[idx].get(i); if (visited[next] == false) { answer[next] = idx; dfs(next); } } } }-
우선 해당 노드를 방문했기 때문에,
visited[idx] = true;를 해준다. -
그런 다음,
graph[idx].size();만큼 반복문을 돌리는 것인데,해석하자면,
ArrayList<Integer>[]형인 graph에서 해당 index에 있는 size만큼 반복문을 돌리는 것이다.예를 들어, 첫번째 예시에서 연결된 두 정점을 통해 1이 연결된 값이 4와 6이라면, 1에 해당하는 size, 즉
graph[1].size()는 2개를 의미한다. -
그리고
next = graph[idx].get(i);을 해석하자면,문제에서 연결된 두 정점을 바탕으로 ArrayList를 그려보면,
graph[1].get(0);= 6이라는 값이next변수에 넣어주게 된다.그런 다음, 아직 방문하지 않았다면, dfs(재귀 함수)를 호출한다.
이때, dfs(재귀 함수)를 호출하기 이전에, 부모 노드인 값(idx)을
answer라는 변수에 담아준다.예를 들어, 1번째 인덱스에서 6이라는 녀석에 dfs를 호출하는데, 6의 부모 노드의 값이 1이므로
answer[6] = 1과 같이answer라는 변수에 담아준다.그리고
dfs(6)을 호출한다.
Review
- 해당 문제를 아래와 같이, 그림을 그리면서 푸니까 확실히 이해가 되면서 정답을 맞출 수 있었다.
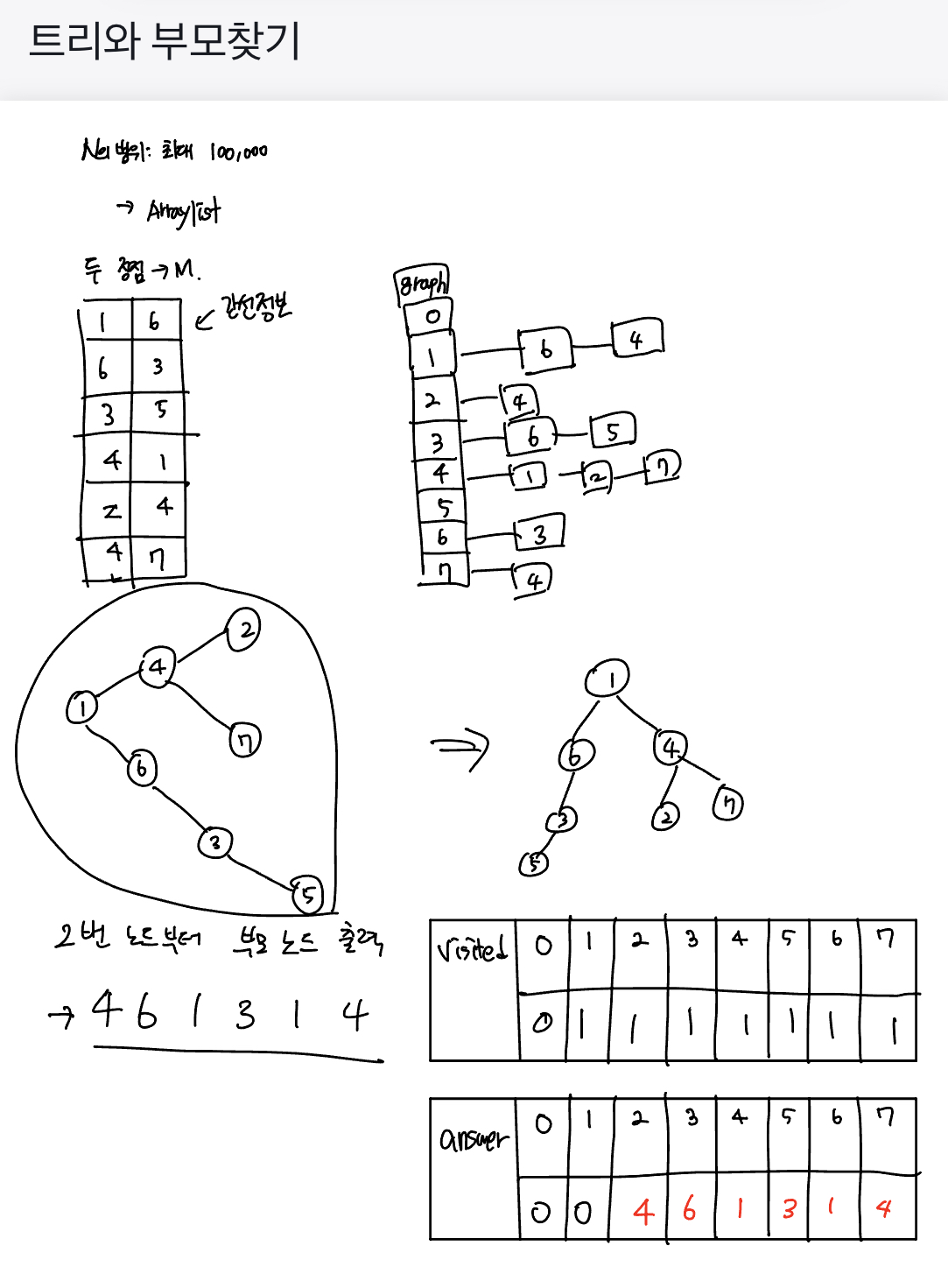
-
매번 이러한 유형의 문제를 접할때 마다
그래프라는 자료구조를 어떻게 잡아야 할지,그리고 재방문은 어떻게 방지할지,
마지막으로 정답은 어떤 자료구조에 담아야 잘 출력할지 고민하는 연습을 계속하자.
-
트리/각 노드의 부모를 찾아라 => DFS/BFS
문제에서 주어진
N이라는 값이 크면ArrayList를 이용하자.
-
[solved.ac] Class3++ 1260. DFS와 BFS
성능 요약
- 메모리: 24156 KB, 시간: 368 ms
구분
- 그래프 이론(graphs), 그래프 탐색(graph_traversal), 너비 우선 탐색(bfs), 깊이 우선 탐색(dfs)
Answer Code1(2023.02.09)
import java.io.*; import java.util.*; public class Main { static int [][] check; //간선 연결상태 static boolean [] checked; //확인 여부 static int n; //정점 개수 static int m; //간선 개수 static int start; // 시작정점 public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); StringTokenizer st = new StringTokenizer(br.readLine()); n = Integer.parseInt(st.nextToken()); m = Integer.parseInt(st.nextToken()); start = Integer.parseInt(st.nextToken()); check = new int[1001][1001]; // 좌표를 그대로 받아들이기 위해 +1 해서 선언 checked = new boolean[1001]; // 초기값 : false //간선 연결상태 저장 for(int i = 0; i < m; i++) { StringTokenizer str = new StringTokenizer(br.readLine()); int x = Integer.parseInt(str.nextToken()); int y = Integer.parseInt(str.nextToken()); check[x][y] = check[y][x] = 1; } //dfs 호출 dfs(start); checked = new boolean[1001]; // 확인상태 초기화 System.out.println(); // 줄바꿈 //bfs 호출 bfs(start); } //시작점을 변수로 받아 확인, 출력 후 다음 연결점을 찾아 시작점을 변경하여 재호출 public static void dfs(int start) { checked[start] = true; System.out.print(start + " "); for(int j = 1; j <= n; j++) { if(check[start][j] == 1 && checked[j] == false) { dfs(j); } } } public static void bfs(int start) { Queue<Integer> queue = new LinkedList<Integer>(); queue.offer(start); // 시작점도 Queue에 넣어야 함 checked[start] = true; System.out.print(start + " "); //Queue가 비어있을 때까지 반복. 방문 정점은 확인, 출력 후 Queue에 넣어 순서대로 확인 while(!queue.isEmpty()) { int temp = queue.poll(); for(int j = 1; j <= n; j++) { if(check[temp][j] == 1 && checked[j] == false) { queue.offer(j); checked[j] = true; System.out.print(j + " "); } } } } }Answer Code2(2023.11.30)
import java.util.*; import java.io.*; class Main { static final int MAX = 1000 + 10; static boolean[][] graph; static boolean[] visited; static ArrayList<Integer> queue; // bfs를 위해 만든 것 static int N, M, V; public static void dfs(int idx) { visited[idx] = true; System.out.print(idx + " "); // 몇 번째 노드를 방문했다. for(int i = 1; i <= N; i++) { if(visited[i] == false && graph[idx][i] == true) { dfs(i); } } } /* * bfs() 풀이 과정 * 1. queue를 만들고, visited를 새로 초기화해준다. * 2. 가장 첫 번째 시작 정점이라는 값(1)을 추가해주고, 그 값(1)을 방문했다라고 표기해준다. (처음 V 값이 1이므로) * 3. !queue.isEmpty() 때까지, 가장 앞에 있는 값을 꺼내오고, 출력해 준 다음에 그 값을 기준으로 방문할 수 있는 값들을 방문한다. * */ public static void bfs() { queue = new ArrayList<>(); visited = new boolean[MAX]; queue.add(V); visited[V] = true; while (!queue.isEmpty()) { int idx = queue.remove(0); // 가장 앞에 있는 녀석을 꺼내서 걔를 인덱스에 담겠다. System.out.print(idx + " "); for(int i = 1; i <= N; i++) { if(visited[i] == false && graph[idx][i] == true) { queue.add(i); visited[i] = true; } } } } public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); V = Integer.parseInt(st.nextToken()); graph = new boolean[MAX][MAX]; visited = new boolean[MAX]; // 1. graph에 연결 정보 채우기 for(int i = 0; i < M; i++) { st = new StringTokenizer(br.readLine()); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); graph[x][y] = true; graph[y][x] = true; } // 2. dfs(재귀 함수) 호출 + 출력하기 dfs(V); System.out.println(); // 3. bfs(너비 우선 탐색) 호출 + 출력하기 bfs(); // 4. 종료 br.close(); } }Review
23.02.15
-
해당 문제는 dfs, bfs 관련 문제를 처음 풀기 좋은 정석같은 문제였다.
-
입출력 부분에서
BufferedReader사용하는 방법을 처음 알게 되었다. 그동안 Scanner를 이용해서 풀었는데, 이번에는 다른 방식으로 풀면서 해당 개념에 대해 배워서 좋았다. -
dfs,bfs에 대해서는 관련 문제들을 풀면서 개념을 계속적으로 복습해 나가면서, 최종적으로는 머릿속으로도 문제를 풀 수 있는 실력을 갖추도록 하자.
23.11.15
-
bfs 문제를 풀 때는 queue 자료구조를 사용하고, 관련 메서드 함수들을 기억해두자.
-
만약 내림차순으로 방문한다라고 가정한다면, dfs 함수에서 for문을
for(int i = N; i >= 1; i--)로 수정해주면 된다. -> 가장 큰 값부터 가장 작은 값까지 방문한다.
Reference
-
[백준] 2644번. 촌수계산(DFS)
성능 요약
- 메모리: 14148 KB, 시간: 120 ms
구분
- 그래프 이론(graphs), 그래프 탐색(graph_traversal), 너비 우선 탐색(bfs), 깊이 우선 탐색(dfs)
Answer Code
```java import java.util.; import java.io.;
class Villages { static final int MAX = 100 + 10; static boolean[][] graph; static boolean visited[]; static int N, M, start, end, answer;
public static void dfs(int idx, int count) { visited[idx] = true; if(idx == end) { answer = count; return; } for(int i = 1; i <= N; i++) { if(visited[i] == false && graph[idx][i]) { dfs(i, count + 1); } } } public static void main(String args[]) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); N = Integer.parseInt(br.readLine()); StringTokenizer st = new StringTokenizer(br.readLine()); start = Integer.parseInt(st.nextToken()); end = Integer.parseInt(st.nextToken()); M = Integer.parseInt(br.readLine()); // 1. graph에 연결 정보 채우기 graph = new boolean[MAX][MAX]; visited = new boolean[MAX]; answer = -1;
-
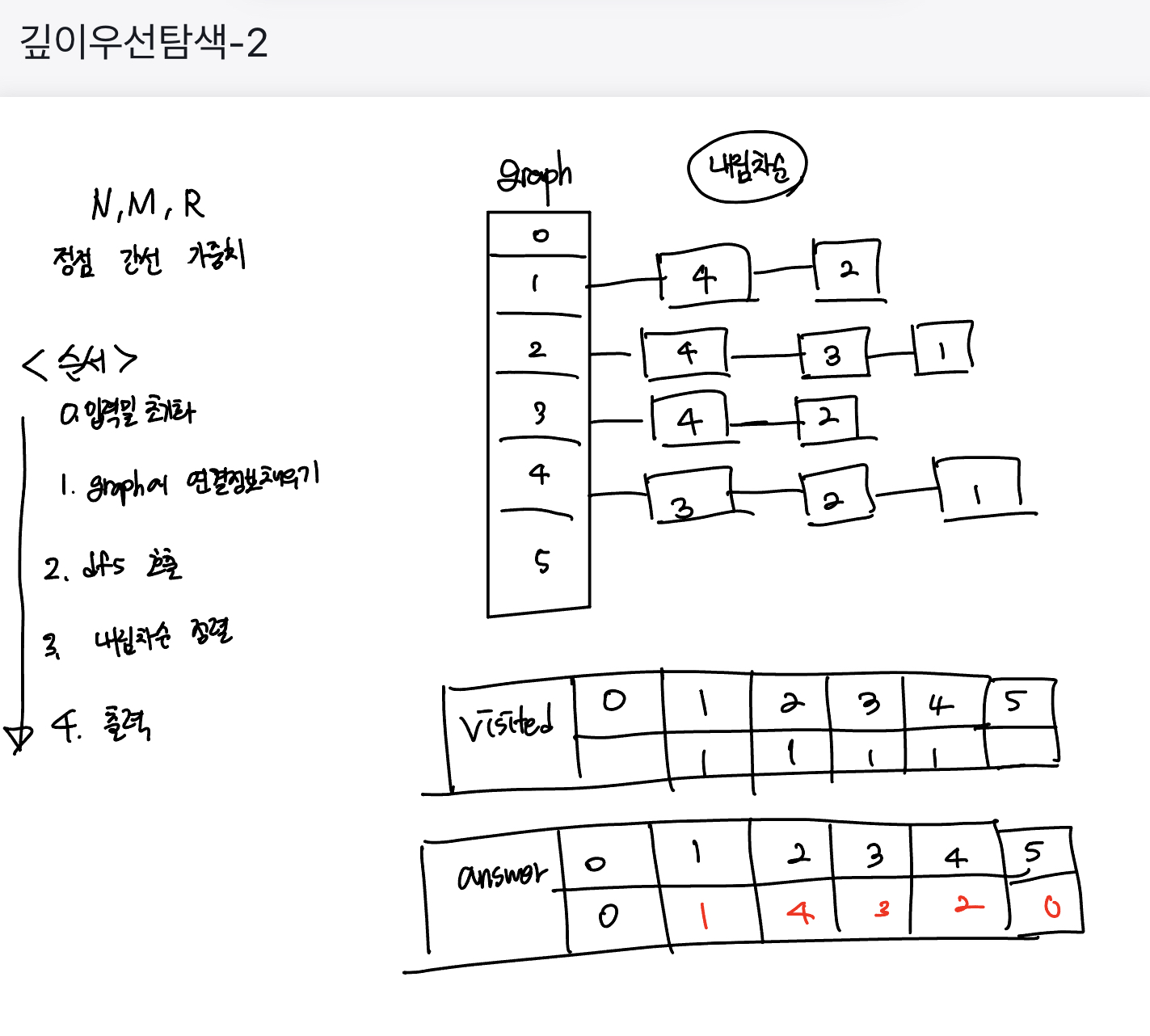
알고리즘 수업 - 깊이 우선 탐색 2(DFS)
성능 요약
- 메모리: 93168 KB, 시간: 1104 ms
구분
- 그래프 이론, 그래프 탐색, 너비 우선 탐색, 깊이 우선 탐색
Answer Code(2023.11.30)
import java.util.*; import java.io.*; public class DFS_2 { static final int MAX = 100000 + 10; static ArrayList<Integer>[] graph; static boolean[] visited; static int N, M, R; static int[] answer; static int order; public static void dfs(int idx) { visited[idx] = true; answer[idx] = order; order++; for(int i = 0; i < graph[idx].size(); i++) { int next = graph[idx].get(i); if(visited[next] == false) { dfs(next); } } } public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); StringTokenizer st = new StringTokenizer(br.readLine()); N = Integer.parseInt(st.nextToken()); M = Integer.parseInt(st.nextToken()); R = Integer.parseInt(st.nextToken()); // 1. graph에 연결 정보 채우기 graph = new ArrayList[MAX]; for(int i = 1; i <= N; i++) { graph[i] = new ArrayList<>(); } visited = new boolean[MAX]; answer = new int[MAX]; order = 1; for(int i = 0; i < M; i++) { st = new StringTokenizer(br.readLine()); int u = Integer.parseInt(st.nextToken()); int v = Integer.parseInt(st.nextToken()); graph[u].add(v); graph[v].add(u); } // 2. 내림차순 정렬 for(int i = 1; i <= N; i++) { Collections.sort(graph[i], Collections.reverseOrder()); } // 3. dfs 호출하기 dfs(R); // 4. 출력하기 for(int i = 1; i <= N; i++) { bw.write(String.valueOf(answer[i])); bw.newLine(); } bw.close(); br.close(); } }문제풀이
-
지난번 문제인 깊이 우선 탐색 - 1과 한 가지 다른 점을 제외하고 나머지는 동일하다.
-
내림차순 정렬을 하기 위해서는 sort()의 인자에 추가로
Collections.reverseOrder()를 전달해주면 된다.
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8