흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[JPA] 영속성 컨텍스트란
이 글은 [자바 ORM 표준 JPA 프로그래밍 - 기본편] 강의를 듣고 정리한 내용입니다.
영속성 컨텍스트란
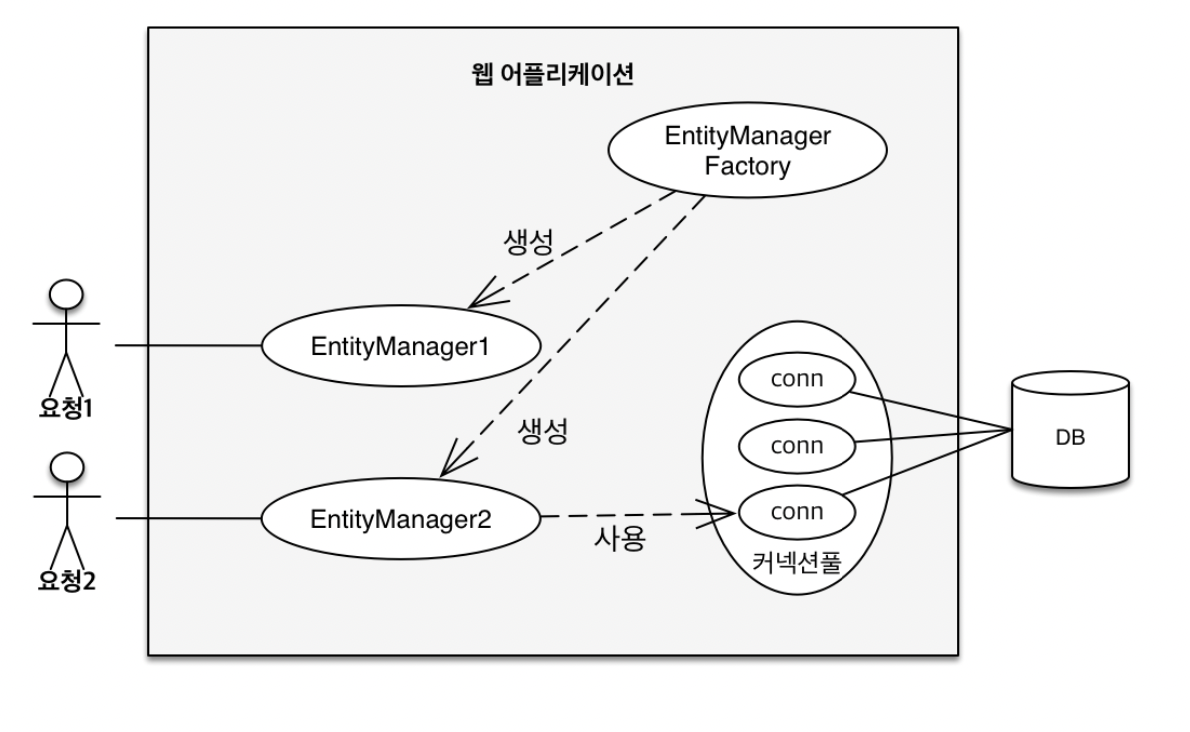
- JPA를 사용하면, 일반적으로 엔티티 매니저 팩토리와 엔티티 매니저에 대해 이해를 해야 한다.
-
웹 애플리케이션을 개발하면서 고객으로부터 요청이 오면, 엔티티 매니저 팩토리를 통해 엔티티 매니저를 생성한다.
-
엔티티 매니저는 데이터베이스 커넥션 풀을 사용해서 DB를 사용하게 된다.
영속성 컨텍스트란 엔티티를 영구 저장하는 환경이라는 뜻을 가진 논리적인 개념으로 어플리케이션과 DB 사이에서 객체를 보관하는 가상의 DB같은 역할을 한다.즉, 애플리케이션에서 DB에 저장하기 전에 사용을 하는 임시 저장 공간이라고 이해를 하면 편할 것이다.
EntityManager.persist(entity);
-
엔티티 매니저를 통해서
영속성 컨텍스트에 접근한다.-
엔티티 매니저(Entity Manager)란 영속성 컨텍스트에 접근하여 엔티티에 대한 데이터베이스 작업을 제공하는 것을 의미한다. -
엔티티 매니저(Entity Manager)는 엔티티를 저장하고, 수정하고, 삭제하고 조회하는 등 엔티티와 관련된 모든 일을 처리한다.
-
-
영속성 컨텍스트를 통해 데이터의 상태 변화를 감지하고 필요한 쿼리를 자동으로 수행한다.
엔티티의 생명 주기
- 엔티티의 생명 주기는 아래와 같이 4가지로 구성되어 있다.
- 비영속(new/transient) : 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
- 영속(managed) : 영속성 컨텍스트에 관리되는 상태
- 준영속(detached) : 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제(removed) : 삭제된 상태
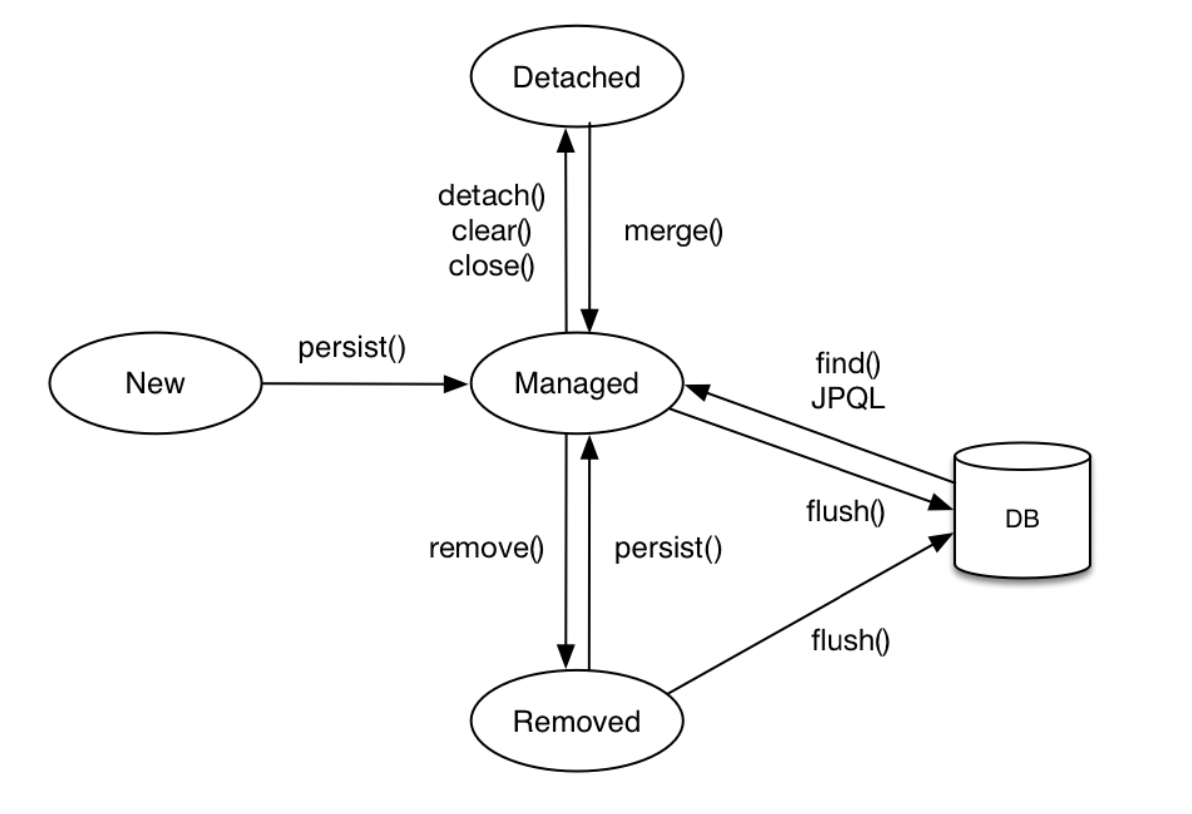
비영속
- 아래와 같이 Member 객체만 생성만 한 상태 ⇒ JPA와 전혀 관계가 없는 새로운 상태를
비영속상태라고 한다.

영속
- 아래와 같이 Member 객체를 생성한 다음에, 엔티티 매니저를 얻어와서 Member 객체를 저장하면 영속성 컨텍스트에 관리되는 상태를
영속상태라고 한다.

- 아래의 java 코드로 비영속 상태와 영속 상태를 구분할 수 있다.
import javax.persistence.Persistence; import javax.persistence.EntityManagerFactory; import javax.persistence.EntityTransaction; public class JpaMain { public static void main(String[] args) { EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello"); EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin() try { // 비영속 Member member = new Member(); member.setId(100L); member.setName("HelloJPA"); // 영속 em.persist(member); tx.commit(); } catch (Exception e) { tx.rollback(); } finally { ex.close(); } } }준영속, 삭제
-
Member 엔티티를 영속성 컨텍스트에서 분리한 상태를
준영속상태라고 한다.- 영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)되어 영속성 컨텍스트가 제공하는 기능을 사용하지 못한다.
-
준영속 상태로 만드는 방법
-
em.detach(entity) : 특정 엔티티만 준영속 상태로 전환
-
em.clear() : 영속성 컨텍스트를 완전히 초기화
-
em.close() : 영속성 컨텍스트를 종료
-
-
객체를 삭제한 상태를
삭제라고 하며, 코드에서는em.remove(member);를 의미한다.
//삭제 대상 엔티티 조회 Member memberA = em.find(Member.class, “memberA"); em.remove(memberA); //엔티티 삭제영속성 컨텍스트의 이점
1차 캐시
-
영속성 컨텍스트 내부에는 엔티티 인스턴스를 캐싱하는
1차 캐시가 있다. -
일반적으로 트랜잭션 내에서 유효한 생명주기를 갖는다.

- member를 영속하면, member1과 member라는 엔티티 클래스를 1차 캐시에 저장한다.
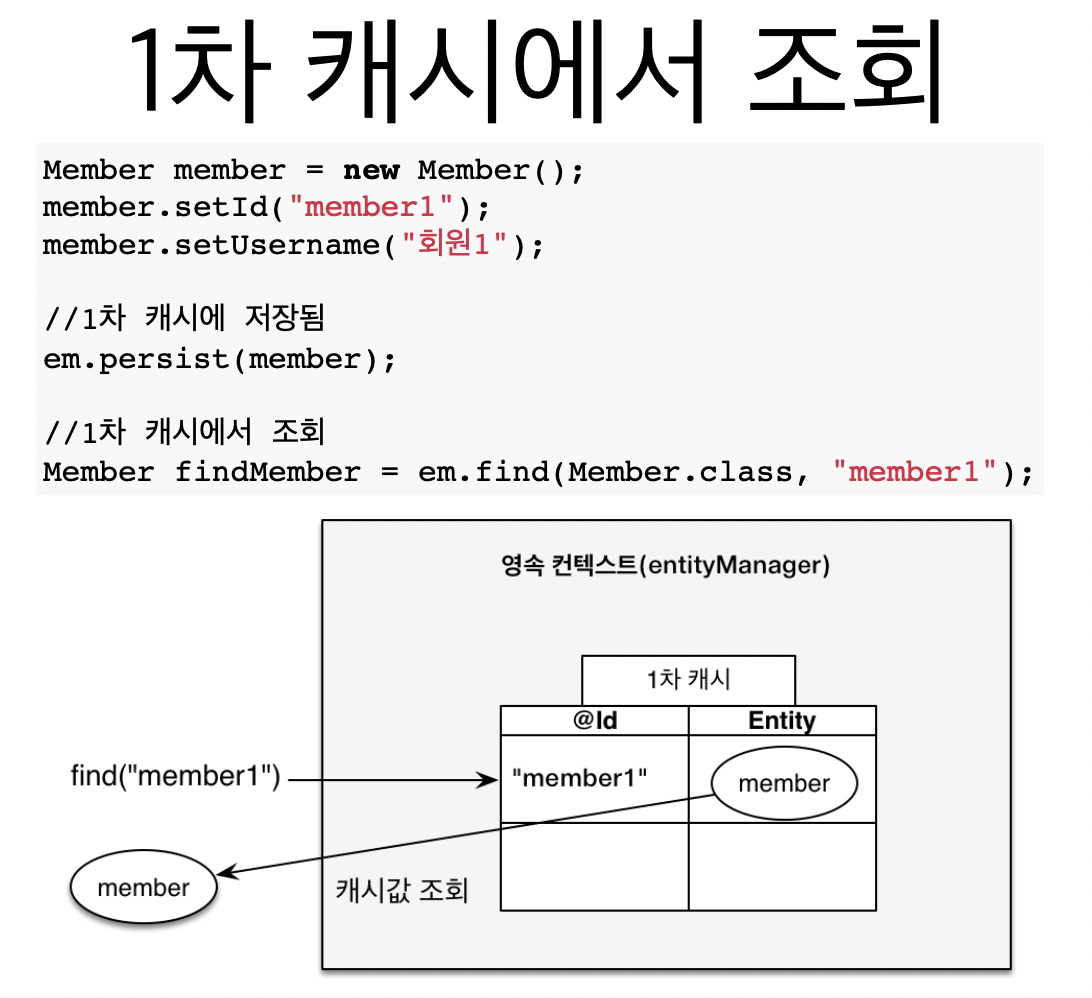
- 그런 다음, 영속성 컨택스트에서
member1를 조회하면, JPA는 DB가 아닌 1차 캐시에 저장된 값을 가져온다.
-
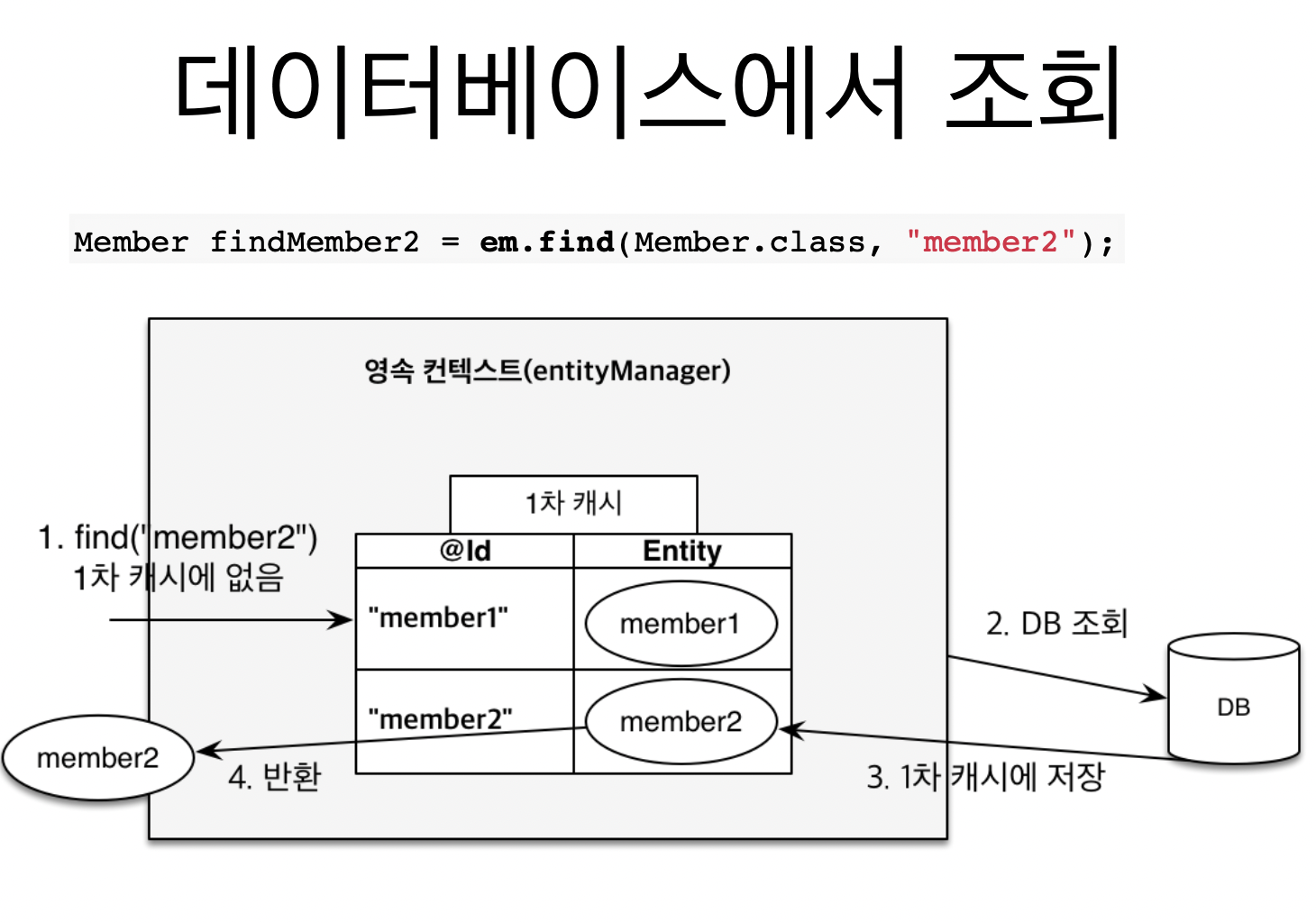
그런데 만약
member2를 조회할 때, 1차 캐시에 없다면, DB를 조회한다. 그런 다음에 해당 값을 1차 캐시에 저장하고 값을 반환한다. -
사실, 엔티티 매니저라는 건 데이터베이스 트랜잭션이 끝날 때 종료된다. ⇒ 비즈니스가 끝나면, 해당 엔티티 매니저가 사라져버린다.
-
차 캐시라는건 데이터베이스 하나의 트랜잭션 안에서만 효과가 있기 때문에 성능에 대한 장점은 없다.
동일성 보장
-
영속성 컨텍스트는 영속성 컨텍스트 안에서 영속 엔티티들의 동일성을 보장한다.
-
따라서 같은 식별자를 통해 1차 캐시에서 얻은 엔티티 인스턴스는
==연산을 통해 동일성을 보장한다.
Member a = em.find(Member.class, "member1"); Member b = em.find(Member.class, "member1"); System.out.println(a == b); //동일성 비교 true-
JPA가 영속 엔티티의 동일성을 보장한다. 마치 자바 컬렉션에서 똑같은 레퍼런스 객체를 꺼내오는 것과 같다. 1차 캐시가 있기 때문에 가능한 것이다.
-
같은 트랜잭션 안에서 비교할 때에만 동일하다는 것이다.
트랜잭션 쓰기 지연
EntityManager em = emf.createEntityManager(); EntityTransaction transaction = em.getTransaction();//엔티티 매니저는 데이터 변경시 트랜잭션을 시작해야 한다. transaction.begin(); // [트랜잭션] 시작 em.persist(memberA); // 1 em.persist(memberB); // 2 //여기까지 INSERT SQL을 데이터베이스에 보내지 않는다. //커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다. transaction.commit(); // 3 [트랜잭션] 커밋- 위에 작성한 자바 코드에서 1->2->3 순서대로 세부 과정에 대해 알아보자.
em.persist(memberA);
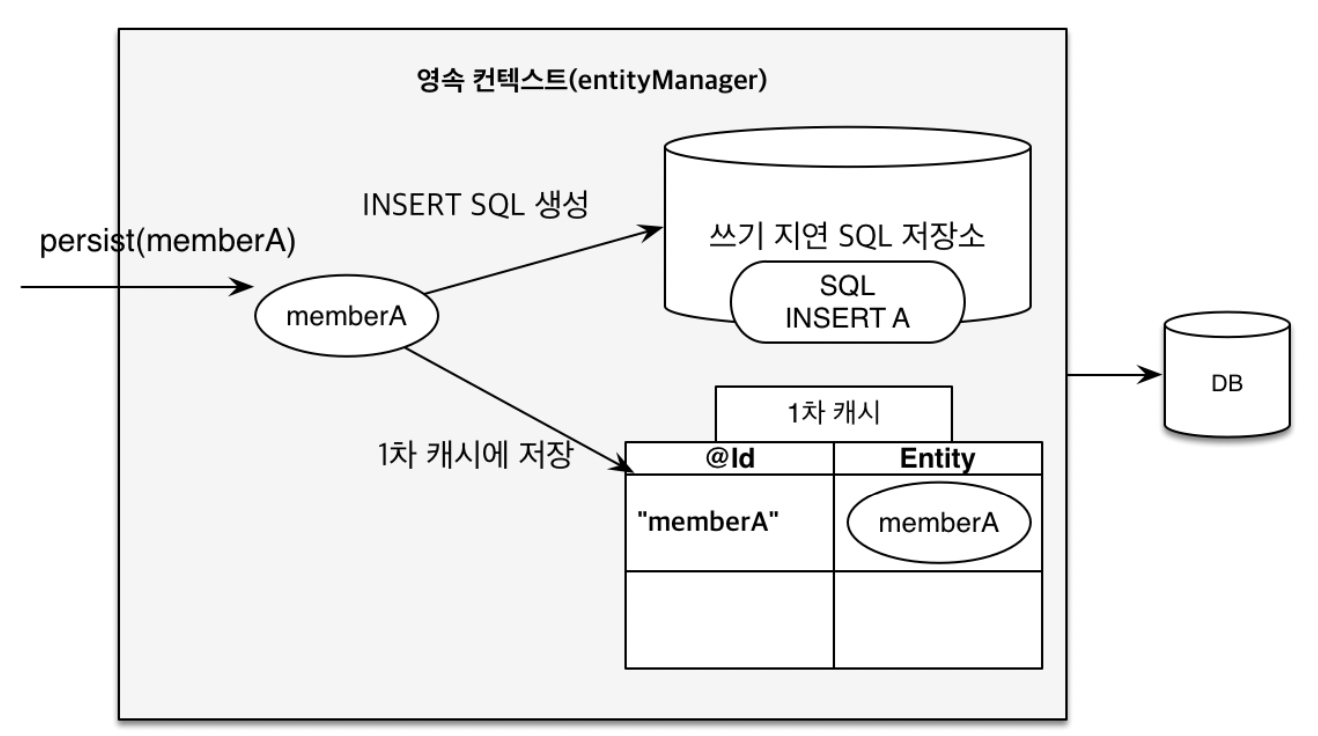
-
[1]
em.persist(memberA);을 통해 memberA가 1차 캐시에 들어간다.(집어 넣는다) -
[2] 그러면서 동시에 JPA가 이 엔티티를 분석해서 INSERT SQL 쿼리를 생성한다.
-
[3] 그래서 쓰기 지연 SQL 저장소에 쌓아둔다.
em.persist(memberB);
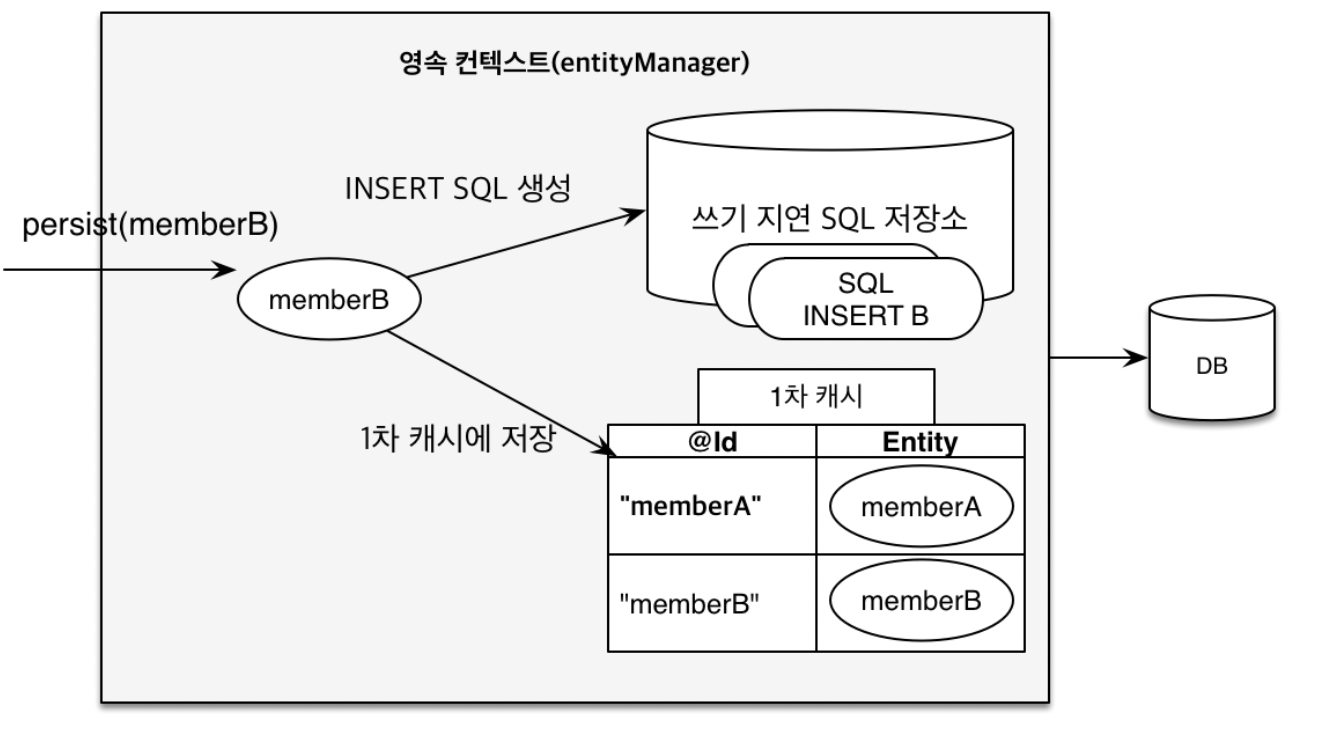
-
[4] 그런 다음에
em.persist(memberB);을 하면, memberB도 1차 캐시에 들어간다.(집어 넣는다) -
[5] 그리고 이때, INSERT SQL 쿼리를 생성해서 쓰기 지연 SQL 저장소에 차곡차곡 쌓아둔다.
transaction.commit();
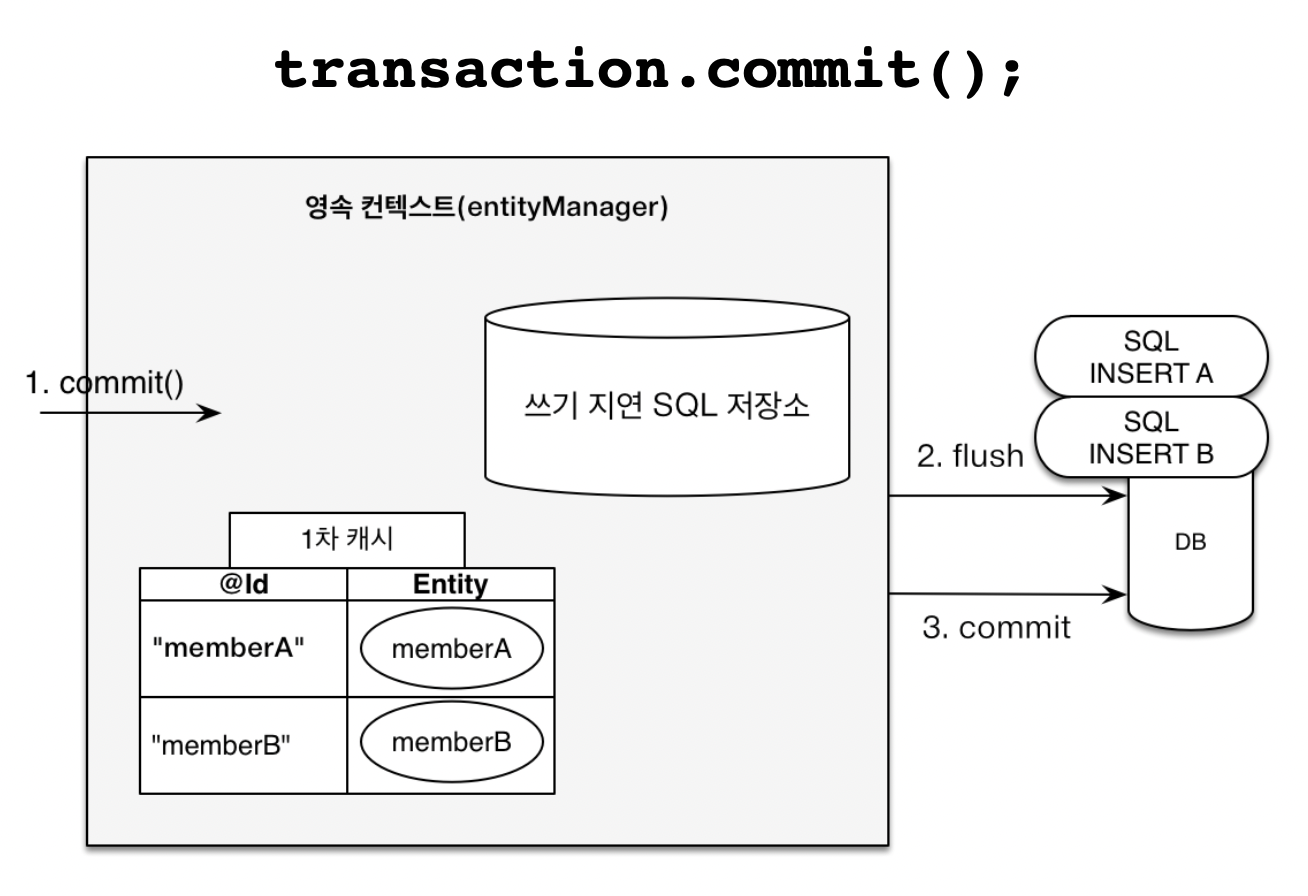
-
[6] 그리고
transaction.commit();을 통해 커밋하는 순간쓰기 지연 SQL 저장소에 있던 데이터들이 flush가 되면서,데이터베이스에 INSERT SQL을 보낸다. -
[7] 그리고 실제 데이터베이스가 commit 된다.
변경 감지
변경 감지란 JPA를 사용하여 데이터를 수정하려면Entity를 조회하여 조회된Entity데이터를 변경만 하면데이터베이스에 자동으로 반영이 되도록 하는 기능이다.
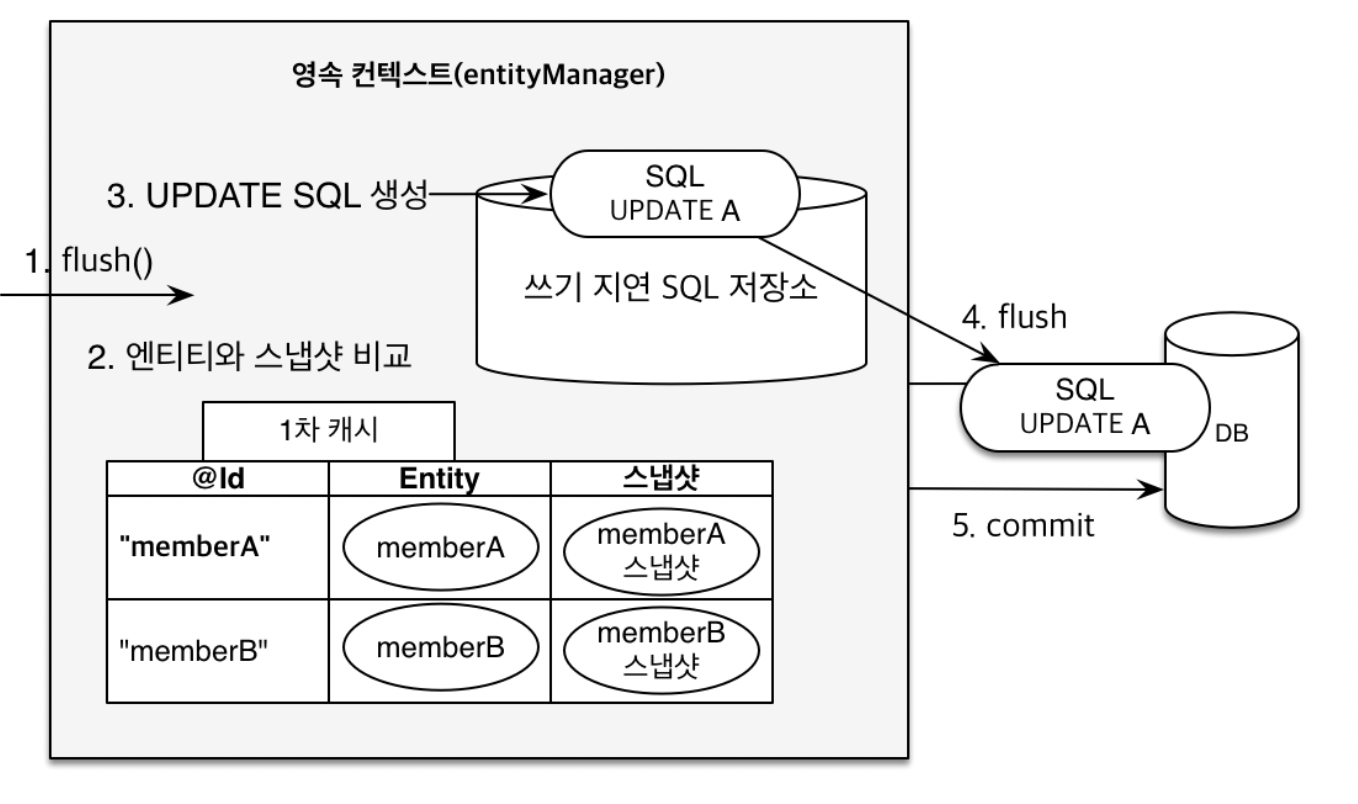
-
[1] 데이터베이스에 커밋하면, 내부적으로 flush가 발생하고
-
[2] JPA가 엔티티하고 스냅샷을 비교한다.
엔티티 인스턴스 값을 읽어온 그 시점의 최초 상태를영속성 컨텍스트에 저장하는 데, 이를스냅샷이라 부른다.
-
만약 MemberA에 대한 데이터가 변경되면
쓰기 지연 SQL 저장소에 [3] UPDATE SQL 쿼리를 생성한다. -
그리고 [4] UPDATE SQL 쿼리를 flush를 통해 데이터베이스에 반영하고
-
[5] commit 하게 된다.
플러시
-
flush란 영속성 컨텍스트의 변경내용을 데이터베이스에 반영하는 것을 말한다. -
플러시가 발생하면, 다음 3가지가 일어난다.
-
변경 감지
-
수정된 엔티티의 쓰기 지연 SQL 저장소에 등록
-
쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송 (등록, 수정, 삭제 쿼리)
-
-
영속성 컨텍스트를 플러시하는 방법은 3가지가 있다.
-
em.flush() - 직접 호출 -> 쿼리가 DB에 반영되어 버린다.
-
트랜잭션 커밋 - 플러시 자동 호출
-
JPQL 쿼리 실행 - 플러시 자동 호출
-
-
플러시 모드 옵션은 기본적으로 AUTO(
em.setFlushMode(FlushModeType.AUTO)로 사용된다. (거의 사용할 일은 없다)-
FlushModeType.AUTO : 커밋이나 쿼리를 실행할 때 플러스 (기본값)
-
FlushModeType.COMMIT : 커밋할 때만 플러시
-
-
정리하면, 플러시는
영속성 컨텍스트를 비우지 않고, 변경 내용을 데이터베이스에 동기화하고
트랜잭션 커밋 직전에만 동기화하면 된다.
Reference
-
[리뷰] 함께 자라기 (애자일로 가는 길)
- 실제 실력과 상관있는 것은 의도적 수련이다.
- 자기개발은 복리로 돌아온다.
- 적절한 실력과 작업 난이도를 조절하면서 성장한다.
- 실수는 예방하는 것이 아니라 관리하는 것이다.
- 사회적 자본과 기술
- 신뢰 자산의 중요성
- 설득할 때 주관적인 부분도 필요하다.
- 심리적 안전감
- Review
- Reference
이 글은 함께 자라기 책을 읽고 저의 생각과 같이 정리한 내용입니다.

책을 2월에 사고 난 뒤 9개월이 지난 지금에서야 다 읽게 되었다.
2월 당시에는 팀 프로젝트를 하기 전이라,
협업에 대해 크게 흥미가 없어서 그런지 집중이 잘 안됐다.하지만 3월부터 10월까지 진행했던 히빗과 8월부터 9월까지 진행했던 굿프렌즈 팀 프로젝트를 경험한 이후에, 이 책을 다시 읽어보자는 생각이 들었다.
그래서 기존에 중반까지 읽었던 내용을 주말 동안 다시 복습 겸? 읽으면서 완독을 했다.
확실히 협업과 관련된 경험을 하고 나서 읽으니까, 공감된 부분들도 많았고 더 관심 있게 읽으면서 빠르게 완독할 수 있었다.
아래는 책을 읽으면서 개인적으로 느낀 인상 깊었던 부분 몇 개를 내 생각과 같이 정리해 보려고 한다.
실제 실력과 상관있는 것은 의도적 수련이다.
“소프트웨어 개발에서 개발에서 점차 경력 연수를 중시하는 문화가 사라질 것이다. 따라서 개발자들은 자신의 경력 연차 외에 다른 것에도 신경을 써야 한다.”
몇 년 전까지만 해도 안데쉬 에릭손의
1만 시간 법칙이 유행이었다. 그런데 이 법칙에서 나오는 시간을 본인의경력과 연관 지어선 안된다는 의미이다.예를 들어, 일상생활에 우리는 어렸을 때부터 하루 세 번 3분씩 이를 닦는다. 하지만 이를 매일 닦는다고 10년, 20년 이후에도 이를 닦는 경력이 실력과 관련이 없다는 것을 누구나 알 수 있다.
여기서 말하는
의도적 수련(deliberate practice)이란 자신의 기량을 향상시킬 목적으로 반복적으로 하는 수련을 의미한다.국내 여러 스포츠 종목에서 국가대표로 지내는 선수분들은 세계 대회에 출전해서 메달을 따기 위해 매일 본인의 약점을 개선하고, 강점을 더 강화하는 애쓰는 수련을 하고 있다.
이 글을 읽고, ‘내가 공부한 것이 의도적인 수련인가?’라는 생각을 하게 되었다. 단순히 남이 작성한 글을 읽거나 강의를 듣는 시간이 아니라, 누군가한테 설명할 정도의 수준까지 내 것으로 만드는 시간이
의도적인 수련이라고 생각한다.정리하자면, 단순히 인풋만 하는 게 아니라 아웃풋까지 이어 나가는 과정과 결과가 중요하다고 생각한다.
유튜브 채널: 개발바닥 - 용기를 잃지않는 개발자 이력서 (55초 ~)
위의 내용과 완전히 일치하진 않지만, 최근 개발바닥 채널에서 “용기를 잃지않는 개발자 이력서”에서도 향로님이 말씀해주신 내용을 가져와 봤다.
나는 ~~을 위해 이걸 했고, 그래서 그 결과가 ~~이다 이어져야 개인의 실력이 성장하지 않을까 생각한다. 흔히 이력서를 작성할 때에도
Why - What - How - Result과 같이 작성해야 보는 사람에게도 더 읽기 쉬워진다.자기개발은 복리로 돌아온다.
IT 기업에서 종사하시는 여러 직무의 분들이 연말에 한 해를 되돌아보면서 회고라는 글을 작성한다.
일 년 회고를 할 때 항상 되짚어 보는 것 중 하나가 나 자신에게 얼마나 투자를 했냐라는 것이다.
자기개발이 중요한 이유는 현재 나에게 무엇을 투자했느냐가 1년, 혹은 2년 후의 나를 결정한다고 느끼기 때문이다.
2022년 2학기 때 대학교에서 ‘운영체제’라는 과목을 수업하시는 교수님이 하신 말씀이 기억이 문득 생각났다.
교수님이 이전 삼성전자에 재직할 당시에, ‘전체 사원들 중 10% 이하 만이 자기개발을 하고, 나머지 90%는 현재 삶에 만족하는 경우가 많다’ 라고 하셨다.
이 책에서도 2시간 이상 자기개발에 투자하는 사람이 13.2%밖에 되지 않았다. (물론 2012년에 조사한 자료라, 현재와 다를 수 있다)
평소 자기개발을 열심히 하시면서, 블로그를 운영하시는 여러 현직자분들이 좋은 회사에 이직한 것을 블로그를 통해 많이 봤다.
나는 회사에서 일을 해본 경험이 적고, 이직 경험도 없어서 크게 와닿지는 않지만, 꾸준히 자기개발을 하면서 그러한 경험을 맛보는 기회를 언젠간 찾아오지 않을까 기대해 본다.
적절한 실력과 작업 난이도를 조절하면서 성장한다.
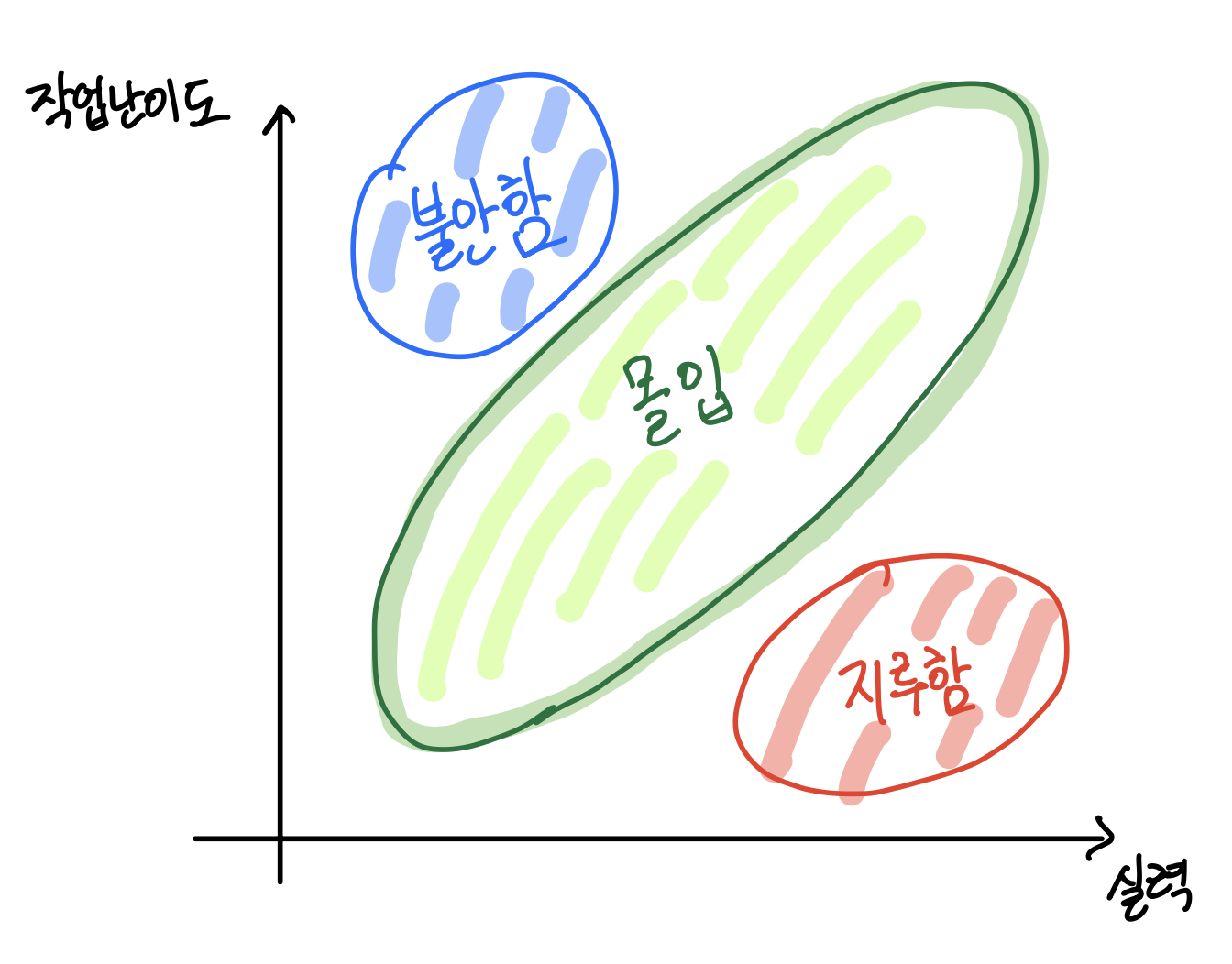
위 그림은
실력과작업 난이도를 기준으로 심리 상태를 그린 도식이다.주목해야 할 부분은
몰입에 해당하는 영역인데, 이때 최고 수준의 집중력을 보이고, 그 덕분에 퍼포먼스나 학습 능력이 최대치가 될 수 있다고 한다.해당 영역이 아닌, 실력이 작업 난이도를 초과하면 지루함을 느끼는 영역이나 실력보다 높은 난이도의 작업을 하면 불안함(혹은 두려움)을 느낀다고 한다.
‘팬시님! 현 프로젝트에 통합 및 인수 테스트를 작성해 주세요~ ‘와 같은 작업이 왔을 때 어렵다고 느껴지면, 우선 단위 테스트 작성하는 방법부터 익히도록 하자.
실수는 예방하는 것이 아니라 관리하는 것이다.
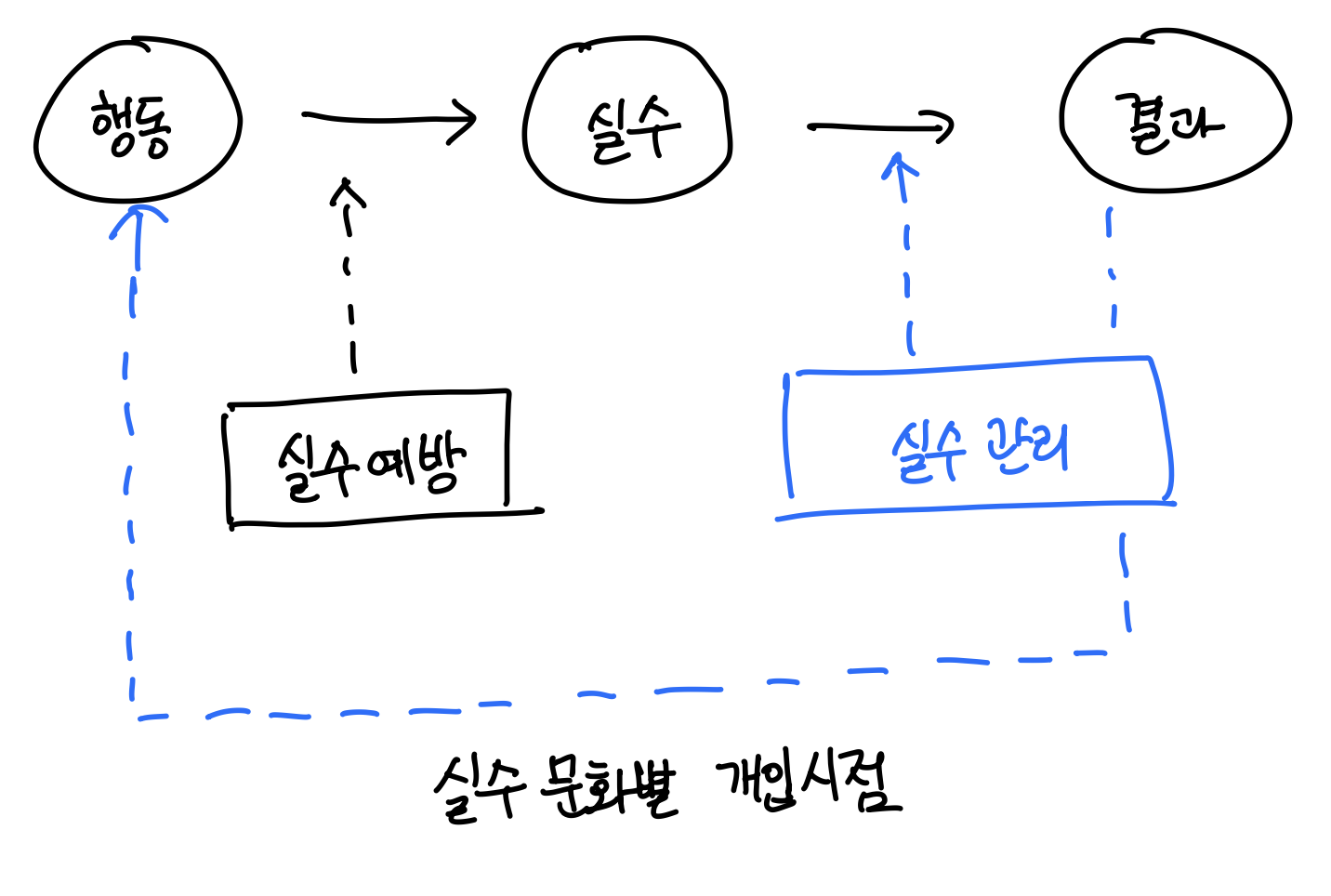
실수 관리 문화에서는 실수가 나쁜 결과를 내기 전에 빨리 회복하도록 돕고, 실수를 공개하고, 실수에 대해 서로 이야기하고 거기에서 배우는 분위기가 생긴다.회사 문화가 실수 관리에 가까울수록 그 기업의 혁신 정도가 더 높고, 회사의 수익성이 더 높다는 연구 자료가 있다.
즉, 실수 관리를 하는 문화일수록
학습을 더 잘한다.팀 프로젝트를 하다 보면 반드시는 아니지만, 실수가 종종 나타나는 경우가 있다. 그럴 때마다 실수를 한 팀원에게 따끔한 충고보단 따뜻한 조언을 하는 게 중요하다고 생각한다.
똑같은 실수에 대해 반복적이면 안 되겠지만, 처음 하는 실수에 대해서는 누구에게나 생길 수 있고, 그런 상황이 발생할 때 어떻게 해야 나은 방향으로 개선할 수 있을지 스스로에게 질문을 하면서 답을 찾아가 보자.
사회적 자본과 기술
새로운 기술을 개인 또는 외부 스터디 활동을 통해서 배웠다고 회사에 바로 적용하기가 쉽지 않다.
아무리 기술적인 실천법이라고 해도 그 기술은 사회적 맥락속에서 실천되어야 하며, 그 기술의 성공을 위해서는 사회적 자본과 사회적 기술이 함께 필요하다.
이 책에서는 신뢰 구축을 보다 잘하는 사람을 사회적 자본이 좋은 사람들이라고 합니다. 그리고 사회적 자본이 좋은 사람들이 통상 사회적 기술이 뛰어나다고 합니다.
뛰어난 개발자일수록 동료와의 협업에 시간을 투자하는 부분으로 커뮤니케이션의 중요성을 강조합니다.
TDD(테스트 주도 개발)이라는 프로그래밍 기법을 가져왔다면, 해당 기법 전체를 단번에 적용하는 것보다는 팀원들과 지속적으로 협업하면서 기초적인 개념부터 천천히 도입하는 방향으로 가는게 좋다고 생각한다.
실제로 이전 팀 프로젝트에서 DDD 패턴을 도입했을 때, 해당 개념의 전체적인 것을 적용하지 않고 일부의 개념만 도입하고 이후에 추가하는 식으로 진행했었다.
신뢰 자산의 중요성
신뢰 자산이 높은 조직은 커뮤니케이션 효율이나 생산성이 높다.
특히 애자일을 제대로 하려는 조직이라면 이 부분에 많은 노력을 들이고 있다.
이 책에서는 신뢰를 쌓는 데에 널리 사용되는 한 가지 방법은 투명성, 공유, 인터랙션이라고 한다.
자신이 한 작업물을 투명하게 서로 공유하고 그에 대해 피드백을 주고받으며 인터랙션을 하는 것이다.
개발자끼리 팀 프로젝트를 진행했을 때, 기획부터 같이 진행한 적이 있었다. 그때 각자만의 아이디어를 공유할 때 한 사람당 여러 개의 아이디어를 공유했는데, 여기서도 그와 관련된 글이 있다.
나의 아이디어가 1개밖에 없다면,
아아디어=나가 되어서 상대방이 나에게 뭐라고 하기가 쉽지 않다.반면에 복수로 공유하면, 그런 불안감이 상대적으로 덜하고, 부정적인 피드백을 수용하려는 마음도 있다.
이 책에서는 복수 공유를 한 그룹이 단수로 공유하는 것보다(개인당 아이디어가 1개) 신뢰도가 높아지고 성과도 더 좋았다고 합니다.
설득할 때 주관적인 부분도 필요하다.
품질 전문가 제럴드 와인버그는 품질을 다음과 같이 정의했습니다.
“품질 이란 누군가에게 가치가 되는 것이다.”
사실 품질은 사람을 빼놓고 이야기할 수가 없다.
고품질을 얻으려고 노력하는 사람들은 ‘인간’에 대한 이해가 필수적이다.
설득도 마찬가지이다. 대부분의 사람들이 설득을 하기 위해 객관성이 필요하다고 하는데, 사실 객관성을 정의하는 것도 사람이기 때문에, 이 개념 자체가 매우 주관적이라는 것이다.회사에는 직원과 사장이 있고, 중요한 부분을 결정하고 실행하기 전에는 직원이 사장으로부터 승인을 받아야 하는 경우가 있다.
사장도 사람이기 때문에, 사장을 설득하라면 어쩔 수 없이 객관적인 자료뿐 아니라 감정적이고 직관적인 부분도 필요하다.
이 책에서는 남을 설득하려면 논리성과 객관성에 대한 환성을 버려야 하고, 그래야 현실적으로 설득이 가능하다고 한다.
결국, 설득에 성공하려면 우선 그 사람을 이해하는 것에서 출발해야 한다. 그런 이유로 설득을 하기 위해 ‘객관적’인 자료뿐 아니라 그 이상으로 상대를 이해하는데 많은 시간을 투자해야 한다.
상대방에게 신뢰감을 잃어버리면, 아무리 좋은 ‘객관적’인 자료와 근거가 있더라도 소용없다.
심리적 안전감
이 책에서는
심리적 안전감을 내 생각이나 의견, 질문, 걱정, 혹은 실수가 드러났을 때 처벌받거나 놀리지 않을 거라는 믿음을 말한다고 한다.이 개념은 정말 중요하다고 생각한다. 어떤 프로젝트를 진행할 때, 팀원 간의 의견을 주고 받는게 없다면, 이러한 심리적 안전감이 떨어질 것이고, 갈수록 상대방에 대한 이해가 낮아질 것이라고 본다.
히빗 프로젝트를 진행하면서, 매주 회의를 팀원들과 같이 진행하면서 모르는 부분이나 궁금한 부분들을 적극적으로 물어봤고, 나에게 질문이 들어오는 경우에도 최대한 자세히 알려주려고 노력했다.
개발을 하면서, 어려운 부분을 마주쳤을 때 혼자서 끙끙 앓는 것보다는 혼자서 어느 정도의 시간을 투자한 뒤에 동일 직군의 팀원에게 물어보는게 팀 전체적으로 더 도움이 된다고 생각한다.
Review
이 책의 제목인
함께 자라기는 함께(협력)과 자라기(학습)을 내포하고 있다.협력과 학습에 대한 중요성을 여러 가지 상황을 예시로 들면서, 좋은 해결 방안을 알려주고 있는 내용이었다.
이후에 팀 프로젝트를 진행한다면, 이 책을 다시 한번 복기해봐야 겠다는 생각이 들 정도로, 나에게 도움을 많이 준 책이다.
Reference
-
[내 코드가 그렇게 이상한가요?] 8 - 12장 정리
- 8장. 강한 결합: 복잡하게 얽혀서 풀 수 없는 구조
- 9장. 설계의 건정성을 해치는 여러 악마
- 10장. 이름 설계: 구조를 파악할 수 있는 이름
- 11장. 주석: 유지 보수와 변경의 정확성을 높이는 주석 작성 방법
- 12장. 메서드(함수): 좋은 클래스에는 좋은 메서드가 있다.
- Reference
이 글은 내 코드가 그렇게 이상한가요? 책을 읽고 정리한 내용을 바탕으로 작성하였습니다.
8장. 강한 결합: 복잡하게 얽혀서 풀 수 없는 구조
소프트웨어 설계에서
결합도는 모듈 사이의 의존도를 나타내는 지표이고,책무는 어떤 관심사를 정상적으로 작동하게 제어하는 책임이다.-
단일 책임 원칙을 기반으로 설계해야 한다.-
단일 책임 원칙은 ‘클래스가 담당하는 책임은 하나로 제한해야 한다’는 설계 원칙이다. -
책임을 대신 지는 클래스가 만들어지면, 다른 클래스가 제대로 성장할 수 없다. (= 성숙해지지 않는다)
-
따라서 관심사에 따라 분리해서 독립되어 있는 구조, 즉
느슨한 결합으로 설계해야한다.
-
-
DRY 원칙(= Don’t Repeat Yourself) : ‘빈복을 피해라’
-
DRY는 각각의 개념 단위내에서 반복을 하지 말라는 의미이다.
-
같은 로직, 비슷한 로직이라도 개념이 다르면 중복을 허용해야 한다.
-
무리하게 중복을 제거하려 하면, 강한 결합 상태가 된다.
-
-
상속을 하면, 강한 결합 구조를 유발하게 된다. (이 책에서는 상속 자체를 권장하지 않는다)
-
상속 관계에서 서브 클래스는 슈퍼 클래스에 크게 의존하게 된다. -> 서브 클래스가 슈퍼 클래스의 구조를 하나하나 신경 써야 한다.
-
강한 결합을 피하려면, 상속보다
컴포지션을 사용하는 것이 좋다. -
컴포지션이란 사용하고 싶은 클래스를 pri-vate 인스턴스 변수로 갖고 사용하는 것을 의미한다. -
상속은 전략 패턴 등으로 조건 분기를 줄일 때 활용할 수 있다.
-
만약 상속을 사용한다면, 반드시
단일 책임 원칙을 염두에 두고 구현해야 하며, 값 객체와 컴포지션 등 다른 설계를 사용할 수는 없는지 검토한다.
-
-
관련된 것끼리 클래스로 분리한다.
- 클래스를 잘 분리하려면, 각각의 인스턴스 변수와 메서드가 무엇과 관련 있는 지 잘 파악해야 한다.
-
특별한 이유 없이
public을 사용하지 않는다. ->public을 붙이면, 강한 결합 구조가 되어버린다. -> 유지보수가 어려워진다.- 클래스는 기본적으로
package private(default)로 만들고, 패키지 외부에 공개할 필요가 있는 클래스에 한해서만public으로 선언한다.
- 클래스는 기본적으로
-
한 클래스 내에서 private 메서드가 많으면, 책임이 너무 많은 건 아닌지 확인해본다. -> 책임이 다른 메서드는 다른 클래스로 분리한다.
- 각각의 개념을 각각의 클래스에 잘 분할해서 값 객체로 설계하는 것이 좋다.
-
스마트 UI는 화면 표시를 담당하는 클래스 중에서 화면 표시와 직접적인 관련이 없는 책무가 구현되어 있는 클래스를 말한다. -
트랜잭션 스크립트 패턴은 메서드 내부에 일련의 처리가 하나하나 길게 작성되어 있는 구조이다. -
갓 클래스는 하나의 클래스 내부에 수천에서 수만 줄의 로직을 담고 있으며, 수많은 책임을 담당하는 로직이 난잡하게 섞여있는 클래스이다. -
강한 결합 클래스 대처 방법 -> 객체 지향 설계와 단일 책임 원칙에 따라 제대로 설계한다.
- 책임별로 클래스를 분할 -> 단일 책임 원칙에 따라 설계된 클래스는 아무리 많아도
200줄, 일반적으로100줄정도이다.
- 책임별로 클래스를 분할 -> 단일 책임 원칙에 따라 설계된 클래스는 아무리 많아도
9장. 설계의 건정성을 해치는 여러 악마
-
데드코드는 절대로 실행되지 않는 조건 내부에 있는 코드를 말한다. -> 발견하는 즉시 제거한다. -
YAGNI: ‘You Aren’t Gonna Need it.’ -> 지금 필요 없는 기능을 만들지 말라 -> 지금 당장 필요한 것들만 만들라는 방침이다. -
매직 넘버는 로직 내부에 직접 작성되어 있어서, 의미를 알기 힘든 숫자를 말한다. -> 구현자 본인만 의도를 이해할 수 있다.- 매직 넘버를 사용하지 않으려면, 상수를 활용하면 된다. 예시) private static final int POINT = 100
-
영향 범위가 가능한 한 되도록 좁게 설계해야 한다. -> 호출할 수 있는 위치가 적고 국소적일수록 로직을 이해하고 구현하기 쉽다.
-
null을 리턴/전달하지 않는다. -> null 대신 static final 인스턴스 변수 EMPTY로 만든다.
-
예외를 확인했다면, 바로 기록하는 것이 좋다.
- catch 구문에서는 최소한 로그로 기록하고, 상위 레이어의 클래스로 오류를 통지하는 것이 좋다.
-
비즈니스 클래스는 비즈니스 개념을 기준으로 폴더를 구분하는 것이 좋다. -> 도메인 별로 구분되어 응집도가 높아진다.
-
이 책에서 설명하는 방법들은 사양 변경이 있을 때, 이를 조금이라도 쉽게 하기 위한 설계를 설명한다.
- 설계에 Best라는 건 없다. 항상 Better을 목표로 임한다.
10장. 이름 설계: 구조를 파악할 수 있는 이름
-
결합이 느슨하고 응집도가 높은 구조로 만들기 위해서는 관심사 분리로, 관심사에 따라서 각각 클래스로 분할해야 한다.
관심사 분리는 ‘관심사(유스케이스, 목적, 역할)에 따라서 분리한다’라는 소프트웨어 공학의 개념이다.
-
이름 설계하기
-
최대한 구체적이고, 의미 범위가 좁고, 특화된 이름을 선택하기 -> 어떤 비즈니스를 하는지 모두 파악해야 한다.
-
존재가 아니라 목적을 기반으로 생각하기 예시)
상품이라면 -> 입고 상품, 예약 상품, 주문 상품, 발송 상품 -
어떤 관심사가 있는지 분석하기
-
소리 내어 이야기해 보기 -> 비즈니스 측면을 잘 이해하고 있는 사람과 이야기 해본다. -> 잘못 인식하는 부분이 있으면 바로 피드백을 받을 수 있다.
-
이용 약관 읽어보기 -> 비즈니스 규칙과 클래스를 일치하게 만든다.
-
다른 이름으로 대체할 수 없는지 검토하기 -> ‘고객’이 아니라 ‘투숙객’, ‘결제자’처럼 대체할 수 없도록 이름을 변경한다.
-
결합이 느슨하고 응집도가 높은 구조인지 검토하기
-
-
이름을 기반으로 메서드와 클래스를 설계해야 한다. -> 프로그램 구조를 크게 좌우한다. -
수식어를 붙이면서까지 차이를 나타내고 싶은 대상은 각각 클래스로 설계하는 것이 좋다. -> 의미가 다른 개념을 서로 다른 클래스로 설계해서 구조화하면, 개념 사이의 관계를 이해하기 쉽다.
-
OriginalMaxHitPoint : ‘캐릭터의 원래 최대 히트 포인트’를 나타내는 클래스
-
CorrectedMaxHitPoint : ‘장비 착용으로 높아진 최대 히트 포인트’를 나타내는 클래스
-
-
DTO(Data Transfer Object) : 예외적으로 데이터 클래스를 사용하는 경우
- 데이터 전송 용도로 사용되는 디자인 패턴으로, 참조 용도로만 사용되며, 값을 변경하는 용도로 사용하면 안된다.
-
메서드의 이름은 동사 하나로 구성되게 한다.
11장. 주석: 유지 보수와 변경의 정확성을 높이는 주석 작성 방법
-
실제 내용과 내용이 다른 주석은 제거한다.
-
주석 규칙
-
로직을 변경할 때는 반드시 주석도 함께 변경해야 한다. -> 주석을 제대로 변경하지 않으면, 실제 로직과 달라져 주석을 읽는 사람에게 혼란을 준다.
-
로직의 내용을 단순하게 설명하기만 하는 주석은 달지 않는다. -> 시간이 지남에 따라 내용이 낡은 주석이 될 가능성이 높다.
-
로직의 의도와 사양을 변경할 때 주의할 점을 주석으로 달아야 한다. -> 유지 보수와 사양 변경에 도움이 된다.
-
-
문서 주석이란 특정 형식에 맞춰 주석을 작성하면, API 문서를 생성해 주거나 코드 에디터에서 주석의 내용을 팝업으로 표시해 주는 기능입니다.- 자바의
Javadoc을 참고하자.
- 자바의
12장. 메서드(함수): 좋은 클래스에는 좋은 메서드가 있다.
-
getter/setter는 값을 마음대로 변경할 수 있으므로 잘못된 값이 섞일 수도 있고, 코드가 중복되는 등 응집도를 낮출 수 있다.
-
매개변수에 final 수식자를 붙여서, 불변으로 만든다.
- 매개변수를 변경하고 싶으면, 불변 지역 변수를 만들고, 여기에 변경 값을 할당하는 형태로 구현한다.
-
출력 매개변수는 사용하지 않는 것이 좋다. -> 가독성 저하
-
매개변수는 최대한 적게 설계한다. -> 메서드가 처리할 게 많아지면, 그만큼 로직이 복잡해진다.
-
오류는 특정 값으로 리턴하지 말고, 곧바로 예외를 발생시키는 것이 좋다. -> throw new IllegalArgumentException()
Reference
-
[Goodfriends] Nginx와 Let's Encrypt로 HTTPS 웹 서비스 배포하기
프로젝트 구조
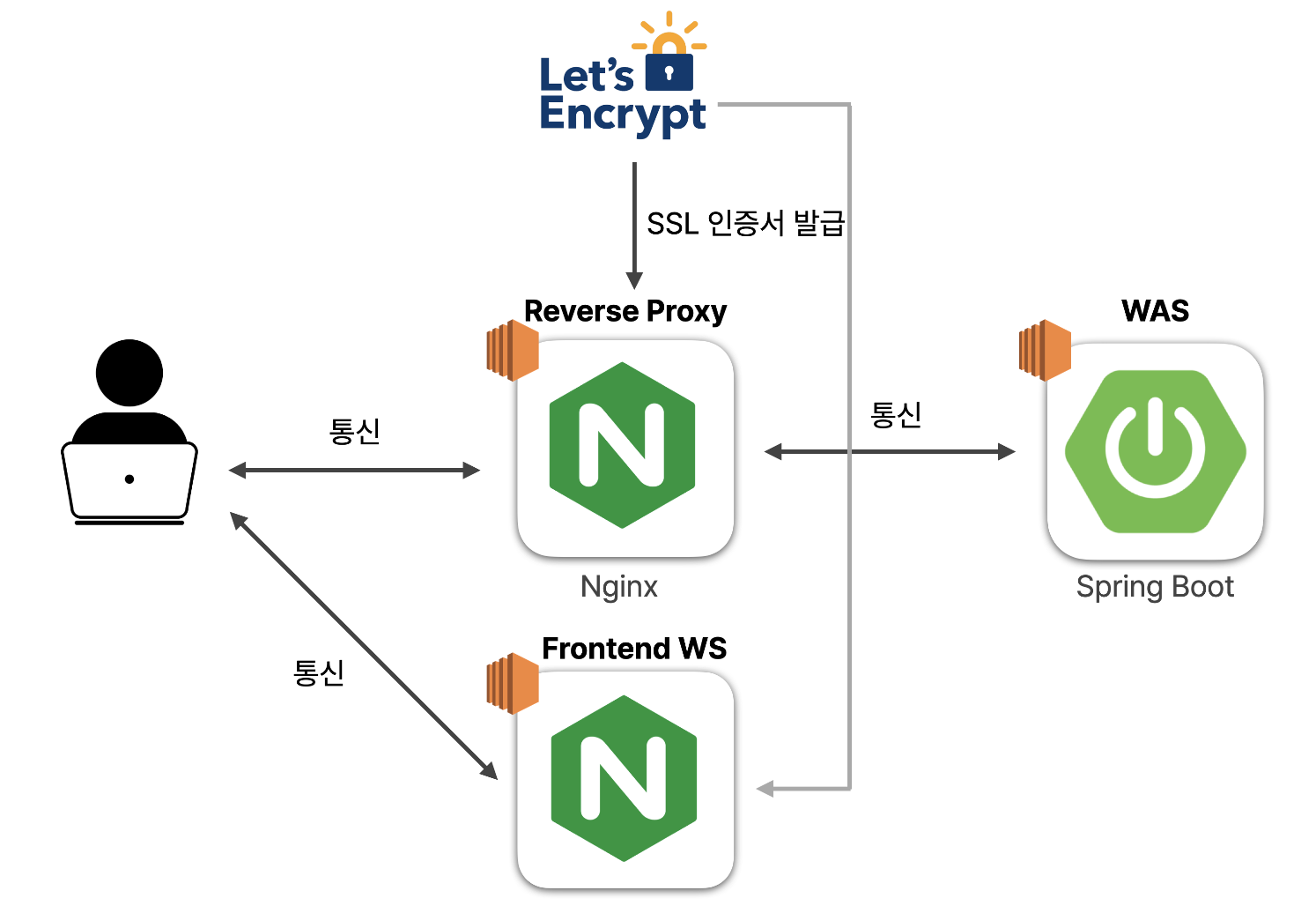
-
굿프렌즈 프로젝트 구조는 위 그림과 같다.
-
클라이언트와 WAS 사이에
리버스 프록시 서버를 둔다.클라이언트는 웹 서비스처럼 리버스 프록시 서버에 요청을 하고, WAS는 리버스 프록시로부터 사용자의 요청을 대신 받는다.
WAS는 리버스 프록시로부터 사용자의 요청을 대신 받는다.
클라이언트는 리버스 프록시 서버 뒷단의 WAS의 존재를 알지 못한다.
이로인해 보안이 한층 강화되었다.
그리고 프론트엔드는 정적 소스 배포를 위해 Nginx를 사용했다.
-
이전 굿프렌즈 서버는
HTTP요청으로 이뤄져있었다.하지만,
HTTP는 누군가 네트워크에서 신호를 가로채면 내용이 노출될 수 있는 문제를 발생하므로, 이를 해결하기 위해HTTPS를 적용해야 한다.(HTTPS를 왜 사용하는지에 대한 글은 이전에 작성했던 왜 HTTPS를 사용하나요?)을 참고하면 좋을 것 같다)
-
이때, 리버스 프록시 서버에 SSL 인증서를 발급해두어
HTTPS를 적용한다.WAS 서버가 여러대로 늘어나도 SSL 인증서 발급을 추가하지 않아도 확장성이 있다.
또한 WAS 서버가 SSL 요청을 처리하는데 드는 비용도 들지 않는다.
-
리버스 프록시 서버는
Nginx를 사용한다. (Nginx를 왜 사용하는지에 대한 글은 이전에 작성했던 NGINX란?를 참고하면 좋을 것 같다)굿프렌즈 프로젝트는 백엔드 기술 스택으로 Spring Boot를 사용했기 때문에, WAS를 Spring Boot를 이용했지만, 프로젝트에 따라서 node.js, fast api, django를 사용해도 상관없다.
CA로는 무료로 SSL 인증서 발급 기관인Let's Encrypt을 사용했다.또한 간단한 SSL 인증서 발급 및 Nginx 환경 설정을 위해
Cerbot을 사용했다. -
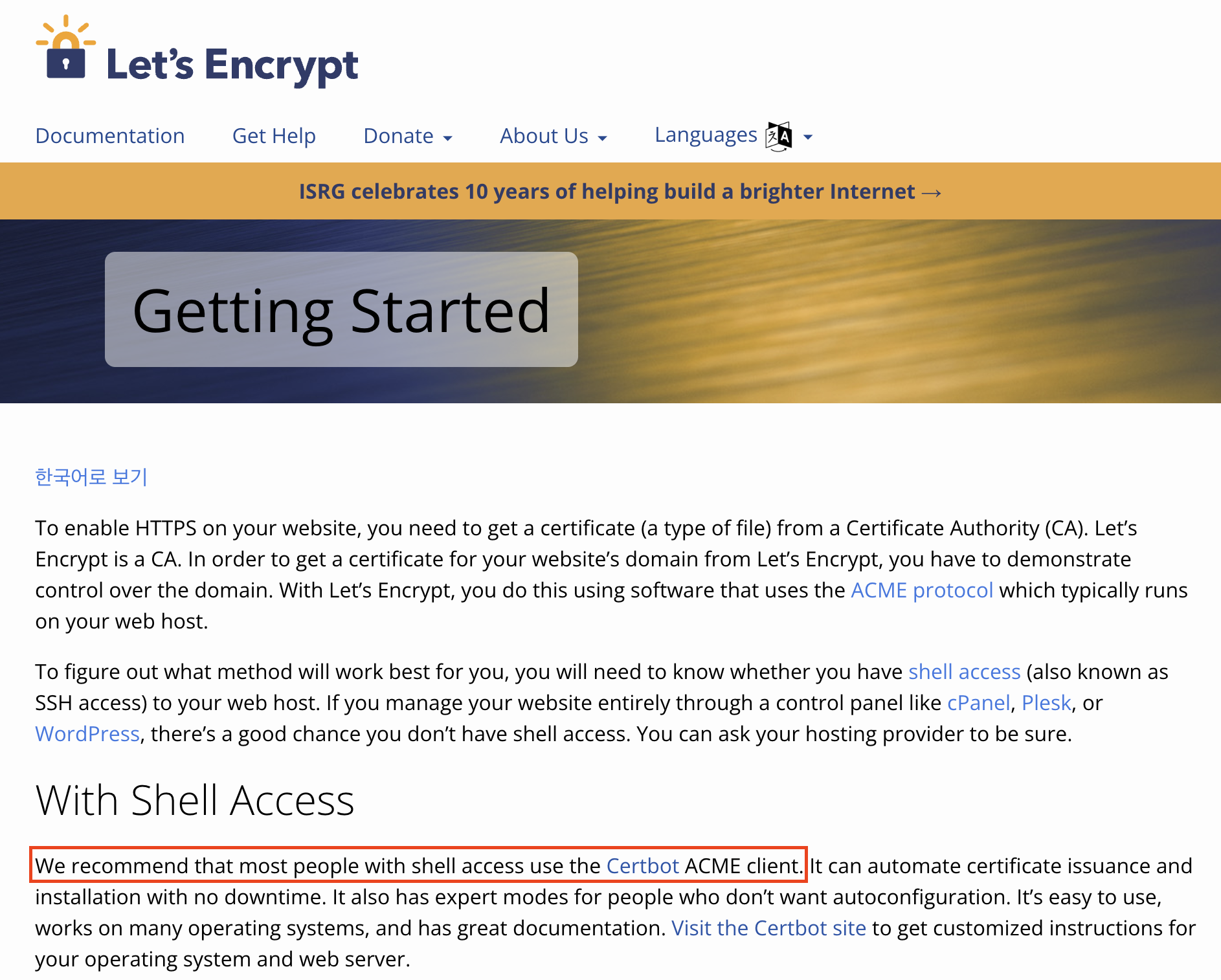
Let's Encrypt에서Cerbot을 함께 사용하는 것을 권장하는 문장을 아래 이미지를 통해 확인할 수 있다.
필요한 것들(준비물)
이 글에서는 총 3개의 서버가 사용된다. AWS의 EC2 또는 타사 VPS를 사용해도 된다.
서버 하나는 WAS가 돌아갈 서버이고(백엔드), 다른 하나는 WS가 돌아갈 서버이고(프론트), 나머지 하나는 리버스 프록시로 사용될 Nginx 이다.
또한 SSL을 적용하기 위해 도메인을 2개 준비해야 한다.
(굿프렌즈 프로젝트의 경우 가비아를 통해 도메인 2개를 구매했다)
AWS EC2와 도메인 연결하기
아래 AWS EC2와 도메인 연결 부분에서는 가비아를 기반으로 정리했습니다.
AWS EC2에 있는 서버를 가비아에서 구매한 도메인 주소와 연결하기 위해서는
Amazone Route 53을 이용해야 한다.Amazon Route 53는 가용성과 확장성이 뛰어난 도메인 이름 시스템(DNS) 웹 서비스입니다. Route 53는 사용자 요청을 AWS 또는 온프레미스에서 실행되는 인터넷 애플리케이션에 연결합니다.
Amazone Route 53에 대한 주요 기능에 대해 자세히 살펴보고 싶다면, Amazon Route 53 기능을 참고하자.
Route 53 검색 후 호스팅 영역을 생성한다.
굿프렌즈의 경우, 프론트엔드 도메인 이름은
goodfriends.life, 백엔드 도메인 이름은goodfriends.pro이다.
호스팅 영역에서
도메인 이름과설명을 아래와 같이 작성한 후 유형 부분에퍼블릭 호스팅 영역을 클릭한 뒤 생성 버튼을 클릭한다.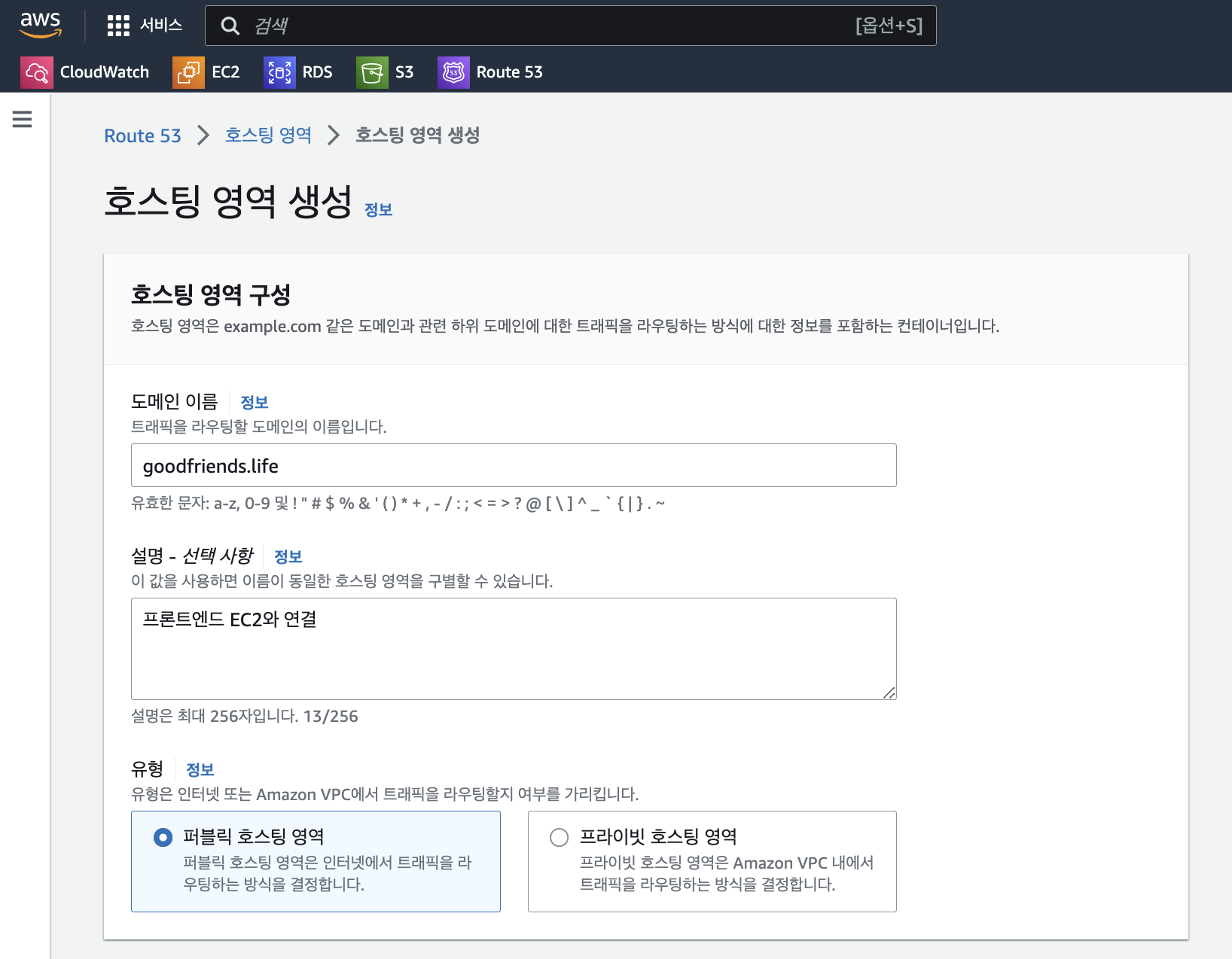
호스팅 영역에서 생성한 도메인에서
레코드 생성버튼을 클릭한다.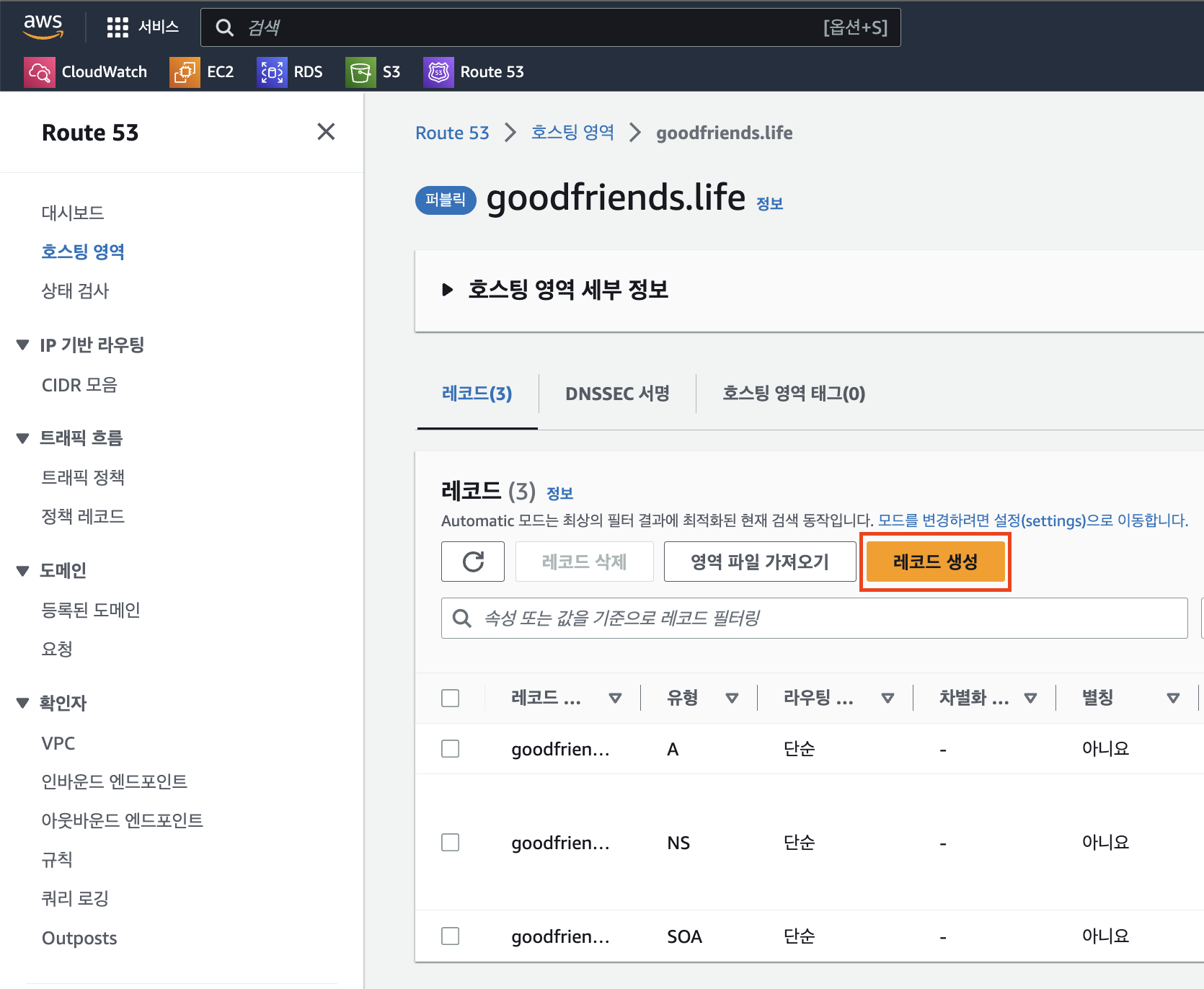
레코드 생성안에
값이라는 부분에 EC2 서버의퍼블릭 IPv4 주소를 기입하고 생성 버튼을 클릭하면 된다. 그러면 레코드가 생성된 것을 확인할 수 있다.레코드를 생성 완료했다면,
NS(네임서버)에서 가비아와 연결할값/트래픽 라우팅 대상을 확인한다.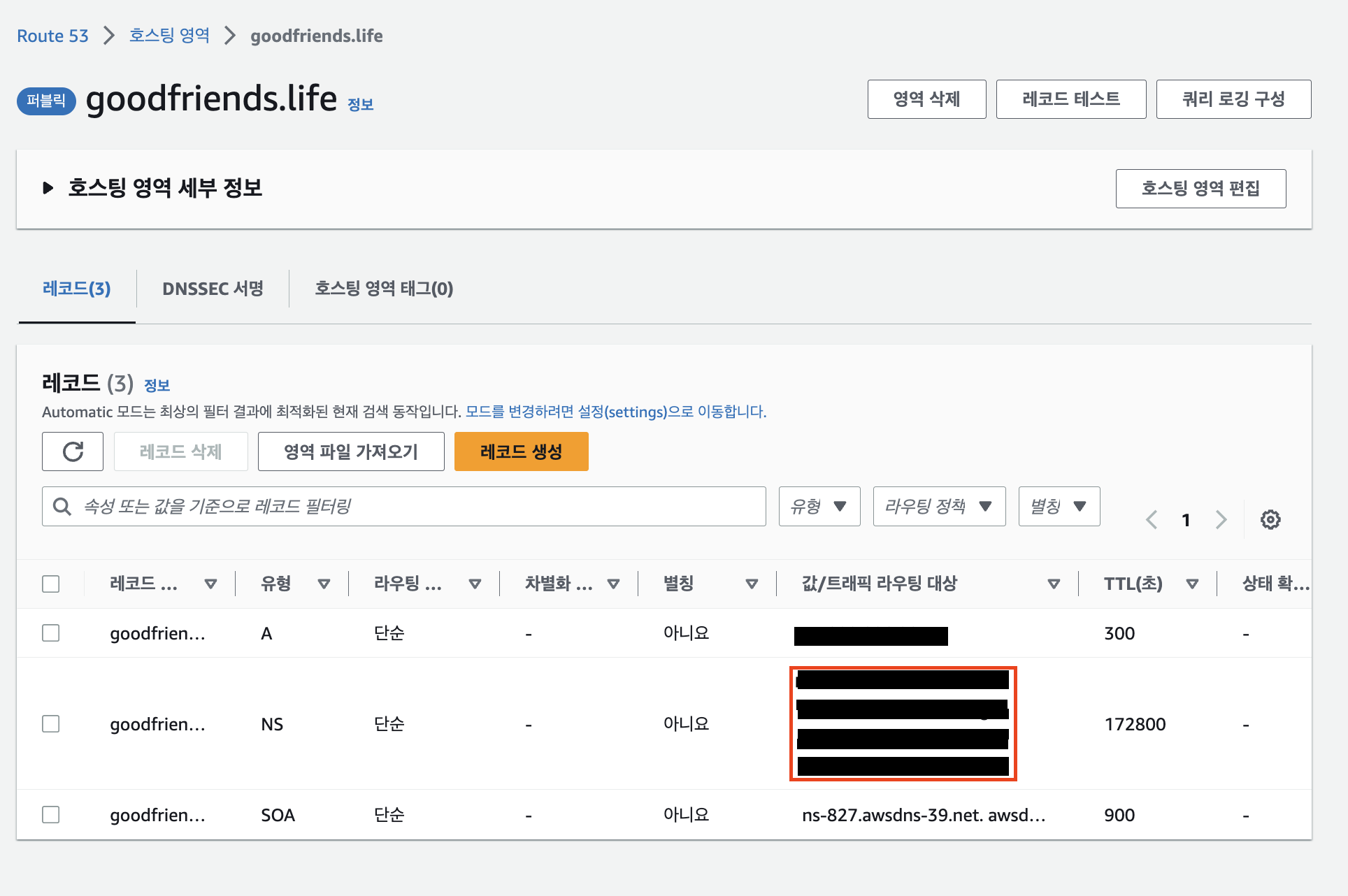
그런 다음, 해당
값/트래픽 라우팅 대상에 있는 값을 가비아 홈페이지에서My가비아-> 구매한 도메인의 관리 탭 클릭 ->네임서버설정에 동일하게 넣어준다.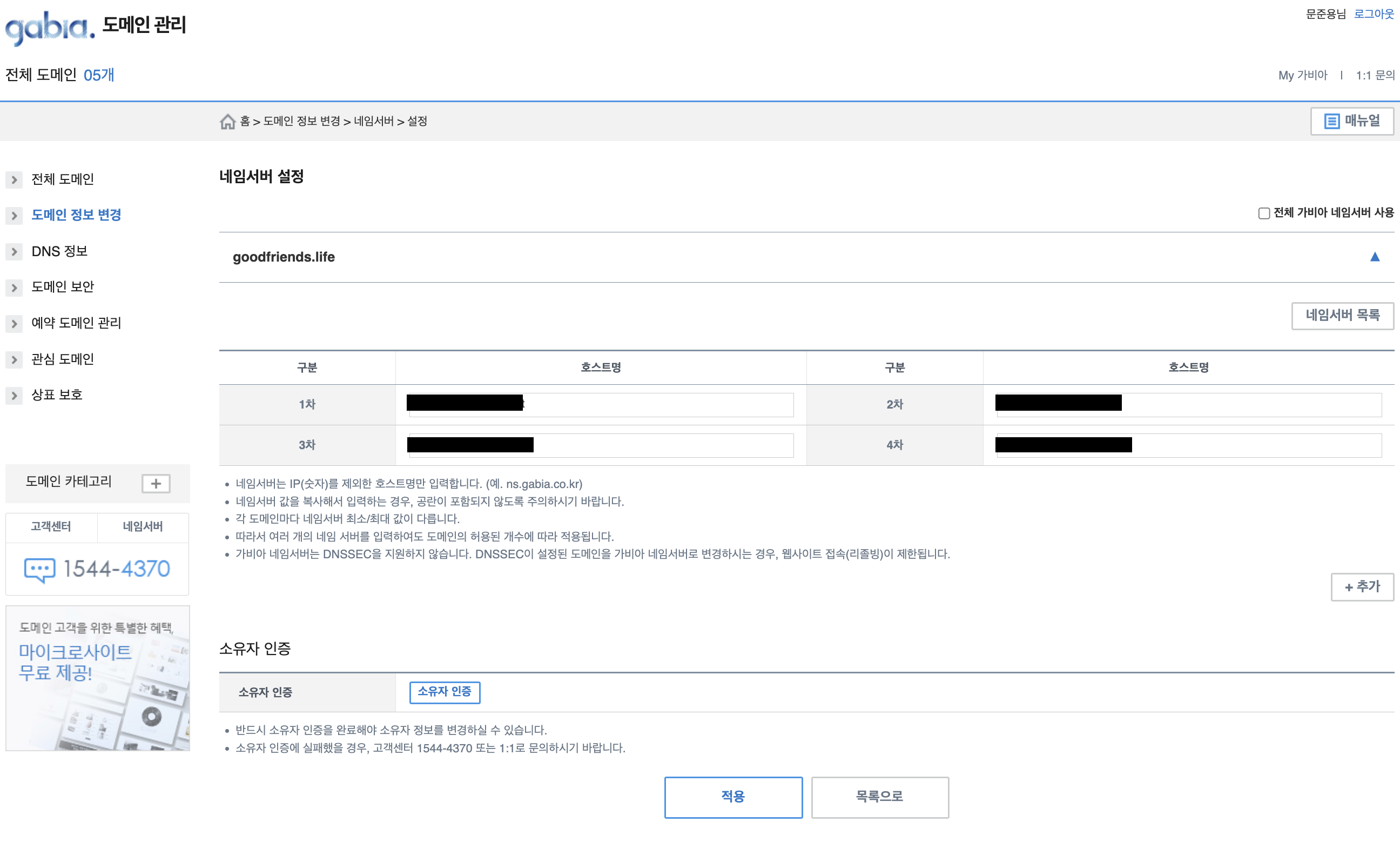
리버스 프록시 서버 설정
Nginx 설치
아래 Nginx 설치부분은 Spring Boot 기반으로 작성한 내용입니다.
Nginx 서버에 아래의 명령어를 입력하여 운영체제 내 패키지 정보를 업데이트를 하고나서
nginx패키지를 설치한다.sudo apt-get update sudo apt-get install nginx그런 다음, Nginx 버전을 확인한다.
nginx -v # nginx version: nginx/1.18.0 (Ubuntu)현재 리눅스에서 실행 중인 프로세스 목록을 확인하기 위해 아래의 명령어를 입력한다. (nginx만 조회)
ps -ef | grep nginxNginx 리버스 프록시 설정
이제 리버스 프록시를 위한 Nginx 설정을 할 것이다.
이 글은 sites-available/sites-enabled 기반으로 Nginx를 설정했다.
cd /etc/nginx/sites-available vi default위 명령을 실행해서
default파일을 아래의 내용으로 채운다.server { listen 80; server_name your.domain.com; location / { proxy_pass http://192.168.XXX.XXX; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; } }server_name부분에 SSL을 적용할 도메인을 입력해준다. 굿프렌즈의 경우 서버 도메인 이름이goodfriends.pro으로 입력했다.이후에 Certbot이 이
server_name을 기준으로 Nginx 설정 파일을 찾고, 여기에 HTTPS에 대한 설정을 자동으로 추가해줄 것이다.proxy_pass는 프록시 서버가 클라이언트 요청을 전달할 리얼 서버의 주소를 적는다. 리버스 프록시의 큰 목적 중 하나는 실제 서버의 IP 주소를 클라이언트에게 노출하지 않기 위함으로서 여기서는 Private IP를 입력했다. Public IP를 입력해도 큰 차이는 없다.Certbot 설치 및 Let’s Encrypt에서 SSL 인증서 발급
Certbot 공식문서를 참고하여 서버에 HTTPS 설정을 한다.
참고로 굿프렌즈의 경우 AWS EC2 서버를 생성할 때 [애플리케이션 및 OS 이미지]를 Ubuntu Server 20.04 LTS (프리 티어)로 설정했다.
Certbot은 손쉽게 SSL 인증서를 자동 발급할 수 있도록 도와주는 도구이다.Certbot은 우분투의 snap 이라는 패키지 매니저를 사용하여 설치하는 것을 권장한다. 따라서 apt가 아닌snap을 사용하여 설치한다.우선
snap이라는 패키지를 설치하고 이미 설치되어 있는 certbot은 제거한다.# certbot을 설치하기 위한 snap을 설치한다. sudo apt update sudo apt install snapd # 이미 설치되어있는 certbot을 제거한다. sudo apt-get remove certbot그리고 아래의 명령어를 통해 Certbot을 설치하고, SSL 인증서를 발급 받기 위해 nginx에 연결하는 명령어를 입력한다.
# certbot을 설치한다. sudo snap install --classic certbot # certbot이 잘 설치되어있는지 확인한다. sudo ln -s /snap/bin/certbot /usr/bin/certbot # certbot을 nginx에 연결하기 sudo certbot --nginx이메일을 입력하고, 이용약관에 동의/비동의를 한 다음에 사용할 도메인을 입력한다.
이때, 적용할 도메인에 대한 A 레코드가
Amazon Route 53에 반드시 적용되어 있어야 한다.만약 기존에 적용되어 있다면, 아래처럼 도메인 이름을 알려준다.
콤마(,)로 구분하여 여러 도메인을 대상으로도 설정할 수 있지만, 굿프렌즈의 경우 1개의 도메인만 설정하도록 했다.
ubuntu@ip-{프라이빗 IP 주소}:~$ sudo certbot --nginx Saving debug log to /var/log/letsencrypt/letsencrypt.log Enter email address (used for urgent renewal and security notices) (Enter 'c' to cancel): fancy.junyongmoon@gmail.com - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Please read the Terms of Service at https://letsencrypt.org/documents/LE-SA-v1.3-September-21-2022.pdf. You must agree in order to register with the ACME server. Do you agree? - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - (Y)es/(N)o: yes - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Would you be willing, once your first certificate is successfully issued, to share your email address with the Electronic Frontier Foundation, a founding partner of the Let's Encrypt project and the non-profit organization that develops Certbot? We'd like to send you email about our work encrypting the web, EFF news, campaigns, and ways to support digital freedom. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - (Y)es/(N)o: no Account registered. Saving debug log to /var/log/letsencrypt/letsencrypt.log Which names would you like to activate HTTPS for? We recommend selecting either all domains, or all domains in a VirtualHost/server block. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1: goodfriends.pro 2: www.goodfriends.pro - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Select the appropriate numbers separated by commas and/or spaces, or leave input blank to select all options shown (Enter 'c' to cancel): 1 Requesting a certificate for goodfriends.pro Successfully received certificate. Certificate is saved at: /etc/letsencrypt/live/goodfriends.pro/fullchain.pem Key is saved at: /etc/letsencrypt/live/goodfriends.pro/privkey.pem This certificate expires on 2024-01-10. These files will be updated when the certificate renews. Certbot has set up a scheduled task to automatically renew this certificate in the background. Deploying certificate Successfully deployed certificate for goodfriends.pro to /etc/nginx/sites-enabled/default Congratulations! You have successfully enabled HTTPS on https://goodfriends.pro - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - If you like Certbot, please consider supporting our work by: * Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate * Donating to EFF: https://eff.org/donate-le - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -위 과정을 통해 Cerbot은 Let’s Encrypt를 통해 자동으로 SSL 인증서를 발급해준다.
또한 우리가 작성한 Nginx의
default파일을 확인해보면 HTTPS를 위한 여러 설정이 자동으로 추가된 것을 확인할 수 있다.server { server_name your domain.com; location / { proxy_pass http://192.168.XXX.XXX:8080; # set for reverse proxy proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } listen [::]:443 ssl; # managed by Certbot listen 443 ssl; # managed by Certbot ssl_certificate /etc/letsencrypt/live/goodfriends.store/fullchain.pem; # managed by Certbot ssl_certificate_key /etc/letsencrypt/live/goodfriends.store/privkey.pem; # managed by Certbot include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot } server { if ($host = your.domain.com) { return 301 https://$host$request_uri; } # managed by Certbot return 301 https://$host$request_uri; listen 80; listen [::]:80 default_server; server_name your.domain.com; return 404; # managed by Certbot }첫 번째 서버 블록에서
location / { ... }은 모든 요청에 대한 처리 규칙을 정의한다.-
proxy_pass는 실제로 요청을 처리할 upstream 서버의 주소를 설정한다. 이 경우 192.168.XXX.XXX의 IP 주소와 8080 포트로 요청을 전달한다. -
proxy_set_header는 프록시 서버로 전달하는 요청 헤더를 설정한다. -
listen [::]:443 ssl;,listen 443 ssl;을 통해 443 포트에서 SSL을 사용하여 HTTPS 트래픽을 처리한다. -
ssl_certificate로 시작하는 두 줄은 SSL 인증서 및 키의 경로를 설정한다. -
include /etc/letsencrypt/options-ssl-nginx.conf;는 Let’s Encrypt에서 제공하는 Nginx 옵션 파일을 포함하여 보안 설정을 추가하는 것을 의미한다.
두 번째 서버 블록은 HTTP 트래픽을 HTTPS로 리다이렉트하는 역할을 한다.
-
listen 80;,listen [::]:80 default_server;은 80 포트에서 HTTP 트래픽을 처리한다. -
if ($host = your.domain.com) { return 301 https://$host$request_uri; }은 요청 도메인이your domain.com일 경우 HTTPS로 리다이렉트하는 것을 의미한다. -
만약
HOST가 일치하지 않으면404를 반환한다.
Certbot으로 SSL 인증서의 만료 시간 확인
Certbot으로부터 발급받은 인증서의 만료일을 확인하기 위해 아래의 명령어를 입력한다.
ubuntu@ip-{프라이빗 IP 주소}:~$ certbot certificates그러면 아래의 결과와 같이 56일 남은 것을 확인할 수 있다.
Saving debug log to /var/log/letsencrypt/letsencrypt.log - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Found the following certs: Certificate Name: {your.domain.com} Serial Number: {your.serial.number} Key Type: ECDSA Domains: goodfriends.pro // your.domain.com Expiry Date: 2024-01-10 06:43:57+00:00 (VALID: 56 days) Certificate Path: /etc/letsencrypt/live/goodfriends.pro/fullchain.pem Private Key Path: /etc/letsencrypt/live/goodfriends.pro/privkey.pem - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -아쉽게도 Let’s Encrypt에서 발급해주는 SSL 인증서는 90일짜리 단기 인증서이다.
그래서 90일마다 서버에 접속하여 SSL 인증서를 수동으로 다시 발급해줘야 한다.
Certbot에서 이러한 SSL 인증서를 수동으로 다시 발급해주는 것이 아닌 갱신을 하기 위해 아래의 명령어를 입력해주면 된다.
# Certbot이 인증서 갱신을 어떻게 수행할지 테스트 명령어, 이를 통해 갱신 프로세스에 문제가 있는지 확인이 가능하다. ubuntu@ip-{프라이빗 IP 주소}:~$ certbot renew --dry-run여기서 실제로 갱신하기 위해서는
--dry-run을 실행해주면 된다.Crontab SSL 인증서를 갱신하는 설정
하지만, SSL 인증서를 수동으로 다시 발급하거나, 갱신하는 것을 넘어서 자동화를 해주면 매번 SSL 인증서를 신경쓰지 않아도 된다.
리눅스
Crontab을 이용해서 이를 자동화해주면 된다.소프트웨어 유틸리티
cron은 유닉스 계열 컴퓨터 운영 체제의 시간 기반 잡 스케줄러이다. 소프트웨어 환경을 설정하고 관리하는 사람들은 작업을 고정된 시간, 날짜, 간격에 주기적으로 실행할 수 있도록 스케줄링하기 위해 cron을 사용한다. -위키백과-Crontab은 리눅스에서 제공하는 기능으로, 지정된 시간과 날짜에 정기적으로 작업을 수행하는 경우에 사용한다다.즉,
Crontab은 스케줄링 도구로 아래 명령어를 이용해서cron job하나를 생성한다.# Crontab 편집 ubuntu@ip-{프라이빗 IP 주소}:~$ crontab -e기본 에디터는 자신이 가장 잘 사용하는 에디터를 선택하면 된다. 필자는 vim(2번)을 선택했다.
그리고 주석 가장 아래에 아래의 내용을 추가하고 파일을 저장하면 된다.
0 0 * * * certbot renew --post-hook "sudo service nginx reload"위 명령어의 의미를 해석하면,
-
매월, 매일 0시 0분에 certbot을 실행하여 SSL 인증서를 갱신하고, 갱신 이후 nginx의 설정 파일을 reload 해주는 작업을 의미한다.
-
*이 총 5개인데, 왼쪽부터분(0-59),시간(0-23),일(1-31),월(1-12),요일(0-7)순으로 설정이 가능하다. -
요일에서 0과 7은 일요일이고, 1~6이 월요일~토요일이다.
Crontab의 사용은 별도로 공부를 해서 익히거나, https://crontab-generator.org/ 와 같이 제너레이터를 사용하는 방법도 있다.마지막으로
Crontab을 재실행하는 명령어를 아래와 같이 입력해주면, 이후부터는 매월, 매일 0시 0분에 자동으로 SSL 인증서를 갱신할 것이다.ubuntu@ip-{프라이빗 IP 주소}:~$ service cron startReference
-
https://docs.nginx.com/nginx/admin-guide/web-server/reverse-proxy/
-
https://certbot.eff.org/
-
https://crontab-generator.org/
-
-
왜 HTTPS를 사용하나요?
HTTPS를 사용하는 이유
-
HTTPS에서
S는 secure을 의미한다. 즉, 기존의 HTTP 보다 안전하다는 얘기다. -
무엇으로부터 안전하냐면, 크게 둘로 나뉜다.
누군가가 도청할 수 있는 HTTP
-
먼저, [1] 내가 어떤 사이트에 보내는 정보를 다른 누군가 훔쳐보지 못하게 한다.
-
네이버에 접속해서 아이디와 비밀번호를 입력하고 로그인 버튼을 누르면,
-
이 두 정보가 인터넷을 타고, 네이버의 서버로 전송된다.
-
그런데 그냥
HTTP로 보내게 되면 이 암호가 입력한 텍스트 그대로, 누구든 알아볼 수 있는 형식으로 보내진다.
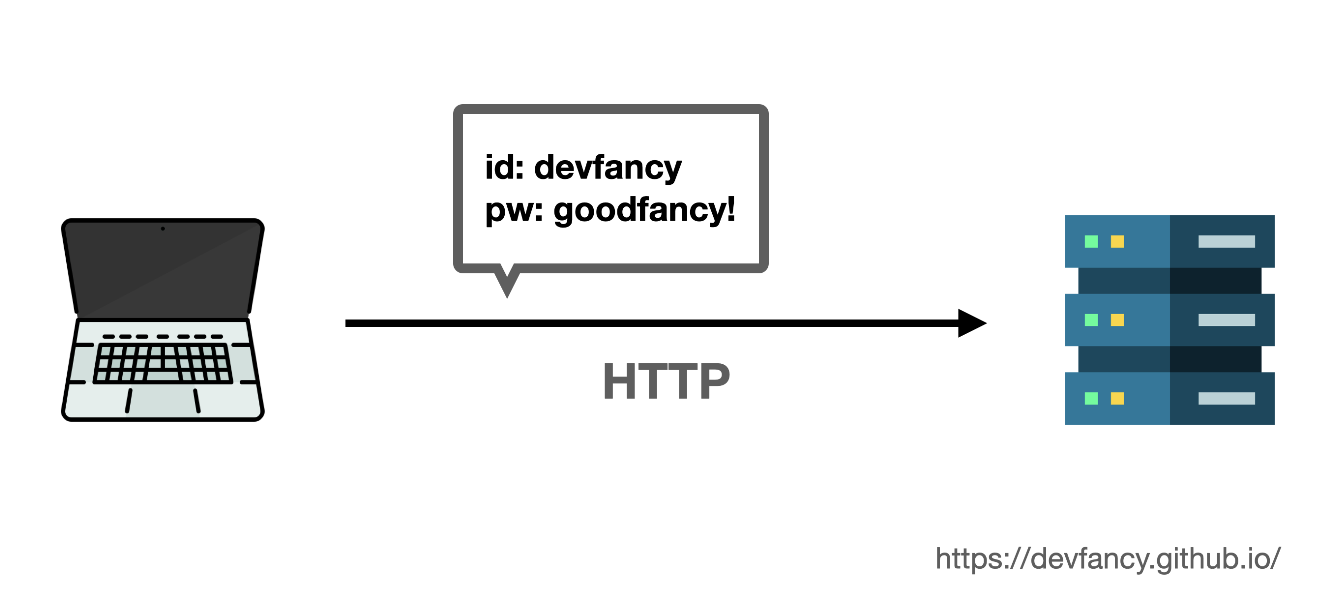
-
만약 누군가가 이 정보를 중간에 들여다보면(도청), 나의 네이버 아이디와 비밀번호를 알게되어 버린다.
-
하지만,
HTTPS는 네이버만 알아볼 수 있는 알 수 없는 텍스트로 변경해서 보내게 된다.
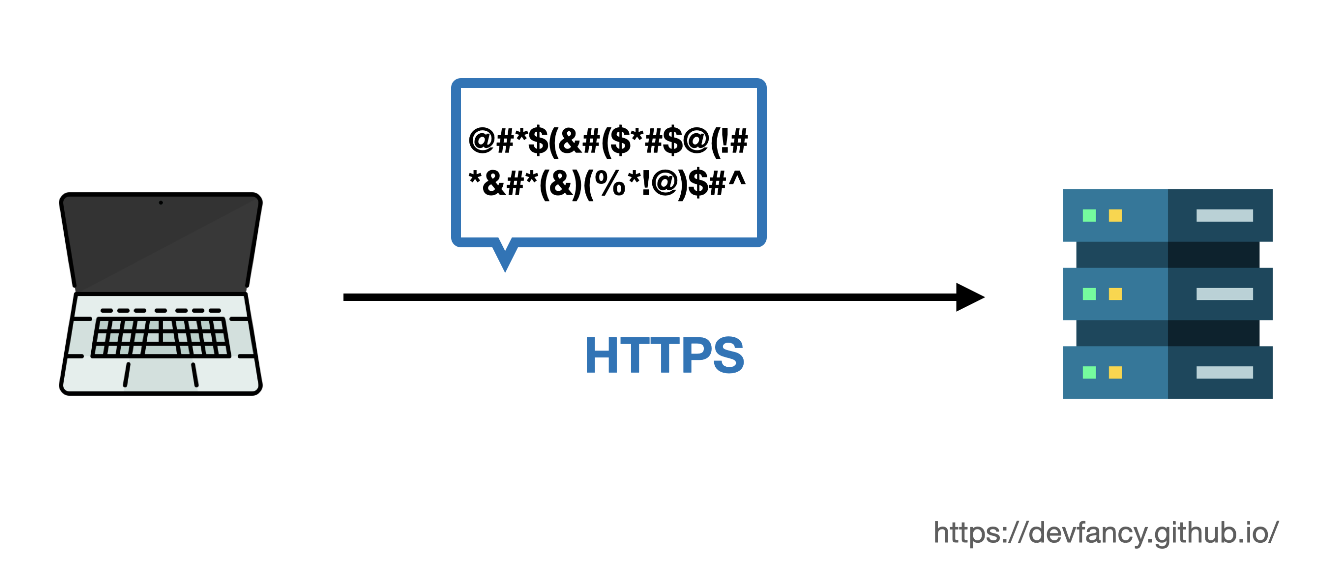
- 그러면, 누군가가 들여다봐도 뭐라도 쓴 건지 알아볼 수 없게 된다.
-
신뢰할 수 없는 HTTP
-
다른 하나는, [2] 내가 접속한 사이트가 진품인지, 신뢰할 수 있는 사이트인지 판별해준다.
-
HTTP를 사용한 요청, 응답에서는 통신 상대를 확인하지 않는다.
-
네이버를 클릭해서 들어갔는데,네이놈이라는 피싱 사이트인 경우가 있다. -
거기에 네이버의 아이디와 비밀번호를 입력하게 되면, 나의 네이버 계정을 알게된다.
-
돈과 관련 있는 은행같은 온라인뱅킹 사이트의 경우 더 큰일이 나게 된다.
-
HTTPS는 이러한 수상한 사이트를 걸러낼 수 있도록 해준다. -
기관으로부터 검증된 사이트만 주소에 HTTPS 사용이 허가되고, HTTP만 사용되는 사이트들은
"안전하지 않음"와 같은 표시가 뜨게 된다.

-
-
요약하자면,
HTTPS는 [1] 내가 사이트에 보내는 정보들을 제 3자가 못보게 하고, [2] 접속한 사이트가 믿을 만한 곳인지를 알려준다.
대칭키와 비대칭키
- 위에서 설명한 두 보안 기능이 어떤 원리로 구현되는지 알아보기 이전에 대칭키와 비대칭키 개념부터 알아보자.
대칭키
-
대칭키는 동일한 키로암호화와복호화를 같이할 수 있는 방식의 암호화 기법을 의미한다. -
암호화와 복호화를 위해 양쪽이 같은 키를 가져야 한다는 점에서 이 키를
대칭키라고 한다.
암호화: 어떤 정보를 외부에 노출시키지 않기 위해 변형하는 것을 의미한다.
복호화: 반대로 암호화된 데이터를 원본으로 복원하는 것을 의미한다.
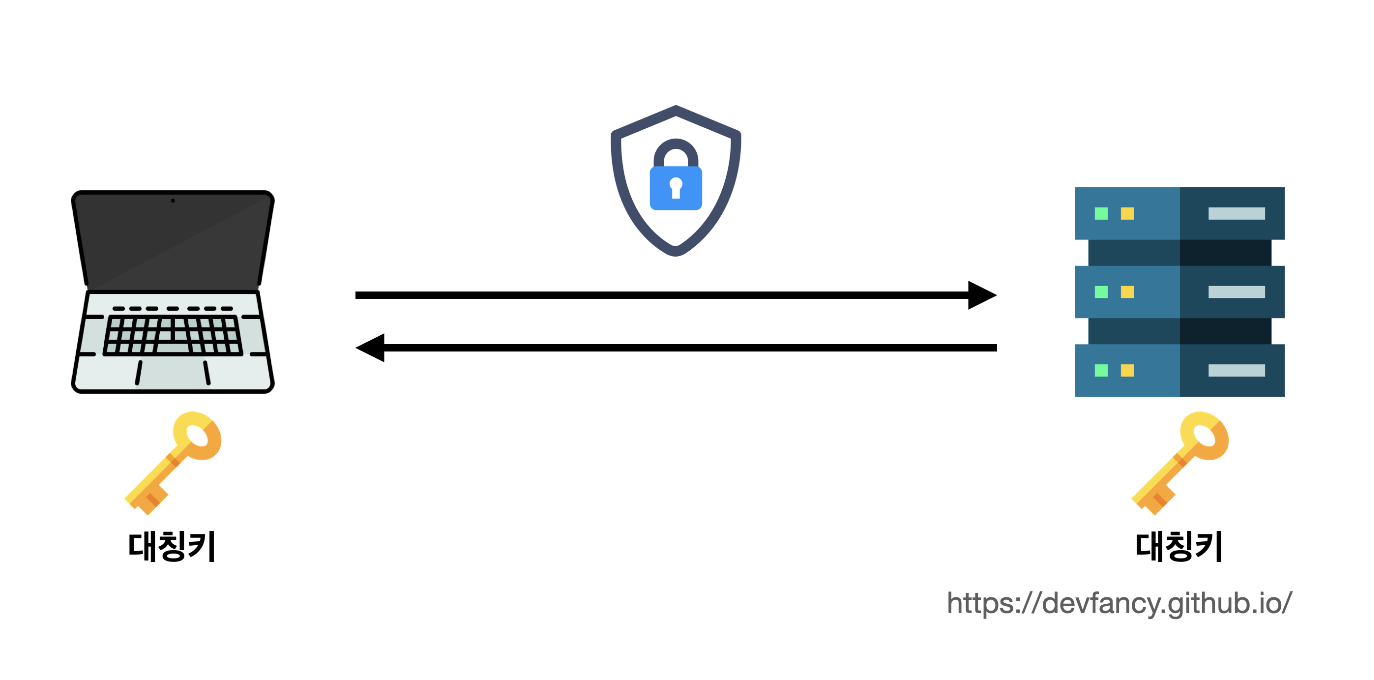
-
네이버에 로그인하는 상황을 가정해보면, 내가 로그인할 때 아이디와 비밀번호를 대칭키로 이용해서
암호화하고, -
네이버에서는 이를
복호화해서 인식할 수 있다. -
그러면 중간에 누가 이걸 훔쳐보더라도 알아볼 수 없게 된다.
-
그런데 대칭키는 큰 단점이 있다.
-
어떻게 이 동일한 키를 애초에 양쪽이 공유하느냐는 것이다.
-
결국 한 번은 한쪽에서 다른 한쪽으로
대칭키를 전달해야 하는데, 이 과정에서 제 3자로부터대칭키가 탈취된다면, 제 3자도 정보를 복호화해서 알 수 있게 된다. -
이러한 한계점을 보완하기 위해 1970년대 수학자들에 의해 개발되어 나온 암호화 방식이
비대칭키(공개키)다. (개발자들 사이에서는공개키라고 부른다)
비대칭키(공개키)
-
비대칭키는 키가 두개가 있다.
-
A키로 암호화하면 B키로 복호화할 수 있고, B키로 암호화하면 A키로 복호화하는 방식이다.
이후부터는 공개키(=비대칭키)라고 부르는게 더 이해하기 쉬울 것 같아서
공개키로 부르겠습니다.-
이 방식에 착안해서 두개의 키 중 하나를 공개키, 다른 하나를 비공개 키로 지정한다.
-
아래 그림을 통해 자세히 살펴보면 다음과 같다.
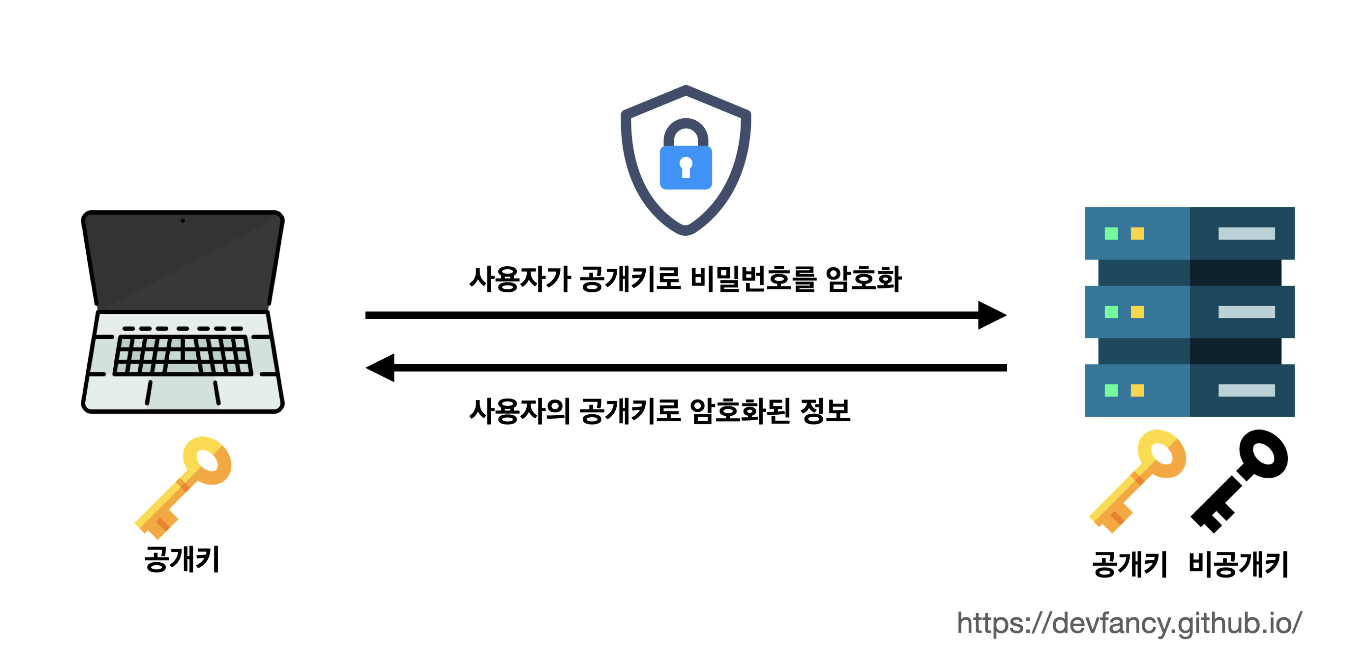
-
네이버 서버는 이 두개의 키들 중 하나는 비밀로 보관하고(개인키), 다른 하나를 대중에게 공유하는 공개키를 제공한다고 가정했을 때,
-
우리가 비밀번호를 암호화해서 네이버에 보내는 과정에서, 중간에 누군가가 가로채도 같은
공개키로는 해당 암호문을 풀 수가 없다. -
이 암호문을 볼 수 있는 건
비공개키(개인키)를 가진 네이버 회사만 가능하다. -
즉,
비공개키(개인키)가 없으면복호화가 불가능하기 때문에 대칭키 방식의 단점을 극복할 수 있다. -
이 원리로 이제 사용자는 개인 정보들을 안심하고 네이버에 보낼 수 있다.
그런데, 이 사이트가 네이버라는 걸 어떻게 증명하나요?
-
네이버에서 우리에게 보내는 정보들은 그 일부가 이 네이버의
개인키로 암호화가 되어 있다. -
우리가 네이버의
공개키로 풀어서 알아볼 수 있는 건 네이버의개인키로 암호화된 정보들 뿐이다. -
신뢰할 수 있는 기관에게 네이버의 공개키만 검증해주면, 이 기준으로 안전하게 네이버를 이용할 수 있다.
- 여기서 신뢰할 수 있는 기관은 민간 기업으로
CA(Certificate Authority)라고 부른다.
- 여기서 신뢰할 수 있는 기관은 민간 기업으로
-
하지만 공개키 방식의 문제점은 대칭키 방식보다 암호화 연산시간이 더 소요되어 비용이 크다.
-
결론적으로 대칭키 방식의 장점이 공개키 방식의 단점이 되고, 대칭키 방식의 단점이 공개키 방식의 장점이 된다.
-
그래서
SSL은 각 방식이 가진 단점 때문에 하나의 방식만 채택하지 않고 두 방식 모두 적절히 섞어서 사용한다.
SSL(Secure Socket Layer): Netscape Communications Corporation에서 서버와 웹 브라우저간의 보안을 위해 만든 프로토콜로, 공개키 방식과 대칭키 방식을 혼합해서 사용한다.
SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 만들 수 있게 도와주고, 서버와 브라우저가 민감한 정보를 주고받을 때 해당 정보가 도난당하는 것을 막아준다.
참고로 SSL 3.0버전은 IETF에서 표준으로 제정되어 TLS라는 이름을 갖게 되었다.
SSL 통신 과정
SSL은 공개키 방식과 대칭키 방식을 적절히 혼합해서 사용하는데, 이를 보다 더 구체적으로 정리하면,-
SSL은 공개키 방식으로 대칭키를 안전하게 전달한다. -
그리고 이 대칭키를 활용해서 암호화와 복호화를 하고 서버와 브라우저간 통신을 한다.
-
통신이 끝나면 종료한다.
이렇게 됨으로써 대칭키를 중간에 탈취당하지 않고, 공개키 방식보다 빠르게 통신할 수 있게 된다.
SSL 통신 과정을 살펴보면 아래와 같은 세가지 과정으로 진행된다.
HandShake-> 통신 -> 통신 종료앞서 이야기한 것처럼 HTTP는 통신 상대를 확인하지 않는다. 클라이언트가 서버로부터 받은 공개키가 진짜인지 가짜인지 판별하기 위해
CA(Certicifate Authority)라는 제 3자를 통해 가능하다.CA는 정말 엄격한 인증 과정을 거쳐야 될 수 있다고 한다. 이 과정을 조금 더 자세히 알아보자.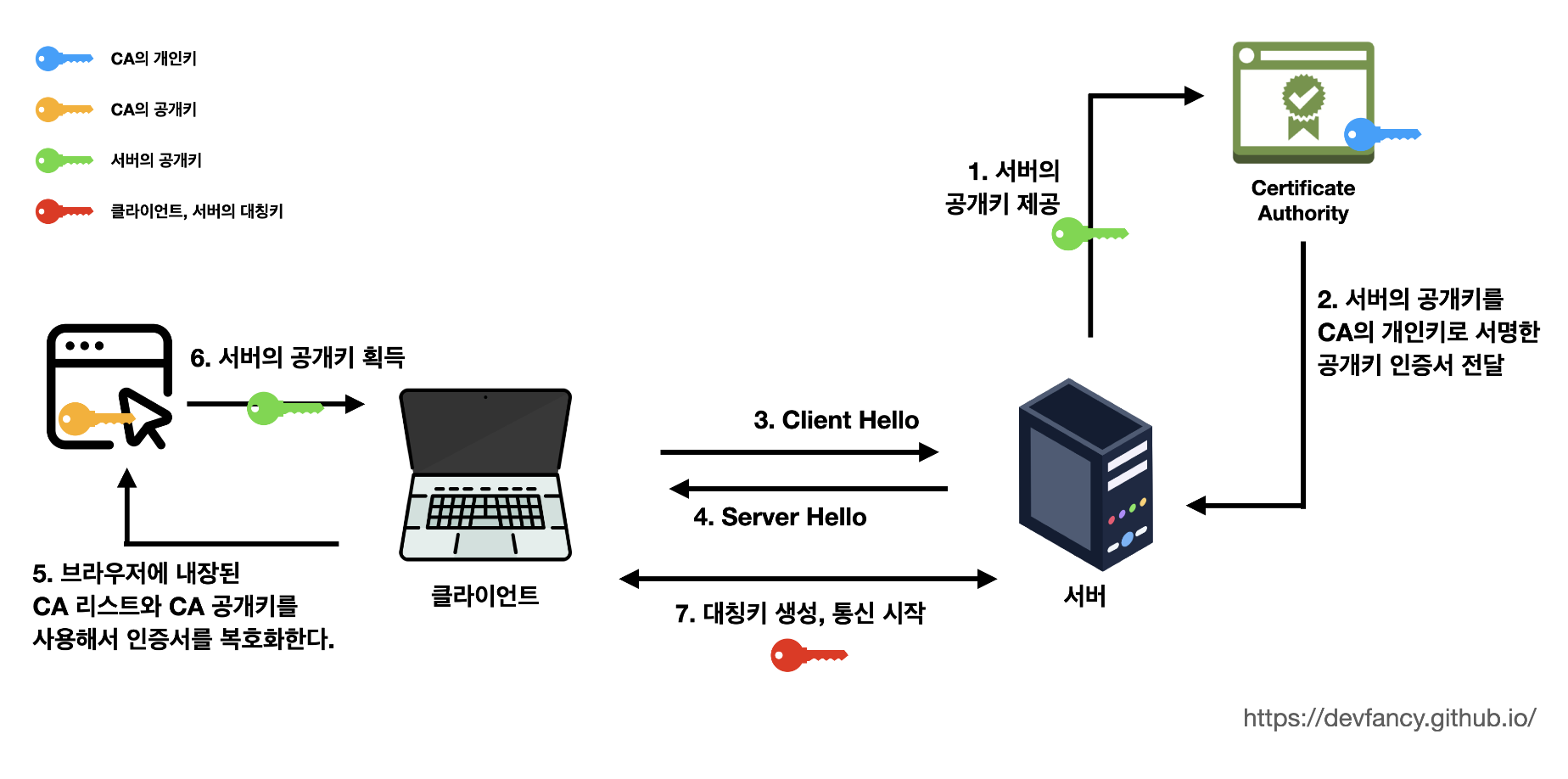
[1] 먼저 서버는
CA에게 자신의공개키를 건넨다.- 그러면 CA는 서버의 공개키를
CA의 개인키로 암호화하여 서명한다.
[2] 이렇게 암호화된 것을
공개키 인증서(Public Key Certificate)라고 한다. 서버는 이공개키 인증서를 클라이언트에게 보낸다.HandShake(악수)
SSL 통신은 데이터를 주고 받기 이전에 어떻게 데이터를 암호화할지, 믿을 만한 서버인지 등에 대한 과정을 확인한다.[3] 클라이언트가 서버에 접속한다. 이 단계를
Client Hello라고 한다. 이 단계에서 주고 받은 정보는 아래와 같다.-
클라이언트 측에서 생성한 랜덤 데이터
-
클라이언트가 지원하는 암호화 방식들 ⇒ 클라이언트가 가능한 암호화 방식을 서버에 알려주기 위함
[4] 서버는
Client Hello에 대한 응답으로Server Hello를 하게 된다.(이때, 클라이언트에게공개키 인증서전달) 이 단계에서 주고 받은 정보는 아래와 같다.-
서버 측에서 생성한 랜덤 데이터
-
서버가 선택한 클라이언트의 암호화 방식 ⇒ 선택한 암호화 방식을 클라이언트에게 알려주기 위함
[5]
클라이언트는서버의 인증서가CA에 의해 발급된 것인지 확인한다. 이때, 브라우저에 내장된CA리스트와 CA 공개키를 사용해서 인증서를 복호화한다.-
성공적으로 인증서가 복호화 됬다면, 서버가 전달한
공개키 인증서가CA의 개인키로 암호화된 문서임이 보증된 것이다. -
즉, 올바른 서버임을 신뢰 할수 있게된다.
-
서버를 신뢰할수 있으므로 클라이언트는
서버가 생성한 랜덤 데이터와클라이언트가 생성한 랜덤 데이터를 조합하여pre master secret이라는 키를 생성한다. -
이때,
공개키 방식을 사용한다.
[6]
서버의 공개키를 전달받은 클라이언트는pre master secret를 암호화해서 서버로 전송한다.-
서버는 자신의 비공개키를 통해
pre master secret를 복호화한다. -
이를 통해, 클라이언트와 서버는 안전하게 같은
pre master secret를 가진다.
[7] 서버와 클라이언트가 공개키 방식을 통해
pre master secret를master secret라는대칭키를 생성한다.-
클라이언트는 서버로부터 받은 공개키를 이용하여 자신의 대칭키를 암호화한다.
-
클라이언트는 이렇게 암호화된 대칭키를 서버에게 전달한다.
-
서버는 전달받은 암호화된 대칭키를 자신의 비공개키(개인키)를 통해 복호화하고, 이 복호화로 인해 클라이언트로부터 대칭키를 얻을 수 있게 된다.
-
그리고 클라이언트와 서버는
HandShake가 종료되었음을 서로에게 알린다.
통신
-
이 대칭키를 통해 실제로 클라이언트와 서버가 암호화된 메시지를 주고받을 수 있게 된다.
다른 말로 표현하면,
master secret라는대칭키를 통해 클라이언트와 서버는 데이터를 암호화/복호화하면서 주고 받게 된다.
통신 종료
-
데이터의 전송이 끝나면
SSL 통신이 끝났음을 서로에게 알려준다. -
그리고 사용한 대칭키인
master secret은 폐기한다.
마치며
-
지난 8-9월에 굿프렌즈 프로젝트에서 백엔드와 프론트엔드 서버에 HTTPS를 설정하는 작업을 진행했었다.
-
HTTPS의 중요성과 그에 기반한 지식들을 복습하기 위해 이 글을 작성하게 되었다.
-
처음에는 완전히 이해가 안됐지만, 계속 보다보니 이해가 점점 되어가는 내 자신에게 뿌듯함을 안겨줬다.
-
HTTPS에 대한 더 깊은 지식은 나중에 이어 학습하고 정리하자.
Reference
-
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8