흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[데이터베이스개론] 정규화 과정
이 글은
데이터베이스 개론교재와 ERD와 정규화 과정를 공부하고 필자의 생각을 포함하여 정리한 내용으로 사실과 맞지 않는 부분이 있을 수 있습니다.-
이 글은 정규화를 이용해 데이터베이스를 설계하는 방법에 대해 소개한다.
-
정규화는 데이터베이스를 설계한 후 설계 결과물을 검증하기 위해 사용하기도 한다. -
두 설계 방법은 데이터 설계 결과물이 비슷한 수준을 유지하므로 상황에 따라 적절한 방법을 선택하면 된다.
이상 현상의 개념
-
데이터베이스를 잘못 설계하면 불필요한 데이터 중복이 발생하여 릴레이션에 대한 데이터 삽입, 수정, 삭제 연산을 수행할 때 부작용이 발생하는데
이러한 부작용을
이상(anomaly)현상이라 부른다. -
이상 현상을 제거하면서 데이터베이스를 올바르게 설계해 나가는 과정이
정규화다. -
정규화의 필요성과 방법을 구체적으로 알아보기에 앞서 먼저 이상 현상을 종류별로 알아보자.
이상 현상의 종류
- 이상 현상에는 삽입 이상(insertion anomaly), 갱신 이상(update anomaly), 삭제 이상(deletion anomaly)이 있다.
삽입 이상
삽입 이상(insertion anomaly)은 새 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제를 말한다.
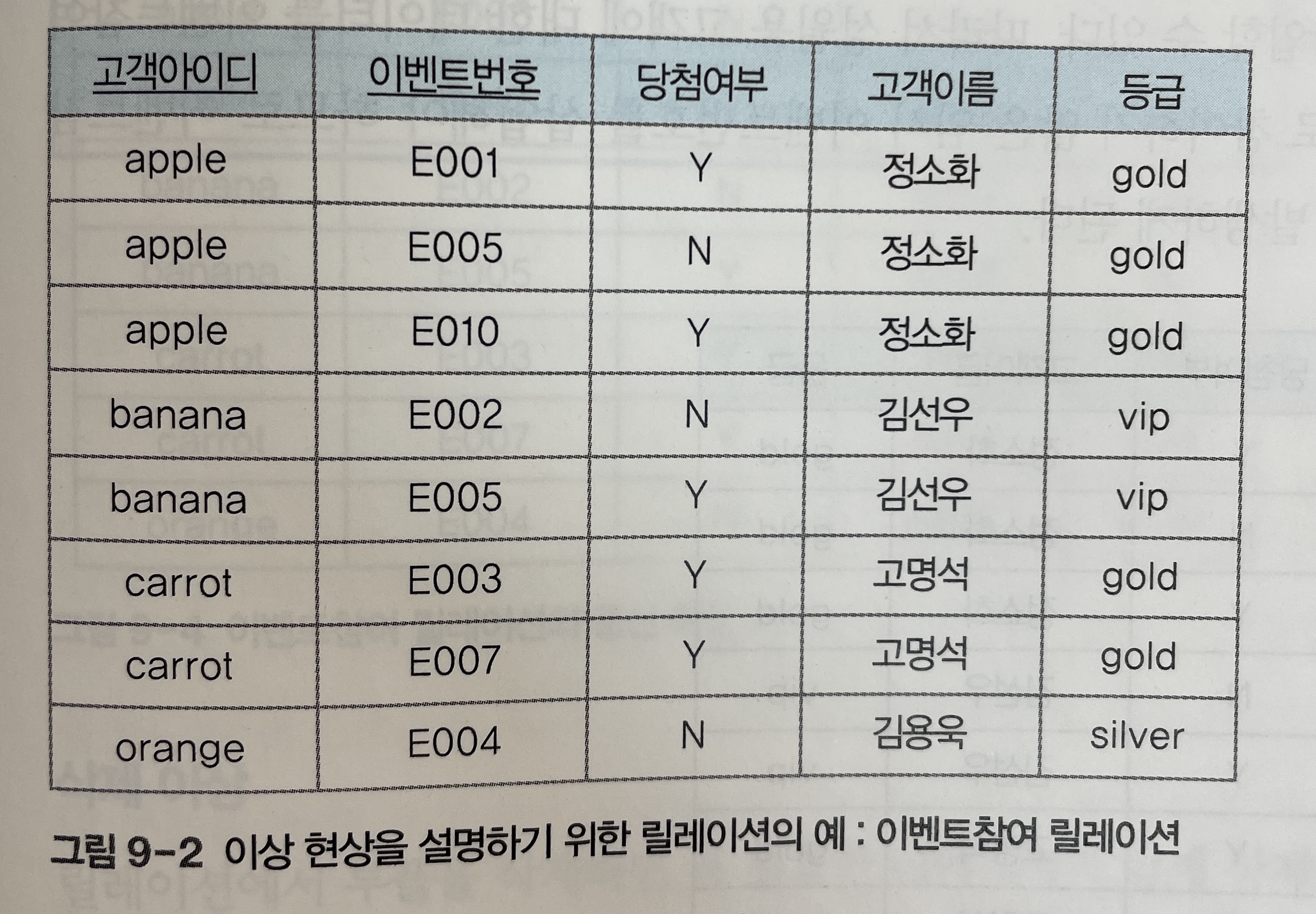
-
[그림 9-2]의 이벤트참여 릴레이션은 고객들이 이벤트에 참여한 결과를 저장하고 있는 릴레이션이다.
-
여기서 이벤트참여 릴레이션에 아이디가
melon이고, 이름이성원용, 등급이gold인 신규 고객에 대한 데이터를 삽입한다고 가정해보자. -
이 고객이 참여한 이벤트가 아직 없다면, 다시 말하면, 이벤트번호와 당첨여부가 존재하지 않는다면 해당 릴레이션에 신규 고객에 대한 데이터를 삽입할 수 없다.
-
따라서 신규 고객(성원용)와 같이 이벤트참여 릴레이션에 삽입하려면 실제로 참여하지 않는 임시 이벤트번호를 삽입해야 하는데, 이때 발생하게 되는 것이
삽입 이상이다.
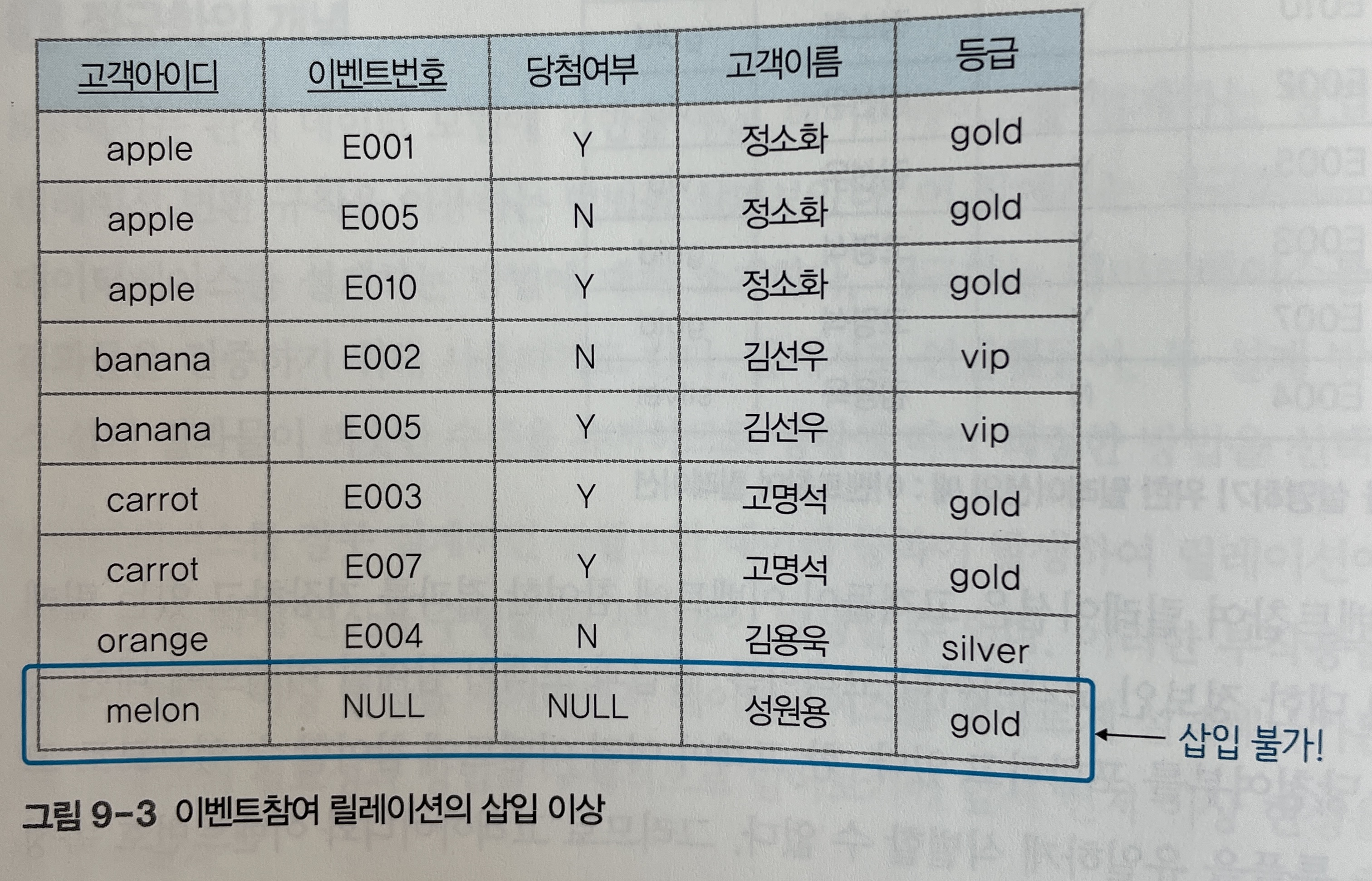
갱신 이상
갱신 이상(update anomaly)은 릴레이션의 중복된 튜플(=행)들 중 일부만 수정하여 데이터가 불일치하게 되는 모순이 발생하는 문제를 말한다.
-
[그림 9-2]의 이벤트참여 릴레이션에는 아이디가
apple인 고객에 대한 튜플(행)이 3개 존재하여, 고객아이디, 고객이름, 등급 속성의 값이 중복되어 있다. -
만약 아이디가
apple인 고객의 등급이gold에서vip로 변경하게 된다면,apple고객에 대한 튜플 3개의 등급 속성 값이 모두 수정되어야 한다. -
그렇지 않고, 아래 [그림 9-4]와 같이 2개의 튜플만 등급이 수정되면
apple고객이 서로 다른 등급을 가지는 모순이 생겨갱신 이상이 발생하게 된다.
삭제 이상
-
삭제 이상(deletion anomaly)은 릴레이션에서 튜플(행)을 삭제하면 꼭 필요한 데이터까지 함께 삭제하여 데이터가 손실되는 연쇄 삭제 현상을 말한다. -
아이디어가
orange인 고객이 이벤트 참여를 취소하여 [그림 9-2]의 이벤트참여 릴레이션에서 관련된 튜플을 삭제해야 한다면, 아래 [그림 9-5]와 같이 하나의 튜플만 삭제하면 된다. -
그런데 이 튜플은 이벤트에 대한 정보(이벤트번호, 당첨여부) 뿐만 아니라 의도치 않게 해당 고객에 대한 정보인 고객아이디, 고객이름, 등급에 대한 정보도 같이 손실되는
삭제 이상이 발생하게 된다.

정규화의 필요성
-
[그림 9-2]의 이벤트참여 릴레이션에서 여러
이상 현상이 발생하는 이유는 관련 없는 속성들이 하나의 릴레이션에 모아두고 있기 때문이다. -
이상 현상이 발생하지 않기 위해서는 관련 있는 속성들로만 릴레이션을 구성 해야 하는데 이를 위해 필요한 것이
정규화다. -
정규화는 이상 현상이 발생하지 않도록, 릴레이션을 관련있는 속성들로만 구성하기 위해 릴레이션을분해하는 과정이다. -
정규화과정에서 고려해야 하는 속성들 간의 관련성을함수적 종속성(FD, Functional Dependency)이라고 한다.
함수 종속
이후부터는
함수적 종속성대신함수 종속성이라는 용어를 사용하기로 한다.함수적 종속성: 테이블의 특정 컬럼 A의 값을 알면 다른컬럼 B값을 알 수 있을 때,컬럼 B는 컬럼 A에 함수적 종속성이 있다고 한다.-
함수 종속 관계는 X -> Y를 표현하고 X를
결정자, Y를종속자라고 한다. -
일반적으로 릴레이션에 함수적 종속성이 하나 존재하도록 정규화를 통해 릴레이션을 분해한다.
-
아래 [그림 9-7]의 고객 릴레이션을 대상으로 속성 간의 함수 종속 관계를 판단해보자.
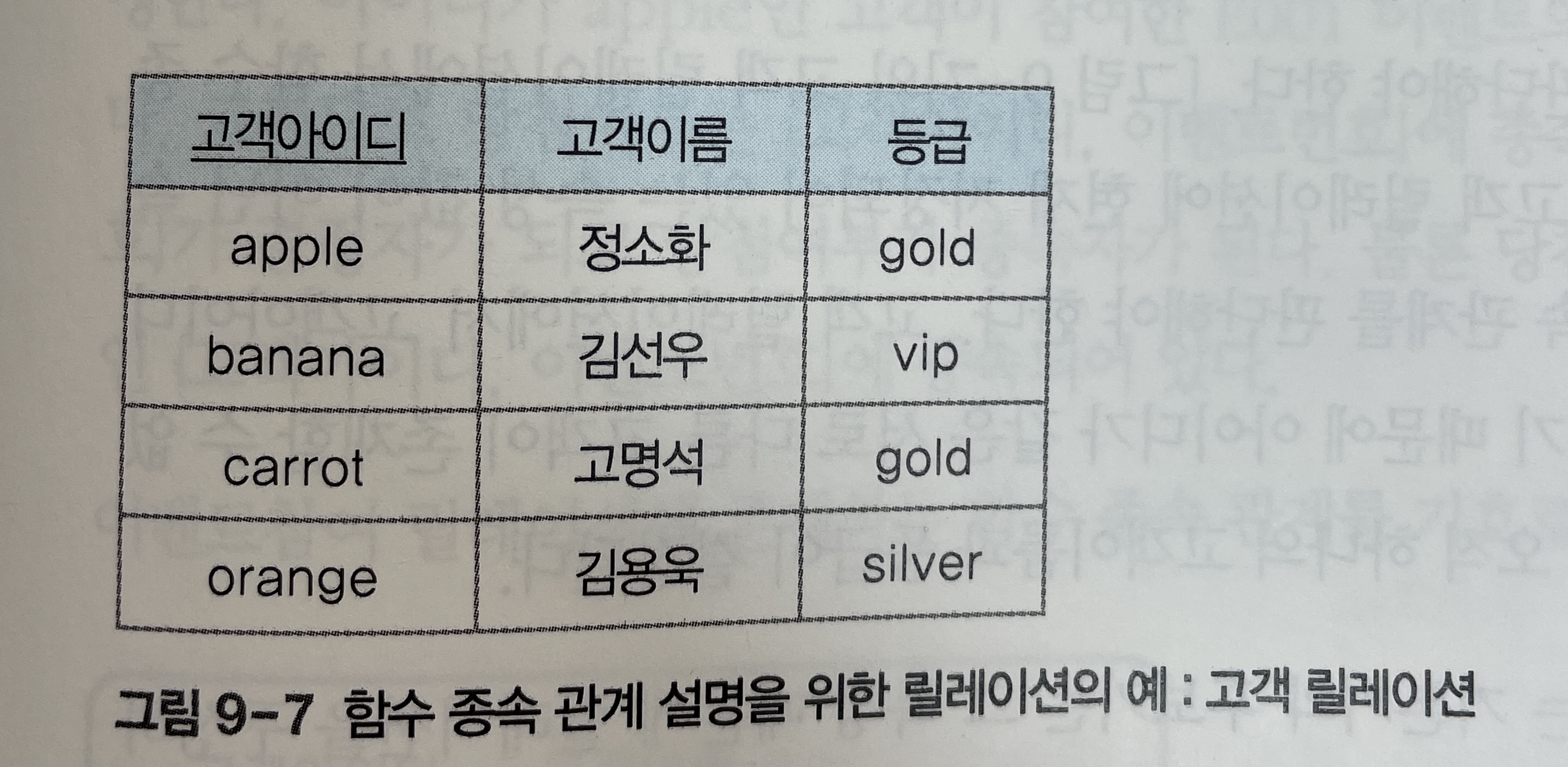
-
고객 릴레이션에서 각
고객아이디속성 값에 대응되는고객이름속성과등급속성의 값이 단 하나이므로, -
고객아이디가고객이름과등급을 결정한다고 볼 수 있다. -
그러므로 고객 릴레이션에서
고객아이디는 결정자가 되고,고객이름과등급은 종속자가 된다. -
함수 종속에는 2가지 종류가 있다.
-
완전 함수 종속은 릴레이션에서 속성 집합 Y가 속성 집합 X 전체에 함수적으로 종속되어 있다는 의미이다. -
부분 함수 종속은 속성 집합 Y가 속성 집합 X의 전체가 아닌 일부분에도 함수적으로 종속됨을 의미한다.
-
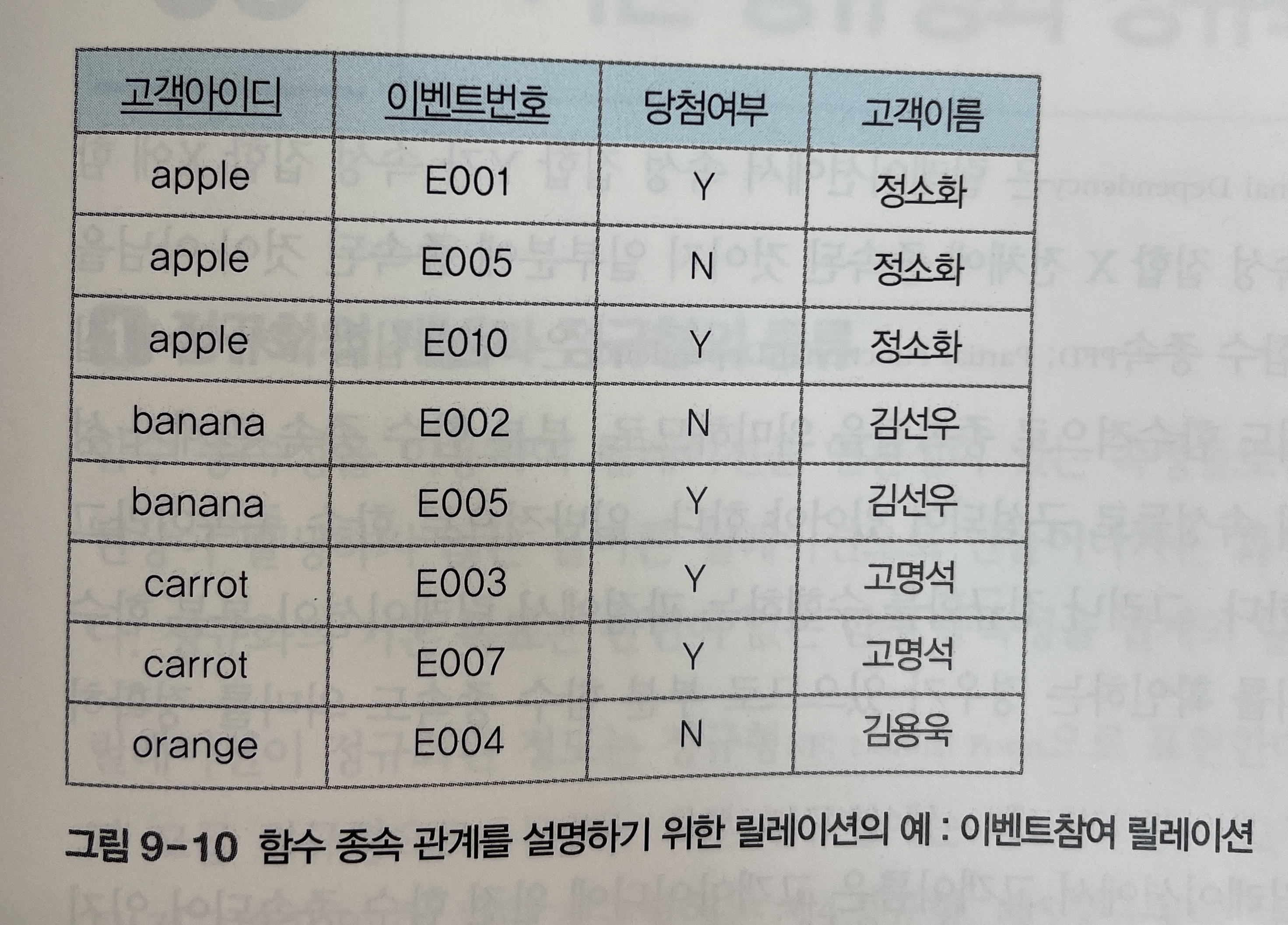
- 예를 들어, [그림 9-10]의 이벤트참여 릴레이션에서
고객이름은 고객아이디에 완전 함수 종속되어 있지만, {고객아이디, 이벤트번호}에는 부분 함수 종속되어 있다. 그리고당첨여부는 {고객아이디, 이벤트번호}에 완전 함수 종속되어 있다.
기본 정규형과 정규화 과정
정규화의 개념과 정규형의 종류
-
정규화(normalization)란 함수적 종속성을 이용하여 릴레이션을 연관성이 있는 속성들로만 구성되도록 분해해서, 이상 현상이 발생하지 않는 올바른 릴레이션으로 만들어나가는 과정을 말한다. -
정규화의 기본 목표는 관련이 없는 함수 종속성을 별개의 릴레이션으로 표현하는 것이다. -
릴레이션이 정규화된 정도는
정규형(NF, Nomal Form)으로 표현된다. -
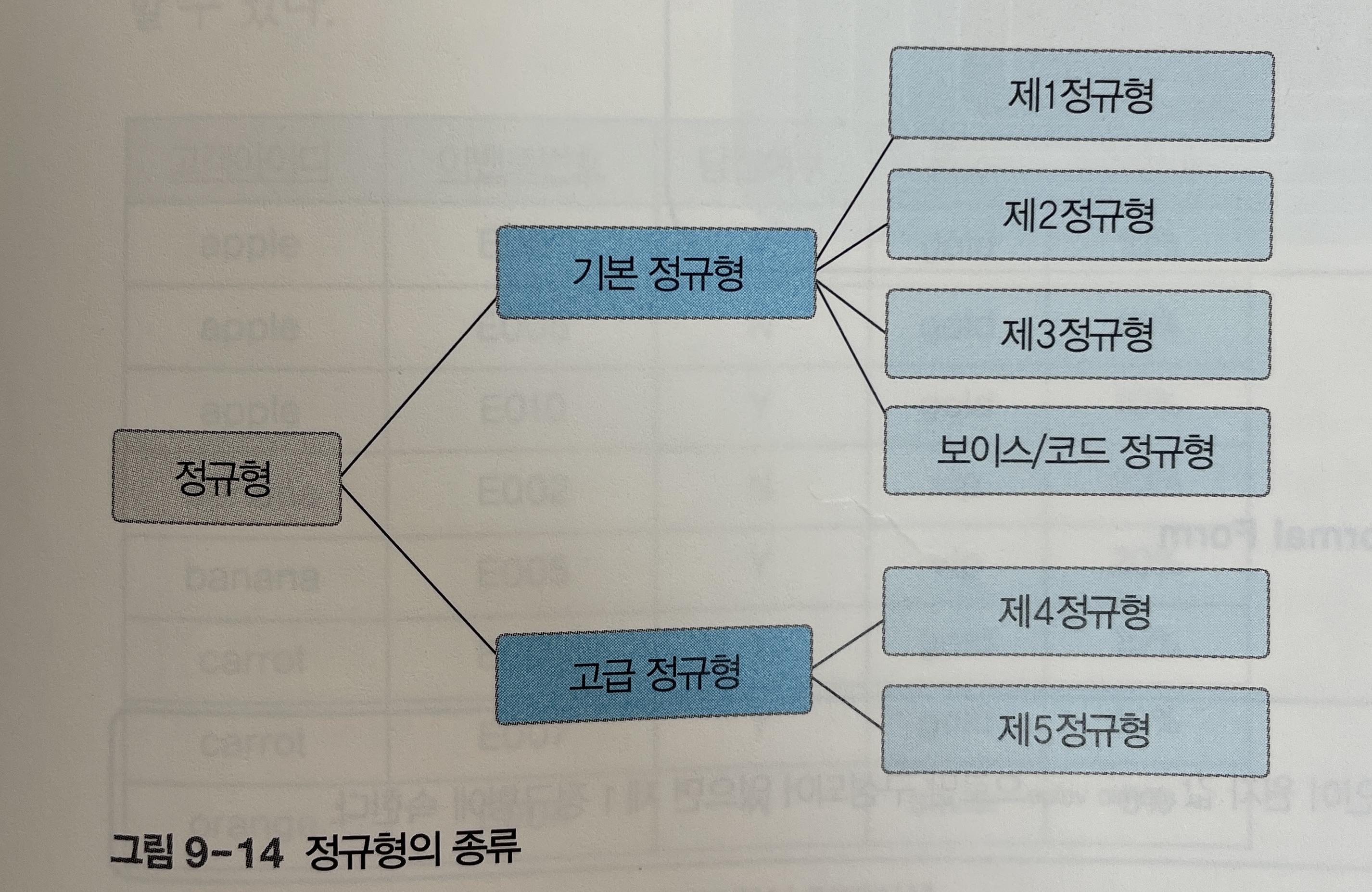
정규형은 크게
기본 정규형과고급 정규형으로 나뉜다.-
기본 정규형에는 제1정규형, 제2정규형, 제3정규형, 보이스/코드 정규형이 있다. -
고급 정규형에는 제4정규형, 제5정규형이 있다.
-
-
각 정규형마다 만족시켜야 하는 제약조건이 존재하며, 정규형의 차수가 높아질수록 요구되는 제약조건이 많이지고 엄격해진다.
-
일반적으로 차수가 높은 정규형일수록 바람직한 릴레이션일 수 있다.
-
하지만 모든 릴레이션이 제5정규형에 속해야 되는 것은 아니므로 릴레이션의 특성을 고려해서 적합한 정규형을 선택해야 한다.
-
일반적으로
기본 정규형에 속하도록 릴레이션을 정규화하는 경우가 대부분이므로 여기서는기본 정규형을 중심으로 정규화 과정을 알아본다.
제1정규형(1NF)
제1정규형: 릴레이션에 속한 모든 속성의 도메인이 원자값으로만 구성되어 있으면 제 1 정규형에 속한다.-
릴레이션이 제1정규형에 속하려면 릴레이션에 속한 모든 속성이 더는 분해되지 않는 원자 값만 가져야 한다.
-
즉, 다중 값을 가질 수 있는 속성은 분리되어야 한다.
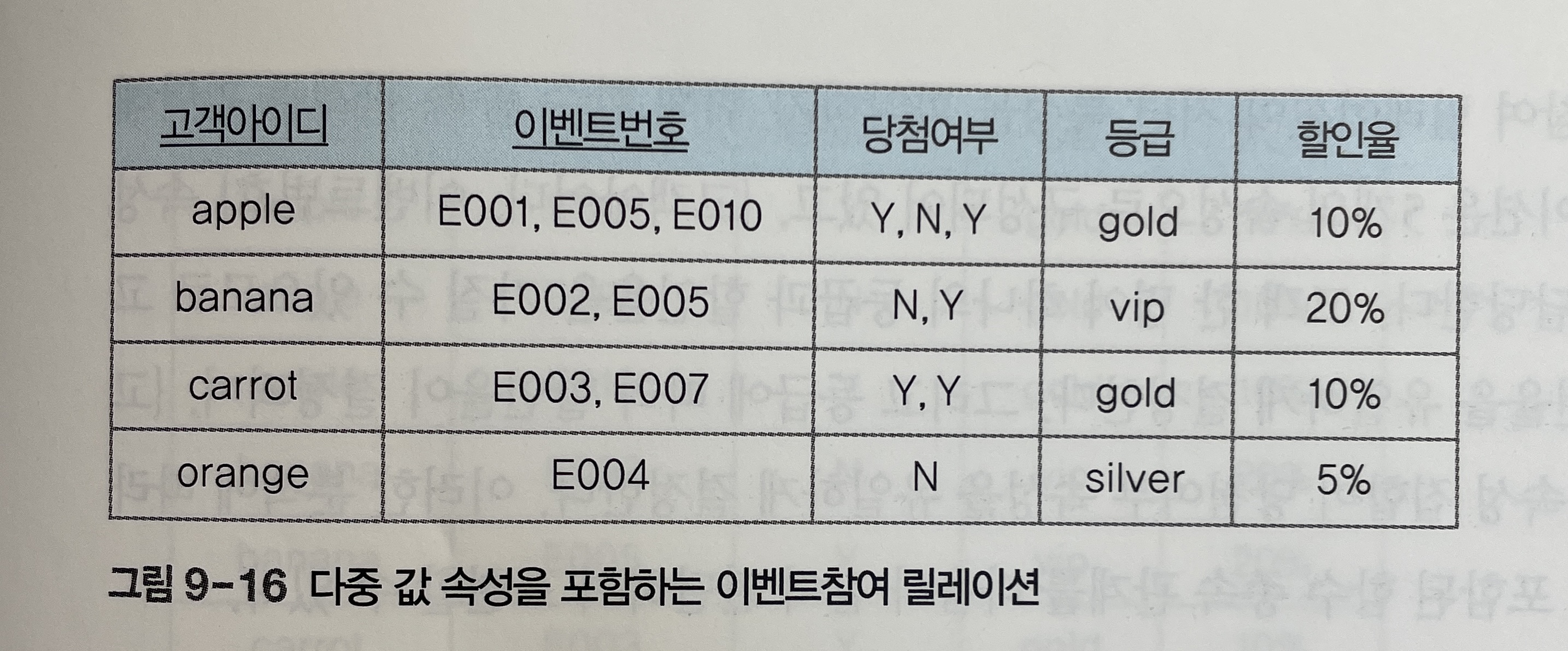
-
[그림 9-16]의 이벤트참여 릴레이션에서 이벤트번호 속성과 당첨여부 속성은 하나의 고객아이디에 해당하는 값이 여러 개다.
-
제1정규형에 속하게 하려면 튜플마다
이벤트번호와당첨여부속성 값을 하나씩만 포함되도록 분해하여, 모든 속성이 원자값을 가지도록 해야 한다. -
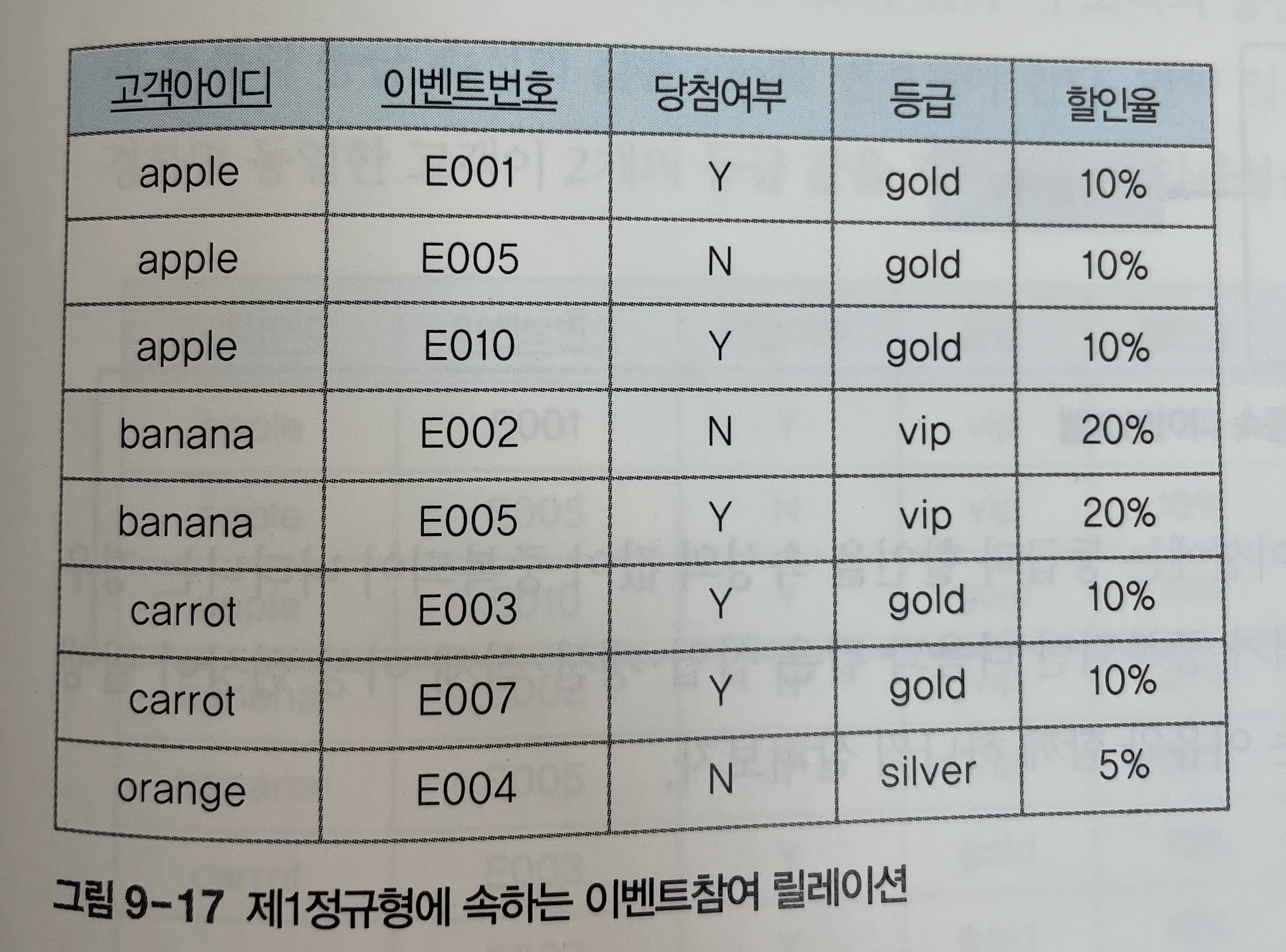
제1정규형을 만족하도록 정규화를 수행한 결과는 아래 [그림 9-17]과 같다.
-
제1정규형을 정리하면 아래와 같다.
-
[1] 모든 속성은 원자 값을 가져야 한다.
-
[2] 다중 값을 가질 수 있는 속성은 분리되어야 한다.
-
-
[그림 9-17]은 제1정규형에 속하지만, 불필요한 데이터 중복으로 인해 이상 현상이 발생하는 릴레이션이 있을 수 있다.
-
이러한 문제를 해결하기 위해서는 부분 함수 종속이 제거되도록 이벤트참여 릴레이션을 분해해야 한다.
-
릴레이션을 분리하여 부분 함수 종속을 제거하면, 분해된 릴레이션들은 제2정규형에 속하게 되고 이상 현상은 발생하지 않게 된다.
제2정규형(2NF)
제2정규형: 릴레이션이 제1정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속되면 제2정규형에 속한다.제2정규형을 만족하게 하려면, 부분 함수 종속을 제거하고 모든 속성이 기본키에 완전 함수 종속되도록 릴레이션을 분해하는 정규화 과정을 거쳐야 한다.
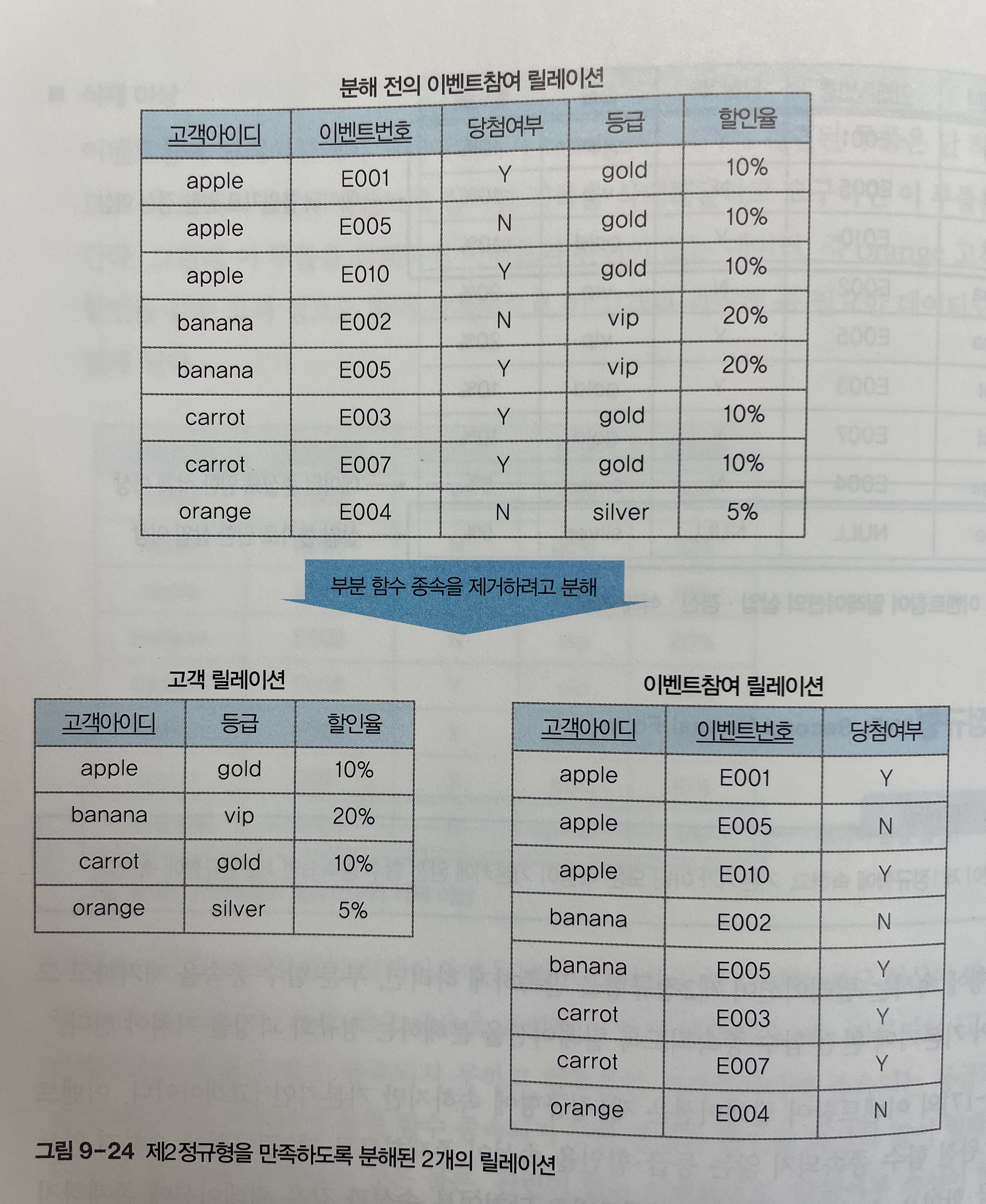
-
이벤트참여 릴레이션에서 기본키인 {고객아이디, 이벤트번호}에 완전 함수 종속되지 않는 등급, 할인율 속성이 존재하므로
-
[그림 9-24]와 같이 2개의 릴레이션으로 분해하면, 분해된
고객릴레이션과이벤트참여릴레이션은 모두 제2정규형에 속하게 된다. -
정규화 과정에서 릴레이션을 분해할 때 주의할 점은, 분해된 릴레이션들을 자연 조인하여 분해 전의 릴레이션으로 다시 복원할 수 있어야 한다.
-
즉, 릴레이션이 의미상 동등한 릴레이션들로 분해되어야 하고, 릴레이션을 분해했을 때 정보 손실이 발생하지 않아야 한다.
-
제2정규형을 정리하면 아래와 같다.
-
[1] 제 1정규형을 만족하고 모든 Non-Key 컬럼은 기본키(PK) 전체에 종속(완전 종속)되어야 한다.
-
[2] 만약 Non-Key 컬럼이 기본키에 종속되어있지 않거나 부분 종속되어 있으면, 기본키에 완전 종속되도록 릴레이션을 분리되어야 한다.
-
[3] 정규화 과정에서 수행되는 릴레이션의 분해는
무손실 분해여야 한다.
-
무손실 분해(nonloss decomposition): 정보의 손실 없이 릴레이션을 분해하는 것을 의미한다.제3정규형(3NF)
-
제3정규형: 릴레이션이 제2정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 이행적 함수 종속이 되지 않으면, 제3정규형에 속한다. -
제3정규형을 살펴보기에 앞서 이를 이해하기 위해 필요한
이행적 함수 종속(transitive FD)을 잠깐 살펴보자. -
릴레이션을 구성하는 3개의 속성 집합 X, Y, Z에 대해 함수 종속 관계 X -> Y 와 Y -> Z가 존재하면 논리적으로 X -> Z가 성립한다.
-
이때 속성 집합 Z가 집합 X에 이행적으로 함수 종속되었다고 한다.
-
제2정규형을 만족하더라도 하나의 릴레이션에 함수 종속 관계가 여러개 존재하고, 논리적으로 이행적 함수 종속 관계가 유도되면 이상 현상이 발생할 수 있다. -
제3정규형을 만족하기 위해서는 릴레이션에서 이행적 함수 종속을 제거해서, 모든 속성이 기본키에 이행적 함수 종속이 되지 않도록 릴레이션을 분해하는 정규화 과정을 거쳐야 한다.
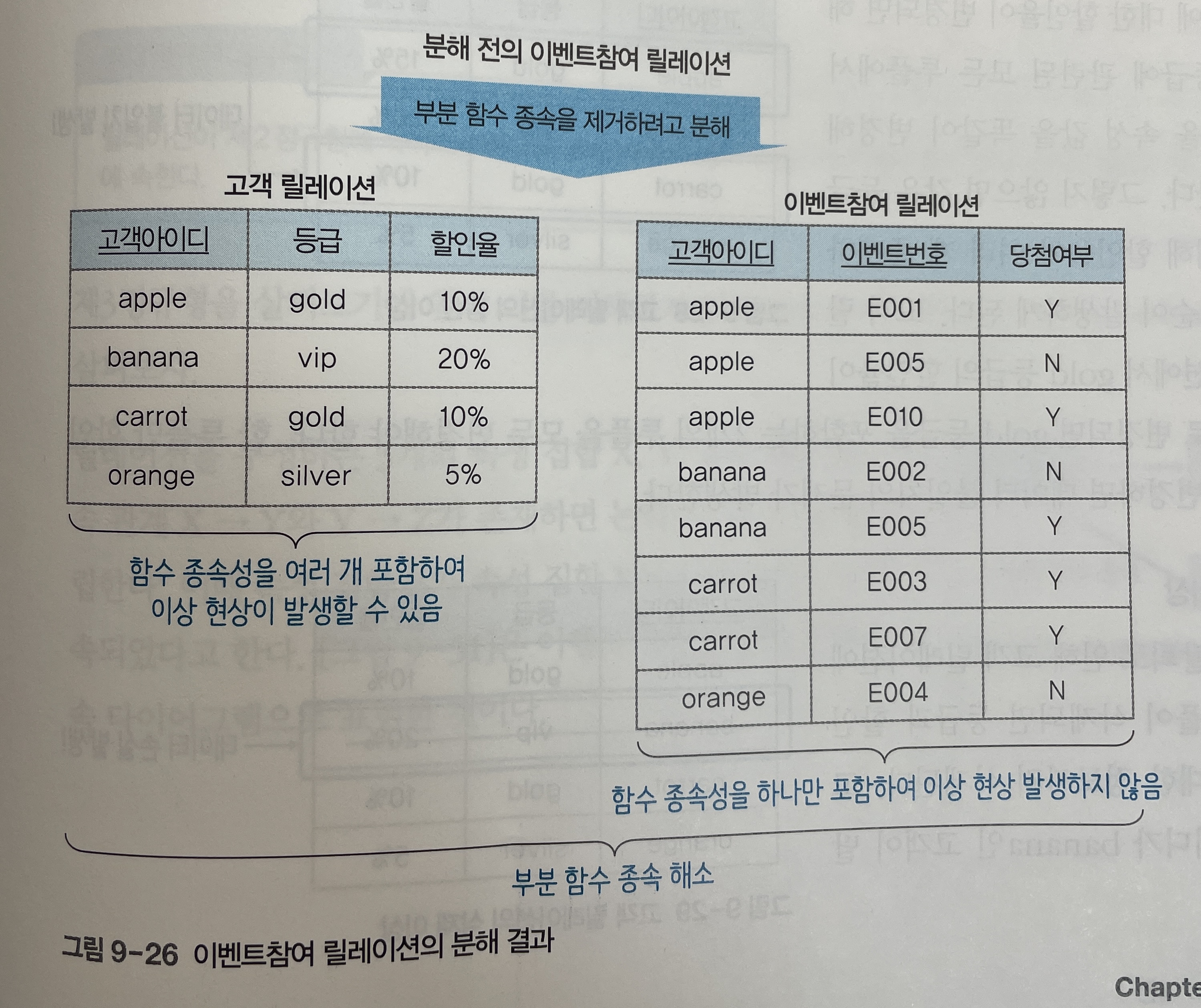
-
위 [그림 9-26]에서 보는 것처럼 고객아이디가 등급을 결정하고, 등급이 할인율을 결정하는 함수 종속 관계로 인해,
-
고객아이디가 등급을 통해 할인율을 결정하는 이행적 함수 종속 관계도 존재한다.
-
이러한 이행적 함수 종속이 나타나는 이유는 함수 종속 관계가 하나의 릴레이션에 여러 개 존재하기 때문이다.
-
따라서
고객 릴레이션에 이상 현상이 발생하지 않도록 하려면 이행적 함수 종속이 나타나지 않게 2개의 릴레이션으로 분해해야 한다. -
제3정규형을 만족하기 위해서 [그림 9-26]의 분해된 고객 릴레이션은 고객아이디 -> 등급, 등급 -> 할인율의 함수 종속 관계를 유지할 수 있도록 아래 [그림 9-32]와 같이 2개의 릴레이션으로 분해하면 된다.

- 아래 [그림 9-33]의 함수 종속 다이어그램에서 확인할 수 있듯이, 릴레이션을 분해하면 하나의 릴레이션에 하나의 관계만 존재하게 되어 이행적 함수 종속으로 인한 이상 현상이 발생하지 않게 된다.

- 고객 릴레이션과 고객등급 릴레이션 모두 기본기가 직접 결정하므로 제3정규형에 속한다.
보이스/코드 정규형(BCNF)
보이스/코드 정규형(BCNFm Boyce/Codd Normal Form): 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키이면 보이스/코드 정규형에 속한다.-
하나의 릴레이션에 여러개의 후보키가 존재할 수도 있는데, 이 경우에는 제3정규형까지 모두 만족하더라도 이상 현상이 발생할 수 있다.
-
이를 해결하기 위해 제3정규형보다 좀 더 엄격한 제약조건을 제시한 것이
보이스/코드 정규형이다. -
[그림 9-26]에서 {고객아이디, 이벤트번호} -> 당첨여부의 함수 종속 관계를 포함하고 있는 분해된
이벤트참여 릴레이션은 {고객아이디, 이벤트번호}가 유일한후보키이자 기본키이면서 함수 종속관계에서도 유일한결정자다. -
그러므로 제3정규형에 속하는
이벤트참여 릴레이션은 보이스/코드 정규형에도 속한다. -
[그림 9-32]에서 고객아이디 -> 등급의 함수 종속 관계를 포함하고 있는 분해된
고객 릴레이션도 마찬가지로 기본키인 고객아이디가 함수 종속 관계에서 유일한 결정자이므로 보이스/코드 정규형에 속한다. -
이제 제3정규형에 속하지만 보이스/코드 정규형에는 속하지 않는 릴레이션의 예를 통해, 후보키가 여러 개인 릴레이션에서 어떠한 이상 현상이 발생할 수 있는지 알아보자.
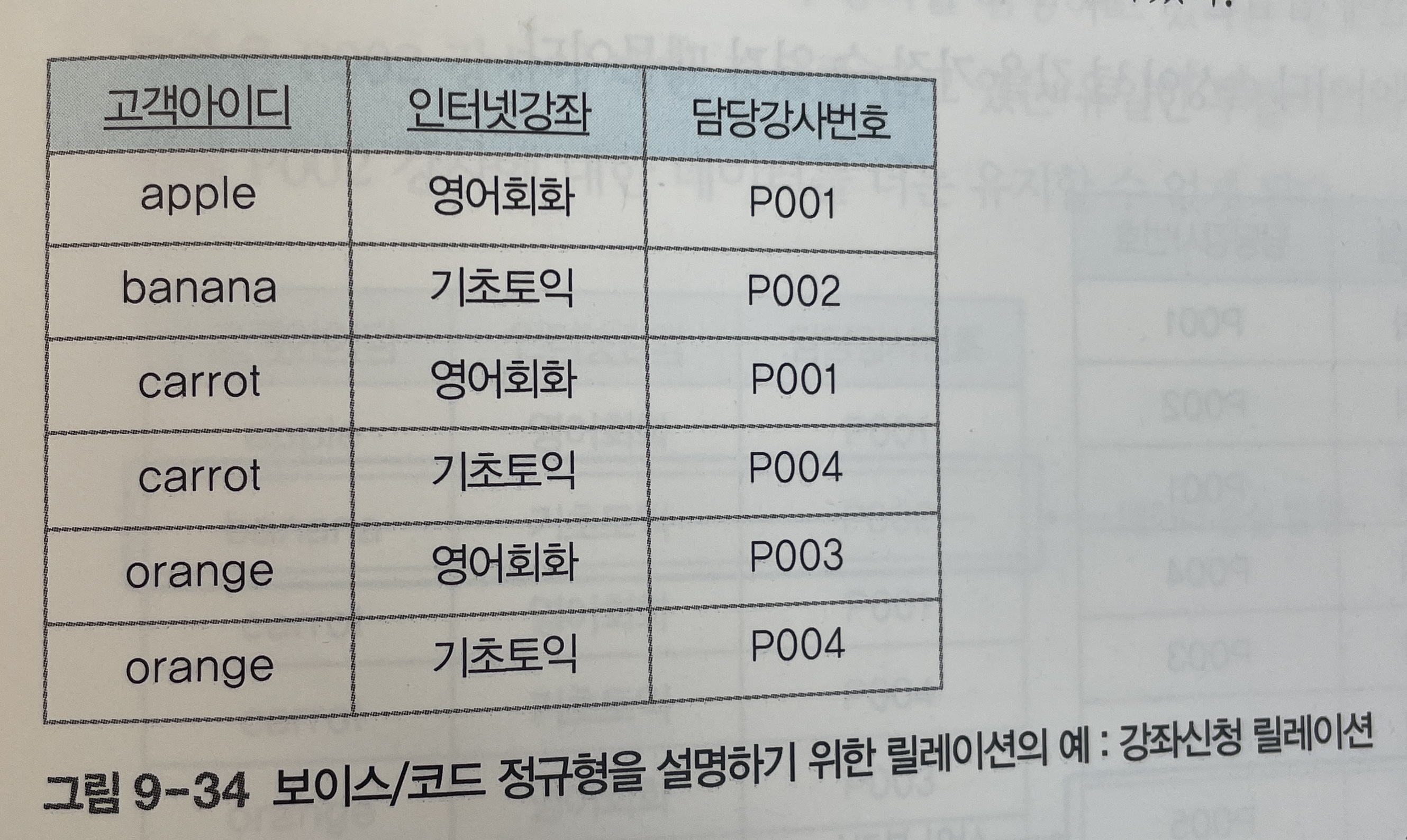
-
[그림 9-34]의 강좌신청 릴레이션은 고객이 인터넷강좌를 신청하면 해당 강좌의 담당강사에 대한 데이터를 저장한다.
-
요구 사항은 다음과 같다고 가정해본다.
-
한 고객이 인터넷강좌를 여러 개 신청할 수 있지만 동일한 인터넷강좌를 여러 번 신청할 수는 없다.
-
그리고 강사 한 명이 인터넷강좌를 하나만 담당할 수 있고, 하나의 인터넷강좌는 여러 강사가 담당할 수 있다.
-
-
그러므로 튜플을 구별할 수 있는 후보키는 {고객아이디, 인터넷강좌}, {고객아이디, 담당강사번호}가 있고 이 중에서 {고객아이디, 인터넷강좌}를 기본키로 선정했다.
-
[그림 9-34]의 강좌신청 릴레이션에서 기본키인 {고객아이디, 인터넷강좌}가 담당강사번호 속성을 함수적으로 결정하는 것은 당연하다.
-
그리고 강사 한 명이 인터넷강좌를 하나만 담당하므로 담당강사번호가 인터넷강좌를 함수적으로 결정한다고 볼 수 있다.
-
강좌신청 릴레이션의 함수 종속 다이어그램은 아래 [그림 9-35]와 같다.
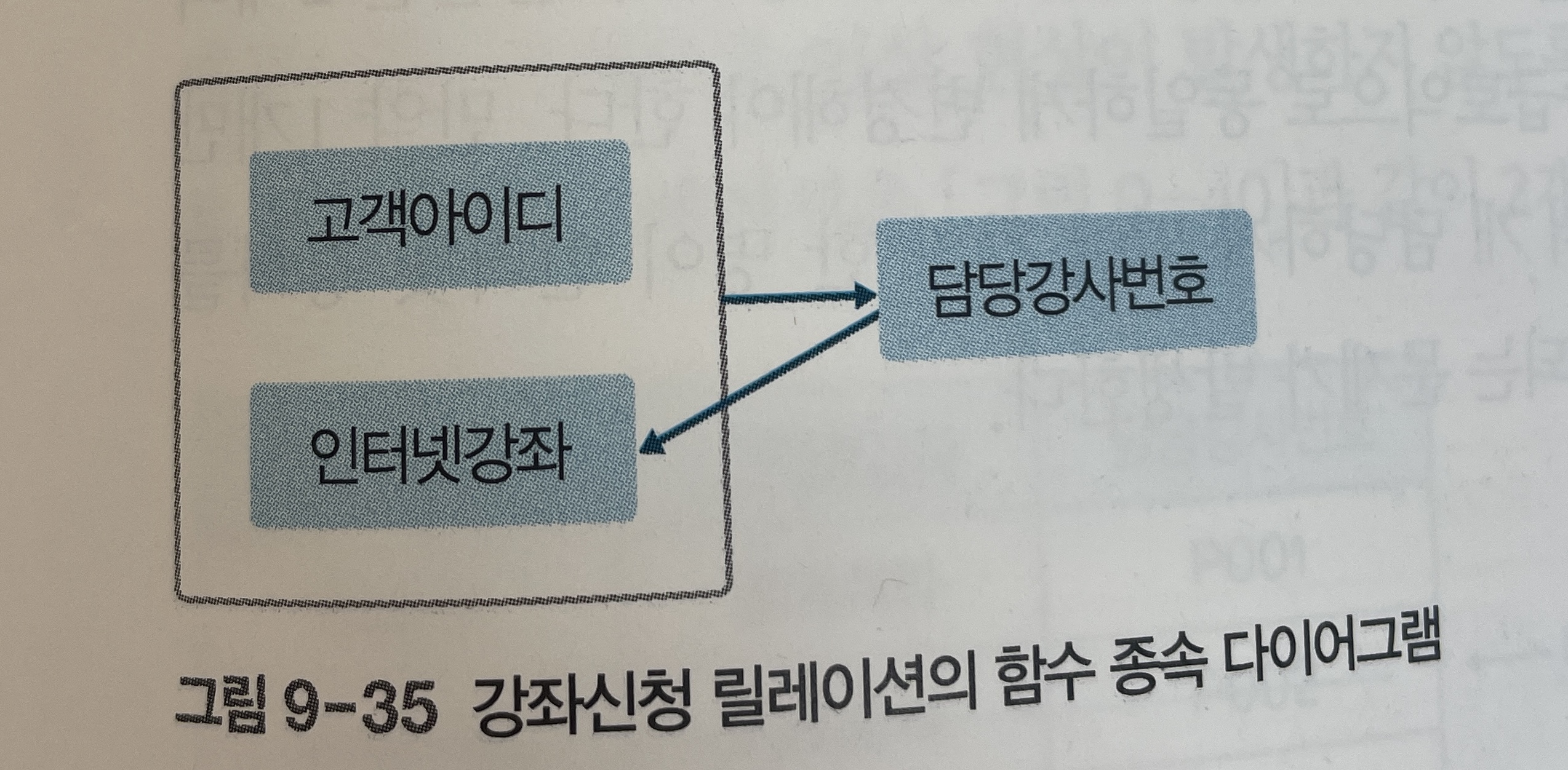
- 하지만 담당강사번호 속성이 후보키가 아님에도 인터넷강좌 속성을 결정하므로 강좌신청 릴레이션은 보이스/코드 정규형에는 속하지 않는다.
후보키: 유일성과 최소성을 만족하는 속성 또는 속성들의 집합이다.
고객아이디속성은 단독으로 고객 튜플을 유일하게 구별할 수 있으므로 후보키가 될 수 있다.- 키에 대해 자세한 설명은 이전에 작성한 [DB] 관계 데이터 모델의 개념 - Key의 종류글을 참고하자.
- 이상현상이 발생하지 않도록 하려면 모든 결정자가 후보키가 될 수 있도록 강좌신청 릴레이션을 아래 [그림 9-40]과 같이 2개의 릴레이션으로 분해해야 된다.
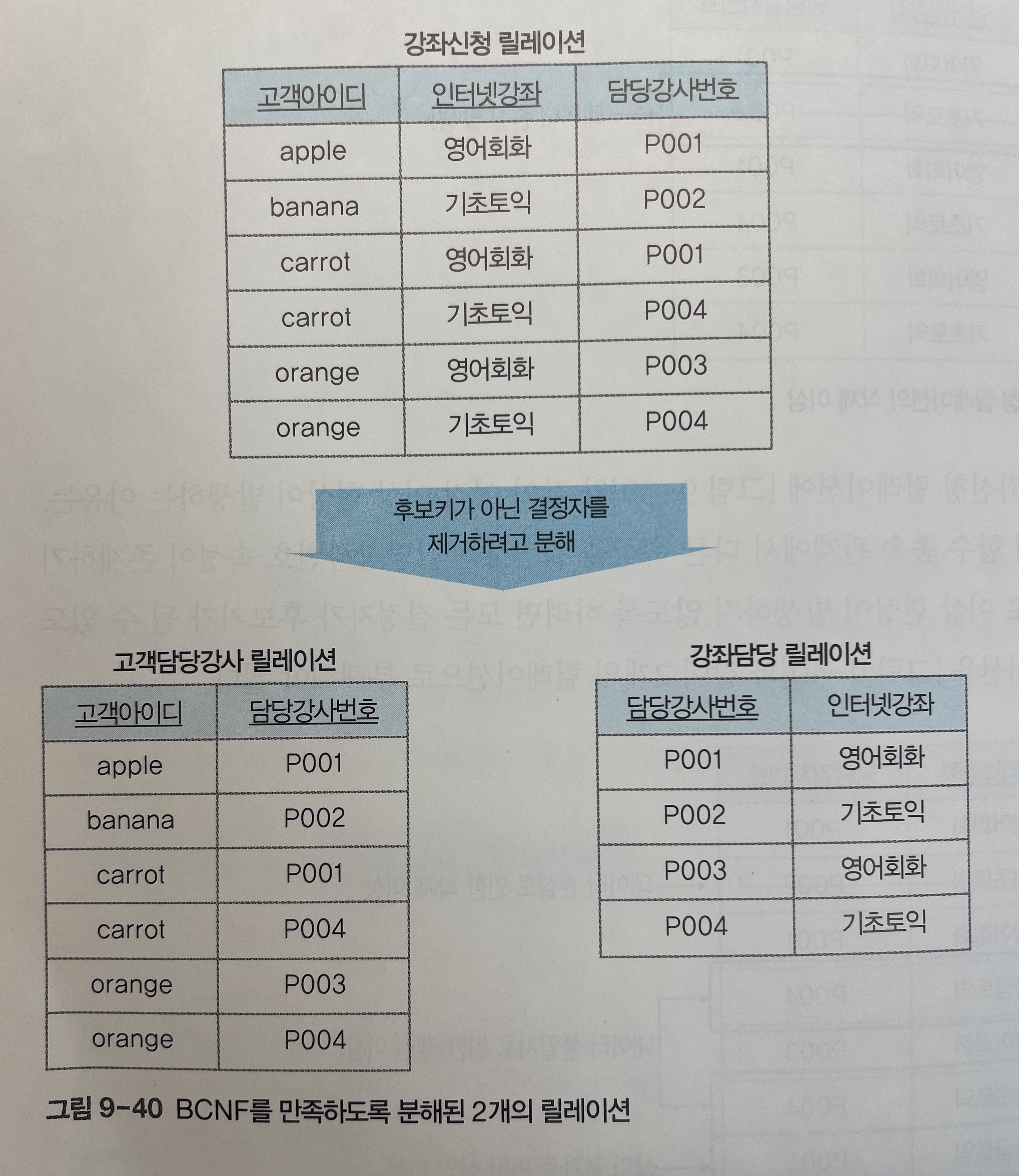
-
고객담당강사 릴레이션은 함수 종속 관계가 성립하지 않는 고객아이디, 담당강사번호 속성으로 구성하고, {고객아이디, 담당강사번호}가 기본키의 역할을 담당한다.
-
강좌담당 릴레이션은 담당강사 -> 인터넷강좌의 함수 종속 관계를 포함하고 있고 담당강사번호가 유일한 후보키이자 기본키다.
-
두 개의 릴레이션 모두 후보키가 아닌 결정자가 존재하지 않아 보이스/코드 정규형에 속한다.
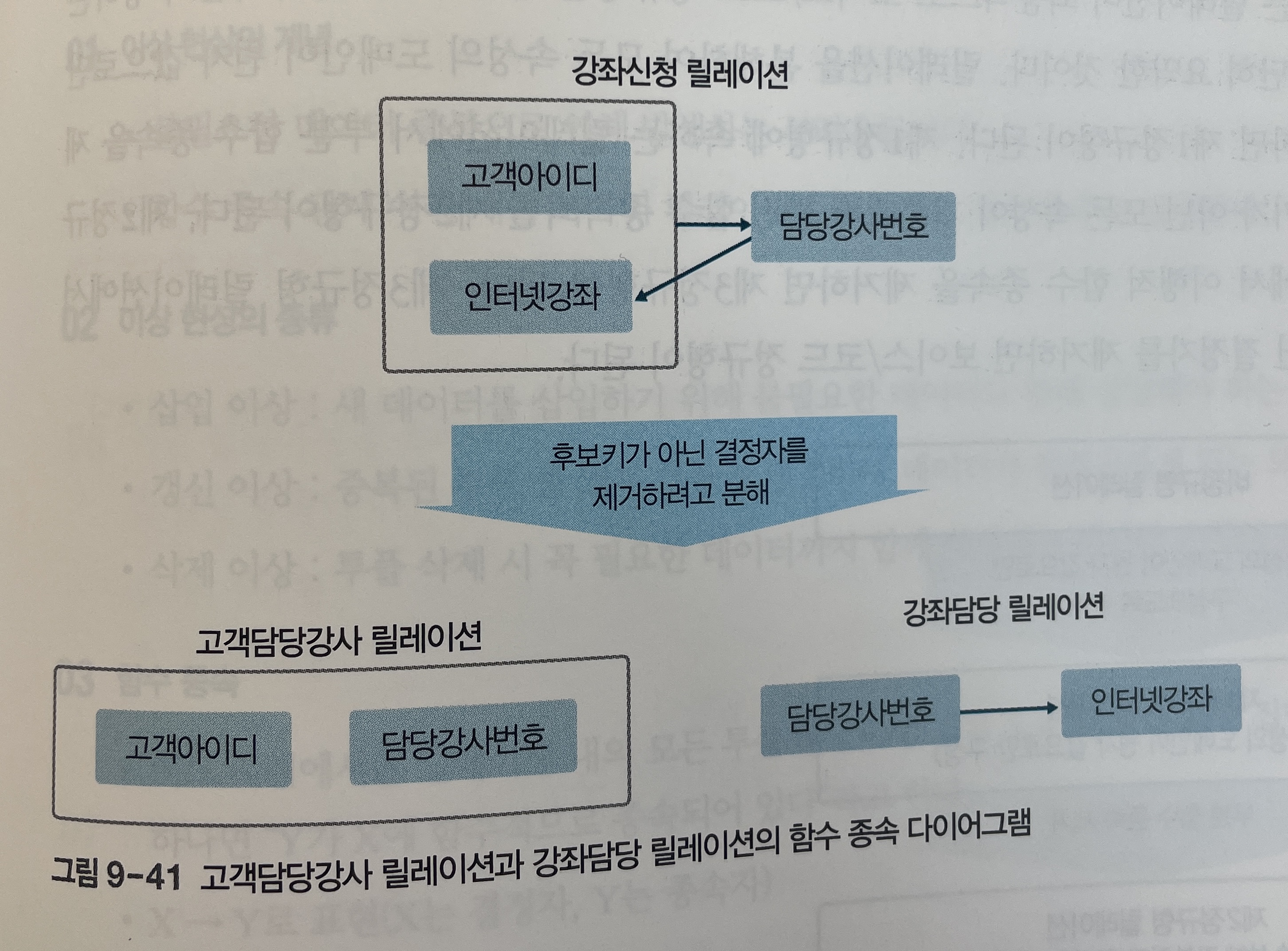
- [그림 9-41]은 강좌신청 릴레이션을 분해한 후의 고객담당강사와 강좌담당 릴레이션의 함수 종속 다이어그램이다.
제4정규형과 제 5정규형
고급 정규형으로 분류되는 제4정규형과 제5정규형은 필요시 나중에 자료를 직접 찾아보고 정리하기로 하고 여기서는 간단하게 개념만 알고 넘어가자 .
제4정규형은 릴레이션이 보이스/코드 정규형을 만족하면서, 함수 종속이 아닌 다치 종속(MVD, Multi Valued Dependency)을 제거해야 만족할 수 있다.제5정규형은 릴레이션이 제4정규형을 만족하면서 후보키를 통하지 않는 조인 종속(JD, Join Dependency)를 제거해야 만족할 수 있다.마치며..
-
실제로 데이터베이스를 설계할 때 모든 릴레이션이 무조건 제5정규형에 속하도록 분해해야 하는 것은 아니라고 생각한다.
-
오히려 제5정규형으 만족할때 까지 분해하면 비효율적이고 바람직하지 않는 경우가 많다. (성능이 100% 좋아지는 것은 아니다)
-
테이블을 나누게 되면 어떠한 쿼리는 조인을 해야 하는 경우도 발생해서 오히려 느려질 수도 있기 때문에 서비스에 따라 정규화 또는 비정규화 과정을 진행해야 한다고 생각한다.
-
실제로 최근에 했던 굿프렌즈의 경우 여러번의 조인을 발생하지 않고 한번만 조인을 하도록 설계했다.
-
-
일반적으로는 제3정규형이나 보이스/코드 정규형에 속하도록 릴레이션을 분해하여 데이터 중복을 줄이고 이상 형산이 발생하는 문제를 해결하는 경우가 있다.
-
굿프렌즈 프로젝트를 진행할 때 정규화 과정을 생각하면서 테이블을 설계했지만, 위의 정규화 과정을 모두 지킨 것은 아니라고 생각한다. 굿프렌즈 프로젝트에 있는 DB 설계 부분을 서비스 환경과 성능에 따라 개선할 수 있는 부분이 있다면 추후에 리팩터링하자.
Reference
-
-
[내 코드가 그렇게 이상한가요?] 6장. 조건 분기: 미궁처럼 복잡한 분기 처리를 무너뜨리는 방법
이 글은 내 코드가 그렇게 이상한가요? 책을 읽고 중요하다고 생각한 부분들을 중점으로 정리했습니다.
-
결론부터 말하면 조건 분기 중첩을 해결하기 위해서는 인터페이스, 전략 패턴, 정책 패턴을 사용한다.
-
세 가지에 대해서 하나씩 정리해 가보자.
조기 리턴
-
if문을 중첩으로 하면 코드의 가독성이 크게 떨어지는 문제가 있다.
-
이런 중첩 악마를 퇴치하는 방법 중 하나로
조기 리턴(early return)이 있다.조기 리턴은 조건을 만족하지 않는 경우 곧바로 리턴하는 방법이다.
-
가독성을 낮추는
else 구문도 조기 리턴으로 해결이 가능하다.- 바로 리턴하면, 사실 else 절 자체를 사용할 필요가 없다. -> else if, else문을 if문으로 바꿔서 로직을 개선할 수 있다.
switch 조건문 중복
- switch 조건문에서 중복을 해소하려면, 단일 책임 선택의 원칙 생각해봐야 한다.
단일 책임 선택의 원칙이란 소프트웨어 시스템이 선택지를 제공해야 한다면, 그 시스템 내부의 어떤 한 모듈만으로 모든 선택지를 파악할 수 있어야 한다. - 객체 지향 소프트웨어 설계 2판 원칙과 개념 -
-
따라서 조건식이 같은 조건 분기가 있으면, 여러 클래스로 작성하지 말고 하나의 클래스에 작성하자.
-
그리고 클래스가 거대해지면 관심사에 따라 작은 클래스로 분할하는 것이 중요한데, 이러한 문제를 해결할 때는
인터페이스를 사용한다. -
인터페이스는 기능 변경을 편리하게 할 수 있는 개념으로, 분기 로직을 작성하지 않고도 분기와 같은 기능을 구현할 수 있다.- 잘 활용하면 조거 분기가 많이 줄어들어 로직이 간단해진다.
-
인터페이스에는 다음과 같은 장점들이 있다.-
같은 자료형으로 사용할 수 있으므로, 굳이 자료형을 판정하지 않아도 된다.
-
조건 분기를 따로 작성하지 않고도 각각의 코드를 적절하게 실행할 수 있다.
-
자료형 판정 분기를 따로 작성하지 않아도 된다.
-
-
예를 들어 사각형과 원을 프로그램상에서 같은 도형을 다룰 수 있게 가정한다.
여기서 도형을 나타내는 Shape라는 이름의 인터페이스를 만든다.
그리고 공통 메서드도 정의한다. 도형의 면적을 나타내는 area 메서드를 정의한다.
삼각형을 나타내는 Triangle 클래스, 타원을 나타내는 Ellipse 클래스 등 새로운 도형을 추가할 수도 있다.
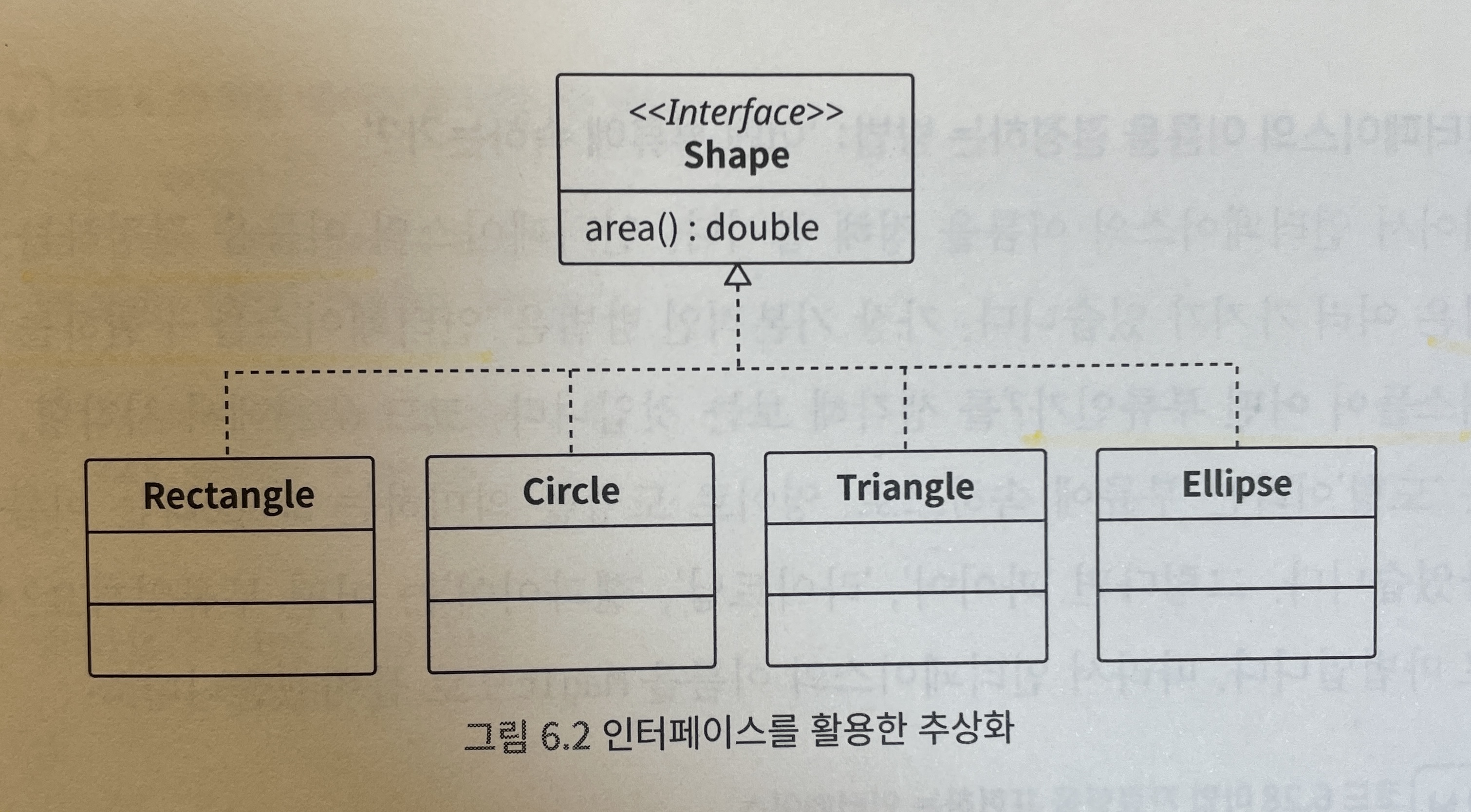
- 이처럼 인터페이스를 사용해서 처리를 한꺼번에 전환하는 설계를
전략 패턴(strategy pattern) 이라고 한다.
조건 분기 중첩
-
인터페이스는 switch 조건문의 중복을 제거할 수 있을 뿐만 아니라, 다중 중첩된 복잡한 분기를 제거하는 데 활용할 수 있다.
-
이러한 상황에서 유용하게 활용할 수 있는 패턴으로
정책 패턴(policy pattern)이 있다.정책 패턴은 조건을 부품처럼 만들고, 부품으로 만든 조건을 조합해서 사용하는 패턴이다.
-
예를 들어 다음의 상황을 가정해보자.
-
온라인 쇼핑몰에서 우수 고객인지 판정하는 로직이 있다.
-
고객의 구매 이력을 확인하고 다음 조건을 모두 만족하는 경우, 골드 회원으로 판정한다.
-
골드 회원의 구매 금액 규칙: 지금까지 구매한 금액이 100만원 이상
-
구매 빈도 규칙: 한 달에 구매하는 횟수가 10회 이상
-
반품률 규칙: 반품률이 0.1% 이하
-
-
아래의 코드처럼 하나하나의 규칙(판정 조건)을 나타내는 인터페이스를 만든다.
// 우수 고객 규칙을 나타내는 인터페이스 interface ExcellentCustomerRule { /** * @param history 구매 이력 * @return 조건을 만족하는 경우 true */ boolean ok(final PurchaseHistory history); }- 골드 회원이 되려면 3개의 조건을 만족해야 한다. 이러한 조건을 각각 아래의 코드처럼
ExcellentCustormerRule을 구현해서 만든다.
// 골드 회원의 구매 금액 규칙 class GoldCustomerPurchaseAmountRule implements ExcellentCustomerRule { public boolean ok(final PurchaseHistory history) { return 1000000 <= history.totalAmount; } } // 구매 빈도 규칙 class PurchaseFrequencyRule implements ExcellentCustomerRule { public boolean ok(final PurchaseHistory history) { return 10 <= history.purchaseFrequencyPerMonth; } } // 반품률 규칙 class ReturnRateRule implements ExcellentCustomerRule { public boolean ok(final PurchaseHistory history) { return history.returnRate <= 0.001; } }- 이어서 정책 클래스를 만든다. add 메서드로 규칙을 집약하고, complyWith All 메서드 내부에서 규칙을 모두 만족하는지 판정한다.
// 우수 고객 정책을 나타내는 클래스 class ExcellentCustomerPolicy { private final Set<ExcellentCustomerRule> rules; ExcellentCustomerPolicy() { rules = new HashSet(); } /** * 규칙 추가 * * @param rule 규칙 */ void add(final ExcellentCustomerPolicy rule) { rules.add(rule); } /** * @param history 구매 이력 * @return 규칙을 모두 만족하는 경우 true */ boolean complyWithAll(final PurchaseHistory history) { for(ExcellentCustomerRule each : rules) { if(!each.ok(history)) return false; } return true; } }-
Rule(
ExcellentCustomerRule)과 Policy(ExcellentCustomerPolicy)을 사용해서 골드 회원 판정 로직을 개선했다. -
그러면 골드 회원에 대한 정책을 아래와 같이 작성할 수 있다.
class GoldCustomerPolicy { private final ExcellentCustomerPolicy policy; GoldCustomerPolicy() { policy = new ExcellentCustomerPolicy(); policy.add(new GoldCustomerPurchaseAmountRule()); policy.add(new PurchaseFrequencyRule()); policy.add(new ReturnRateRule()); } /** * @param history 구매이력 * @return 규칙을 모두 만족하는 경우 true */ boolean complyWithAll(final PurchaseHistory history) { return policy.complyWithAll(history); } }- 여기서 골드 회원 뿐만 아니라, 실버 회원을 추가해도 구조를 크게 바꾸지 않은 채로 필요한 클래스만 추가해주면 된다.
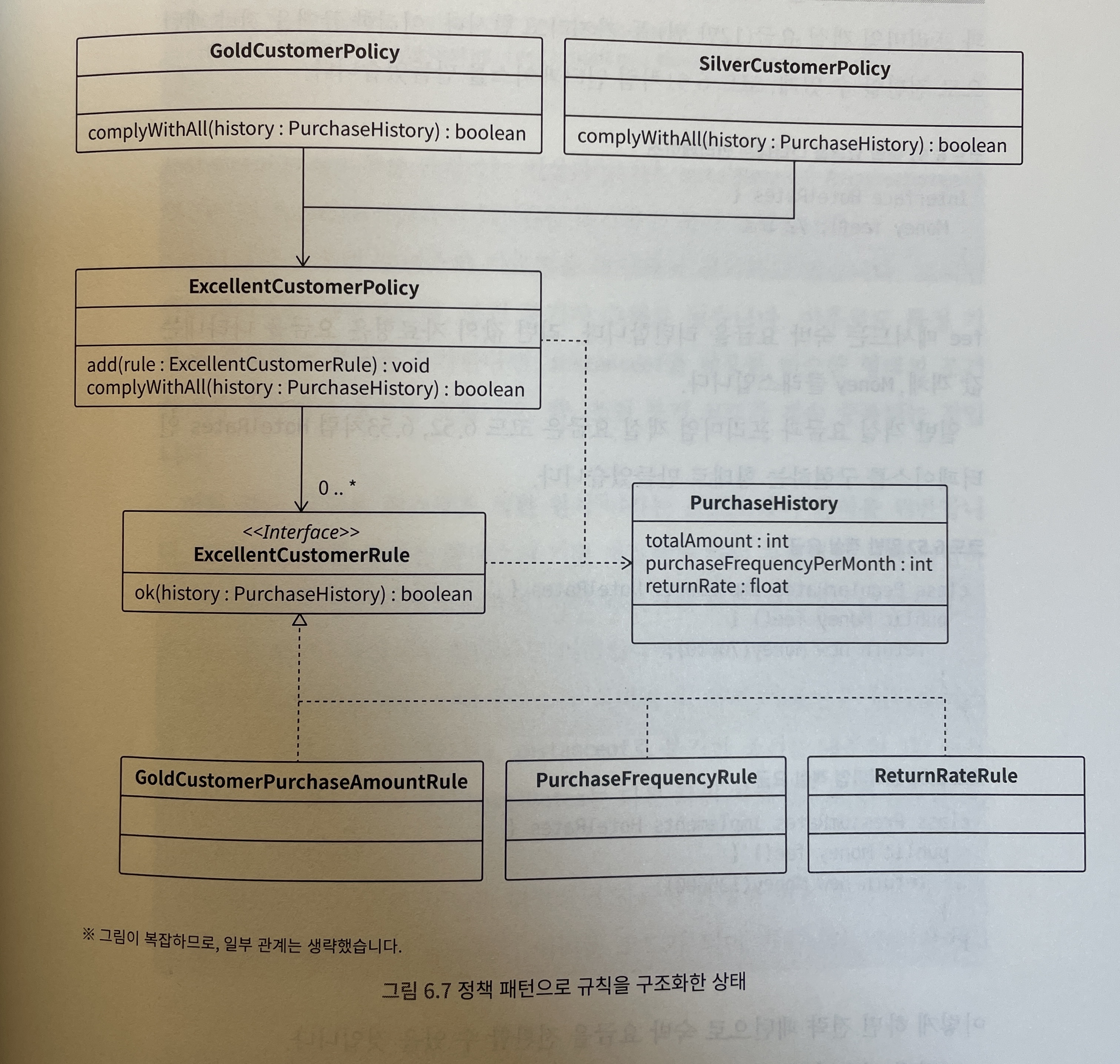
- 이처럼 조건 분기 중복과 중첩을 제거하기 위해 정책 패턴으로 규칙을 구조화한 상태로 만들면 된다.
-
-
[Programmers] 수식 최대화(dfs, 순열)
성능 요약
-
메모리: 72.3 MB, 시간: 11.40 ms - Answer Code1
-
메모리: 72.8 MB, 시간: 2.81 ms - Answer Code2
구분
- 코딩테스트 연습 > 2020 카카오 인턴십 > 수식 최대화
Answer Code1(23.11.09)
import java.util.*; class Solution { static long answer = 0; static String op[] = {"+", "-", "*"}; static boolean[] visited = new boolean[3]; static ArrayList<Long> numList = new ArrayList<>(); // 피연산자, 숫자 static ArrayList<String> opList = new ArrayList<>(); // 연산자 static String[] perm = new String[3]; public long solution(String expresstion) { String num = ""; //num op 구분 for(int i = 0; i < expresstion.length(); i++) { char c = expresstion.charAt(i); if(c == '*' || c == '+' || c == '-') { // 연산자인 경우 opList.add(c+""); numList.add(Long.parseLong(num)); num = ""; // num을 초기화합니다. 새로운 피연산자를 시작하기 위해서 num을 비워줍니다. } else { // 피연산자인 경우 num += c; } } // 마지막 숫자 numList.add(Long.parseLong(num)); // 순열 만들기 makePermutation(0); return answer; } static void makePermutation(int depth) { if(depth == op.length) { // 3개를 선택 -> 연산 sol(); return; } for(int i = 0; i < op.length; i++) { if(visited[i]) continue; visited[i] = true; perm[depth] = op[i]; makePermutation(depth+1); visited[i] = false; } } static void sol() { // list 복사 ArrayList<String> oper = new ArrayList<String>(); oper.addAll(opList); ArrayList<Long> num = new ArrayList<Long>(); num.addAll(numList); // 연산자 우선순위에 따라 계산 for(int i = 0; i < perm.length; i++) { String op = perm[i]; for(int j = 0; j < oper.size(); j++) { if(oper.get(j).equals(op)) { long n1 = num.get(j); long n2 = num.get(j+1); long res = cal(n1, n2, op); // list 갱신 num.remove(j+1); num.remove(j); oper.remove(j); num.add(j, res); j--; } } } answer = Math.max(answer, Math.abs(num.get(0))); } static long cal(long n1, long n2, String op) { long result = 0; switch(op) { case "*": result = n1 * n2; break; case "+": result = n1 + n2; break; case "-": result = n1 - n2; break; } return result; } }문제풀이 - Answer Code1
[풀이]
- 먼저 피연산자와 연산자를 분리해서 List에 넣은 후, 모든 연산자의 우선순위 순열에 대해 값을 계산해준다.
- +, *, - 3가지 연산자에 대해서 가능한 우선순위는 3!=6가지이다. dfs를 통해 이에 대한 순열을 구할 수 있다.
- 그 후 연산자 우선순위에 따라서 계산해준 후 최대값을 비교해서 얻어낸다.
초기화
class Solution { static long answer = 0; static String op[] = {"+","-","*"}; // 가능한 연산자 static boolean[] visited = new boolean[3]; // 연산자들의 사용 여부 static ArrayList<Long> numList = new ArrayList<>(); // 숫자(피연산자) static ArrayList<String> opList = new ArrayList<>(); // 연산자 static String[] perm = new String[3]; // 순열을 만들기 위한 배열 // 밑부분 생략 }피연산자와 연산자 분리
//num op 구분 for(int i = 0; i < expression.length(); i++) { char c = expression.charAt(i); if(c == '*' || c == '+' || c == '-') { // 연산자인 경우 opList.add(c+""); numList.add(Long.parseLong(num)); num = ""; // num을 초기화합니다. 새로운 피연산자를 시작하기 위해서 num을 비워줍니다. } else { // 피연산자인 경우 num += c; } }연산자인 경우와 피연산자인 경우를 조건문으로 구분했다.
- 연산자인 경우는 문자 변환하여
opList에 추가한다.numList.add(Long.parseLong(num));은 지금까지 쌓인 숫자를Long타입으로 변환하여numList에 추가한다는 의미이다.num = “”;을 한 이유는 새로운 피연산자를 시작하기 위해서num을 비워주는 것을 의미한다.
- 피연산자인 경우는 현재 숫자를
num에 더해준다.- 이렇게하면 다음 반복문에서 if문에 있는
numList.add(Long.parseLong(num));에서 해당 숫자를numList에 넣어주게 된다.
- 이렇게하면 다음 반복문에서 if문에 있는
- 마지막에 쌓인 숫자를
Long타입으로 변환하여numList에 추가한다.
이 코드는 주어진 수식을 순회하면서 연산자와 피연산자를 구분하여
opList와numList에 저장하는 역할을 한다.예를 들어, 수식이 “100-200300-500+20”인 경우에는
opList에는 [”-“, “”, “-“, “+”]이 저장되고,numList에는 [100, 200, 300, 500, 20]이 저장된다.dfs를 통해 순열 처리
static void makePermutation(int depth) { if(depth == op.length) { // 3개를 선택 -> 연산 sol(); return; } for(int i = 0; i < op.length; i++) { if(visited[i]) continue; visited[i] = true; perm[depth] = op[i]; makePermutation(depth+1); visited[i] = false; } }위 코드는 연산자의 우선순위의 모든 가능한 순열을 생성하는 메서드다.
makePermutation메서드는 재귀적으로 호출된다.- if문에서는 현재 순열의 길이가 연산자의 총 개수와 같다면, 즉 모든 연산자에 대한 순열이 만들어진 경우다.
- 그런 경우
sol()메서드를 호출하여 순열에 대한 연산을 수행한다.
- 그런 경우
- for문에서는 가능한 모든 연산자를 대상으로 반복문을 실행한다.
visited[i] = true;의 경우 현재 연산자op[i]를 사용한다는 의미이다.- 그리고
makePermutation(depth+1);을 통해 더 깊은 위치로 재귀 호출을 해서 다음 연산자를 선택한다. visited[i] = false;는 현재 연산자op[i]를 다시 사용하지 않는 상태로 되돌린다.
연산자 우선순위에 따라서 계산해준 후 최대값을 비교
static void sol() { // list 복사 ArrayList<String> oper = new ArrayList<String>(); oper.addAll(opList); ArrayList<Long> num = new ArrayList<Long>(); num.addAll(numList); // 연산자 우선순위에 따라 계산 for(int i = 0; i < perm.length; i++) { String op = perm[i]; for(int j = 0; j < oper.size(); j++) { if(oper.get(j).equals(op)) { long n1 = num.get(j); long n2 = num.get(j+1); long res = cal(n1, n2, op); // list 갱신 num.remove(j+1); num.remove(j); oper.remove(j); num.add(j, res); j--; } } } answer = Math.max(answer, Math.abs(num.get(0))); } static long cal(long n1, long n2, String op) { long result = 0; switch(op) { case "*": result = n1 * n2; break; case "+": result = n1 + n2; break; case "-": result = n1 - n2; break; } return result; }oper라는 새로운 문자열 리스트를 생성하고, 연산자 리스트의 복사본을 만든다.num이라는 새로운 Long 타입의 리스트를 생성하고 숫자 리스트의 복사본을 만든다.연산자 우선순위의 모든 경우를 for문을 통해 반복한다.
- 현재 순열에서 선택한 연산자를
op에 저장한다. - 연산자 리스트를 순회하면서 현재 연산자
op와 연산자 리스트의 원소가 일치하는 경우, 현재 연산자 앞 뒤에 있는 두 숫자를n1과n2에 저장한다. - 그런 다음
cal메서드를 호출하여n1과n2를op로 계산한 결과를res에 저장한다. - 계산에 사용된 두 숫자와 연산리스트를 리스트에서 제거하고
num.add(j, res);**을 통해 계산 결과를 원래 순서에 넣는다.- 여기서
res값을j인덱스 위치에 추가하는 역할을 한다. - 예를 들어,
num리스트가 [1,2,3,4,5]이고,j가 2이고,res가 10이라면, 실행 후num리스트는 [1,2,10,3,4,5]가 된다.
- 여기서
- 리스트에서 요소가 제거되었으므로
j를 감소시켜서 다음 순회에 올바른 인덱스가 가리키도록 한다.
static long cal(long n1, long n2, String op) { ... }: 주어진 두 숫자와 연산자로 계산을 수행하는 메서드다.Answer Code2(23.11.09)
import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; class Solution { static List<List<String>> list = new ArrayList<>(); public long solution(String expression) { long answer = 0; boolean[] visited = new boolean[3]; String[] operationTypes = {"-","+","*"}; // 연산자 우선순위 모든 경우의 수 계산 permutation(new ArrayList<>(), operationTypes, visited); // 연산자를 " "로 치환 후 split 값들을 Long 값으로 변환 후 toList List<Long> numbers = Arrays.stream(expression.replaceAll("-|\\*|\\+"," ").split(" ")) .map(Long::parseLong).collect(Collectors.toList()); // 숫자를 공백으로 치환 후 toList List<String> collect = Arrays.stream(expression.replaceAll("[0-9]", "").split("")) .collect(Collectors.toList()); // 우선순위 모든 경우의 수에 따른 max 연산 값 for (List<String> strings : list) { answer = Math.max(answer, solve(strings, numbers, collect)); } return answer; } static long solve(List<String> strings, List<Long> numbers, List<String> operations) { // 리스트에 remove 메서드를 사용하기 위해서 복사 List<Long> numbersClone = new ArrayList<>(numbers); List<String> operationsClone = new ArrayList<>(operations); for (int i = 0; i < strings.size(); i++) { String operation = strings.get(i); // 현재 순위의 연산자 for(int j = 0; j < operationsClone.size(); j++) { // 현재 순위의 연산자와 같은 경우 if(operation.equals(operationsClone.get(j))) { // 연산자 앞의 수와 뒤의 수를 구한뒤 연산 long front = numbersClone.get(j); long back = numbersClone.get(j + 1); long temp = calc(front, back, operation); // 연산에 사용된 두수를 제거 numbersClone.remove(j+1); numbersClone.remove(j); // 연산에 사용된 연산자 제거 operationsClone.remove(j); // 연산된 값을 추가 numbersClone.add(j, temp); // 연산이 진행되는 경우 2개 -> 1개 가되므로 리스트의 사이즈에 변경이 일어남 // 이를 맞추기 위해서 j를 --하여 다움 for문에서 범위를 벗어나지 않게 함 j--; } } } // 절대값으로 변환해서 리턴 return Math.abs(numbersClone.get(0)); } static void permutation(ArrayList<String> arrayList, String[] orders, boolean[] visited) { if(arrayList.size() == 3) { list.add(arrayList); return; } for (int i = 0; i < orders.length; i++) { if (!visited[i]) { ArrayList<String> temp = new ArrayList<>(arrayList); temp.add(orders[i]); visited[i] = true; permutation(temp, orders, visited); visited[i] = false; } } } static long calc(long one, long two, String calc) { switch (calc) { case "-" : return one - two; case "+" : return one + two; default : return one * two; } } }Review
-
해당 문제를 어떻게 접근해야 할지 감이 오질 않아서 다른 사람의 풀이를 참고했고, 해당 코드를 이해하느라 시간이 오래걸렸다.
-
순열과 dfs을 이용하여 문제를 풀었는데, 해당 코드를 이해하는데도 어려워서 해당 문제는 여러 번 복습해야겠다는 생각이 들었다.
-
두번째 정답은 첫번째에 비해 성능적으로 5배나 좋게 되어있어서 다음에 기회되면 두번째 풀이방식으로도 접근해야겠다.
Reference
- https://stritegdc.tistory.com/232 - Answer Code1
-
-
[내 코드가 그렇게 이상한가요?] 4장. 불변 활용하기: 안정적으로 동작하게 만들기
이 글은 내 코드가 그렇게 이상한가요? 책을 읽고 정리한 내용을 바탕으로 작성하였습니다.
재할당
-
재할당은 변수에 값을 다시 할당하는 것을 말하며,파괴적 할당이라고도 말한다.재할당은 변수의 의미를 바꿔 추측하기 어렵게 만들고,언제 어떻게 변경되는지 추척하기 힘들게 한다.
-
따라서
재할당을 막기 위해서는변수에 final 수식자를 붙여준다.마찬가지로,
매개변수에도 final 수식자를 붙인다.
가변으로 인해 발생하는 의도하지 않는 영향
- 인스턴스가 가변이면 다른 부분에 의도하지 않은 영향을 주기 쉽다.
부수 효과의 단점
-
함수의
부수 효과는 함수가 매개변수를 전달받고, 값을 리턴하는 것 이외에 외부 상태(인스턴스 변수)를 변경하는 것을 가리킨다. -
조금 더 구체적으로 설명하면, 함수(메서드)에는 주요 작용과 부수 효과가 있다.
-
주요 작용: 함수(메서드)가 매개변수를 전달받고, 값을 리턴하는 것
-
부수 효과: 주요 작용 이외의 상태 변경을 일으키는 것
-
-
여기서
상태 변경이란 함수 밖에 있는 상태를 변경하는 것을 의미한다. 예를 들어 다음과 같은 것이다.-
인스턴스 변수 변경
-
전역 변수 변경
-
매개변수 변경
-
파일 읽고 쓰기 같은 I/O 조작
-
-
작업 실행 순서에 의존하는 코드는 결과를 예측하기 힘들며, 유지 보수하기 힘들다.
함수의 영향 범위 한정하기
-
부수 효과가 있는 함수는 영향 범위를 예측하기 힘들다.
-
따라서 예상치 못한 동작을 막으려면, 함수가 영향을 주거나 받을 수 있는 범위를 한정하는 것이다.
-
함수는 다음 동작을 만족하도록 설계하는 것이 좋다.
-
데이터(상태)는 매개변수로 받는다.
-
상태를 변경하지 않는다.
-
값은 함수의 리턴 값으로 돌려준다.
-
-
따라서 매개변수로 상태를 받고, 상태를 변경하지 않고, 값을 리턴하기만
함수가 이상적이다.
불변으로 만들어서 예기치 못한 동작 막기
-
지금까지 설명한 방식에 따라, 예상하지 못한 동작을 막기 위해 불변을 기반으로 코드를 설계한다.
-
부수 효과의 자체를 없애는 방법은 간단하다.
인스턴스 변수에 final 수식자를 붙여서 불변으로 만들면 된다.
원시(기본) 타입(primitive type): byte, char, short, int, long, float, double, boolean
참조 타입(reference type): 배열 타입, 열거 타입, 클래스, 인터페이스
참고로, int형과 같은
원시 타입(primitive)은 참조값이 존재하지 않기 때문에 외부에서도 그대로불변으로 존재하게 된다.하지만,
참조 타입인 객체나 Array, List와 같은 컬렉션일 경우에는불변을 보장하려면 setter를 포함하지 않아야 하며, getter 사용시 방어적 복사를 통해 값을 전달해야 한다. 또한, 참조 변수 객체 내부 또한 불변이어야 불변이 성립한다.-
불변 변수로 만들면 변경할 수 없기 때문에, 변경된 값을 사용하고 싶다면 새로운 값을 가진 새로운 인스턴스 변수를 만들어서 사용해야 한다.
-
아래 코드의 reinforce 메서드와 disable 메서드처럼
AttackPower인스턴스를 새로 생성하고 리턴하는 구조로 변경한다.
class AttackPower() { static final int MIN = 0; final int value; // final로 불변으로 만들기 AttackPower(final int value) { if(value < MIN) { throw new IllegalArgumentException(); } this.value = value; } /** * 공격력 강화하기 * @param increment 공격력 증가량 * @return 증가된 공격력 */ AttackPower reinforce(final AttackPower increment) { return new AttackPower(this.value + increment.value); // 인스턴스를 새로 생성하고 리턴하는 구조로 변경 } /** * 무력화하기 * @return 무력화한 공격력 */ AttackPower disable() { return new AttackPower(MIN); // 인스턴스를 새로 생성하고 리턴하는 구조로 변경 } }불변과 가변은 어떻게 다루어야 할까?
-
지금까지 설명한 것처럼 변수를 불변으로 만들면 다음과 같은 장점이 있다.
-
변수의 의미가 변하지 않으므로, 혼란을 줄일 수가 있음.
-
동작을 안정적이게 되므로, 결과를 예측하지 쉬움
-
코드의 영향 범위가 한정적이므로, 유지 보수가 편리해짐
-
-
따라서 기본적으로는
불변으로 설계하는 것이 좋다. (이 책에서도 불변을 표준 스타일로 사용한다)
가변으로 설계해야 하는 경우
-
기본적으로 불변으로 설계하는 것이 좋지만, 가변이 필요한 경우도 있다.
-
바로 성능(performance)이 중요한 경우이다.
-
대량의 데이터를 처리해야 하는 경우,
-
이미지를 처리하는 경우
-
리소스에 제약이 큰 임베디드 소프트웨어를 다루는 경우
-
-
위와 같은 예시에서는 가변을 사용하는 것이 좋을 수 있다.
-
불변이라면 값을 변경할 때 인스턴스를 새로 생성해야 한다.
-
만약 크기가 큰 인스턴스를 새로 생성하면서 시간이 오래 걸려 성능에 문제가 생긴다면 불변 보다는 가변을 사용하는 것이 좋다.
상태를 변경하는 메서드 설계하기
-
어떤 게임에서 히트포인터에 대한 기본적인 조건은 다음과 같다.
-
히트포인트는 0이상
-
히트포인트가 0이 되면, 사망 상태로 변경
-
-
히트포인트가 0이 될때 뮤테이터(mutater)를 통해 사망 상태로 변경하자.
뮤테이터(mutater): 상태를 변화시키는 메서드
class Hitpoint { ... /** * 대미지 받는 처리 * @param damageAmount 대미지 크기 */ void damage(final int damageAmount) { hitPoint.damage(damageAmount) { if(hitPoint.isZero) { states.add(StateType.dead); // 사망 상태로 변경 } } } }Reference
-
-
우선순위 큐(Priority Queue) 개념 및 사용법 정리
Prologue
해당 문제를 풀면서 우선순위 큐에 대한 개념과 사용법을 다시 한번 짚고 넘어가고자 정리하게 되었다.
Priority Queue란
-
우선순위 큐는 우선순위가 가장 높은 데이터를 가장 먼저 삭제하는 자료구조이다. -
우선순위 큐는 데이터를 우선순위에 따라 처리하고 싶을 때 사용합니다.
- ex) 물건 데이터를 자료구조에 넣었다가 가치가 높은 물건부터 꺼내서 확인해야 하는 경우
-
우선순위 큐를 구현하는 방법은 다양하다.
-
(1) 단순히
리스트(List)를 이용하여 구현할 수 있다. -
(2)
힙(Heap)을 이용하여 구현할 수 있다.
-
-
데이터의 개수가 N개일 때, 구현 방식에 따라서 시간 복잡도를 비교한 내용은 다음과 같다.
-
리스트 - 삽입 시간: O(1), 삭제 시간: O(N)
-
힙 - 삽입 시간: O(logN), 삭제 시간: O(logN)
-
-
단순이 N개의 데이터를 힙에 넣었다가 모두 꺼내는 작업은 정렬과 동일하다. (힙 정렬)
- 이 경우 시간 복잡도는 O(NlogN) 이다.
-
정리하면, 우선순위 큐는 배열, 연결리스트, 힙으로 구현이 가능하나 이 중 힙(Heap)으로 구현하는 것이 가장 효율적이다.
-
데이터를 삽입할 때 우선순위를 기준으로 최대 힙 또는 최소 힙을 구성하고
데이터를 꺼낼 때 루트 노드를 얻어낸 뒤
루트 노드를 삭제할 때는 빈 루트 노드 위치에 맨 마지막 노드를 삽입한 후
아래로 내려가면서 적절한 자리를 찾아 옮기는 방식으로 진행한다.
-
최대 값이 우선순위인 큐 = 최대힙, 최소 값이 우선순우이인 큐 = 최소 힙
힙(Heap) 특징
-
힙은 완전 이진 트리 자료구조의 일종이다. -
힙에서는 항상 루트 노드(root node)를 제거한다.
-
최소 힙(min heap)
-
루트 노드가 가장 작은 값을 가진다.
-
따라서 값이 작은 데이터가 우선적으로 제거된다.
-
-
최대 힙(max heap)
-
루트 노드가 가장 큰 값을 가진다.
-
따라서 값이 큰 데이터가 우선적으로 제거된다.
-
완전 이진 트리(Complete Binary Tree)
-
완전 이진 트리란 루트 노트부터 시작하여 왼쪽 자식 노드, 오른쪽 자식 노드 순서대로 데이터가 차례대로 삽입되는 트리를 의미한다.
-
원소를 제거할 때는 가장 마지막 노드가 루트 노드의 위치에 오도록 한다.
Priority Queue 특징
-
높은 우선순위의 요소를 먼저 꺼내서 처리하는 구조이다. (우선순위 큐에 들어가는 원소는 비교가 가능한 기준이 있어야 한다)
-
내부 요소는 힙으로 구성되어
이진 트리이루어져 있다. -
내부 구조가 힙으로 구성되어 있기에 시간 복잡도는
O(NlogN)이다. -
우선순위를 중요시해야 하는 상황에서 주로 쓰인다.
Priority Queue 선언
Priority Queue를 사용하려면java.util.PriorityQueue를 import해야 한다.
import java.util.PriorityQueue; import java.util.Collections; public class PriorityQueue() { //낮은 숫자가 우선 순위인 int 형 우선순위 큐 선언 PriorityQueue<Integer> priorityQueueLowest = new PriorityQueue<>(); //높은 숫자가 우선 순위인 int 형 우선순위 큐 선언 PriorityQueue<Integer> priorityQueueHighest = new PriorityQueue<>(Collections.reverseOrder()); }Priority Queue 동작
Priority Queue 값 추가하기
public class PriorityQueueDemo { public static void main(String[] args) { PriorityQueue<Integer> pq = new PriorityQueue<>(); // 1, 15, 10, 21, 25, 18, 8 값 추가 pq.add(1); pq.add(15); pq.offer(10); pq.add(21); pq.add(25); pq.offer(18); pq.add(8); System.out.print(pq); // 결과 출력: [1, 15, 8, 21, 25, 18, 10] } }-
우선순위 큐에 값을 추가하는 방법은
add(),offer()메서드가 있다.add(value)메서드는 삽입이 성공하면 true를 반환하고, 큐에 여유 공간이 없어 삽입에 실패하면 IllegalStateException 을 발생시킨다.
-
add()메서드는 Collection 클래스에서 가져오는 메서드라면,offer()메서드는 Queue 클래스에서 가져오는 메서드다. -
결과를 보면 값을 입력한 순서가 아닌 우선순위 큐만의 정렬방식으로 출력된다.
-
결과: 1, 15, 8, 21, 25, 18, 10
추가할 때 우선순위 큐의 동작은 아래와 같은 과정을 통해 정렬이 된다.
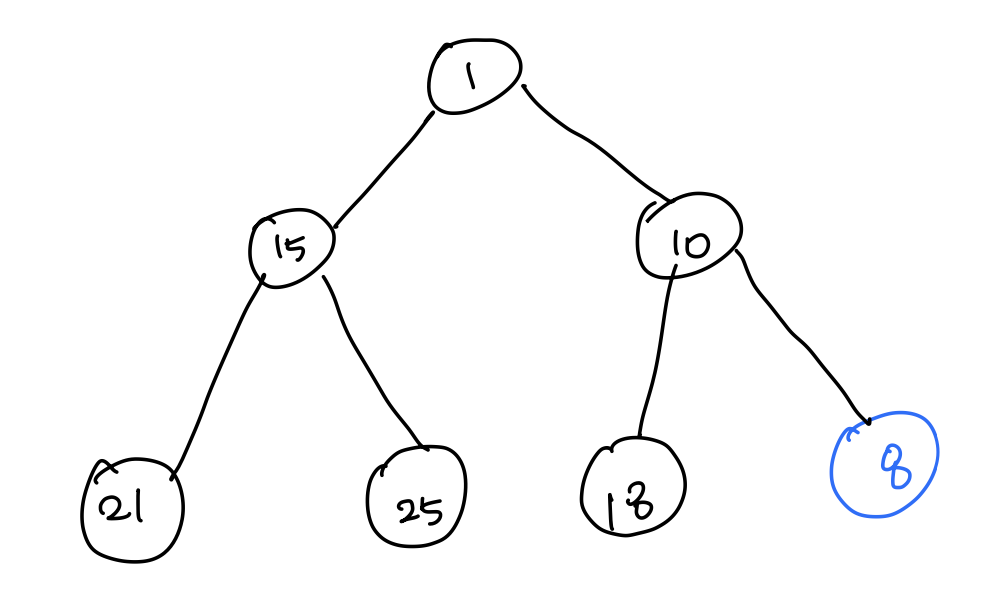
- [1] 우선순위 큐에 숫자 8을 추가한다. 숫자 8은 부모와 비교해서 부모보다 작은 값인 경우 스왑한다. -> 10과 8의 위치가 변경된다.
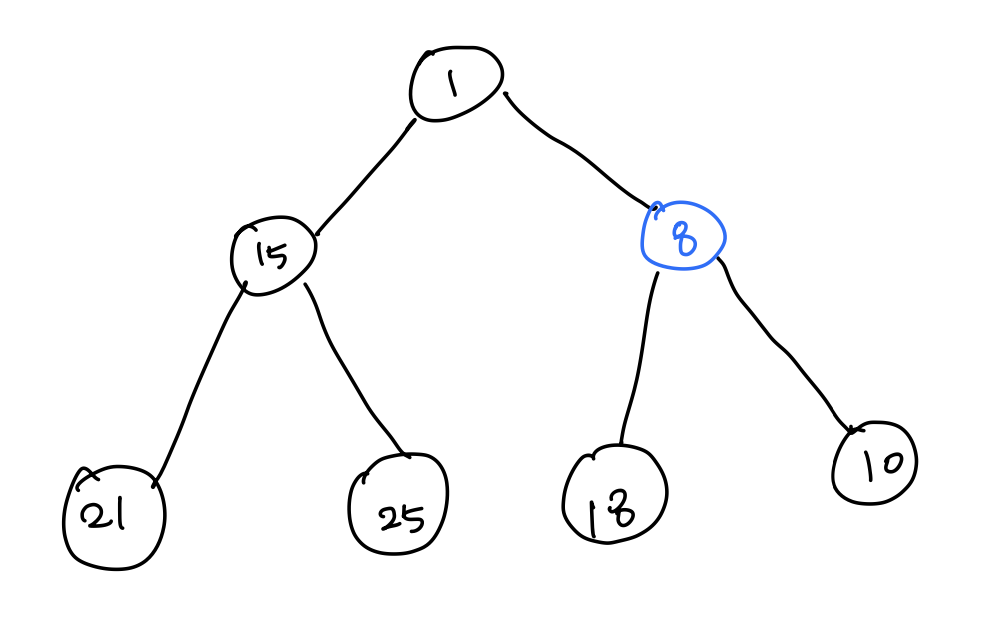
- [2] 8은 다시 부모의 값과 비교한다. 하지만 자식 값이 더 크므로 스왑하지 않는다.
Priority Queue 값 삭제하기
public class PriorityQueueDemo { public static void main(String[] args) { PriorityQueue<Integer> pq = new PriorityQueue<>(); // 1, 15, 10, 21, 25, 18, 8 값 추가 pq.add(1); pq.add(15); pq.offer(10); pq.add(21); pq.add(25); pq.offer(18); pq.add(8); System.out.println(pq); // 결과 출력: [1, 15, 8, 21, 25, 18, 10] pq.poll(); System.out.println(pq); // 결과 출력: [8, 15, 10, 21, 25, 18] pq.remove(); pq.remove(1); System.out.println(pq); // 결과 출력: [10, 15, 18, 21, 25] pq.clear(); System.out.println(pq); // 결과 출력: [] } }-
우선순위 큐에서 값을 삭제하는 방법은 여러가지가 있다.
-
poll(),remove()메서드를 사용하면 우선순위가 가장 높은 값을 제거한다.-
poll()메서드는 첫번째 값을 반환하고 제거한다. 만약 우선순위 큐가 비어있다면 null을 반환한다. -
remove()메서드는 첫번째 값을 제거한다.
-
-
clear()메서드를 사용하면 우선순위의 큐의 모든 값을 삭제한다. (=초기화) -
결과를 보면 첫 번째 우선순위를 삭제하면 하나씩 밀리는 것이 아니라 우선순위를 재정렬하는 것을 확인할 수 있다.
삭제할 때, 우선순위 큐의 동작은 아래와 같은 과정을 통해 정렬이 된다.
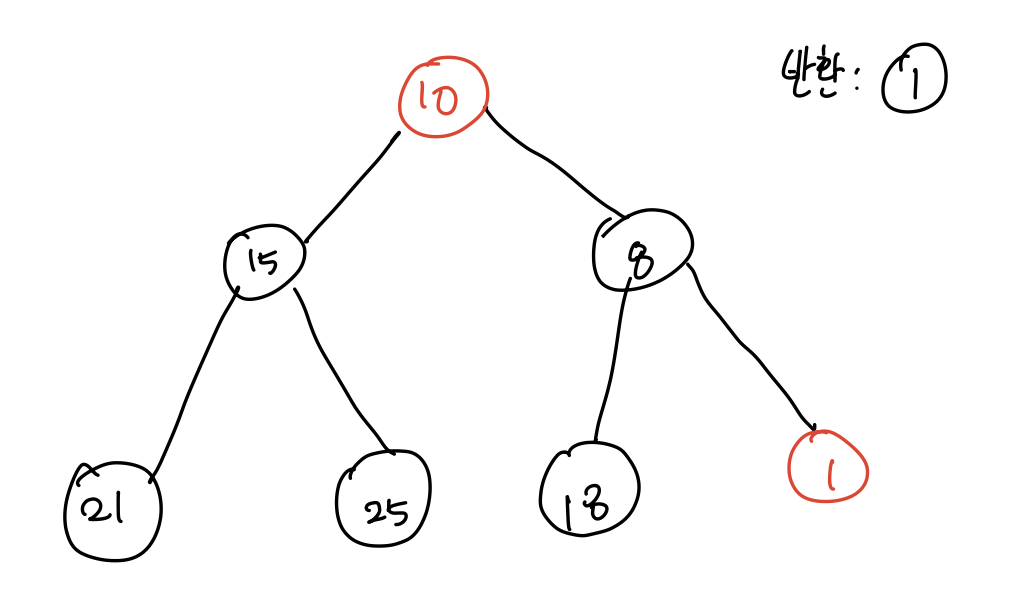
- [1] 우선순위 가장 높은 루트 노드인 (1)를 반환하고, 마지막 노드인 (10)이 스왑하고 난 뒤에 제거한다.
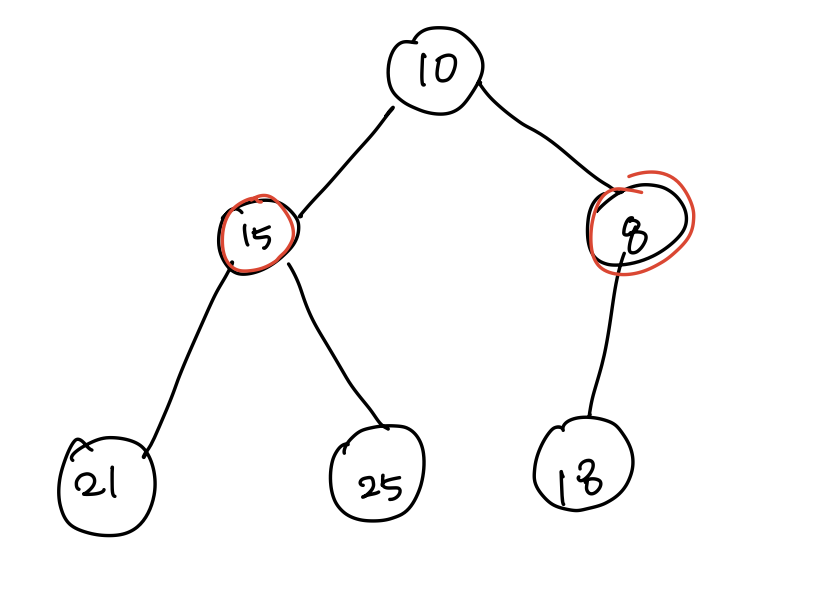
- [2] (1)을 제거하고 부모 노드 (10), 자식 노드(15, 8)과 비교하여 더 작은 값이 부모 노드로 올라간다.
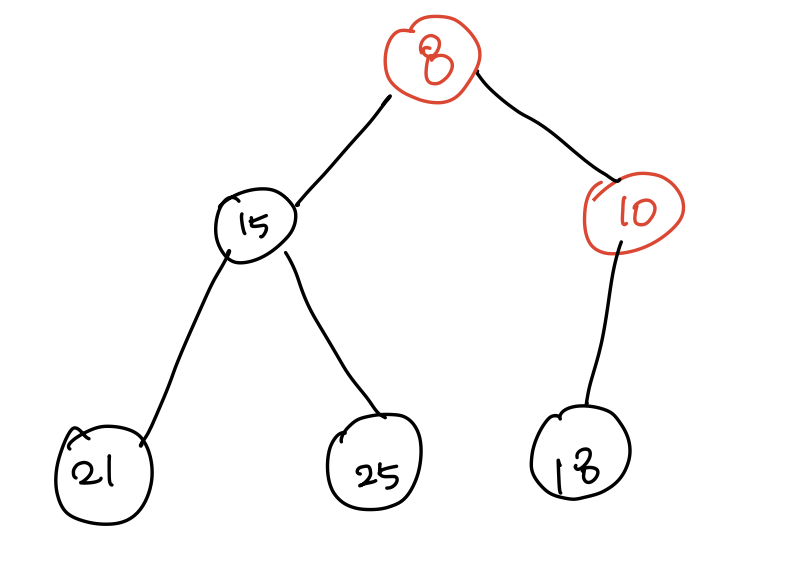
- 이렇게 다시 우선순위가 정렬된다.
Priority Queue 값 출력하기
public class PriorityQueueDemo { public static void main(String[] args) { PriorityQueue<Integer> pq = new PriorityQueue<>(); // 1, 15, 8, 21, 25, 18, 10 값 추가 pq.add(1); pq.add(15); pq.offer(10); pq.add(21); pq.add(25); pq.offer(18); pq.add(8); System.out.println(pq.peek()); // 결과 출력: 1 Iterator iterator = pq.iterator(); while(iterator.hasNext()) System.out.print(iterator.next() + " "); // 결과 출력: 1 15 8 21 25 18 10 } }-
Priority Queue에서
peek()메서드를 사용하면 우선순위가 가장 높은 값이 출력된다. -
전체 Queue의 값을 가져오려면 Iterator() 메서드를 사용하여 가져오면 된다.
Reference
-
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8