흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[DB] 파티셔닝(Partitioning)
이 글은 MySQL 공식문서를 바탕으로 공부하고 정리한 내용입니다.
Motivation
-
서비스, 사용자 요구사항의 고도화에 따라서 데이터 규모가 대용량으로 증가되면서, 기존에 사용하던 DB의 용량(storage)과 성능(performance)에 한계가 생기게 된다.
-
즉, VLDB(Very Large DBMS)와 같이 하나의 DBMS에 너무 큰 table이 들어가면서 용량과 성능 측면에서 많은 이슈가 발생하게 되었고, 이런 이슈를 해결하기 위한 방법으로 테이블을
partition이라는 몇 개의 단위로 나눠서 관리하는파티셔닝(Partitioning)기법을 활용하면 된다. -
파티셔닝(Partitioning)기법을 통해 SW적으로 DB를 분산처리하여 성능이 저하되는 것을 방지하고 관리를 보다 수월하게 할 수 있게 되었다.
파티셔닝이란
-
파티셔닝(Partitioning)이란 하나의 테이블을 다수의 테이블로 분할하여 관리하는 것을 의미하며, 프로그래머 입장에서는 여전히 하나의 테이블로 동작하는 것처럼 사용할 수 있다. -
즉, 큰 테이블이나 인덱스를, 관리하기 쉬운 파티션이라는 작은 단위로 물리적으로 분할하는 것을 의미한다.
-
논리적으로는 하나의 테이블처럼, 물리적으로는 여러 개의 테이블로 구성된다.
파티셔닝의 목적
성능(performence)
-
특정 DML과 Query의 성능을 향상시킨다.
-
주로 대용량 data wirte 환경에 효율적이다.
-
특히, full scan에서 데이터 access의 범위를 줄여 성능 향상을 가져온다.
가용성(Availability)
-
물리적인 파티셔닝으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
-
각 분할 영역(partition 별로)을 독립적으로 백업하고 복구할 수 있다.
-
table의 partition 단위로 Disk I/O을 분산하여 경합을 줄이기 때문에 update 성능을 향상시킨다.
관리 용이성(Manageability)
- 큰 테이블을 제거하여 관리를 쉽게 해준다.
파티셔닝의 장단점
장점
- 관리적 측면: partition 단위 백업, 추가, 삭제, 변경
- 전체 데이터를 손실할 가능성이 줄어들어 데이터 가용성이 향상된다.
- partition별로 백업 및 복구가 가능하다.
- partition 단위로 I/O 분산이 가능하며 update 성능을 향상시킨다.
- 성능적 측면: partition 단위로 조회 및 DML 수행
- 데이터 전체 검색시 필요한 부분만 탐색해 성능이 증가된다.
- 즉, full scan에서 데이터 접근의 범위를 줄여 성능 향상을 가져온다.
- 필요한 데이터만 빠르게 조회할 수 있기 때문에 쿼리 자체가 가볍다.
단점
- table간 JOIN에 대한 비용이 증가한다.
- table과 index를 별도로 파티셔닝할 수 없다. -> table과 index를 같이 파티셔닝해야 한다.
파티셔닝 방식
- 테이블을 파티셔닝하는 방법은 크게 2가지로 구분할 수 있다.
- 수평 분할 - 주로 사용
- 수직 분할
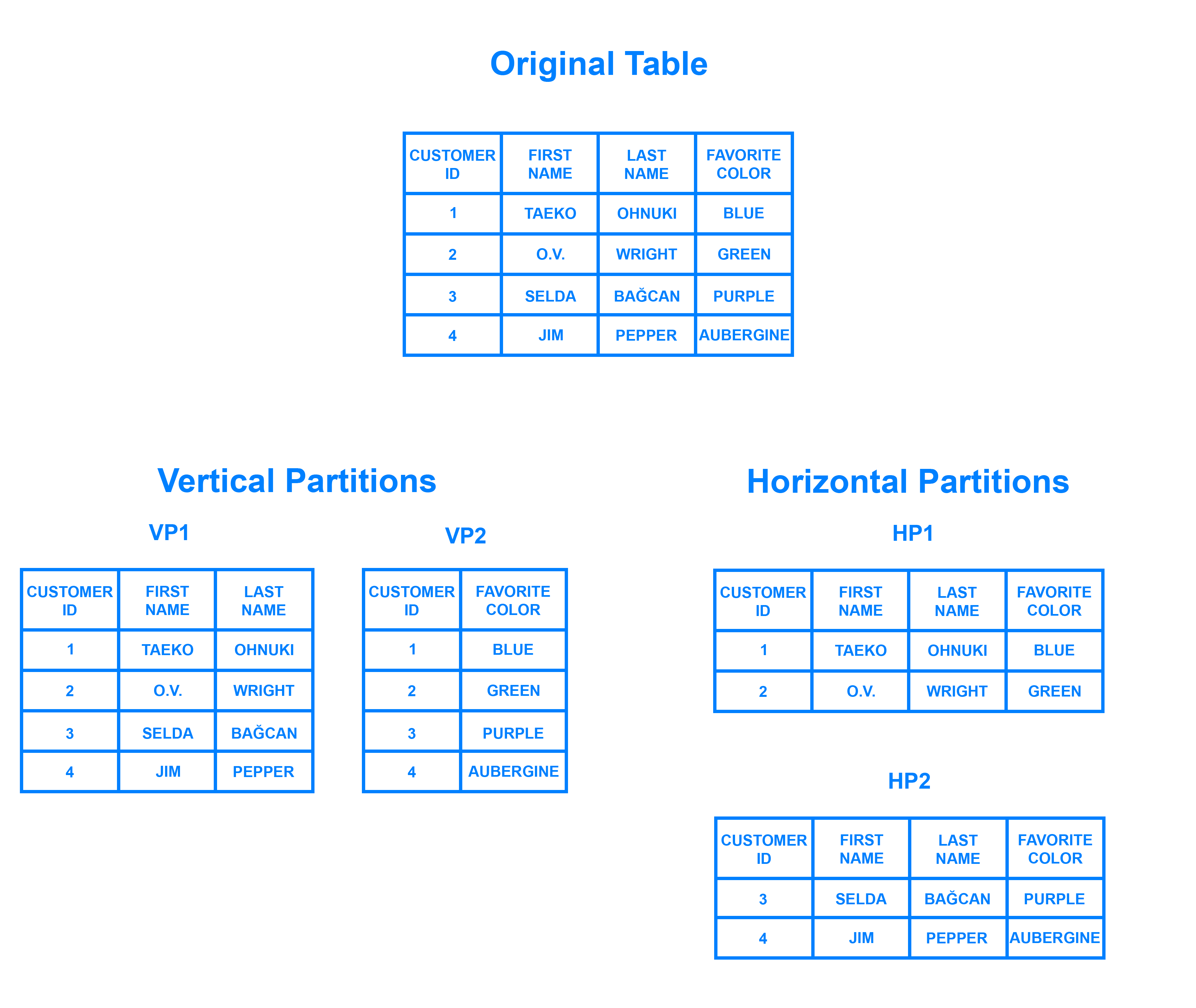
수평 분할 방식
- 수평분할(Horizontal Partitioning)은 행(row)을 기준으로 테이블을 분할하는 형테이다.
수직 분할 방식
- 특정 열에 대한 접근을 제한하거나 성능 향상이 필요할 때 열(column) 기준으로 분할하는 방식이다.
파티셔닝 종류
RANGE 파티셔닝
-
지정된 범위에 속하는 열 값을 기반으로 파티션에 행을 할당한다.
-
예를 들어, 우편 번호를 분할 키로 수평 분할하는 경우이다.
LIST 파티셔닝
-
값 목록에 파티션을 할당 분할 키 값을 그 목록에 비추어 파티션을 선택한다.
-
예를 들어, Country 라는 컬럼의 값이 Iceland , Norway , Sweden , Finland , Denmark 중 하나에 있는 행을 빼낼 때 북유럽 국가 파티션을 구축 할 수 있다.
HASH 파티셔닝
-
해시 함수의 값에 따라 파티션에 포함할지 여부를 결정한다.
-
예를 들어, 4개의 파티션으로 분할하는 경우 해시 함수는 0-3의 정수를 돌려준다.
KEY 파티셔닝
-
key 파티션은 hash 파티션과 거의 동일하다.
-
key 파티션은 선정된 파티션 키 값에 대하여 내부적으로 MD5()을 이용하여 해시값을 계산하고, 그 값에 MOD를 적용하여 저장할 파티션을 결정한다.
Reference
-
-
ArrayList
와 LinkedList 의 성능 비교 이 글의 코드와 정보들은 Do it! 자바 완전 정복 책에서 공부하고 정리한 내용을 토대로 작성하였습니다.
ArrayList
와 LinkedList 의 성능 비교 LinkedList
와 같은 저장 구조를 지니게 되면 얻을 수 있는 이점이 무엇일까? 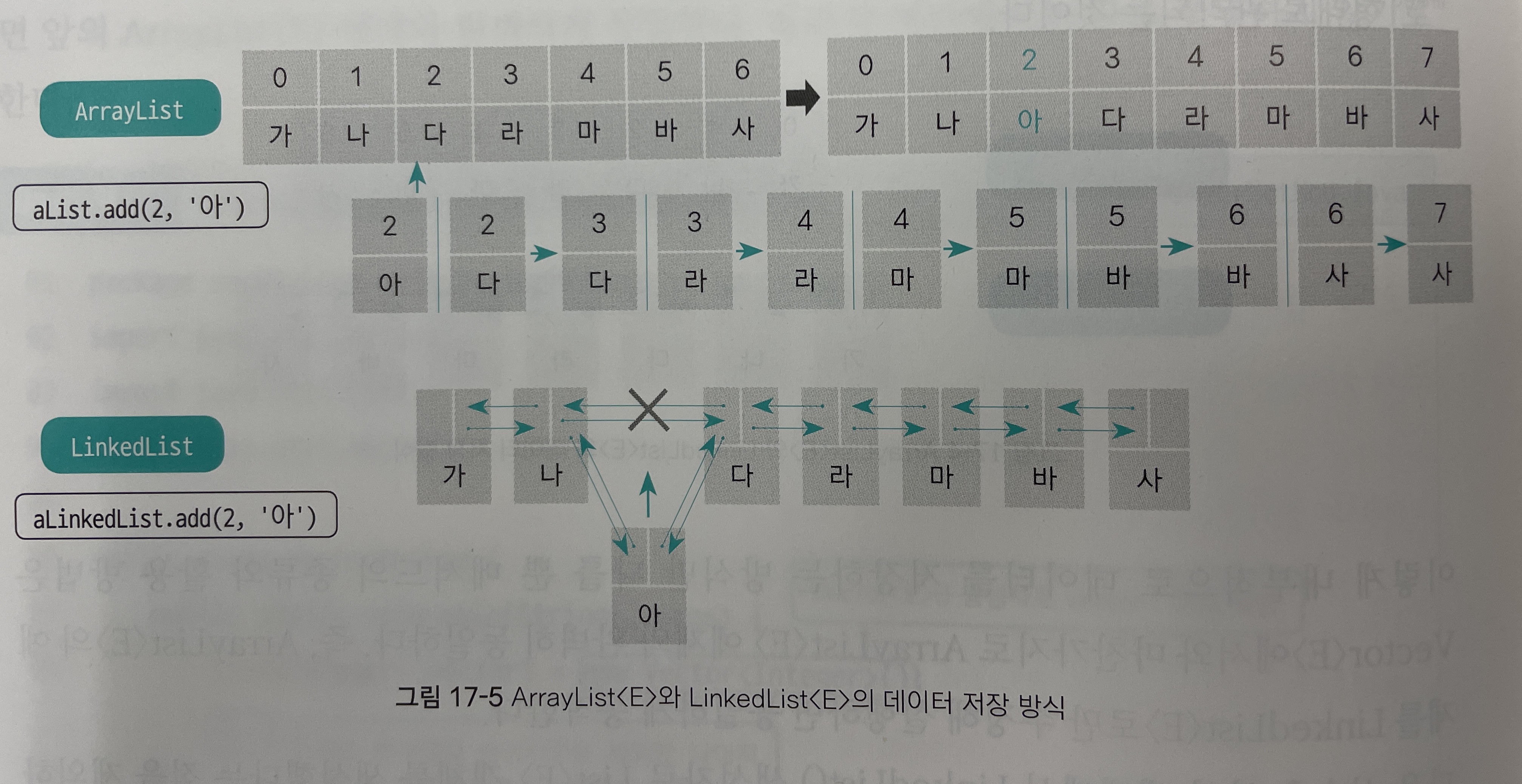
가정1: 7개의 데이터를 가진ArrayList<E>객체에서 2번 인덱스에 데이터를 추가하고자 한다.이 때 기존 2번 이후의 모든 데이터는 한 칸씩 뒤로 밀려나게 되는데, 이는 밀려나는 모든 데이터의 위치 정보를 수정해야 한다는 것을 의미한다.
만일 데이터가 1,000개이고 0번 인덱스에 데이터를 추가하면, 1,000개의 데이터 위치 정보를 모두 수정해야 한다는 것이다.
반면
LikedList<E>는 각 원소의 앞뒤 객체 정보만을 저장하고 있으므로 어딘가에 값이 추가되면 값이 추가된 위치의 앞뒤 데이터 정보만 수정하면 된다.따라서 중간에 데이터를 추가할 때 속도 차이가 날 것이라는 점을 예상할 수 있다.
가정2: 특정 인덱스 위치의 값을 가져오려고 한다.이런 경우
LinkedList<E>에서는 각 원소가 자신의 인덱스 정보를 따로 갖고 있지 않다.- 특정 인덱스 위치의 값을 가져오기 위해서는 앞에서부터 차례대로 번호를 세어가면서 인덱스의 위치를 찾아야 한다.
반면
ArrayList<E>는 데이터 자체가 인덱스 번호를 갖고 있으므로 특정 인덱스의 위치를 빠르게 찾을 수 있다.정리하자면, 데이터의 추가 또는 삭제를 하는 경우는
LinkedList<E>의 속도가 빠르며, 데이터를 검색하는 경우에는ArrayList<E>의 속도가 빠를 것이다.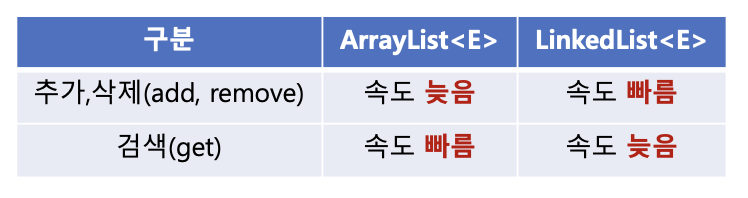
실습 - 성능 비교(데이터 추가/검색/삭제)
데이터의 추가, 검색, 삭제를 통해 비교해보면 둘의 차이점을 알 수 있다.
```java package sec01_list.EX06_ArrayListVsLinkedList;
import java.util.ArrayList; import java.util.LinkedList; import java.util.List;
public class ArrayListVsLinkedList { public static void main(String[] args) {
//#1. 데이터 추가시간 비교 List<Integer> aList = new ArrayList<>(); List<Integer> linkedList = new LinkedList<>(); long startTime=0, endTime=0; //@1-1 ArrayList 데이터 추가시간 startTime = System.nanoTime(); for(int i=0; i<100000; i++) { aList.add(0, i); } endTime = System.nanoTime(); System.out.println("ArrayList 데이터 추가시간 = " +(endTime-startTime) + " ns"); //@1-2 LinkedList 데이터 추가시간 startTime = System.nanoTime(); for(int i=0; i<100000; i++) { linkedList.add(0, i); } endTime = System.nanoTime(); System.out.println("LinkedList 데이터 추가시간 = " +(endTime-startTime) + " ns");
-
[MySQL] SELECT, JOIN, SubQuery - Practice
이 글은 MySQL 기반의 SELECT, JOIN, SubQuery 문제에 대한 정리를 바탕으로 작성했습니다.
해당 문제는 sakila DB를 기반으로 풀었습니다.
-
설치 과정에 대한 내용은 Installation이며,
-
sakila DB를 다운받는 위치는 Other MySQL Documentation 안에 Example Databases -
sakila database(ZIP)다운받으면 됩니다.
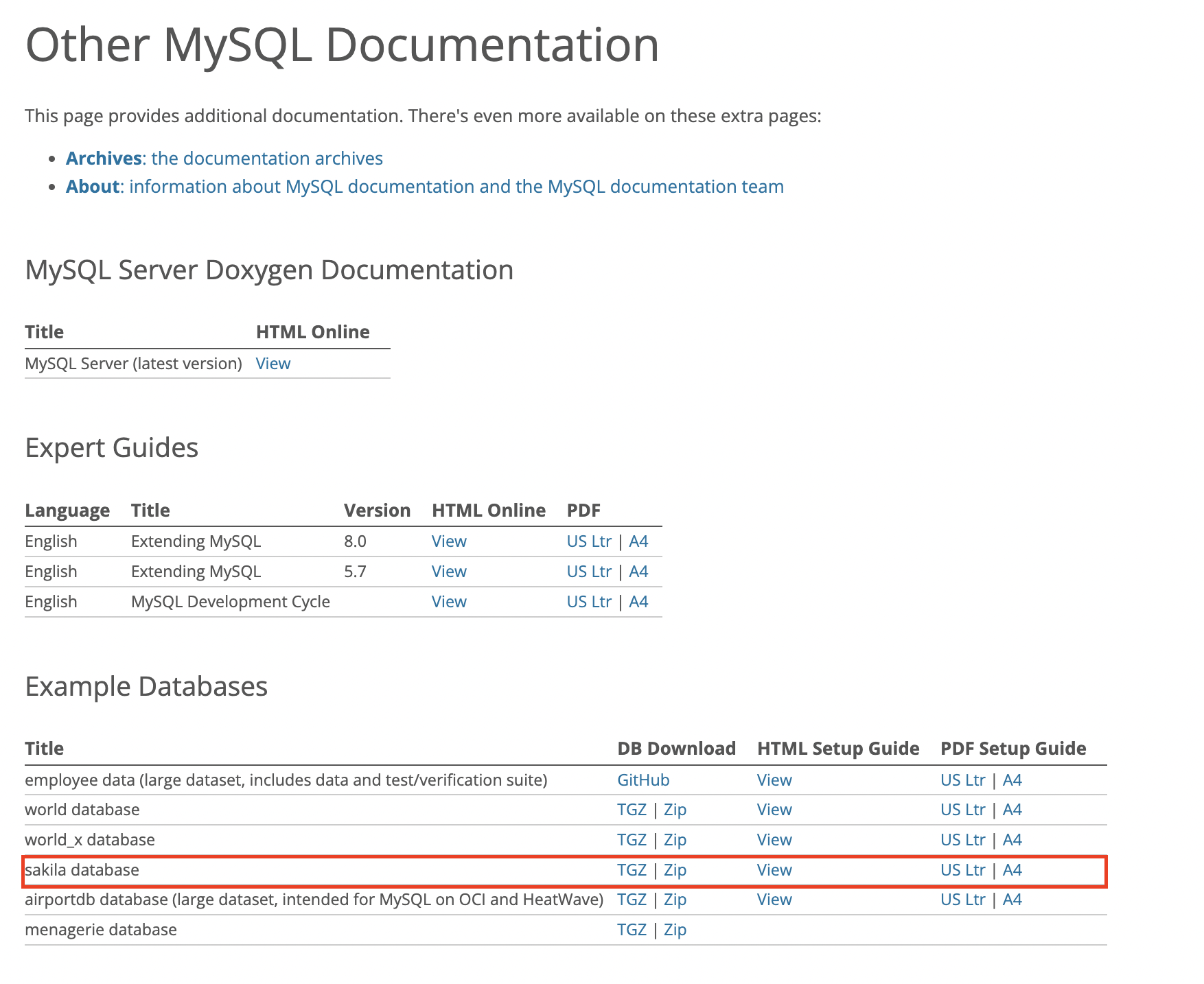
-
위의 sakila DB 다운받은 후에
MySQL Workbench를 실행한 다음, 해당 파일(4.exercise)에서 문제를 풀었습니다. -
문제를 풀기 전에
sakila DB를 사용하는 명령어를 입력한다.
use sakila;Example 1
-
-
[MySQL] SELECT, JOIN - Practice
이 글은 MySQL 기반의 SELECT, JOIN 문제에 대한 정리를 바탕으로 작성했습니다.
해당 문제는 sakila DB를 기반으로 풀었습니다.
-
설치 과정에 대한 내용은 Installation이며,
-
sakila DB를 다운받는 위치는 Other MySQL Documentation 안에 Example Databases -
sakila database(ZIP)다운받으면 됩니다.
-
위의 sakila DB 다운받은 후에
MySQL Workbench를 실행한 다음, 해당 파일(4.exercise)에서 문제를 풀었습니다. -
문제를 풀기 전에
sakila DB를 사용하는 명령어를 입력한다.
use sakila;SELECT Example
Q1. actor 테이블에서 전체 컬럼(열) 조회 -> 실행 결과 행의 수는 총 200개
SELECT * FROM actor LIMIT 200;Q2. actor 테이블에서 first_name, last_name 컬럼 조회 -> 실행 결과 행의 수는 총 200개
SELECT first_name, last_name FROM actor LIMIT 200;Q3. actor 테이블에서 first_name과 last_name을 하나로 연결(concat)하여 Actor Name이라는 컬럼명으로 조회하고, 전부 대문자로 조회 -> 실행 결과 행의 수는 총 200개
SELECT concat(first_name, '+' ,last_name) AS Actor_Name FROM actor;Q4. actor 테이블에서 actor_id, first_name, last_name을 조회하되, first_name이 Joe인 데이터만 필터링하여 조회 -> 실행 결과 행의 수는 1개
SELECT actor_id, first_name, last_name FROM actor WHERE first_name = 'Joe';Q5. actor 테이블에서 actor_id, first_name, last_name을 조회하되, last_name 에 Gen이 포함된 actor를 필터링하여 조회 (last_name의 맨 앞, 맨 뒤, 중간 등 어느 부분에 포함되어도 상관없이 전체 조회) -> 실행 결과 행의 수는 총 4개
SELECT actor_id, first_name, last_name FROM actor WHERE last_name LIKE '%Gen%';Q6. actor 테이블에서 actor_id, first_name, last_name을 조회하되, last_name에 LI(엘, 아이)가 포함된 데이터를 필터링하고, last_name, first_name 순서로 오름차순 정렬하여 조회 -> 실행 결과 행의 수는 총 10개
SELECT actor_id, first_name, last_name FROM actor WHERE last_name LIKE '%LI%' ORDER BY last_name, first_name ASC;Q7. country 테이블에서 country_id, country 열을 조회하되,
IN 연산자를 활용하여 country가 Afghanistan, Bangladesh, China 중에 속하는 데이터만 필터링하여 조회 -> 실행 결과 행의 수는 총 3개SELECT country_id, country FROM country WHERE country IN('Afghanistan', 'Bangladesh', 'China');Q8. actor 테이블에서 서로 동일한 last_name을 사용하는 배우(actor)들이 각각 몇 명인지 조회하고 싶을 때, actor 테이블에서 last_name 컬럼과 해당 last_name을 사용하는 사람의 인원 수를 집계해주는 컬럼을 조회 ex) 아래의 이미지를 참고하면, last_name으로 ALLEN을 사용하는 배우(actor)는 총 3명(2번째 행) https://guguttemy.speedgabia.com/DB/dml_practice8.png -> 8번 문제 실행 결과 행의 수는 총 121개
SELECT last_name, count(last_name) FROM actor GROUP BY last_name;Q9. actor 테이블에서 last_name 컬럼과 해당 last_name을 사용하는 수를 집계해주는 컬럼을 조회하되, 집계되는 컬럼의 별칭은
Count of Last Name이라고 짓고, last_name 카운트가 2 초과인 그룹만 필터링하여 조회 -> 실행 결과 행의 수는 총 20개SELECT last_name, count(last_name) AS "Count of Last Name" FROM actor GROUP BY last_name HAVING count(last_name) > 2;JOIN Example
Q10. address 테이블의 정보(description) 조회
SELECT * FROM address;Q11. address 테이블의 총 행 수 조회 -> 실행 결과 행의 수는 총 603개
SELECT count(*) FROM address;Q12. address 테이블의 가상 상위 데이터 5개만 제한(LIMIT)하여 조회 -> 실행 결과 행의 수는 총 5개
SELECT * FROM address ORDER BY address_id LIMIT 5;Q13. staff 테이블의 별칭을 s, address 테이블의 별칭을 a로 짓고, 두 테이블을 연결(JOIN)하여 address_id가 일치하는 first_name, last_name, address를 조회 -> 실행 결과 행의 수는 총 2개
SELECT first_name, last_name, address FROM staff c JOIN address a WHERE c.address_id = a.address_id;Q14. staff 테이블의 별칭을 s, payment 테이블의 별칭을 p로 짓고, 두 테이블을 연결(JOIN)하여 staff_id가 일치하는 조건의 staff_id, first_name, last_name 및 amount의 총 금액(sum) 컬럼을 조회하되 payment_date가 2005-08-01 00:00:00 이후이고, 2005-08-02 00:00:00 ‘미만’인 데이터만 필터링하여 staff_id를 기준으로 묶어서(grouping) 조회** -> 실행 결과 행의 수는 총 2개
SELECT s.staff_id, first_name, last_name, sum(amount) FROM staff s JOIN payment p ON s.staff_id = p.staff_id WHERE p.payment_date BETWEEN '2005-08-01 00:00:00' AND '2005-08-02 00:00:00' GROUP BY staff_id;Q15. film 테이블의 별칭을 f, film_actor 테이블의 별칭을 fa로 짓고, 두 테이블을 연결(JOIN)하여 각 film_id가 일치하는 조건의 title 및 해당 film에 참여한 총 actor의 수를 의미하는 컬럼 ‘총 배우 수’ 컬럼을 film 테이블의 title 별로(grouping) 조회 (단, 이대로 조회하면 결과 데이터가 총 997행이기 때문에 상위 20개의 행만 제한하여 조회) -> 실행 결과 행의 수는 총 20개(로 제한, LIMIT 사용)
SELECT title, actor FROM film f JOIN film_actor fa WHERE f.film_id = fa.film_id LIMIT 20;Q16. inventory 테이블의 정보(description) 조회
SELECT * FROM inventory;Q17. inventory 테이블의 데이터 상위 10개 조회 ->실행 결과 행의 수는 총 10개
SELECT * FROM inventory LIMIT 10;Q18. film 테이블에서 title, description 컬럼을 조회하되, 상위 20개만 조회 -> 실행 결과 행의 수는 총 20개
SELECT title, description FROM film LIMIT 20;Q19. ALABAMA DEVIL film이 모든 영화 대여점에 총 몇 개의 복제본(영화 필름)이 배포되어있는지 알고 싶을 때, film 테이블의 별칭을 f, inventory 테이블의 별칭을 i로 짓고, 두 테이블을 연결(JOIN)하여 film_id 컬럼이 일치하는 조건의 title 및 film_id의 총 개수(count)를 ‘복제본’으로 별칭을 작성하여 title 별로 조회하되, title이 ‘ALABAMA DEVIL’인 film만 조회 -> 실행 결과 행의 수는 1개
LECT title, count(f.film_id) AS '복제본' FROM film f JOIN inventory i WHERE f.film_id = i.film_id AND title = 'ALABAMA DEVIL';Q20. 고객 별 총 사용 금액을 last_name을 오름차순 정렬하여 조회하고 싶을 때, customer 테이블의 별칭을 c, payment 테이블의 별칭을 p로 짓고, 두 테이블을 customer_id컬럼으로 연결(JOIN)하여 first_name, last_name, amount의 총 액수를 조회하되, first_name, last_name 순으로 묶어서(grouping) last_name을 기준으로 오름차순하여 조회 -> 실행 결과 행의 수는 599개
SELECT first_name, last_name, sum(amount) FROM customer c JOIN payment p GROUP BY first_name, last_name ORDER BY last_name ASC;
-
-
[MySQL] MacOS M1 기반 MySQL, Workbench, Sakila 설치하기
해당 글은 MacOS M1 기반으로 MySQL, Workbench 설치하는 과정을 간략하게 작성했습니다.
MySQL
[1] brew를 통해 mysql 설치
brew install mysql➜ ~ brew install mysql ==> Downloading https://formulae.brew.sh/api/formula.jws.json #=#=# ==> Downloading https://formulae.brew.sh/api/cask.jws.json #=#=# ==> Fetching dependencies for mysql: icu4c, ca-certificates, openssl@1.1, libevent, libcbor, libfido2, lz4, protobuf@21, zlib, xz and zstd ==> Fetching icu4c ==> Downloading https://ghcr.io/v2/homebrew/core/icu4c/manifests/72.1 ######################################################################### 100.0% // ... 중간 생략 ==> Downloading https://ghcr.io/v2/homebrew/core/zstd/blobs/sha256:e3cb579108afe ==> Downloading from https://pkg-containers.githubusercontent.com/ghcr1/blobs/sh ######################################################################### 100.0% ==> Fetching mysql ==> Downloading https://ghcr.io/v2/homebrew/core/mysql/manifests/8.0.33_1 ######################################################################### 100.0% ==> Downloading https://ghcr.io/v2/homebrew/core/mysql/blobs/sha256:e56237aaf649 ==> Downloading from https://pkg-containers.githubusercontent.com/ghcr1/blobs/sh ######################################################################### 100.0% ==> Installing dependencies for mysql: icu4c, ca-certificates, openssl@1.1, libevent, libcbor, libfido2, lz4, protobuf@21, zlib, xz and zstd ==> Installing mysql dependency: icu4c ==> Pouring icu4c--72.1.arm64_monterey.bottle.tar.gz 🍺 /opt/homebrew/Cellar/icu4c/72.1: 263 files, 78.4MB ==> Installing mysql dependency: ca-certificates ==> Pouring ca-certificates--2023-05-30.arm64_monterey.bottle.tar.gz ==> Regenerating CA certificate bundle from keychain, this may take a while... 🍺 /opt/homebrew/Cellar/ca-certificates/2023-05-30: 3 files, 216.2KB ==> Installing mysql dependency: openssl@1.1 ==> Pouring openssl@1.1--1.1.1u.arm64_monterey.bottle.tar.gz // ... 중간 생략 🍺 /opt/homebrew/Cellar/zstd/1.5.5: 31 files, 2.3MB ==> Installing mysql ==> Pouring mysql--8.0.33_1.arm64_monterey.bottle.tar.gz ==> /opt/homebrew/Cellar/mysql/8.0.33_1/bin/mysqld --initialize-insecure --user= ==> Caveats We've installed your MySQL database without a root password. To secure it run: mysql_secure_installation MySQL is configured to only allow connections from localhost by default To connect run: mysql -u root To start mysql now and restart at login: brew services start mysql Or, if you don't want/need a background service you can just run: /opt/homebrew/opt/mysql/bin/mysqld_safe --datadir=/opt/homebrew/var/mysql ==> Summary 🍺 /opt/homebrew/Cellar/mysql/8.0.33_1: 318 files, 300.0MB ==> Running `brew cleanup mysql`... Disable this behaviour by setting HOMEBREW_NO_INSTALL_CLEANUP. Hide these hints with HOMEBREW_NO_ENV_HINTS (see `man brew`). ==> Upgrading 1 dependent of upgraded formulae: Disable this behaviour by setting HOMEBREW_NO_INSTALLED_DEPENDENTS_CHECK. Hide these hints with HOMEBREW_NO_ENV_HINTS (see `man brew`). openssl@3 3.1.0 -> 3.1.1 ==> Fetching openssl@3 ==> Downloading https://ghcr.io/v2/homebrew/core/openssl/3/manifests/3.1.1 ######################################################################### 100.0% ==> Downloading https://ghcr.io/v2/homebrew/core/openssl/3/blobs/sha256:e2a9c60c ==> Downloading from https://pkg-containers.githubusercontent.com/ghcr1/blobs/sh ######################################################################### 100.0% ==> Upgrading openssl@3 3.1.0 -> 3.1.1 ==> Pouring openssl@3--3.1.1.arm64_monterey.bottle.tar.gz 🍺 /opt/homebrew/Cellar/openssl@3/3.1.1: 6,495 files, 28.4MB ==> Running `brew cleanup openssl@3`... Removing: /opt/homebrew/Cellar/openssl@3/3.1.0... (6,494 files, 28.4MB) Removing: /Users/junyongmoon/Library/Caches/Homebrew/openssl@3--3.1.0... (7.6MB) ==> Checking for dependents of upgraded formulae... ==> No broken dependents found! ==> Caveats ==> mysql We've installed your MySQL database without a root password. To secure it run: mysql_secure_installation MySQL is configured to only allow connections from localhost by default To connect run: mysql -u root To start mysql now and restart at login: brew services start mysql Or, if you don't want/need a background service you can just run: /opt/homebrew/opt/mysql/bin/mysqld_safe --datadir=/opt/homebrew/var/mysql[2] mysql 버전 확인
mysql --version➜ ~ mysql --version mysql Ver 8.0.33 for macos12.6 on arm64 (Homebrew)[3] mysql server 실행
- MySQL 서버를 가동시켜주는 명령어
mysql.server start➜ ~ mysql.server start Starting MySQL . SUCCESS![4] mysql 기본 설정
mysql_secure_installation질문 리스트
- VALIDATE PASSWORD COMPONENT ( 복잡한 비밀번호 여부 ) : n
- set the password (비밀번호 설정 & 확인) : 1234
- Remove anonymous users? (익명 사용자 삭제) : y
- Disallow root login remotely? (원격 접속 허용하지 않을 것인지) : y
- Remove test database and access to it? (test DB 삭제 여부) : n
- Reload privilege tables now? (변경된 권한을 반영하여 테이블 다시 로드) : y
``` ➜ ~ mysql_secure_installation
Securing the MySQL server deployment.
Connecting to MySQL using a blank password.
VALIDATE PASSWORD COMPONENT can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which are secure enough. Would you like to setup VALIDATE PASSWORD component?
Press y|Y for Yes, any other key for No: n Please set the password for root here.
New password:
Re-enter new password: By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment.
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y Success.
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8