흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[Goodfriends] 젠킨스를 사용하여 CI/CD Pipeline 구축기(백엔드편)
이 글은 우리FISA 1기 굿프렌즈팀의 기술 블로그에 게시된 글 입니다.
Intro
굿프렌즈팀의 프로젝트에서 백엔드 CI/CD 구조는 다음과 같습니다.
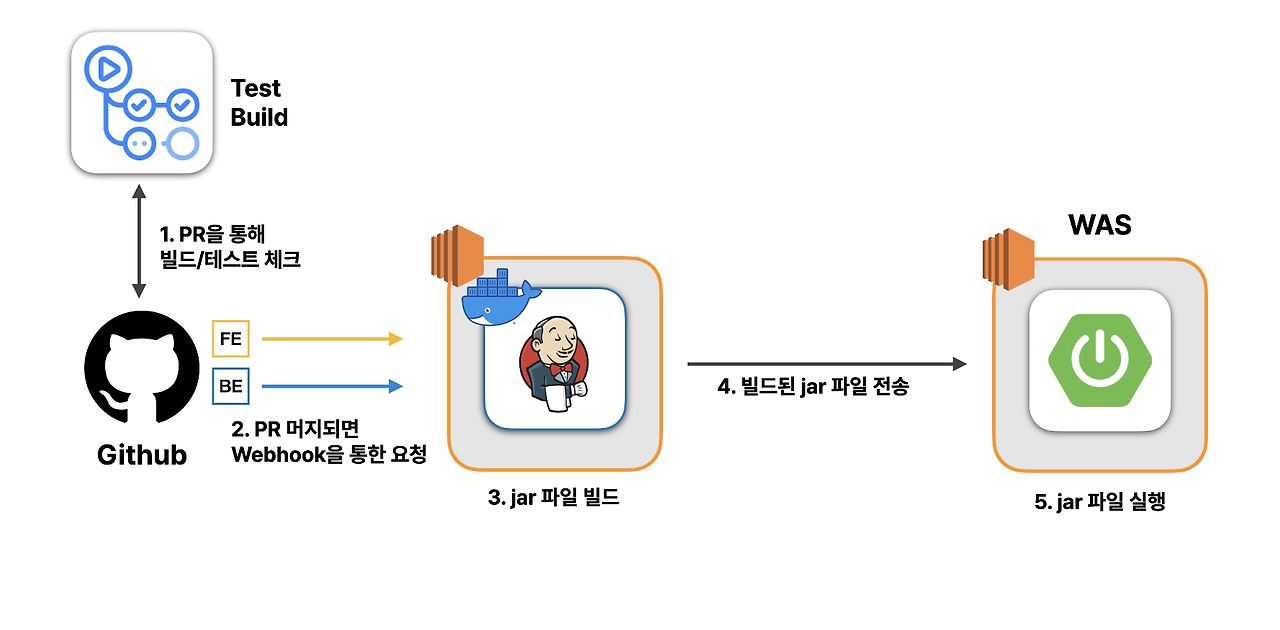
우선, 굿프렌즈의 프론트/백엔드 개발자가 기능을 개발하여 Github에 PR을 생성합니다. 이때 PR 코드가 정상적으로 빌드되고, 모든 테스트를 통과하는지 Github Actions를 사용하여 우선적으로 검사합니다. 이때, PR 브랜치의 코드가 문제가 있다면 develop 브랜치로 병합이 불가능합니다.
정상적으로 빌드가 되는 코드는 굿프렌즈 개발자들끼리 코드리뷰가 진행되고, develop 브랜치에 병합이 됩니다.
이때, Github은 굿프렌즈팀이 구축한 젠킨스 서버에
Webhook을 통해 병합 사실을 알립니다.Webhook이란, 특정한 애플리케이션이 다른 애플리케이션으로 이벤트 발생 정보를 실시간으로 제공하기 위한 방법입니다.젠킨스는 외부에 Webhook URL을 열어두고, Github으로부터 이 Webhook URL로 요청을 받아 이벤트가 발생한 즉시 그 사실을 알 수 있습니다.
[백엔드]
Webhook을 통해 신호를 받은 젠킨스는 미리 지정된 젠킨스 파이프라인 스크립트를 실행하여 스프링 부트 애플리케이션을 빌드하여 jar 파일을 생성합니다.
생성한 jar 파일은 스프링부트 애플리케이션이 실행되고 있는 EC2 인스턴스로 전송됩니다. 그리고 스프링부트 인스턴스에서 jar 파일이 실행되어 배포가 완료됩니다.
1. 젠킨스 서버에게 github 접근 권한 주기
젠킨스가 Github에서 레포지토리를 clone하기 위해서는 해당 레포지토리에 대한 접근 권한이 필요합니다.
(public repository이면 아래 과정들을 안해도 상관 없습니다)
1-1. github에서 personal access token 발급 받기
우측 상단 프로필 선택 후 하단 settings → 좌측 하단 Developer settings → Personal Access tokens → Tokens(classic) →
우측 상단에
Generate new token선택합니다.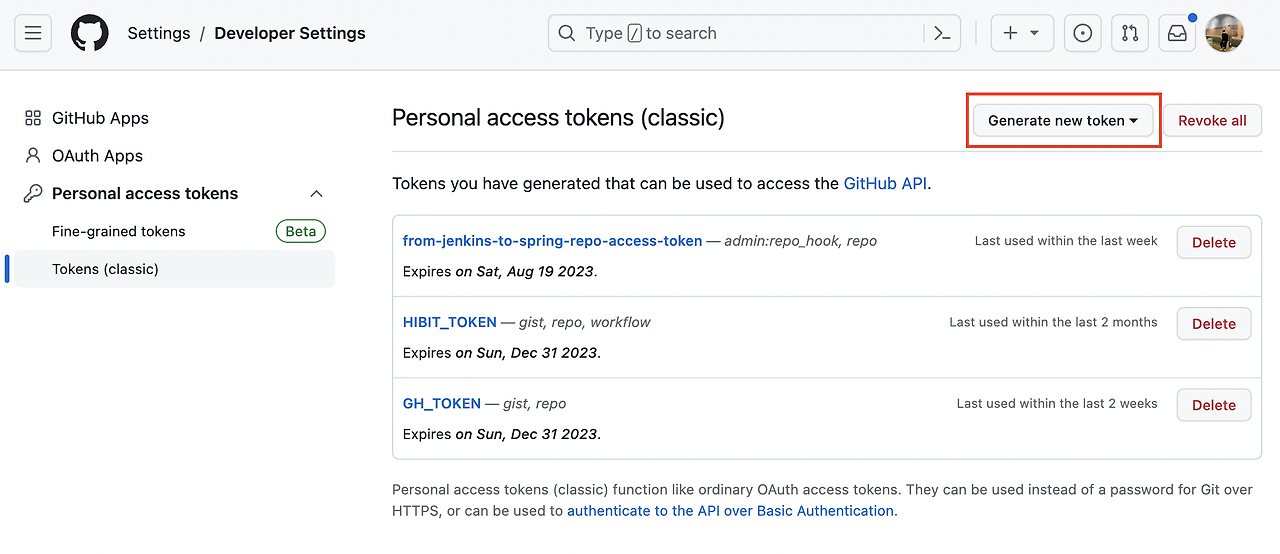
Note, Expiration, Select scopes를 아래와 같이 선택했습니다.
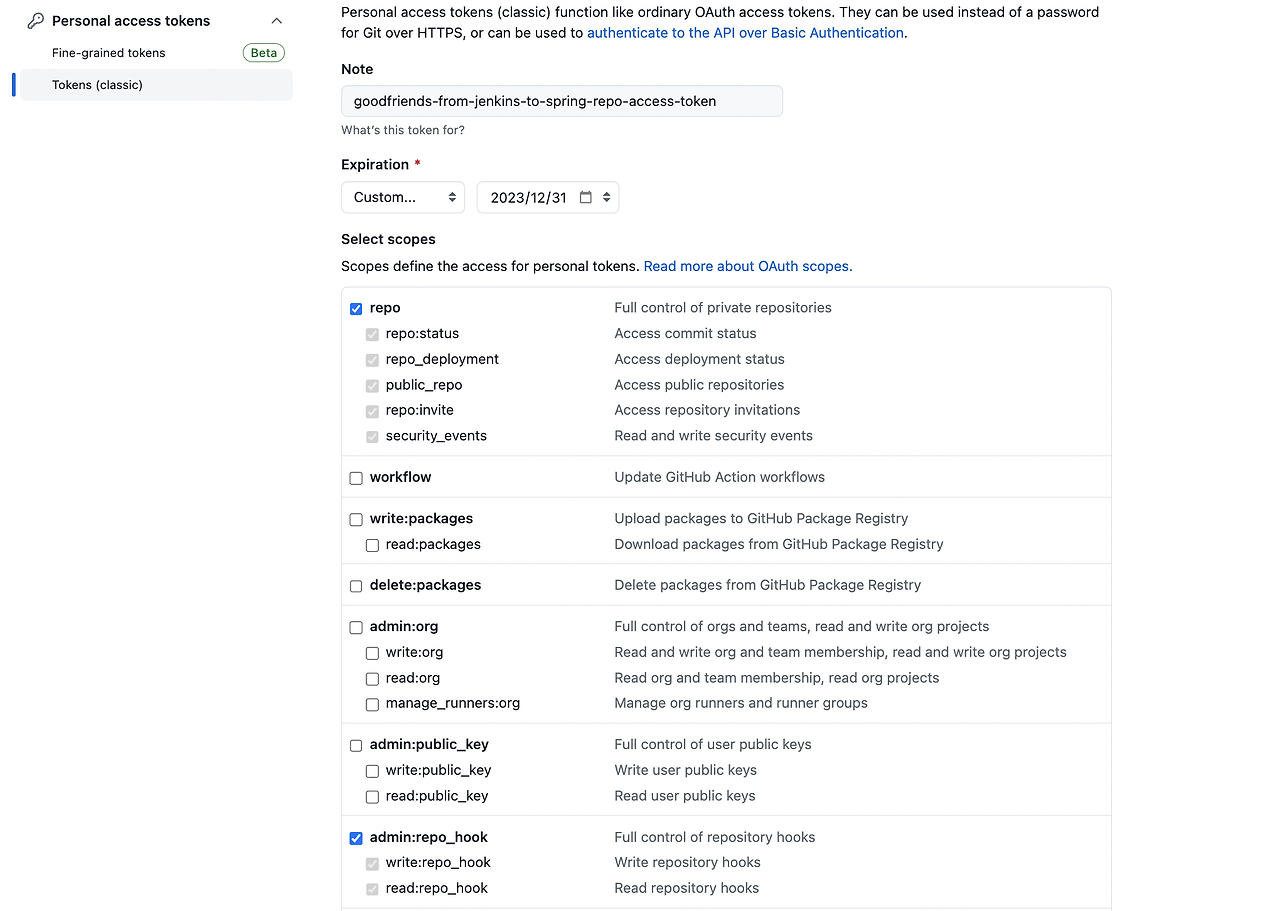
그런 다음 하단에
Generate token을 선택했습니다.가운데 부분에 체크 아이콘으로 표시된 access token 값을 복사한 뒤 따로 보관해두셔야 합니다.
(저희 굿프렌즈팀은 “goodfriends-from-jenkins-to-spring-repo-access-token.txt” 라는 파일을 생성한 뒤에 복사한 키 값을 보관했습니다)
-
[Goodfriends] EC2 환경에서 도커를 활용한 젠킨스 설치하기
이 글은 우리FISA 1기 굿프렌즈팀의 기술 블로그에 게시된 글 입니다.
우선 굿프렌즈팀의 프로젝트에서 구축하려는 CI/CD 구조는 다음과 같습니다.
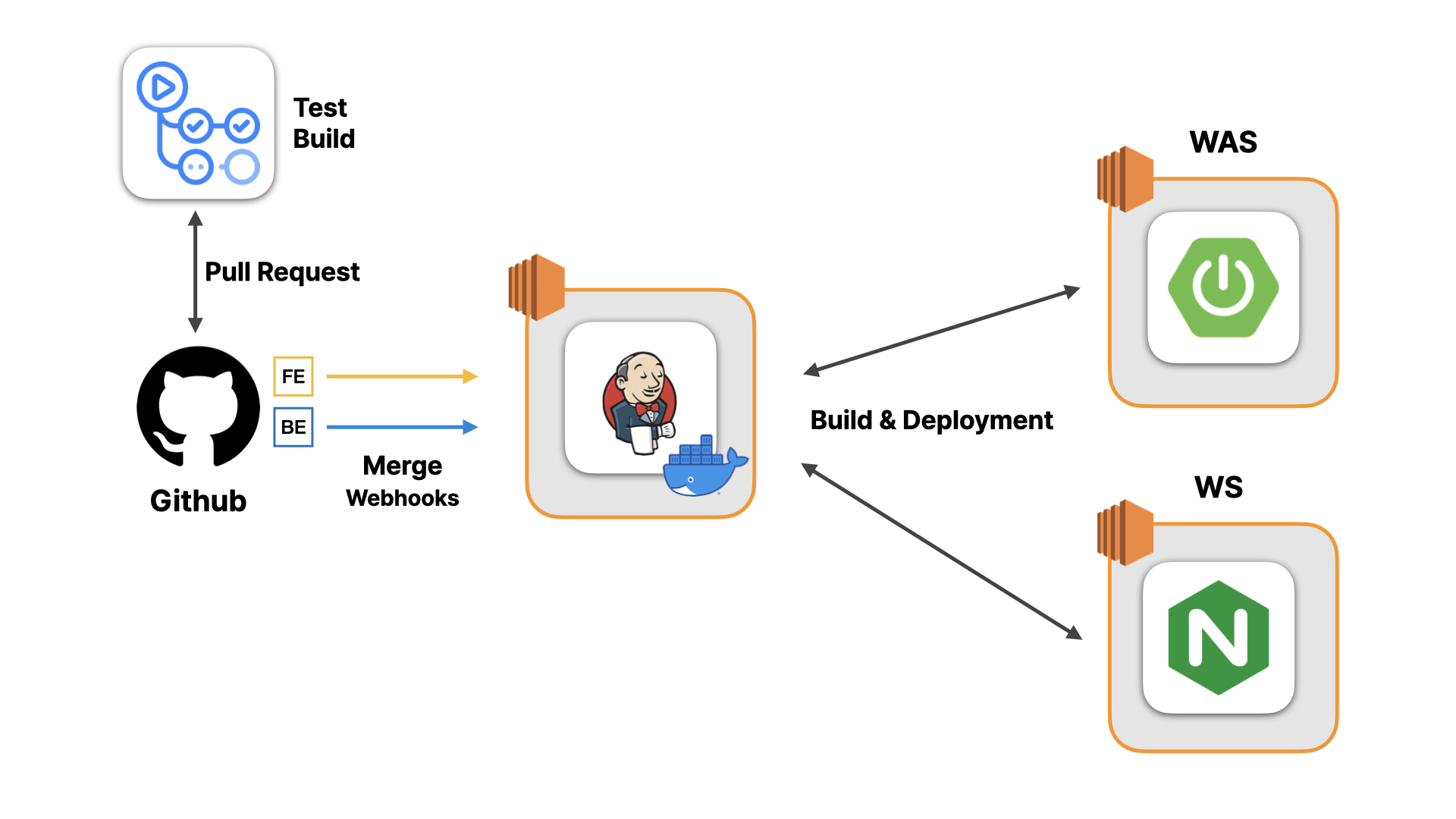
이번 스프린트3에서는 저는 배포와 CI/CD와 같이 인프라와 관련된 태스크에 집중하고 있습니다.
기존 스프린트 2에서 굿프렌즈팀은 새로운 기능을 병합할 때마다 SSH로 EC2 인스턴스에 접속하여 쉘 스크립트를 매번 실행해야만 한다는 단점이 존재했습니다. 저희 팀은 develop 브랜치에 새로운 기능을 병합될 때마다 자동으로 감지하고, 스프링 애플리케이션을
jar파일로 빌드하여 배포하는 환경이 필요하다고 느꼈습니다. 따라서 CI/CD 도구를 도입하기로 결정했습니다.이번 글에서는 굿프렌즈가 EC2 환경에서 도커를 사용하여 젠킨스를 설치한 방법에 대해서 정리하려고 합니다.
젠킨스 도입
파이프라인을 구축할 때 여러 가지 방법이 있습니다. Github Action, Jenkins, Travis CI, Circle CI 등등
그 중에서 젠킨스(Jenkins)는 세계적으로 많은 개발자들이 사용중인 CI/CD 관리(빌드, 테스트, 배포)를 돕는 개발 도구입니다.
그리고 젠킨스는 매우 다양한 IDE를 지원하고 개발자가 직접 커스텀할 수 있는 옵션이 많습니다.
또한 많은 개발자분들이 사용하기 때문에 래퍼런스할 수 있는 다양한 문서들이 존재하여 초기 학습 비용이 적게 든다고 생각합니다.
따라서, 젠킨스를 구축하고 인프라에 있어서 다양한 선택지를 가져가는게 더 좋을 것 같아서 젠킨스를 도입하기로 결정했습니다.
1. Jenkins 전용 EC2 서버 생성
저희 굿프렌즈팀은 우선 Jenkins 전용의 EC2 인스턴스 주소를 생성했습니다.
1-1. 인스턴스 시작
인스턴스 이름: GOODFRIENDS-jenkins-server
애플리케이션 및 OS 이미지(Amazon Machine Image): Ubuntu
인스턴스 유형: t2.micro
키 페어(로그인): GOODFRIENDS-rsa-key.pem
네트워크 생성
-
기존 보안그룹 선택 -> GOODFRIENDS-jenkins-security-group -> 인바운드 규칙(아래 2가지 유형 추가)
-
1) 유형: SSH / 포트 범위: 22 / 소스: 내 IP 주소
-
2) 유형: HTTP / 포트 범위: 80 / 소스: 내 IP주소 / 설명: ec2 port for access to use jenkins
도커를 사용하는 이유
굿프렌즈 팀은 EC2 인스턴스에 도커를 사용하여 젠킨스 컨테이너를 띄웠습니다.
만약 도커를 사용하지 않고, 젠킨스를 우분투에 직접 설치한다면 해주어야할 환경 설정이 많습니다. 젠킨스를 돌리기 위한 JDK 설치, 젠킨스 설치 및 포트 설정, 방화벽 설정 등등..
하지만 도커를 이용한다면 이런 환경 설정 없이 간단한 명령어 몇 가지만으로 젠킨스를 설치하고 서버에 띄울 수 있습니다.
즉, 우분투에 직접 설치할 때 해주어야할 여러 과정들을 생략할 수 있습니다.
도커는 컨테이너 기술을 제공하는 수 많은 서비스들 중 하나입니다. 도커를 통해 젠킨스 컨테이너를 받아와서 실행만 하면 됩니다.
이러한 이점으로 굿프렌즈팀은 도커의 이점을 이용하고자 도커를 사용하게 되었습니다.
-
-
[Goodfriends] Agile 기반 Scrum 프로세스 도입
이 글은 우리FISA 1기 굿프렌즈팀의 기술 블로그에 게시된 글 입니다.
애자일(Agile)이란?
애자일 소프트웨어 개발(Agile software development) 혹은 애자일 개발 프로세스는 소프트웨어 엔지니어링에 대한 개념적인 얼개로, 프로젝트의 생명주기동안 반복적인 개발을 촉진한다. - 위키백과 -
-
[Goodfriends] 우리 팀의 Git-flow 전략을 소개합니다.
이 글은 우리FISA 1기 굿프렌즈팀의 기술 블로그에 게시된 글 입니다.
이 게시글은 git에 대한 기본적인 명령어 이해를 알고 있다는 전제하에 작성했습니다
Git-flow 전략
git 브랜치의 대표적인 전략은 다음과 같습니다.
- git flow
- github flow
- gitlab flow
우리 팀은 git 브랜치 전략 중 하나인 Git flow 전략을 사용하기로 했습니다. 참고로 “git flow”는 2010년 빈센트 드리슨이 창안했습니다.
하지만 git flow 전략을 모두 가져가진 않고, 그중에서 필요한 부분을 가져가기로 했습니다.
git flow 전략을 들어본 사람은 알겠지만, 배포 주기가 길고 팀의 이력이 있는 경우 적합한 브랜치 전략입니다.
결과: 굿프렌즈팀의 Git-flow
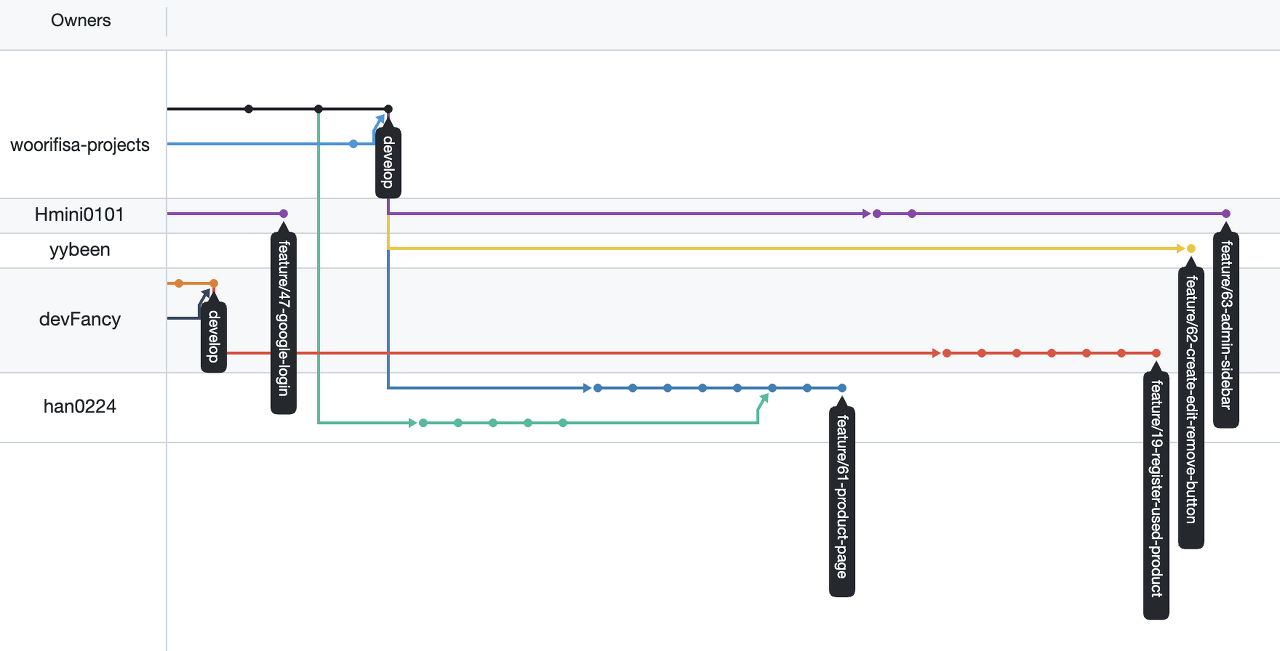
결론적으로 우리 굿프렌즈팀이 Git-flow을 적용한 사진입니다.
해당 부분에 대한 설명을 지금부터 다루도록 하겠습니다.
Git Repository 구성
프로젝트 시작하기에 앞서, 현재 Git Repository 구성부터 살펴보겠습니다.
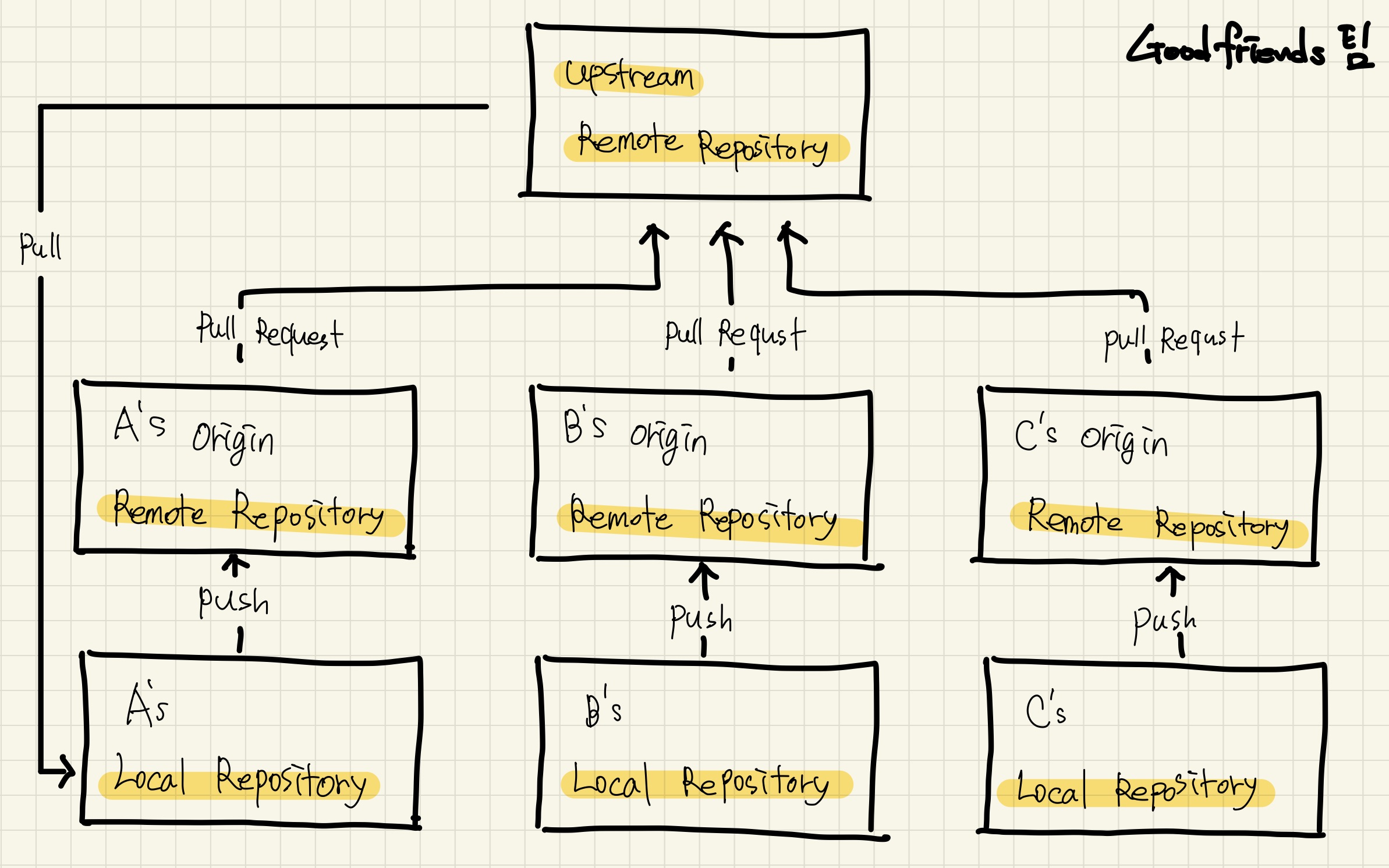
위 그림은 Git Repository 구성과 워크플로우를 설명하고 있습니다.
-
[Goodfriends] 굿프렌즈팀의 이벤트 스토밍(Event Storming) 도입기
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8