흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
Spring Boot 요청 흐름 추적: Logging Filter와 traceId 적용기
Prologue
이번 포스팅에서는 Spring Boot 프로젝트에서 HTTP 요청과 응답을 효과적으로 로깅하고, 멀티쓰레드 환경에서 요청 흐름을 명확히 추적할 수 있도록
traceId를 활용하는 방법을 소개합니다.일반적으로
- 단일 서비스에서는
requestId로 요청을 구분하고, - 분산 시스템(마이크로서비스) 에서는
traceId로 전체 요청 흐름을 추적합니다.
이 글에서는 단일 서비스 환경을 다루지만, 초기부터
traceId를 적용하여 향후 분산 시스템에서도 확장 가능한 구조를 제공합니다.특히, 실무에 적용한 내용을 중심으로 프로덕션 환경에서도 활용 가능한 실용적인 예제를 설명합니다.
예상 독자
-
Spring Boot 프로젝트에 Logging Filter를 적용하고자 하는 분
-
Filter와 HandlerInterceptor의 차이점을 알고 싶은 분
-
OncePerRequestFilter의 동작 원리와 사용 이유가 궁금한 분
-
멀티쓰레드 환경에서 로그가 뒤섞이는 문제를 해결하고 싶은 분
-
프로덕션 환경에 바로 적용 가능한 실용적인 예제를 찾는 분
관련 포스팅
Filter vs. HandlerInterceptor
해당 섹션에 대한 자세한 내용은 이 글을 참고해 주시기 바랍니다.
아래 세부 섹션에 있는 내용은 해당 글과 다른 자료들을 종합해서 정리했습니다.
Filter
Filter는 Spring Framework의 일부가 아닌 웹 서버(servlet container) 수준의 컴포넌트입니다. 요청과 응답을 서블릿이 처리하기 전후로 가로채어 조작할 수 있습니다.대표적인 예로
Spring Security가 있습니다.Spring Security에서는 인증/인가를 위해 여러 개의 Filter 체인을 사용하며, 이를 Spring과 연동하기 위해DelegatingFilterProxy를 활용합니다.
이 구조 덕분에Spring Security는 Spring MVC에 종속되지 않고도 동작할 수 있습니다.Filter는 다음과 같은 메서드를 제공합니다.
init: 필터 초기화 시 호출doFilter: 요청과 응답을 가로채어 처리 (핵심 메서드)destroy: 필터 종료 시 호출
- 단일 서비스에서는
-
Spring Boot 환경의 Multi Module에서 logback 환경별 설정하기
Prologue
-
멀티 모듈 프로젝트로 전환하면서 환경별 로그 설정의 필요성을 절실히 느꼈습니다.
-
운영 환경에서는 로그의 형식과 수준이 서비스 안정성과 직결되기 때문에 더욱 중요합니다.
-
이번 글은 실제 운영 환경에서 적용하는 것 보다는 멀티 모듈 구조에서 환경별로
logback.xml을 구성한 경험을 공유하기 위해 작성했습니다.
관련 포스팅
-
-
글또 10기 회고
글또는 글 쓰는 개발자 모임의 줄임말입니다. 궁금하시다면 글또 운영진분들이 만든 홈페이지에 가보시면 자세히 확인할 수 있습니다.
시작하며
지난 글또 9기 회고에 이어, 글또 10기가 3월 30일을 끝으로 마무리되면서 지난 6개월간의 활동을 돌아보고자 이 글을 작성하게 되었다.
글또 10기를 시작한 이유
글또 10기를 시작한 이유는 9기 때와 마찬가지로 글을 꾸준히 작성하는 것을 목표로 삼았고, 글쓰기 외에도 얻을 수 있는 다양한 장점들이 있어 다시 한번 참여하게 되었다.
이번 10기를 가로(INPUT/OUTPUT/못해서 아쉬운 것)과 세로(예상했던 일/예상에 없던 일)를 기준으로 표를 만들었고, 활동을 키워드로 정리해본 결과, 아래 그림과 같이 필자의 주요 활동들을 한눈에 확인할 수 있다.
(해당 회고 템플릿을 제공해준 YI님께 이 자리를 빌어 감사의 말씀 전합니다 👏)
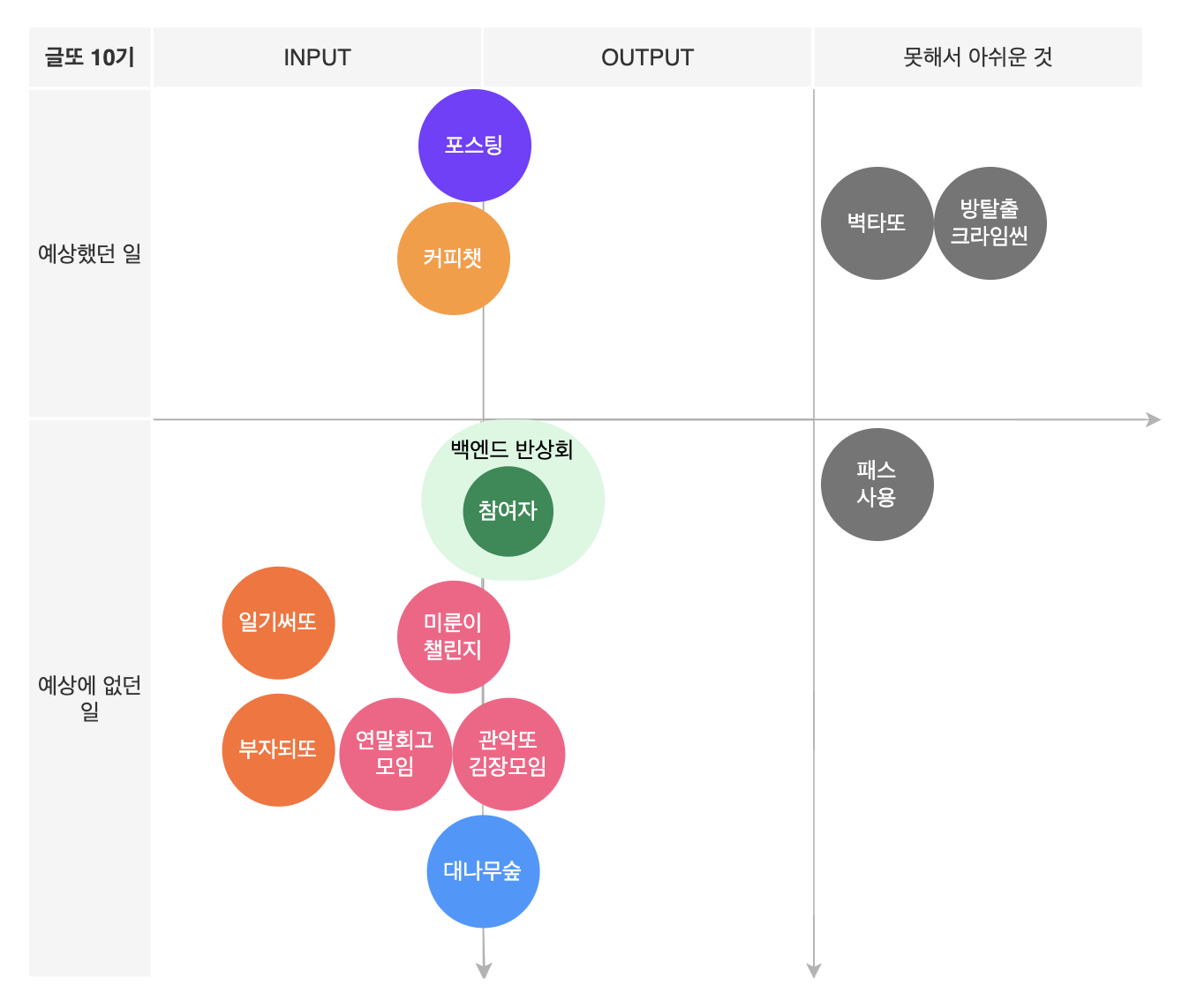
-
DDD 세레나데 7기, 5주간의 여정을 돌아보며
이 글은 넥스트스텝의 DDD 세레나데 7기 교육을 5주간 참여하며 배운 경험과 느낀 점을 정리한 후기입니다.
Prologue
아래는 DDD 세레나데 7기 교육을 무사히 끝마친 후 받은 수료증입니다.

DDD 세레나데 7기에 참여하면서 도메인 주도 설계(DDD)의 기본 개념부터 실전 적용까지 다양한 내용을 배울 수 있었습니다.
미션을 수행하며 리뷰어 피드백을 반영하는 과정이 큰 도움이 되었습니다.
1주차에 대한 리뷰는 이미 작성한 글인 DDD 세레나데 7기 1주차 (feat. 이벤트 스토밍) 를 참고하시면 되므로, 이번 글에서는 2주차부터 정리하고자 합니다.
-
[리뷰] 삶의 태도를 돌아보는 면접의 질문들 - 면접을 넘어, 일하는 태도를 고민하다
이 글을 삶의 태도를 돌아보는 면접의 질문들 책을 읽고, 책의 내용을 정리하며 필자의 개인적인 생각을 함께 정리한 것입니다.
시작하며

이 책의 제목을 보면 처음에는 ‘면접을 어떻게 잘 볼 수 있을까?’라는 궁금증에서 읽기 시작했다.
하지만 책을 읽어갈수록, 면접 기술을 배우는 것을 넘어 면접이라는 과정이 어떤 의미를 가지는지 고민하게 되었다. 특히 직장인이라면, 면접을 단순한 평가가 아니라 자신의 일하는 방식과 태도를 되돌아볼 기회로 삼을 수 있다는 점에서 더욱 의미 있는 책이었다.
이 책은 단순히 면접을 잘 보는 법을 알려주는 것이 아니라, 자신이 해왔던 일들을 돌아보고, 앞으로 어떤 방식으로 일해야 하는지 고민할 기회를 제공하는 책이다. 필자는 책을 읽으며 정리한 내용을 개인적인 경험과 해석을 덧붙여 작성했다. 따라서 본문의 내용이 실제 책과 100% 일치하지 않을 수 있다는 점을 미리 밝힌다.
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8