흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[Hibit] Gradle 프로젝트에 Jacoco 설정하기: 코드 커버리지 80%
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
-
예상 독자: Spring Boot 기반 테스트 코드를 작성하는 개발자
-
이 글은 히빗 프로젝트(ver.2)에
Jacoco를 설정한 과정에 대해 공유하고자 합니다. 아래 글부터는 히빗 프로젝트(ver.2) 를히빗2로 줄여서 작성했습니다.
-
-
Spring Boot 기반 통합 테스트와 슬라이스 테스트: 효과적인 레이어별 코드 검증 방법
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
- 예상 독자: Spring Boot 기반 통합 테스트와 슬라이드 테스트 코드를 작성하는 개발자
-
[Hibit] 좋은 단위 테스트란?
이 글은 실제 히빗 프로젝트(ver.2)를 혼자서 개발하면서 경험한 내용을 정리한 글입니다.
- 예상 독자: Spring Boot 기반 단위 테스트 코드를 작성하는 개발자
도입 배경
이전 히빗 프로젝트(ver.1)에서는 테스트 코드를 도입하지 못했다. 정확히 말하면 하지 않았다.
작년 4월부터 11월까지 진행했던 팀 프로젝트인 히빗(ver.1) 을 진행하면서, 초반에는 테스트 코드를 작성하려고 노력했다.
소셜 로그인 기능에 대한 단위 테스트와 통합 테스트를 작성하면서 얻은 경험을 정리하고 팀원들과 공유하기도 했지만, 각 팀원들이 히빗 팀 프로젝트 외에 다른 곳에도 시간을 할애해야 했기 때문에 이뤄지지 못했다.
나 또한 히빗 프로젝트 뿐만 아니라 여러 활동에 참여하고 있어서, 시간이 갈 수록 테스트 코드를 작성하는 것에 대한 시간을 투자하지 못했다.
그러나 9월부터 QA 작업을 진행하면서 정말 많은 에러들이 발생했다.
어느 부분에서 예외가 발생하였고, 어떤 현상이 발생했는지 아래와 같이 세부 기능별로 기록했다.
-
Spring의 Transaction 이해 (@Transactional)
이 글은 스프링 DB 1편 - 데이터 접근 핵심 원리 강의를 듣고 정리한 내용입니다.
이 글을 작성한 이유
Spring의 Transaction에 대한 심층적인 이해를 위해 “Spring의 Transaction 정리 (@Transactional)”이라는 주제로 글을 작성하려고 한다.
이전에는 데이터베이스 교재를 통해 트랜잭션과 트랜잭션 격리 수준을 공부하며 관련 개념을 정리했다.
그러나 팀 프로젝트에서는
@Transactional어노테이션을 사용하면서도 실제로 어떻게 트랜잭션을 관리해야 하는지 제대로 알지 못했다.. 이에 따라서 이번 기회에 Spring의 Transaction에 대해서, 그리고@Transactional어노테이션이 왜 도입하게 되었고, 어떻게 사용하고 있는지 알아가보자.
-
커넥션 풀과 데이터소스 이해
이 글은 스프링 DB 1편 - 데이터 접근 핵심 원리 강의를 듣고 정리한 내용입니다.
커넥션 풀 도입 배경
커넥션 풀을 배우기 전에, 먼저 기존 데이터베이스에서 커넥션을 획득하는 과정에 대해 알아보자.
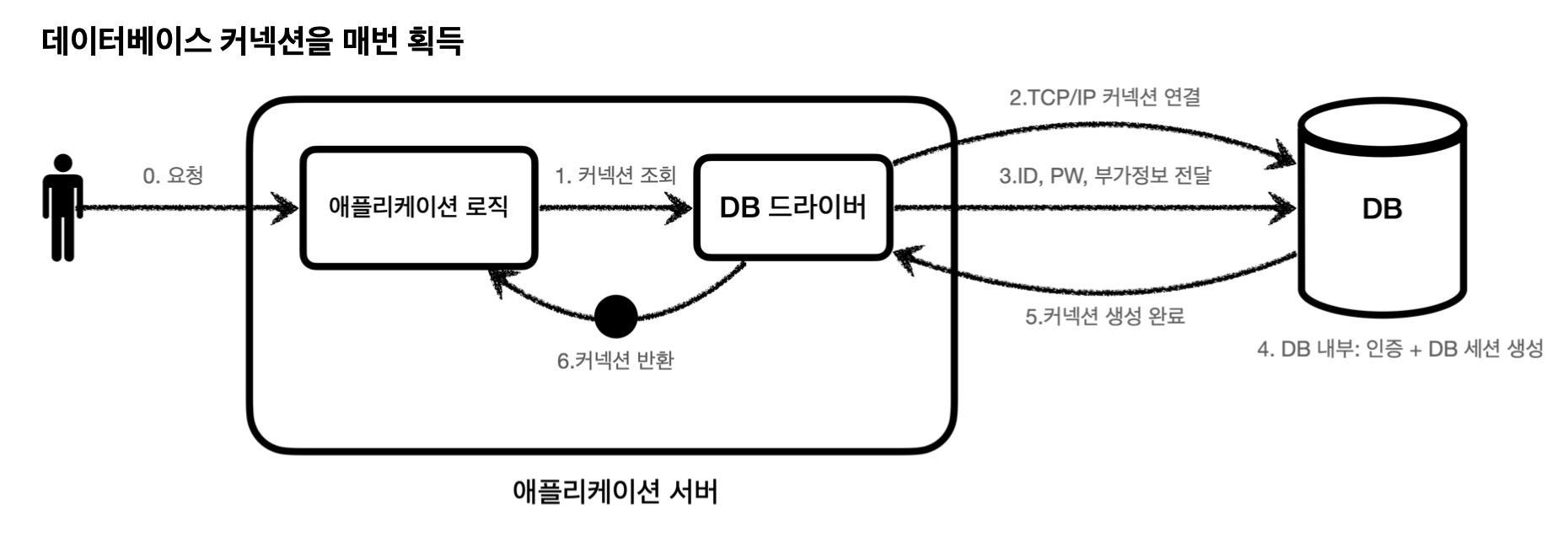
데이터베이스 커넥션을 획득할 때는 다음과 같은 복잡한 과정을 거친다.
- 애플리케이션 로직은
DB 드라이버를 통해 커넥션을 조회한다. - DB 드라이버는 DB와
TCP/IP커넥션을 연결한다. 이 과정에서 3 way handshake와 같은TCP/IP연결을 위한 네트워크 동작이 발생한다.- 3 way handshake 에 대한 자세한 내용은 이전에 작성했던 TCP와 UDP - TCP의 내부동작 원리1: 연결 설정단계를 참고하자
- DB 드라이버는
TCP/IP커넥션이 연결되면 ID, PW와 같은 부가정보를 DB에 전달한다. - DB는 ID, PW를 통해 내부 인증을 완료하고, 내부에 DB 세션을 생성한다.
- DB는 커넥션 생성이 완료되었다는 응답을 보낸다.
- DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환한다.
이렇게 커넥션을 새로 만드는 것에 대한 과정이 복잡하고 시간도 많이 소모된다.
- 애플리케이션 로직은
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8