흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[JPA] 값 타입
이 글은 [자바 ORM 표준 JPA 프로그래밍 - 기본편] 강의를 듣고 정리한 내용입니다.
기본값 타입
-
엔티티 타입
-
@Entity로 정의하는 객체이다. -
데이터가 변해도 식별자로 지속해서 추적이 가능하다.
-
ex) 회원 엔티티의 키나 나이 값을 변경해도 식별자로 인식이 가능하다.
-
-
값 타입
-
int, Integer, String 처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체이다.
-
식별자가 없고 값만 있으므로 변경시 추적 불가능하다
-
ex) 게시판의 내용(content)
-
값 타입 분류
-
기본 값
-
자바 기본 타입(int, double)
-
래퍼 클래스(Integer, Long)
-
String
-
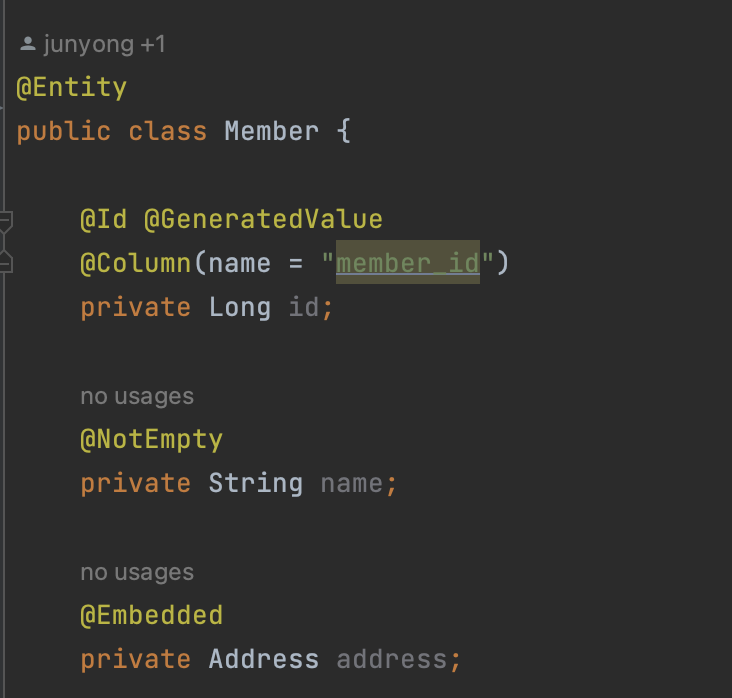
// 기본 값 타입 - 예시) - id, userName @Entity public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String userName; }-
임베디드 타입(Embedded type, 복합 값 타입) - ex) 우편번호
-
컬렉션 값 타입(Collection value type)
임베디드 타입
-
임베디드 타입는 복합 값 타입으로 새로운 값 타입을 직접 정의할 수 있다. -
주로 기본 값 타입을 모아서 만들어 복합 값 타입이라고도 한다.
-
임베디드 타입 역시 직접 정의를 할 뿐, int, String과 같은 타입으로 이루어진다.
-
예를 들어, 회원 엔티티에 이름, 근무기간, 집 주소를 가질 때 -> 아래와 같이
Address클래스 임베디드 타입으로 바꿀 수 있다. -
임베디드 타입을 사용하려면 값 타입을 정의하는 곳(Address)에 기본 생성자를 필수로 생성해야 한다.
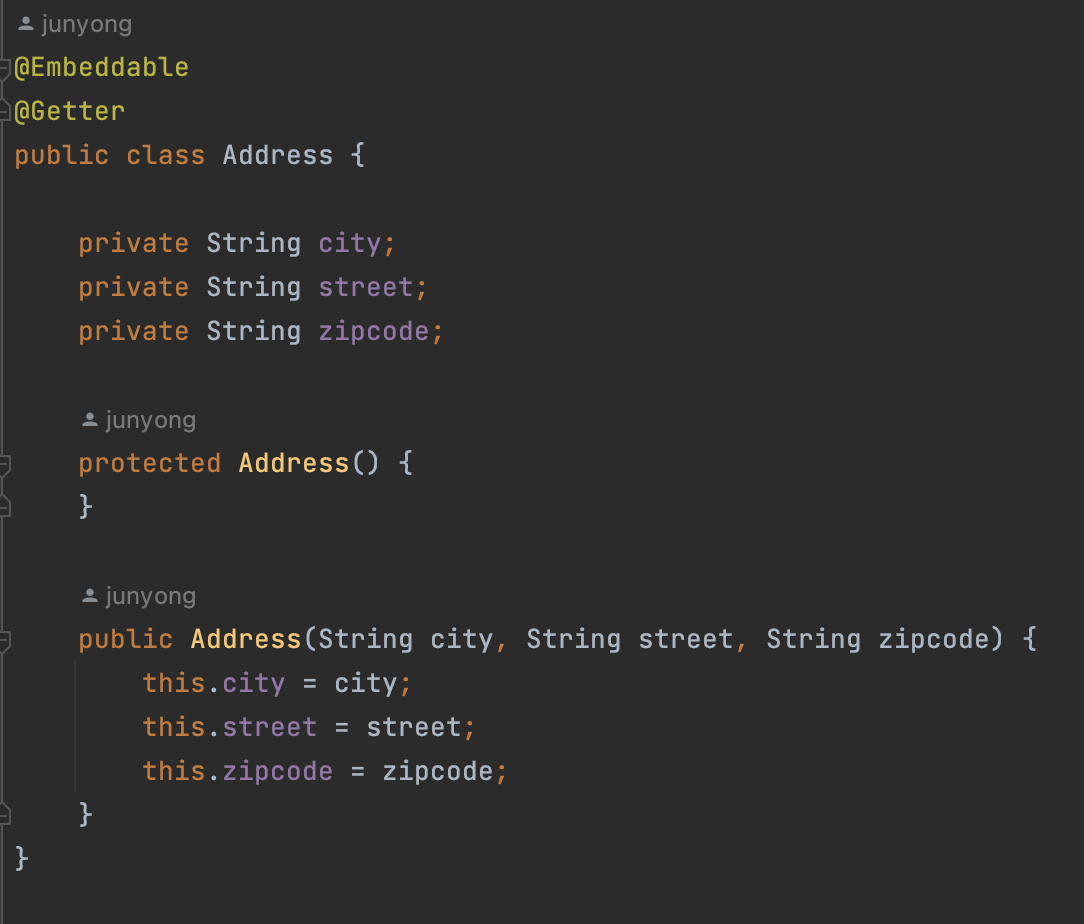
임베디드 타입 사용법
-
@Embeddable: 값 타입을 정의하는 곳에 표시한다. -> Address 클래스 -
@Eembedded: 값 타입을 사용하는 곳에 표시한다. -> Member 클래스 안에 Address 객체를 필드로 선언한 뒤, 그 위에 표시해준다.
임베디드 타입의 장점
-
재사용성과 높은 응집도
-
임베디드 타입을 포함한 모든 값 타입은, 값 타임을 소유한 엔티티에 생명주기를 의존한다.
임베디드 타입과 테이블 매핑
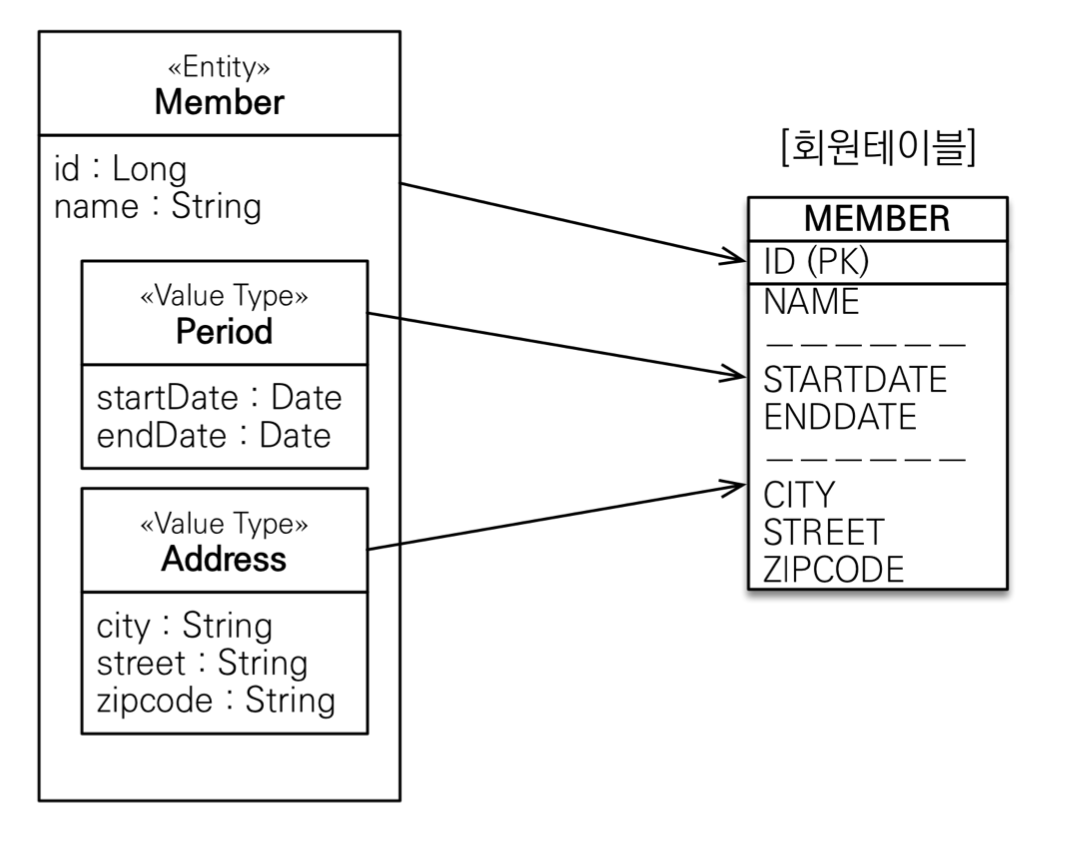
-
임베디드 타입은 엔티티의 값일 뿐이다. 그래서 임베디드 타입을 사용하기 전과 후에 매핑하는 테이블은 같다.
-
객체와 테이블을 아주 세밀하게 매핑하는 것이 가능하다.
-
잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많다.
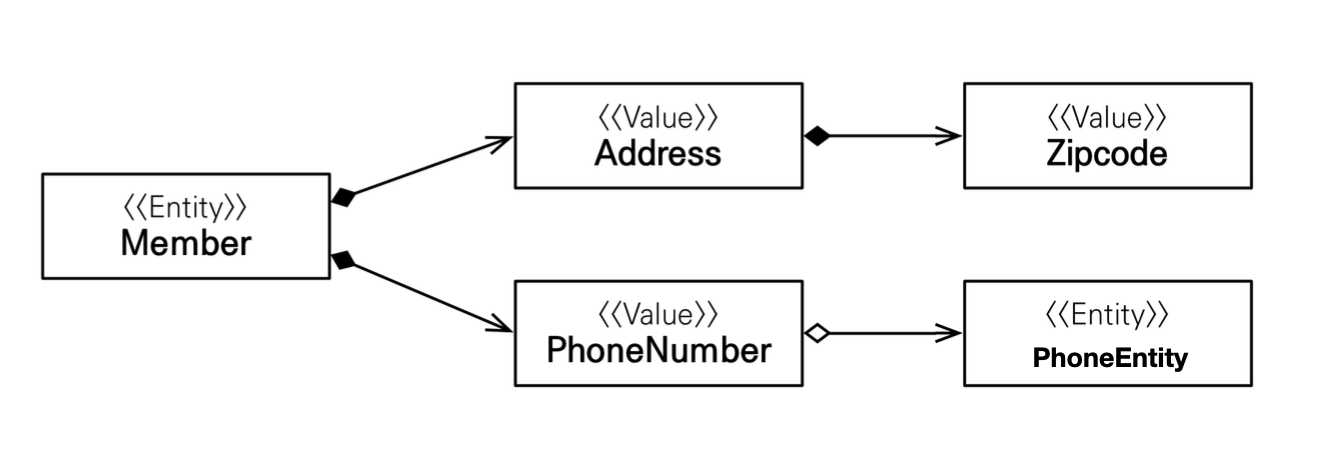
@AttributeOverride: 속성 재정의
-
한 엔티티에서 같은 값 타입을 사용하면 컬럼명이 중복될때,
@AttributeOverrides,@AttributeOverride를 사용해서 컬러명 속성을 재정의한다. -
아래 그림과 같이 주소라는 컬럼명을 재정의하기 위해
workAddress변수를 만들고, 그 위에@AttributeOverrides,@AttributeOverride을 사용했다.

값 타입과 불변 객체
-
값 타입 공유 참조 - 임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 위험함 → 부작용이 발생할 수 있다.
-
따라서 부작용을 피하기 위해서는 값 타입을 복사해준다.
-
값 타입의 실제 인스턴스인 값을 공유하는 것은 위험하다.
-
대신 값(인스턴스)를 복사해서 사용한다.
-
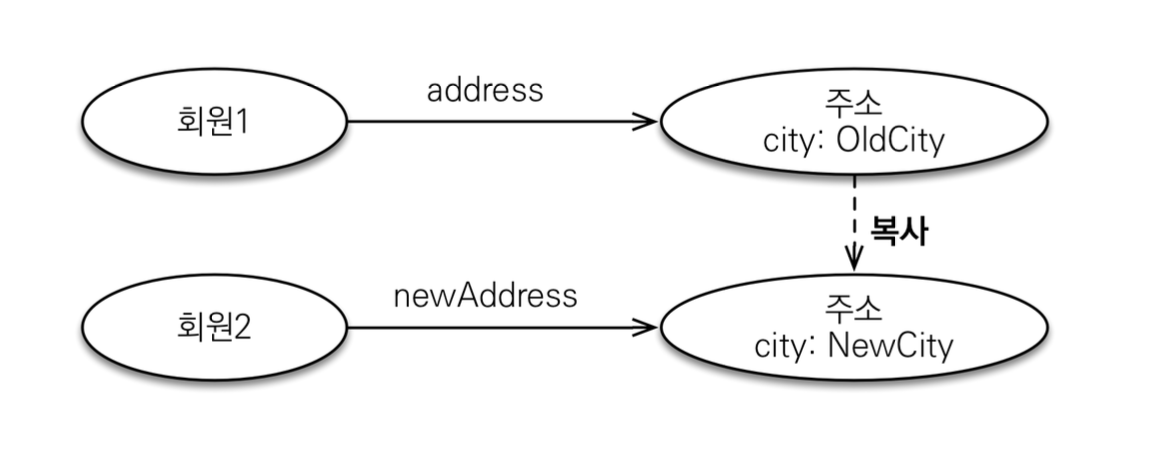
값 타입의 한계
-
항상 값을 복사해서 사용하면 공유 참조로 인해 발생하는 부작용을 피할 수 있지만, 문제는 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입이 아니라
객체 타입이다. -
객체 타입을 수정할 수 없게 만들기 위해서는 값 타입을
불변 객체로 설계해야 한다.불변 객체: 생성 시점 이후에 절대 값을 변경할 수 없는 객체를 말한다.
-
불변 객체로 설계하기 위해서는 생성자로만 값을 설정하고, 수정자(Setter)를 만들지 않으면 된다.
-
참고로, Integer, String은 자바가 제공하는 대표적인 불변 객체이다.
-
불변이라는 작은 제약으로 부작용이라는 큰 재양을 막을 수 있다.
값 타입의 비교
-
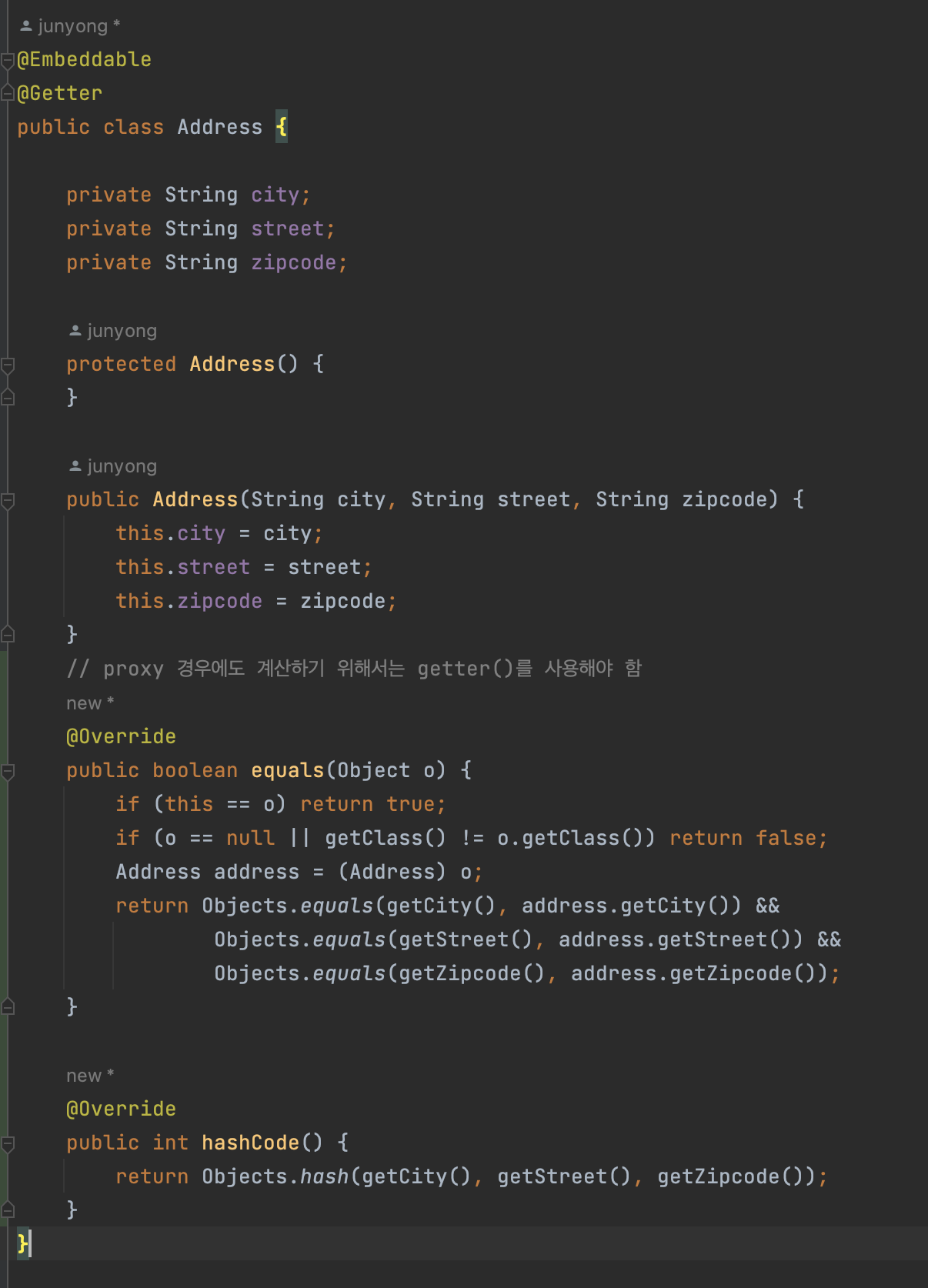
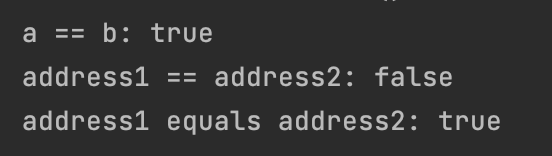
값 타입을 비교할 때 동일성 비교(==) 보다는 동등성 비교(equals)을 이용하여 비교한다.
-
동일성(identity) 비교: 인스턴스의 참조 값을 비교해서,==을 사용한다. -
동등성(equivalence) 비교: 인스턴스의 값을 비교해서,equals()을 사용한다. -
동등성 비교(equals())을 사용하기 위해서는 해당 메서드를 적절하게 재정의 해줘야 한다.
-
해당 체크를 통해 필드에 직접 접근이 아닌 getter를 통해서 동등성을 비교하도록 한다. 그래야 프록시 객체에 접근할 수 있도록 하여 비교가 가능해진다.

값 타입 컬렉션
-
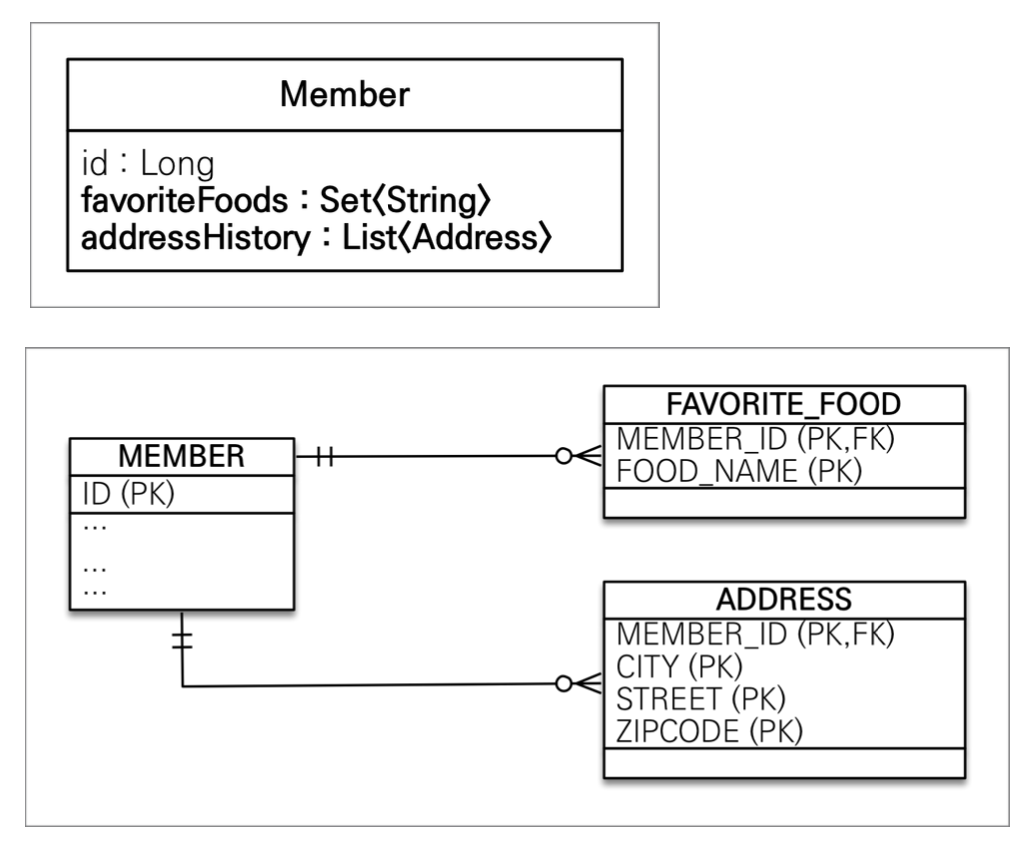
값 타입을 하나 이상 저장할 때에는
값 타입 컬렉션을 사용한다. 그래서 컬렉션의 경우 1대다 관계로 되어있다. -
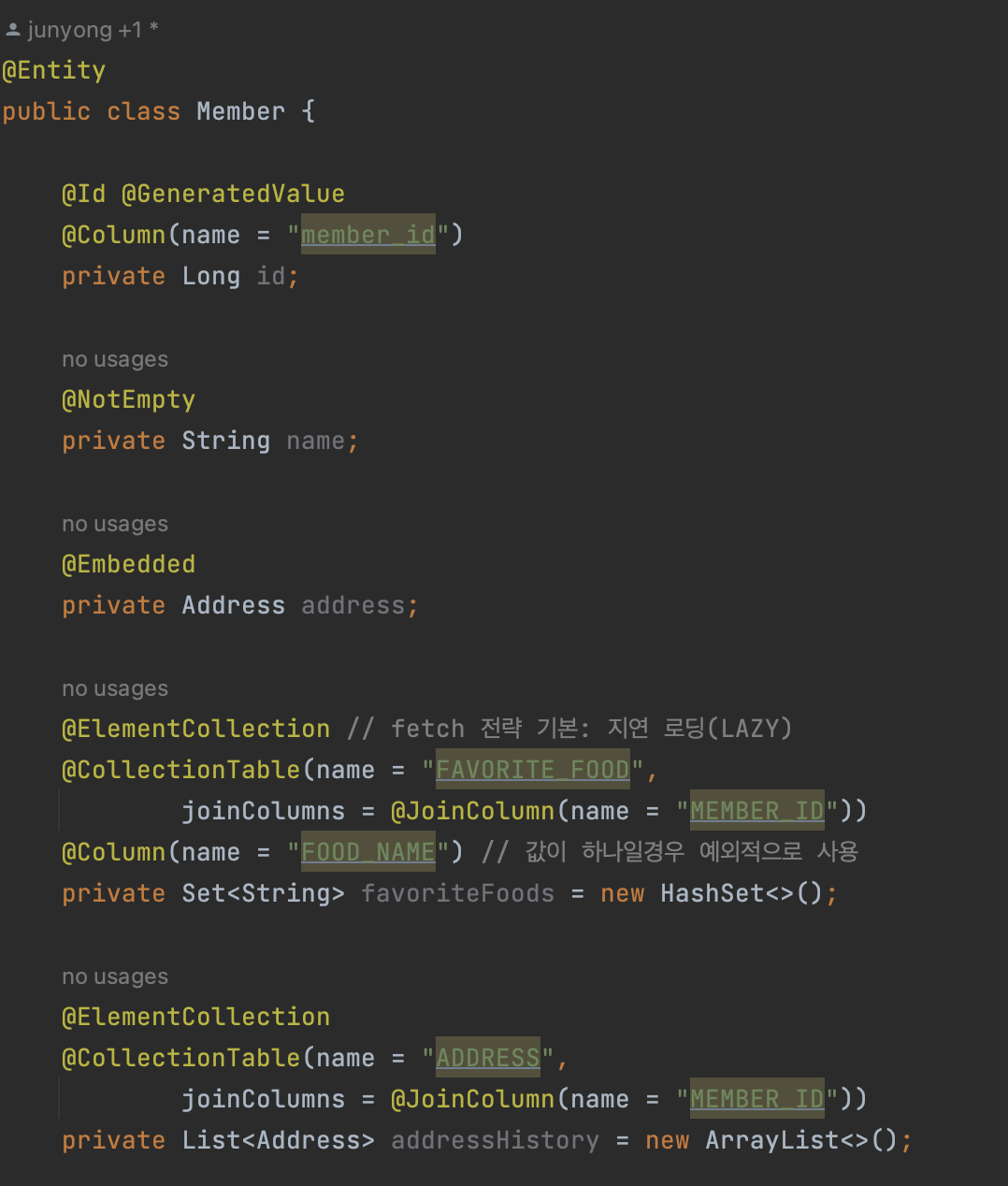
테이블로 보면 아래와 같이 favoriteFoods, addressHistory와 같이 되어있다.
-
값 타입을 하나 이상 저장할 때,
@ElementCollection,@CollectionTable을 사용한다. -
@ElementCollection어노테이션을 사용하여 값 타입 컬렉션을 지정하고(fetch 전략 기본이 지연 로딩(LAZY)임),@CollectionTable어노테이션을 통해 값 타입 컬렉션이 사용할 테이블을 지정해준다.
값 타입 컬렉션의 제약사항
-
하지만 값 타입 컬렉션은 다음과 같은 제약사항이 있다.
-
값 타입은 엔티티와 다르게 식별자 개념이 없고, 값을 변경하면 추적이 어렵다.
-
값 타입 컬렉션에 변경 사항이 발생하면 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 저장하게 된다.
-
그리고 값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본 키를 구성해야 한다. -> null 입력X, 중복 저장X
-
-
따라서 값 타입 컬렉션을 사용하는 걸 추천하지는 않는다.
값 타입 컬렉션의 대안
-
대신, 값 타입 컬렉션의 대안으로 실무에서는 상황에 따라 값 타입 컬렉션 대신에 일대다 관계를 고려한다.
-
일대다 관계를 위한 엔티티를 만들고 여기에서 값 타입을 사용한다.
-
영속성 전이(Cascade) + 고아 객체 제거(orphan remove) 를 사용해서 값 타입 컬렉션 처럼 사용하는 방법이 있다. ⇒ ex)
AddressEntity -
아래와 같이 AddressEntity 라는 엔티티 테이블을 만들고, Member 테이블과 연관관계를 맺어준다.
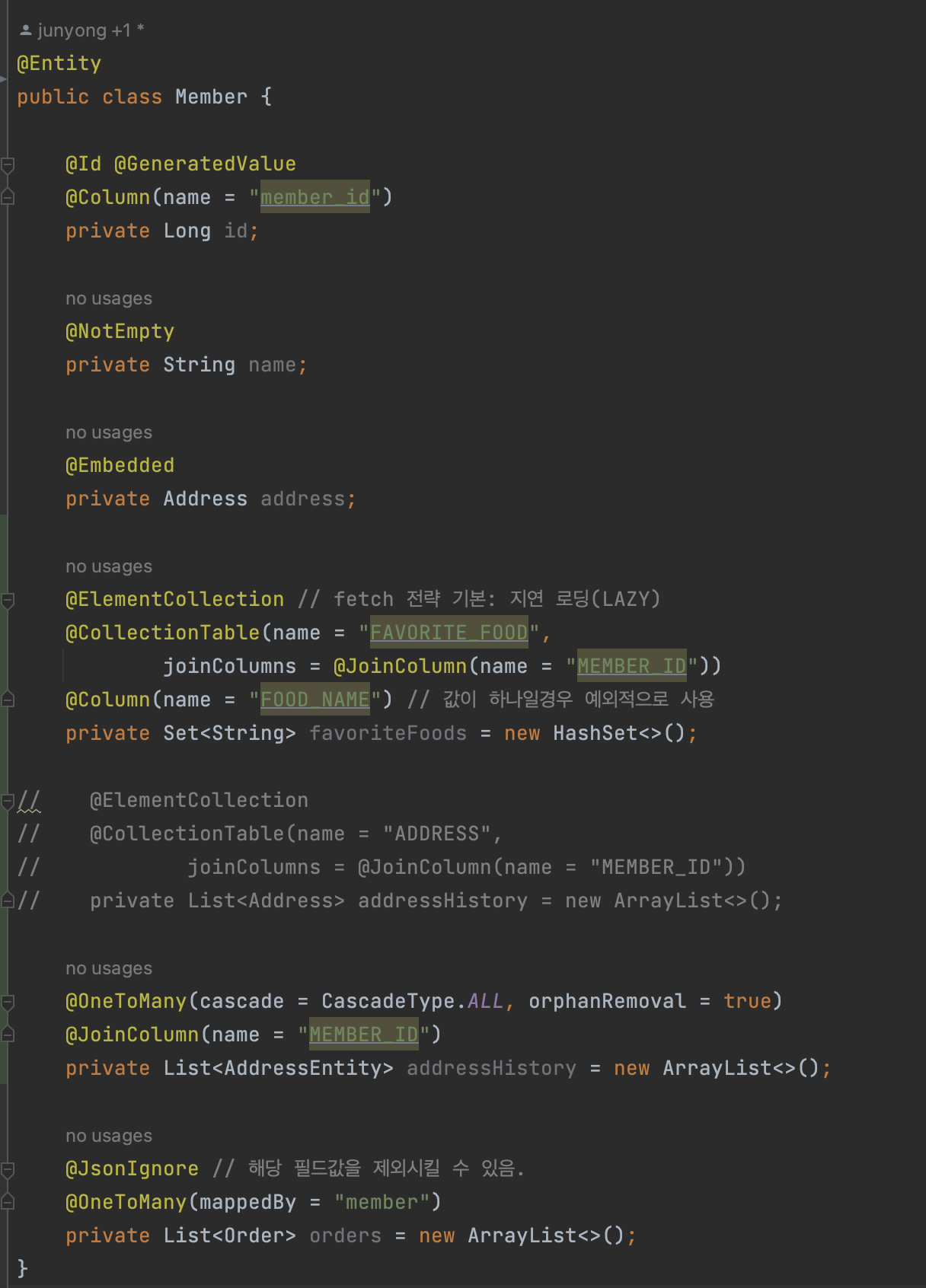
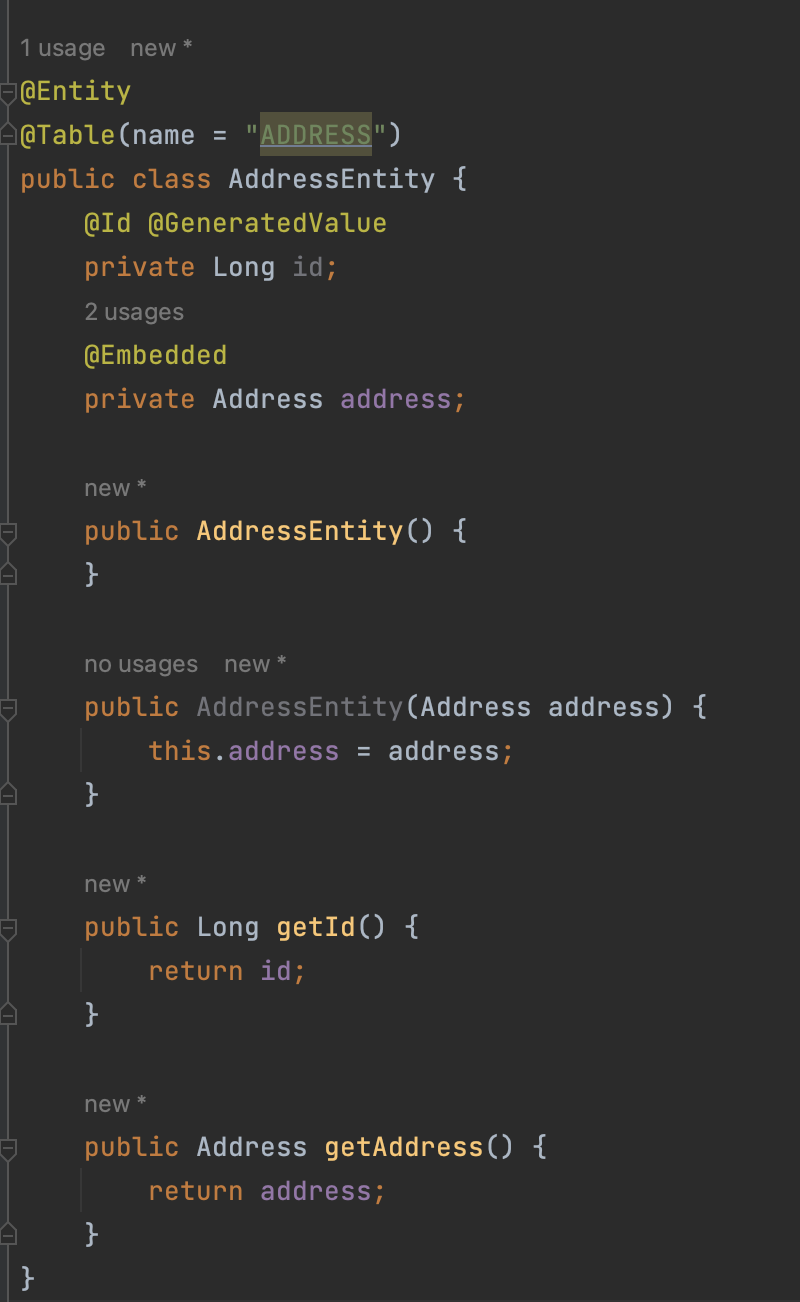
- 값 타입 컬렉션은 select box 처럼 멀티로 체크하는 등 단순한 경우에만 사용하는 것을 권장한다.
엔티티 타입과 값 타입의 특징
-
엔티티 타입의 경우 식별자가 있고, 생명 주기를 관리하며, 공유가 된다.
-
값 타입의 경우 식별자가 없고, 생명 주기를 엔티티에 의존하고 공유하지 않는 것이 안전하다. -> 복사해서 사용하거나 불변 객체로 만드는 것이 안전하다.
=> 정리하면, 식별자가 필요하고, 지속해서 값을 추적, 변경해야 한다면 그것은 값 타입이 아닌
엔티티를 사용하는 걸 권장한다.Reference
-
-
[JPA] 프록시와 연관관계 관리
이 글은 [자바 ORM 표준 JPA 프로그래밍 - 기본편] 강의를 듣고 정리한 내용입니다.
프록시
-
JPA에서
프록시는 실제 엔티티 객체를 대신하여 데이터베이스 조회를 지연할 수 있는가짜 객체를 의미한다. -
가짜 객체라 해서 실제 엔티티의 동작을 수행하지 못하는 것은 아니다.
- 실제 엔티티 클래스로부터 상속받아 생성하기 때문에, 실제 클래스와 겉 모양은 같으므로 (이론상) 사용하는 입장에서는 구분하기 않고 사용하면 된다.
em.find() vs em.getReference
-
em.find()는 데이터베이스를 통해 실제 엔티티 객체를 조회하는 메서드이다. -
em.getReference()는 데이터베이스 조회를 지연하는 가짜 객체(프록시)를 조회한다. -> DB에 쿼리가 안나가는데 조회가 된다.-
실제 엔티티 클래스로부터 상속받지만, 내부는 null 값을 가지고 있다.
-
하이버네이트가 내부의 라이브러리를 써서
프록시라는 가짜 엔티티를 주게 된다.
-
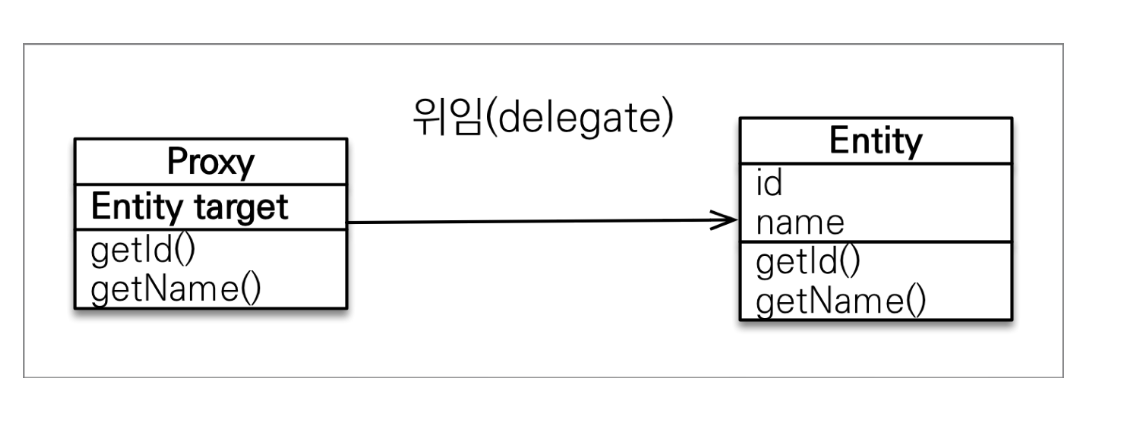
-
프록시 객체는 실제 객체의 참조(target)를 보관한다.
-
프록시 객체를 호출하면, 프록시 객체는 실제 객체의 메서드를 호출한다.
프록시 객체의 초기화
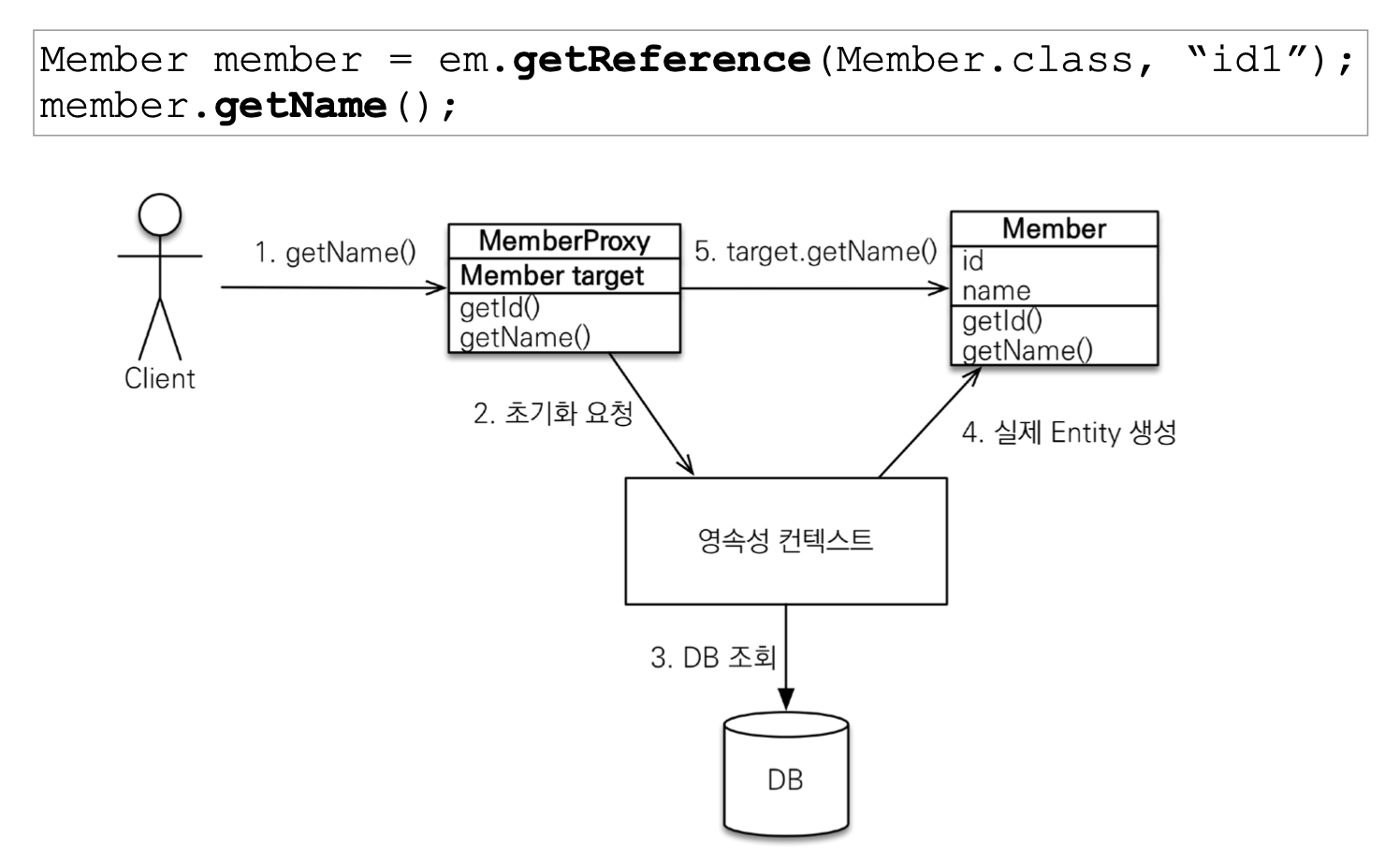
- 위의 그림을 통해 프록시 객체의 초기화하는 과정은 다음과 같다.
-
getName() 메서드를 호출하면 처음에
Member target에 값이 없다. (만약 1차 캐시가 존재한다면 프록시 객체가 아닌 실제 객체를 반환한다) -
그래서 JPA가 영속성 컨텍스트에 진짜 Member 객체를 가져오기 위해 초기화를 요청한다.
-
영속성 컨텍스트에는 DB를 조회한다.
-
그런 다음 실제 엔티티 객체를 생성해서 Member 엔티티에 넘겨준다.
-
그리고 MemberProxy에 있는
Member target을 실제 Member 엔티티(진짜 객체)와 연결시켜준다.
- 정리하면
getName()을 영속성 컨텍스트를 총해 초기화 요청 및 DB에서 조회한 다음, 가짜 객체를 실제 객체와 연결시켜서 값을 받아온다.
코드로 확인하면 아래와 같다.
public class JpaMain { public static void main(String[] args) { EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello"); EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); try { Member member = new Member(); member.setName("woochang"); em.persist(member); em.flush(); em.clear(); // 실제 엔티티를 조회하는 경우 Member findMember = em.find(Member.class, member.getId()); // 프록시를 사용하는 경우 Member findMember = em.getReference(Member.class, member.getId()); System.out.println(findMember.getClass().getName()); tx.commit(); } catch (Exception e) { tx.rollback(); } finally { em.close(); } emf.close(); } }-
EntityManager의getReference()메서드를 통해 프록시 객체를 가져온다. -
실행 결과로
package명.Member$HibernateProxy$chd0xZ3이라는 형태로 출력하게 되는데, 이를 통해 프록시 객체임을 확인할 수 있다. -
프록시 객체는 메서드 호출(getName()) 과 같이 실제 사용될 때 데이터베이스를 조회해서 실제 엔티티 객체를 생성 후 해당 객체를 참조로 가지게 된다.
-
이를
프록시 객체의 초기화라고 한다.
프록시의 특징
-
프록시 객체는 처음 사용할 때 한 번만 초기화한다.
-
프록시 객체를 초기화 할 때, 프록시 객체가 실제 엔티티로 바뀌는 것은 아니다.
- 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근이 가능한 것이다. -> 교체되는게 아니라 프록시는 유지되고 내부에 값이 채워진 것이다.
-
프록시 객체는 원본 엔티티를 상속받는다. 따라서 타입 체크시 주의해야 한다. ->
==로 비교하는 대신,instanceof로 사용해야 한다)
class ProxyEx { private static void logic(Member m1, Member m2) { System.out.println("m1 == m2: " + (m1 instanceof Member)); // true System.out.println("m1 == m2: " + (m2 instanceof Member)); // true } }-
영속성 컨텍스트에 찾는 엔티티가 이미 있으면(1차 캐시),
em.getReference()를 호출해도 실제 엔티티를 반환된다.- JPA에서는 같은 트랜잭션 안에서 영속 엔티티의 동일성을 보장한다.
-
초기화는 영속성 컨텍스트의 도움을 받아야 하기에 준영속 상태의 프록시를 초기화하면 문제가 발생한다.
프록시 확인
해당 객체가 프록시인지 확인하는 방법은 다음과 같다.
-
PersistenceUnitUtil.isLoaded(Object entity): 프록시 인스턴스의 초기화 여부 확인 -
entity.getClass().getName(): 프록시 클래스 확인하는 방법 -
org.hibernate.Hibernate.initialize(entity);: 프록시 강제 초기화 (JPA 표준은 강제하는 초기화가 없다)
즉시 로딩과 지연 로딩
즉시 로딩
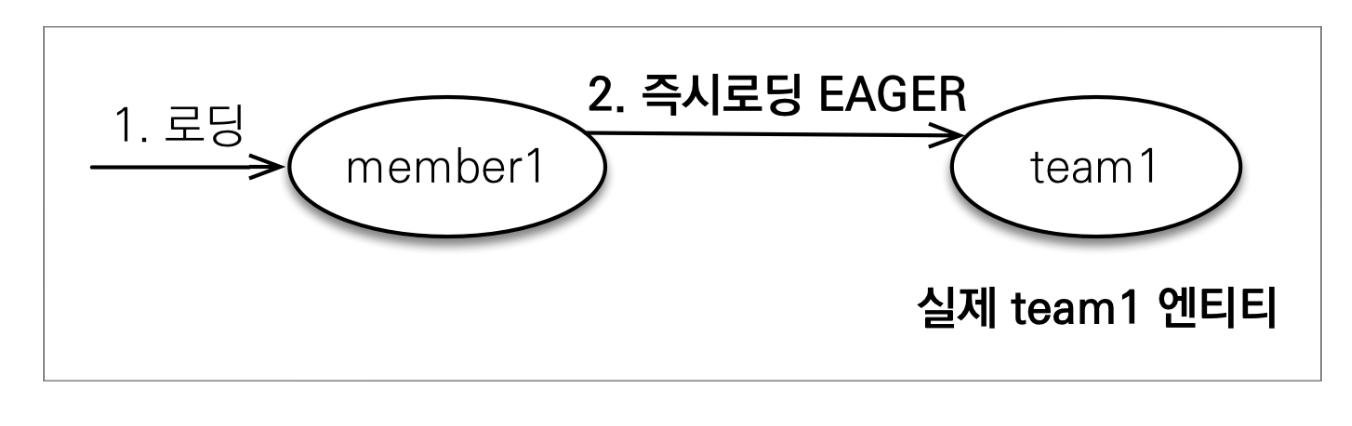
-
즉시로딩은 엔티티를 조회할 때 연관관계가 있는 실제 엔티티도 함께 조회하는 방법이다. -
즉시 로딩을 사용하기 위해서는 fetch 속성을
FetchType.EAGER으로 지정하면 된다.
@Entity public class Member { // ... @ManyToOne(fetch = FetchType.EAGER) // 즉시 로딩 @JoinColumn(name = "TEAM_ID") private Team team; // ... }-
즉시 로딩을 사용하면, JPA 구현체가 가능하면 조인을 사용해서 SQL에서 한번에 함께 조회하게 된다.
-
이때
외부 조인(left outer join)을 사용하는 것을 확인할 수 있는데, 이는Null가능성 때문이다. -
내부 조인이 외부 조인보다 좋은 이유는 성능이 좋기에 최적화에 유리하지만, 이때 외래키에
NOT NULL제약조건이 필요하다.
-
@Entity public class Member { // ... @ManyToOne(fetch = FetchType.EAGER) // 즉시 로딩 @JoinColumn(name = "TEAM_ID", nullable = false) private Team team; // ... }지연 로딩
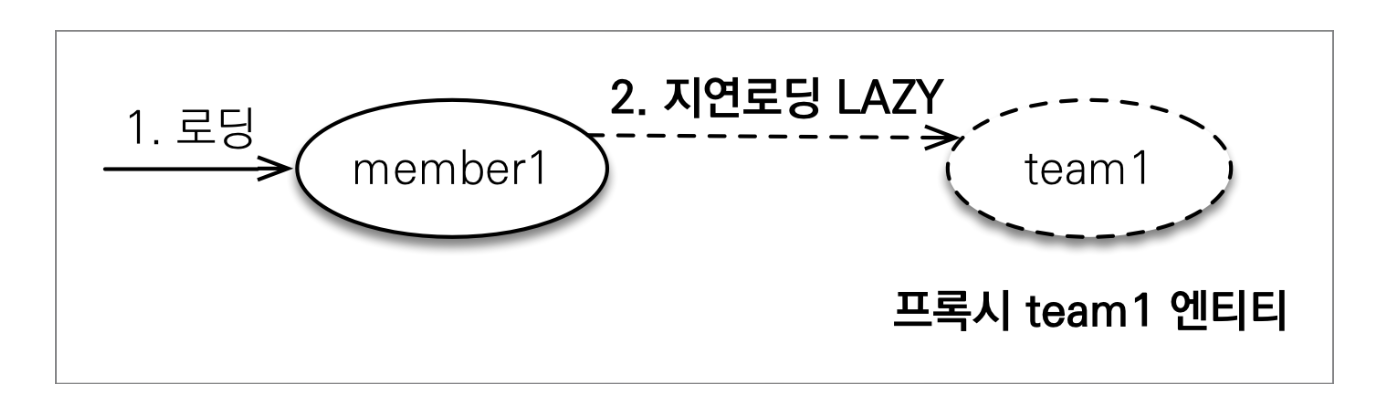
-
지연 로딩은 연관된 엔티티를 실제 사용할 때 조회하는 방법이다. -
지연 로딩을 사용하기 위해서는 fetch 속성을
FetchType.LAZY으로 지정하면 된다. -
지연 로딩을 사용하게 되는 경우 실제 엔티티 객체 대신 앞에서 설명한 프록시 객체가 들어가게 된다.
-
아래에서
team이라는 연관된 엔티티를 실제 사용할 때 (ex. team.getName()), 그 시점에 초기화, 즉 DB 조회가 이루어진다는 의미이다.
@Entity public class Member { // ... @ManyToOne(fetch = FetchType.LAZY) // 지연로딩 @JoinColumn(name = "TEAM_ID") private Team team; // ... }-
지연 로딩은 연관된 엔티티(team)를 사용할 때에만 프록시 객체를 통해 조회하는 반면,즉시 로딩은 연관된 엔티티를 사용하지 않더라도 실제 객체를 통해 함께 조회가 된다. -
Member에만 조회하는 경우가 많으면
지연 로딩을 사용하고, Member와 Team을 같이 사용하면즉시 로딩을 사용하는 걸 권장한다.
프록시와 즉시로딩 주의
-
실무에서는 가급적
지연 로딩만 사용한다.-
즉시 로딩을 적용하면 예상하지 못한 SQL이 발생한다.
-
즉시 로딩은 JPQL에서 N+1 문제를 일으킨다. ->
select로Member만 가져오는 SQL을 작성했지만, 해당 SQL의 개수만큼 필요하지도 않은Team select SQL가 발생하게 될 수도 있다.
-
-
로딩 전략 - 테이블이 복잡하게 얽혀있는 경우에는 지연 로딩을 사용하는 것을 권장한다.
-
@ManyToOne, @OneToOne은 기본이
즉시 로딩-> 실무에서지연 로딩으로 바꾸고 진행한다. -
@OneToMany, @ManyToMany는 기본이
지연 로딩
-
예시 - 지연 로딩 활용
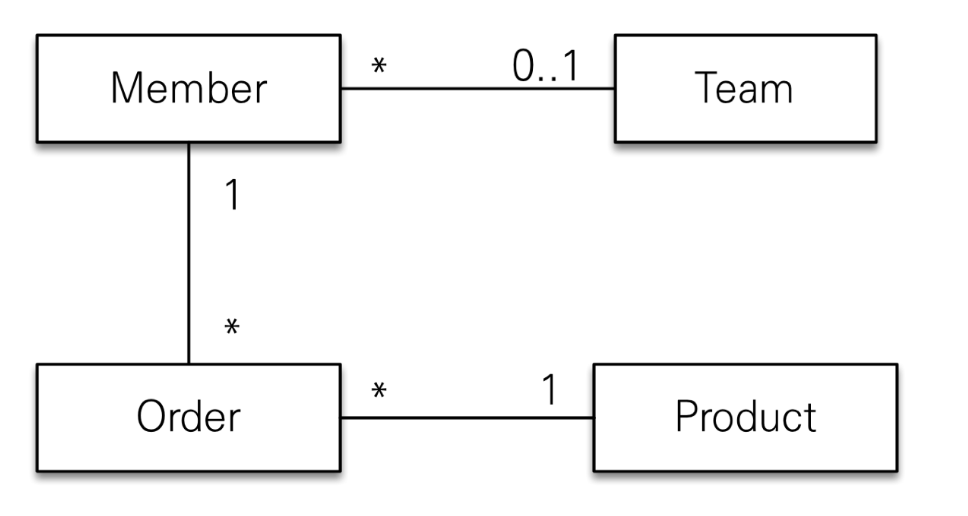
-
Member와Team(다대일)은 자주 함께 사용 -> 즉시 로딩 -
Member와Order(일대다)는 가끔 사용 -> 지연 로딩 -
Order와Product(다대일)는 자주 함께 사용 -> 즉시 로딩
영속성 전이: CASCADE
참고로
영속성 전이는 위에서 다룬 프록시 객체와 로딩 전략과 연관이 없는 개념이다)-
영속성 전이란 특정 엔티티를 영속 상태로 만들 때, 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때 사용한다. -
예를 들어 아래 그림처럼 부모 엔티티를 저장할 때 자식 엔티티도 함께 저장하는 경우에 사용한다.
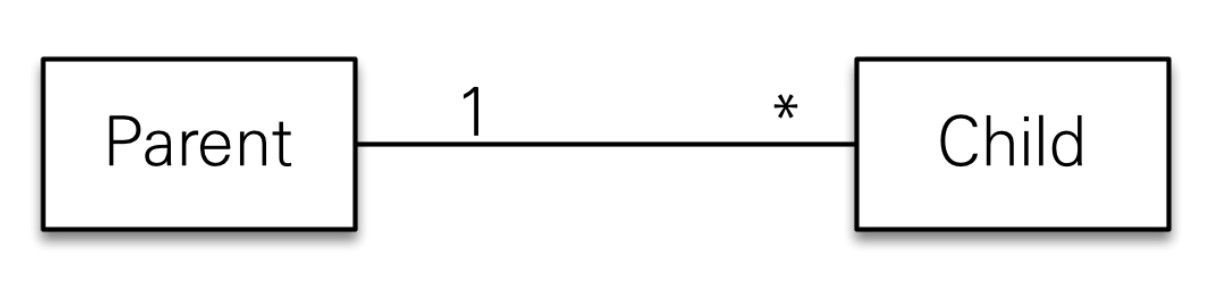
코드로 적용하면 아래와 같다.
```java @Getter @Entity public class Parent {
@Id @GeneratedValue @Column(name = "PARENT_ID") private Long id; private String name;
-
-
[Programmers] 43162. 네트워크(DFS)
성능 요약
- 메모리: 71.4 MB, 시간: 0.10 ms
구분
- 코딩테스트 연습 > 깊이/너비 우선 탐색 > 네트워크
Answer Code1(23.11.08)
class Solution { public int solution(int n, int[][] computers) { int answer = 0; boolean[] visited = new boolean[computers.length]; // 노드 방문 초기화 for (boolean visit : visited) { visit = false; } for(int i = 0; i < computers.length; i++) { if(visited[i] == false) { // 해당 노드를 방문하지 않았을 경우 answer++; // 새로운 네트워크 찾았으므로 +1 증가 dfs(i, visited, computers); } } return answer; } // node: 현재 노드, visited: 방문여부, computers: 컴퓨터간의 연결 정보를 나타내는 2차원 배열 public void dfs(int node, boolean[] visited, int[][] computers) { visited[node] = true; for(int i = 0; i < computers.length; i++) { // 아직 방문하지 않는 노드 && 현재 노드와 연결된 경우 if(visited[i] == false & computers[node][i] == 1) { dfs(i, visited, computers); } } } }문제풀이(Answer Code1)
DFS에 대한 알고리즘 개념을 안 상태로 해당 문제에 접근하면,
(1) 처음에 노드 방문을 boolean 배열을 만들어서 컴퓨터의 개수(n)만큼 for문을 돌려서 초기화해주고,
(2) visited[i] 값이 false이면
깊이 우선 탐색(dfs)메서드를 호출하고 answer++ 해준다.(3) 전달받은 파라미터인 visited[i] 값을 true로 바꿔준다.
(4) computers[] 길이만큼 반복문들 돌면서
(5) 아래 조건을 모두 만족하면 재귀 호출을 한다.
-
자기 자신이 아니며 (i != j)
-
visited 배열 i의 위치 값이 false이며
-
computers 배열의 값이 1인 것
(6) 2번으로 돌아간다.
(7) answer을 리턴한다.
Answer Code2(23.12.14)
// 프로그래머스 - 네트워크 class Solution { static boolean[] visited; public int solution(int n, int[][] computers) { int answer = 0; visited = new boolean[computers.length]; // 노드 방문 초기화 for(boolean visit : visited) { visit = false; } for(int i = 0; i < computers.length; i++) { if(visited[i] == false) { answer ++; dfs(i, computers); } } return answer; } /* * node: 현재 노드 * visited: 방문여부 * computer: 컴퓨터간의 연결 정보를 나타내는 2차원 배열 */ public void dfs(int node, int[][] computers) { visited[node] = true; for(int i = 0; i < computers.length; i++) { if(visited[i] == false && computers[node][i] == 1) { dfs(i, computers); } } } }Review(23.12.14)
-
첫번째 풀이와 다른 점은 visited 배열을 static으로 선언해서 dfs를 호출할 때, visited 매개변수를 없애주었다.
-
해당 문제는
연결된 요소 찾기유형과 흡사해서, 이전에 풀었던 문제와 비슷했지만, 아직은 익숙치 않아서 더 자주 풀어봐야겠다.
Reference
- https://beaniejoy.tistory.com/41
-
Practical Testing: 테스트 코드 작성 방법 - Mock, 더 나은 테스트를 위한 구체적 조언
이 글은 Practical Testing: 실용적인 테스트 가이드 강의를 듣고 내용을 정리한 글입니다.
지난 글에 이어서 정리해보려고 합니다.
Mock을 마주하는 자세
Mockito로 Stubbing 하기
새로운 요구사항
-
관리자 페이지에서 주문관리탭 - 오늘 하루동안 발생한 매출 통계를 메일로 전송받는 기능을 구현한다. → 날짜와 결제금액
-
주문 데이터를 기반으로 총 결제가 이뤄진 금액을 알고 싶다.
-
주문통계에 대한 서비스 -
OrderStatisticsService
(실무에서는 주문완료 시간과 별도로 결제완료 시간에 대한 필드가 있어야 하는데, 이 토이 프로젝트에서는 모의로 구현하는 것이기때문에 일단 주문완료 시간을 가지고 구현한다)
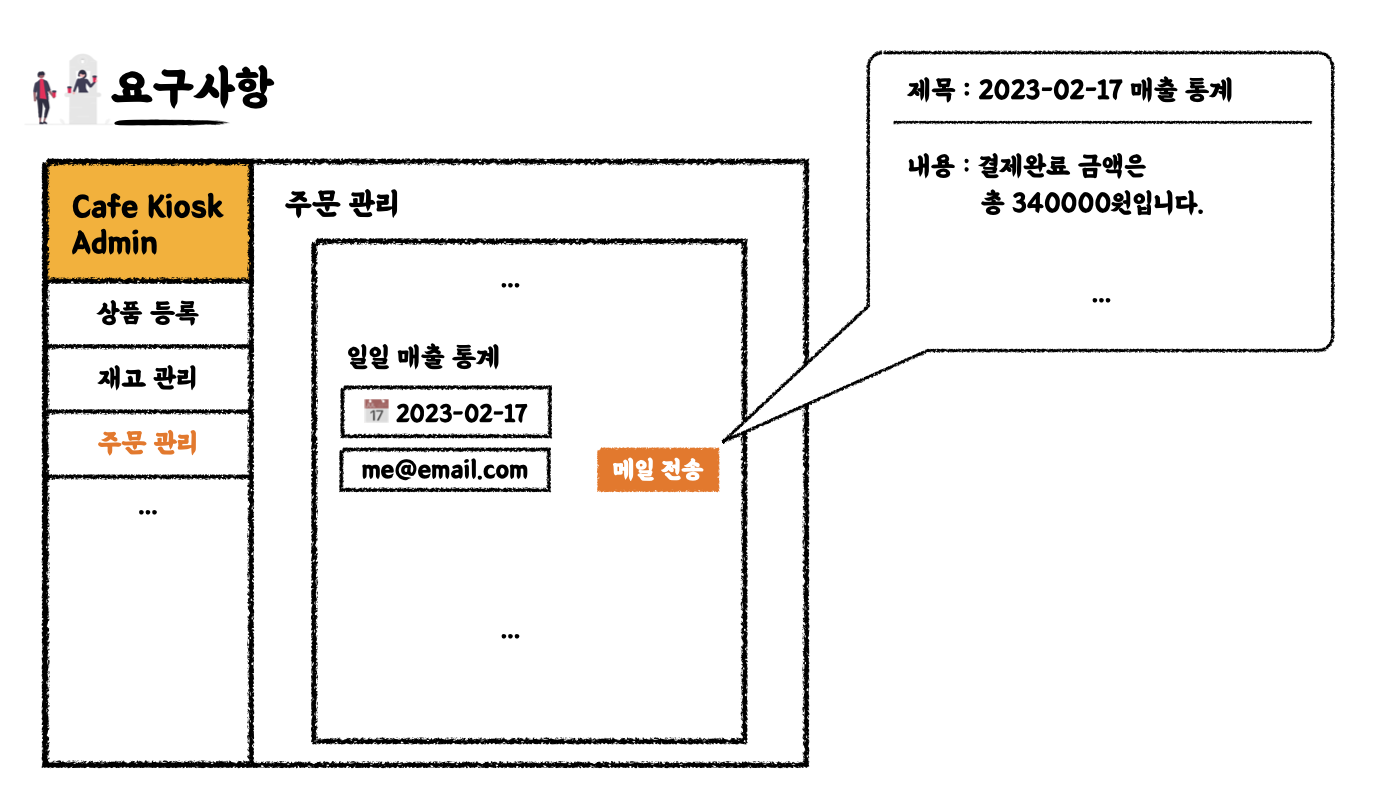
해당 요구사항에 대한 구현 코드 - Mockito로 Stubbing하기입니다.
해당 코드에서
OrderStatisticsServiceTest.java을 참고해주시면 되겠습니다.Stubbing이란 테스트를 진행할 때 가짜 객체(Mock)에 대해 어떤 행동을 하도록 지정하는 작업을 말한다.여기서
Stubbing을 하기 위해 MailSendClient 클래스를@MockBean을 통해 Mockito에서 만든 Mock 객체를 주입한 다음, 원하는 행위를 정의해준다.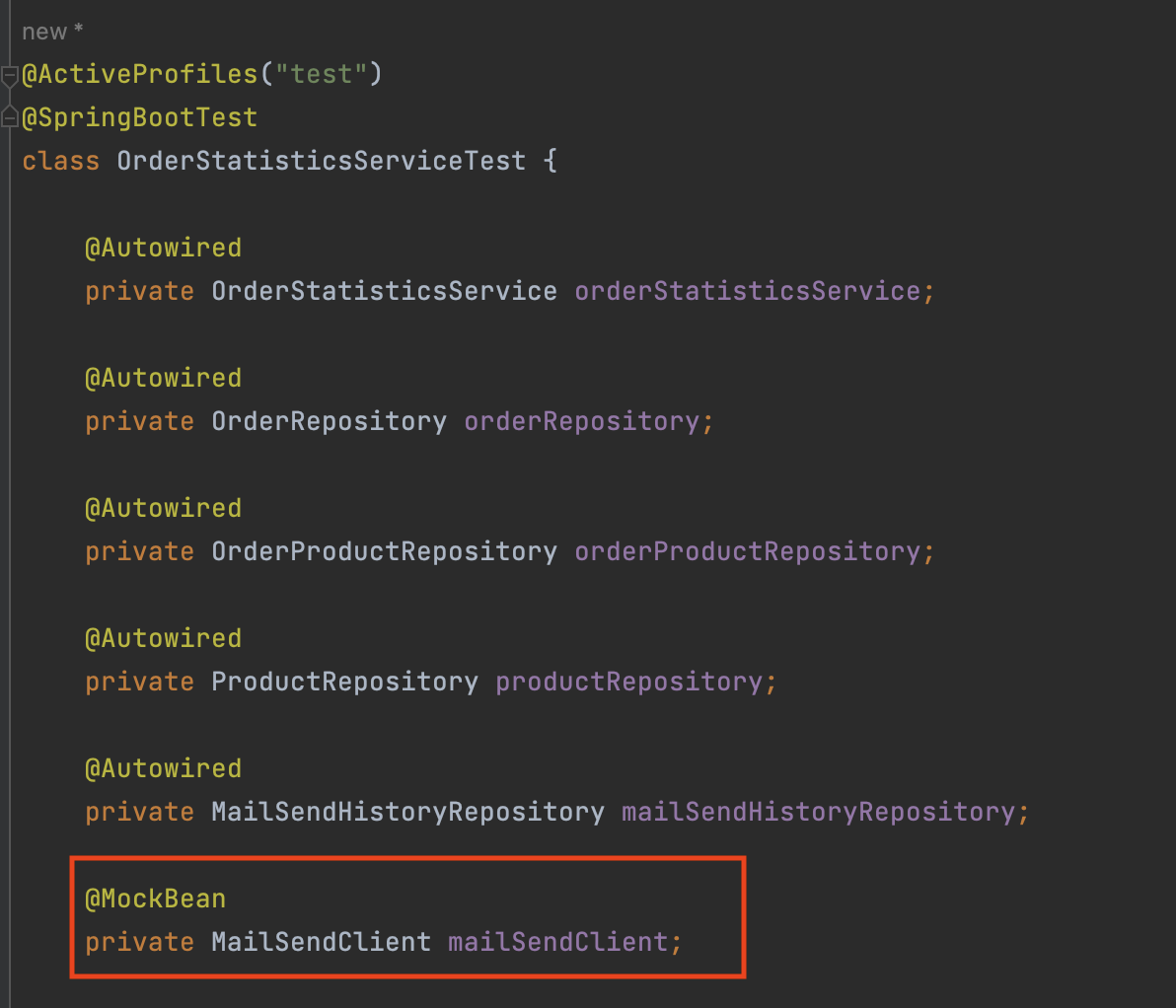
MockBean은 기존에 사용되던 Bean의 껍데기만 가져오고 내부의 구현 부분은 모두 사용자에게 위임한 형태이다. 실제 빈의 동작과는 별개로 사용자(개발자)가 원하는 행동을 정의할 수 있다.(
@MockBean은@SpringBootTest에서 사용되며, 테스트에서 사용할 Mock 객체를 주입하는 데에 쓰인다)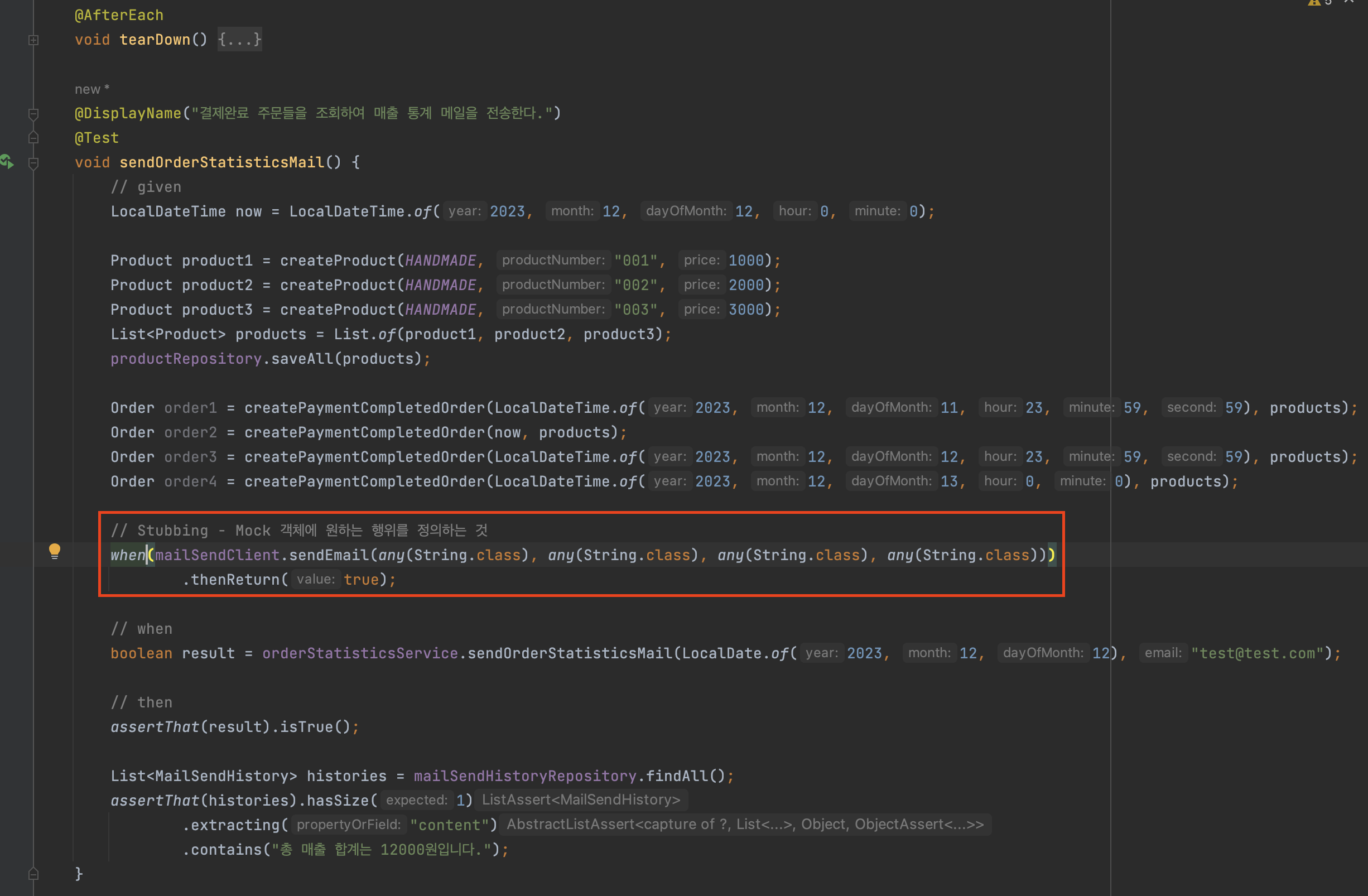
이렇게
@MockBean을 이용하여 Stubbing 하는 행위는given절에서 작성한다.-
when(mailSendClient.sendEmail(any(String.class), any(String.class), any(String.class), any(String.class))).thenReturn(true);를 예로 들면, -
when메서드는 특정 메서드 호출이 발생할 때 어떤 값으로 리턴해야 하는지 정의하는데, 여기서는mailSendClient.sendEmail메서드가 아무 문자열(any(String.class)) 인자로 호출될 때, -
모의 객체(Mock)인
mailSendClient는 항상 true를 반환한다는 의미이다. -
이처럼 테스트 환경에서는 실제로 이메일을 보내지 않고도, 메일 전송 메서드의 성공적인 호출을 시뮬레이션하기 위해
Mockito로 Stubbing 하는 방식을 사용한다.
[참고] 메일 전송과 같은 로직에서는
Transactional어노테테이션을 붙일 필요가 없다.-
OrderStatisticsService에는 DB 조회를 하는findOrdersBy와 같은 로직이 존재하는데 왜 트랜잭션이 필요가 없을까? -
DB 조회를 할 때 커넥션을 가지고 메일이 전송 완료될 때까지 커넥션을 유지하고 있을 것이다. 메일 전송 등과 같은 오랜 시간이 걸리는 작업에서는 트랜잭션을 걸지 않는 것이 좋다.
Test Double
Test Double에 대한 정의와 종류에 대해 자세히 알고 싶다면, 이 글을 참고하자.
-
Dummy: 아무것도 하지 않는 깡통 객체 -
Fake: 단순한 형태로 동일한 기능은 수행하나, 프로덕션에서 쓰기에는 부족한 객체(FakeRepository) -
Stub: 테스트에서 요청한 것에 대해 미리 준비한 결과를 제공하는 객체. 그 외에는 응답하지 않는다. -
Spy: Stub이면서 호출된 내용을 기록하여 보여줄 수 있는 객체. 일부는 실제 객체처럼 동작시키고 일부만 Stubbing만 할 수 있다. → 실제 객체와 유사하게 동작 -
Mock:행위에 대한 기대를 명세하고, 그에 따라 동작하도록 만들어진 객체
Stub vs Mock
-
공통점: 둘다 가짜 객체, 요청한 것에 대해 미리 준비한 결과를 제공한다.
-
차이점: 검증하는 목적이 다르다. (There is a difference in that the stub uses state verification while the mock uses behavior verification. - Martin Fowler -)
-
Stub: 상태 검증(State Verification) -
Mock: 행위 검증(Behavior Verification)
-
@Mock, @Spy, @InjectMocks
모든 객체에 대해 Stubbing을 해주지 않았는데도 테스트가 통과되는 이유
아래 코드는
MailService의 sendMail 메서드에 대한 테스트 코드이다.// MailService 클래스 // 클라이언트(MailSendClient)를 통해 메일을 보낸 후, 이를 성공적으로 전송했을 때 해당 이력을 mailSendHistoryRepository 을 통해 기록하는 역할을 수행 @RequiredArgsConstructor @Service public class MailService { private final MailSendClient mailSendClient; private final MailSendHistoryRepository mailSendHistoryRepository; public boolean sendMail(String fromEmail, String toEmail, String subject, String content) { boolean result = mailSendClient.sendEmail(fromEmail, toEmail, subject, content); if(result) { mailSendHistoryRepository.save(MailSendHistory.builder() .fromEmail(fromEmail) .toEmail(toEmail) .subject(subject) .content(content) .build() ); return true; } return false; } } // MailServiceTest class MailServiceTest { @DisplayName("메일 전송 테스트") @Test void sendMail() { // given MailSendClient mailSendClient = Mockito.mock(MailSendClient.class); MailSendHistoryRepository mailSendHistoryRepository = Mockito.mock(MailSendHistoryRepository.class); MailService mailService = new MailService(mailSendClient, mailSendHistoryRepository); // Stubbing - Mock 객체에 원하는 행위를 정의하는 것 when(mailSendClient.sendEmail(anyString(), anyString(), anyString(), anyString())) .thenReturn(true); // when boolean result = mailService.sendMail("", "", "", ""); // then Assertions.assertThat(result).isTrue(); } }자세히 보면,
MailService의 sendMail 메서드에서mailSendHistoryRepository.save()에 대한 Stubbing 없이 sendMail 메서드를 테스트하면 정상적으로 통과가 되는데 왜 그런걸까?Mockito의 mock 메서드에 가보면 아래와 같이 withSettings() 메서드를 볼 수 있다.
여기서 withSettings() 메서드에서 리턴하는 부분에서
RETURNS_DEFAULTS에 가보면
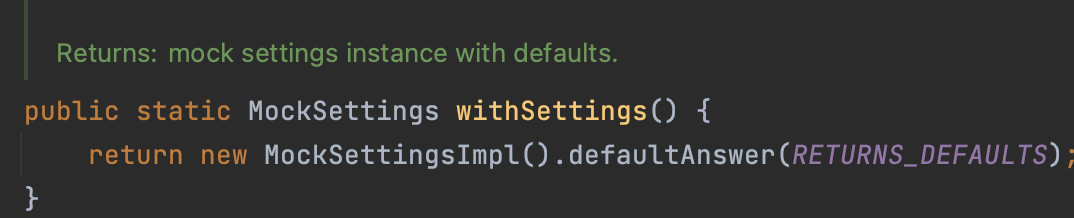

Integer인 경우 zero을 리턴하고, null이 반환되는 값들은 null을 반환하고, Collection의 경우 empty 를 반환하도록 기본 정책이 걸려있는 걸 확인할 수 있다.
그래서 save 메서드를 호출했을 때 기본으로 null을 반환하도록 하여 테스트가 통과된 것을 알 수 있다.
이를 조금 더 명시적으로 검증하기 위해 아래와 같이
verify메서드를 통해 작성해볼 수 있다.// mailSendHistoryRepository.save()가 1 번 호출되었는지를 검증 Mockito.verify(mailSendHistoryRepository, times(1)).save(any(MailSendHistory.class));위의
MailServiceTest을 다음과 같이 리팩터링 작업을 진행한다.-
MailSendClient,MailSendHistoryRepository클래스를Mock어노테이션을 이용하여 생성자를 주입한다. -
그리고 MailServiceTest 위에
@ExtendWith(MockitoExtension.class)걸어준다 -> “테스트가 시작될때, Mockito를 통해 mock 만들거야”를 알려줘야 한다. → 그리고 mock 객체를 만들어주고mailService에 넣어주게 된다.
@ExtendWith(MockitoExtension.class) class MailServiceTest { @Mock private MailSendClient mailSendClient; @Mock private MailSendHistoryRepository mailSendHistoryRepository; @DisplayName("메일 전송 테스트") @Test void sendMail() { // given MailService mailService = new MailService(mailSendClient, mailSendHistoryRepository); // Stubbing - Mock 객체에 원하는 행위를 정의하는 것 when(mailSendClient.sendEmail(anyString(), anyString(), anyString(), anyString())) .thenReturn(true); // when boolean result = mailService.sendMail("", "", "", ""); // then Assertions.assertThat(result).isTrue(); // mailSendHistoryRepository.save()가 1 번 호출되었는지를 검증 Mockito.verify(mailSendHistoryRepository, times(1)).save(any(MailSendHistory.class)); } }여기서
MailService도@InjectMocks어노테이션으로 만들어줄 수 있다.-
MailService에 생성자를 보고 Mockito의 mock으로 선언된MailSendClient,MailSendHistoryRepository애들을 inject 해준다. -
즉,
@InjectMocks어노테이션은 DI와 똑같은 일을 하게 된다.-
MailService클래스 내에서 사용하는 Mock 객체들을 자동으로 주입해주는 역할이다. =>MailService mailService = new MailService(mailSendClient, mailSendHistoryRepository); -
이는 Mockito가 관리하는 Mock 객체들을 테스트 대상 클래스에 주입하여 테스트를 수행할 수 있도록 도와주는 기능이다.
-
InjectMocks 어노테이션 사용하면 아래와 같이 된다.
@ExtendWith(MockitoExtension.class) class MailServiceTest { @Mock private MailSendClient mailSendClient; @Mock private MailSendHistoryRepository mailSendHistoryRepository; @InjectMocks private MailService mailService; @DisplayName("메일 전송 테스트") @Test void sendMail() { // given // Stubbing - Mock 객체에 원하는 행위를 정의하는 것 when(mailSendClient.sendEmail(anyString(), anyString(), anyString(), anyString())) .thenReturn(true); // when boolean result = mailService.sendMail("", "", "", ""); // then Assertions.assertThat(result).isTrue(); // mailSendHistoryRepository.save()가 1 번 호출되었는지를 검증 Mockito.verify(mailSendHistoryRepository, times(1)).save(any(MailSendHistory.class)); } }@Spy는 기록을 하는 객체
@Spy어노테이션은 객체의 일부 메소드만을 Mock으로 대체할 수 있기 때문에, 나머지 메소드는 실제 객체의 동작을 그대로 따르게 된다.이는 특히 특정 메소드의 동작을 유지하면서 일부 동작을 변경하거나 감시할 때 유용하다. -> 일부만 Stubbing만 하여 테스트를 할 수 있다.
예를 들어,
MailSendClient클래스에 여러 메서드 기능들이 있고,MailService에서 a,b,c 기능을 그대로 사용하고 있다고 가정해보자.// MailSendClient - sendMail, a, b, c 메서드가 구현되어 있음. @Slf4j @Component public class MailSendClient { public boolean sendEmail(String fromEmail, String toEmail, String subject, String content) { log.info("메일 전송"); throw new IllegalArgumentException("메일 전송"); } public void a() { log.info("a"); } public void b() { log.info("b"); } public void c() { log.info("c"); } } // MailService - a, b, c 기능을 그대로 사용하고 있음. @RequiredArgsConstructor @Service public class MailService { private final MailSendClient mailSendClient; private final MailSendHistoryRepository mailSendHistoryRepository; public boolean sendMail(String fromEmail, String toEmail, String subject, String content) { boolean result = mailSendClient.sendEmail(fromEmail, toEmail, subject, content); if(result) { mailSendHistoryRepository.save(MailSendHistory.builder() .fromEmail(fromEmail) .toEmail(toEmail) .subject(subject) .content(content) .build() ); mailSendClient.a(); mailSendClient.b(); mailSendClient.c(); return true; } return false; } } //여기서
MailServiceTest에서MailSendClient의 sendEmail()만 Stubbing 하고 싶고, 나머지 a,b,c는 원본 객체의 기능이 동일하게 동작하고 싶은 경우@Spy어노테이션을 활용한다.-
@Spy는 실제 객체를 기반으로 만들어지기 때문에,MailServiceTest에서 아래와 같은 when 부분을 지워야(주석 처리해야) 한다. → Stubbing이 되지 않는다. -
대신 doReturn으로 아래와 같이 작성해준다.
@ExtendWith(MockitoExtension.class) class MailServiceTest { @Spy private MailSendClient mailSendClient; @Mock private MailSendHistoryRepository mailSendHistoryRepository; @InjectMocks private MailService mailService; @DisplayName("메일 전송 테스트") @Test void sendMail() { // given // // Stubbing - Mock 객체에 원하는 행위를 정의하는 것 // when(mailSendClient.sendEmail(anyString(), anyString(), anyString(), anyString())) // .thenReturn(true); doReturn(true) .when(mailSendClient) .sendEmail(anyString(), anyString(), anyString(), anyString()); // when boolean result = mailService.sendMail("", "", "", ""); // then Assertions.assertThat(result).isTrue(); // mailSendHistoryRepository.save()가 1 번 호출되었는지를 검증 Mockito.verify(mailSendHistoryRepository, times(1)).save(any(MailSendHistory.class)); } }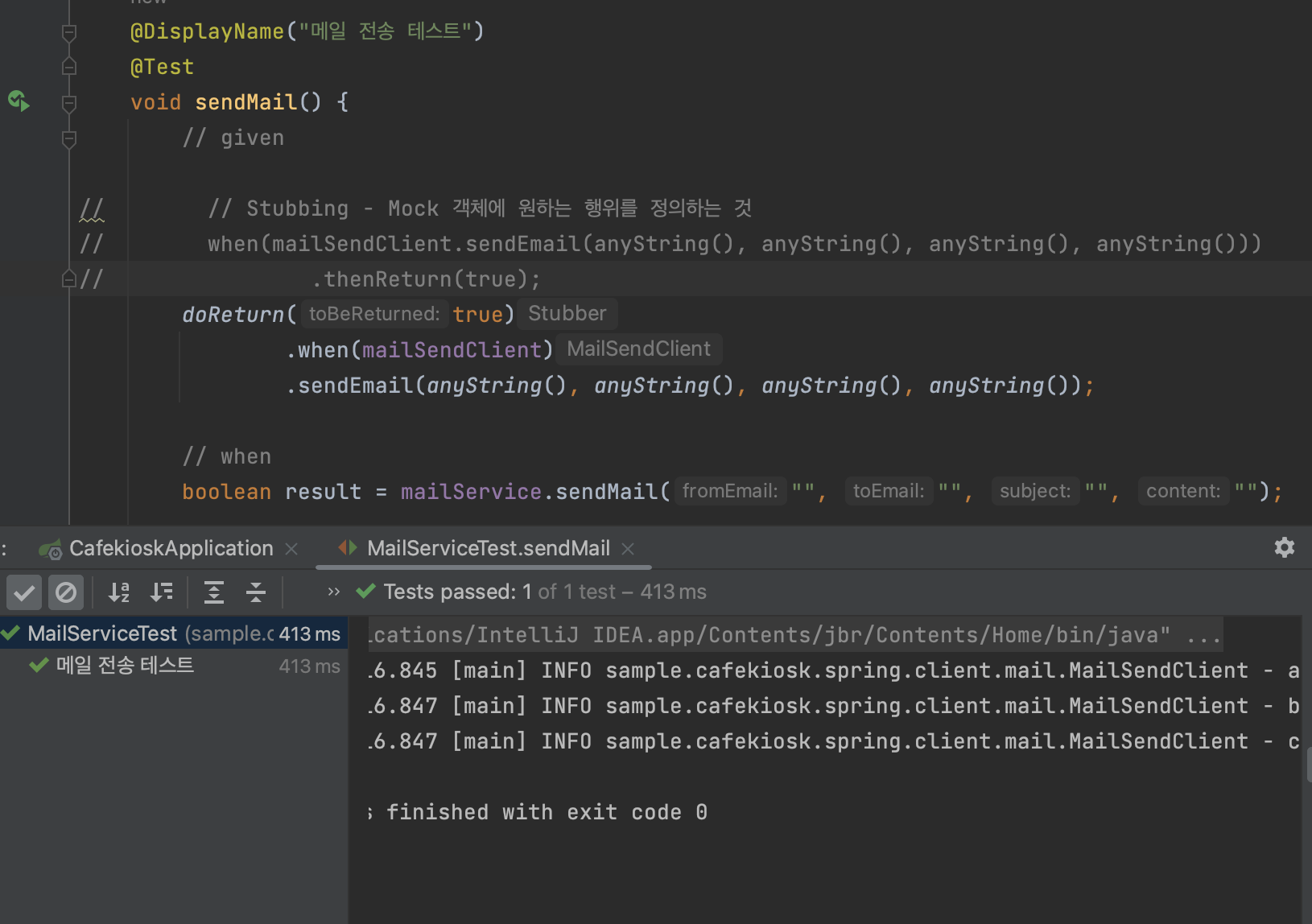
sendEmail()만 원하는 Stubbing이 된거고, 나머지 a,b,c 라는 실제 객체는 그대로 동작이 되었다.
이처럼 일부는 Stubbing, 나머지 실제처럼 사용할 때
@Spy어노테이션을 사용한다.(사실
@Spy를 사용하면 특정 서비스의 일부 기능만 테스트하는데, 빈도수가 그렇게 많지는 않아서 실무에서는@Spy보다는@Mock을 더 자주 사용한다)BDDMockito
아래 코드에서 given 절을 보면, 어색한 부분을 확인할 수 있다.
@ExtendWith(MockitoExtension.class) class MailServiceTest { @Mock private MailSendClient mailSendClient; @Mock private MailSendHistoryRepository mailSendHistoryRepository; @InjectMocks private MailService mailService; @DisplayName("메일 전송 테스트") @Test void sendMail() { // given - Stubbing Mockito.when(mailSendClient.sendEmail(anyString(), anyString(), anyString(), anyString())) .thenReturn(true); // when boolean result = mailService.sendMail("", "", "", ""); // then Assertions.assertThat(result).isTrue(); // mailSendHistoryRepository.save()가 1 번 호출되었는지를 검증 Mockito.verify(mailSendHistoryRepository, times(1)).save(any(MailSendHistory.class)); } }given 절에 사용된
Mockito.when()메서드는 Stubbing을 위해 given 영역에 사용하는 것이 맞지만 when() 이라는 문법이 가독성을 저하시키고 혼란을 야기할 수 있다.그래서 이를 해결하기 위해 BDDMockito의 문법인
BDDMockito.given()메서드를 사용하면, given 절과 유사해진다.@ExtendWith(MockitoExtension.class) class MailServiceTest { @DisplayName("메일 전송 테스트") @Test void sendMail() { // given // BDDMockito의 문법인 BDDMockito.given을 사용하면 BDD 스타일을 지킬 수 있다. BDDMockito.given(mailSendClient.sendEmail(anyString(), anyString(), anyString(), anyString())) .willReturn(true); // when boolean result = mailService.sendMail("", "", "", ""); // then Assertions.assertThat(result).isTrue(); // mailSendHistoryRepository.save()가 1 번 호출되었는지를 검증 Mockito.verify(mailSendHistoryRepository, times(1)).save(any(MailSendHistory.class)); } }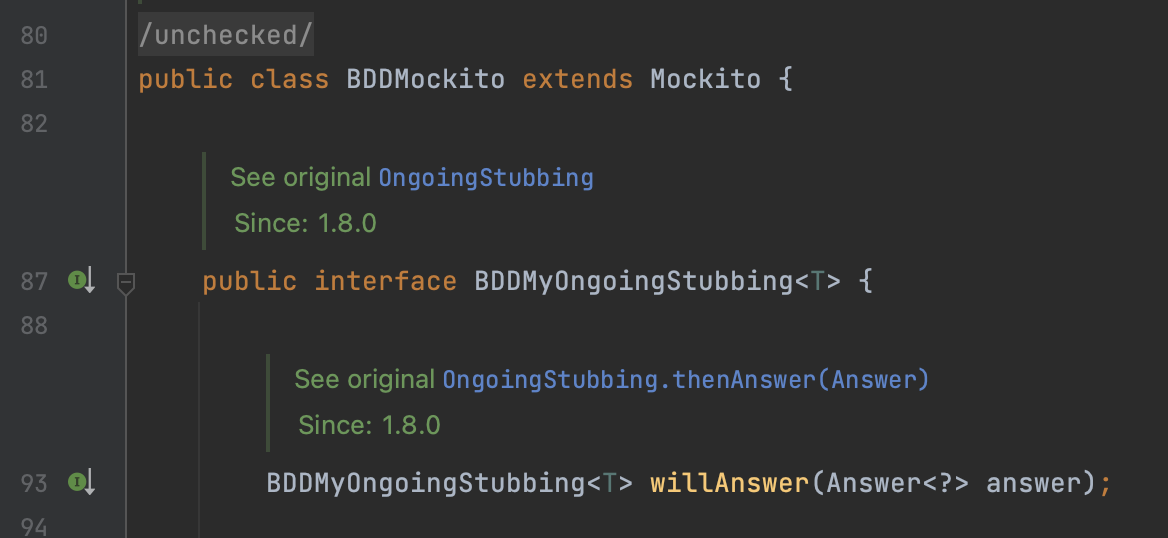
BDDMockito를 가보면 Mockito를 감싸고 있다. (상속받고 있다)모든 동작이 같은데, BDD 스타일로만 바뀐 것이다. -> 이름만 바꿨고, 기능은 동일하다.
결론은 앞으로 테스트 코드를 BDD 스타일로 작성할 때는
BDDMockito문법을 사용하자!Classicist vs Mockist
-
Classicist - 진짜 객체로 테스트를 하자. -> 상태 검증을 통한 의존 객체의 구현보다는 실제 입/출력 값을 통해 검증하는 테스트이다.
-
Mockist - 모든 걸 mocking 위주(가짜 객체)로 테스트를 하자. -> 행위 검증을 통해 의존 객체의 특정 행동이 이루어졌는지를 검증하는 테스트이다.
이번 강의에서는 Controller 테스트할 때는 Service와 Repository를 Mocking하여 단위 테스트를 진행했고, Service 테스트 할 때는 Repository의 실제 객체를 사용한 통합 테스트를 진행했다.
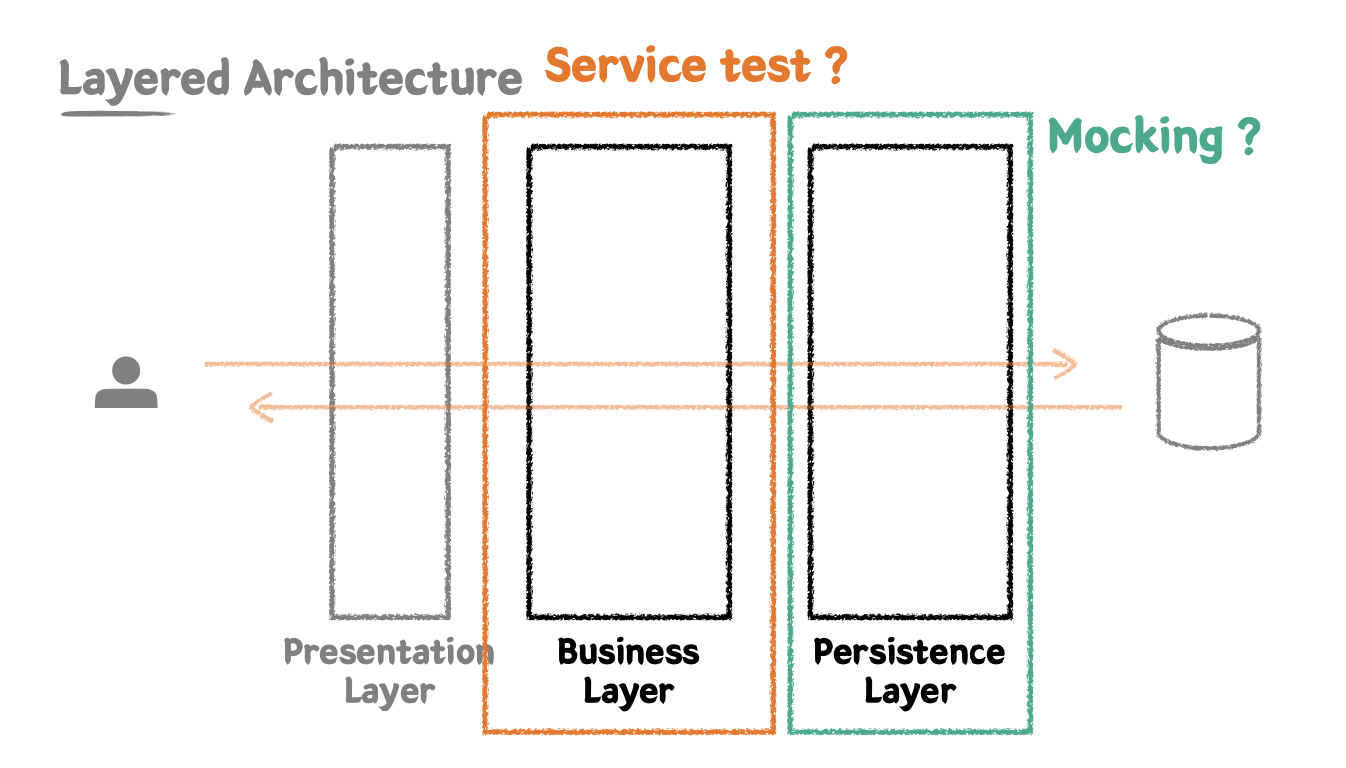
Mockist 입장에서 바라보면 Service 테스트 할 때에도 Repository에도 실제 객체가 아닌 Mocking을 하여 단위 테스트로 신속히 테스트를 해야 한다. -> 어느 것이 더 좋은 방법일까?
이 강의를 만드신 우빈님의 생각
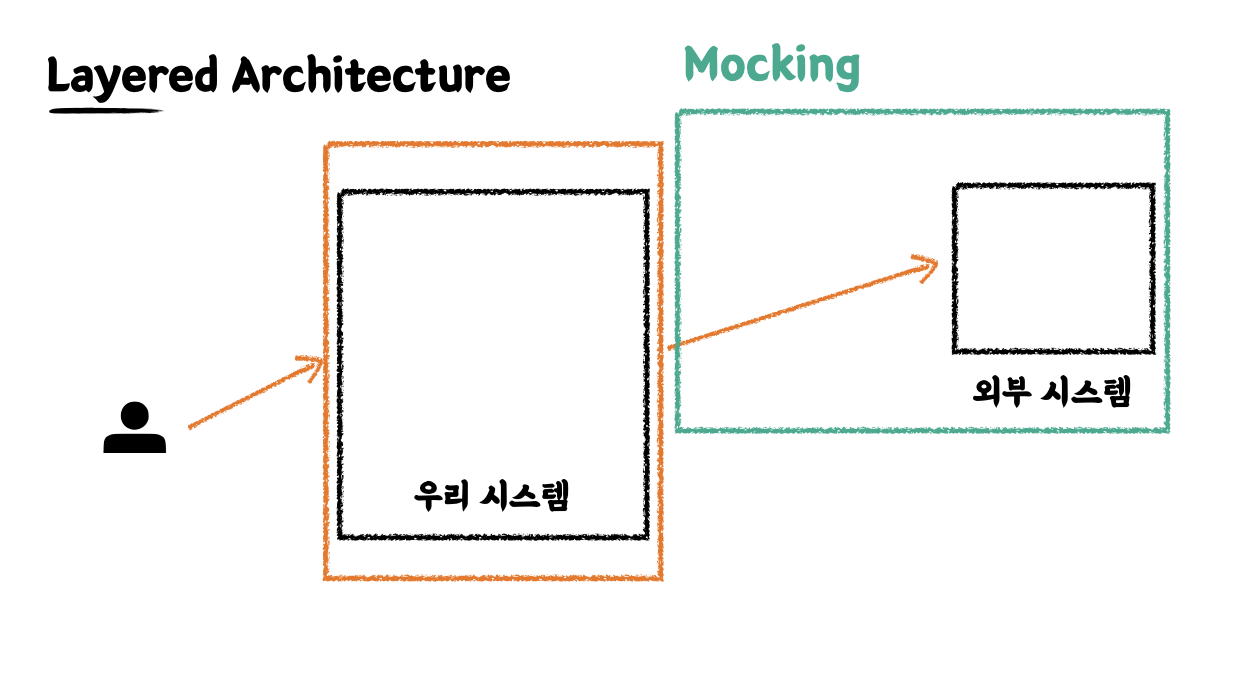
-
메일 전송같은 외부 시스템을 요청하거나 연결할 때 Mocking을 쓴다. -> 외부 시스템은 우리가 개발한 게 아니기 때문이다.
-
Mocking 위주로 테스트를 작성한다면, “실제 프로덕션 코드에서 런타임 시점에 일어날 일을 정확하게
Stubbing(Mocking)했다고 단언할 수 있는가?” -
테스트를 했다고 100% 재현할 수 있나? → 그런 리스크를 안고 갈 바에는 비용을 조금 더 들여서 실제 객체를 가져와서 테스트를 하는게 낫다는게 Classicist 입장이신 우빈님의 생각이다.
-> 내 생각: AWS S3나 소셜 로그인(OAuth 2.0)과 같은 외부 시스템과 연동하는 비즈니스 로직을 테스트할 경우에는 Mock을 사용하는 것이 효과적이라는 생각이 들었다.
더 나은 테스트를 작성하기 위한 구체적 조언
한 문단에 한 주제!
테스트 코드를 글쓰기 관점에서 봤을 때, 하나의 테스트는 하나의 주제만을 가져야 한다.
논리구조에는 분기문(if), 반복문(while, for)이 있다.
-
분기문이 존재한다는 것 자체가 2가지 이상 내용이 들어가있다는 걸 반증한다.
-
반복문 역시 테스트 코드를 읽는 사람이 한번 더 생각해야 한다.
-
결론은, 케이스가 두 가지 이상 생기면 → 테스트 코드를 2개로 나눠서 코드를 작성한다. -> 논리구조는 방해 요소가 될 수 있기 때문에 되도록 지양하자.
완벽하게 제어하기
테스트 환경에서 제어할 수 없는 것들은 완벽하게 제어할 수 있도록 한다.
LocalDateTime.now()와 같은 제어할 수 없는 코드의 경우 -> 현재 시간을 분리해서 상위 레벨로 올리고, 테스트할 때는 원하는 시간을 주입해서 상황을 재연한다.현재 시간이라는 데이터를 기준으로 테스트하는 것 보다, 고정된 날짜 또는 시간 등을 가지고 테스트하는 것이 좋다.
// CafeKiosk @Getter public class CafeKiosk { public Order createOrder() { LocalDateTime currentDateTime = LocalDateTime.now(); LocalTime currentTime = currentDateTime.toLocalTime(); if(currentTime.isBefore(SHOP_OPEN_TIME) || currentTime.isAfter(SHOP_CLOSE_TIME)) { throw new IllegalArgumentException("주문 시간이 아닙니다. 관리자에게 문의하세요."); } return new Order(currentDateTime, beverages); } public Order createOrder(LocalDateTime currentDateTime) { LocalTime currentTime = currentDateTime.toLocalTime(); if(currentTime.isBefore(SHOP_OPEN_TIME) || currentTime.isAfter(SHOP_CLOSE_TIME)) { throw new IllegalArgumentException("주문 시간이 아닙니다. 관리자에게 문의하세요."); } return new Order(currentDateTime, beverages); } } // CafeKioskTest class CafeKioskTest { @Test void createOrder() { CafeKiosk cafeKiosk = new CafeKiosk(); Americano americano = new Americano(); cafeKiosk.add(americano); Order order = cafeKiosk.createOrder(); assertThat(order.getBeverages()).hasSize(1); assertThat(order.getBeverages().get(0).getName()).isEqualTo("아메리카노"); } @Test void createOrderWithCurrentTime() { CafeKiosk cafeKiosk = new CafeKiosk(); Americano americano = new Americano(); cafeKiosk.add(americano); Order order = cafeKiosk.createOrder(LocalDateTime.of(2023, 11, 30, 10, 0)); assertThat(order.getBeverages()).hasSize(1); assertThat(order.getBeverages().get(0).getName()).isEqualTo("아메리카노"); } @Test void createOrderOutsideOpenTime() { CafeKiosk cafeKiosk = new CafeKiosk(); Americano americano = new Americano(); cafeKiosk.add(americano); assertThatThrownBy(() -> cafeKiosk.createOrder(LocalDateTime.of(2023, 11, 30, 9, 59))) .isInstanceOf(IllegalArgumentException.class) .hasMessage("주문 시간이 아닙니다. 관리자에게 문의하세요."); } }createOrder()는 현재 시간을 기준으로 성공할 수도, 실패할 수도 있다.반면에,
createOrderWithCurrentTime(),createOrderOutsideOpenTime()는 임의의 시간을 정해서 원하는 상황을 완벽하게 연출할 수 있게 되었다.외부 시스템일 경우, Mocking 처리하고 테스트를 구성한다.
테스트 환경의 독립성을 보장하자
```java // OrderServiceTest class OrderServiceTest { @DisplayName(“재고가 부족한 상품으로 주문을 생성하려는 경우 예외가 발생한다.”) @Test void createOrderWithNoStock() { LocalDateTime registeredDateTime = LocalDateTime.now(); // given Product product1 = createProduct(BOTTLE, “001”, 1000); Product product2 = createProduct(BAKERY, “002”, 3000); Product product3 = createProduct(HANDMADE, “003”, 5000); productRepository.saveAll(List.of(product1, product2, product3));
Stock stock1 = Stock.create("001", 2); Stock stock2 = Stock.create("002", 2); stock1.deductQuantity(1); // todo stockRepository.saveAll(List.of(stock1, stock2));
-
-
[백준] 16173. 점프왕 쩰리 (Small)
성능 요약
- 메모리: 14128 KB, 시간: 124 ms
구분
- 너비 우선 탐색, 브루트포스 알고리즘, 깊이 우선 탐색, 그래프 이론, 그래프 탐색, 구현
Answer Code1
```java // [백준] 16173. 점프왕 쩰리 (Small) - 23.12.11 import java.util.; import java.io.;
class Jump_king_jelly { static final int MAX = 3 + 100 + 10; static int map[][]; static boolean visited[][]; static int N; static int dirY[] = {1, 0}; static int dirX[] = {0, 1};
public static void dfs(int y, int x) { visited[y][x] = true;
if(y == N && x == N) return; for(int i = 0; i < 2; i++) { int newY = y + dirY[i] * map[y][x]; int newX = x + dirX[i] * map[y][x]; if(visited[newY][newX] == false) { dfs(newY, newX); } } }public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
N = Integer.parseInt(br.readLine()); map = new int[MAX][MAX]; visited = new boolean[MAX][MAX]; // 1. map에 정보 반영 for(int i = 1; i <= N; i++) { StringTokenizer st = new StringTokenizer(br.readLine()); for(int j = 1; j <= N; j++) { map[i][j] = Integer.parseInt(st.nextToken()); } }
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8