흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
Practical Testing: 테스트 코드 작성 방법
이 글은 Practical Testing: 실용적인 테스트 가이드 강의를 듣고 내용을 정리한 글입니다.
학습 목표
-
테스트 코드의 필요성을 이해하고 숙지한다.
-
좋은 테스트 코드가 무엇이고 깔끔하고 명확한 테스트 코드를 작성하는 방법을 학습하고 정리한다.
-
Spring 및 JPA 기반의 API를 설계하고 개발하는 과정에서 실무 수준의 테스트 코드를 작성하고 이를 정리한다.
테스트를 하는 이유
-
테스트는 기본적으로 귀찮은 작업이다. 실무에서는 짧은 시간안에 기능 구현만 만들기도 벅찬데, 테스트 코드를 작성하기가 쉽지 않다.테스트의 필요성을 명확히 이해하지 못하면, 이 작업을 소홀히하고 무시하는 경향이 생길 수 있다.
-
테스트 코드가 없는 환경에서는 새로운 기능을 추가하거나 코드를 수정할 때 기존 코드가 여전히 정상 작동하는지 확인하기 위해 사람이 직접 수동으로 테스트해야 한다.
프로덕션 코드는 시간이 지날수록 점점 더 확장하게 되는데, 그때마다 테스트 인력을 무한정 늘릴 수 있을 까에 대한 고민이 있을 수 있다.
그리고 사람이 수동으로 테스트를 하다 보면 누락되는 케이스가 발생할 수도 있고, 그게 곧 치명적인 결함이 돼서 실제 상용 소프트웨어에 큰 문제가 발생할 수도 있다.
소프트웨어가 커지는 속도를 따라잡지 못하게 되고, 기능들도 서로 겹치면서 기존에 테스트 했던 영역을 또 테스트하게 되면서 커버할 수 없는 영역이 발생하게 된다.
또한 프로덕션 코드가 확장됨에 따라 이 프로젝트를 오래 했던 사람들 또는 개발(or 테스트)을 오래 했던 사람들의 경험과 감에 의존할 수 밖에 없게 된다.
사람이 테스트를 하다 보니까 시간이 오래 걸려서 피드백이 늦어지게 되고, 테스트 도중 버그가 생기면 다시 수정 개발을 하면서 이런 사이클이 되게 느리게 돌아가게 된다. 이로 인해 유지보수가 어려워지고, 이는 결국 소프트웨어의 신뢰도를 낮추는 일이 된다.
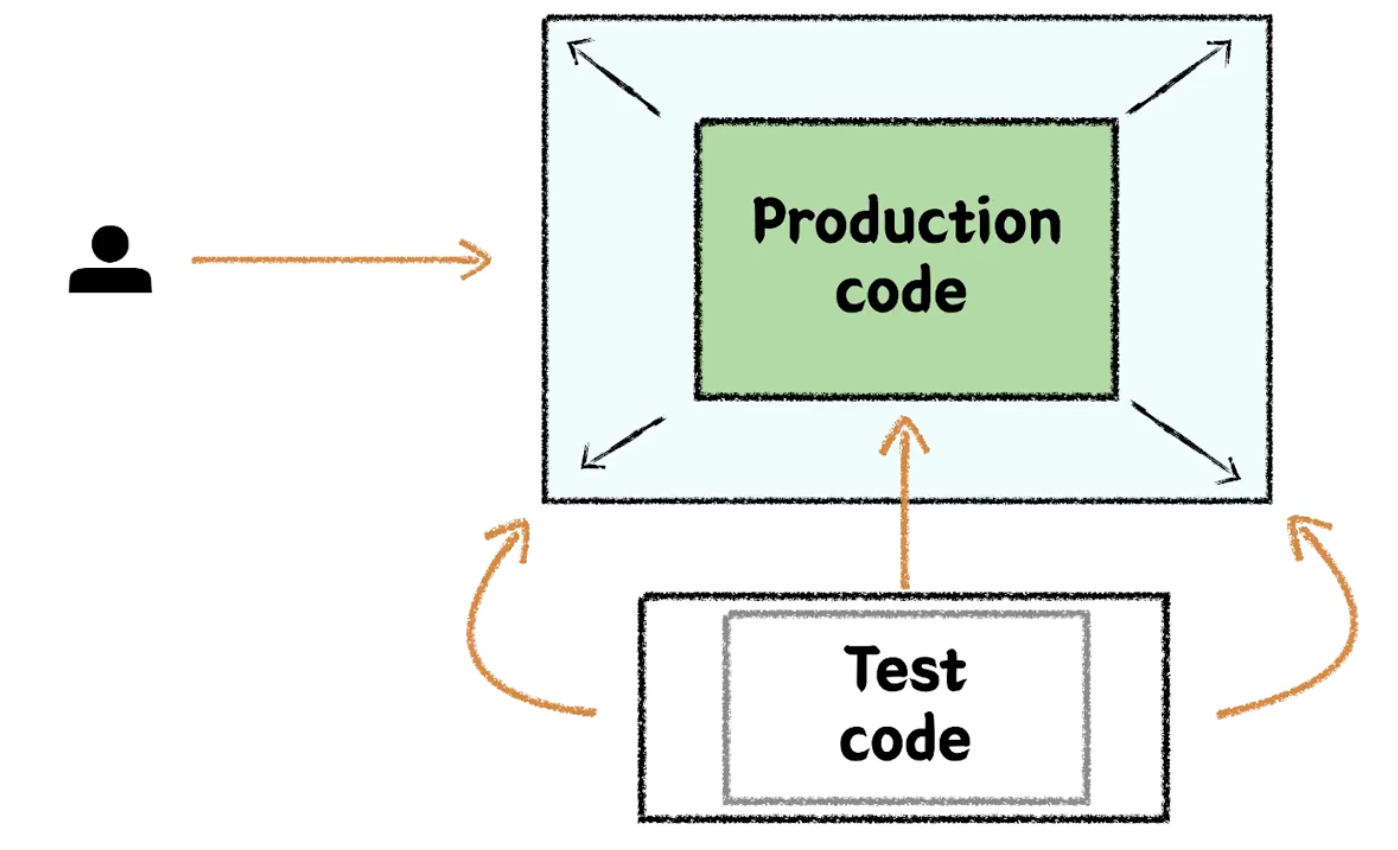
-
그래서 우리는 테스트 코드를 통해서 내가 개발한 기능에 대해서 내가 의도한 대로 동작하는지 빠른 피드백을 받을 수 있어야 하고, 기계가 검증할 수 있도록 자동화를 해서 내가 만든 소프트웨어에 대한 안정감과 신뢰감을 얻을 수 있어야 한다.
빠뜨리지 않고 테스트 코드를 잘 추가했다면, 커지는 소프트웨어를 프로덕션 코드를 테스트 코드가 계속 커버할 수 있게 된다.
-
그런데 테스트 코드가 엉망으로 작성되어 있다면,
프로덕션 코드의 안정성을 제공하기 힘들며, 유지보수하기 어려운 상황이 발생하여, 이는 곧 테스트의 검증이 잘못될 가능성이 높아진다.
-
그래서 올바른 테스트 코드를 작성해야 한다.
올바른 테스트 코드를 통해 자동화가 되어 빠른 시간안에 버그를 발견할 수 있고, 수동 테스트에 드는 비용을 크게 절약할 수 있다.
그리고 소프트웨어의 빠른 변화를 지원할 수 있게 해준다.
또한 내가 고민했던 것들을 코드로 녹여내면, 팀내 공유 지식이 되면서 팀원들의 집단 지성을 팀 차원의 이익으로 승격시켜주는 이점이 있다.
이는 ‘가까이 보면 느리지만, 멀리 보면 가장 빠르다’ 라고 표현될 수 있다.
-
테스트는 확실한 귀찮은 작업이지만, 이를 극복하고 왜 해야 하는지 명확히 이해하고, 실무에서 테스트 작성 시 귀찮음을 인정하면서도 꾸준한 노력으로 해내야 한다는 마음가짐을 갖춰야 한다.
단위 테스트
개발 환경
프로젝트 주제인 ‘초간단 카페 키오스크 시스템’을 개발하면서 테스트 코드를 작성하는 방법을 배워보자.
해당 프로젝트에 대한 실습을 깃허브에 기록했습니다.
개발 환경은 다음과 같다.
-
IntelliJ Ultimate
-
Java 11
-
Spring Boot 2.7.7
-
Gradle & Groovy
-
Dependency - Spring Web, Thymeleaf, Spring Data JPA, H2 Database, Lombok, Validation
Junit5, AssertJ
-
단위 테스트란 작은 코드 단위를 독립적으로 검증하는 테스트이다. 여기서 작은 코드는 클래스 혹은 메서드를 의미한다.단위 테스트는 검증 속도가 빠르고 안정적인 특징을 가진다.
-
Junit5란 단위 테스트를 위한 테스트 프레임워크이다. (참고 - 공식문서) -
AssertJ란 테스트 코드 작성을 원활하게 돕는 테스트 라이브러리이다. 풍부한 API, 메서드 체이닝을 지원한다. (참고 - 공식문서)
테스트 케이스 세분화하기
요구 사항: 한 종류의 음료 여러 잔을 한 번에 담는 기능
이러한 요구 사항이 들어왔을 때, 자신에게 혹은 요구 사항을 들고온 기획자, 타직군에게 다시 질문을 해 볼 수 있어야 한다.
질문하기: 암묵적이거나 아직 드러나지 않은 요구 사항이 있는지 항상 염두하고 고민을 해봐야 한다.
해피 케이스와예외 케이스, 이 두가지 케이스를 가지고 경계값 테스트를 도출 할 수 있어야 한다.-
여기서
경계값 테스트는 범위(이상, 이하, 미만, 초과), 구간, 날짜 등을 말한다. -
예를 들어, 어떤 정수 값이 있고 이 정수가 3이상일 때, A라는 조건을 만족한다고 가정한다면,
-
3 이상에 대한 해피 케이스와 3 미만에 대한 예외 케이스를 작성해야 한다.
해당 요구 사항(한 종류의 음료 여러 잔을 한 번에 담는 기능)에 대해 해피 케이스와 예외 케이스를 작성해보면 아래와 같다.
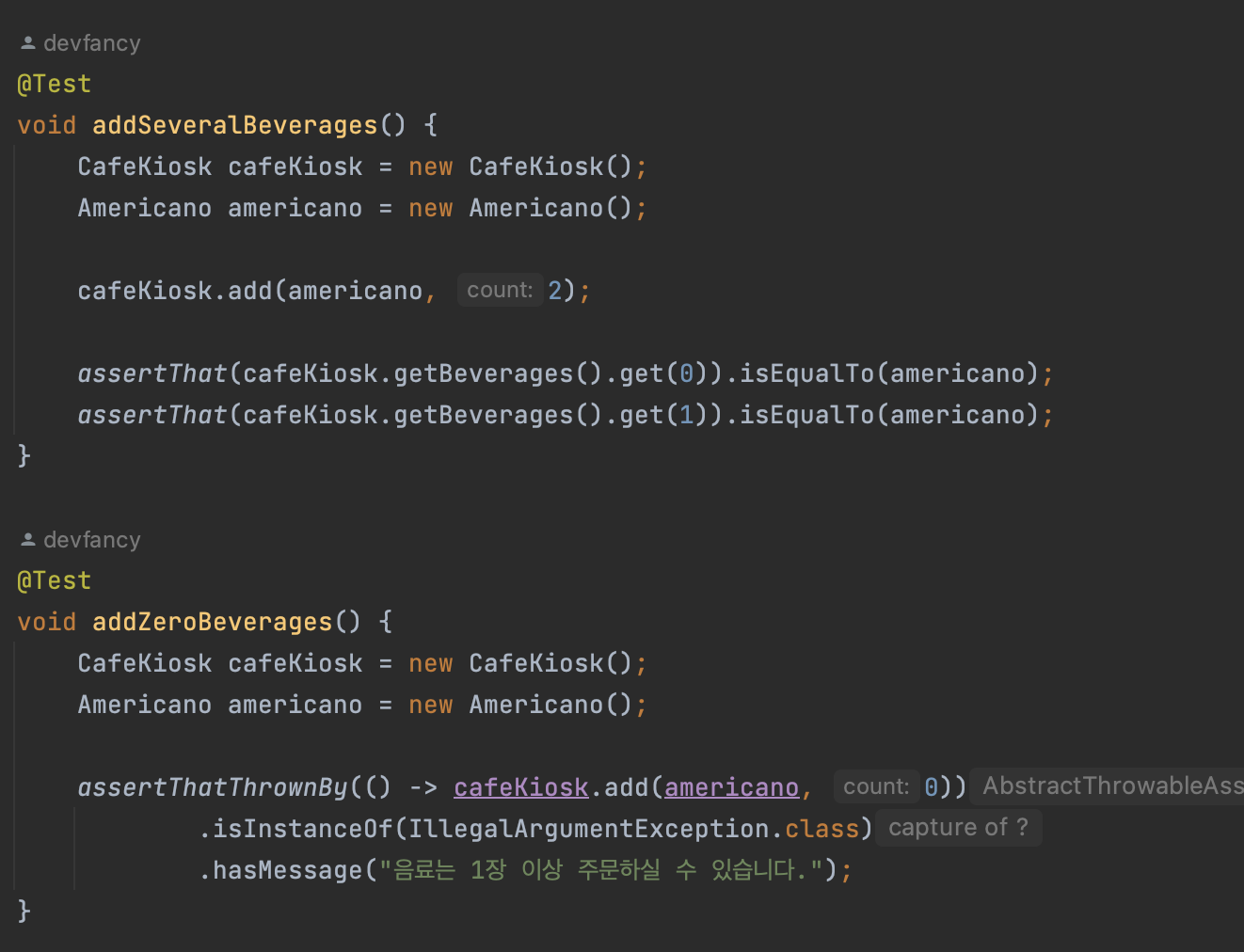
addSeveralBeverages메서드는 하나의 종류인 아메리카노에 2개를 담는 테스트로 해피 케이스이고,addZeroBeverages메서드는 하나의 종류인 아메리카노에 0개를 담았을 때 예외가 발생하는 예외 케이스인 것을 확인할 수 있다.테스트하기 어려운 영역
요구사항: 가게 운영 시간(10:00 ~ 22:00) 외에는 주문을 생성할 수 없다.
영업 시간 내에 주문이 생성되려면 시간과 관련된 부분도 고려하기 때문에 테스트하기 어려울 수 있다.
주문을 생성하는 로직에 시간과 관련된 부분을 추가하게 되면, 기존 프로덕션 코드가 전부 수정되어야 하기 때문에 좋지 않다.
이를 위해 주문을 생성할 때 외부에서 시간 데이터를 받아올 수 있도록 변경한다면 테스트 시에는 원하는 시간을 통해 검증할 수 있고, 프로덕션 코드에서도 현재 시간을 인자로 주어 동작할 수 있다.
```java @Getter public class CafeKiosk {
public static final LocalTime SHOP_OPEN_TIME = LocalTime.of(10, 0); public static final LocalTime SHOP_CLOSE_TIME = LocalTime.of(22, 0);
-
-
equals와 hashCode 관계
이 글은 자바의 정석 책에서 나온 개념과 예제를 학습하고 정리한 글입니다.
java.lang 패키지
-
java.lang패키지는 자바프로그래밍에서 가장 기본이 되는 클래스를 포함하고 있다. -
그렇기 때문에
java.lang패키지의 클래스들은 import문 없이도 사용할 수 있게 되어 있다.- java.lang 패키지에 포함되는 클래스 : Object, String, StringBuffer, StringBuilder, Math, Wrapper
-
java.lang패키지의 여러 클래스들 중에서 자주 사용되는Object클래스와 관련 메서드에 대해 학습해보자.
Object 클래스
-
Object클래스는 모든 클래스의 최고 조상이기 때문에 Object 클래스의 멤버들은 모든 클래스에서 바로 사용 가능하다. -
Object클래스는 멤버변수는 없고 오직 11개의 메서드만 가지고 있다. 이 메서드들은 모든 인스턴스가 가져야 할 기본적인 것들이며, 이 중에서 중요한 몇 가지만 살펴보자.(11개 메서드에 대해 확인하고 싶으면, “자바의 정석” p.450을 참고하자)
equals(Object obj)
-
equals()는 매개변수로 객체의 참조변수를 받아서 비교하여 그 결과를 boolean 값으로 알려주는 역할을 한다.
-
아래의 코드는 Object 클래스에 정의되어 있는 equals의 실제 내용이다.
public boolean equals(Object obj){ return(this == obj); }-
두 객체의 같고 다름을 참조변수의 값으로 판단한다. 그렇기 때문에 서로 다른 두 객체를
equals메서드로 비교하면 항상 false를 결과로 얻게 된다.equals메서드는 주소값으로 비교하기 때문에, 멤버변수의 값이 서로 같을지라도 참조변수의 값(주소값)이 다르면 false일 수 밖에 없다. -
Object 클래스로부터 상속받은 equals 메서드는 결국 두개의 참조변수가 같은 객체를 참조하고 있는지, 즉 두 참조변수에 저장된 값(주소값)이 같은지를 판단하는 기능밖에 할 수 없다는 것을 알 수 있다.
equals메서드로 인스턴스가 가지고 있는 value 값을 비교하도록 할 수 있는 방법은 equals 메서드를 오버라이딩하여 주소가 아닌 객체에 저장된 내용을 비교하도록 변경하면 된다.
class Person { long id; @Override public boolean equals(Object obj) { if(obj instanceof Person) { return id == ((Person) obj.id); // obj가 Object 타입이므로 id 값을 참조하기 위해서는 Person 타입으로 형변환이 필요하다. } else return false; // 타입이 Person이 아니면 값을 비교할 필요도 없다. } Person(long id) { this.id = id; } } class EqualsEx { public static void main(String[] args) { Person p1 = new Person(12345L); Person p2 = new Person(12345L); if(p1 == p2) System.out.println("p1과 p2는 같은 사람입니다."); else System.out.printf("p1과 p2는 다른 사람입니다."); // 첫번째 결과 if(p1.equals(p2)) System.out.println("p1과 p2는 같은 사람입니다."); // 두번째 결과 else System.out.printf("p1과 p2는 다른 사람입니다."); } }-
equals메서드가 Person 인스턴스의 주소값이 아닌 멤버변수 id의 값을 비교하도록 하기 위해equals메서드를 다음과 같이 오버라이딩했다.이렇게 함으로써 서로 다른 인스턴스일지라도 같은 id(주민등록번호)를 가지고 있다면, equals 메서드로 비교했을 때, true로 결과를 얻게 할 수 있다.
-
String클래스 역시 Obejct 클래스의 equals 메서드를 그대로 사용하는 것이 아니라 이처럼 오버라이딩을 통해서 String 인스턴스가 갖는 문자열 값을 비교하도록 되어있다.그렇기 때문에 같은 내용의 문자열을 갖는 두 String 인스턴스에 equals 메서드를 사용하면 항상 true 값을 얻을 수 있다.
hashCode()
-
hashCode 메서드는
해싱(hashing)기법에 사용되는 ‘해시함수(hash function)’을 구현한 것이다.해싱은 데이터관리기법 중 하나인데 다량의 데이터를 저장하고 검색하는데 유용하다.
-
해시함수는 찾고자 하는 값을 입력하면, 그 값이 저장된 위치를 알려주는 해시코드(hashcode)를 반환한다.
일반적으로 해시코드가 같은 두 객체가 존재하는 것은 가능하지만, Object 클래스에 정의된
hashCode메서드는 객체의 주소값을 int 값으로 해시코드를 만들어 반환하기 때문에32 bit JVM에서는 서로 다른 두 객체는 결코 같은 해시코드를 가질 수 없었다.하지만
64 bit JVM에서는 8 byte 주소값으로 해시코드(4 byte)를 만들 수 있기 때문에 해시코드가 중복될 수 있다. -
앞서 살펴본 것과 같이 클래스의
인스턴스 변수 값으로 객체의 같고 다름을 판단해야 하는 경우라면 equals 메서드 뿐 만 아니라hashCode메서드도 적절히 오버라이딩해야 한다.같은 객체라면 hashCode 메서드를 호출했을 때의 결과값인 해시코드도 같아야 하기 때문이다.
class HashCodeEx { public static void main(String[] args) { String str1 = new String("hello"); String str2 = new String("hello"); System.out.println(str1.hashCode()); // 12345 System.out.println(str2.hashCode()); // 12345 } }-
String클래스는 문자열의 내용이 같으면, 동일한 해시코드를 반환하도록hashCode메서드가 오버라이딩되어 있기 때문에, 문자열 내용이 같은 str1과 str2에 대해hashCode()를 호출하면 항상 동일한 해시코드값을 얻는다.반면에
Object클래스의hashCode메서드처럼 객체의 주소값으로 해시코드를 생성하기 때문에 모든 객체에 대해 항상 다른 해시코드값을 반환할 것을 보장한다.
참고:
해싱기법을 사용하는 HashMap이나 HashSet과 같은 클래스에 저장할 객체라면 반드시hashCode메서드를 오버라이딩 해야한다. - 자바의 정석 11장. 컬렉션 프레임웍 -equals와 hashCode를 같이 재정의 해야하는 이유
equals만 재정의할 경우
우선 예제로 사용될 Product 클래스를 살펴보자.
public class Product { private final String name; public Product(String name) { this.name = name; } // intellij Generate 기능 사용 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Product product = (Product) o; return Objects.equals(name, product.name); } }- Product 클래스에는 equals만 재정의했다.
public static void main(String[] args){ Product product1 = new Product("아메리카노"); Product product2 = new Product("아메리카노"); // true 출력 System.out.println(product1.equals(product2)); }-
equals를 재정의했기 때문에 Product 객체의 name이 같은 product1, product2 객체는 논리적으로 같은 객체로 판단된다.
-
이제 아래 main 메서드의 출력 결과를 예측해보자.
public static void main(String[] args) { List<Product> products = new ArrayList<>(); products.add(new Product("아메리카노")); products.add(new Product("아메리카노")); System.out.println(products.size()); }-
Product 객체를 2개
List<Product> products에 넣어줬으니 출력 결과는 당연히 2일 것이다. -
그렇다면 이번엔 Collection에 중복되지 않는 Product 객체만 넣으라는 요구사항이 추가되었다고 가정해보자.
-
요구사항을 반영하기 위해 List에서 중복 값을 허용하지 않는 Set으로 로직을 바꿨다.
public static void main(String[] args) { Set<Product> products = new HashSet<>(); products.add(new Product("아메리카노")); products.add(new Product("아메리카노")); System.out.println(products.size()); }-
추가된 두 Product 객체의 이름이 같아서 논리적으로 같은 객체라 판단하고 HashSet의 size가 1이 나올거라 예상했지만, 예상과 다르게 2가 출력된다.
-
hashCode를 equals와 함께 재정의하지 않으면 코드가 예상과 다르게 동작하는 위와 같은 문제를 일으킨다.
-
정확히 말하면 hash 값을 사용하는 Collection(HashSet, HashMap, HashTable)을 사용할 때 문제가 발생한다.
문제가 발생하는 이유
- hash 값을 사용하는 Collction(HashMap, HashSet)은 객체가 논리적으로 같은지 비교할 때 아래 그림과 같은 과정을 거친다.
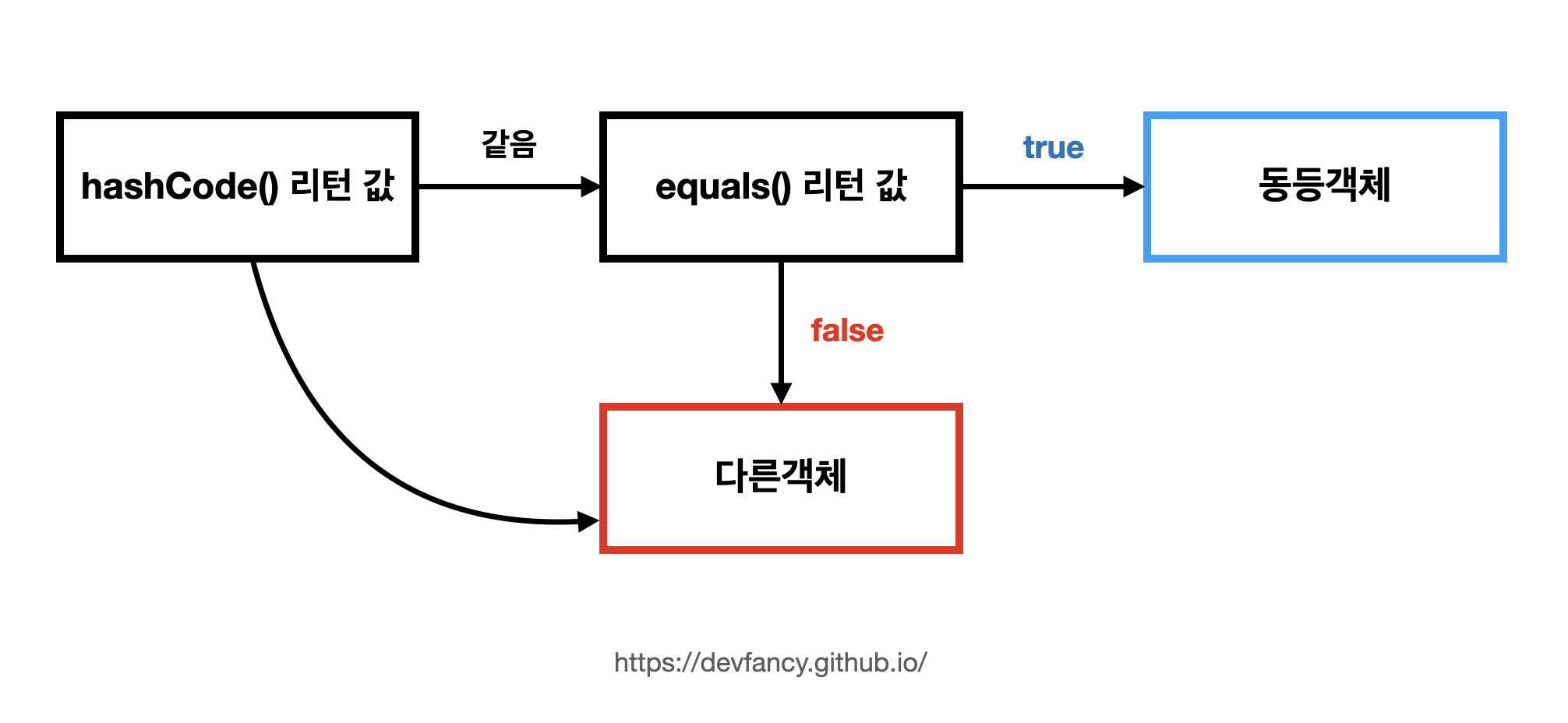
-
[1] hashCode 메서드의 리턴 값이 우선 일치하고 [2] equals 메서드의 리턴 값이 true여야 논리적으로
같은 객체라고 판단한다. -
앞서 봤던 main 메서드의 HashSet에 Product 객체를 추가할 때도 위와 같은 과정으로 중복 여부를 판단하고 HashSet에 추가됐다.
다만 Product 클래스에는 hashCode 메서드가 재정의 되어있지 않아서 Object 클래스의 hashCode 메서드가 사용되었다.
Object 클래스의 hashCode 메서드는
객체의 고유한 주소 값을 int 값으로 변환하기 때문에 객체마다 다른 값을 리턴한다.두 개의 Product 객체는 equals로 비교도 하기 전에 서로 다른 hashCode 메서드의 리턴 값으로 인해 다른 객체로 판단된 것이다.
해결방안: hashCode 오버라이딩
- 앞서 살펴봤던 문제를 해결하기 위해 Product 클래스에 hashCode 메서드를 아래와 같이 재정의했다.
public class Product { private final String name; public Product(String name) { this.name = name; } // intellij Generate 기능 사용 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Product product = (Product) o; return Objects.equals(name, product.name); } @Override public int hashCode() { return Objects.hash(name); } }-
intellij 의 Generate 기능을 사용했더니 Objects.hash 메서드를 호출하는 로직으로 hashCode 메서드가 재정의 됐다.
Objects.hash 메서드는 hashCode 메서드를 재정의하기 위해 간편히 사용할 수 있는 메서드이지만 속도가 느리다.
인자를 담기 위한 배열이 만들어지고 인자 중 기본 타입이 있다면 박싱과 언박싱도 거쳐야 하기 때문이다.
-
성능에 아주 민감하지 않은 대부분의 프로그램은 간편하게 Objects.hash 메서드를 사용해서 hashCode 메서드를 재정의해도 문제 없다.
민감한 경우에는 직접 재정의해주는 게 좋다. (관련 정보 - Guide to hashCode() in Java)
무조건 재정의해야 할까?
-
‘hash 값을 사용하는 Collection을 사용하지 않는다면, equals와 hashCode를 같이 재정의(오버라이딩)하지 않아도 되는건가?’ 라고 생각할 수 있다.
-
사용자정의 클래스를 작성할 때 equals 메서드를 오버라이딩해야 한다면, hashCode()도 클래스의 작성의도에 맞게 재정의하는 것이 원칙이지만, 요구사항에 따라 할지 말지 결정하면 된다.
(만약 Collection을 사용한다면 재정의 해주는게 맞다고 생각한다)
Reference
-
자바의 정석 - 9장. java.lang 패키지와 유용한 클래스 / 11장. 컬렉션 프레임웍
-
-
[백준] 4963. 섬의 개수
성능 요약
- 메모리: 16012 KB, 시간: 176 ms
구분
- 그래프 이론, 그래프 탐색, 트리, 너비 우선 탐색, 깊이 우선 탐색
Answer Code
```java // 섬의 개수([백준] 4963.) - 23.12.04 import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.util.StringTokenizer;
public class Number_of_Islands { static final int MAX = 50 + 10; static boolean[][] map; static boolean[][] visited; static int M, N; static int[] dirY = {-1, -1, 0, 1, 1, 1, 0, -1}; // 상하좌우, 대각선 포함 - 8개 방향 static int[] dirX = {0, 1, 1, 1, 0, -1, -1, -1};
public static void dfs(int y, int x) { visited[y][x] = true; for(int i = 0; i < 8; i++) { int newY = y + dirY[i]; int newX = x + dirX[i]; if(map[newY][newX] && visited[newY][newX] == false) { dfs(newY, newX); } }
}
public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
-
[백준] 1388. 바닥장식
성능 요약
- 메모리: 14196 KB, 시간: 128 ms
구분
- 깊이 우선 탐색, 그래프 이론, 그래프 탐색, 구현
Answer Code1(23.12.05)
```java // 바닥장식([백준] 4963.) import java.util.; import java.io.;
class FloorDecoration { static final int MAX = 50 + 10; static char[][] map; static boolean[][] visited;
public static void dfs(int y, int x) { visited[y][x] = true;
if(map[y][x] == '-' && map[y][x+1] == '-') { dfs(y, x+1); } if(map[y][x] == '|' && map[y+1][x] == '|') { dfs(y+1, x); }} public static void main(String[] args) throws IOException { // 0. 입력 및 초기화 BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine()); int N = Integer.parseInt(st.nextToken()); int M = Integer.parseInt(st.nextToken()); map = new char[MAX][MAX]; visited = new boolean[MAX][MAX];
-
[solved.ac] Class3++ 1012. 유기농 배추
성능 요약
-
메모리: 16044 KB, 시간: 164 ms - Answer Code2(2023.02.09) - BFS
-
메모리: 16236 KB, 시간: 160 ms - Answer Code1(2023.02.09) - DFS
-
메모리: 15792 KB, 시간: 164 ms - Answer Code3(2023.12.04) - DFS
구분
- 그래프 이론(graphs), 그래프 탐색(graph_traversal), 너비 우선 탐색(bfs), 깊이 우선 탐색(dfs)
Answer Code1(2023.02.09) - BFS
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.util.LinkedList; import java.util.Queue; import java.util.StringTokenizer; public class Main { static int[][] ground; //2차원 배열로 배추밭을 표현한다 static boolean[][] check; //2차원 배열로 배추가 있는 곳을 체크한다 static int weight; //배추밭의 가로 static int height; //배추밭의 세로 public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); int T = Integer.parseInt(br.readLine()); StringTokenizer st; for (int i = 0; i < T; i++) { st = new StringTokenizer(br.readLine(), " "); weight = Integer.parseInt(st.nextToken()); height = Integer.parseInt(st.nextToken()); ground = new int[weight][height]; check = new boolean[weight][height]; int K = Integer.parseInt(st.nextToken()); for (int j = 0; j < K; j++) { st = new StringTokenizer(br.readLine(), " "); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); ground[x][y] = 1; //배추 좌표 입력 } //=========================================================== //여기까지는 입력된 내용 저장하는 내용이다. int count=0; //테스트 케이스마다 지렁이의 개수를 세야한다 //bfs의 시작좌표를 셋팅해서 다른 곳에 모여있는 배추들도 파악할 수 있게한다 //가로 세로 좌표들을 하나씩 입력해주고 for (int j = 0; j < weight; j++) { for (int k = 0; k < height; k++) { //좌표에 배추가 있는지 확인, 내가 체크안한 곳인지 확인한다 if(ground[j][k] == 1 && !check[j][k]){ //배추가 있고 체크안된 좌표에서부터 bfs로 연결된 곳을 파악한다 bfs(j, k); //지렁이의 개수는 인접한 곳마다 1개씩이다. //인접한 곳을 모두 파악했으면 지렁이를 한마리 놓는다. count++; } } } System.out.println(count); } } private static void bfs(int startX, int startY) { Queue<int[]> queue = new LinkedList<>(); //bfs에서 queue의 역할은 다음 탐색할 좌표를 미리 저장해 놓는 것이다. //bfs 1번 실행될때마다 인접한 곳을 모두 탐색하고 종료되니 bfs안에 queue를 선언했다. queue.offer(new int[] {startX, startY}); //x, y좌표 저장 check[startX][startY] = true; //시작좌표엔 배추가 있으니 미리 true로 처리해준다. int[] X = {0, 0, -1, +1}; int[] Y = {-1, +1, 0, 0}; //배추가 상하좌우에 인접하면 이동할 수 있다. //현재좌표에서 상하좌우 움직이는 좌표를 지정한다. //queue가 비어있으면 더이상 인접한 배추가 없다는 뜻이다. while(!queue.isEmpty()){ int[] poll = queue.poll(); //저장된 queue를 꺼낸다 //상하좌우 4가지 방법이니 for문 4번 반복 for (int i = 0; i < 4; i++) { int x = poll[0] + X[i]; int y = poll[1] + Y[i]; //상하좌우 좌표 조정 //좌표가 배추밭을 벗어나게되면 다음 좌표를 체크해야한다 if(x < 0 || x >= weight || y < 0 || y >= height){ continue; } //상하좌우 움직인 좌표에 배추가 있고, 체크하지 않은 좌표이면 if(ground[x][y] == 1 & !check[x][y]){ queue.offer(new int[] {x, y}); //좌표를 저장한다. check[x][y] = true; //체크한다 } } } } }Answer Code2(2023.02.09) - DFS
```java import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.util.LinkedList; import java.util.Queue; import java.util.StringTokenizer;
public class Main {
static int[][] ground; //2차원 배열로 배추밭을 표현한다 static boolean[][] check; //2차원 배열로 배추가 있는 곳을 체크한다 static int weight; //배추밭의 가로 static int height; //배추밭의 세로 public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); int T = Integer.parseInt(br.readLine()); StringTokenizer st; for (int i = 0; i < T; i++) { st = new StringTokenizer(br.readLine(), " "); weight = Integer.parseInt(st.nextToken()); height = Integer.parseInt(st.nextToken()); ground = new int[weight][height]; check = new boolean[weight][height]; int K = Integer.parseInt(st.nextToken()); for (int j = 0; j < K; j++) { st = new StringTokenizer(br.readLine(), " "); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); ground[x][y] = 1; //배추 좌표 입력 } //=========================================================== //여기까지는 입력된 내용 저장하는 내용이다. int count=0; //테스트 케이스마다 지렁이의 개수를 세야한다 //bfs의 시작좌표를 셋팅해서 다른 곳에 모여있는 배추들도 파악할 수 있게한다 //가로 세로 좌표들을 하나씩 입력해주고 for (int j = 0; j < weight; j++) { for (int k = 0; k < height; k++) { //좌표에 배추가 있는지 확인, 내가 체크안한 곳인지 확인한다 if(ground[j][k] == 1 && !check[j][k]){ //배추가 있고 체크안된 좌표에서부터 dfs로 연결된 곳을 파악한다 dfs(j, k); //지렁이의 개수는 인접한 곳마다 1개씩이다. //인접한 곳을 모두 파악했으면 지렁이를 한마리 놓는다. count++; } } } System.out.println(count); } } private static void dfs(int startX, int startY) { check[startX][startY] = true; //시작좌표엔 배추가 있으니 미리 true로 처리해준다. int[] X = {0, 0, -1, +1}; int[] Y = {-1, +1, 0, 0}; //배추가 상하좌우에 인접하면 이동할 수 있다. //현재좌표에서 상하좌우 움직이는 좌표를 지정한다. //상하좌우 4가지 방법이니 for문 4번 반복 for (int i = 0; i < 4; i++) { int x = startX + X[i]; int y = startY + Y[i]; //상하좌우 좌표 조정 //좌표가 배추밭을 벗어나게되면 다음 좌표를 체크해야한다 if(x < 0 || x >= weight || y < 0 || y >= height){ continue; } //상하좌우 움직인 좌표에 배추가 있고, 체크하지 않은 좌표이면 if(ground[x][y] == 1 & !check[x][y]){ dfs(x, y); //해당 좌표로 dfs 실행 } }
-
- DevHistory 4
- Essay 2
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8