흔들리지 않고, 후회 없이
My path, my pace, no regrets.-
[DB] RDB와 NoSQL
이 글의 정보들은
데이터베이스 개론과면접을 위한 CS 전공지식 노트교재를 공부하면서 정리한 내용을 토대로 작성하였습니다.RDB
-
RDB는 키(key)와 값(value)들의 간단한 관계를 테이블화 시킨 매우 간단한 원칙의 전산정보 데이터베이스이다. -
관계 데이터베이스 모델의 주요 이점은 직관적인 데이터 표현 방법을 제공하고 관련 데이터 포인트에 쉽게 접근할 수 있다는 점이다.
-
관계 데이터베이스를 사용하면 데이터를 관리하고 저장할 때 다음과 같은 여러 가지 장점이 있다.
-
RDB의 장점-
[1] 정형화된 데이터를 저장하기 때문에 데이터의 형태와 크기를 미리 정하고 테이블 단위로 구분하여 데이터를 저장할 수 있다.
-
[2] 트랜잭션을 통해 ACID (원자성, 일관성, 격리성, 지속성)를 보증하여 안정적인 데이터 관리가 가능하다.
-
[3] 조인을 포함해 복잡한 조건을 포함하는 데이터 검색이 가능하다. (복잡한 질의 처리 가능)
-
[4] 데이터베이스 정규화 : 관계 데이터베이스는 데이터 중복성을 줄이고 데이터 무결성을 개선하는
정규화라는 설계 기법을 사용한다.
-
RDBMS
-
RDBMS란 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스를 가리키며SQL이라는 언어를 써서 조작한다. -
RDBMS 종류에는
MySQL,PostgreSQL,Oracle,Microsoft SQL Server,MariaDB등이 있다.

- 현재 기준(2023.02.13) 가장 인기있는 10가지
DBMS는 다음과 같다.
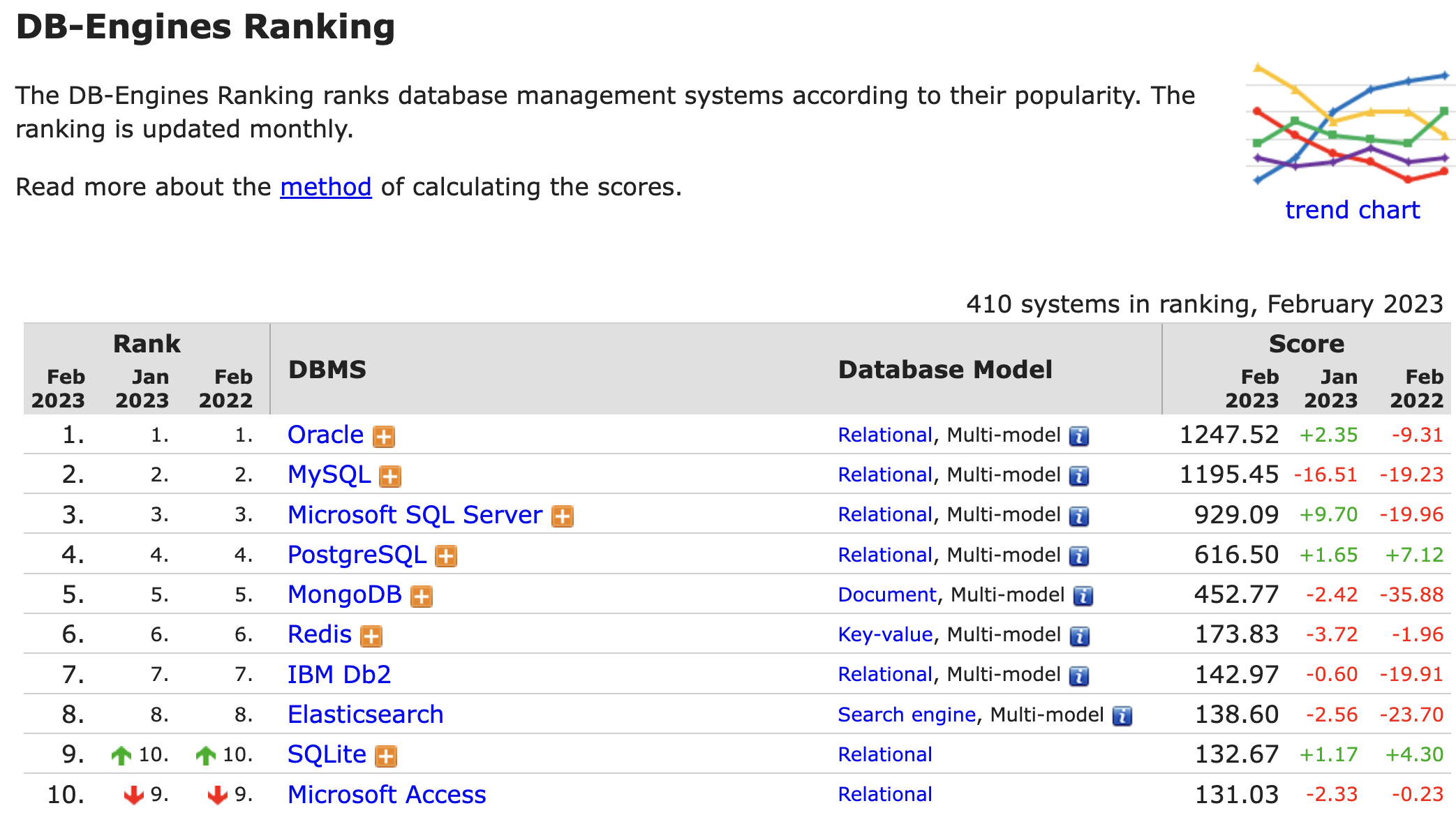
-
관계 데이터베이스의 경우 표준 SQL은 지키기는 하지만, 각각의 제품에 특화시킨
SQL을 사용한다.- 예를 들어 Oracle의 경우 PL/SQL 이라고 하며 SQL Server에서는 T-SQL, MySQL은 SQL을 사용한다.
MySQL
-
MySQL은 대부분의 OS(운영체제)와 호환되며 현재 2위로 많이 사용하는 데이터베이스 관리 시스템이며 메타, 트위터 등 많은 기업에서 MySQL를 사용하고 있다.- 참고) - DB-Engines Ranking
-
C, C++로 만들어졌으며 MyISAM 인덱스 압축 기술, B-tree 기반의 인덱스, Thread 기반의 메모리 할당 시스템, 매우 빠른 조인, 최대 64개의 인덱스를 제공한다.
-
대용량 데이터베이스를 위해 설계되어 있고 롤백, 커밋, 이중 암호 지원 보안등의 기능을 제공하며 많은 서비스에서 사용한다.
-
MySQL의 스토리지 엔진 아키텍쳐는 다음과 같다.
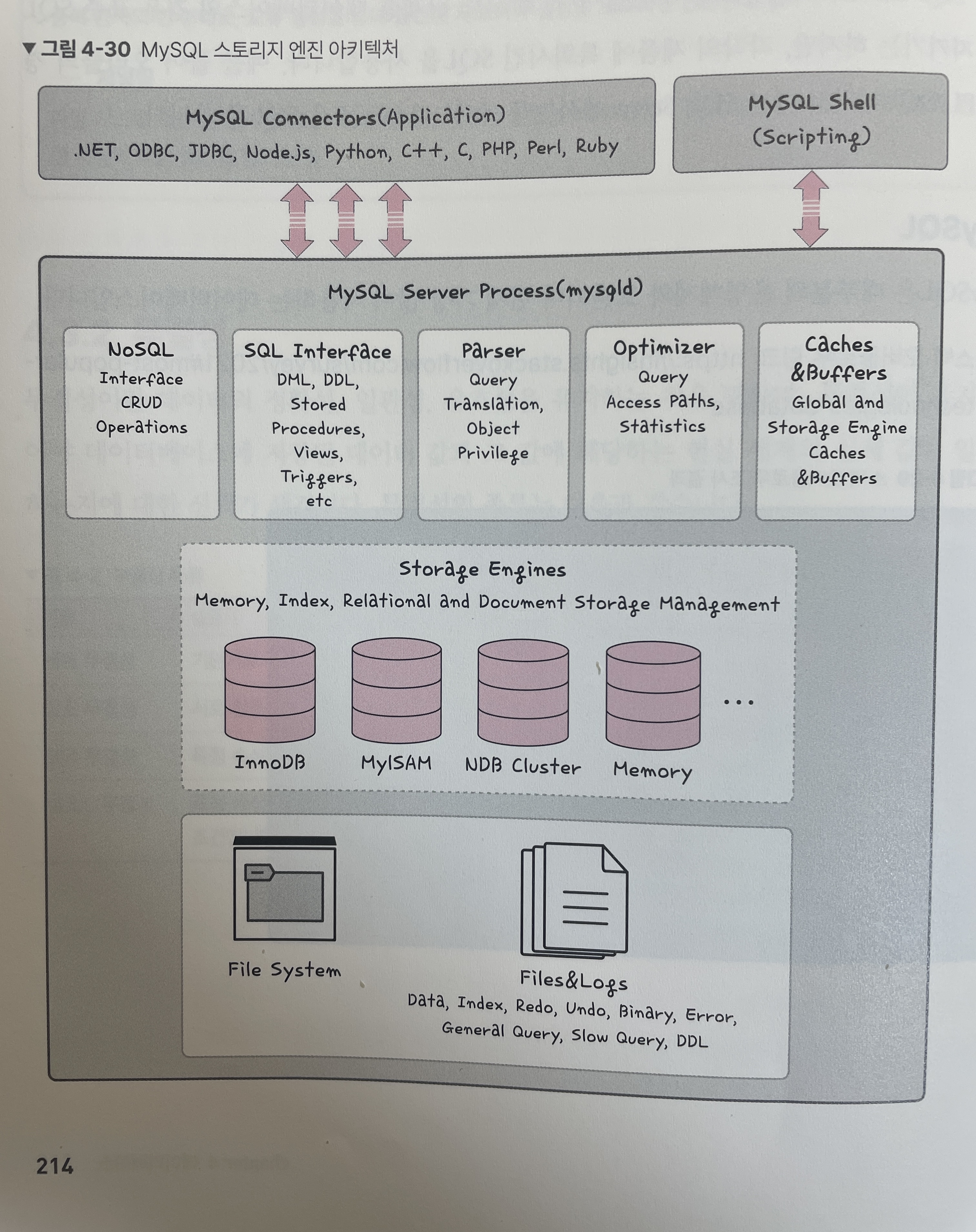
-
데이터베이스의 심장과도 같은 역할을 하는 곳이 바로
스토리지 엔진인데, 모듈식 아키텍쳐로 쉽게 스토리지 엔진을 바꿀 수 있으며, 데이터 웨어하우징, 트랜잭션 처리, 고가용성 처리에 강점을 두고 있다. -
스토리지 엔진 위에는
커넥터 API및서비스 계층을 통해 MySQL 데이터베이스와 쉽게 상호 작용할 수 있다. -
또한, MySQL은 쿼리 캐시를 지원해서 입력된 쿼리 문에 대한 전체 결과 집합을 저장하기 때문에 사용자가 작성한 쿼리가 캐시에 있는 쿼리와 동일하면 서버는 단순히 구문 분석, 최적화 및 실행을 건너뛰고 캐시의 출력만 표시한다.
-
하지만 MySQL에는 단점들이 있다.
-
복잡한 쿼리를 사용할 때에는 성능 저하를 일으킨다.
-
트랜잭션 지원이 완벽하지 않다.
-
사용자정의 함수의 사용이 쉽지 않고 유연하지 않는다.
-
PostgreSQL
PostgreSQL역시 개발자들이 선호하는 데이터베이스 기술로 널리 인정받고 있다.(세계 4위)
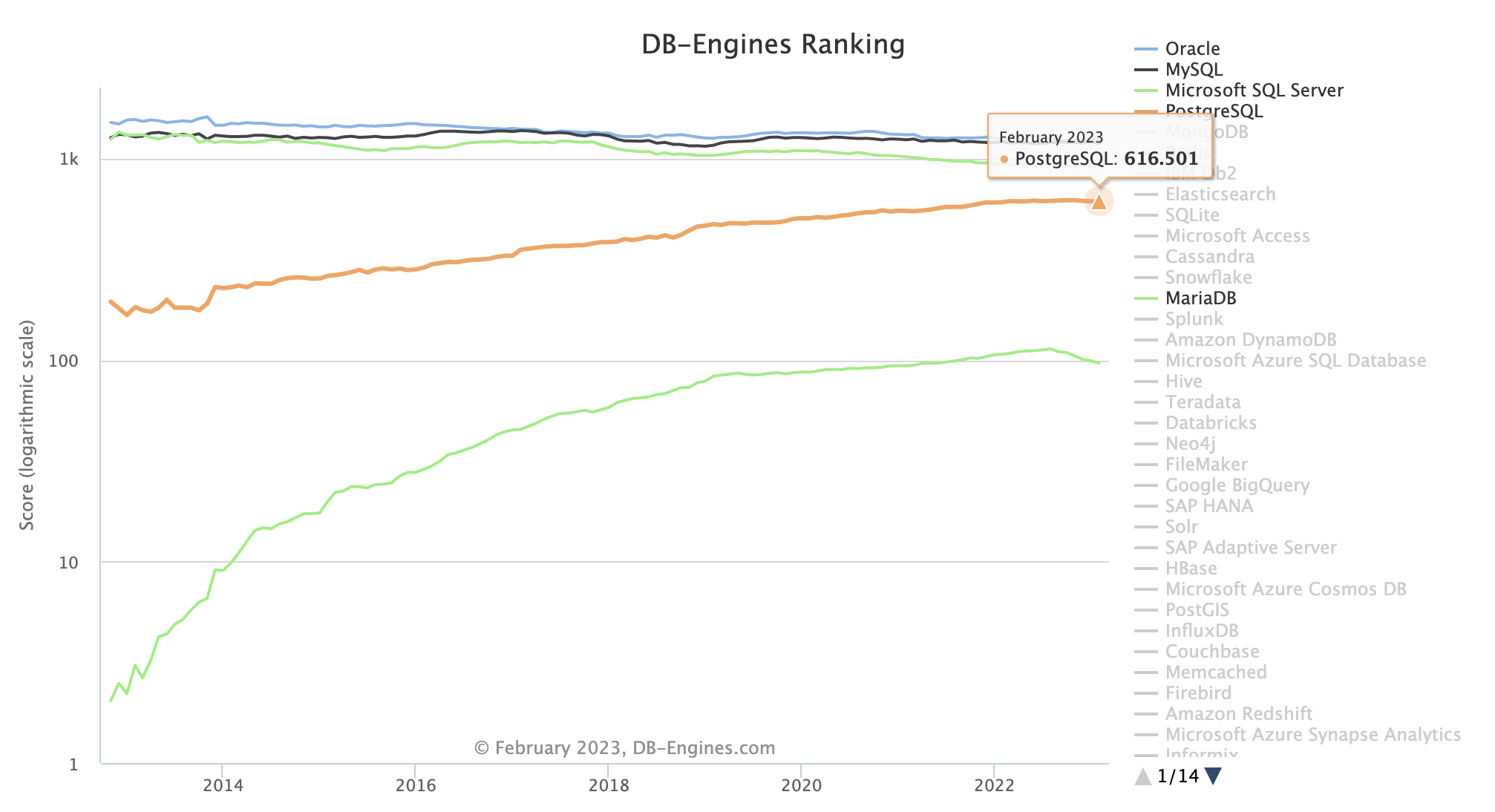
-
PostgreSQL 은 수년간 압도적인 성장 속도를 보여주며 3위와의 격차를 좁혀나가고 있다.
-
PostgreSQL의 특장점은 다음과 같다.
-
[1] 라이선스에 대한 비용 문제가 전혀 없다. - BSD 라이선스이며, 라이선스의 가장 큰 특징은 소스를 변경하고 그 소스를 숨긴 채 재배포 해도 법적으로 문제가 없다는 점이다.
-
[2] 오래된 오픈소스의 안정성 - 매우 가볍게 돌아가는 데이터베이스지만, 대용량 데이터의 처리에도 큰 문제점이 발견되지 않았고, 표준SQL 잘 따르고있다.
-
[3] 여전히 발전중인 데이터베이스 - PostgreSQL은 생각보다 빠른 속도로 업데이트를 지속하고 있다.
-
[4] 장점이자 단점인 독창적인 자료형 및 문법 - 장애 시 참고자료로 국내자료에서 쉽게 찾아볼 수 없다. ostgreSQL의 최근 버젼들이 오류메시지를 한글화해서 보여주면서, 한글 오류를 해외 레퍼런스에서 검색하는데 있어 많은 어려움을 겪기도 했다.
-
-
-
[Programmers] 17677. [1차] 뉴스 클러스터링
성능 요약
- 메모리: 81.2 MB, 시간: 7.34 ms
구분
- 코딩테스트 연습 > 2018 KAKAO BLIND RECRUITMENT
Answer Code1(2021.02.11)
import java.util.*; class Solution { public int solution(String str1, String str2) { //[1] ArrayList<String> list1 = new ArrayList<>(); ArrayList<String> list2 = new ArrayList<>(); ArrayList<String> intersection = new ArrayList<>(); ArrayList<String> union = new ArrayList<>(); double jaccard = 0; //[2] str1 = str1.toLowerCase(); str2 = str2.toLowerCase(); //[3] for(int i = 0; i < str1.length()-1; i++) { char first = str1.charAt(i); char second = str1.charAt(i + 1); if((first >= 'a' && first <= 'z') && (second >= 'a' && second <= 'z')) { list1.add(first + "" + second); } } for(int i = 0; i < str2.length()-1; i++) { char first = str2.charAt(i); char second = str2.charAt(i + 1); if((first >= 'a' && first <= 'z') && (second >= 'a' && second <= 'z')) { list2.add(first + "" + second); } } for(String s : list1) { if(list2.remove(s)) { intersection.add(s); } union.add(s); } for(String s : list2) { union.add(s); } //[4] if(union.size() == 0) { jaccard = 1; } else { jaccard = (double)intersection.size() / (double)union.size(); } //[5] return (int)(jaccard * 65536); } }문제 풀이
-
문제 설명 요약 : 자카드 유사도를 구하는 문제인데, 자카드 유사도의 값은
교집합 / 합집합이다.-
대소문자를 구분하지 않는다.
-
공집합일 경우에는 값을
1로 정의한다. -
기타 공백 or 숫자 or 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다.
-
-
풀이 순서
-
[1] 두 집합을 연결리스트로 생성한다. 그리고 교집합과 합집합을 담는 연결리스트를 생성한다.
-
[2] 두 문자열을 전부 소문자로 변환한다.
-
[3] 기타 공백 or 숫자 or 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다.
list2.remove(s): 해당 값이 있으면 제거하고 true을 반환하거나 해당 값이 없으면 false를 반환한다.
-
[4] 공집합일 경우에는
1로 정의한다. -
[5] 자카드 유사도를 구한다.(소수점이 나오도록 double형으로 변환하여 계산한다)
- 마지막에 정수형으로 return 할 때 int형으로 변환하여 65536을 곱한다.
-
Review
-
2018 KAKAO BLIND RECRUITMENT 1차 5번 문제였다. (난이도 : 중)
-
문제 설명이 길다고 해서 겁먹지 말고, 집중해서 읽으면 쉽게 풀 수 있는 문제였다.
-
조건이 많으면, 풀이 순서를 정리한 뒤에 하나씩 풀어나가는 연습을 꼭 하자.
-
[Programmers] 64065. 튜플
성능 요약
-
메모리: 76.2 MB, 시간: 0.38 ms - Answer Code1(2022.02.10)
-
메모리: 75.2 MB, 시간: 0.69 ms - Answer Code2(2022.02.10)
구분
- 코딩테스트 연습 > 2019 카카오 개발자 겨울 인턴십
Answer Code1(2022.02.10)
import java.util.ArrayList; import java.util.Comparator; import java.util.Arrays; class Solution { public ArrayList<Integer> solution(String s) { ArrayList<Integer> answer = new ArrayList<>(); s = s.substring(2, s.length()); s = s.substring(0, s.length() -2).replace("},{", "-"); String str[] = s.split("-"); Arrays.sort(str, new Comparator<String>() { public int compare(String s1, String s2) { return s1.length() - s2.length(); // return Integer.compare(o1.length(), o2.length()); } }); for(String x : str) { String [] temp = x.split(","); for(int i = 0; i < temp.length; i++) { int n = Integer.parseInt(temp[i]); if(!answer.contains(n)) { answer.add(n); } } } return answer; } }문제 풀이
-
튜플을 만들 ArrayList 객체를 선언하고, 가장 앞에 있는
{{부분과 가장 뒤에 있는}}부분을 제거한다. => substring() 메서드를 사용하여 제거한다. -
{,}형태의 문자열을-으로 바꾼다. =>replace("},{", "-")' -
위에서 바꾼 문자열
-을 기준으로 구분해준다. =>.split("-"); -
원소들의 길이를 기준으로 정렬한 뒤 가장 짧은 원소부터 고려하며 튜플을 채워나간다.
-
예)
"{{2},{2,1},{2,1,3},{2,1,3,4}}"인 경우 가장 짧은 원소인{2}부터 시작해서 채워나간다. -
java.util.Arrays유틸리티 클래스를 사용하여Arrays.sort()메서드를 통해 오름차순 정렬을 해준다. -
원하는 정렬 조건을 만들기 위해서는
import java.util.Comparator클래스내compare()메서드를 사용한다. -
반복문을 이용하여
,을 기준으로 구분(split(","))하여 새로운 문자열 배열을 만든다. -
그리고 안에 반복문을 이용하여 각 문자열 값을 정수로 바꾼다. =>
Integer.parseInt(); -
튜플에 들어있는 값이 아니라면 추가한다. =>
.contains(),.add()
-
-
-
[Jekyll] 에서 Liquid syntax error 처리하는 방법
-
TCP와 UDP
- 전송 계층
- TCP/UDP 계층의 기능 및 역할
- 흐름 제어 기법(Flow control)
- TCP의 내부동작 원리1: 연결 설정 단계
- TCP의 내부동작 원리2: 상대 소켓과의 데이터 송수신
- TCP의 내부동작 원리3: 상대 소켓과의 연결종료
전송 계층
-
전송 계층은 인터넷 기반의 송신자와 수신자를 연결하는 통신 서비스를 제공하며
[1]연결 지향 데이터 스트림 지원, [2]신뢰성, [3]흐름 제어를 제공할 수 있으며
애플리케이션과 인터넷 계층 사이의 데이터가 전달될 때 중계 역할을 한다.
-
대표적으로 TCP와 UDP가 있다.
TCP/UDP 계층의 기능 및 역할
- 실제 데이터의 송신과 관련 있는 계층으로 전송(Transport) 계층이라고도 한다.
TCP
-
TCP(Transmission Control Protocol)는 데이터의 전송을 보장하는 프로토콜이다.(신뢰성이 있는 프로토콜) -
TCP는 패킷 사이의 순서를 보장하고 신뢰성을 보장하기 때문에 연결 지향 프로토콜로 수신여부를 확인하기 때문에 신뢰성은 높지만 속도가 느리다는 단점이 있다.
-
대부분 1대1 통신이며, 가상 회선 패킷 교환방식을 사용한다.
- 가상 회선 패킷 교환방식 - 각 패킷에는 가상회선 식별자가 포함되며, 모든 패킷을 전송하면 가상회선이 해제되고 패킷들은 전송된 순서대로 도착하는 방식을 말한다.
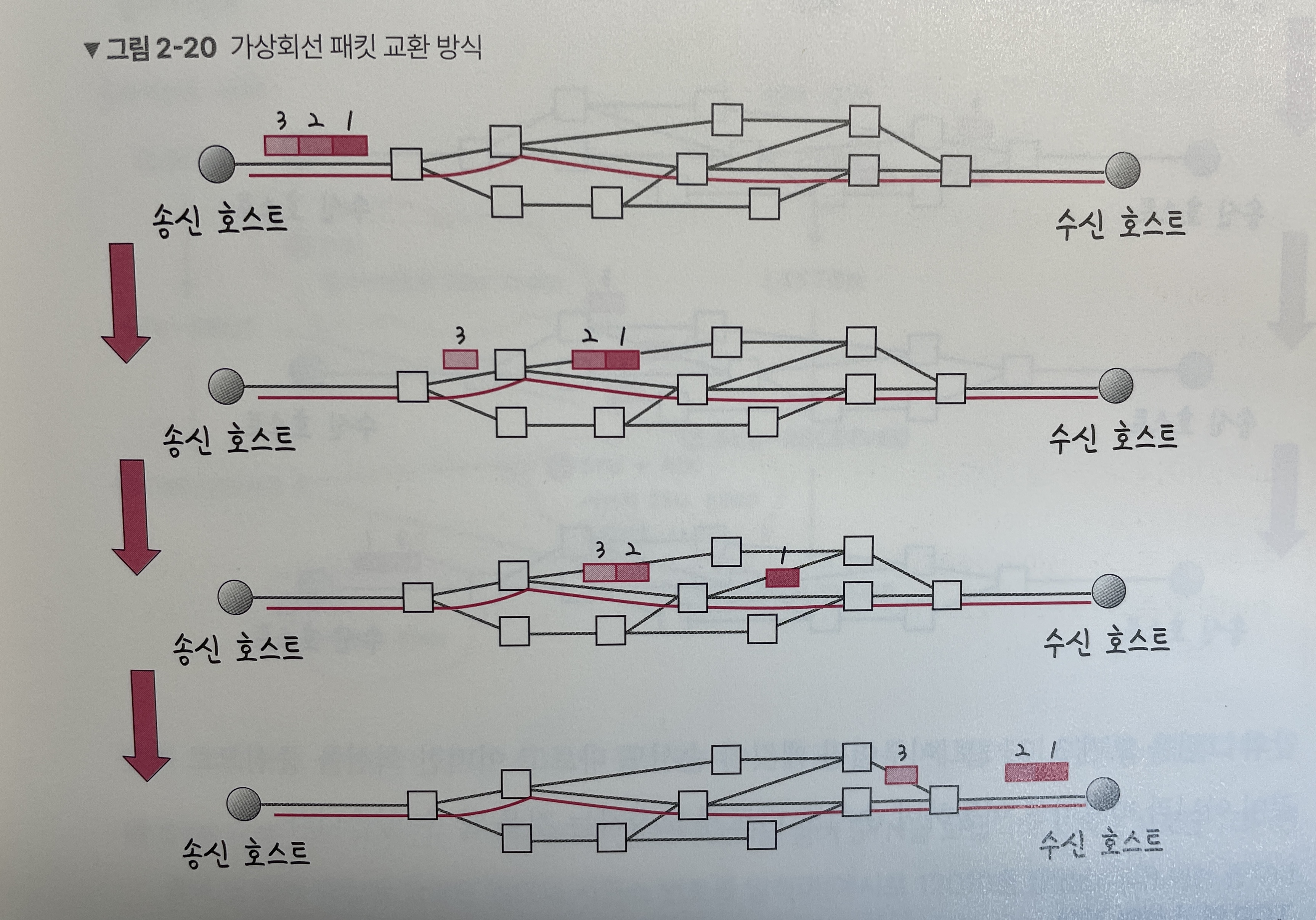
-
예) HTTP, Email, File transfer
UDP
-
UDP(User Datagram Protocol)는 데이터의 전송을 보장하지 않는 프로토콜이다. -
UDP는 패킷 사이의 순서를 보장하지 않고 수신 여부를 확인하지 않으며 단순히 데이터만 주는
데이터 패킷 교환 방식을 사용한다.- 데이터 패킷 교환 방식 - 패킷이 독립적으로 이동하며 최적의 경로를 선택하여 간다. 하나의 메시지에서 분할된 여러 패킷은 도착한 순서가 다를 수 있는 방식을 말한다.
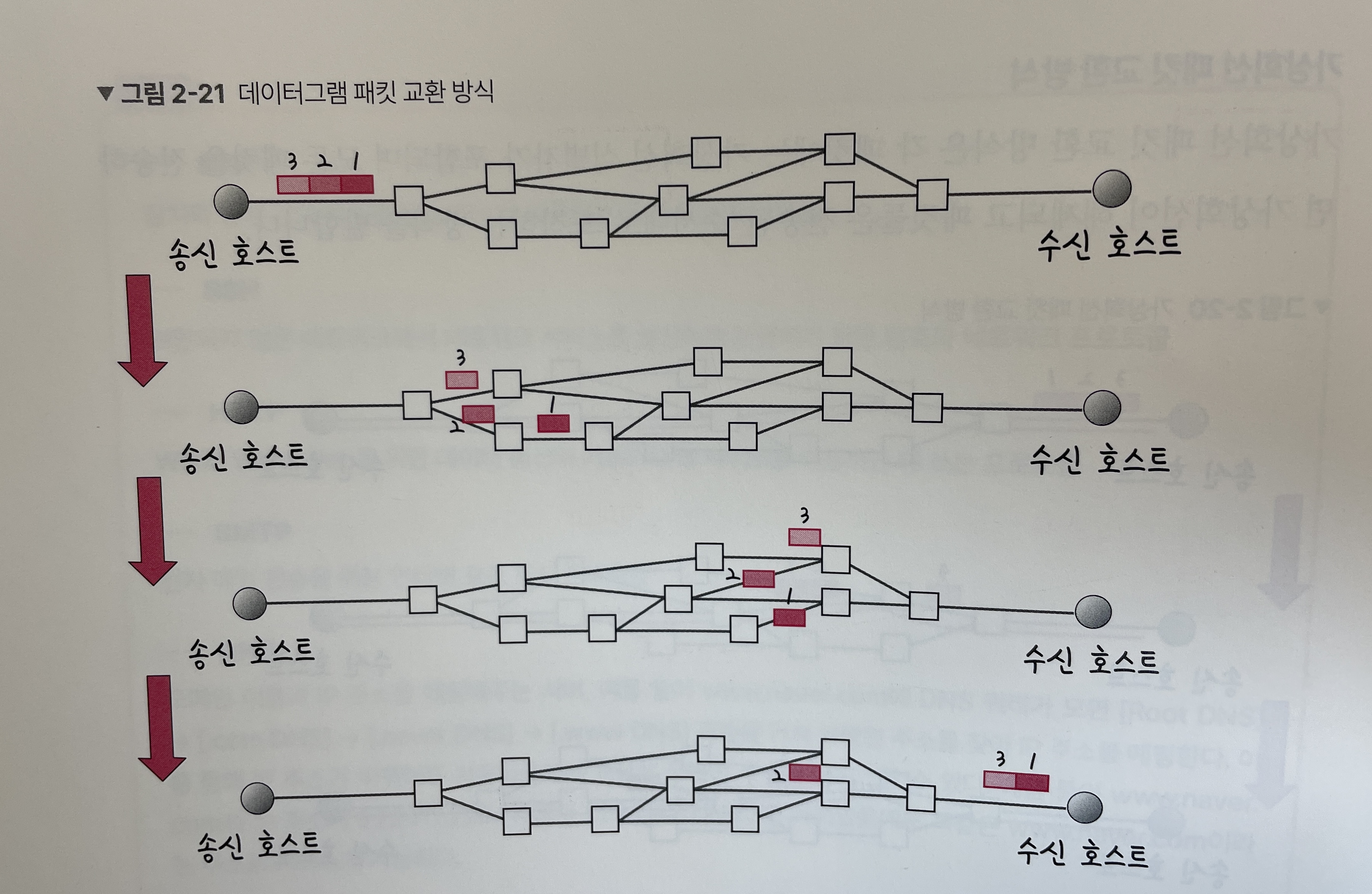
-
1대1 통신 또는 1대 N 통신 또는 N:N 통신이 있다.
-
예) DNS, Broadcasting
흐름 제어 기법(Flow control)
- 송신측과 수신측의 데이터 처리 속도 차이를 해결 하기 위한 방법
-
정지-대기(Stop-and-wait) 기법
-
슬라이딩 윈도우 (Sliding Window) 기법
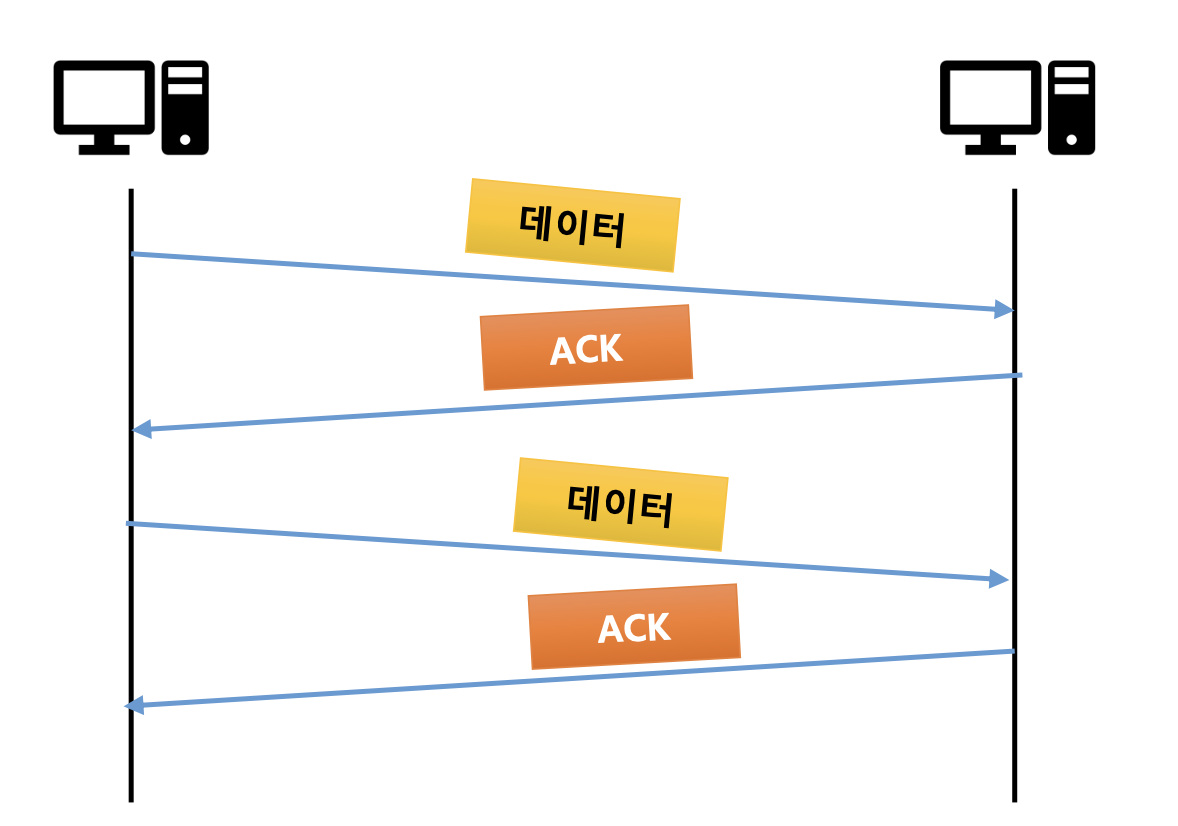
Stop-and wait 동작 방법
-
전송 측이 프레임을 전송한 다음, 각 데이터 프레임에 대한
ACK를 기다린다. -
ACK프레임이 도착하면 다음 프레임을 전송하는 기법이다.
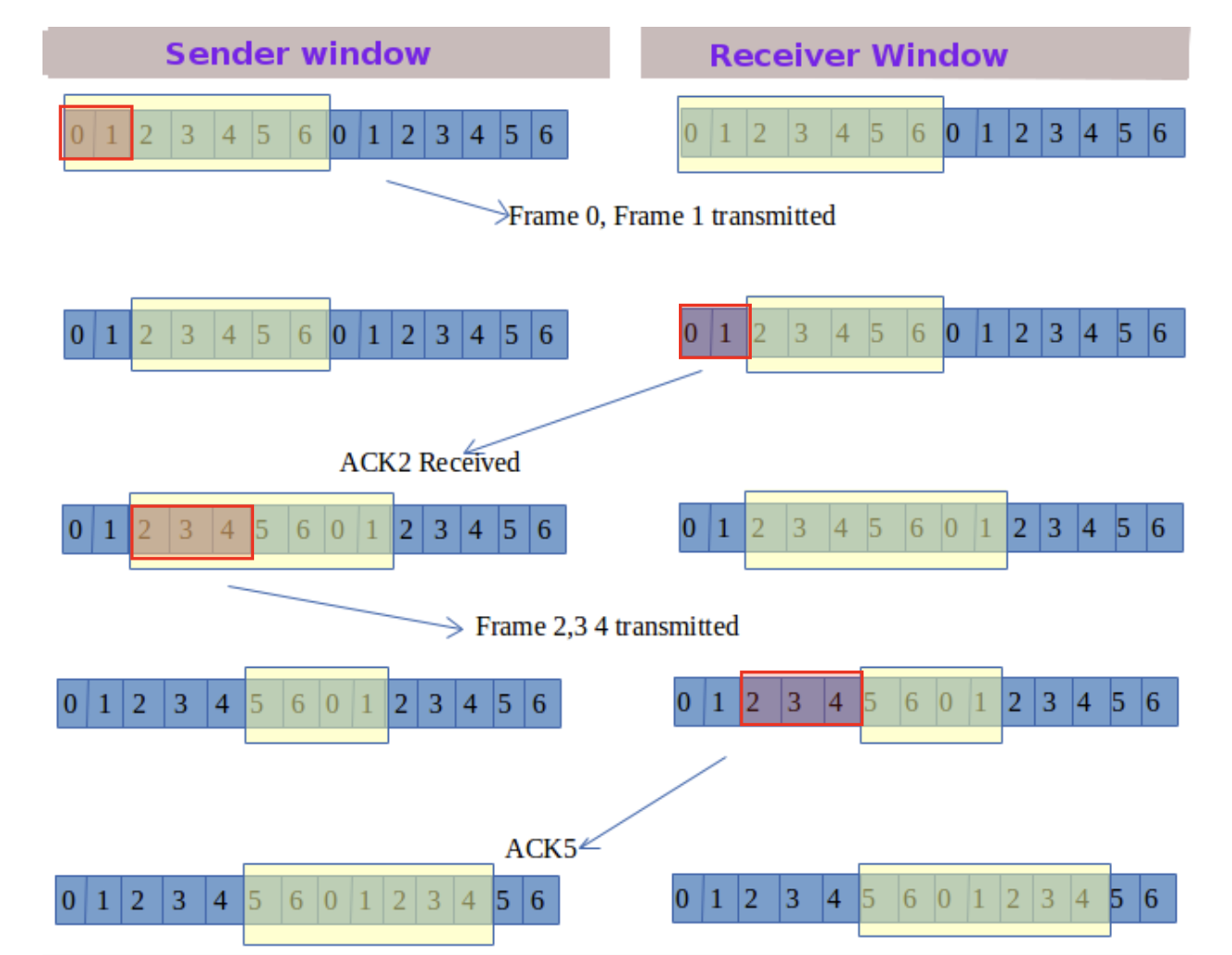
Sliding Window 동작 방법
-
수신측에서 설정한 윈도우 크기만큼 송신측에서 확인 응답(ACK) 없이 패킷을 전송할 수 있어서 데이터 흐름을 동적으로 조절하는 기법이다.
- Window : 전송 및 수신 측에서 만들어진 버퍼의 크기
-
ACK 프레임이 도착하면, 전송측 윈도우는 ACK 프레임 수에 따라 오른쪽 경계가 이동하여 윈도우 크기가 늘어난다.
TCP의 내부동작 원리1: 연결 설정 단계
상황 : 팬시가 주디에게 데이터를 전달하는 상황
-
팬시 : 안녕! 주디, 내가 전달할 데이터가 있으니 우리 연결좀 하자.
-
주디 : 알겠어! 지금 나도 준비가 되었으니 언제든 시작해도 좋아!
-
팬시 : 내 요청을 들어줘서 고마워~
이런 TCP 연결 성립 과정을
Three-way handshaking이라고 한다.SYN - SYN + ACK - ACK
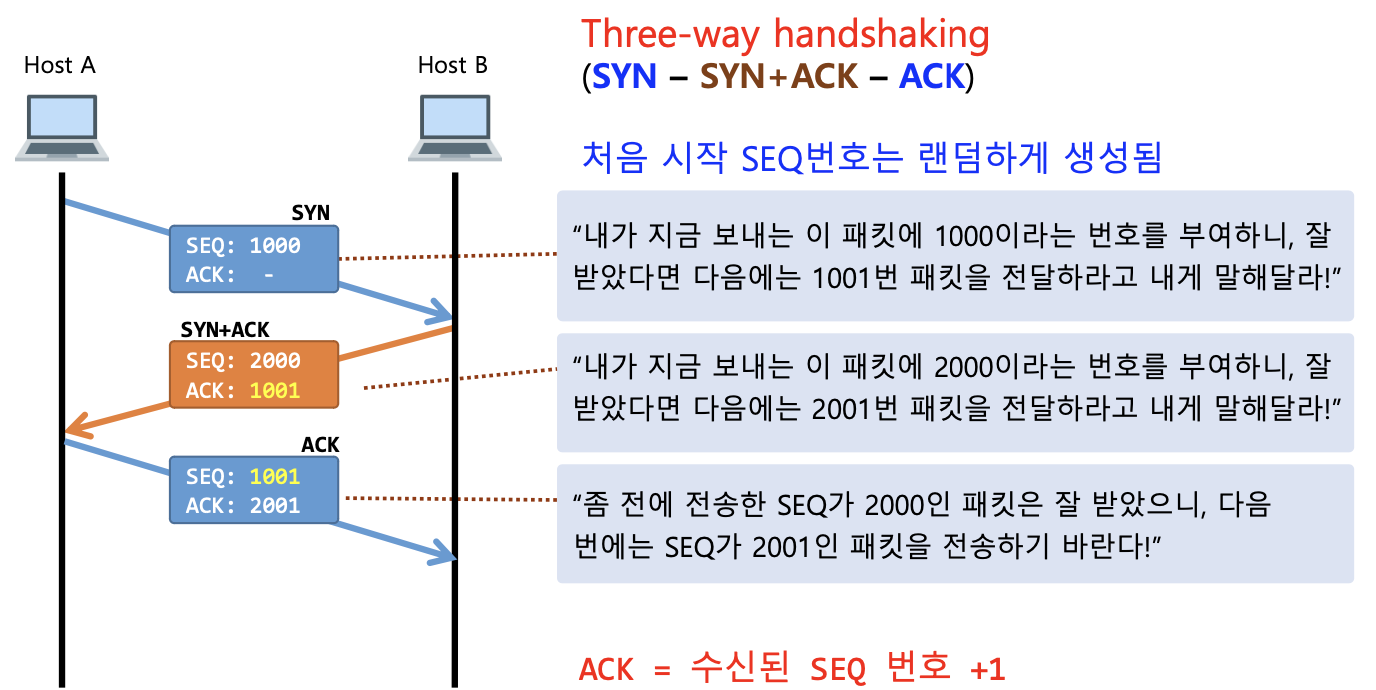
-
처음 시작 SEQ번호는 랜덤하게 생성된다. 그 이유는 연결을 맺을 때 사용하는 포트(Port)는 유한 범위 내에서 사용하고 시간이 지남에 따라 재사용된다.
-
따라서 두 통신 호스트가 과거에 사용된 포트 번호 쌍을 사용하는 가능성이 존재한다. 서버측에서는 패킷의 SYN을 보고 패킷을 구분하게 되는데 난수가 아닌 순차적인 숫자가 전송된다면 이전의 연결로부터 오는 패킷으로 인식할 수 있다.
-
이런 문제의 발생 가능성을 낮추기 위해 SEQ번호를 랜덤으로 설정한다.
TCP의 내부동작 원리2: 상대 소켓과의 데이터 송수신
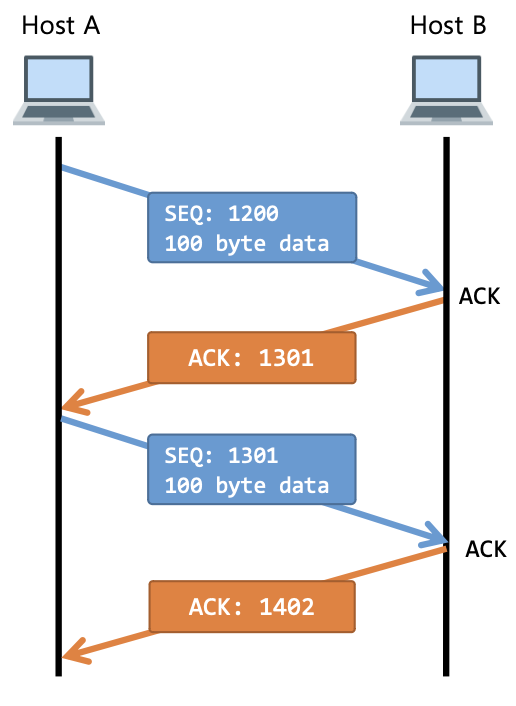
-
ACK의 값을 전송된 바이트 크기만큼 증가시키는 이유는 패킷의 전송유무 뿐만 아니라, 데이터 손실유무까지 확인하기 때문이다.
-
[1] ACK = 1200 + 100 byte + 1
-
[2] ACK = 1301 + 100 byte + 1
-
-
ACK 번호 = SEQ 번호 + 전송된 바이트 수 + 1
-
SEQ 전송 시 타이머가 작동되며 SEQ에 대한 ACK가 전송되지 않을 경우 데이터를 재전송한다.
TCP의 내부동작 원리3: 상대 소켓과의 연결종료
상황 : 팬시가 주디에게 연결을 끊고자 하는 경우
-
팬시 : 주디! 지금 연결을 끊고자 하는데 지금 괜찮을까요?
-
주디 : 아! 그러세요? 잠시만요~
-
주디 : 네 저도 준비가 끝났습니다. 그럼 연결을 끊으시죠!
-
팬시 : 네! 그동안 즐거웠습니다.
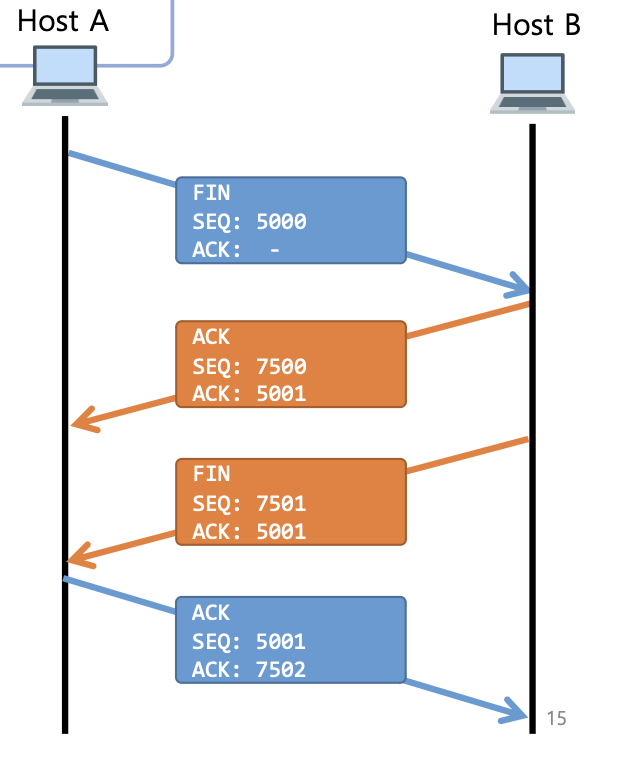
이러한 TCP 연결 해제 과정을
Four-way handshaking이라고 한다.FIN – ACK – FIN - ACK
-
TCP의 연결 성립 과정과 연결 해제 과정의 단계수가 차이 나는 이유는 클라이언트가 데이터 전송을 마쳤다고 해도 서버는 아직 보낼 데이터가 남아있을 수 있기 때문에 일단 FIN에 대한 ACK만 보내고, 데이터를 모두 전송한 후 자신(서버)도 FIN 메시지를 보내기 때문이다.
-
그래서 마지막 4번째인 클라이언트(팬시)에서 TIME_WAIT 상태가 된다. 서버(주디)로부터 해지 준비가 되었다는 ACK를 보낸후 서버에서 CLOSE 상태가 된 이후에 클라이언트(팬시)는 어느 정도의 시간을 대기한 후에 연결을 닫고 모든 자원의 연결이 종료된다.
-
TIME_WAIT이란 소켓이 바로 소멸되지 않고 일정 시간 유지하는 상태이다. -
Four-way handshaking과정을 거쳐서 연결을 종료하는 이유는 패킷이 지연되거나 일반적인 종료로 인한 데이터 손실을 막기 위함이다.
- DevHistory 4
- Essay 1
- Java 10
- Spring 15
- SpringBoot 17
- JPA 13
- MySQL 3
- Flyway 1
- Kafka 8
- Technology 22
- GoodCode 7
- Side_Project 20
- Retrospective 4
- AlgorithmSkill 3
- LeetCode 2
- Algorithm 70
- SQL 9
- OS 14
- Database 8
- Network 7
- HTTP 7
- DataStructure 5
- Linux 4
- Woowacourse 4
- Git 9
- AssertJ 1
- IntelliJ 5
- Probability-Statistics 5
- Electronic-Finance 13
- Business-Statistics 13
- Competition 1
- Book 6
- Workout 7
- E.T.C 8